aws re:invent 2016: real-time data exploration and analytics with amazon elasticsearch service and...
TRANSCRIPT

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Jon Handler, Principal Solutions Architect
November 29, 2016
Real-Time Data Exploration and
Analytics with Amazon Elasticsearch
Service and Kibana
BDM302

What to do with a terabyte of logs?


What to Expect from the Session
data source Amazon Kinesis Firehose Amazon Elasticsearch
Service
Kibana
123 4
Query DSL5

Demo: create an Amazon ES
domain

Shard 1 Shard 2 Shard 3 Shard 4
An index is a collection of documents, divided
into shards
Documents
Index
ID ID ID ID ID ID ID ID ID ID ID ID ID ID ID ID
...
Indexing, compression

Deployment of indices to a cluster
• Index 1– Shard 1
– Shard 2
– Shard 3
• Index 2– Shard 1
– Shard 2
– Shard 3
Amazon ES cluster
1
2
3
1
2
3
1
2
3
1
2
3
Primary Replica
1
3
3
1
Instance 1,
Master
2
1
1
2
Instance 2
3
2
2
3
Instance 3

How many instances?
The index size will be about the same as the
corpus of source documents
• Double this if you are deploying an index replica
Size based on storage requirements
• Either local storage or 512GB of Amazon Elastic
Block Store (EBS) per instance
• Example: 2TB corpus will need 8 instances– Assuming a replica and using EBS
– With i2.2xlarge nodes using 1.6TB ephemeral storage, 4 nodes would be enough
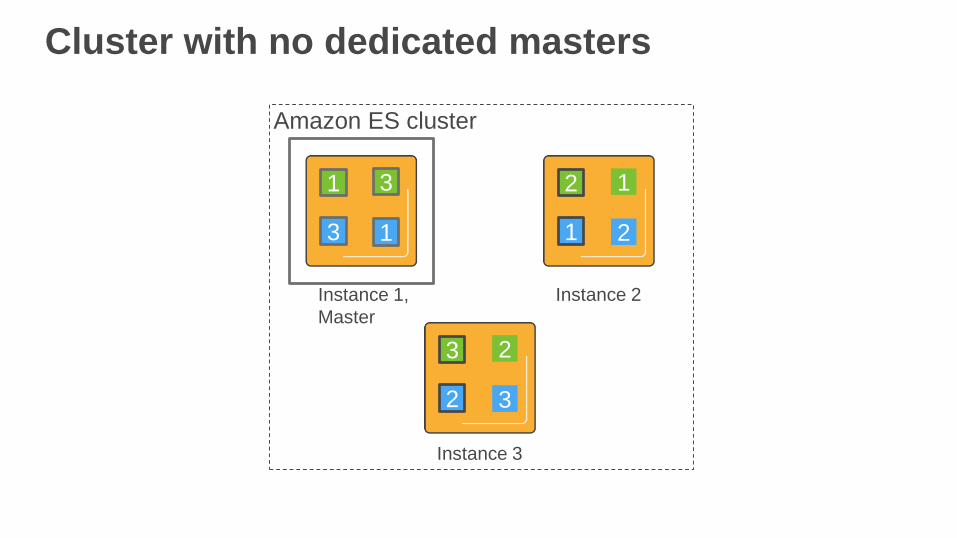
Cluster with no dedicated masters
Amazon ES cluster
1
3
3
1
Instance 1,
Master
2
1
1
2
Instance 2
3
2
2
3
Instance 3

Cluster with dedicated masters
Amazon ES cluster
1
3
3
1
Instance 1
2
1
1
2
Instance 2
3
2
2
3
Instance 3Dedicated master nodes
Data nodes: queries and updates

Cluster with zone awareness
Amazon ES cluster
1
3
Instance 1
2
1 2
Instance 2
3
2
1
Instance 3
Availability Zone 1 Availability Zone 2
2
1
Instance 4
3
3

Best practices
Data nodes = Storage needed/Storage per node
Use GP2 EBS volumes
Use 3 dedicated master nodes for production deployments
Enable zone awareness
Set indices.fielddata.cache.size = 40

Amazon Elasticsearch Service
overview
Amazon Route
53
Elastic Load
BalancingAWS IAM
Amazon
CloudWatch
Elasticsearch API
AWS CloudTrail

Amazon Elasticsearch Service benefits
Easy to use
Open-source
compatible
Secure
Highly available
AWS integrated
Scalable

Kinesis Firehose
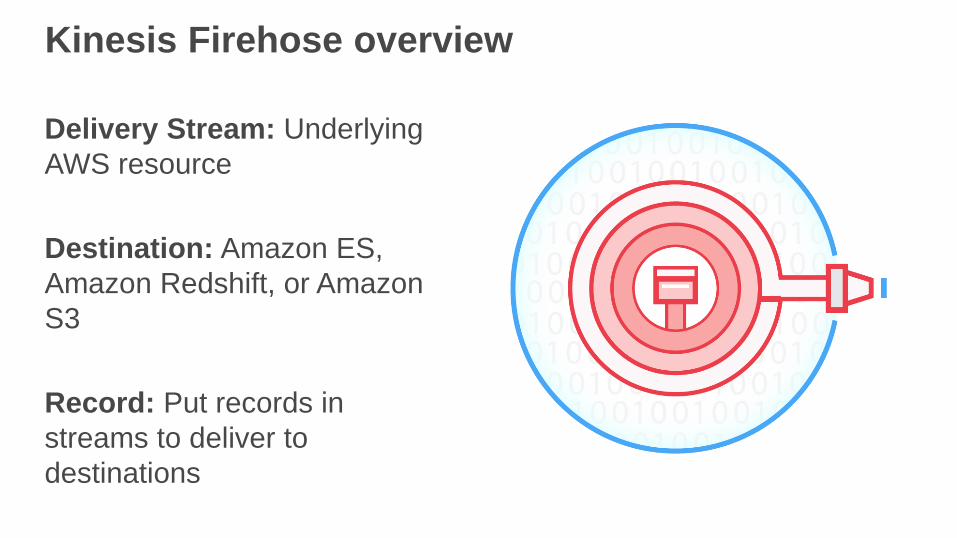
Kinesis Firehose overview
Delivery Stream: Underlying
AWS resource
Destination: Amazon ES,
Amazon Redshift, or Amazon
S3
Record: Put records in
streams to deliver to
destinations

