articles project halo - grenoble inp
TRANSCRIPT

■ Project Halo is a multistaged effort, sponsoredby Vulcan Inc, aimed at creating Digital Aristo-tle, an application that will encompass much ofthe world’s scientific knowledge and be capableof applying sophisticated problem solving toanswer novel questions. Vulcan envisions twoprimary roles for Digital Aristotle: as a tutor toinstruct students in the sciences and as an inter-disciplinary research assistant to help scientistsin their work.
As a first step towards this goal, we have justcompleted a six-month pilot phase designed toassess the state of the art in applied knowledgerepresentation and reasoning (KR&R). Vulcanselected three teams, each of which was to for-mally represent 70 pages from the advancedplacement (AP) chemistry syllabus and deliverknowledge-based systems capable of answeringquestions on that syllabus. The evaluationquantified each system’s coverage of the syl-labus in terms of its ability to answer novel, pre-viously unseen questions and to provide hu-man-readable answer justifications. Thesejustifications will play a critical role in buildinguser trust in the question-answering capabilitiesof Digital Aristotle.
Prior to the final evaluation, a “failure taxono-my” was collaboratively developed in an at-tempt to standardize failure analysis and to fa-cilitate cross-platform comparisons. Despitedifferences in approach, all three systems didvery well on the challenge, achieving perfor-mance comparable to the human median. Theanalysis also provided key insights into how theapproaches might be scaled, while at the sametime suggesting how the cost of producing suchsystems might be reduced. This outcome leaves
us highly optimistic that the technical chal-lenges facing this effort in the years to come canbe identified and overcome.
This article presents the motivation and long-term goals of Project Halo, describes in detailthe six-month first phase of the project—theHalo Pilot—its KR&R challenge, empirical eval-uation, results, and failure analysis. The pilot’soutcome is used to define challenges for thenext phase of the project and beyond.
Aristotle (384–322 BCE) was remarkablefor the depth and scope of his knowl-edge, which included mastery of a wide
range of topics from medicine and philosophyto physics and biology. Aristotle not only hadcommand over a significant portion of theworld’s knowledge, but he was also able to ex-plain this knowledge to others, most famously,though briefly, to Alexander the Great.
Today, the knowledge available to hu-mankind is so extensive that it is not possiblefor a single person to assimilate it all. This isforcing us to become much more specialized,further narrowing our worldview and makinginterdisciplinary collaboration increasinglydifficult. Thus, researchers in one narrow fieldmay be completely unaware of relevantprogress being made in other neighboring dis-ciplines. Even within a single discipline, re-searchers often find themselves drowning innew results. MEDLINE,1 for example, is anarchive of 4,600 medical publications in 30languages, containing over 12 million publica-tions, with 2,000 added daily.
Articles
WINTER 2004 29
Project HaloTowards a Digital Aristotle
Noah S. Friedland, Paul G. Allen, Gavin Matthews, Michael Witbrock, David Baxter, Jon Curtis, Blake Shepard, Pierluigi Miraglia, Jürgen Angele,
Steffen Staab, Eddie Moench, Henrik Oppermann, Dirk Wenke, David Israel,Vinay Chaudhri, Bruce Porter, Ken Barker, James Fan, Shaw Yi Chaw,
Peter Yeh, Dan Tecuci, and Peter Clark
Copyright © 2004, American Association for Artificial Intelligence. All rights reserved. 0738-4602-2002 / $2.00

knowledge that will form the foundation forDigital Aristotle.
The Halo PilotThe pilot phase of Project Halo was a six-month effort to set the stage for a long-term re-search and development effort aimed at creat-ing Digital Aristotle. The primary objective wasto evaluate the state of the art in applied KR&Rsystems. Understanding the performance char-acteristics of these technologies was consideredto be especially critical to DA, as they are ex-pected to form the basis of its reasoning capa-bilities. The first objectives were to identify andengage leaders in the field and to develop suit-able evaluation methodologies; the project wasalso designed to help in the determination of aresearch and development roadmap for KR&Rsystems. Finally, the project adopted principlesof scientific transparency aimed at producingunderstandable, reproducible results.
Vulcan undertook a formal bidding processto identify teams to participate in the pilot.Criteria for selection included a well-estab-lished and mature technology and a world-class team with a track record of governmentand private funding. Three teams were con-tracted to participate in the evaluation: a teamled by SRI International with substantial con-tributions from Boeing Phantom Works andthe University of Texas at Austin; a team fromCycorp; and a team from Ontoprise.
Significant attention was given to selecting aproper domain for the evaluation. It was im-portant, given the limited scope of this phaseof the project, to adapt an existing, well knownevaluation methodology with easily under-stood and objective standards. First a decisionwas made to focus on a “hard” science and,more specifically, on a textbook presentation ofsome part of that science. Several standardizedtest formats were also examined. In the end, a70-page subset of introductory college-level ad-vanced placement (AP) chemistry was selectedbecause it was reasonably self-contained anddid not require solutions to other hard AI prob-lems, such as representing and reasoning withuncertainty, or understanding diagrams(Brown, LeMay, and Bursten 2003). This latterconsideration, for example, argued against se-lecting physics as a domain.
Table 1 lists the topics in the chemistry syl-labus. Topics included stoichiometry calcula-tions with chemical formulas; aqueous reac-tions and solution stoichiometry; andchemical equilibrium. Background materialwas also identified to make the selected chap-ters more fully self-contained.2
This scope was large enough to support a
Making the full range of scientific knowl-edge accessible and intelligible might involveanything from simply retrieving facts to an-swering a complex set of interdependent ques-tions and providing appropriate justificationsfor those answers. Retrieval of simple factsmight be achieved by information-extractionsystems searching and extracting informationfrom a large corpus of text, such as Voorheese(2003). But aside from the simplicity of thetypes of questions such advanced retrieval sys-tems are designed to answer, they are only ca-pable of retrieving “answers”—and justifica-tions for those answers—that already exist inthe corpus. Knowledge-based question–an-swering systems, by contrast, though generallymore computationally intense, are capable ofgenerating answers and appropriate justifica-tions and explanations that are not found intexts. This capability may be the only way tobridge some interdisciplinary gaps where littleor no documentation currently exists.
Project Halo is a multistaged effort aimed atcreating Digital Aristotle (DA), an applicationencompassing much of the world’s scientificknowledge and capable of answering novelquestions through advanced problem solving.DA will act both as a tutor capable of instruct-ing students in the sciences and as a researchassistant with broad interdisciplinary skills,able to help scientists in their work. The finalDA will differ from classical expert systems infour important ways.
First, in speed and ease of knowledge formu-lation. Classical expert systems required yearsto perfect and highly skilled knowledge engi-neers to craft them; Digital Aristotle will pro-vide tools to facilitate rapid knowledge formu-lation by domain experts with little or no helpfrom knowledge engineers.
Second, in coverage. Classical expert systemswere narrowly focused on the single topic forwhich they were specifically designed; DA willover time encompass much of the world’s sci-entific knowledge.
Third, in reasoning techniques. Classical ex-pert systems mostly employed a single infer-ence technology; DA will employ multipletechnologies and problem solving methods.
Fourth, in explanations. Classical expert sys-tems produced explanations derived directlyfrom inference proof trees; DA will produceconcise explanations, appropriate to the do-main and the user’s level of expertise.
Adoption by communities of subject matterexperts of the Project Halo tools and method-ologies is critical to the success of DA. Thesetools will empower scientists and educators tobuild the peer-reviewed, machine-processable
Articles
30 AI MAGAZINE

