basic statistics european molecular biology laboratory predoc bioinformatics course 17 th nov 2009...
TRANSCRIPT

Basic statistics
European Molecular Biology LaboratoryPredoc Bioinformatics Course
17th Nov 2009
Tim Massingham, [email protected]

Introduction
Basic statisticsWhat is a statistical testCount data and Simpson’s paradoxA Lady drinking tea and statistical power Thailand HIV vaccine trial and missing dataCorrelation
Nonparametric statisticsRobustness and efficiencyPaired data Grouped data
Multiple testing adjustmentsFamily Wise Error Rate and simple correctionsMore powerful correctionsFalse Discovery Rate

What is a statisticAnything that can be measuredCalculated from measurements
Branches of statisticsFrequentistNeo-FisherianBayesianLiesDamn lies
(and each of these can be split further)
“If your experiment needs statistics, you ought to have done a better experiment.” Ernest Rutherford
“Statistical thinking will one day be as necessary for efficient citizenship as the ability to read and write.” H.G.Wells
“He uses statistics as a drunken man uses lamp-posts, for support rather than illumination.” Andrew Lang (+others)
Classical statistics

Repeating the experiment
1,000 times
10,000 times100 times
Initial experiment
Imagine repeating experiment, some variation in statistic

Frequentist inferenceRepeated experiments at heart of frequentist thinking
Have a “null hypothesis”
Null distributionWhat distribution of statistic
would look like if we could repeatedly sample
Likely Unlikely
Compare actual statistic to null distribution
Classical statistics Finding statistics for which the null distribution is known

Anatomy of a Statistical Test
Value of statistic
Density of null distribution
P-value of testProbability of observing statistic or something more extremeEqual to area under the curve
Density measures relative probabilityTotal area under curve equals exactly one

Some antiquated jargon
Critical values
Dates back to when we used tables
Old wayCalculate statisticLook up critical values for testReport “significant at 99% level”Or “rejected null hypothesis at ….”
Size 0.05 0.01 0.001 0.0001
Critical value 1.64 2.33 3.09 3.72
Pre-calculated values (standard normal distribution)

PowerPowerProbability of correctly rejecting null hypothesis (for a given size)
Null distribution An alternative distribution
Power changes with size
Reject nullAccept null

Confidence intervals
Use same construction to generate confidence intervalsConfidence interval = region which excludes unlikely values
For the null distribution, the “confidence interval” is the region which we accept the null hypothesis.
The tails where we reject the null hypothesis are the critical region

Count data

Count data
(Almost) the simplest form of data we can work with
Each experiment gives us a discrete outcomeHave some “null” hypothesis about what to expect
Yellow Black Red Green Orange
Observed 19 27 15 22 17
Expected 20 20 20 20 20
Example: Are all jelly babies equally liked by PhD students?

Chi-squared goodness of fit test
Yellow Black Red Green Orange
Observed 19 27 15 22 17
Expected 20 20 20 20 20
Summarize results and expectations in a table
jelly_baby <- c( 19, 27, 15, 22, 17)expected_jelly <- c(20,20,20,20,20)chisq.test( jelly_baby, p=expected_jelly, rescale.p=TRUE )
Chi-squared test for given probabilities
data: jelly_baby X-squared = 4.4, df = 4, p-value = 0.3546
pchisq(4.4,4,lower.tail=FALSE)[1] 0.3546

