assisting user’s transition to titan’s accelerated architecture
TRANSCRIPT

ORNL is managed by UT-Battelle for the US Department of Energy
Leveraging Leadership Computing Facilities: Assisting User's Transition to Titan's Accelerated Architecture Fernanda Foertter HPC User Assistance Team Oak Ridge Leadership Computing Facility Oak Ridge National Laboratory Workshop on “Directives and Tools for Accelerators: A Seismic Programming Shift” Center for Advanced Computing and Data Systems, University of Houston 20 October 2014

2
Outline
• OLCF Center Overview
• Manycore is here to stay
• The Titan Project: Lessons Learned
• Coding for future architectures

3
OLCF Services
Liasons User Assistance
Viz Tech Ops
Outreach
Oak Ridge Leadership Computing Facility
Everest
Future
Tours
Internships
Tools
Collaboration
Scaling
Performance
Advocacy
Training
Software
Communications

4
Increased our system capability by 10,000X
5
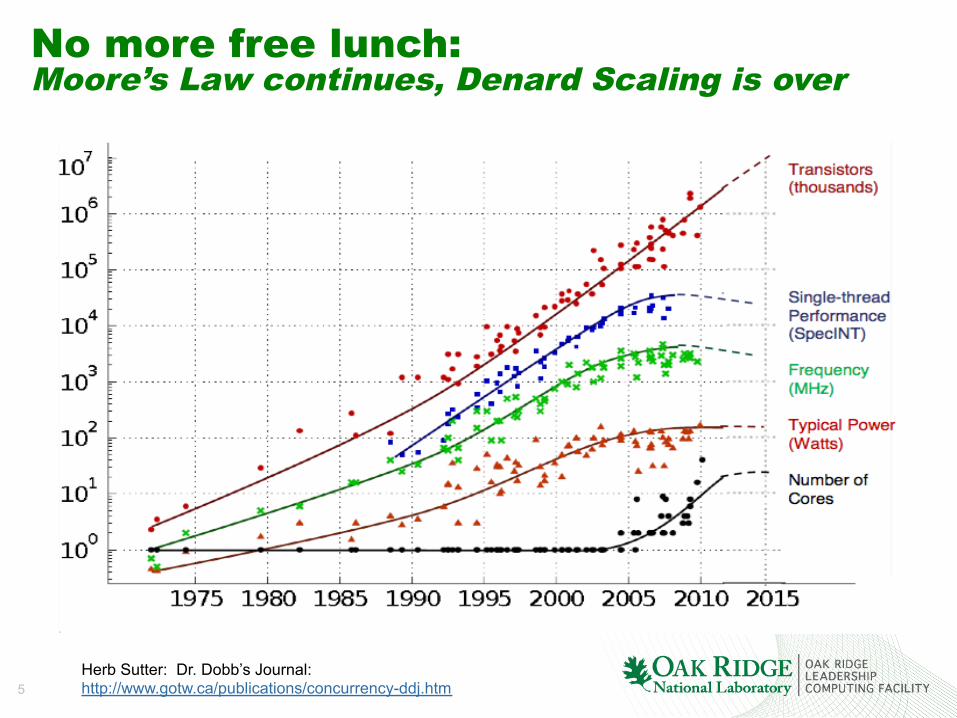
No more free lunch: Moore’s Law continues, Denard Scaling is over
Herb Sutter: Dr. Dobb’s Journal: http://www.gotw.ca/publications/concurrency-ddj.htm