large variety of novel, and hence unanticipat-ed, question types. One analysis of the syllabusidentified nearly 100 distinct chemistry laws,suggesting that it was rich enough to requirecomplex inference. It was also small enough tobe represented relatively quickly—which wasessential because the three Halo teams were al-located only four months to create formal en-codings of the chemistry syllabus. This amountof time was deemed sufficient to construct de-tailed solutions that leveraged the existingtechnologies, yet was too brief to allow signifi-cant revisions to the teams’ platforms. Hence,by design, we were able to avoid undue cus-tomization to the task domain and thus to cre-ate a true evaluation of the state of the art ofKR&R technologies.
Nevertheless, at the outset of the project itwas completely unclear whether competentsystems could be built. In fact, Vulcan’s secretintent was to set such a high bar for success thatthe experiment would expose the weaknessesin KR&R technologies and determine whetherthese technologies could form the foundationof DA. The teams accepted the challenge withtrepidation caused by several factors, includingthe mystery of working in a new domain withthe novel performance task of answering hard,and highly varied, advanced placement ques-tions; and generating coherent explanations inEnglish—all within four months.
The TechnologyThe three teams had to address the same set ofissues: knowledge formation, question answer-ing, and explanation generation (Barker et al.2004; Angele et al. 2003; and Witbrock andMatthews 2003.) They all built knowledgebases in a formal language and relied onknowledge engineers to encode the requisiteknowledge. Furthermore, all the teams used au-tomated deductive inference to answer ques-tions. Despite these high-level similarities, theteams’ approaches differed in some interestingways, especially with respect to explanationgeneration.
Knowledge FormationEach system achieved significant coverage ofthe parts of the domain represented by the syl-labus and was able to use that coverage to an-swer substantial numbers of novel questions.All three systems used class taxonomies, suchas the one illustrated in figure 1, to organizeconcepts such as acids, physical constants, andreactions; represented properties of classes us-ing relations; and used rules to represent com-plex relationships.
Domain-Driven Versus Question-Driven Knowledge FormationRecall that Vulcan released a course descriptionconsisting of 70 pages of a chemistry textbookand 50 sample questions. The teams had thechoice of building knowledge bases either start-ing from the syllabus text or from the samplequestions or working from both in parallel.Ontoprise and Cycorp approached knowledgeformation in a target-text-driven approach,and SRI approached knowledge formation in aquestion-driven approach.
The Ontoprise team encoded knowledge inthree phases. During the first phase team mem-bers encoded the knowledge within the corpusinto the ontology and rules without consider-ing any sample test questions. They then testedthis knowledge on test questions that appearedin the textbook—which were different fromthe sample set released by Vulcan. In the sec-ond phase, they tested the sample questions re-leased by Vulcan. The initial coverage they ob-served was around 30 percent. During thisphase, they refined the knowledge base untilcoverage of around 70 percent was reached. Inthe second phase, they also coded the explana-tion rules. In the third phase, they refined theencoding of the knowledge base and the expla-nation rules.
Cycorp used a hybrid approach by first con-centrating on representing the basic conceptsand principles of the corpus and graduallyshifting over to a question-driven approach.The intent behind this approach was to avoidoverfitting the knowledge to the specifics ofthe sample questions available. This strategymet with mixed success: in the second phase,considerable reengineering of the knowledgewas required to meet the requirements of thequestions without compromising the strategy’sgenerality. This was partly because the text-book adopted an example-based approach withsomewhat varied depth, whereas the process ofknowledge formation would have benefitedfrom a more systematic and uniform coverage.
The SRI team’s approach for knowledge for-mation was highly question-driven. Startingfrom the 50 sample questions, team membersworked backwards to identify what pieces ofknowledge would be needed to solve them. In-
Articles
WINTER 2004 31
Subject Chapters Sections PagesStoichiometry: Calculationswith Chemical Formulas
3 3.1 – 3.2 75 - 83
Aqueous Reactions and SolutionStoichiometry
4 4.1 – 4.4 113 - 133
Chemical Equilibrium 16 16.1 – 16.11 613 - 653
Table 1. Course Outline for the Halo Challenge.

building a library of representations of genericentities, events, and roles (Barker, Porter, andClark 2001) and they were able to reuse parts ofthis for the Project Halo pilot. In addition toproviding the types of information commonlyfound in ontologies (class-subclass relationsand instance-level predicates), their representa-tions include sets of axioms for reasoningabout instances of these classes. The portion ofthe ontology dealing with properties and val-ues was especially useful for the Halo pilot. Itincludes representations for numerous dimen-sions (for example, capacity, density, duration,frequency, quantity) and values of three types:scalars, cardinals, and categoricals. This ontol-ogy also includes methods for convertingamong units of measurement (Novak 1995),which the SRI team’s system used to align therepresentation of questions with representa-tions of terms and laws, even if they are ex-pressed with different units of measurement.
Cycorp publishes an open-source version ofCyc3 that was used as a platform for the Open-Halo system. Cyc’s knowledge consists of
terestingly, the initial set of questions wasfound to require coverage of a substantial por-tion of the syllabus. Once the coverage for thesample set of questions was achieved, theylooked for additional sample questions fromthe available AP tests. Working with this addi-tional set of sample questions, they ensuredthe robustness of their initial coverage.
Reliance on Domain-Independent OntologiesBoth Cycorp and SRI relied on their preexistingknowledge base content. Ontoprise startedfrom scratch. Not surprisingly, the top-levelclasses in the Ontoprise knowledge base arechemistry concepts such as elements, mixtures,and reactions. Interestingly, the Ontopriseknowledge base did not draw on well-knownontological distinctions such as object typeversus stuff type. We describe here in more de-tail how SRI and Cycorp leveraged their priorknowledge base and the issues that arose in do-ing so.
For several years the SRI team has been
Articles
32 AI MAGAZINE
#$ChemicalSubstanceType
#$AcidType-Negligible
#$BaseType-Negligible
#$genis
#$AcidType-Lewis
#$AcidType-Bronsted-Lowry
#$AcidType-Arhenius
#$AcidType-Strong
#$AcidType-Monoprotic
#$AcidType-Polyprotic
#$AcidType-Diprotic
#$BaseType-Bronsted-Lowry
#$BaseType-Arrhenius
$#BaseType-Strong
#$BaseType-Weak#$AcidType-Weak
#$AmphotericSubstanceType
#$BaseType-Lewis
Figure 1. Extract from Cyc’s Ontology of Acids and Bases.These nodes represent second-order collections for organizing specific substance types; edges represent subsuption relationships.

terms, relations, and assertions. The assertionsare organized into a hierarchy of microtheoriesthat permit the isolation of specific assump-tions into a specific context. OpenHalo utilizedOpenCyc’s 6,000 concepts but was augmentedfor Project Halo with 1,000 new concepts and8,000 existing concepts selected from the fullCyc knowledge base. A significant fraction ofthe latter formed part of the compositionalexplanation-generation system.
Reliance on Domain ExpertsCycorp and Ontoprise relied on their knowl-edge engineers to do all the knowledge forma-tion, while SRI relied on a combined team ofknowledge engineers and chemistry domainexperts.
Team SRI used four chemists to help with theknowledge formation process, which was donein the following steps. First, ontological engi-neers designed representations for chemistrycontent, including the basic structure for termsand laws, chemical equations, reactions, andsolutions. Second, chemists consolidated thedomain knowledge into a 35-page compendi-um of terms and laws summarizing the rele-vant material from 70 pages of a textbook.While doing this, the chemists were asked tostart from the premise to be proven and tracethe reasoning in a backward-chaining mannerto make it easy for knowledge engineers to en-code this in the knowledge base. Third, knowl-edge engineers implemented that knowledgein the KM frame language, creating representa-tions of about 150 laws and 65 terms. Whiledoing so, they compiled a large suite of test cas-es for individual terms and laws as well as com-binations of them. This test suite was run daily.Fourth, the “explanation engineer” augmentedthe representation of terms and laws to gener-ate English explanations. Finally, the domainexperts reviewed the output of the system forcorrectness and understandability.
Ontoprise knowledge engineers learned thedomain and built the knowledge base—mostlystarting with understanding and modeling theexamples given in the textbook. They com-piled a set of 41 domain concepts, 582 domaininstances, 47 domain relations, and 345 ax-ioms used for answering the questions. In addi-tion, they added 138 rules in order to provideexplanations for the answers produced.
Explanation GenerationThe three teams took quite different approach-es to explanation generation. These differenceswere based on the teams’ available technolo-gies (recall that the project allowed little timeto develop new technologies), their longer-
term goals, and their instincts of what mightwork.
The Ontoprise System. OntoNova, the Onto-prise system, was based on the representationlanguage F(rame)-Logic (Kifer, Lausen, and Wu1995) and the logic programming-based infer-encing system OntoBroker (Angele et al. 2003).For answer justification, OntoNova usedmetainferencing, as follows. While processinga query OntoBroker produced a log file of theproof tree for any given answer. This proof tree,which was represented in F-Logic and con-tained the instantiated rules that were success-fully applied to derive an answer, acted as in-put for a second inference run to produceEnglish answer justifications.
We illustrate this approach with a samplequestion. The question asks for the Ka value ofa substance, given its quantity in moles and itspH. The following is an extract from the log fileof the proof tree:
a15106:Instantiation[ofRule->>kavalueMPhKa;instantiatedVars->>{i(M,0.2),i(PH,3.0),…].
This log file extract states that the rule kaval-ueMPhKa was applied at the point in timelogged here. Then, the variables M and PH wereinstantiated by 0.2 and 3.0 respectively. Rulesimportant for justifying results, for example“kavalueMPhKa,” were applied in the second,meta-inference run. Explanation rules werespecified by their reference to an inference ruleused to derive the answer, the instantiations ofthe variables of that rule, and a human-au-thored explanation template referring to thosevariables. These explanation rules resembledthe explanation templates of the SRI system.The corresponding explanation rule for kaval-ueMPhKa was:
FORALL I,M1,PH1 explain(EX1,I) <-I:Instantiation[ofRule->>kavalueMPhKa; instantiatedVars->>{i(M,M1),i(PH,PH1)}] andEX1 is (“The equation for calculating the acid-dissociation.”).
These explanation rules were applied to theproof tree for the example to produce the fol-lowing justification output:
The equation for calculating the acid-dissocia-tion constant Ka for monoprotic acids isKa=[H+][A-]/[HA]. For monoprotic acids theconcentrations for hydrogen [H+] and for theanion [A-] are the same: [H+]=[A-]. Thus, we getKa= 0.0010 * 0.0010 / 0.2 = 5.0E-6 for a solu-tion concentration [HA] = 0.2 M.
The equation for calculating the pH-valueis ph=-log[H+]. Thus we get the pH-value,ph = 3, H+ concentration [H+] = 0.0010.
This two-step process for creating explanationsallowed the application of OntoBroker to gen-erate explanations. For OntoNova, the Onto-
Articles
WINTER 2004 33

