asynchronous migration for parallel genetic programming on a computer cluster with multi-core...
TRANSCRIPT

ORIGINAL ARTICLE
Artif Life Robotics (2012) 16:533–536 © ISAROB 2012DOI 10.1007/s10015-011-0983-z
Shingo Kurose · Kunihito Yamamori · Masaru Aikawa Ikuo Yoshihara
Asynchronous migration for parallel genetic programming on a computer cluster with multi-core processors
1 Introduction
Genetic programming (GP)1–3 is one type of evolutionary computation for optimization inspired by biological evolu-tion. In GP, an individual who is a candidate for a solution has a tree-like structure, and each individual evolves by genetic operations such as crossover and mutation. In selec-tion, individuals with a higher fi tness have a higher prob-ability of remaining for the next generation. So GP can produce an appropriate solution automatically. The compu-tation time of GP becomes longer with an increase in the number of individuals and generations included in order to obtain a more accurate solution. To reduce the computation time, GP is sometimes implemented in parallel computers such as a computer cluster.
This article proposes a new parallel genetic program-ming implementation based on the island model with asyn-chronous migration. Most recent computers are equipped with one or more multi-core processors, and are suitable for multi-threading. Therefore we employ a communication thread for migration between islands. The communication thread on a processor communicates with the communica-tion thread on another processor to migrate individuals at appropriate intervals. Since the migration and other genetic operations can be independently processed on each core, and since we allow the exchange of individuals of different generations, no synchronization is needed in our implemen-tation. In addition, a fi tness calculation is also executed in parallel by the remaining cores. We evaluated the proposed implementation on an actual computer cluster.
2 Parallel genetic programming
2.1 The island model
The island model2 is one of the implementation models of parallel and distributed genetic programming. The island model distributes individuals into several groups, and each group is assigned to an island. Since genetic operations in
Abstract An island model is a typical implementation of genetic programming on parallel computers with distrib-uted memory. The island model has a migration facility that sends/receives some individuals in an island to/from another island to maintain diversity. The island model requires synchronization to migrate same-generation individuals between islands, and this synchronization causes an increase in computation time. This article proposes a new parallel genetic programming implementation based on the island model with asynchronous migration. Most recent comput-ers are equipped with one or more multi-core processors, and are suitable for multi-threading. Therefore we employ a communication thread for migration between islands. The communication thread on a processor communicates with the communication thread on another processor to migrate individuals at appropriate intervals. Since the migration and other genetic operations can be independently processed on each core, and since we allow the exchange of individuals of different generations, no synchronization is needed in our implementation. In addition, a fi tness calculation is also executed in parallel by the remaining cores. Experimental results show that the proposed method can reduce the com-putation time to about 17% in serial GP by using 40 threads.
Key words Genetic programming (GP) · Message-passing interface (MPI) · Multi-threading · Island model · Asyn-chronous migration
Received: June 28, 2011 / Accepted: June 30, 2011
S. KuroseGraduate School of Engineering, University of Miyazaki, 1-1 Gakuen Kibanadai-nishi, Miyazaki-shi 889-2192, Japan
K. Yamamori (*) · I. YoshiharaFaculty of Engineering, University of Miyazaki, 1-1 Gakuen Kibanadai-nishi, Miyazaki-shi 889-2192, Japane-mail: [email protected]
M. AikawaTechnical Center, Faculty of Engineering, University of Miyazaki, 1-1 Gakuen Kibanadai-nishi, Miyazaki-shi 889-2192, Japan
This work was presented in part at the 16th International Symposium on Artifi cial Life and Robotics, Oita, Japan, January 27–29, 2011

534
each island can be processed in parallel, the island model can reduce the computation time. The island model usually includes migration, so that individuals can migrate from one island to another in order to maintain diversity. Figure 1 shows an example of the island model with three processing elements (PEs).