Chi-squared goodness of fit test
jelly_baby <- c( 19, 27, 15, 22, 17)expected_jelly <- c(20,20,20,20,20)chisq.test( jelly_baby, p=expected_jelly, rescale.p=TRUE )
Chi-squared test for given probabilities
data: jelly_baby X-squared = 4.4, df = 4, p-value = 0.3546
What’s this?
Yellow Black Red Green Orange
Observed 19 27 15 22 17
19 27 15 22 ?
How much do we need to know to reconstruct table?Number of samplesAny four of the observationsor equivalent, ratios for example
More complex models
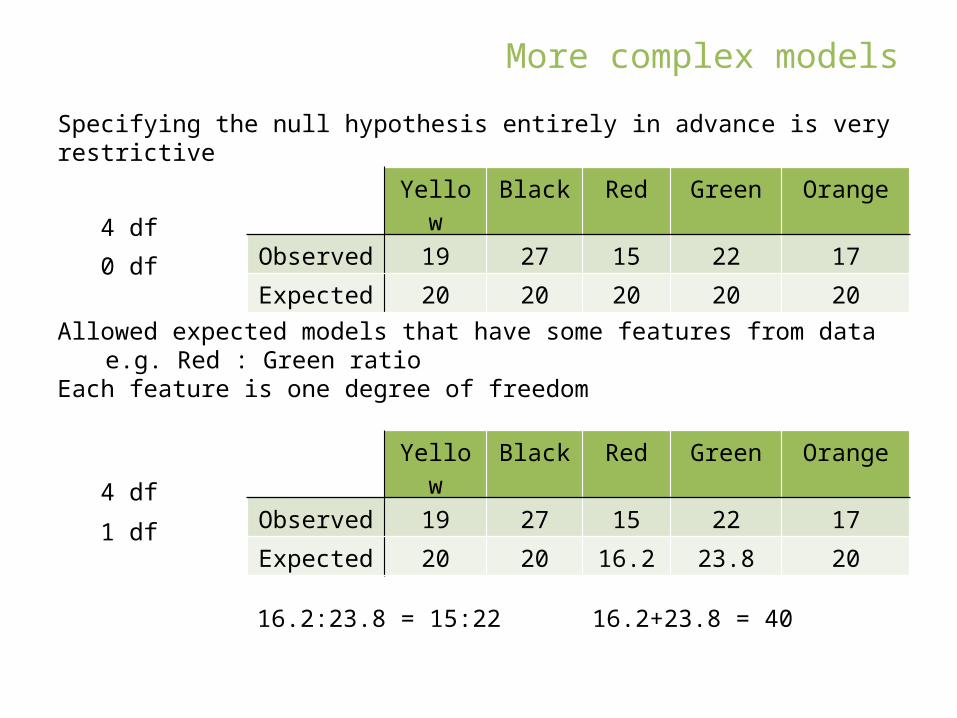
Specifying the null hypothesis entirely in advance is very restrictive
Yellow Black Red Green Orange
Observed 19 27 15 22 17
Expected 20 20 20 20 20
4 df
0 df
Allowed expected models that have some features from datae.g. Red : Green ratio
Each feature is one degree of freedom
Yellow Black Red Green Orange
Observed 19 27 15 22 17
Expected 20 20 16.2 23.8 20
16.2:23.8 = 15:22 16.2+23.8 = 40
4 df
1 df
Example: Chargaff’s parity rule
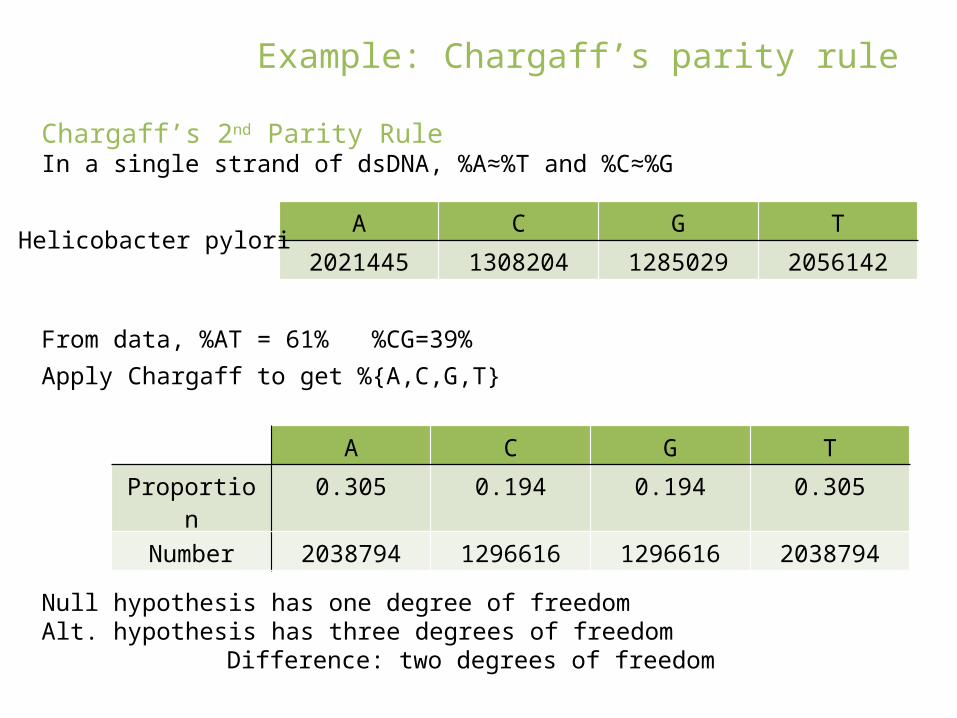
Chargaff’s 2nd Parity RuleIn a single strand of dsDNA, %A≈%T and %C≈%G
A C G T
2021445 1308204 1285029 2056142Helicobacter pylori
From data, %AT = 61% %CG=39%
Apply Chargaff to get %{A,C,G,T}
A C G T
Proportion 0.305 0.194 0.194 0.305
Number 2038794 1296616 1296616 2038794
Null hypothesis has one degree of freedomAlt. hypothesis has three degrees of freedom
Difference: two degrees of freedom

