automatic spatio-temporal indexing to integrate and analyze the data of an organization
TRANSCRIPT

Craig Knoblock (University of Southern California)
Aparna Joshi (National Institute of Technology Karnataka)
Abhishek Megotia (University of Southern California)
Minh Pham (University of Southern California)
Chelsea Ursaner (Office of Los Angeles Mayor Garcetti)
UrbanGIS’17, November 7–10, 2017, Redondo Beach, CA, USA
Automatic Spatio-temporal Indexing
to Integrate and Analyze the Data
of an Organization

Problem
• 1,100 datasets available about the City of Los Angeles
• Difficult to locate all relevant data
• No means of visualizing or integrating the data
• Cannot query for data in a particular geographic region or
time period
2

Approach
Automatically extract all data and store with their temporal and spatial extent
Preprocessing of the data
Querying the datasets
API Semantic
Labeling
Geocoding
Data
cleaning/
conversion
Store and index
data in
ElasticSearch
Open
data
portals
Downloaded
datasets
Latitude, Longitude
absent
Latitude, Longitude
present
ElasticSearch
Datastore
Queries filtering
documents
spatially and
temporally
Filtered
documents
with Map
visualizations
3

Acquiring the datasets
Acquiring the datasets from open data portals:
http://geohub.lacity.org https://data.lacity.org
An example dataset: Sewer_Structures
4
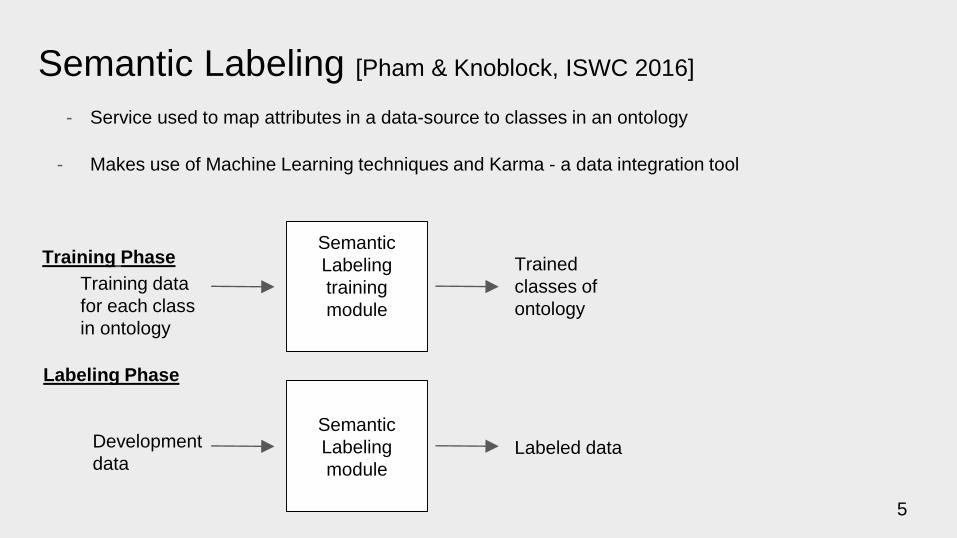
Semantic Labeling [Pham & Knoblock, ISWC 2016]
- Service used to map attributes in a data-source to classes in an ontology
- Makes use of Machine Learning techniques and Karma - a data integration tool
Training Phase
Training data
for each class
in ontology
Semantic
Labeling
training
module
Trained
classes of
ontology
Labeling Phase
Development
data
Semantic
Labeling
moduleLabeled data
5
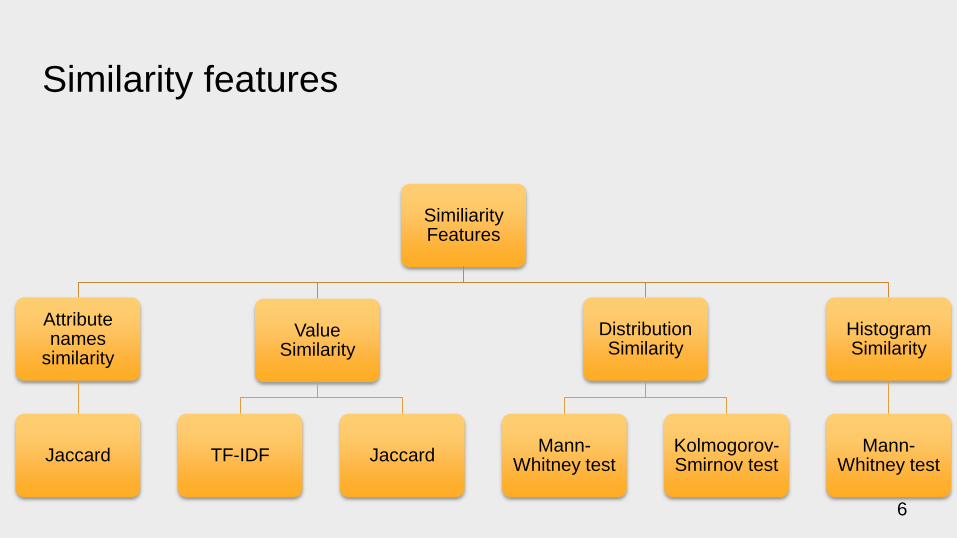
Similarity features
Similiarity Features
Attributenames
similarity
Jaccard
Value Similarity
TF-IDF Jaccard
Distribution Similarity
Mann-Whitney test
Kolmogorov-Smirnov test
Histogram Similarity
Mann-Whitney test
6
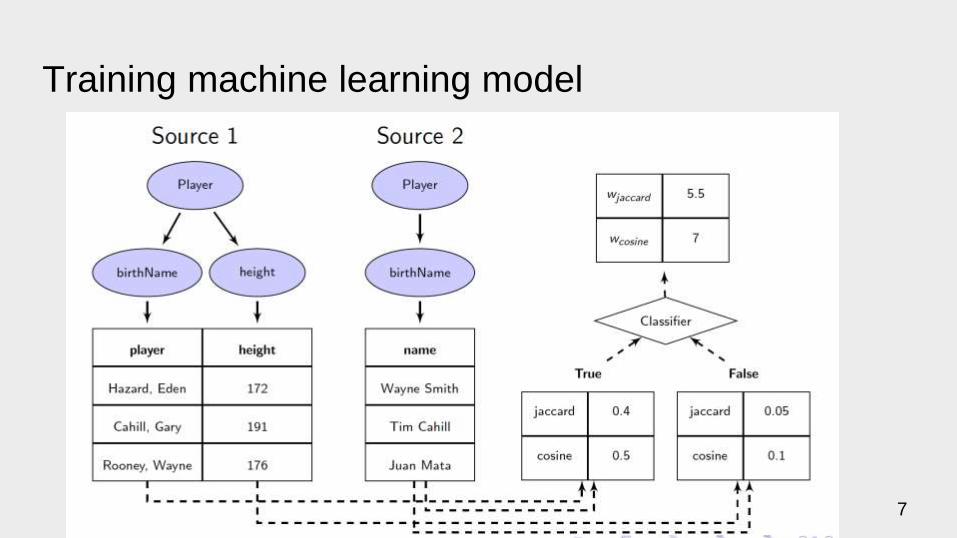
Training machine learning model
7

