aws re:invent 2016: building hpc clusters as code in the (almost) infinite cloud (cmp318)
TRANSCRIPT

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Nathan McGuirt, Manager, Solutions Architecture, AWS
Gabriele Garzoglio, HEP Cloud Facility Project Manager, Fermilab
December 2016
Building HPC Clusters as Code
in the (Almost) Infinite Cloud
CMP318

What to Expect from the Session
• Why customers are using AWS for HPC/HTC
• Leveraging Spot Instances for big compute at low cost
• Accelerating deployment with automation and managed
services

Agenda
• Why AWS for HPC?
• Automating cluster deployment
• Fermi National Accelerator Laboratory
• Demo of scaling jobs on a budget
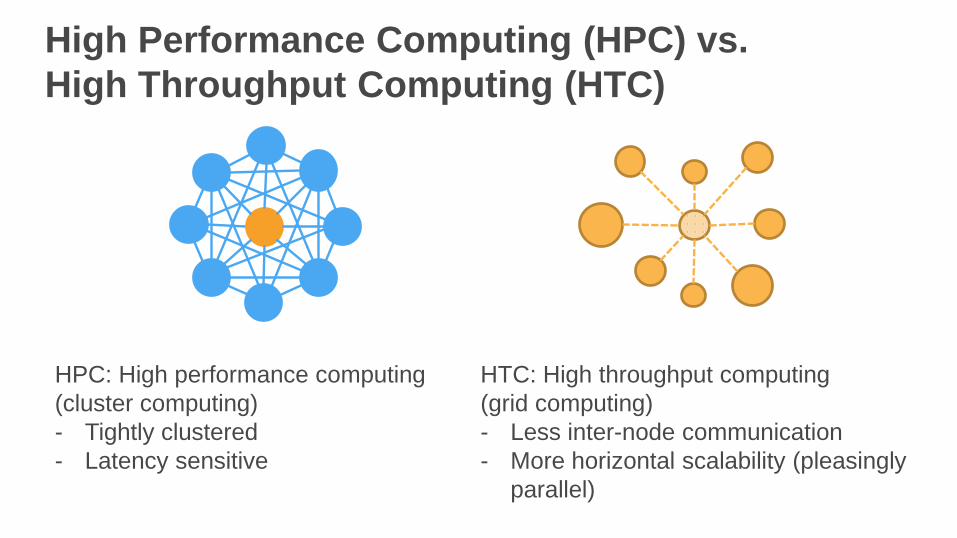
High Performance Computing (HPC) vs.
High Throughput Computing (HTC)
HPC: High performance computing
(cluster computing)
- Tightly clustered
- Latency sensitive
HTC: High throughput computing
(grid computing)
- Less inter-node communication
- More horizontal scalability (pleasingly
parallel)

Why AWS for HPC?

Time to research
%

Time to research

Innovation and performance

Scalability and flexibility

Data
AWS Snowball AWS Direct Connect

Cost

Cost – Spot market
Request
1
2
3
4
5
6
7
8
9
Bid Price
$1.00
$0.55
$0.50
$0.33
$0.20
$0.18
$0.15
$0.10
$0.05
Spot Price
$0.20
$0.20
$0.20
$0.20
$0.20