Contingency tables
Pie Fruit
Custard a c
Ice-cream b d
Observe two variables in pairs - is there a relationship between them?
Silly example: is there a relationship desserts and toppings?
A test of row / column independence
Real exampleMcDonald-Kreitman test - Drosophila ADH locus mutations
Between Within
Nonsynonymous 7 2
Synonymous 17 42

Contingency tables
A contingency table is a chi-squared test in disguise
Pie Fruit
Custard p
Ice-cream (1-p)
q (1-q) 1
Null hypothesis: rows and columns are independentMultiply probabilities
Pie & Custard
Pie & Ice-cream
Fruit & Custard
Fruit & Ice-cream
Observed a b c d
Expected n p q n (1-p) q n p (1-q) n (1-p)(1-q)
p q p (1-q)
(1-p) q (1-p)(1-q)
× n
× n

Contingency tables
Pie & Custard
Pie & Ice-cream
Fruit & Custard
Fruit & Ice-cream
Observed a b c n - a - b - c
Expected n p q n (1-p) q n p (1-q) n (1-p)(1-q)
Observed: three degrees of freedom (a, b & c)Expected: two degrees of freedom(p & q)
In general, for a table with r rows and c columnsObserved: r c - 1 degrees of freedomExpected: (r-1) + (c-1) degrees of freedomDifference: (r-1)(c-1) degrees of freedom
Chi-squared test with one degree of freedom