and displayed, followed by the nested explana-tion of dependent facts, followed by the exittext. The explanation generated for the compu-tation of concentration of ions in NaOH is asfollows:
If a solute is a strong electrolyte, the concen-tration of ions is maximalChecking the electrolyte status of NaOH.
Strong acids and bases are strong elec-trolytes.
NaOH is a strong base and is therefore astrong electrolyte.
NaOH is thus a strong electrolyte. The concentration of ions in NaOH is 1.00molar.
A more complete description of team SRI’s sys-tem can be found in Barker et al. (2004).
The Cycorp System. All the systems generatedtheir explanations by appropriate filtering andtransformation of the inference proof tree. Theprimary difference in Cycorp’s approach wasthat Cyc was already capable of providing nat-ural language explanations for any detail, how-ever minor, whereas the other systems requiredthe addition of template responses for eachrule and fact deemed important. The result ofthis was that much of the effort expended onexplanations by Cycorp concerned judiciousstrengthening of the filters, and Cyc’s outputconsequently erred on the side of verbosity.Moreover, Cyc’s English, being built up compo-sitionally by automatic techniques rather thanbeing handcrafted for a specific project, ex-hibits a certain clumsiness of expression.
A specific example of where Cyc had a lot oftrouble generating readable explanations waswhen the use of a mathematical equation re-quired a lot of arithmetic. While a step-by-stepexposition of every mathematical step in-volved is technically correct, it makes mostreaders recoil in horror. Cyc’s lower scores forexplanations may therefore be ascribed not toany errors contained within, nor to the com-plete absence of an explanation, but to the factthat the key chemistry principles involvedtended to be buried amid more trivial reason-ing. In the Halo pilot challenge, the graders ap-peared to value conciseness of expression overeither correctness or completeness.
In the Halo pilot challenge, Cyc producedexplanations for every question it answeredcorrectly, and it was rare for any of the gradersto find any fault with the explanations’ correct-ness. Comments like “calculations are correctbut once again buried” and “not well focused”were common. It was clear at the end of the pi-lot phase that Cyc required significant work inexplanation filtering; substantial progress hasbeen made during subsequent projects.
prise team developed an entire knowledge basefor this purpose. Running short of time, theycould not fully exploit the flexibility of this ap-proach and thus mostly restricted it to an ap-proach similar to template matching. In the fu-ture, however, they plan to apply additionalinference rules to (1) integrate additionalknowledge, (2) reduce redundancies of expla-nations, (3) abstract from fine-grained explana-tions, and (4) provide personalized explana-tions.
Team SRI’s System. Team SRI’s system wasbased on KM, a frame language with some sim-ilarities to KRL and KL-ONE systems.4 Duringreasoning, KM records which rules are used inthe derivation of ground facts. These proof treefragments could be presented as an “explana-tion” of the derivation of a fact. Experiencewith expert systems, however, has taught usthat proof trees and inference traces are notcomprehensible explanations for most users.
To provide better explanations, KM allowsthe knowledge engineer to supply explanationtemplates for each knowledge base rule. Theseexplanation templates provide control overwhich proof tree fragments are presented inthe explanation and what English text is usedto describe them. In particular, the knowledgeengineer specifies what text to display when arule is invoked (“entry text”), what text is dis-played when the rule has been successfully ap-plied (“exit text”), and a list of any other factsthat should be explained in support of the cur-rent rule (dependent facts). The three parts ofthe explanation template can contain arbitraryKM expressions, allowing the knowledge engi-neer considerable control over explanationgeneration.
Consider the law for computing the concen-tration of ions in a chemical solution, shownin figure 2. When the explanation of a rule ap-plication is requested, the entry text is formed
Articles
34 AI MAGAZINE
ComputeConcentrationOfIons(C) if C is a strong electrolyte
return(Max) [expl-tag-1] else
… [expl-tag-2]
[expl-tag-1] entry: "If a solute is a strong electrolyte, the
concentration of ions is maximal" exit: "The concentration of ions in" C "is" Max dependencies: electrolyte-status(C)
Figure 2. The Law for Computing the Concentration of Ions in a Chemical.

EvaluationAt the end of four months, knowledge formu-lation was stopped, even though the teams hadnot completed the task. All three systems weresequestered on identical servers at Vulcan.Then the challenge exam, consisting of 100novel AP-style English questions, was releasedto the teams. The exam consisted of three sec-tions: 50 multiple choice questions and twosets of 25 multipart questions—the detailed an-swer and free-form sections. The detailed an-swer section consisted mainly of quantitativequestions requiring a “fill in the blank” (withexplanation) or short essay response. The free-form section consisted of qualitative, compre-hension questions, which exercised additionalreasoning tasks such as metareasoning, and re-lied more, if only in a limited way, on com-monsense knowledge and reasoning.
Due to the limited scope of the pilot, therewas no requirement that questions be input intheir original, natural language form. Thus,two weeks were allocated to the teams for thetranslation of the exam questions into their re-spective formal languages. Upon completion ofthe encoding effort, the formal question en-codings of each team were evaluated by a pro-gramwide committee to guarantee high fidelityto the original English. The criterion of fidelitywas as follows:
Assume that a student was fluent in both Eng-lish and the formal language in question. If sheis able to infer additional facts from the formalencodings either through omission of detail orbecause new material details were provided thatwere not available in the English description ofthe question, then a fidelity violation had oc-curred.
Once the encodings were evaluated, Vulcanpersonnel submitted them to the sequesteredsystems. The evaluations ran in batch mode.The Ontoprise system completed its processingin 2 hours, the SRI system in 5 hours and theCycorp system in a little over 12 hours. Each ofthe three systems produced an output file in ac-cordance with a predefined specification. Foreach question, the format required the specifi-cation of the question number; the full Englishtext of the question; a clear answer, either inprose or letter form for multiple choice ques-tions; and an explanation of how the answerwas derived—even for multiple choice ques-tions. See the sidebar “Examples of SystemOutputs and Grader Comments” for more de-tails.
Vulcan engaged three chemistry professorsto evaluate the exams. Adopting an AP-styleevaluation methodology, they graded eachquestion for both correctness and the quality
of the explanation. The exam encompassed168 distinct gradable components consisting ofquestions and question subparts. Each of thesereceived marks, ranging from 0 to 1 point eachfor correctness and separately for explanationquality, for a maximum high score of 336. Allthree experts graded all three exams. The scor-ing of all three chemistry experts was aggregat-ed for a maximum high score of 1008.
Empirical Results Vulcan was able to run all of the applicationsduring the challenge despite minor problemsassociated with each of the three systems.5 Re-sults were compiled for the three exam sectionsseparately and then aggregated to form the to-tal scores. Despite significant differences in ap-proach, all three systems performed remark-ably well, above 40 percent for correctness formost of the graders—a score comparable to anAP-3 (out of 5)—close to the mean humanscore of AP-2.82!
The multiple choice (MC) section consistedof 50 questions, MC1 through MC50. Each ofthese questions featured five choices, lettered“a” through “e.” The evaluation required bothan answer and a justification for full credit,even for MC questions. Figure 3 provides an ex-ample of one of the multiple choice questions,MC3.
Figure 4 depicts the correctness (on the left)and answer-justification (on the right) scoresfor the multiple choice section as a percentageof the 50-point maximum. The Cycorp, Onto-prise, and SRI scores are depicted by the differ-ent gray bars. Bars are grouped by the gradingchemistry professors, SME1 through SME3,where SME stands for subject matter expert. SRIand Ontoprise both scored about 70 percentcorrect in this section, while Cycorp scoredslightly above 50 percent. Cycorp applied ametareasoning technique to evaluate multiplechoice questions. First, Cycorp’s OpenHalo at-tempted to find a correct answer among the
Articles
WINTER 2004 35
Sodium azide is used in air bags to rapidly producegas to inflate the bag. The products of the decompositionreaction are:
(a) Na and water;(b) Ammonia and sodium metal;(c) N2 and O2;(d) Sodium and nitrogen gas;(e) Sodium oxide and nitrogen gas.
Figure 3. An Example of a Multiple Choice Section Question, MC3.

