authors:jochen dijrre, peter gerstl, roland seiffert adapted from slides by: trevor crum presenter:...
TRANSCRIPT

Authors:Jochen Dijrre, Peter Gerstl, Roland SeiffertAdapted from slides by: Trevor Crum Presenter: Nicholas Romano
Text Mining:Finding Nuggets in Mountains of Textual Data
1

Outline
● Definition and Paper Overview● Motivation● Methodology● Feature Extraction● Clustering and Categorizing● Some Applications● Comparison with Data Mining● Conclusion & Exam Questions
2

Definition
● Text Mining: ○ The discovery by computer of new, previously
unknown information, by automatically extracting information from different unstructured textual documents.
○ Also referred to as text data mining, roughly equivalent to text analytics which refers more specifically to problems based in a business settings.
3

Paper Overview
● This paper introduced text mining and how it differs from data mining proper.
● Focused on the tasks of feature extraction and clustering/categorization
● Presented an overview of the tools/methods of IBM’s Intelligent Miner for Text
4

Outline
● Definition and Paper Overview● Motivation● Methodology● Feature Extraction● Clustering and Categorizing● Some Applications● Comparison with Data Mining● Conclusion & Exam Questions
5

Motivation
● A large portion of a company’s data is unstructured or semi-structured – about 90% in 1999!• Letters• Emails• Phone transcripts• Contracts
• Technical documents• Patents• Web pages• Articles
6

Typical Applications
● Summarizing documents● Discovering/monitoring relations among
people, places, organizations, etc● Customer profile analysis● Trend analysis● Document summarization● Spam Identification● Public health early warning● Event tracks
7

Outline
● Definition and Paper Overview● Motivation● Methodology● Comparison with Data Mining● Feature Extraction● Clustering and Categorizing● Some Applications● Conclusion & Exam Questions
8

Methodology: Challenges
● Information is in unstructured textual form● Natural language interpretation is difficult &
complex task! (not fully possible)○ Google and Watson are a step closer
● Text mining deals with huge collections of documents○ Impossible for human examination
9

Google vs Watson
● Google justifies the answer by returning the text documents where it found the evidence.
● Google finds documents that are most suitable to a given Keyword.
● Watson tries to understand the semantics behind a given key phrase or question.
● Then Watson will use its huge knowledge base to find the correct answer.
10

Methodology: Two Aspects
● Knowledge Discovery○ Extraction of codified information
■ Feature Extraction○ Mining proper; determining some structure
● Information Distillation○ Analysis of feature distribution
11

Two Text Mining Approaches● Extraction
○ Extraction of codified information from a single document
● Analysis○ Analysis of the features to detect patterns, trends, and
other similarities over whole collections of documents
12

Outline
● Definition and Paper Overview● Motivation● Methodology● Feature Extraction● Clustering and Categorizing● Some Applications ● Comparison with Data Mining● Conclusion & Exam Questions
13

Feature Extraction
● Recognize and classify “significant” vocabulary items from the text
● Categories of vocabulary○ Proper names – Mrs. Albright or Dheli, India○ Multiword terms – Joint venture, online document○ Abbreviations – CPU, CEO○ Relations – Jack Smith-age-42 ○ Other useful things: numerical forms of numbers,
percentages, money, dates, and many other
14

Canonical Form Examples
● Normalize numbers, money○ Four = 4, five-hundred dollars = $500
● Conversion of date to normal form○ 8/17/1992 = August 18 1992
● Morphological variants○ Drive, drove, driven = drive
● Proper names and other forms○ Mr. Johnson, Bob Johnson, The author = Bob
Johnson
15

Feature Extraction Approach● Linguistically motivated heuristics● Pattern matching● Limited lexical information (part-of-speech)● Avoid analyzing with too much depth
○ Does not use too much lexical information○ No in-depth syntactic or semantic analysis
16

IBM Intelligent Miner for Text● IBM introduced Intelligent Miner for Text in
1998● SDK with: Feature extraction, clustering,
categorization, and more● Traditional components (search engine, etc)
17

Advantages to IBM’s approach● Processing is very fast (helps when dealing
with huge amounts of data)● Heuristics work reasonably well● Generally applicable to any domain
18

Outline
● Definition and Paper Overview● Motivation● Methodology● Comparison with Data Mining● Feature Extraction● Clustering and Categorizing● Some Applications● Conclusion & Exam Questions
19

Clustering
● Fully automatic process● Documents are grouped according to
similarity of their feature vectors● Each cluster is labeled by a listing of the
common terms/keywords● Good for getting an overview of a document
collection
20