2.2 Synchronous migration
Migration is a process that moves individuals from one island to another every few generations in order to maintain the diversity of individuals. The genetic operations in each island are processed independently and in parallel, and the computation time for these operations is different in each PE. Therefore synchronization among PEs is needed when we want same-generation individuals to migrate between islands. This means that the PEs cannot move an individual until all the PEs have fi nished their genetic operations. This overhead synchronization results in long computation times.
3 Multi-threaded parallel genetic programming
3.1 Asynchronous migration
To avoid overhead synchronization, we propose a multi-threaded GP that separates migration operations from genetic operations. Recent processors are equipped with several processing cores on a die, and they share the main memory. This architecture is suitable for multi-threading.4
We create two types of thread, one is the main thread that executes the genetic operations, and the other is the communication thread that exchanges individuals between PEs by a message-passing interface (MPI).3 These threads can work in parallel. It is then possible to exchange indi-viduals of different generations, and we can avoid overhead synchronization by this synchronization. We now explain asynchronous migration in detail. First each PE creates a main thread. The main thread generates individuals at random, and calculates the fi tness of each individual. Next the main thread selects an elite individual and writes it into the transmission buffer. Here, synchronization is executed only once. Then a communication thread is created, and this sends the stored elite individuals in the transmission buffer to the other PE at appropriate intervals, as shown in Fig. 2. The communication thread also receives the individual transferred from the other PE and writes it into the receiv-ing buffer. The main thread reads the receiving buffer in every few generations, and it takes the migrated individuals to their own island. Since the main thread and the commu-nication thread share both buffers, they exclusively access those buffers.
3.2 Multi-threaded fi tness calculation
Some current processors have more than two cores, so we utilize the remaining cores except for the main thread and the communication thread. Our implementation creates threads for fi tness calculations, and these threads also work in parallel. The main thread and the fi tness calculation threads in the same PE access the individuals via a shared memory. Figure 3 illustrates an example of the task alloca-
Serial GP
Island model GP
PE 1
PE 1
Island 1
PE 2 PE 3
Migration
Individuals
Island 2 Island 3
Group 1Group 2Group 3
Group 1
Group 2 Group 3
Fig. 1. An example of the island model with three processing elements
PE
Group k
Core 1
Core 2
Communicationthread
ProcessorShared memory
The transmission buffer
The receiving buffer
Anothercommunication
thread
Communication
Main thread
Read
Read
Write
Write
Send
Receive
Individuals
Island k
Fig. 2. The main thread and the communication thread share both the transmission buffer and the receiving buffer
535
tion for two PEs, where each PE has four processing cores in a processor.
4 Experimental results and discussions
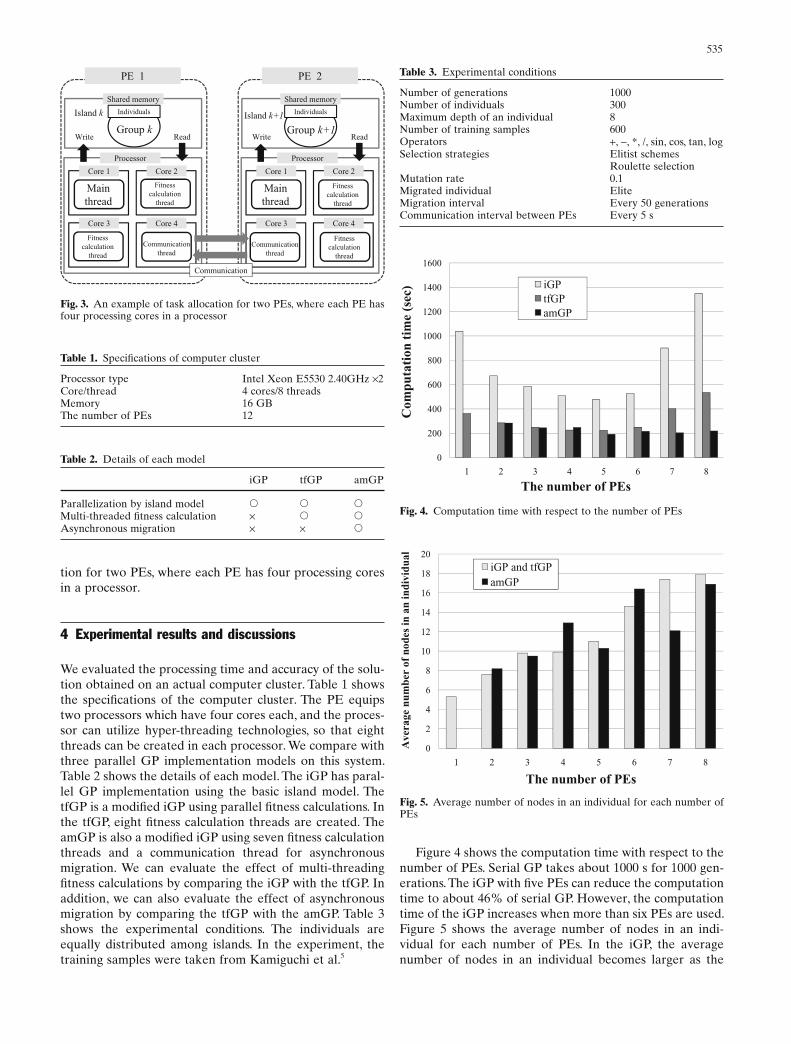