6
Per core performance down, cores up

7
Kogge and Shalf, IEEE CISE
Watts per Sq Cm

8
Manycore Accelerators

9
4,352 ft2
404 m2
SYSTEM SPECIFICATIONS: • Peak performance of 27.1 PF (24.5 & 2.6) • 18,688 Compute Nodes each with: • 16-Core AMD Opteron CPU (32 GB) • NVIDIA Tesla “K20x” GPU (6 GB) • 512 Service and I/O nodes • 200 Cabinets • 710 TB total system memory • Cray Gemini 3D Torus Interconnect
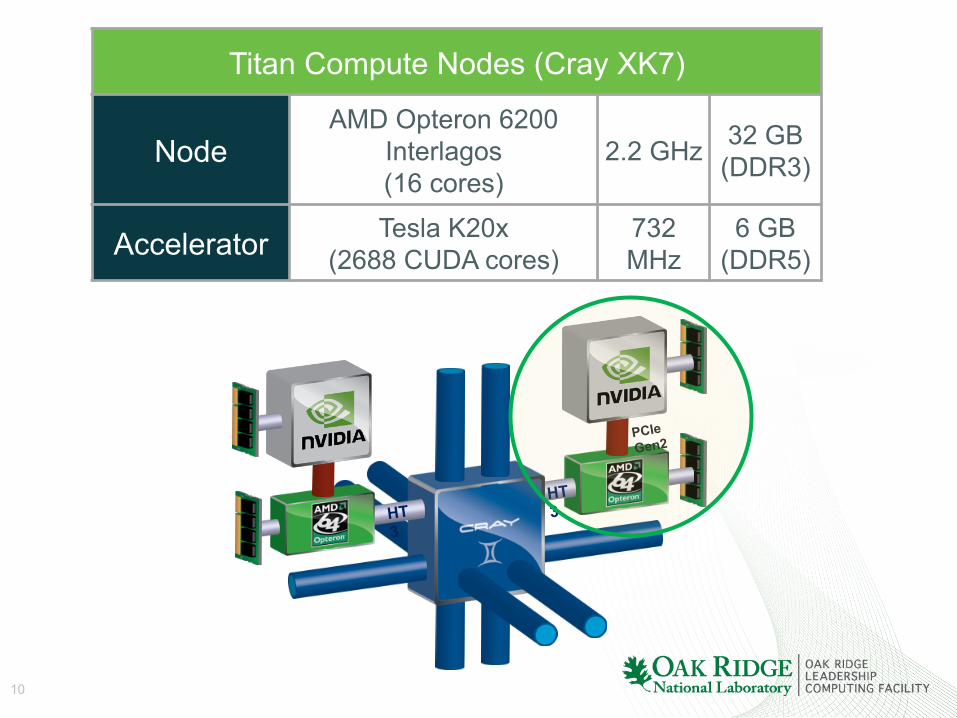
ORNL’s “Titan” Hybrid System: Cray XK7 with AMD Opteron and NVIDIA Tesla processors
10
Titan Compute Nodes (Cray XK7)
Node AMD Opteron 6200
Interlagos (16 cores)
2.2 GHz 32 GB (DDR3)
Accelerator Tesla K20x (2688 CUDA cores)
732 MHz
6 GB (DDR5)
HT3 HT
3
PCIe Gen2
11