Two Clustering Engines
● Hierarchical clustering○ Orders the clusters into a tree reflecting various levels
of similarity● Binary relational clustering
○ Flat clustering○ Relationships of different strengths between clusters,
reflecting similarity
21
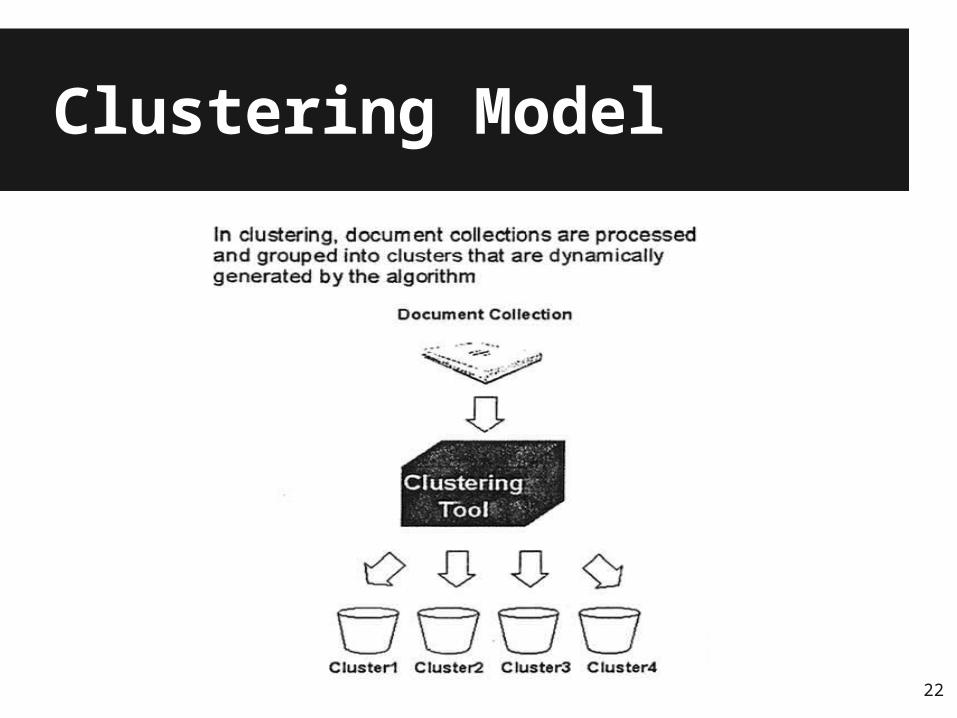
Clustering Model
22

Categorization
● Assigns documents to preexisting categories● Classes of documents are defined by
providing a set of sample documents.● Training phase produces “categorization
schema”● Documents can be assigned to more than
one category● If confidence is low, document is set aside
for human intervention
23
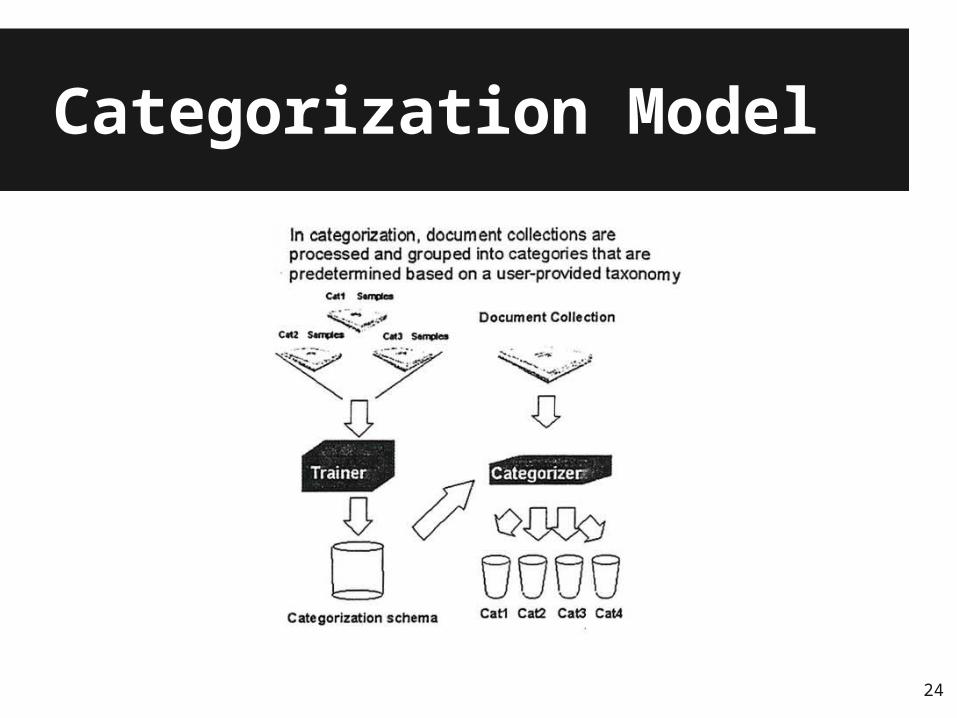
Categorization Model
24