Bisphenol A
Bisphenol A is an environmental estrogen monomerUsed to manufacture polycarbonate plastics• lining for food cans• dental sealants• food packaging
Many in vivo studies on whether safe: could polymer break down?
Is the result of the study independent of who performed it?
F vom Saal and C Hughes (2005) An Extensive New Literature Concerning Low-Dose Effects of Bisphenol A Shows the Need for a New Risk Assessment. Environmental Health Perspectives 113(8):928
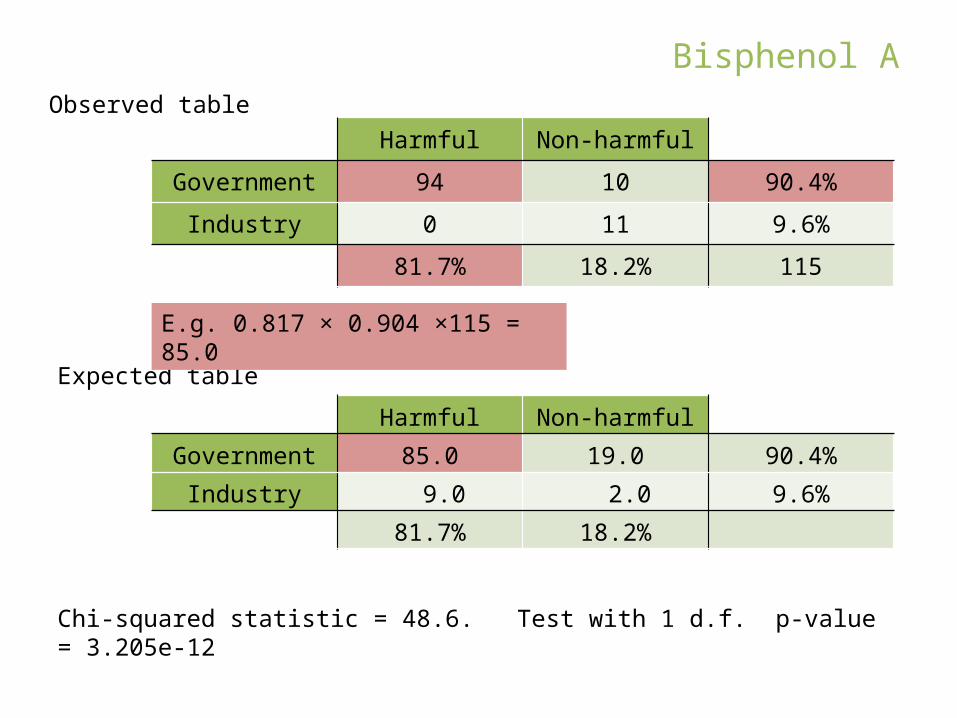
Harmful Non-harmful
Government 94 10
Industry 0 11
Bisphenol A
Harmful Non-harmful
Government 94 10 90.4%
Industry 0 11 9.6%
81.7% 18.2% 115
Observed table
Harmful Non-harmful
Government 85.0 19.0 90.4%
Industry 9.0 2.0 9.6%
81.7% 18.2%
Expected table
E.g. 0.817 × 0.904 ×115 = 85.0
Chi-squared statistic = 48.6. Test with 1 d.f. p-value = 3.205e-12

Bisphenol AAssociation measureDiscovered that we have dependenceHow strong is it?
€
ϕ =X 2
nCoefficient of associationfor 2×2 table
Chi-squared statistic
Number of observations
Number between 0 = independent to 1 = complete dependence
For the Bisphenol A study data
€
ϕ =X 2
n=48.56
115= 0.65
Should test really be one degree of freedom?Reasonable to assume that government / industry randomly assigned?Perhaps null model only has one degree of freedom
pchisq(48.5589, df=1, lower.tail=FALSE)[1] 3.205164e-12pchisq(48.5589, df=2, lower.tail=FALSE)[1] 2.854755e-11

Simpson’s paradox
Famous example of Simpson’s paradoxC R Charig, D R Webb, S R Payne, and J E Wickham (1986) Comparison of treatment of renal calculi by open surgery, percutaneous nephrolithotomy, and extracorporeal shockwave lithotripsy. BMJ 292: 879–882
Compare two treatments for kidney stones• open surgery• percutaneous nephrolithotomy (surgery through a small puncture)
Success Fail
open 273 77 350
perc. neph. 289 61 350
562 138 700
78% success83% success
Percutaneous nephrolithotomy appears better(but not significantly so, p-value 0.15)