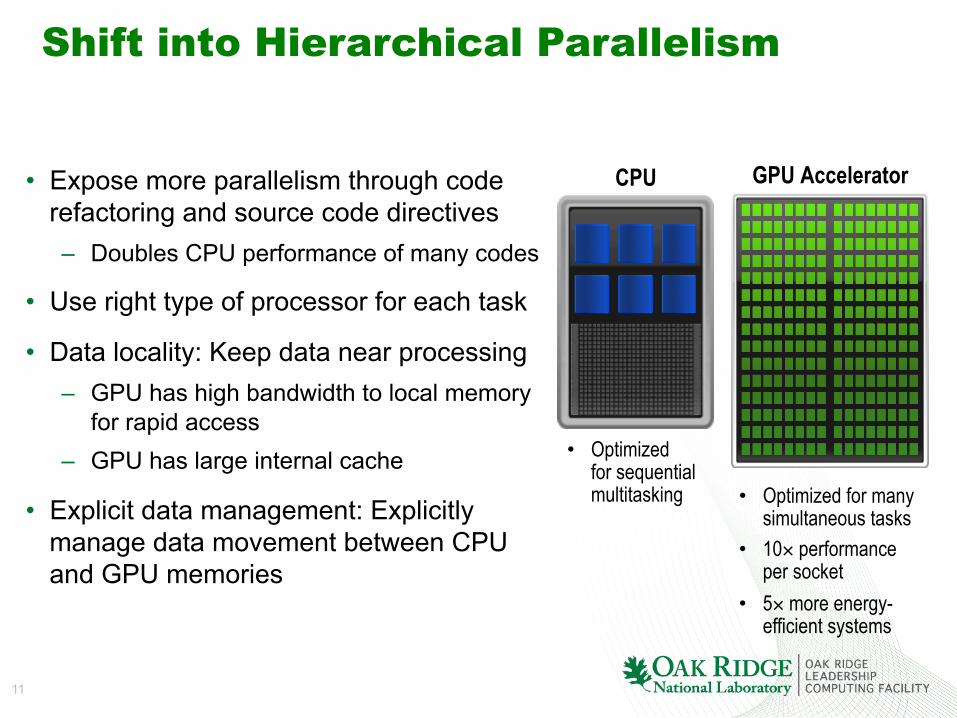
Shift into Hierarchical Parallelism
• Expose more parallelism through code refactoring and source code directives – Doubles CPU performance of many codes
• Use right type of processor for each task
• Data locality: Keep data near processing – GPU has high bandwidth to local memory
for rapid access – GPU has large internal cache
• Explicit data management: Explicitly manage data movement between CPU and GPU memories
CPU GPU Accelerator
• Optimized for sequential multitasking • Optimized for many
simultaneous tasks • 10× performance
per socket • 5× more energy-
efficient systems
12
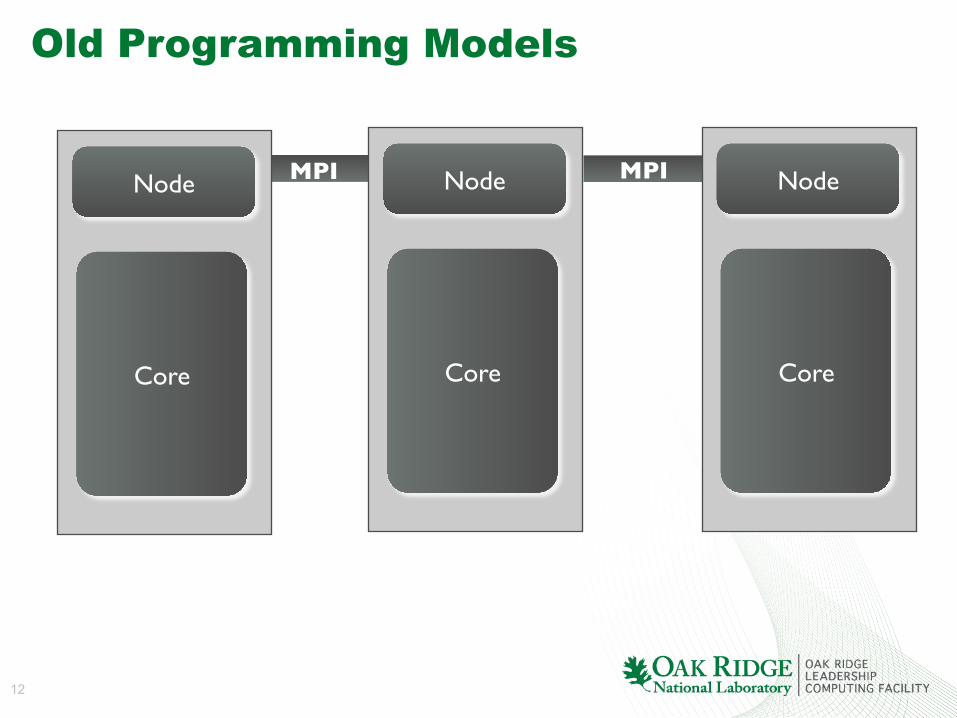
Old Programming Models
Node
Core
MPI MPI Node
Core
Node
Core