Outline
● Definition and Paper Overview● Motivation● Methodology● Feature Extraction● Clustering and Categorizing● Some Applications● Comparison with Data Mining● Conclusion & Exam Questions
25

Applications
● Customer Relationship Management application provided by IBM Intelligent Miner for Text called “Customer Relationship Intelligence” or CRI ○ “Help companies better understand what their
customers want and what they think about the company itself”
26

Customer Intelligence Process● Take as input body of communications with
customer● Cluster the documents to identify issues● Characterize the clusters to identify the
conditions for problems● Assign new messages to appropriate
clusters
27
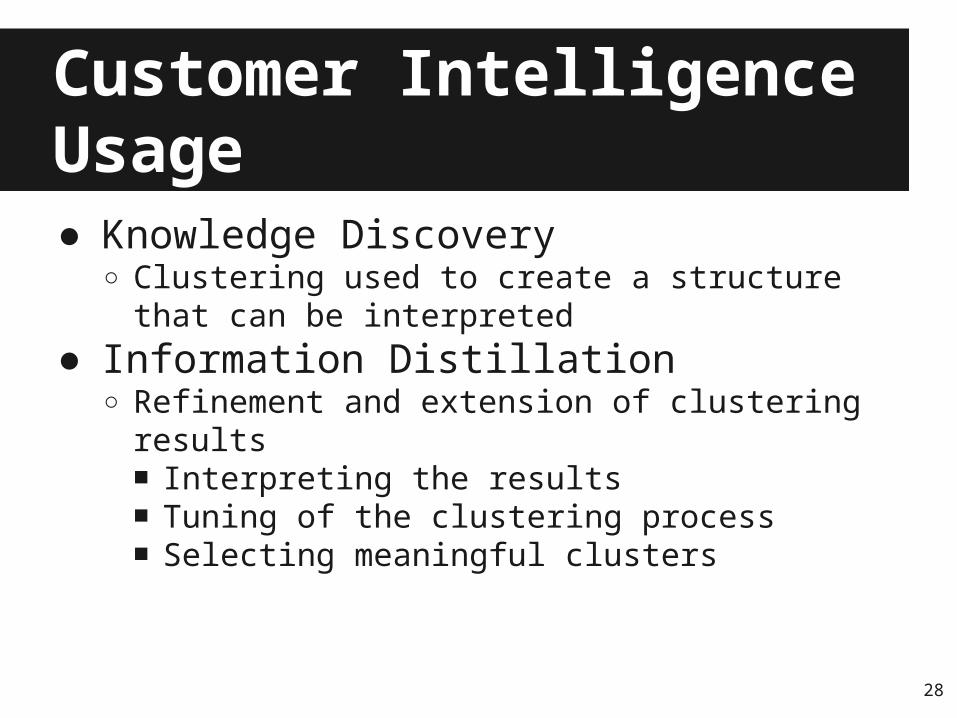
Customer Intelligence Usage● Knowledge Discovery
○ Clustering used to create a structure that can be interpreted
● Information Distillation○ Refinement and extension of clustering results
■ Interpreting the results■ Tuning of the clustering process■ Selecting meaningful clusters
28

Outline
● Definition and Paper Overview● Motivation● Methodology● Feature Extraction● Clustering and Categorizing● Some Applications ● Comparison with Data Mining● Conclusion & Exam Questions
29

Comparison with Data Mining● Data mining
○ Discover hidden models.
○ tries to generalize all of the data into a single model.
○ marketing, medicine, health care
● Text mining○ Discover hidden facts.○ tries to understand the
details, cross reference between individual instances
○ biosciences, customer profile analysis
30

Outline
● Definition and Paper Overview● Motivation● Methodology● Feature Extraction● Clustering and Categorizing● Some Applications ● Comparison with Data Mining● Conclusion & Exam Questions
31