Simpson’s paradox
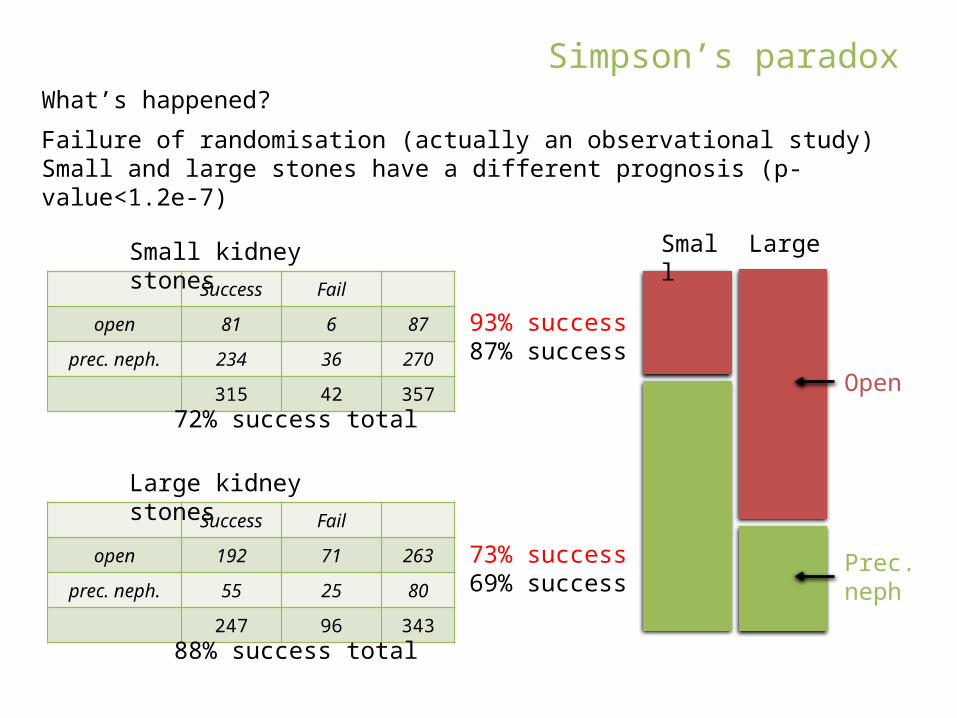
Success Fail
open 81 6 87
perc. neph. 234 36 270
315 42 357
Success Fail
open 192 71 263
perc. neph. 55 25 80
247 96 343
Small kidney stones
Large kidney stones
Missed a clinically relevant factor: the size of the stones
The order of treatments is reversed
93% success87% successp-value 0.15
73% success69% successp-value 0.55
CombinedOpen
78%Perc. neph. 83%
Simpson’s paradox
Success Fail
open 81 6 87
prec. neph. 234 36 270
315 42 357
Success Fail
open 192 71 263
prec. neph. 55 25 80
247 96 343
Small kidney stones
Large kidney stones
What’s happened?
Small Large
Failure of randomisation (actually an observational study)Small and large stones have a different prognosis (p-value<1.2e-7)
88% success total
72% success total
Open
Prec. neph
93% success87% success
73% success69% success

A Lady Tasting Tea

The Lady Tasting Tea
“A LADY declares that by tasting a cup of tea made with milk she can discriminate whether the milk or the tea infusion was first added to the cup …Our experiment consists in mixing eight cups of tea, four in one way and four in the other, and presenting them to the subject for judgment in a random order. The subject has been told in advance of what the test will consist, namely that she will be asked to taste eight cups, that these shall be four of each kind, and that they shall be presented to her in a random order.”
Fisher, R. A. (1956) Mathematics of a Lady Tasting Tea
• Eight cups of tea• Exactly four one way and four the other• The subject knows there are four of each• The order is randomised
Guess tea Guess milk
Tea first ? ? 4
Milk first ? ? 4
4 4 8

Fisher’s exact test
Guess tea Guess milk
Tea first ? ? 4
Milk first ? ? 4
4 4 8
Looks like a Chi-squared test
But the experiment design fixes the marginal totals• Eight cups of tea• Exactly four one way and four the other• The subject knows there are four of each• The order is randomised
Fisher’s exact test gives exact p-values with fixed marginal totals
Often incorrectly used when marginal totals not known

Sided-nessNot interested if she can’t tell the difference
Guess tea Guess milk
Tea first 4 0 4
Milk first 0 4 4
4 4 8
Guess tea Guess milk
Tea first 0 4 4
Milk first 4 0 4
4 4 8
Two possible ways of being significant, only interested in one
Exactly right
Exactly wrong

Sided-ness
tea <- rbind( c(0,4) , c(4,0) )tea [,1] [,2][1,] 0 4[2,] 4 0fisher.test(tea)$p.value[1] 0.02857143fisher.test(tea,alternative="greater")$p.value[1] 1fisher.test(tea,alternative="less")$p.value[1] 0.01428571
More correctMore wrong
Only interested in significantly greaterJust use area in one tail

Statistical power
Are eight cups of tea enough?
Guess tea Guess milk
Tea first 4 0 4
Milk first 0 4 4
4 4 8
A perfect score, p-value 0.01429
Guess tea Guess milk
Tea first 3 1 4
Milk first 1 3 4
4 4 8
Better than chance, p-value 0.2429