We evaluated the processing time and accuracy of the solu-tion obtained on an actual computer cluster. Table 1 shows the specifi cations of the computer cluster. The PE equips two processors which have four cores each, and the proces-sor can utilize hyper-threading technologies, so that eight threads can be created in each processor. We compare with three parallel GP implementation models on this system. Table 2 shows the details of each model. The iGP has paral-lel GP implementation using the basic island model. The tfGP is a modifi ed iGP using parallel fi tness calculations. In the tfGP, eight fi tness calculation threads are created. The amGP is also a modifi ed iGP using seven fi tness calculation threads and a communication thread for asynchronous migration. We can evaluate the effect of multi-threading fi tness calculations by comparing the iGP with the tfGP. In addition, we can also evaluate the effect of asynchronous migration by comparing the tfGP with the amGP. Table 3 shows the experimental conditions. The individuals are equally distributed among islands. In the experiment, the training samples were taken from Kamiguchi et al.5
Figure 4 shows the computation time with respect to the number of PEs. Serial GP takes about 1000 s for 1000 gen-erations. The iGP with fi ve PEs can reduce the computation time to about 46% of serial GP. However, the computation time of the iGP increases when more than six PEs are used. Figure 5 shows the average number of nodes in an indi-vidual for each number of PEs. In the iGP, the average number of nodes in an individual becomes larger as the
PE 1
Group k
Core 1
Processor
Core 3
Core 2
Core 4
Shared memory
Main thread
ReadWrite
PE 2
Core 1
Processor
Core 3
Core 2
Core 4
Shared memory
Main thread
ReadWrite
Fitness calculation
thread
Communication thread
Fitness calculation
thread
Communication thread
Fitness calculation
thread
Fitness calculation
thread
Communication
Group k+1
Individuals IndividualsIsland k Island k+1
Fig. 3. An example of task allocation for two PEs, where each PE has four processing cores in a processor
Table 1. Specifi cations of computer cluster
Processor type Intel Xeon E5530 2.40GHz ×2Core/thread 4 cores/8 threadsMemory 16 GBThe number of PEs 12
Table 2. Details of each model
iGP tfGP amGP
Parallelization by island model � � �
Multi-threaded fi tness calculation × � �
Asynchronous migration × × �
Table 3. Experimental conditions
Number of generations 1000Number of individuals 300Maximum depth of an individual 8Number of training samples 600Operators +, −, *, /, sin, cos, tan, logSelection strategies Elitist schemes
Roulette selectionMutation rate 0.1Migrated individual EliteMigration interval Every 50 generationsCommunication interval between PEs Every 5 s
0
200
400
600
800
1000
1200
1400
1600
1 2 3 4 5 6 7 8
Com
pu
tati
on t
ime
(sec
)
The number of PEs
iGPtfGPamGP
Fig. 4. Computation time with respect to the number of PEs
0
2
4
6
8
10
12
14
16
18
20
1 2 3 4 5 6 7 8
Ave
rage
nu
mb
er o
f n
odes
in a
n in
div
idu
al
The number of PEs
iGP and tfGPamGP
Fig. 5. Average number of nodes in an individual for each number of PEs

536
where n is the number of training samples, and yi and yi are the desired value and the output of an individual for the i-th training sample, respectively. In Fig. 6, the average fi tness of the iGP, the tfGP, and the amGP becomes larger as the number of PEs increases. The GP parallelized by the island model can improve the fi tness compared with serial GP because the island model searches solutions in a wider space.6 From Figs. 4 and 6, it can be seen that our proposed method is effective when many PEs are used to obtain a more accurate solution.