Spot Bid Advisor

Spot Fleet
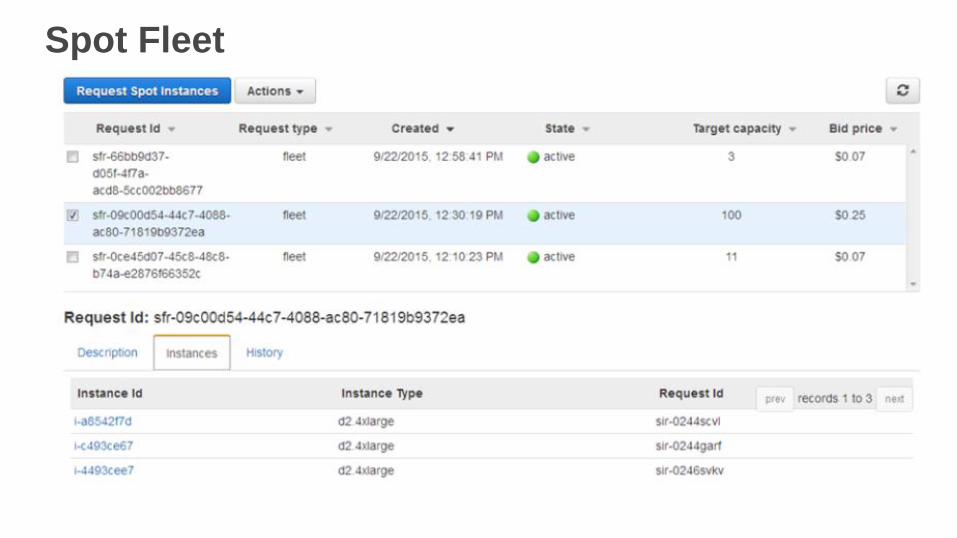
Spot Fleet

Clusters as code

Automation
• Fully custom
• APIs
• AWS CloudFormation
• Managed services
• Amazon EMR
• AWS Batch
• Software cluster management solutions
• CFNCluster
• Alces Flight
• Partner offerings

API - SDKs
Java Python PHP .NET Ruby nodeJS
iOS Android AWS Toolkit
for Visual
Studio
AWS Toolkit
for Eclipse
Tools for
Windows
PowerShell
CLI

CloudFormation
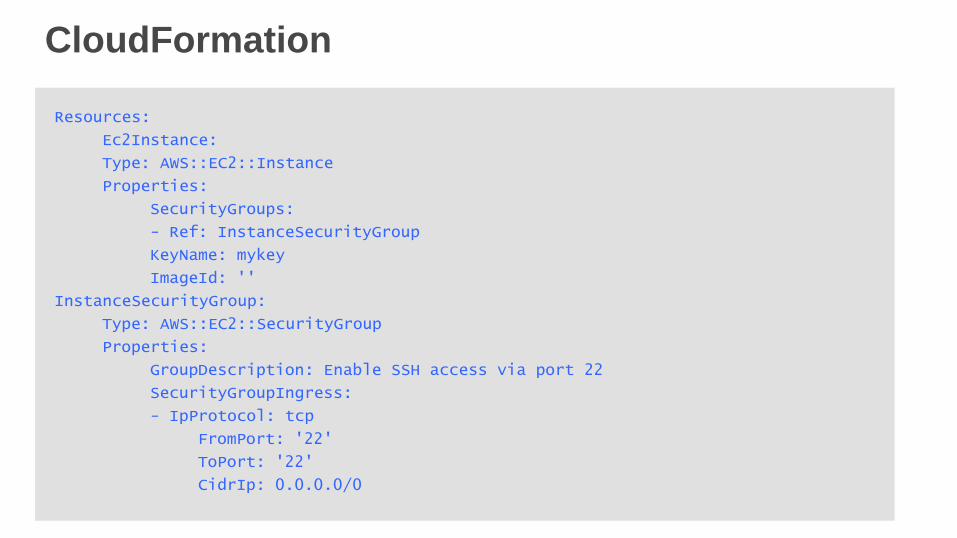
CloudFormation
Resources:
Ec2Instance:
Type: AWS::EC2::Instance
Properties:
SecurityGroups:
- Ref: InstanceSecurityGroup
KeyName: mykey
ImageId: ''
InstanceSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Enable SSH access via port 22
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: '22'
ToPort: '22'
CidrIp: 0.0.0.0/0