siderably lower than the correctness scores.Note that these two measurements were not in-dependent. Systems that were unable to pro-duce an answer did not produce a justification,and systems that produced incorrect answerswere rarely able to produce convincing answerjustifications. The answer justification scoreswere also far less uniform than the correctnessscores,6 with the scoring for SRI appearing to bethe most consistent across the three evaluators.All the evaluators found the SRI justificationsto be the best, while the Cycorp generative-English was the least comprehensible to thesubject matter experts.
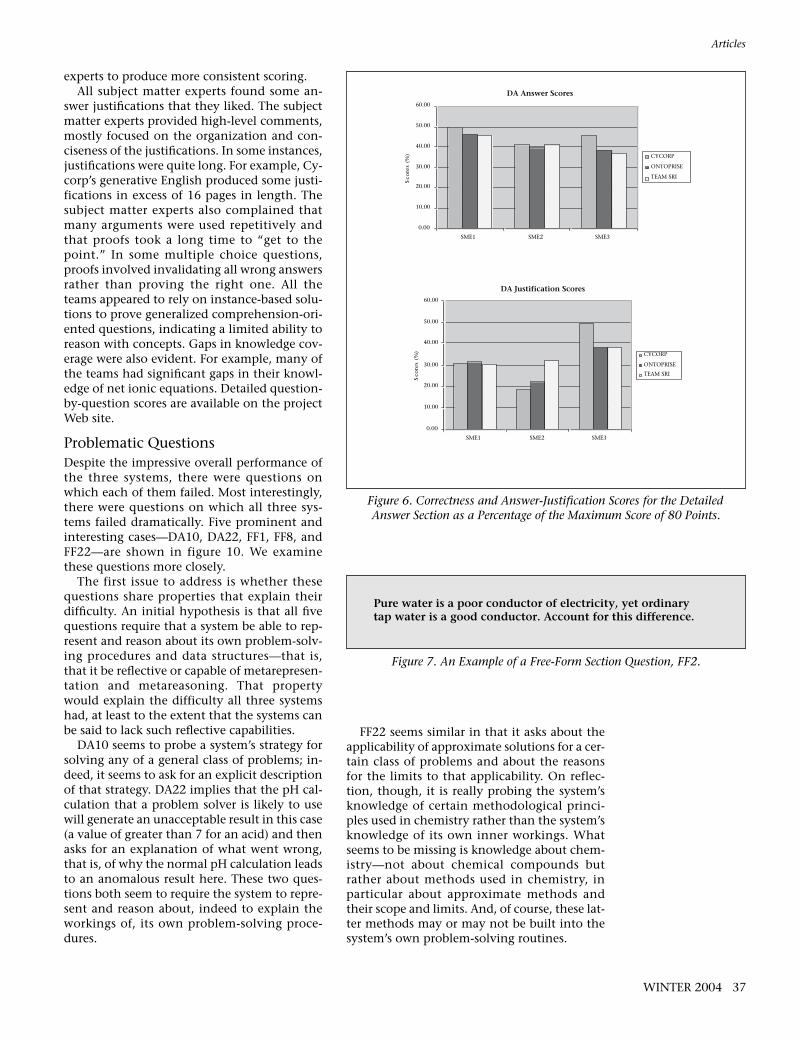
The detailed answer (DA) section had 25multipart essay questions, DA1–DA25, repre-senting a total of 80 gradable answer compo-nents. Figure 5 depicts an example of a DA sec-tion question, DA1. Figure 6 depicts thecorrectness and answer-justification scores forthe DA section. The correctness assessmentshows a slight advantage to the Cycorp systemin this section. OpenHalo may have fared bet-ter here because it was not penalized by itsmultiple choice strategy in this section.
The free-form (FF) section also had 25 multi-part essay questions, FF1–FF25, representing 38gradable answer components. Figure 7 depictsan example of a FF question, FF2. Figure 8shows the correctness and answer-justificationscores for the FF section. This section was de-signed to include questions that were some-what beyond the scope of the defined syllabus.Some required metareasoning and, in somecases, limited commonsense knowledge. Theobjective was to see how well the systems per-formed faced with such challenges andwhether the additional knowledge constructsavailable to SRI and Cycorp would translate in-to better results. The outcome of this sectionshowed a marked advantage to the SRI system,both for correctness and for justification. Wewere surprised that the Cycorp system did notdo better, given its many thousands of con-cepts and relations and the rich expressivity ofCycL. This result may reflect the inability oftheir knowledge engineering team to leverageknowledge in Cyc for this particular challenge.
Figure 9 provides the total challenge results,as percentages of the 168-point maximumscores, for answer correctness and justifica-tions. The correctness scores show a similartrend for the three subject matter experts, withteam SRI slightly outperforming Ontoprise andOntoprise slightly outperforming Cycorp. Bycontrast, the justification scores display a sig-nificant amount of variability. We are consider-ing changes in our methodology to address thisissue, including training future subject matter
five. If it failed to do so, it would attempt to de-termine which of the five options were prov-ably wrong. This led to some questions return-ing more than one letter answer, none ofwhich received credit from the subject matterexperts. In contrast, the other two teams hard-coded the approach to be used—direct proofversus elimination of obvious wrong an-swers—and appeared to fare better.
The answer-justification scores were all con-
Articles
36 AI MAGAZINE
MC Answer Scores
0.00
10.00
20.00
30.00
40.00
50.00
60.00
70.00
80.00
SME1 SME2 SME3
ocS
r(se
)% CYCORP
ONTOPRISE
TEAM SRI
MC Justification Scores
0.00
10.00
20.00
30.00
40.00
50.00
60.00
SME1 SME2 SME3
Sco
r%( se
)
CYCORP
ONTOPRISE
TEAM SRI
Figure 4. Correctness and Answer-Justification Scores for the Multiple Choice Section as a Percentage of the Maximum Score of 50 Points.
Balance the following reactions, and indicate whether they are examples of combustion, decomposition, or combination(a)C4H10 + O2 → CO2 + H2O(b)KClO3 → KCl + O2
(c)CH3CH2OH + O2 → CO2 + H2O(d)P4 + O2 → P2O5
(e)N2O5 + H2O → HNO3
Figure 5. An Example of a Detailed Answer Section Question, DA1.
experts to produce more consistent scoring.All subject matter experts found some an-
swer justifications that they liked. The subjectmatter experts provided high-level comments,mostly focused on the organization and con-ciseness of the justifications. In some instances,justifications were quite long. For example, Cy-corp’s generative English produced some justi-fications in excess of 16 pages in length. Thesubject matter experts also complained thatmany arguments were used repetitively andthat proofs took a long time to “get to thepoint.” In some multiple choice questions,proofs involved invalidating all wrong answersrather than proving the right one. All theteams appeared to rely on instance-based solu-tions to prove generalized comprehension-ori-ented questions, indicating a limited ability toreason with concepts. Gaps in knowledge cov-erage were also evident. For example, many ofthe teams had significant gaps in their knowl-edge of net ionic equations. Detailed question-by-question scores are available on the projectWeb site.
Problematic Questions Despite the impressive overall performance ofthe three systems, there were questions onwhich each of them failed. Most interestingly,there were questions on which all three sys-tems failed dramatically. Five prominent andinteresting cases—DA10, DA22, FF1, FF8, andFF22—are shown in figure 10. We examinethese questions more closely.
The first issue to address is whether thesequestions share properties that explain theirdifficulty. An initial hypothesis is that all fivequestions require that a system be able to rep-resent and reason about its own problem-solv-ing procedures and data structures—that is,that it be reflective or capable of metarepresen-tation and metareasoning. That propertywould explain the difficulty all three systemshad, at least to the extent that the systems canbe said to lack such reflective capabilities.
DA10 seems to probe a system’s strategy forsolving any of a general class of problems; in-deed, it seems to ask for an explicit descriptionof that strategy. DA22 implies that the pH cal-culation that a problem solver is likely to usewill generate an unacceptable result in this case(a value of greater than 7 for an acid) and thenasks for an explanation of what went wrong,that is, of why the normal pH calculation leadsto an anomalous result here. These two ques-tions both seem to require the system to repre-sent and reason about, indeed to explain theworkings of, its own problem-solving proce-dures.
FF22 seems similar in that it asks about theapplicability of approximate solutions for a cer-tain class of problems and about the reasonsfor the limits to that applicability. On reflec-tion, though, it is really probing the system’sknowledge of certain methodological princi-ples used in chemistry rather than the system’sknowledge of its own inner workings. Whatseems to be missing is knowledge about chem-istry—not about chemical compounds butrather about methods used in chemistry, inparticular about approximate methods andtheir scope and limits. And, of course, these lat-ter methods may or may not be built into thesystem’s own problem-solving routines.
Articles
WINTER 2004 37
DA Answer Scores
0.00
10.00
20.00
30.00
40.00
50.00
60.00
SME1 SME2 SME3
roc
S( se%
) CYCORP
ONTOPRISE
TEAM SRI
DA Justification Scores
0.00
10.00
20.00
30.00
40.00
50.00
60.00
SME1 SME2 SME3
roc
S( se%
) CYCORP
ONTOPRISE
TEAM SRI
Figure 6. Correctness and Answer-Justification Scores for the Detailed Answer Section as a Percentage of the Maximum Score of 80 Points.
Pure water is a poor conductor of electricity, yet ordinary tap water is a good conductor. Account for this difference.
Figure 7. An Example of a Free-Form Section Question, FF2.