Firehose delivery architecture today
intermediate
Amazon S3 bucket
backup S3 bucket
source records
data source
source records
Amazon Elasticsearch
Service
Firehose
delivery stream
delivery failure

Coming soon! Firehose delivery architecture
with transformations
intermediate
Amazon S3
bucket
backup S3 bucket
source records
data source
source records
Amazon Elasticsearch
Service
Firehose
delivery streamtransformed
records transformed
records
transformation failure
delivery failure
Kinesis Firehose features for ingest
Serverless scale Error handling S3 Backup

Demo: create a Kinesis
Firehose stream

Best practices
Use smaller buffer sizes to increase throughput, but be
careful of concurrency
Use index rotation based on sizing
Default: stream limits: 2,000 transactions/second, 5,000
records/second, and 5 MB/second

Upload template and data

Number of shards = index size/30GB
Define the number of shards
when you create the index
Less is more
Writes occupy 1 shard, reads
occupy all shards
Amazon ES cluster
1
3
3
1
Instance 1,
Master
2
1
1
2
Instance 2
3
2
2
3
Instance 3
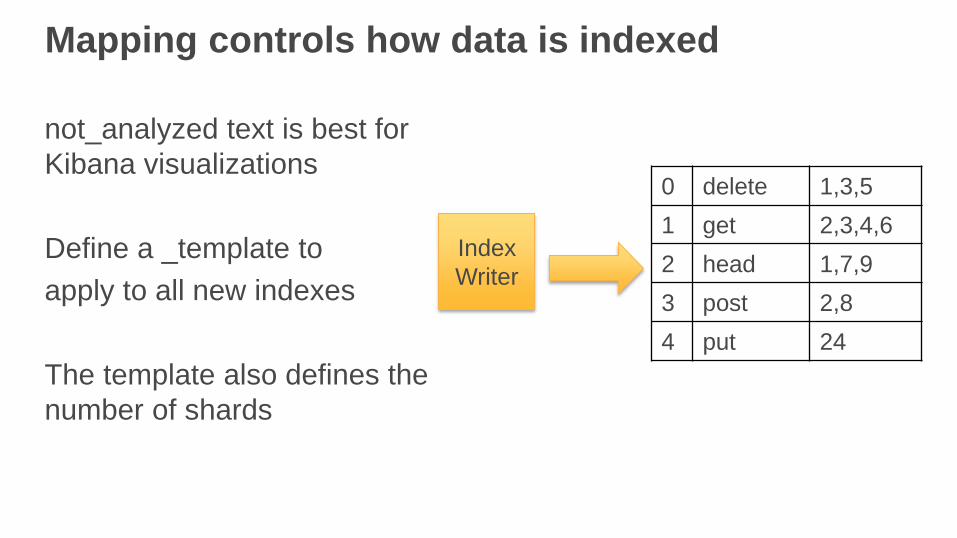
Mapping controls how data is indexed
not_analyzed text is best for
Kibana visualizations
Define a _template to
apply to all new indexes
The template also defines the
number of shards
0 delete 1,3,5
1 get 2,3,4,6
2 head 1,7,9
3 post 2,8
4 put 24
Index
Writer

Transform log lines to search documents
d104.aa.net - - [01/Jul/1995:00:00:15 -0400] "GET /images/KSC-logosmall.gif HTTP/1.0" 200 1204
{"status": 200, "ident": "-", "@timestamp": "1995-07-01T00:00:05", "request": "/images/KSC-logosmall.gif HTTP/1.0", "auth": "-", "host": "d104.aa.net", "verb": "GET", "time": "01/Jul/1995:00:00:15 -0400", "size": 1204}

Send_data method

Demo: upload template, send
logs to Firehose

Best practices
• Use a template for settings
• Set number of shards based on 30 GB per shard
• Best case, 1 active shard per node
• For analysis use cases, set not_analyzed on all fields

Analyze Apache web logs

Amazon ES aggregations
Buckets – a collection of documents meeting some criterion
Metrics – calculations on the content of buckets
Bucket: time
Metr
ic: count

Best practices
Make sure that your fields are not_analyzed
Visualizations are based on buckets/metrics
Use a histogram on the x-axis first, then sub-aggregate

Run Elasticsearch in the AWS Cloud with Amazon
Elasticsearch Service
Use Kinesis Firehose to ingest data simply
Kibana for monitoring, Elasticsearch queries for
deeper analysisAmazon
Elasticsearch
Service

What to do next
Qwiklab:
https://qwiklabs.com/searches/lab?keywords=introduction
%20to%20amazon%20elasticsearch%20service
Centralized logging solution
https://aws.amazon.com/answers/logging/centralized-
logging/
Our overview page on AWS
https://aws.amazon.com/elasticsearch-service/

Thank you!

Remember to complete
your evaluations!