EMR
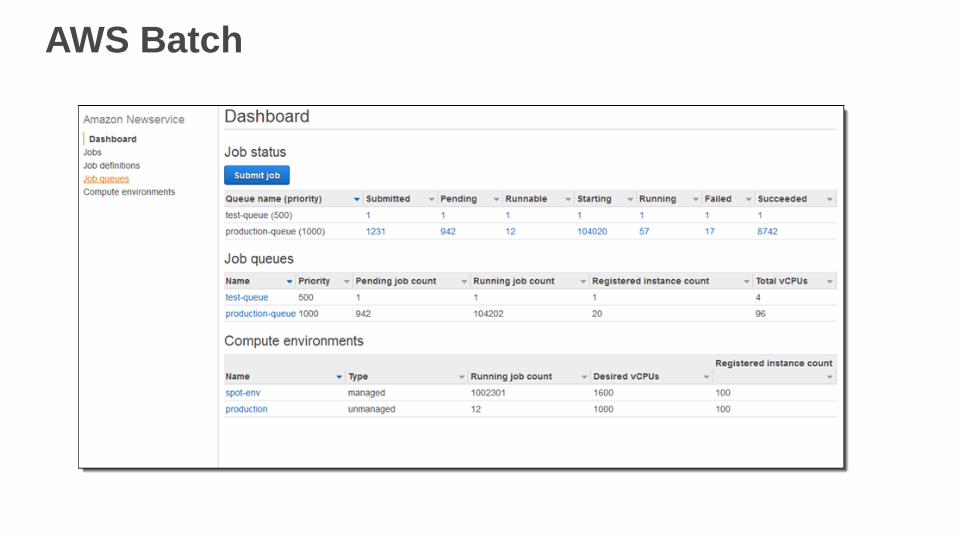
AWS Batch

AWS CFNCluster
$ pip install cfncluster
...
$ cfncluster configure
...
$ cfncluster run mycluster

Alces FlightAlces Flight is a software offering self-service
supercomputers via the AWS Marketplace.
Creates self-scaling clusters with more than
750 popular scientific applications pre-installed,
complete with libraries and various compiler
optimizations, ready to run. The clusters use
the AWS Spot Instances by default.

AWS Partners in the HPC Space

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Gabriele Garzoglio, HEP Cloud Facility Co-Project Manager, Fermilab
December 2016
The HEP Cloud FacilityElastic Computing for High Energy Physics

Computing at the Fermi National Accelerator Laboratory
Lead United States particle physics laboratory• Funded by the Department of Energy
• ~100 PB of data on tape
• High Throughput Computing characterized by:• “Pleasingly parallel” tasks
• High CPU instruction / Bytes IO ratio
• But still lots of I/O. See Pfister: “In Search of Clusters”
Focus on Neutrino Physics• Including the NOvA Experiment
Strong collaborations with international laboratories
• CERN / Large Hardron Collider (LHC) Experiments
• Brookhaven National Laboratory (BNL)
• Lead institution (“Tier-1”) for the Compact Muon Solenoid (CMS)
2
7
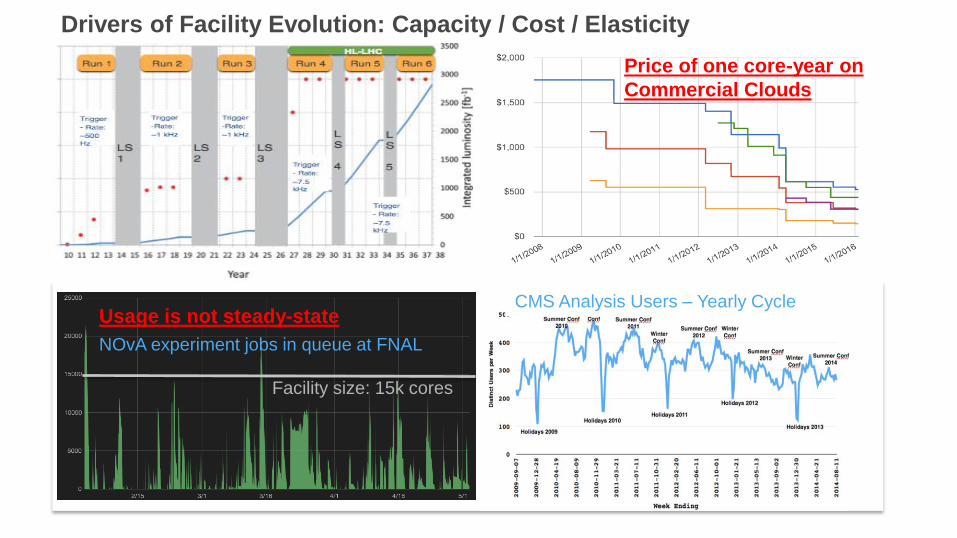
Drivers of Facility Evolution: Capacity / Cost / Elasticity
Price of one core-year on
Commercial CloudsHEP needs: 10-100 x today capacity
Facility size: 15k cores
NOvA experiment jobs in queue at FNAL
Usage is not steady-stateCMS Analysis Users – Yearly Cycle