Predicting new attribute
8
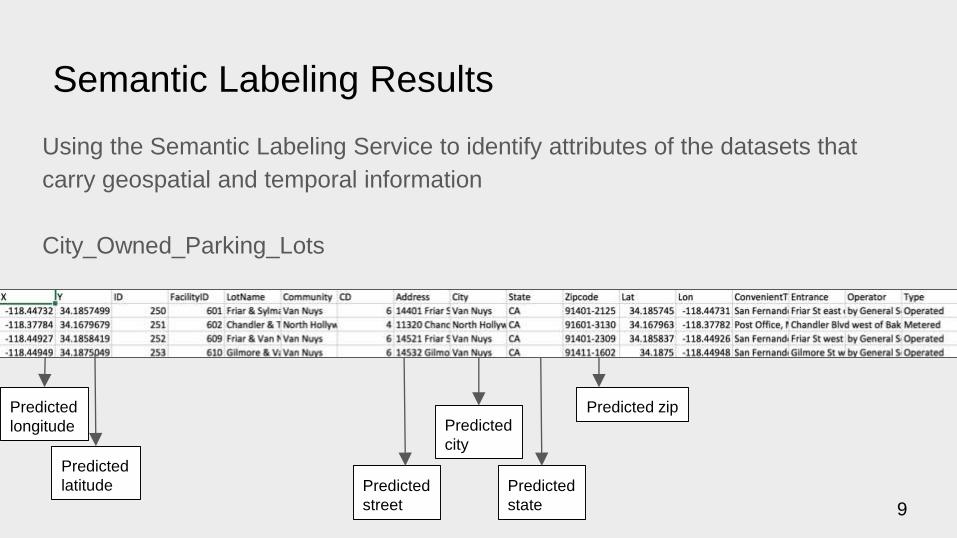
Semantic Labeling Results
Using the Semantic Labeling Service to identify attributes of the datasets that
carry geospatial and temporal information
City_Owned_Parking_Lots
Predicted
longitude
Predicted
latitude
Predicted
city
Predicted
state
Predicted zip
Predicted
street 9
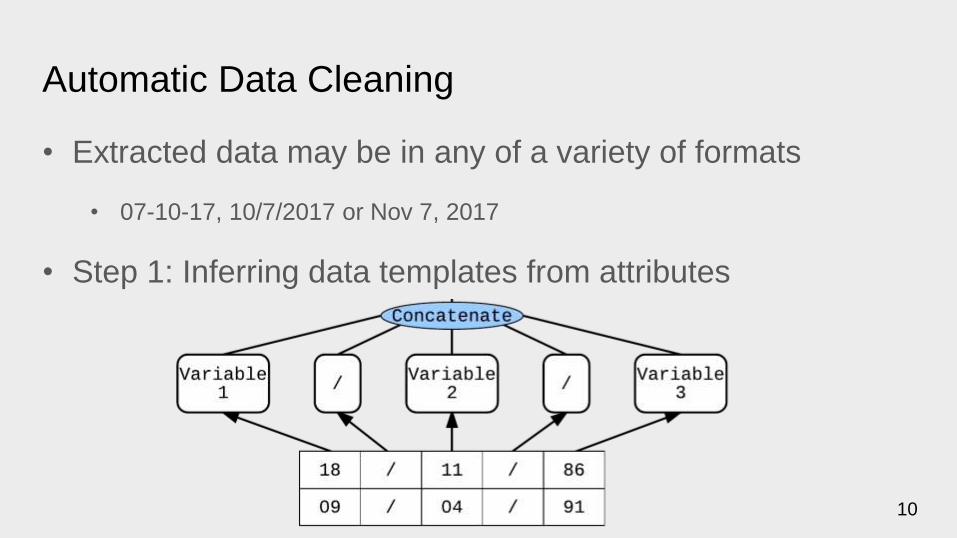
Automatic Data Cleaning
• Extracted data may be in any of a variety of formats
• 07-10-17, 10/7/2017 or Nov 7, 2017
• Step 1: Inferring data templates from attributes
10

Data Cleaning (cont.)
• Step 2: Map corresponding
elements in templates across
different attributes
• Step 3: Replace corresponding
elements in the standard format
with elements from original
format
11

Data Conversion
Extraction of meta-data to support querying:
• Table_name
• Row_in_dataset
• url_link
• Date
• Location
• Data – original data record
12

99th row of Trees_Recreation_and_Parks_Department in JSON format:
{"index":{"_index":"datasets","_type":"Trees_Recreation_and_Parks_Department"}}
{ "url_link": "http://geohub.lacity.org/datasets/3ac3c0dc510a4581bb7f2c879f15ede5_6.csv",
"table_name": "Trees_Recreation_and_Parks_Department",
"location": { "lat": "33.790500072784795",
"lon": "-118.259720508240946"},
"date": "2004-07-15T00:00:00.000Z",
"row_in_dataset": 99,
"data": { "GROWTH_AND": "Slow growing to 40' with dense canopy of stiff fronds",
"TREE_HEIGH": "10-20 ft. Small",
"TREETYPE": "Palm",
"AREA_DEVEL": "Irrigated Turf",
"SPECIAL_VA": "0",
"CANOPY_DEN": "Light",
...
"FAMILY": "Arecaceae",
"FACILITY": "Banning Residence Museum"}}
Results of Data Conversion
13

