artmosphere demo
TRANSCRIPT

+
Artmosphere Discover the beauty not yet seen
Keira Zhou October, 2015

+ Demo
2
n www.artmosphere.nyc
n http://54.215.136.187:5000
n Video: https://youtu.be/skzZ7sosC8c

+ Data Pipeline
Web API: • JSON files Self-‐Engineered user activity log
Data Source
3

+ Cluster Setup
4
8GB Memory 50GB Storage
8GB Memory 1TB Storage
8GB Memory 1TB Storage
8GB Memory 1TB Storage

+ Dataset
n Artsy.net: n About 26K artworks n About 45K artists n JSON
5

+ Dataset
n Artsy.net: n About 26K artworks n About 45K artists n JSON
n Generated User Log: n Simulated user “collect” activities n Multiplied real user location
6

+ Search Artwork by Title
7
n Raw JSON of 45K artwork n Spark -‐ Elasticsearch

+ Real-‐Time Streaming
8
n Track the trend of each art n Spark Streaming -‐ Cassandra

+ Batch Processing
9
n Artists Location n Similar Artworks n Spark – Cassandra

+ Batch Processing Artists Location
10
n Spark: processed 507GB of data

+ Challenges
n Find the right database for your problem n Elasticsearch for search n Cassandra for time series
n Computers are multilingual –Python, Scala, Java…
n But challenges make life interesting
11

+ About Me
12
n MS & BS in Systems Engineering, University of Virginia n Machine Learning n Natural Language Processing
n High Performance Computing

+ About Me
13
n MS & BS in Systems Engineering, University of Virginia n Machine Learning n Natural Language Processing
n High Performance Computing
n Enjoy n Sketching
n Adventures
n Laughing n Life

+ Backup Slides
14

+ Batch Processing Art Similarity
15
n Artworks are manually tagged n Input format:
n [art1]: [tag1][tag2][tag3]…
n Compute common tags between two artworks
n Spark – Cassandra n Could also use Collaborative Filtering (MLlib in Spark)

+ Benchmark Reads/Writes
16
“Benchmarking Top NoSQL Databases” End Point: http://www.datastax.com/wp-‐content/themes/datastax-‐2014-‐08/files/NoSQL_Benchmarks_EndPoint.pdf
Most Writes Writes/Reads Balanced
n Operations / sec n Cassandra | Couchbase | Hbase | MongoDB