13 13
Old Programming Models
Node
MPI
MPI
MPI
Collectives Node
MPI
MPI
MPI
MPI
Node
MPI
MPI
MPI
MPI
Collectives
MPI

14 14
Directive Programming Models
Node
O
penM
P
MPI MPI Node
O
penM
P
Node
O
penM
P

15 15
Hybrid Programming Models
Node
Dir
ectiv
es
Accelerator
Node
Dir
ectiv
es
Accelerator
Node
Dir
ectiv
es
Accelerator
MPI MPI

16 16
Hybrid Programming Models
TORUS
TORUS
TORUS
Node
MPI
Ope
nMP
O
penA
CC
Intr
insi
cs
Accelerator
Accelerator
Node
MPI
Ope
nMP
O
penA
CC
Intr
insi
cs
Accelerator
Accelerator
Node
MPI
Ope
nMP
O
penA
CC
Intr
insi
cs
Accelerator
Accelerator

17
Nod
e 1
Nod
e 18
,688
File System
...
Let’s not forget I/O

18
Path to Exascale
Hierarchical parallelism Improve scalability of applications
Expose more parallelism Code refactoring and source code directives can double
performance
Explicit data management Between CPU and GPU memories
Data locality: Keep data near processing GPU has high bandwidth to local memory and large internal cache
Heterogeneous multicore processor architecture Using right type of processor for each task

19
Applications
Libraries
“Drop-in” Acceleration
Programming Languages
(CUDA, OpenCL)
Maximum Performance
OpenACC OpenMP Directives
Incremental, Enhanced Portability
Programming Hybrid Architectures

20
All Codes Will Need Refactoring To Scale!
• Up to 1-2 person-years required to port each code from Jaguar to Titan
• We estimate possibly 70-80% of developer time was spent in code restructuring, regardless of whether using OpenMP / CUDA / OpenCL / OpenACC / … – Experience shows this is a one-time investment
• Each code team must make its own choice of using OpenMP vs. CUDA vs. OpenCL vs. OpenACC, based on the specific case—may be different conclusion for each code
• Our users and their sponsors must plan for this expense.

21
Center for Accelerated Application Readiness (CAAR)
• Prepare applications for accelerated architectures • Goals:
– Create applications teams to develop and implement strategies for exposing hierarchical parallelism for our users applications
– Maintain code portability across modern architectures – Learn from and share our results
• We selected six applications from across different science domains and algorithmic motifs

22
CAAR: SElected Lessons Learned
• Repeated themes in the code porting work • finding more threadable work for the GPU • Improving memory access patterns • making GPU work (kernel calls) more coarse-grained if possible • making data on the GPU more persistent • overlapping data transfers with other work (leverage HyperQ) • use as much asynchronicity as possible (CPU, GPU, MPI, PCIe-2)

23
CAAR: SElected Lessons Learned
• The difficulty level of the GPU port was in part determined by: • Structure of the algorithms—e.g., available parallelism, high
computational intensity
• Code execution profile—flat or hot spots
• The code size (LOC)

24
CAAR: SElected Lessons Learned
• More available flops on the node should lead us to think of new science opportunities enabled
• We may need to look in unconventional places to get another ~30X thread parallelism that may be needed for exascale—e.g., parallelism in time

25
Co-designing Future Programming Models • Evolutionary vs. Revolutionary approaches:
– Message Passing and PGAS • MPI, UPC, OpenSHMEM, Fortran 2008 CoArrays, Chapel
– Shared Memory Models • OpenMP, Pthreads
– Acceletator-based models • OpenACC, OpenMP 4.0, OpenCL, CUDA
– Hybrid Models • MPI+OpenACC ,MPI + OpenMP 4.0, OpenSHMEM + OpenACC, etc
• New runtime models: Legion, OCR, Express, ParSeC, – Asychronous task based models
• How to efficiently map the model to the hardware while meeting application requirements?

