automatic text classification through machine learning david w. miller semantic web spring 2002...
Post on 21-Dec-2015
222 views
TRANSCRIPT

Automatic Text Classification through
Machine Learning
David W. Miller
Semantic Web
Spring 2002
Department of Computer Science
University of Georgia
www.cs.uga.edu/~miller/SemWeb
2
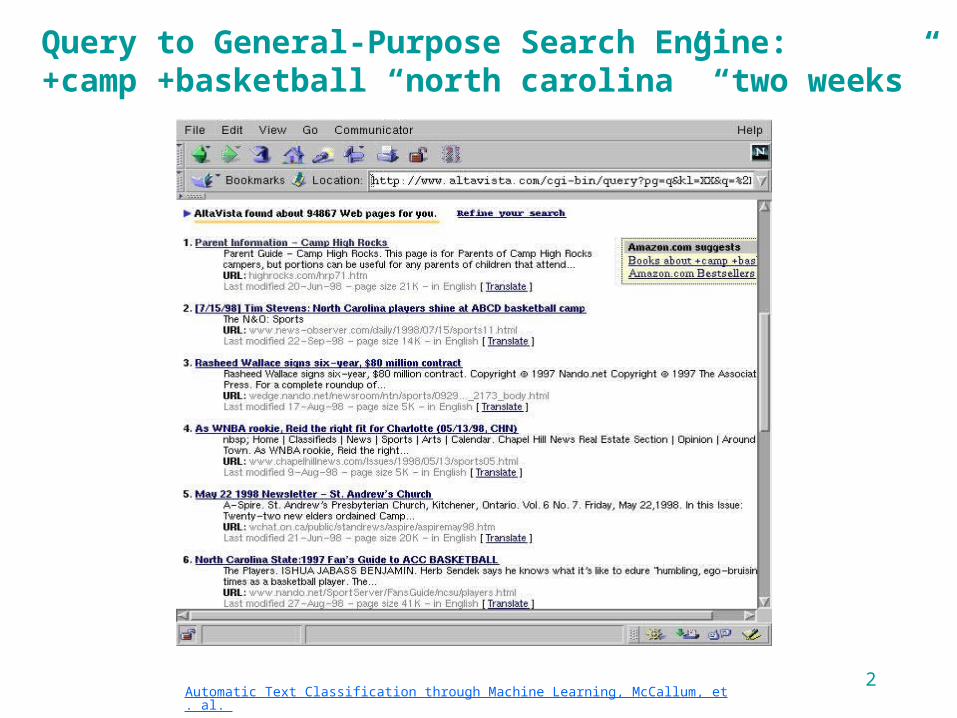
Query to General-Purpose Search Engine: +camp +basketball “north carolina” “two weeks”
Automatic Text Classification through Machine Learning, McCallum, et. al.

3
Domain-Specific Search Engine
Automatic Text Classification through Machine Learning, McCallum, et. al.

4Automatic Text Classification through Machine Learning, McCallum, et. al.

5Automatic Text Classification through Machine Learning, McCallum, et. al.

6
Domain-Specific Search EngineAdvantages
• High precision.
• Powerful searches on domain-specific features.– by location, time, price, institution.
• Domain-specific presentation interfaces:– Topic hierarchies.– Specific fields shown in clear format.– Links for special relationships.
Automatic Text Classification through Machine Learning, McCallum, et. al.

7
Domain-Specific Search EngineDisadvantages
• Much human effort to build and maintain!
– e.g. Yahoo has hired many people to build their hierarchy, and maintain “Full Coverage”, etc.
Automatic Text Classification through Machine Learning, McCallum, et. al.

8
Tough Tasks• Find pages that belong in the search engine.
• Find specific fields (price, location, etc).
• Organize the content for browsing.
Automatic Text Classification through Machine Learning, McCallum, et. al.

9
Machine Learning to the Rescue!• Find pages that belong in the search engine.
– Efficient spidering by reinforcement learning.
• Find specific fields (price, location, etc).– Information extraction with hidden Markov
models.
• Organize the content for browsing.– Populate a topic hierarchy by document
classification.
Automatic Text Classification through Machine Learning, McCallum, et. al.