Statistical power
Guess tea Guess milk
Tea first p n (1-p) n n
Milk first (1-p) n p n n
n n 2n
Assume the lady correctly guesses proportion p of the time
4 6 8 10 12 14 16 18 20
70% 0.39 0.31 0.25 0.20 0.17 0.14 0.12 0.11 0.09
80% 0.25 0.16 0.11 0.07 0.05 0.04 0.03 0.02 0.01
90% 0.12 0.06 0.02 0.01 0.007 0.003 0.001 8e-5 4e-5
To investigate• simulate 10,000 experiments• calculate p-value for experiment• take mean

Thailand HIV vaccine trials

Thailand HIV vaccine trialNews story from end of September 2009
“Phase III HIV trial in Thailand shows positive outcome”
16,402 heterosexual volunteers tested every six months for three years
Sero +ve Sero -ve
Control 51 8197
Vaccine 74 8198
fisher.test(hiv)
Fisher's Exact Test for Count Data
data: hiv p-value = 0.04784alternative hypothesis: true odds ratio is not equal to 1 95 percent confidence interval: 0.4721409 0.9994766 sample estimates:odds ratio 0.689292
16,395
Rerks-Ngarm, Pitisuttithum et al. (2009) New England Journal of Medicine 10.1056/NEJMoa0908492

Thailand HIV vaccine trial
"Oh my God, it's amazing. "…"The significance that has been established in this trial is that there is a 5% chancethat this is a fluke. So we are 95% certain that what we are seeing is real and not down to pure chance. And that's great."
Significant? Would you publish? Should you publish?
Study was randomized (double-blinded)Deals with many possible complications• male / female balance between arms of trial• high / low risk life styles• volunteers who weren’t honest about their sexuality (or changed their mind mid-trial)• genetic variability in population (e.g. CCL3L1)• incorrect HIV test / samples mixed-up• vaccine improperly administered

Thailand HIV vaccine trial
"Oh my God, it's amazing. "…"The significance that has been established in this trial is that there is a 5% chancethat this is a fluke. So we are 95% certain that what we are seeing is real and not down to pure chance. And that's great."
Significant? Would you publish? Should you publish?
Initially published data based on modified Intent To TreatIntent To Treat
People count as soon as they are enrolled in trialmodified Intent To Treat
Excluded people found to sero +ve at beginning of trialPer-Protocol
Only count people who completed course of vaccines
A multiple testing issue?
How many unsuccessful HIV vaccine trials have there been?One or more and these results are toast.

Missing dataSome people go missing during / drop out of trials
This could be informative
E.g. someone finds out they have HIV from another source, stops attending check-ups
Double-blinded trials help a lotExtensive follow-up, hospital records of death etc
Missing Completely At RandomMissing data completely unrelated to trial
Missing At RandomMissing data can be imputed
Missing Not At RandomMissing data informative about effects in trial
1 2 3 4 5 6
Volunteer 1 - - - - ? ?
Volunteer 2 - - + + + +