+ Cassandra Time Series
17
time_stamp_1 time_stamp_2 time_stamp_3 …
art_id_1 3 1 2 …
art_id_2 5 3 1 …
art_id_3 1 4 2 …
… … … … … Prim
ary Ke
y (Partit
ion Ke
y)
Primary Key (Clustering Key): with Clustering Order By (Desc)
n Compound Primary Key (art_id, time_stamp) n art_id: Partition key, responsible for data distribution across nodes n time_stamp: Clustering key, responsible for data sorting within the partition
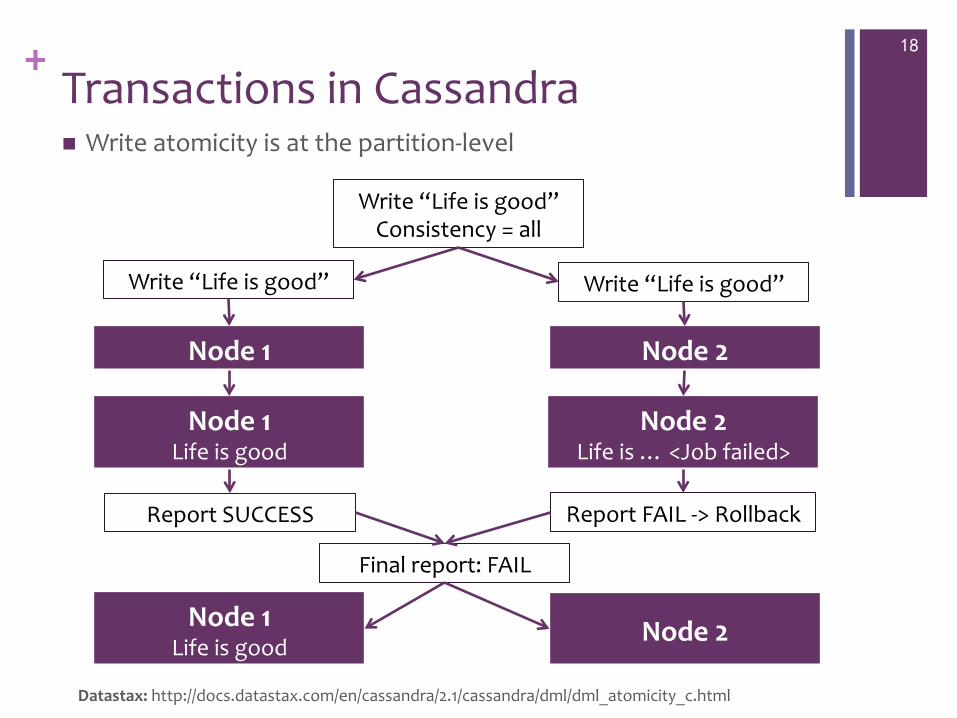
+ Transactions in Cassandra
18
Node 1 Node 2
Write “Life is good” Consistency = all
Write “Life is good” Write “Life is good”
Node 1 Life is good
Node 2 Life is … <Job failed>
Report FAIL -‐> Rollback Report SUCCESS
Final report: FAIL
Node 1 Life is good Node 2
Datastax: http://docs.datastax.com/en/cassandra/2.1/cassandra/dml/dml_atomicity_c.html
n Write atomicity is at the partition-‐level
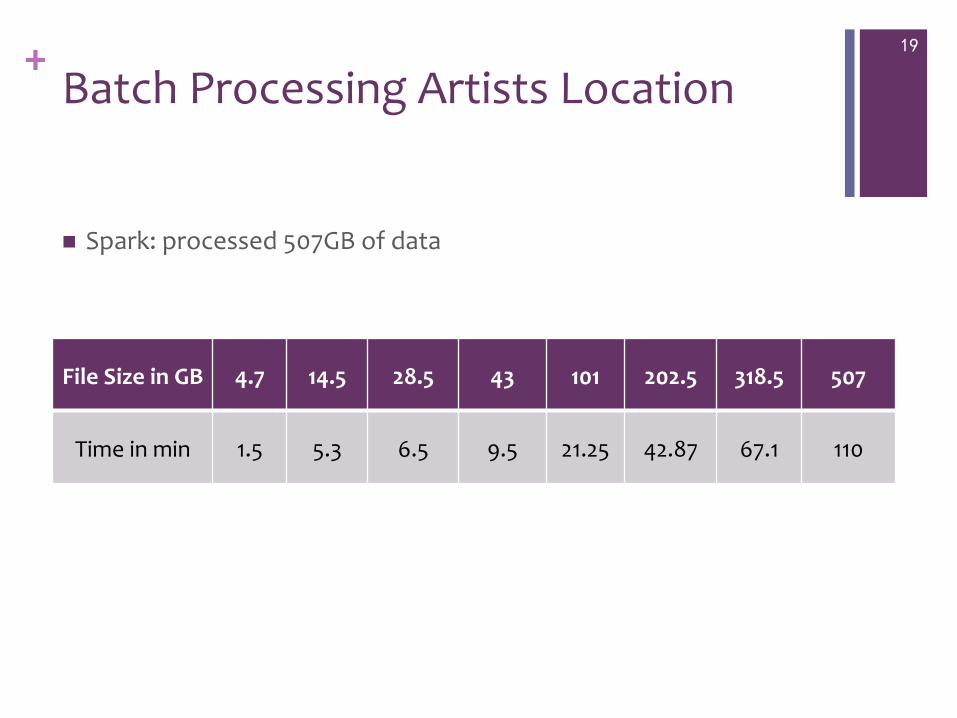
+ Batch Processing Artists Location
19
n Spark: processed 507GB of data
File Size in GB 4.7 14.5 28.5 43 101 202.5 318.5 507
Time in min 1.5 5.3 6.5 9.5 21.25 42.87 67.1 110