systems. The Ontoprise system proved to bethe fastest and most reliable, taking approxi-mately 2 hours to complete its batch run. TheSRI system ran the challenge in approximately5 hours, and the Cycorp system completed itsprocessing in over 12 hours. In this latter case,a memory leak on the sequestered platformcaused the server to crash, and the system wasrebooted and run until the evaluation timelimit expired.
All three teams undertook modifications andimprovements to the sequestered systems andran the challenges again. In this case the Onto-prise system was able to complete the chal-lenge in 9 minutes, the SRI system took 30minutes, and the Cycorp system took approxi-mately 27 hours to process the challenge. Boththe sequestered and the improved systems arefreely available for download off the ProjectHalo Web site.
AnalysisThe three systems did well—better than Vulcanexpected. Nevertheless, their performance wasfar from perfect, and the goal of the pilot pro-ject was to go beyond evaluations of KR&R sys-tems to an analysis of them. Therefore, wewanted to understand why these systems failedwhen they did, the relative frequency of eachtype of failure, and the ways these failuresmight be avoided or mitigated.
Based on our collective experience buildingKR&R systems, at the beginning of Project Halowe designed a taxonomy of failures that fieldedsystems might experience. Then, at the end ofthe project, we analyzed every point lost on theevaluation in an attempt to identify the failureand place it within the taxonomy. We studiedthe resulting data to draw lessons about thetaxonomy, the systems, and (by extrapolation)the current state of KR&R technologies forbuilding fielded systems. See Friedland et al.(2004) for a comprehensive report of thisstudy.
In particular, our failure analysis suggeststhree broad lessons that can be drawn acrossthe board for the three systems: modeling, an-swer justification, and scalability for speed andreuse.
Modeling. A common theme in the modelingproblems across the systems was that the incor-rect knowledge was represented, or some do-main assumption was not adequately factored-in, or the knowledge was not captured at theright level of abstraction. Addressing theseproblems requires us to have direct involve-ment of the domain experts in the knowledge-engineering process. The teams involved such
FF1 and FF8 are similar in that one asks forsimilarities and the other for differences, andin both cases, the systems did represent theknowledge but did not support the reasoningmethod to compute them.
FF1 is a question about the language ofchemistry, in particular about the abstract syn-tax or type conventions of terms for chemicalcompounds. All three systems had someknowledge encoded so that the differencescould be computed but lacked the necessaryreasoning method to compute them.
A Note on PerformanceThe Halo pilot challenge was run over thecourse of a day and a half on sequestered sys-tems at Vulcan, by Vulcan personnel. As notedabove, we did encounter minor problems withall three systems that were resolved over thisperiod of time. Among other issues, the batchfiles containing the formal encodings of thechallenge questions needed to be broken intotwo to facilitate their processing on all three
Articles
38 AI MAGAZINE
FF Answer Scores
0.00
5.00
10.00
15.00
20.00
25.00
30.00
35.00
40.00
45.00
SME SME2 SME3
)%( ser
ocS
CYCORP
ONTOPRISE
TEAM SRI
FF Justification Scores
0.00
5.00
10.00
15.00
20.00
25.00
30.00
SME1 SME2 SME3
)%( ser
ocS
CYCORP
ONTOPRISE
TEAM SRI
Figure 8. Correctness and Answer Justification Scores for the Free-Form Section as a Percentage of the Maximum Score of 38 Points.
Note that SRI fared significantly better both in the correctness and justificationscoring.

experts to different extents and at differenttimes during the course of the project. The SRIteam, which involved professional chemistsfrom the beginning of the project, appeared tobenefit substantially. This presents a researchchallenge, since it suggests that the expositionsof chemistry in current texts are not sufficientfor building or training knowledge-based sys-tems. Instead, a high-level domain expert mustbe involved in formulating the knowledge ap-propriately for system use. Two approaches toameliorating this problem being pursued byparticipants are (1) providing tools that sup-port direct manipulation and testing of KR&Rsystems by such experts, and (2) providing thebackground knowledge required by a system tomake appropriate use of specialized knowledgeas it is presented in texts.
Answer Justification. Explanation, or, moregenerally, response interpretability, is funda-mental to the acceptance of a knowledge-basedsystem, yet for all three state-of-the-art sys-tems, it proved to be a substantial challenge.Since the utility of the system will be evaluatedend to end, it is to a large degree immaterialwhether its answers are correct, if they cannotbe understood. Reaching the goals of projects
Articles
WINTER 2004 39
Challenge Answer Scores
0.00
10.00
20.00
30.00
40.00
50.00
60.00
SME1 SME2 SME3
Sc
ro
( se%
) CYCORP
ONTOPRISE
TEAM SRI
Challenge Justification Scores
0.00
5.00
10.00
15.00
20.00
25.00
30.00
35.00
40.00
45.00
SME1 SME2 SME3
Sc
ro
( se%
) CYCORP
ONTOPRISE
TEAM SRI
Figure 9. Total Correctness and Justification Scores as a Percentage of the Maximum Score of 168 Points.
DA10: HCl, H2SO4, HClO4, and HNO3 are all examples of strong acids and are 100% ionized in water. This is known as the “leveling effect” of the solvent. Explain how you would establish the relative strengths of these acids. That is, how would you answer a question such as “which of these acids is the strongest?”
DA22. Phenol, C6H5OH, is a very weak acid with an acid equilibrium constant of Ka = 1.3 x 10-10. Determine the pH of a very dilute, 1 x 10-5 M, solution of phenol. Is the value acceptable? If not, give a possible explanation for the unreasonable pH value.
FF1. What is the difference between the subscript 3 in HNO3 and a coefficient 3 in front of HNO3?
FF8. Although nitric acid and phosphoric acid have very different properties as pure substances, their aqueous solutions possess many common properties. List some general properties of these solutions and explain their common behavior in terms of the species present.
FF22. When we solve equilibrium expressions for the [H3O+] approximations are often made to reduce the complexity of the equation thus making it easier to solve. Why can we make these approximations? Would these approximations ever lead to significant errors in the answer? If so give an example of an equilibrium problem that would require use of the quadratic equation.
Figure 10. Examples of Chemistry Questions That Proved to Be Problematic for All Three Teams.

A Brief History of Evaluating Knowledge Systems
One unique aspect of the Halo pilot is its rigorous schemeof evaluation. It uses an independently defined andwell-understood test, specifically, the advanced place-
ment test for chemistry, on a well-defined scope, specifically, 70pages of a chemistry textbook. Though such rigorous evalua-tion schemes have been developed in the areas of shallow in-formation extraction (the MUC conferences) information re-trieval and simple question answering (the TREC conferences)for quite a while, the corresponding task of evaluating the kindof knowledge-based systems deployed in the Halo Pilot had ap-peared to be too difficult to be approached in one step.
Thus, previous efforts at measuring the performance ofknowledge-based systems such as in high-performance knowl-edge bases (HPKB) and rapid knowledge formation (RKF) con-stituted important stepping stones towards rigorous evaluationof knowledge-based systems, but the Halo pilot represents a sig-nificant advance. To substantiate this summary, we shall reviewsome of the details of developments in these various areas.
Retrieving Answers from TextsQuestion-answering via information retrieval and extractionfrom texts has been an active area of research, with a progres-sion of annual competitions and conferences, especially the 7message-understanding conferences (MUCs) and the 12 text-re-trieval conferences (TRECs) from 1992–2003, sponsored byNIST, IAD, DARPA, and ARDA. TRECs were initially aimed at re-trieving relevant texts from large collections and then at ex-tracting relevant passages from texts (Voorheese 2003). The ear-lier systems had virtually no need for inference-capableknowledge bases and reasoning capabilities. In recent years thequestion-answering tasks have become more challenging, forexample, requiring a direct answer to a question rather than apassage containing the answer. The evaluation schemes arevery well defined, including well worked out definitions of thetasks and answer keys that are used to compute evaluation mea-sures including precision and recall.
Recently there has been a surge of interest in the use of do-main knowledge in question answering (for example, seeChaudhri and Fikes [1999]). ARDA’s current advanced questionand answering for intelligence program (AQUAINT), started in2001, is pushing text-based question-answering technology fur-ther, seeking to address a typical intelligence-gathering scenarioin which multiple, interrelated questions are used to fulfill anoverall information need rather than answer just single, isolat-ed, fact-based questions. AQUAINT has both adopted TREC’sapproach to the evaluation of question-answering and tried toextend it to encompass more complex question types, for ex-ample biographical questions of the form “Tell me all the im-portant things you know about Osama bin Laden.” The funda-mental difference between the Halo evaluation and theAQUAINT evaluation is that the AQUAINT evaluations are de-
signed to test the question-answering capability on huge bodiesof text on widely ranging subjects using very limited reasoningcapabilities. In contrast, the Halo evaluation is focused on eval-uating deep reasoning in the field of sciences. The eventual goalof Halo is to do significant coverage of sciences, but the currentphase was limited to only 70 pages of a chemistry textbook.
Building and Running Knowledge-Based SystemsIn the area of knowledge-based systems, DARPA, AFOSR, NRI,and NSF jointly funded the knowledge sharing effort in 1991(Neches et al. 1991). This was a three-year collaborative pro-gram to develop “knowledge sharing” technologies to facilitatethe exchange and reuse of inference-capable knowledge basesamong different groups. The aim was to help reduce costs andpromote development of knowledge-based applications. Thiswas followed by DARPA’s High Performance Knowledge Base(HPKB) program (1996–2000), designed to push knowledge-based technology further and demonstrate that very large(100k+ axiom) systems could be built quickly and be usefullyapplied to question-answering tasks (Cohen et al. 1998). Theevaluation in HPKB was aimed simply at the hypothesis thatlarge knowledge-based systems can be built at all, that they canaccomplish interesting tasks, and that they do not break—as atoy system would and as many of the initial knowledge-basedsystems did—when working with a realistically sized knowl-edge base.
Evaluating Knowledge-Based SystemsThere have been few efforts so far at documenting and analyz-ing the quality of fielded KR&R systems (Brachman et al. 1999;Keyes 1989; and Batanov and Brezillon 1996). RKF made signif-icant efforts to analyze and document the quality of knowledgebase performance (Pool et al. 2003). Specifically, an evaluationin DARPA’s Rapid Knowledge Formation project, which wasroughly comparable to the one used in Project Halo, was basedon approximately 10 pages from a biology textbook and a setof test questions—however, this was not an independently es-tablished test. The Halo pilot, reported on here, improves uponthese evaluations by being more systematic and usable forcross-system comparisons. The Halo pilot has adopted an eval-uation standard that is comparable to the rigor of the chal-lenges for retrieving answers from texts. It provides an exact de-finition of the scope of the domain—an AP chemistry testsetting that has proven its validity in many years with manystudents—as well as an objective evaluation by independentgraders. We conjecture that the Halo evaluation scheme is ex-tensible enough to support a coherent long-term developmentprogram.
Articles
40 AI MAGAZINE