Vision for Facility Evolution• Strategic Plan for U.S. Particle Physics (P5 Report to the U.S. funding agencies)
Fermilab Facility
HTC, HPC Cores
68.7KDisk Systems
37.6 PB
Tape
101 PB10/100 Gbit
Networking
~5k internal
network ports
The Facility Today is “Fixed”
Rapidly evolving computer architectures
and increasing data volumes require
effective crosscutting solutions that are
being developed in other science
disciplines and in industry.
• HEP Cloud Vision Statement– HEPCloud is envisioned as a portal to an ecosystem of diverse computing resources commercial or
academic
– Provides “complete solutions” to users, with agreed upon levels of service
– The Facility routes to local or remote resources based on workflow requirements, cost, and efficiency of accessing various resources
– Manages allocations of users to target compute engines
• Pilot project to explore feasibility, capability of HEPCloud– Goal of moving into production during FY18
– Seed money provided by industry

HEP Cloud ArchitectureOverview External Relationships

HEP Cloud ArchitectureOverview External Relationships
Basic idea: Add
disparate resources
(Cloud VM, HPC slots,
Grid nodes, local
resources) into a
central resource pool.

Fermilab HEPCloud: Expanding to the Cloud
Reference herein to any specific commercial product, process, or service by trade name, trademark,
manufacturer, or otherwise, does not necessarily constitute or imply its endorsement, recommendation, or
favoring by the United States Government or any agency thereof.
– Provisioning
– Performance
– Image portability
– On-demand services
• Where to start?
– Market leader:
Amazon Web Services (AWS)
• Integration challenges that needs to
be managed to run at scale:
– Networking
– Storage and data movement
– Monitoring and accounting
– Security

Integration Challenges: Provisioning – Create an Overlay Batch System with
GlideinWMS and HTCondor
condor
submit
VO Frontend
HTCondor
Central Manager
HTCondor
SchedulersHTCondor
Schedulers
Frontend
Grid Site
Virtual Machine
Job
Local Resources
Virtual Machine
Job
GlideinWMS Factory
HTCondor-G
High Performance
Computers
Virtual Machine
Job
Cloud Provider
Virtual MachineVM
Glidein
HTCondor
StartdJob
Pull Job

Integration Challenges: Provisioning – Containing costs
• Using AWS Spot market to
contain costs
• Workflows are already engineered
to sustain preemption from the
Grid
– Job are “short”, i.e., killed jobs are
affordable w/o checkpointing
– Preempted jobs are automatically
resubmitted
– Data management systems
identify files in a dataset that were
not processed and allow recovery
CMS use case:
Histogram of number
of times each job
started
(measure of
preemption)
NOvA use case:
number of VMs
running (blue) and
preempted (red)
every hour
2.5M jobs
with no
preemption
240 VM / h
60 VM preempted
in 1h
400K jobs
with one
preemption

Integration Challenges: Provisioning – Containing costs
• The Decision Engine oversees
the costs and optimizing VM
placement using the status of the
facility, the historical prices, and
the job characteristics
Bid at 25% x on-demand price has lowest expected cost • Based on pre-emption history,
calculating the probability that a 5-
24 h job finishes within a week
although it has to restart due to
preemption, for various bidding
algorithms.
$0.25 / h