Conclusion
● Text mining can be used as an effective business tool that supports○ Creation of knowledge by preparing and organizing
unstructured textual data [Knowledge Discovery] ○ Extraction of relevant information from large amounts
of unstructured textual data through automatic pre-selection based on user defined criteria [Information Distillation]
32

Exam Question #1
● How does the procedure for text mining differ from the procedure for data mining?○ Adds feature extraction phase○ Infeasible for humans to select features manually○ The feature vectors are, in general, highly
dimensional and sparse
33

Questions?
34

Web Mining Research: A Survey
Authors: Raymond Kosala & Hendrik BlockeelPresenter: Nick Romano Slides adapted from: Ryan Patterson
April 23rd 2014 CS332 Data Mining
pg 01

outline• Introduction• Web Mining• Web Content Mining• Web Structure Mining• Web Usage Mining• Review• Exam Questions
pg 03

Introduction“The Web is huge, diverse, and dynamic . . . we are currently drowning in information and facing information overload.”Web users encounter problems:
• Finding relevant information• Creating new knowledge out of the information available
on the Web• Personalization of the information• Learning about consumers or individual users
pg 04

outline• Introduction• Web Mining• Web Content Mining• Web Structure Mining• Web Usage Mining• Review• Exam Questions
pg 05

Web Mining“Web mining is the use of data mining techniques to automatically discover and extract information from Web documents and services.”Web mining subtasks:1. Resource finding2. Information selection and pre-processing3. Generalization4. Analysis
pg 06

Information Retrieval & Information Extraction• Information Retrieval (IR)
o the automatic retrieval of all relevant documents while at the same time retrieving as few of the non-relevant as possible
• Information Extraction (IE)o transforming a collection of documents into
information that is more readily digested and analyzed
pg 07

outline• Introduction• Web Mining• Web Content Mining• Web Structure Mining• Web Usage Mining• Review• Exam Questions
pg 09

Web Content MiningInformation Retrieval ViewUnstructured Documents
• Most utilizes “bag of words” representation to generate documents featureso ignores the sequence in which the words occur
• Document features can be reduced with selection algorithmso ie. information gain
• Possible alternative document feature representations:o word positions in the documento phrases/terms (ie. “annual interest rate”)
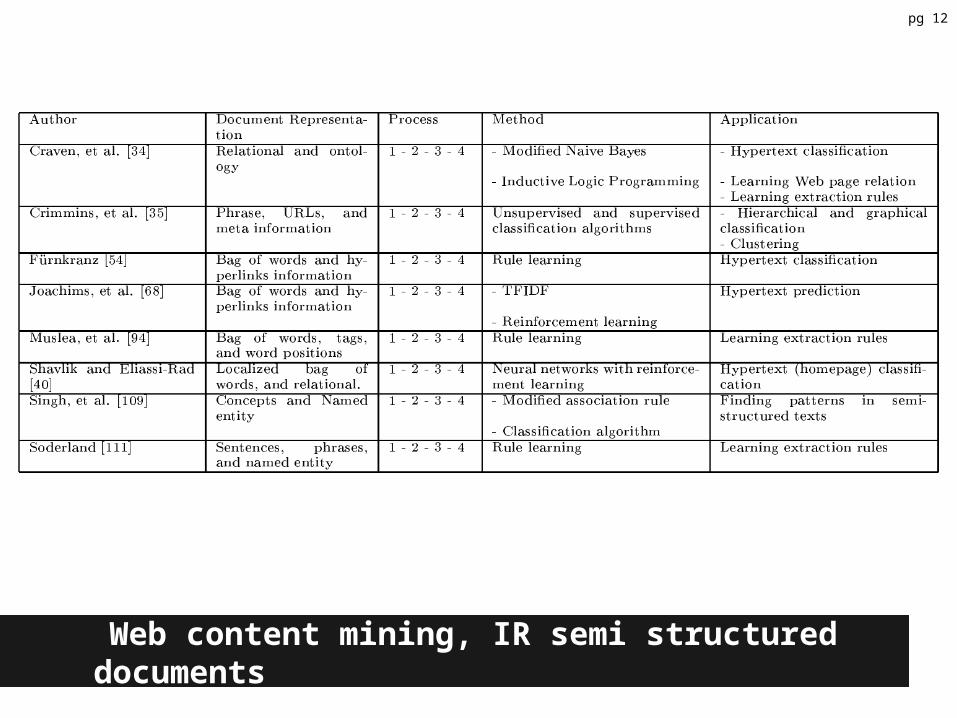
Semi-Structured Documents• Utilize additional structural information gleaned from the document
o HTML markup (intra-document structure)o HTML links (inter-document structure)
pg 10
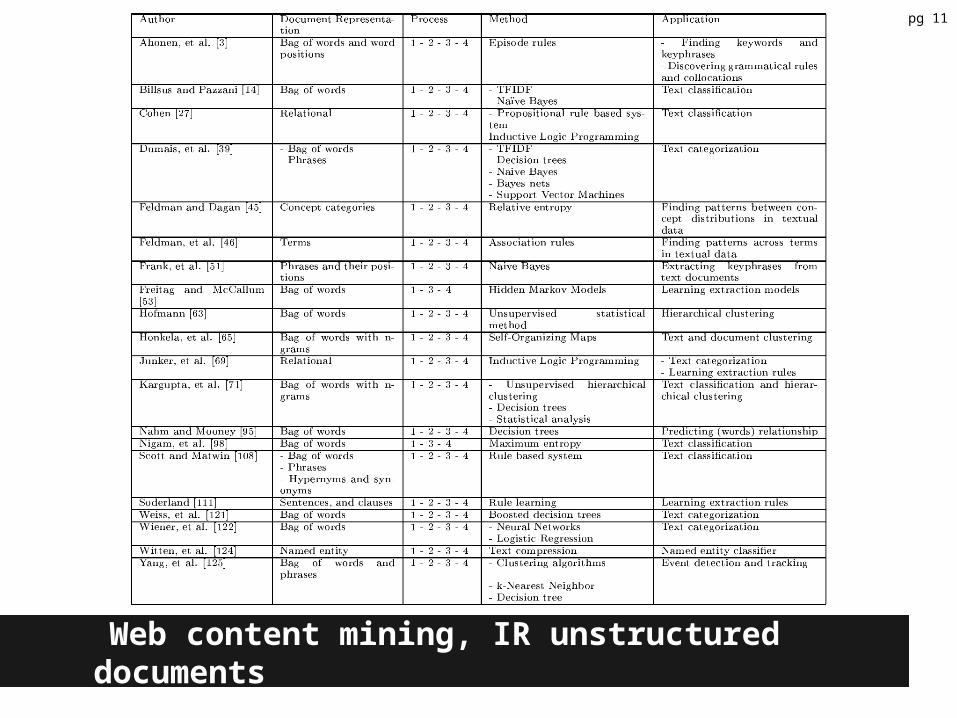
Web content mining, IR unstructured documents
pg 11
Web content mining, IR semi structured documents
pg 12