like Digital Aristotle will require an investmentof considerably more resources into this aspectof systems to realize robust gains in their com-petence. Constructing explanations directlyfrom the system’s proof strategy is neitherstraightforward nor particularly successful, es-pecially if that strategy has not been designedwith explanation in mind. One alternative is touse explicit representations of problem-solvingmethods (PSMs) so that explanations can in-clude statements of problem-solving strategy aswell as statements of facts and rules (Clancey1983). Another is to perform more metareason-ing over the proof tree to construct a morereadable explanation.
Scalability for Speed and Reuse. There hasbeen substantial work in the literature on thetrade-off between expressiveness and tractabil-ity, yet managing this trade-off, or even pre-dicting its effect in the design of fielded sys-tems over real domains, is still not at allstraightforward. To move from a theoretical toan engineering model of scalability, the KRcommunity would benefit from a more system-atic exploration of this area driven by the em-pirical requirements of problems at a widerange of scales. For example, the three Halosystems, and more generally, the Halo develop-ment and testing corpora, can provide an ex-cellent test bed to enable KR&R researchers topursue experimental research in the trade-offbetween expressiveness and tractability.
DiscussionAll three logical languages, KM, F-Logic, andCycL, were expressive enough to representmost of the knowledge in this domain. F-Logicwas by far the most concise and easy to read,with syntax most resembling an object-orient-ed language. F-Logic also yielded very high-fi-delity representations that appear to be easierand more intuitive to construct. Ontoprise wasthe only team to conduct a sensitivity study ofthe impact of different question encodings onsystem performance. In the case of the twoquestions they examined, their system pro-duced similar answers with slightly differentjustifications. For the most part, the encodingprocess and its impact on question-answeringstability remain an open research topic.
SRI and Ontoprise yielded comparably sizedknowledge bases. OntoNova was built fromscratch using no predefined primitives, whileSRI’s system leveraged the Component Library,though not as extensively as the team had ini-tially hoped. SRI’s use of professional chemistsin the knowledge-formulation process was ahuge advantage, and the quality of their out-come is reflected by this fact. The other teams
have conceded that, if they had the opportuni-ty to revisit the challenge, they would adoptthe use of subject matter experts in knowledgeformation. Cycorp’s OpenHalo knowledge basewas two orders of magnitude larger than theother teams’. They were unable to demonstrateany measurable advantage in using this addi-tional knowledge, even in example-based ques-tions, where they exhibited metareasoningbrittleness similar to that observed in the othersystems. The size of Cycorp’s knowledge basedoes, however, explain some of the significantrun-time differences. They have also yet todemonstrate successful, effective reintegrationof Halo knowledge into the extended Cyc plat-form. Reuse and integration appear to remainopen questions for all three Halo teams.
The most novel aspect of the Halo pilot wasthe great emphasis put on answer explana-tions, which served two primary purposes: first,to exhibit and thereby verify that deep reason-ing was occurring, and second, to validate thatappropriate domain explanations can be gener-ated. This is an area that is still open to signifi-cant improvement. SRI’s approach producedthe best-quality results, but it leaves openmany questions regarding how well it might bescaled, generalized, and reused. Cycorp’s gener-ative approach may eventually scale and gener-alize, but the current results were extremelyverbose and often unintelligible to domain ex-perts. Ontoprise’s approach of running a sec-ond inference process appears to be verypromising in the near term.
Vulcan Inc. and the pilot participants haveinvested considerable efforts in promoting thescientific transparency of the Halo pilot. Theproject Web site provides all the scientificallyrelevant documentation and tutorials, includ-ing an interactive results browser and fully doc-umented downloads representing both the se-questered systems and improved Halo pilotchemistry knowledge bases. We eagerly antici-pate comment from the AI community andlook forward to its use by universities and otherresearchers.
Finally, the issue of cost must be considered.We estimate that the per page expense for eachof the three Halo teams was on the order of$10,000 per page for the 70-page syllabus. Thiscost must be significantly reduced before thistechnology can be considered viable for DigitalAristotle.
In summary, all of the Halo systems scoredwell on a very difficult challenge: extrapolatingthe results of team SRI’s system on the limited70-page syllabus to the entire AP syllabus yield-ed the equivalent of an AP-3 score for answercorrectness—good enough to earn course cred-
Articles
WINTER 2004 41

Articles
42 AI MAGAZINE
The Halo pilot evaluation was intended to as-sess deep-reasoning capabilities of the threecompeting systems in the context of a well-known evaluation methodology. Seventypages of the advance placement (AP) chem-istry syllabus were selected. Systems were re-quired to produce coherent answers and an-swer justifications in English to each of the100 AP-style questions posed. In the case ofmultiple choice questions, a letter responsewas required. The evaluation team consistedof three chemistry professors, who were in-structed to grade the exams using AP guide-lines. Answer justifications were thus re-quired to conform to AP guidelines to receivefull credit.
System outputs were required to conformto strict formats. The question number need-ed to be clearly indicated, followed by theoriginal English text of the question. This wasto be followed by the answer. Multiple choicequestions required a letter answer. Finally,the answer justification was required. Justifi-cation guidelines required that the answersbe clear, concise, and appropriate for AP ex-ams.
The system outputs were rendered intohardcopy and distributed to three chemistryprofessors for evaluation. These subject mat-ter experts were asked to apply AP gradingguidelines to assess the system outputs and toprovide lots of written comments.
Question examples 1 through 3 presentOntoprise, SRI, and Cycorp system outputs,respectively. Examples 1 and 2 depict re-sponses to multiple choice question 20, whileexample 3 depicts the response to multiplechoice question 34. These figures also containgraders’ remarks.
Question Example 2. SRI’s SHAKEN Output. Human-authored templates associated with chem-ical methods were combined during the back-chaining process to produce the English text. Thetemplates specify the salient subgoals to be elabo-rated as indented “sub explanations.” This result-ed in generally superior answer justifications.
Question Example 1. Ontoprise’s OntoNova Application’s Output for Multiple Choice Question 20.
Note the output’s format: the question number is indicated at the top; fol-lowed by the full English text of the original question; next, the letter answeris indicated; finally, the answer justification is presented. The graders writtenremarks are included. OntoNova employed a second inference step to derivethe answer justification, using human-authored templates, the proof tree, andcombination rules to assemble the English text.
Examples of System Outputs andGrader Comments

Articles
WINTER 2004 43
Comments on SRI Output
Well done, and to the point
In general, the program appears to take a quantitative approach whenanswering questions and does not know how to take a qualitativeapproach. For example, when the activity series was part of a question, the program would use cell potentials
The “reasoning” are much, much, much too long. A sufficient “reasoning” to any of the questions on the exam never requires more than the 1/2 page.
A good approach for replacing the “reasoning” used in this program isto use “Show Method of Calculation” (for all questions which involve the calculation of a numerical answer) and “Explain Reasoning” (for allquestions which do not involve a calculated answer)
Main strength of the program is that it did a fairly good job of arriving at the correct answers
There was a common error in the use of significant figures. Answers areoften given in as many figures as the program could generate. This is also a common problem with students so I guess we could claim that the com-puter is being more human-like in these responses
The logic is more readable (and shorter!) than the KB justifications, but it often seems to be presented backwards — arguing from the answer as opposed to arguing to the answer.
Good logical flow, set up with substitutions shown
Generally, when a calculation was required, the program did not follow what I would expect from a student: namely, a setup, substituted numbers, followed by a solution to the problem.
Very good, brief presentation in logical order Good use of selective eliminationThis is a good first effort, but still looks a little like what would be expected from a student taking this exam.
Comments on Ontoprise Output
Comments on Cycorp Output
Comments on Output.This figure shows a small, if representative, sub-set of verbatim comments that subject matterexperts made on the answers to the questionsproduced by the system. The subject matter ex-perts had well-defined expectations of systembehavior, for example setting up a problem be-fore actually presenting its solution or thenumber of significant digits used in the output.These comments did not reflect, for the mostpart, on the correctness of the computation,but rather were indicators of “how things wereto be done on an AP chemistry exam.” Thishighlights the importance of understandingdomain-specific requirements in answer andanswer-justification formation and generationby question-answering systems.
Question Example 3. The Output of Cycorp’s OpenHalo Application for
Multiple Choice Question 34. Note the grader’s remarks. OpenHalo used theproof tree and Cyc’s generative English capabil-ities to produce the English answer. This exam-ple illustrates one of the better outcomes—some questions produced many pages of gener-ative English, which were far less intelligible tothe graders.