Integration Challenges: Performance
Benchmarks used to compare workflow duration on AWS (and $$) with local execution
Need EBS
Need EBS
32 cores
scale w/ cores Need EBS
Need EBS
32 cores
scale w/ cores
Need
parallel
streams
c3.2xlarge c3.2xlargegood candidate – want > 1
From AWS to
FNAL: 7GbpsAccess to S3 always
saturates the 1 Gbps
interface
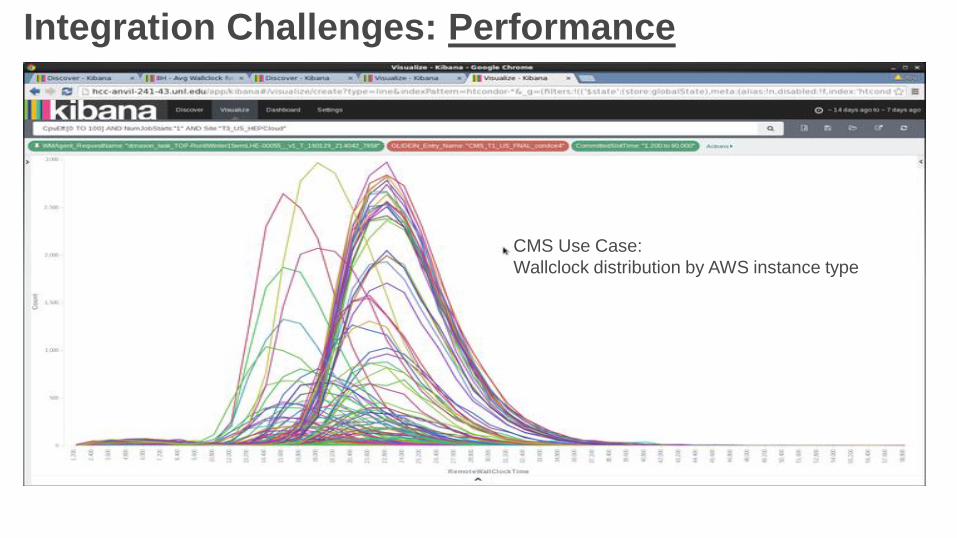
Integration Challenges: Performance
CMS Use Case:
Wallclock distribution by AWS instance type

Integration Challenges: Image Portability
Build VM management tool,
considering:
• HVM virtualization (HW VM
+ Xen) on AWS: gives
access to all AWS
resources
• Contain VM size (saves
import time and cost)
• Import process covers
multiple AWS accounts and
regions
• AuthN with AWS use short-
lived role-based tokens,
rather than long term keys
Build “Golden Image” from standard Fermilab Worker Node configuration VM.

Integration Challenges: On-demand Services
Jobs depend on software services to run
Automating the deployment of these services on AWS on-demand - enables scalability and cost savings
• Services include data caching (e.g., Squid) WMS , submission service, data transfer, etc.
• As services are made deployable on-demand, instantiate ensemble of services together (e.g., through AWS CloudFormation)
Example: on-demand Squid
• Deploy Squid via auto-scaling services. Squid is deployed if average group bandwidth utilization is too high. Server is deployed or destroyed in 30 seconds.
• Front Squids with aload balancer.
• Name the load balancer for that region via Route 53
Auto Scaling
group
CloudFormation

"SquidInstanceType" : { "Type" : "String", "Default" : "c3.xlarge", … },
"SquidLaunchConfiguration" : { "Type" : "AWS::AutoScaling::LaunchConfiguration",
"Properties" : {
"InstanceType" : { "Ref" : "SquidInstanceType" },
"ImageId" : { "Fn::FindInMap" : [ "AMIRegionMap", {"Ref":"AWS::Region"}, "SquidAMI" ]},
"SecurityGroups" : [ { "Fn::FindInMap" :
["SecurityGroupRegionMap",{"Ref":"AWS::Region"}, "SquidSG" ] } ],
… } }
"SquidAutoscalingGroup" : { "Type" : "AWS::AutoScaling::AutoScalingGroup",
"Properties" : {
"AvailabilityZones" : {"Ref" : "AvailabilityZones"},
"LaunchConfigurationName" : {"Ref" : "SquidLaunchConfiguration" },
"LoadBalancerNames" : [ {"Ref" : "SquidLoadBalancer" } ],
… } },
"SquidAutoscaleUpPolicy" : { "Type" : "AWS::AutoScaling::ScalingPolicy",
"Properties" : {
"AdjustmentType" : "ChangeInCapacity",
"AutoScalingGroupName" : { "Ref" : "SquidAutoscalingGroup" },
"ScalingAdjustment" : "1”
… } },
…
Integration Challenges: On-demand Services – CloudFormation