Storing the Data in ElasticSearch
Each individual record obtained after data conversion is now loaded into
elasticsearch
ElasticSearch
● A search engine based on Apache Lucene
● Open source
● Can query data really fast due to good indexing techniques
● Provides ability to combine geo-location and date with search effectively
● Provides a web interface, Kibana, to query and visualize data
14

{
"geo_distance": {
"distance": "2km",
"location": {
"lat": "34.052749942056835",
"lon": "-118.29490008763969"
}
}
},
{
"range": {
"date": {
"gte": "1990-01-01T17:56:13.833Z"
}
}
}
Querying based on radius and time
Query - retrieve the documents in ElasticSearch that fall within a radius of 2km from the specified central
location, having dates after the specified date.
15

"_source": ["url_link", "table_name"],
"Query": {
"Bool": {
"Filter": [
{
"Geo_distance": {
"distance": "2km",
"Location": {
"Lat": "34.052749942056835",
"lon": "-118.29490008763969"
}
}},
{
"Range": {"date": {
"gte": "1990-01-01T17:56:13.833Z"
}
}
}]
}},
"Aggs": {
"Genres": { "terms": {
"field": "_type"
} }
}
Query to identify sources of the filtered data"aggregations": {
"Genres": {
"buckets": [
{
"key": "Businesses_Active",
"doc_count": 17876
},
{
"key": "Microwave_Towers",
"doc_count": 78
}
…
…
...
{
"key": "Children_and_Family_Services",
"doc_count": 70
}
]
}
}
}
16

ResultsLoading the data
● ~4M records from 212 datasets
● Time taken to insert the data ~ 60hrs
Querying the data
1. Fetch all the records in a 2km radius from x,y where the date is greater than some date d
2. Fetch all the data that is indexed in the data-store
3. Fetch the records with a given bounding box x1,y1 and x2,y2
4. Fetch the table name and url for all the records in a 2 km radius from x,y where the date
is greater than some date d
17
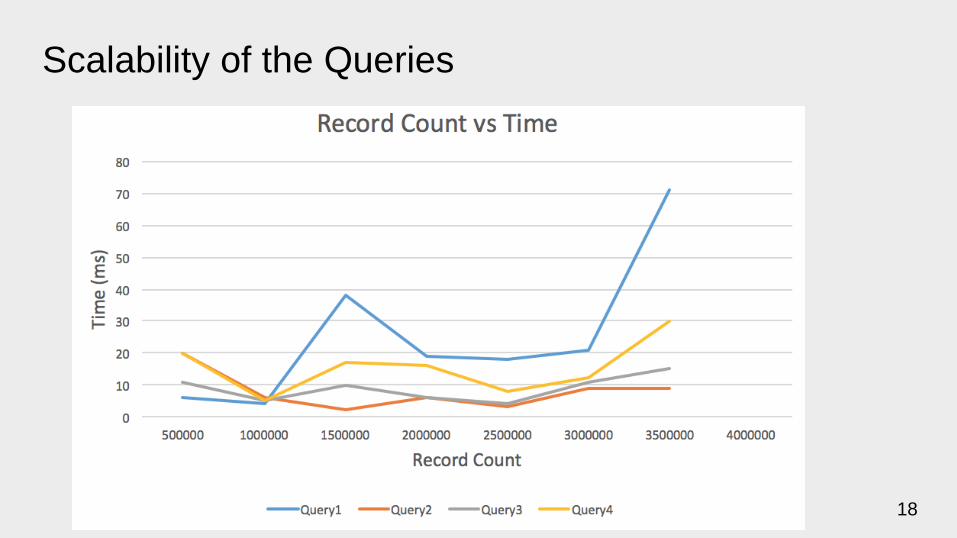
Scalability of the Queries
18

Next Steps
• Running it on all 1,100 sets of data
• Improvement of the precision and recall of semantic labeling
• Additional capabilities in automatic data cleaning
• Automatic extraction and integration of entities across across sources
19

Thanks!
20