portions of the syllabi would be best suited todemonstrate the broadest proof of concept,given our resources, and better understand theways in which the content requirements of thedifferent disciplines can be mutually leveraged;and finally, (4) produce a coherent, well moti-vated design.
A 15-month implementation stage will fol-low. Here, the detailed designs will be renderedinto working systems, and these systems willbe subject to a comprehensive user evaluationto understand their viability and the degree towhich the empirical data from actual use bydomain experts fits the models developed dur-ing the design stage. Finally, a nine-month re-finement stage will attempt to correct theshortcomings detected in the implementationstage evaluation, and a second evaluation willbe undertaken to validate the refinements.
Future work will focus on tactical research tofill gaps identified in Halo 2 that will lead togreater coverage of the scientific domains.These efforts will investigate both automatedand semiautomated methods to facilitate for-mulation of knowledge and posing of ques-tions and provide better tools for evaluationand inspection of the knowledge-formulationand question-answering processes. We will alsobe focusing on reducing brittleness and othersystemic failures of the Halo phase-two systemsthat will be identified by a comprehensive fail-ure analysis of the sort we developed for phaseone. We will be seeking the assistance of theKR&R community to standardize our extendedfailure taxonomy for use in a wide variety ofknowledge-based applications.
Throughout phase two, Project Halo will beconducting an ongoing dialogue with domainexperts and educators, especially those fromthe three target scientific disciplines. Our aimsare to better understand their needs and to ex-plain the potential benefits of the availabilityof high-quality machine-processable knowl-edge to both research and education. For exam-ple, once a proof of concept for our knowledgeformulation approach has been established,Project Halo will consider how knowledgemodules might be integrated into interactivetutoring applications. We will also examinehow such modules might assist knowledge-dri-ven discovery, as part of the functionality of adigital research assistant.
AcknowledgmentsFull support for this research was provided byVulcan Inc. as part of Project Halo. For more in-formation, see www.projecthalo.com.
Notes1. MEDLINE is the National Library of Medicine’s
it at many top universities. The Halo teams be-lieve that with additional, limited effort theywould be able to improve the scores to the AP-4 level and beyond. Vulcan Inc. has developedtwo additional challenge question sets to vali-date these claims at a future date.
Conclusions and Next Steps As we noted at the beginning of this article,Project Halo is a multistaged effort. In the fore-going, we have described phase one, which as-sessed the capability of knowledge-based sys-tems to answer a wide variety of unanticipatedquestions with coherent explanations. Phasetwo of Project Halo will examine whether toolscan be built to enable domain experts to buildsuch with an ever-decreasing reliance onknowledge engineers—a goal that was pursuedin DARPA’s Rapid Knowledge Formation pro-ject. Empowering domain experts to build ro-bust knowledge bases with little or no assis-tance from knowledge engineers will (1)dramatically decrease the cost of knowledgeformulation; (2) greatly reduce the type of er-rors observed in the Halo Pilot that resultedfrom lack of understanding of the domain onthe part of knowledge engineers; and (3) facili-tate a growing, peer-reviewed body of ma-chine-processable knowledge that will formthe basis for Digital Aristotle. A critical measureof success is the degree to which the relevantscientific communities are willing to adoptthese tools, especially in their pedagogies.
At the core of the knowledge formulationapproach envisioned in phase two is a docu-ment-rooted methodology in which the do-main expert uses an existing document such asa textbook as the basis for the formulation of aknowledge module. Tying knowledge modulesto documents in this way will help determinethe scope and context of each module, thetypes of questions they can be expected to an-swer, and the appropriate depth and resolutionof the answers. The 30-month phase-two effortwill be undertaken in three stages. First, a six-month, analysis-driven design process will ex-amine the complete AP syllabi for chemistry,biology, and physics (B). The objective of thisanalysis will be to determine requirements oneffective use by domain experts of a range ofknowledge-acquisition technologies. The re-sults of this study should allow us to (1) deter-mine the gaps in “coverage” of current state-of-the-art knowledge-acquisition techniques anddefine targeted research to fill those gaps; (2)understand and prioritize the methods, tech-niques, and technologies that will be central tothe Halo 2 application; (3) understand which
Articles
44 AI MAGAZINE

premier bibliographic database covering the fields ofmedicine, nursing, dentistry, veterinary medicine,the health care system, and the preclinical sciences.
2. Sections 2.6–2.9 in chapter 2 provide detailed in-formation. Chapter 16 also requires the definition ofmoles, which appears in section 3.4, pages 87–89,and molarity, which can be found on page 134. Theform of the equilibrium expression can be found onpage 580, and buffer solutions can be found in sec-tion 17.2.
3. Available from http://www.opencyc.org/.
4 The system code and documentation are availableat http://www.cs.utexas.edu/users/mfkb/km.html.
5. After the challenge evaluation was complete, theteams put in a considerable effort to make improvedversions of their application for use by the generalpublic. These improved versions address many of theproblems encountered on the sequestered versions.Vulcan Inc has made both the sequestered and im-proved versions available for download on the pro-ject Halo Web site.
6. One explanation for this is that, although agreedguidelines exist for marking human justifications,the Halo systems can create justifications unlike anythat the graders have seen before (for example, withextensive verbatim repetition), and for which noagreed scoring protocol has been established.
ReferencesAngele, J.; Mönch, E.; Oppermann, H.; Staab, S.; andWenke, D. 2003. Ontology-based Query and Answer-ing in Chemistry: Ontonova @ Project Halo. In Pro-ceedings of the Second International Semantic Web Con-ference (ISWC2003). Berlin: Springer Verlag.
Barker, K.; Porter, B.; and Clark, P. A Library of Gener-ic Concepts for Composing Knowledge Bases. In Pro-ceedings of the First International Conference on Knowl-edge Capture (K-Cap’01), 14–21. New York:Association for Computing Machinery Special Inter-est Group on Artificial Intelligence.
Barker, K.; Chaudhri, V. K.; Chaw, S. Y.; Clark, P. E.;Fan, J.; Israel, D.; Mishra, S.; Porter, B.; Romero, P.;Tecuci, D.; and Yeh, P. 2004. A Question-AnsweringSystem for AP Chemistry: Assessing KR&R Technolo-gies. In Proceedings of the Ninth International Confer-ence of Knowledge Representation and Reasoning. MenloPark, Calif.: AAAI Press.
Batanov, D.; and Brezillon, P., eds. 1996. Proceedingsof the First International Conference on Successes andFailures of Knowledge-based Systems in Real World Ap-plications. Bangkok, Thailand: Asian Institute ofTechnology.
Brachman, R. J.; McGuinness, D. L.; Patel-Schneider,P. F.; and Borgida, A. 1999. Reducing CLASSIC to“Practice”: Knowledge Representation Theory MeetsReality. Artificial Intelligence Journal 114(1–2):203–237.
Brown, T. L.; LeMay, H. Eugene; and Bursten, B. 2003.Chemistry: The Central Science. Englewood Cliffs, NJ:Prentice Hall.
Chaudhri, V.; and Fikes, R., eds. 1999. Question An-swering Systems: Papers from the AAAI Fall Symposium.Technical Report FS-99-02. Menlo Park, California:
American Association for Artificial Intelligence.
Clancey, W. J. 1983. The Epistemology of a Rule-Based Expert System: A Framework for Explanation.Artificial Intelligence Journal 20(3): 215–251.
Cohen, P.; Schrag, R.; Jones, E.; Pease, A.; Lin, A.;Starr, B.; Gunning, D.; and Burke, M. 1998. TheDARPA High Performance Knowledge Bases Project.AI Magazine 19(4): 5–49.
Friedland, N.; Allen, P. G.; Witbrock, W.; Matthews,G.; Salay, N.; Miraglia, P.; Angele, J.; Staab, S.; Israel,D.; Chaudhri, V.; Porter, B.; Barker, K.; and Clark, P.2004. Towards a Quantitative Platform-independentQuantitative Analysis of Knowledge Systems. In Pro-ceedings of the Ninth International Conference of Knowl-edge Representation and Reasoning. 2004. Menlo Park,Calif.: AAAI Press.
Keyes, J. 1989. Why Expert Systems Fail? IEEE Expert4(11): 50–53.
Kifer, M.; Lausen, G.; and Wu, J. 1995. LogicalFoundations of Object Oriented and Frame BasedLanguages. Journal of the ACM, 42(4): 741–843.
Neches, R.; Fikes, R.; Finin, T.; Gruber, T.; Patil, R.;Senator, T.; and Swartout, W. R. 1991. Enabling Tech-nology for Knowledge Sharing. AI Magazine 12(3):6–56.
Novak, G. 1995. Conversion of Units of Measure-ment. IEEE Transactions on Software Engineering 21(8):651–661.
Pool, M.; Murray, K.; Mehrotra, M.; Schrag, R.;Blythe, J.; Kim, J.; Miraglia, P.; Russ, T.; and Schnei-der, D. 2003. Evaluation of Expert Knowledge Elicit-ed for Critiquing Military Courses of Action. In Pro-ceedings of the Second International Conference onKnowledge Capture (KCAP-03). New York: Associationfor Computing Machinery.
Voorheese, E. M., ed. 2003. The Twelfth Text RetrievalConference (TREC2003). Washington, DC: Depart-ment of Commerce, National Institute of Standardsand Technology (http://trec.nist.gov/pubs/trec12/t12_proceedings.html).
Witbrock, M.; and Matthews, G. 2003. Cycorp ProjectHalo Final Report. Austin, TX.: Cycorp.
Noah Friedland, the former Pro-ject Halo program manager at Vul-can Inc., led the development ofDigital Aristotle—a knowledge ap-plication that will be capable of as-sisting scientific educators and re-searchers in their work in agrowing number of scientific disci-plines. Friedland holds a Ph.D. in
computer science from the University of Maryland,where he studied under the late Azriel Rosenfeld. Healso holds degrees in aeronautical and electrical en-gineering from the Technion in Haifa, Israel. Prior tojoining Vulcan in 2002, Friedland held a variety ofleadership roles in Seattle-area high-tech startups.His website is www.noahfriedland.com.
Investor and philanthropist Paul G. Allen creates
Articles
WINTER 2004 45