"SquidNetworkBandwidthHighAlarm" : { "Type" : "AWS::CloudWatch::Alarm",
"Properties" : {
"AlarmDescription" : "Scale up if average NetworkIn > for 5 minutes",
"MetricName" : "NetworkOut",
"Statistic" : "Average",
"Period" : "300",
"Threshold" : "1100000000",
"AlarmActions" : [ { "Ref" : "SquidAutoscaleUpPolicy" } ],
"ComparisonOperator" : "GreaterThanThreshold”,
… } }
…
"SecurityGroupRegionMap" : {
"us-west-2“ : { "SquidSG" : "sg-xxxxf6cb" },
"us-east-1" : { "SquidSG" : "sg-xxxx70ca" },
… }
"SquidLoadBalancer" : {"Type" : "AWS::ElasticLoadBalancing::LoadBalancer",
"Properties" : {
"CrossZone" : "false",
"SecurityGroups" : [ {"Fn::FindInMap" :
[ "SecurityGroupRegionMap", { "Ref" : "AWS::Region" } , "SquidSG" ] } ],
"Listeners" : [ { "LoadBalancerPort":"3128", "InstancePort":"3128", "Protocol":"TCP" } ],
"HealthCheck" : { "Target" : "TCP:3128", "HealthyThreshold" : "3", … }
… } }
Integration Challenges: On-demand Services – CloudFormation

"elbHostedZone": { "Type" : "AWS::Route53::HostedZone",
"Properties" : {
"HostedZoneConfig" : {
"Comment" : "auto-generated private hosting zone for ELB” },
"Name" : { "Fn::Join" : ["", [{"Ref":"AvailabilityZone"},".elb.fnaldata.org.”]]},
"VPCs" : [{
"VPCId" : { … },
"VPCRegion" : { "Ref" : "AWS::Region"} }]
} }
"elbDNS" : { "Type" : "AWS::Route53::RecordSet",
"Properties" : {
"HostedZoneId" : { "Ref" : "elbHostedZone" },
"Name" : { "Fn::Join" :
["", ["elb2.",{"Ref":"AvailabilityZone"},".elb.fnaldata.org."]]},
"ResourceRecords" : [ { "Fn::GetAtt" : [ "SquidLoadBalancer", "DNSName" ] } ]
… } }
Clients call Squid as elb2.<AvailabilityZone>.elb.fnaldata.org
Integration Challenges: On-demand Services – CloudFormation

Integration Challenges: Networking
Implement routing / firewall configuration
to use peered ESNet / AWS to route
data flow through ESNet
AWS / ESNet data egress cost waiver
• For data transferred through
ESNet, transfer charges are
waived for data costs up to 15%
of the total
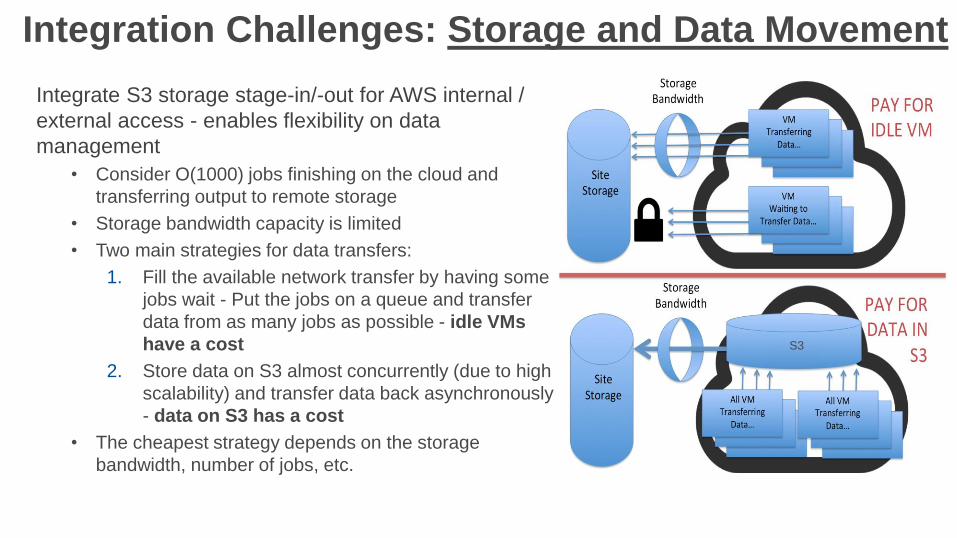
Integration Challenges: Storage and Data Movement
Integrate S3 storage stage-in/-out for AWS internal /
external access - enables flexibility on data
management
• Consider O(1000) jobs finishing on the cloud and
transferring output to remote storage
• Storage bandwidth capacity is limited
• Two main strategies for data transfers:
1. Fill the available network transfer by having some
jobs wait - Put the jobs on a queue and transfer
data from as many jobs as possible - idle VMs
have a cost
2. Store data on S3 almost concurrently (due to high
scalability) and transfer data back asynchronously
- data on S3 has a cost
• The cheapest strategy depends on the storage
bandwidth, number of jobs, etc.
S3