Web Content MiningDatabase View“the Database view tries . . . to transform a Web site to become a database so that . . . querying on the Web become[s] possible.”
• Uses Object Exchange Model (OEM)o represents semi-structured data by a labeled graph
• Database view algorithms typically start from manually selected Web siteso site-specific parsers
• Database view algorithms produce:o extract document level schema or DataGuides
▪ structural summary of semi-structured datao extract frequent substructures (sub-schema)o multi-layered database
▪ each layer is obtained by generalizations on lower layers
pg 13

Web content mining, Database view
pg 14

outline• Introduction• Web Mining• Web Content Mining• Web Structure Mining• Web Usage Mining• Review• Exam Questions
pg 15

Web Structure Mining“. . . we are interested in the structure of the hyperlinks within the Web itself”
• Inspired by the study of social networks and citation analysiso based on incoming & outgoing links we could discover specific types
of pages (such as hubs, authorities, etc)
• Some algorithms calculate the quality/relevancy of each Web pageo ie. Page Rank
• Others measure the completeness of a Web siteo measuring frequency of local links on the same servero interpreting the nature of hierarchy of hyperlinks on one domain
pg 16

outline• Introduction• Web Mining• Web Content Mining• Web Structure Mining• Web Usage Mining• Review• Exam Questions
pg 17

Web Usage Mining“. . . focuses on techniques that could predict user behavior while the user interacts with the Web.”
• Web usage is mined by parsing Web server logso mapped into relational tables → data mining techniques appliedo log data utilized directly
• Users connecting through proxy servers and/or users or ISP’s utilizing caching of Web data results in decreased server log accuracy
• Two applications:o personalized - user profile or user modeling in adaptive interfaceso impersonalized - learning user navigation patterns
pg 18

outline• Introduction• Web Mining• Web Content Mining• Web Structure Mining• Web Usage Mining• Review• Exam Questions
pg 19