10
Building Text Classifiers
• Manual approach– Interactive query refinement– Expert system methodologies
• Supervised learning 1. “Expert” labels example texts with
classes 2. Machine learning algorithm produces
rule that tends to agree with expert classifications
Machine Learning for Text Classification, David D. Lewis, AT&T Labs

11
Advantages of Using Machine Learning to Build Classifiers
• Requires no linguistic or computer skills• Competitive with manual rule-writing• Forces good practices
– Looking at data– Estimating accuracy
• Can be combined with manual engineering– ML research pays too little attention to this
Machine Learning for Text Classification, David D. Lewis, AT&T Labs

12
Main Processes for aMachine-Learning System
Prepare training samples
Feature selection
Text representation
Selected features
Model induction Feature vectors
Selected features
Profiles/Rules
Supervised Machine-Learning Based Text Categorization, Ng Hong I

13
Preparation of Training Texts
• Essential for a supervised machine learning text categorization system
• Decide on the set of categories• A set of positive training texts is
prepared for each of the categories• Assign subject code(s) to each of the
training texts– More than one subject code may be
assigned to one training text
Supervised Machine-Learning Based Text Categorization, Ng Hong I

14
Demonstration System: Cora• Find pages that belong in the search engine.
– Spider CS departments for research papers.
• Find specific fields (price, location, etc).– Extract titles, authors, abstracts, institutions, etc
from paper headers and references.
• Organize the content for browsing.– Populate a hand-built topic hierarchy by using text
classification.
Automatic Text Classification through Machine Learning, McCallum, et. al.

15Automatic Text Classification through Machine Learning, McCallum, et. al.

16Automatic Text Classification through Machine Learning, McCallum, et. al.

17
See also CiteSeer[Bollacker, Lawrence& Giles ‘98]
Automatic Text Classification through Machine Learning, McCallum, et. al.

18Automatic Text Classification through Machine Learning, McCallum, et. al.

19
Automatic Text Classification via Statistical Methods
Text Categorization is the problem of assigning predefined categories to free text documents.
Popular Approach is Statistical Learning Methods
•Bayes Method
•Rocchio Method (most popular)
•Decision Trees
•K-Nearest Neighbor Classification
•Support Vector Machines (fairly new concept)

20
A Probabilistic Generative Model
• Define a probabilistic generative model for documents with classes.
Bayes:Reinforcement
Learning:a Survey
This paper surveysthe field of rein-
forcement learningfrom a computer
science perspective.
35 a1 block12 computer4 field1 leg7 machine44 of3 paper2 perspective1 rate5 reinforcement9 science2 survey56 the11 this1 underrated… …
“Bag-of-words”
Automatic Text Classification through Machine Learning, McCallum, et. al.

21
Bayes Method
)|Pr(maxarg dcc jc j
Pick the most probable class, given the evidence:
jc
d- a class (like “Planning”)
- a document (like “language intelligence proof...”)
)Pr(
)|Pr()Pr()|Pr(
d
cdcdc jj
j
Bayes Rule:
Probability Category cj should be assigned to document d
Automatic Text Classification through Machine Learning, McCallum, et. al.

22
Bayes Rule
)Pr(
)|Pr()Pr()|Pr(
d
cdcdc jj
j
)|( dcP j - Probability that document d belongs to category cj
)(dP - Probability that a randomly picked document has the same attributes
)( jcP - Probability that a randomly picked document belongs to this category
)|( cdP j- Probability that category c contains document d

23
Bayes Method
• Generates conditional probabilities of particular words occurring in a document given it belongs to a particular category.
• Larger vocabulary generate better probabilities
• Each category is given a threshold p for which it judges the worthiness of a document to fall in that classification.
• Documents may fall into one, more than one, or not even one category.

24
Rocchio Method
• Each document is D is represented as a vector within a given vector space V:
),...,( |)(|)1( Fddd
•Documents with similar content have similar vectors
•Each dimension of the vector space represents a word selected via a feature selection process

25
Rocchio Method
• Values of d(i) for a document d are calculated as a combination of the statistics TF(w,d) and DF(w)
• TF(w,d) (Term Frequency) is the number of times word w occurs in a document d.
• DF(w) (Document Frequency) is the number of documents in which the word w occurs at least once.

26
Rocchio Method• The inverse document frequency is calculated as
• Value of d(i) of feature wi for a document d is calculated as the product
)(),()(ii
i wIDFdwTFd
)log()( )(||wDF
DwIDF
•d(i) is called the weight of the word wi in the document d.