Correlation
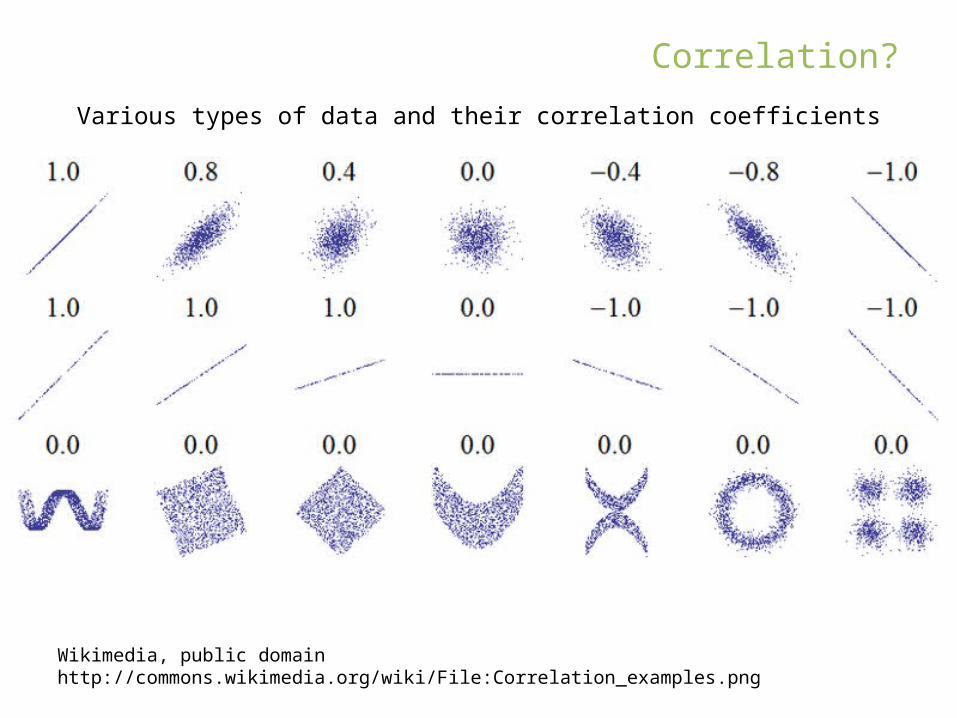
Correlation?
Wikimedia, public domainhttp://commons.wikimedia.org/wiki/File:Correlation_examples.png
Various types of data and their correlation coefficients

Correlation does not imply causationIf A and B are correlated then one or more of the following are true• A causes B• B causes A• A and B have a common cause (might be surprising)
Do pirates cause global warming?
Pirates: http://commons.wikimedia.org/wiki/File:PiratesVsTemp_English.jpg
R. Matthews (2001) Storks delivery Babies (p=0.008) Teaching Statistics 22(2):36-38

Pearson correlation coefficient
Standard measure of correlation “Correlation coefficient”
Measure of linear correlation, statistic belongs to [-1,+1] 0 independent 1 perfect positive correlation-1 perfect negative correlation
cor.test( gene1, gene2, method="pearson")
Pearson's product-moment correlation
data: gene1 and gene2 t = 851.4713, df = 22808, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: 0.9842311 0.9850229 sample estimates: cor 0.984632
Measure of correlationRoughly proportion of variance of gene1 explained by gene2 (or vice versa)

Pearson: when things go wrong
Pearson’s correlation test
Correlation = -0.05076632(p-value = 0.02318)
Correlation = -0.06499109 (p-value = 0.003632)
Correlation = -0.1011426 (p-value = 5.81e-06)
Correlation = 0.1204287 (p-value = 6.539e-08)
A single observation can change the outcome of many tests
Pearson correlation is sensitive to outliers
200 observations from normal distributionx ~ normal(0,1) y ~ normal(1,3)

Spearman’s testNonparametric test for correlation
Doesn’t assume data is normalInsensitive to outliersCoefficient has roughly same meaning
Replace observations by their ranks
Ranks
Raw expression
cor.test( gene1, gene2, method="spearman")
Spearman's rank correlation rho
data: gene1 and gene2 S = 30397631415, p-value < 2.2e-16
alternative hypothesis: true rho is not equal to 0 sample estimates: rho 0.984632

ComparisonLook at gene expression data
cor.test(lge1,lge2,method="pearson")
Pearson's product-moment correlation
data: lge1 and lge2 t = 573.0363, df = 22808, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: 0.9661278 0.9678138 sample estimates: cor 0.9669814
cor.test(lge1,lge2,method="spearman")
Spearman's rank correlation rho
data: lge1 and lge2 S = 30397631415, p-value < 2.2e-16
alternative hypothesis: true rho is not equal to 0 sample estimates: rho 0.984632
cor.test(lge1,lge2,method="kendall")
Kendall's rank correlation tau
data: lge1 and lge2 z = 203.0586, p-value < 2.2e-16
alternative hypothesis: true tau is not equal to 0 sample estimates: tau 0.8974576

ComparisonSpearman and Kendall are scale invariant
Log - Log scalePearson 0.97Spearman0.98Kendall 0.90
Normal - Log scalePearson 0.56Spearman0.98Kendall 0.90
Normal - Normal scalePearson 0.99Spearman0.98Kendall 0.90