Review• Web mining
o 4 subtaskso IR & IE
• Web content miningo primarily intra-page analysiso IR view vs DB view
• Web structure miningo primarily inter-page analysis
• Web usage miningo primarily analysis of server activity logs
pg 20
Web mining categories
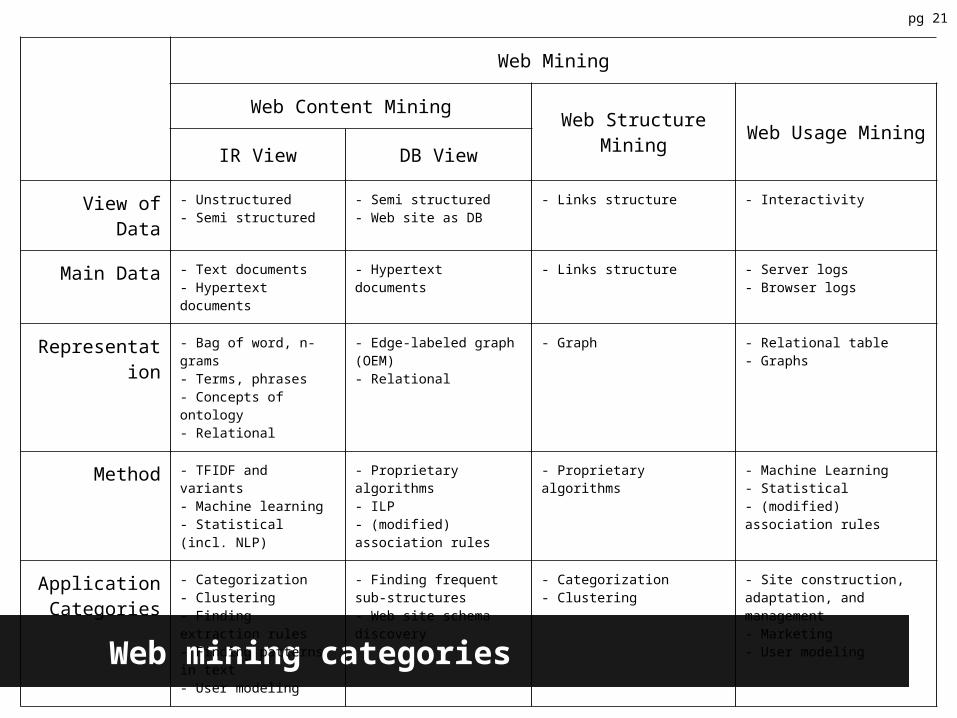
Web Mining
Web Content MiningWeb Structure Mining Web Usage Mining
IR View DB View
View of Data - Unstructured- Semi structured
- Semi structured- Web site as DB
- Links structure - Interactivity
Main Data - Text documents- Hypertext documents
- Hypertext documents - Links structure - Server logs- Browser logs
Representation - Bag of word, n-grams- Terms, phrases- Concepts of ontology- Relational
- Edge-labeled graph (OEM)- Relational
- Graph - Relational table- Graphs
Method - TFIDF and variants- Machine learning- Statistical (incl. NLP)
- Proprietary algorithms- ILP- (modified) association rules
- Proprietary algorithms - Machine Learning- Statistical- (modified) association rules
ApplicationCategories
- Categorization- Clustering- Finding extraction rules- Finding patterns in text- User modeling
- Finding frequent sub-structures- Web site schema discovery
- Categorization- Clustering
- Site construction, adaptation, and management- Marketing- User modeling
pg 21

outline• Introduction• Web Mining• Web Content Mining• Web Structure Mining• Web Usage Mining• Review• Exam Questions
pg 22

Exam Question 2Q: Of the following Web mining paradigms:
• Information Retrieval• Information Extraction
Which does a traditional Web search engine (google.com, bing.com, etc.) attempt to accomplish? Briefly support your answer.
A: Information Retrieval, the search engine attempts provides a list of documents ranked by their relevancy to the search query.
pg 24

Exam Question 3Q: State one common problem hampering accurate Web usage mining? Briefly support your answer.
A:• Users connecting to a Web site though a proxy server,• Users (or their ISP’s) utilizing Web data caching,will
result in decreased server log accuracy. Accurate server logs are required for accurate Web usage mining.
pg 26

Exam Question 1 (Again)
● How does the procedure for text mining differ from the procedure for data mining?○ Adds feature extraction phase○ Infeasible for humans to select features manually○ The feature vectors are, in general, highly
dimensional and sparse
57
Questions?
58