5 Conclusions
We have proposed a new parallel genetic programming implementation based on the island model using asynchro-nous communication between PEs. We implemented the island model using MPI, and employed a communication thread for asynchronous migration between PEs. In addi-tion, the proposed method creates threads for parallel fi tness calculations. In other words, our implementation uti-lizes both the inter-PE parallelism of the island model and the intra-PE parallelism of multi-threading. The experimen-tal results show that our proposed method with fi ve PEs and 40 threads can reduce the computation time to about 17% of serial GP. In the future, we will try to integrate a load-balancing mechanism to improve the effi ciency of parallelization.
References
1. Numata N, Sugawara K, Yamada S, et al (1999) Time series predic-tion modeling by genetic programming without inheritance of model parameters. Proceedings of the 4th International Symposium on Artifi cial Life and Robotics, pp 500–503
2. Eklund SE (2003) Time series forecasting using massively parallel genetic programming. Parallel and Distributed Processing Sympo-sium, 10.1109/IPDS.2003.1213272
3. Messom CH, Walker MG (2002) Evolving cooperative robotic behaviour using distributed genetic programming. Control Autom Robotics Vision 1:215–219
4. Nichols B, Buttlar D, Farrell JP (1996) P-threads programming (a nutshell handbook). Oreilly, California
5. Kamiguchi M, Yamamori K, Yoshihara I, et al (2009) An automatic model building for screening functional foods with GP. ICROS–SICE International Joint Conference 2009, pp 3679–3684
6. Iba H (1996) Genetic programming (in Japanese). Tokyo Denkidai Shuppankyoku
8
8.5
9
9.5
10
10.5
1 2 3 4 5 6 7 8
Ave
rage
fit
nes
s
The number of PEs
iGP and tfGP
amGP
Fig. 6. Average fi tness for each number of PEs
number of PEs increases, as shown in Fig. 5. Since the com-putation time of the fi tness calculations depends on the number of nodes in the individuals, this computation time is different for each island. This difference causes the over-head for synchronous migration. This is the reason for the increase in computation time when more than six PEs are used in iGP and tfGP.
In Fig. 4, a tfGP with fi ve PEs and 40 threads can reduce the computation time to about 21% of serial GP. The com-putation time also increases when more than six PEs are used as well as an iGP. This is because synchronous migra-tion produces a large overhead as well as the iGP.
In Fig. 4, an amGP with fi ve PEs and 40 threads can reduce the computation time to about 17% of serial GP. In addition, the computation time of an amGP does not increase even when more than six PEs are used. This is the effect of asynchronous migration on the amGP.
Figure 6 shows the average fi tness for each number of PEs. The fi tness of an individual is calculated by Eq. 1.
FitnessF
Fn
y yi ii
n
=
= −( )=∑
1
1
1
,
. (1)
ˆ