Integration Challenges: Monitoring and Accounting
Monitor # GCloud VMs (S. Korea Priv. Cloud) Monitor # AWS VMs
Accounting:
$ by VO and VM Type
Monitor
HEP Cloud
Slots

NoVA Data ProcessingProcessing the 2014/2015 dataset
3 use cases: Particle ID, Montecarlo ,
Data Reconstruction
Received AWS research grant
Dark Energy Survey
Gravitational WavesSearch for optical
counterpart of events
detected by LIGO/VIRGO
gravitational wave detectors (FNAL LDRD)
Modest CPU needs, but want 5-10 hour turnaround
Burst activity driven entirely by physical phenomena
(gravitational wave events are transient)
Rapid provisioning to peak
CMS Monte Carlo SimulationGeneration (and detector simulation, digitization,
reconstruction) of simulated events in time for
Moriond conference.
58,000 compute cores, steady-state
Demonstrates scalability
Received AWS research grant
Initial HEPCloud Use Cases

Results from the CMS Use Case
• All CMS simulation requests fulfilled by the conference
deadline (Rencontres de Moriond 2016 )
– 2.9 million jobs, 15.1 million wall hours
• 9.5% badput – includes preemption from spot pricing
• 87% CPU efficiency
– 518 million events generated

CMS Reaching ~60k slots on AWS with HEPCloud
10% Test 25%
60000 slots
10000 VM
Each color corresponds to a
different region / zone /machine type

HEPCloud AWS: 25% of CMS global capacity
Production
Analysis
Reprocessing
Production on AWS
via FNAL HEPCloud
Production
Analysis
Reprocessing
Production on AWS
via FNAL HEPCloud

On-premises vs. cloud cost comparison
Average cost per core-hour• On-premises resource: 0.9 cents per
core-hour• Includes power, cooling, staff,
but assumes 100% utilization
• Off-premises at AWS (CMS use case): 1.4 cents per core-hour
• Off-premises at AWS (NOvA use case): 3.0 cents per core-hour• Use case demanded bigger VM
Benchmarks• Specialized (“ttbar”) benchmark focused on HEP workflows
• On-premises: 0.0163 ttbar /s (higher = better)
• Off-premises: 0.0158 ttbar /s
Raw compute performance roughly equivalent
Cloud costs approaching equivalence
Amazon provisions/retires 60k cores for our system in ~1 hour

Acknowledgements
The support from the Computing Sector
The Fermilab HEPCloud Facility team
AWS and their engagement team, in particular Jamie Baker
The HTCondor team
The collaboration and contributions from KISTI, in particular Dr. Seo-Young Noh
The Illinois Institute of Technology (IIT) students and professors Ioan Raicu and
Shangping Ren
The Italian National Institute of Nuclear Physics (INFN) summer student program
• NOvA: http://cd-docdb.fnal.gov/cgi-bin/ShowDocument?docid=5774
• CMS: http://cd-docdb.fnal.gov/cgi-bin/ShowDocument?docid=5750
For More Information:

demonstration


Thank you!

Remember to complete
your evaluations!

Related Sessions
CMP201 - Auto Scaling – The Fleet Management Solution for Planet Earth