27
Rocchio Method
• Based on word weight heuristics, the word wi is an important indexing term for a document d if it occurs frequently in that document
• However, words that occurs frequently in many document spanning many categories are rated less importantly

28
Decision Tree Learning Algorithm
• Probabilistic methods have been criticized since they are not easily interpreted by humans, not so with Decision Trees
• Decision Trees fall into the category of symbolic (non-numeric) algorithms

29
Decision Trees
• Internal nodes are labeled by terms
• Branches (departing from a node) are labeled by tests on the weight that the term has in a test document
• Leafs are labeled by categories

30
Decision Tree Example

31
Decision Tree
• Classifier categorizes a test document d by recursively testing for the weights that the terms labeling the internal nodes have until a leaf node is reached.
• The label of the leaf node is then assigned to the document
• Most decision trees are binary trees

32
Decision Tree
• Fully grown trees tend to have decision rules that are overly specific and are therefore unable to categorize documents– Therefore, pruning and growing methods
for such Decision Trees are normally standard part of the classification packages

33
K-Nearest Neighbor• Features
– All instances correspond to points in an n-dimensional Euclidean space
– Classification is delayed till a new instance arrives
– Classification done by comparing feature vectors of the different points
– Target function may be discrete or real-valued
K-Nearest Neighbor Learning, Dipanjan Chakraborty

34
1-Nearest Neighbor
K-Nearest Neighbor Learning, Dipanjan Chakraborty

35
K-Nearest Neighbor• An arbitrary instance is represented by
(a1(x), a2(x), a3(x),.., an(x))– ai(x) denotes features
• Euclidean distance between two instances
d(xi, xj)=sqrt (sum for r=1 to n (ar(xi) - ar(xj))2)• Find the k-nearest neighbors whose distance
from your test cases falls within a threshold p.• If x of those k-nearest neighbors are in
category ci, then assign the test case to ci, else it is unmatched.
K-Nearest Neighbor Learning, Dipanjan Chakraborty

36
Support Vector Machines
• Based on the Structural Risk Minimization principle form computational learning theory– Find a hypothesis h for which we can
guarantee the lowest true error• The true error of h is the probability that h will
make an error on an unseen and randomly selected test example

37
Evaluating Learning Algorithms and Software
• How effective/accurate is classification?
• Compatibility with operational environment
• Resource usage
• Persistence
• Areas learning algorithms need improvement
Machine Learning for Text Classification, David D. Lewis, AT&T Labs

38
Effectiveness: Contingency Table
Truth
Yes No
Yes a bSystem
No c d
Machine Learning for Text Classification, David D. Lewis, AT&T Labs

39
• recall = a/(a+c)
• precision = a/(a+b)
• accuracy = (a+c)/(a+b+c+d)
• utility = any weighted average of a,b,c,d
• F-measure = 2a/(2a+b+c)
• others
Truth
Yes No
Yes a bSystem
No c d
Effectiveness Measures
Machine Learning for Text Classification, David D. Lewis, AT&T Labs

40
Effectiveness: How to Predict
• Theoretical gaurantees rarely useful
• Test system on manually classified data– Representativeness of sample important– Will data vary over time?– Effectiveness varies widely across classes
and data sets
• Interindexer agreement an upper bound?
Machine Learning for Text Classification, David D. Lewis, AT&T Labs

41
Effectiveness: How to Improve
• More training data
• Better training data
• Better text representation – Usual IR tricks (term weighting, etc.)– Manually construct good predictor features
• e.g. % capitalized letters for spam filtering
• Hand off hard cases to human being
Machine Learning for Text Classification, David D. Lewis, AT&T Labs

42
Conclusions
• Performance of classifier depends strongly on the choice of data used for evaluation.
• Dense category space become problematic for unique categorization, many documents share characteristics

43
Credits*This Presentation is Partially Based
on Those of Others Listed Below*
• Supervised Machine Learning Based Text Categorization
• Machine Learning for Text Classification • Automatically Building Internet Portals using Machine
Learning
• Web Search • Machine Learning
• K-Nearest Neighbor Learning Full Presentations can be found at: http://webster.cs.uga.edu/~miller/SemWeb/Presentation/ACT.html

44
Resources• Text Categorization Using Weight Adjusted k-Nearest
Neighbor Classification • A Probalisitic Analysis of the Rocchio Alg. w/ TFIDF
for Text Categorization • Text Categorization w/ Support Vector Machines • Learning to Extract Symbolic Knowledge from the
WWW • An Evaluation of Statistical Approaches to Text
Categorization • A Comparison of Two Learning Algorithms for Text
Categorization • Machine Learning in Automated Text Categorization
Full List of Resources can be found at: http://webster.cs.uga.edu/~miller/SemWeb/Presentation/ACT.html