+ Spark vs. Hadoop
Spark Hadoop MapReduce
Fault Tolerance
via RDD (they rebuild lost data on failure using lineage: each RDD remembers how it
was built from other datasets to rebuild itself)
via Replication
Cache Data into Memory
Yes No
Support in-‐memory data sharing across directed acyclic graphs (RDD); well-‐suited to machine learning
algorithms
Each job reads data from stable storage (e.g. file
systems)
Write Intermediate Files into Hard
Disk
Yes Yes
while Shuffle while Map reduce
20
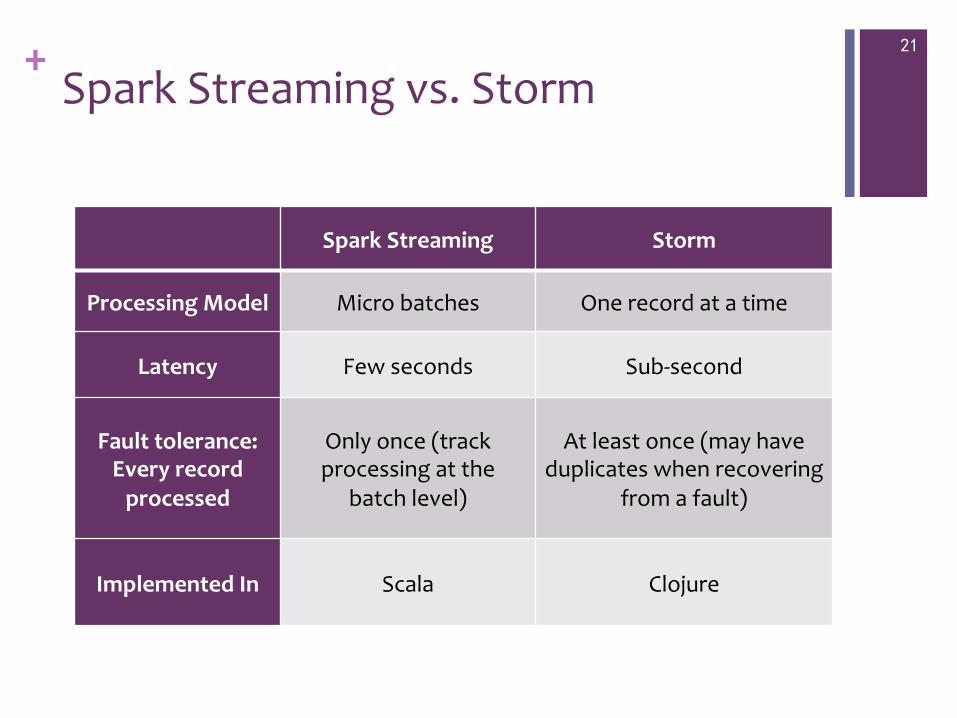
+ Spark Streaming vs. Storm
Spark Streaming Storm
Processing Model Micro batches One record at a time
Latency Few seconds Sub-‐second
Fault tolerance: Every record processed
Only once (track processing at the
batch level)
At least once (may have duplicates when recovering
from a fault)
Implemented In Scala Clojure
21
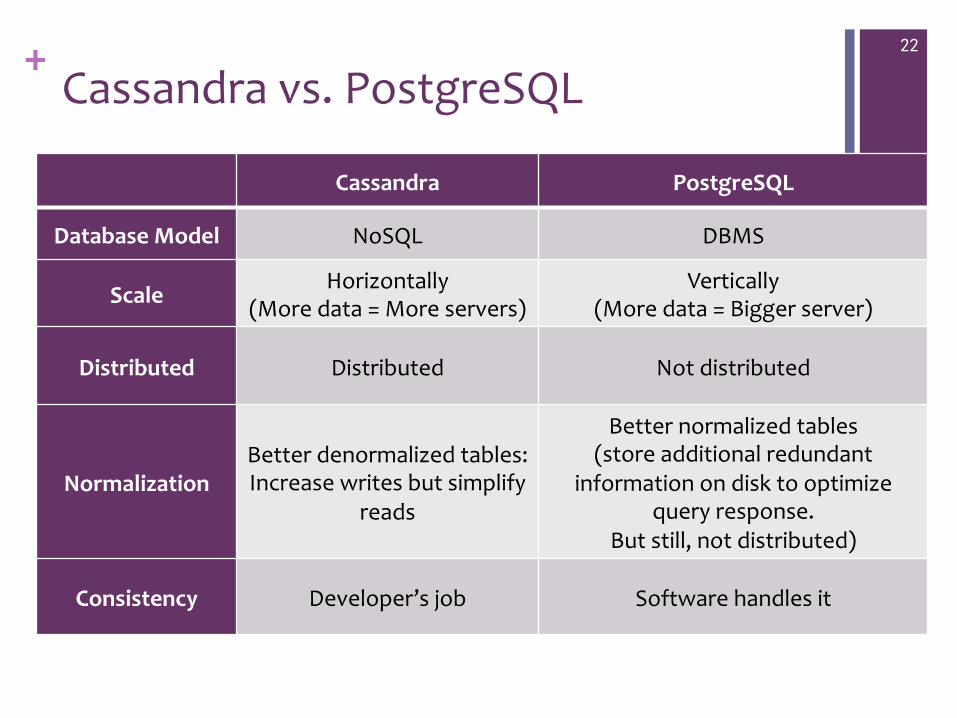
+ Cassandra vs. PostgreSQL
Cassandra PostgreSQL
Database Model NoSQL DBMS
Scale Horizontally (More data = More servers)
Vertically (More data = Bigger server)
Distributed Distributed Not distributed
Normalization Better denormalized tables: Increase writes but simplify
reads
Better normalized tables (store additional redundant
information on disk to optimize query response.
But still, not distributed)
Consistency Developer’s job Software handles it
22

+ Cassandra vs. HBase
Cassandra HBase
Google Bigtable Adopt Google Bigtable
Distributed Yes
Internode communications Integrated Gossip protocol Rely on Zookeeper
Availability Multiple seed nodes
(concentration points for intercluster communication)
Standby master node
Consistency
Richer consistency support: You can configure how many replica nodes must successfully complete the operation before it is acknowledged (You can require all replica nodes)
Strong row-‐level consistency
Query SQL like query hbase> create ‘t1’,
{NAME => ‘f1’}, {NAME => ‘f2’}, {NAME => ‘f3’}
23

+ Elasticsearch vs. Solr
Elasticseach Solr
Lucene Index Both use Lucene index
Distributed Yes Yes but depend on Zookeeper
Nested Object Support complex nested object
Can be implemented as a flat object but hard to update
Change # of Shards No
(hash(doc_id) % #_of_primary_shards)
Yes
Automatic shard rebalancing (after adding new nodes)
Yes No
Faceting Support richer faceting (exclude terms using Regex) Support faceting
24