26
• Serve in standard’s committees
• Gather requirements from users
• Translate users’ needs and use cases
Directives collaboration
27
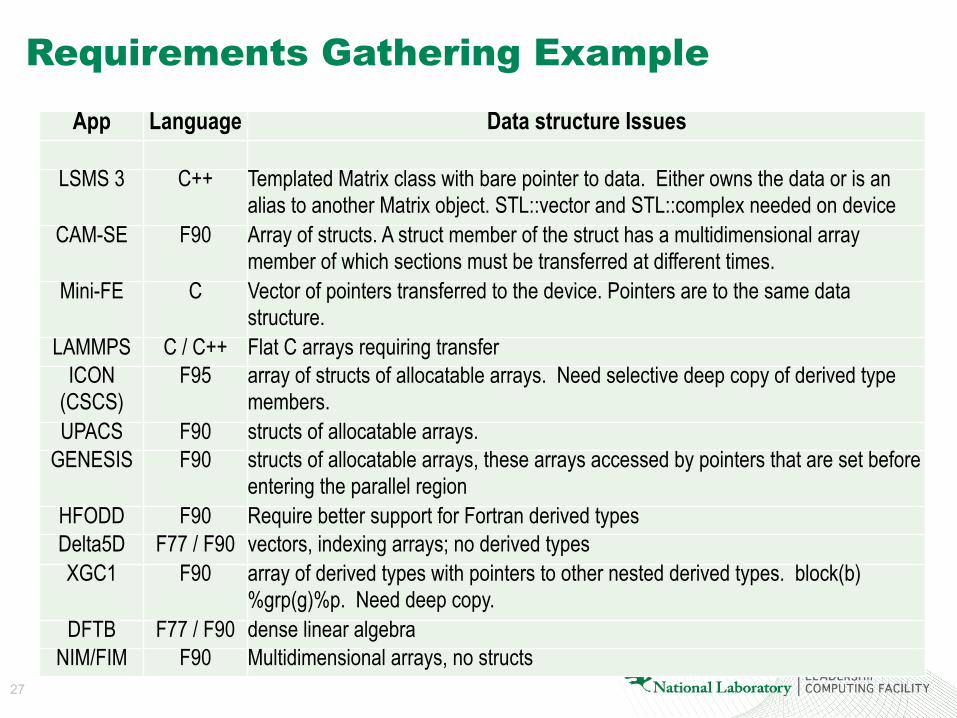
App Language Data structure Issues
LSMS 3 C++ Templated Matrix class with bare pointer to data. Either owns the data or is an alias to another Matrix object. STL::vector and STL::complex needed on device
CAM-SE F90 Array of structs. A struct member of the struct has a multidimensional array member of which sections must be transferred at different times.
Mini-FE C Vector of pointers transferred to the device. Pointers are to the same data structure.
LAMMPS C / C++ Flat C arrays requiring transfer ICON
(CSCS) F95 array of structs of allocatable arrays. Need selective deep copy of derived type
members. UPACS F90 structs of allocatable arrays.
GENESIS F90 structs of allocatable arrays, these arrays accessed by pointers that are set before entering the parallel region
HFODD F90 Require better support for Fortran derived types Delta5D F77 / F90 vectors, indexing arrays; no derived types XGC1 F90 array of derived types with pointers to other nested derived types. block(b)
%grp(g)%p. Need deep copy. DFTB F77 / F90 dense linear algebra
NIM/FIM F90 Multidimensional arrays, no structs
Requirements Gathering Example