ontologies, and inference for large sharedknowledge bases.
Peter Clark ([email protected]) is a researchscientist in the IntelligentInformation Systemsgroup, Boeing PhantomWorks, leading research inthe areas of knowledge-based systems, machine
reasoning, and controlled language pro-cessing.
research interests center on advancingknowledge-based systems as a feasible toolfor knowledge management and evolution.
David Israel ([email protected]) is di-rector of the natural language program inthe Artificial Intelligence Center at SRI In-ternational.
Vinay Chaudhri ([email protected]) is the program manager for ontol-ogy management in the Artificial Intelli-gence Center at SRI International. His re-search focuses on knowledge acquisition,
and advances world-classprojects and high-im-pact initiatives thatchange and improve theworld. He cofounded Mi-crosoft with Bill Gates in1976, remained the com-pany’s chief technologistuntil he left Microsoft in
1983, and is the founder and chairman ofVulcan Inc. and the chairman of CharterCommunications (a broadband communi-cations company). Named one of the topten philanthropists in America, Allen givesback to the community through his chari-table foundations. Learn more about Allenonline at www.vulcan.com.
Bruce Porter ([email protected]) is aprofessor in the Department of ComputerScience at the University of Texas at Austinand the director of the Artificial Intelli-gence Laboratory. His research and teach-ing focuses on knowledge-based systemsand the contributing technologies ofKR&R, machine learning, explanation gen-eration, and natural language understand-ing.
Ken Barker ([email protected]) inves-tigates knowledge-based systems as a re-search associate in the Department of Com-puter Sciences at the University of Texas atAustin. He received a Ph.D. in computa-tional linguistics from the University of Ot-tawa in 1998.
James Fan ([email protected]) is a Ph.D.student at the University of Texas at Austin.He has an M.S. (2001) and a B.S. (1996) incomputer sciences from the University ofTexas. His research interests include knowl-edge-based systems, ontologies, semanticweb, natural language processing, and ma-chine learning.
Dan G. Tecuci ([email protected]) iscurrently a Ph.D. student in computer sci-ences at the University of Texas at Austin.He received a M.Sc. in computer sciencesfrom the same university in 2001. His mainresearch interest is artificial intelligencewith a focus on knowledge-based systems.
Peter Z. Yeh ([email protected]) is cur-rently a Ph.D. student in computer sciencesat the University of Texas at Austin. He re-ceived his B.S. and M.S. in computer sciencefrom the same institution. His research in-terests are in the areas of inexact and se-mantic graph matching, knowledge-basesystems, and knowledge representation.
Shaw Yi Chaw ([email protected]) iscurrently a Ph.D student in computer sci-ences at the University of Texas at Austin.He has a B.Comp in computer science fromthe National University of Singapore. His
Articles
46 AI MAGAZINE
SRI Team. Front row (left to right): Lisa Ahlberg, Vinay Chaudhri, Irina Beylin, David Israel,Tomas Uribe. Back row (left to right): Ken Murray, Pedro Romero, Anne Venturelli, and
David Wilkins.
Knowledge Based Systems Group at University of Texas at Austin. Sitting (left to right): KenBarker, Bruce Porter. Standing (left to right): Jason Chaw, Peter Yeh, Dan Tecuci, James Fan.

Juergen Angele ([email protected]) isthe chief executive officer and cofounder ofOntoprise GmbH. He has published some75 papers on ontologies, frame-based log-ics, reasoning, and semantic web technolo-gies. He is the inventor of the inference en-gine, OntoBroker.
Steffen Staab, PD Dr. rer. nat. ([email protected]), is a senior lecturer at the Univer-sity of Karlsruhe and cofounder of Onto-prise GmbH. He is currently on theeditorial board of IEEE Intelligent Systems,International Journal of Human-ComputerStudies, Journal of Web Semantics, and Jour-nal of IT&T.
Dirk Wenke, Dipl. Math. Oec. ([email protected]), is a senior software developerand knowledge engineer at OntopriseGmbH, Karlsruhe. He is responsible for thedevelopment of the ontology editing tools.
Eddie Moench, Dipl. Wi.-Ing. ([email protected]), is software engineer at On-toprise GmbH. He is responsible for the de-velopment of SemanticMiner, the ontol-ogy-based knowledge-retrieval application.
Henrik Oppermann, Dipl.-Ing. ([email protected]), is vice president ofprofessional services at and shareholder ofOntoprise GmbH. His focus is on industrialapplication of ontologies and reasoningtechnologies.
Gavin Matthews ([email protected]) is aproject manager with Cycorp. He holds anM.A. in computer science and mathematicsfrom the University of Cambridge andgraduated in 1991. He has been with Cy-corp since 2002. He has experience in soft-ware engineering management at GeodesicSystems, Harlequin Group plc, and Elec-
tronic Data Systems, specializing in mem-ory management and 3-D solid modeling.
Michael Witbrock ([email protected]) iscurrently vice president for research at Cy-corp. Previously Witbrock was a principalscientist at Terra Lycos, a research scientistat Just Systems Pittsburgh Research Center,and a system scientist at CMU. He has aPh.D. in computer science from CarnegieMellon University and is the author ofmore than two dozen papers and twogranted patents.
John Curtis ([email protected]) received hisPh.D. in philosophy at the Ohio State Uni-versity in 1999, where he specialized in thehistory of analytic philosophy and the phi-losophy of logic. With Cycorp since 1999,he has worked primarily at the intersectionof NLP and ontology, designing semanticmodels for parsing, and overseeing the de-velopment and implementation of strate-gies for resolving intermediate-level repre-sentations (Cyc’s semantic layer betweennatural language and inferentially salientCycL).
Pierluigi Miraglia ([email protected]) earned his doctorate in philosophy atthe Ohio State University. After workingfor several years at Cycorp, he is now a se-
Articles
WINTER 2004 47
Cycorp Team. Front row (left to right): Michael Witbrock, Gavin Matthews.Back row (left to right): David Baxter, John Curtis, Blake Shaperd.
At Left: Ontoprise Team.
Sitting (left to right):Eddie Moench, Jurgen Angele.
Standing (left to right):Dirk Wenke,
Henrik Oppermann,Steffen Staab.
nior ontologist with Convera Corporation.He lives in Austin, Texas.
David Baxter ([email protected]) holds aPh.D. in linguistics from the University ofIllinois. He has worked for Cycorp since1998 and specializes in natural languageparsing and generation.
Blake Shepard ([email protected]) is an on-tologist at Cycorp. He received his Ph.D. inphilosophy from the University of Texas atAustin in 2000 and has been with Cycorpsince 1999.

AAAI Press
48 AI MAGAZINE
www.aaai.org/Press/Books/
Data Mining: Next GenerationChallenges and Future Directions
Edited by Hillol Kargupta, Anupam Joshi, Krishnamoorthy Sivakumar and Yelena Yesha
Data mining, or knowledge discovery, has become an in-dispensable technology for businesses and researchers inmany fields. Drawing on work in such areas as statistics,
machine learning, pattern recognition, databases, and high per-formance computing, data mining extracts useful informationfrom the large data sets now available to industry and science.This collection surveys the most recent advances in the field andcharts directions for future research.
The first part looks at pervasive, distributed, and stream datamining, discussing topics that include distributed data mining al-gorithms for new application areas, several aspects of next-gen-eration data mining systems and applications, and detection ofrecurrent patterns in digital media. The second part considersdata mining, counter-terrorism, and privacy concerns, examin-ing such topics as biosurveillance, marshalling evidence throughdata mining, and link discovery. The third part looks at scientificdata mining; topics include mining temporally-varying phenom-ena, data sets using graphs, and spatial data mining. The last partconsiders web, semantics, and data mining, examining advancesin text mining algorithms and software, semantic webs, and oth-er subjects.
ISBN 0-262-61203-8 576 pp, index.
$40.00 softcover Copublished by The MIT Press
New Directions in Question Answering
Edited by Mark Maybury
Question answering systems, which provide natural lan-guage responses to natural language queries, are the sub-ject of rapidly advancing research encompassing both
academic study and commercial applications, the most well-known of which is the search engine Ask Jeeves. Question answer-ing draws on different fields and technologies, including naturallanguage processing, information retrieval, explanation genera-tion, and human computer interaction. Question answering cre-ates an important new method of information access and can beseen as the natural step beyond such standard Web search meth-ods as keyword query and document retrieval. This collectioncharts significant new directions in the field, including temporal,spatial, definitional, biographical, multimedia, and multilingualquestion answering. After an introduction that defines essentialterminology and provides a roadmap to future trends, the bookcovers key areas of research and development. These include cur-rent methods, architecture requirements, and the history of ques-tion answering on the Web; the development of systems to ad-dress new types of questions; interactivity, which is often requiredfor clarification of questions or answers; reuse of answers; ad-vanced methods; and knowledge representation and reasoningused to support question answering. Each section contains an in-troduction that summarizes the chapters included and placesthem in context, relating them to the other chapters in the bookas well as to the existing literature in the field and assessing theproblems and challenges that remain.
ISBN 0-262-63304-3 352 pp., index.
$40.00 softcover Copublished by The MIT Pres