automatic speaker recognition - kit features used in speaker recognition systems are cepstral...
TRANSCRIPT

Automatic Speaker Recognition
Qian Yang
04. June, 2013

Outline
Overview
Traditional Approaches
Speaker Diarization


State-of-the-art speaker recognition systems use:
GMM-based framework
SVM-based framework





Outline
Overview
Traditional Approaches
Features and Models
Evaluation and Performance
Speaker Diarization





Primary features used in speaker recognition systems are cepstral features (eg. MFCC, PLP)
Voice activity detection (VAD) to remove non-speech frames
Some form of blind decovolution is used to remove stationary channel effects (CMS)
Feature warping is to compensate channel variability
Time differential cepstral (delta cepstra, or delta detla features) are usually appended to cepstral features
Typically 24-40 dimensional features are used
Traditional Approaches
Features for Speaker Recognition


Support Vector Machines
Latest discriminative approach for speaker verification






Traditonal Approaches Support Vector Machines
A SVM is a supervised method
• A SVM is a binary discriminative classifier ( target speaker vs.
impostors)
• transform data to a higher dimensional space using kernel functions
• Construct a hyperplane in higher dimensional space to maximize the margin between support vectors
• The data points lying on the boundaries are support vectors
• Design different kernels for speaker recognition task kernel
Ideal output (0/1)
Support vectors
When classification, a class decision is based upon whether the value, f(x), is above or below a threshold

• How to represent speaker utterances in higher dimensional space ??
• Example: A linear kernel for speaker verification task
– Train GMMs on two utterances using MAP
– Derive a distance metric between two utterances using a modified KL divergence
– Define a linear kernel based on the distance above
Traditonal Approaches Support Vector Machines







Outline
Overview
Traditional Approaches
Speaker Diarization
Overview
Cross-show speaker diarization
Speaker Tracking

Unlike speaker verification/identifcation, no enrollment data for training and
no prior knowledge about number of speakers !!!




Speaker Diarization Generic Architecture
3-step Diarization process
1. Voice Activity Detection (VAD)
Detects different acoustic events: music, speech, noise ..
2. Speaker Change Detection
Detects speaker turn changes missed by VAD
3. Speaker Clustering
Group speaker segments from same speaker together




Cross-show Speaker Diarization
Giving a set of shows from same source, provides global
IDs for speakers who appear across shows.
Why cross-show?
In digital libraries or multimedia archives, some
speakers may appear multiple times, such as
journalists, politicians ..
Linkage to conventional speaker diarization
Global IDs vs. Local IDs

Cross-show Speaker Diarization
Generic Architectures
Scheme 1
Scheme 2 Scheme 3

Cross-show Speaker Diarization
Some results on English Podcast News data
Cross-show DER as metrics

Speaker Tracking
Aims to determine if and when target speaker speaks in a multi-speaker record. The target speaker has been enrolled into the system in the previous phase.
Why speaker tracking?
Tracking anchor speakers or politicians on broadcast news
Linkage to speaker diarization
Supervised approach (speaker models are required)
Diarization results are used as inputs
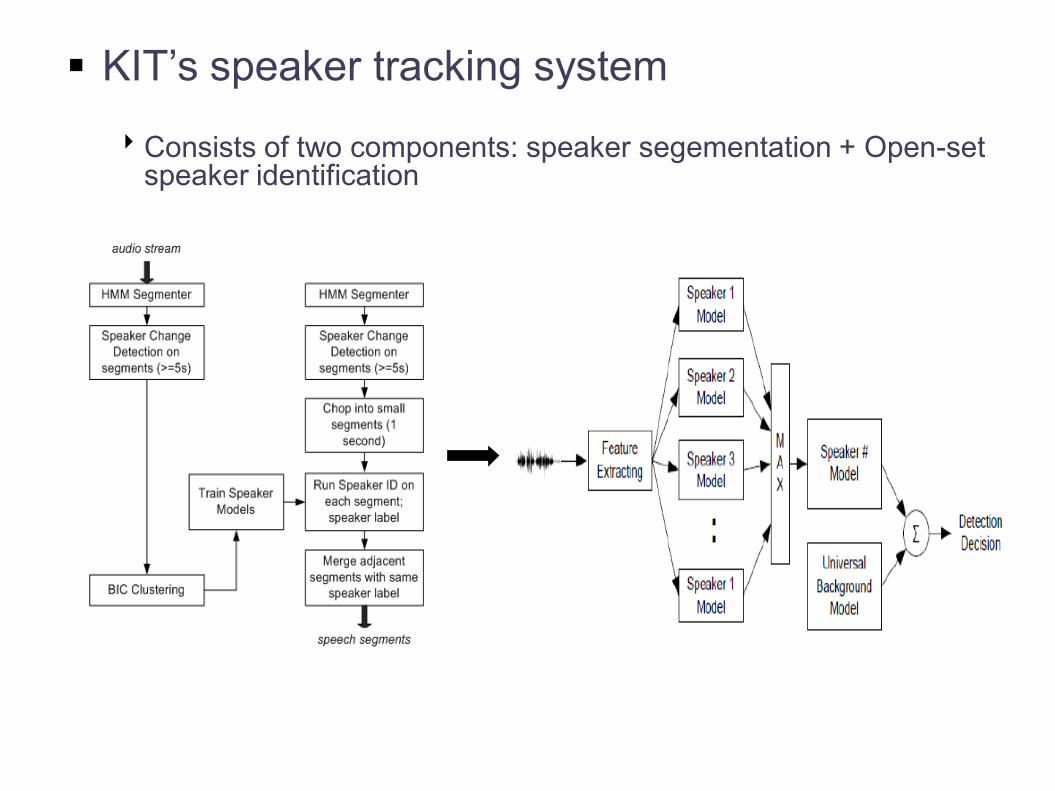
KIT’s speaker tracking system
Consists of two components: speaker segementation + Open-set speaker identification

System Architecture
Speaker segmentation
Split the speech into segments. Each segment has only one speaker speaking
Open-set speaker identification(SID)
- Training Phase:
• train 4 UBMs for telephone/studio male/female speech (gender and channel dependent) on ESTER2 data
• Speaker models obtained by MAP adapted on corresponding UBMs
- Detection Phase:
• System 1(baseline) - gender/bandwidth classification (GMM-based classifier), test segment scored against speaker and UBM models which matches gender/bandwidth conditions
• System 2 (FSC) - Apply frame-base score competition (FSC) [JSW07]
- 100 impostors(50F+50M) for T-Norm from ESTER1 data

Some results on French broadcast news
ESTER2 data, French BN
114 target speakers, 105h training data, 6 hours dev data
Metrics: Half total error rate (HTER)
System HTER-time HTER-speaker
Baseline 25.307% -- 31.943% --
Baseline+TNorm 25.314% -0.03% 31.953% -0.03%
FSC 24.098% 4.78% 31.319% 1.95%
FSC+TNorm 27.830% -9.97% 33.260% -4.12%

Thanks for your attention!
Questions?