28
Challenges with Directive-based programming models
• How to specify the in-node parallelism in the application – Loop based parallelism is not enough for future systems
• How to efficiently map the parallelism of the application to the hardware – How to schedule work to multiple accelerators within the node? – How to schedule work to within accelerators while being portable?
• How to transfer data across different types of memory – Problem may go away but is important for data locality
• How to specify different memory hierarchies in the programming model – Shared memory within GPU, etc
29
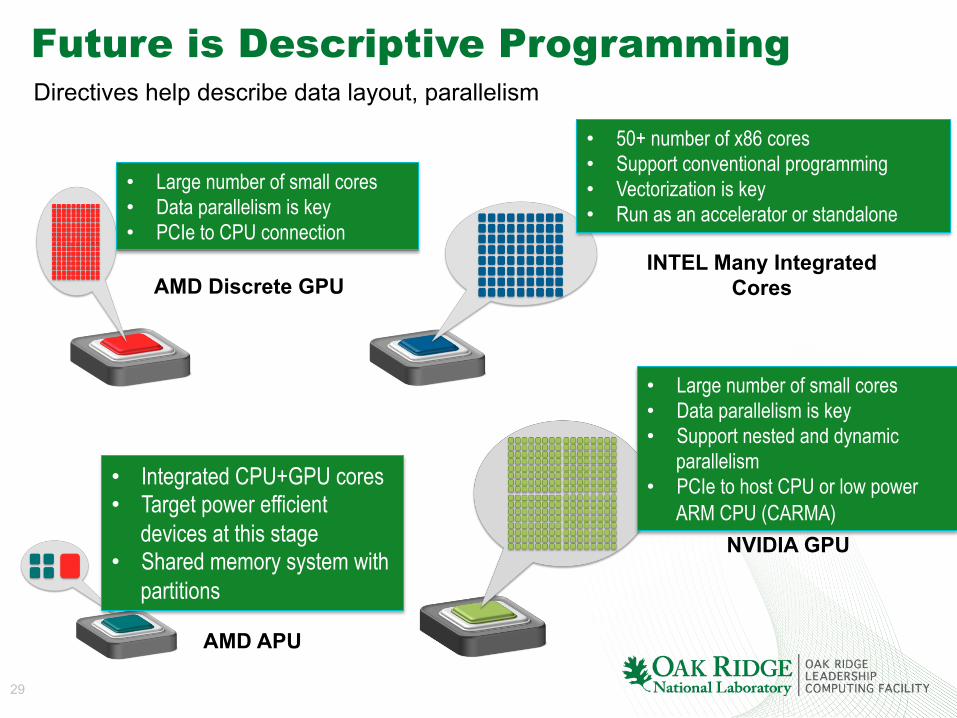
Future is Descriptive Programming
• Large number of small cores • Data parallelism is key • PCIe to CPU connection
AMD Discrete GPU
AMD APU
• Integrated CPU+GPU cores • Target power efficient
devices at this stage • Shared memory system with
partitions
INTEL Many Integrated Cores
• 50+ number of x86 cores • Support conventional programming • Vectorization is key • Run as an accelerator or standalone
NVIDIA GPU
• Large number of small cores • Data parallelism is key • Support nested and dynamic
parallelism • PCIe to host CPU or low power
ARM CPU (CARMA)
Directives help describe data layout, parallelism

30
OpenACC influence à OpenMP
• Compare OpenMP 4.0 accelerator extension with OpenACC – Understand mapping – Understand impact of
newer OpenACC features
• OpenACC is evolving with new features which may impact OpenMP 4.1 or 5.
• OpenACC interoperability with OpenMP is important for the transition
OpenACC 2.0 OpenMP 4.0
parallel target
parallel/gang/workers/vector target teams/parallel/simd
data target data
parallel loop teams/distribute/parallel for
update target update
cache
wait OpenMP 4.1 proposal
declare declare target
data enter/exit OpenMP 4.1 proposal
routine declare target
async wait OpenMP 4.1 proposal
device type
tile
host data

31
Training at OLCF
• Webinars/Remote • Hands on • Lectures • Open to public!!

32
Training at OLCF

33
Conclusions
• There’s no avoiding manycore
• Rethink algorithms to expose more parallelism
• Directives are morphing into Descriptive Programming
• Memory placement is important
• Flops are free, avoid reads/writes
• Standards built from application requirements
• Training events are open to the public
• Looking for domain specific communities

34
Acknowledgements
OpenACC and OpenMP Standards Committees
OLCF-3 CAAR Team:
• Bronson Messer, Wayne Joubert, Mike Brown, Matt Norman, Markus Eisenbach, Ramanan Sankaran
OLCF-3 Vendor Partners: Cray, AMD, NVIDIA, CAPS, Allinea
This research used resources of the Oak Ridge Leadership Computing Facility at the Oak Ridge National Laboratory, which is supported by the Office of Science of the U.S. Department of Energy under Contract No. DE-AC05-00OR22725.

35
Questions? [email protected]
35
Contact us at http://olcf.ornl.gov http://jobs.ornl.gov
@hpcprogrammer