architecture of high end processors
TRANSCRIPT

Topic Architecture of High End Processors
Core 2 Duo-Core I5
2
• Ahsan Zafar 12063122-087
• Naeem Raza 12063122-084•
Zain-ul-Hassan 12063122-049•
Fahad Ali Amjad 12063122-027•
Mohsin Raza 12063122-019
Group Members University Of Gujrat (Pakistan)

3
What is a High End Microprocessor?
The Microprocessors that are:
• Usually expensive as compared to other types of Microprocessors
• Superior in Quality
• More Sophisticated

4
Micro-Architecture?
• Microarchitecture (sometime abbreviated to µarch or uarch) is a description of the electrical circuitry of a computer, central processing unit, or digital signal processor that is sufficient for completely describing the operation of the hardware.
5
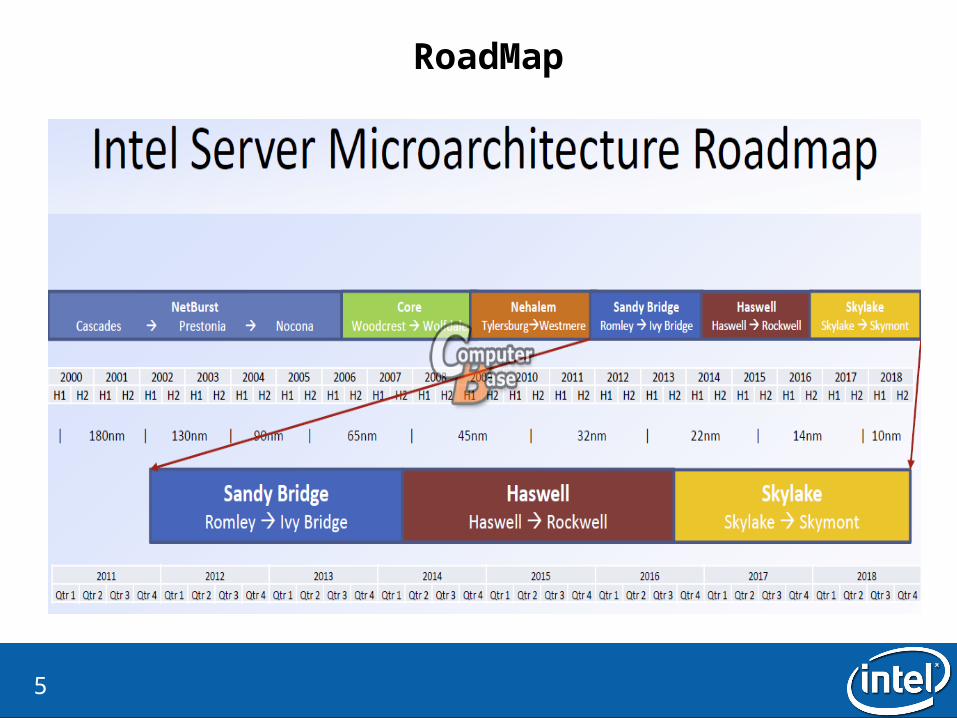
RoadMap

6
Core Micro-Architecture
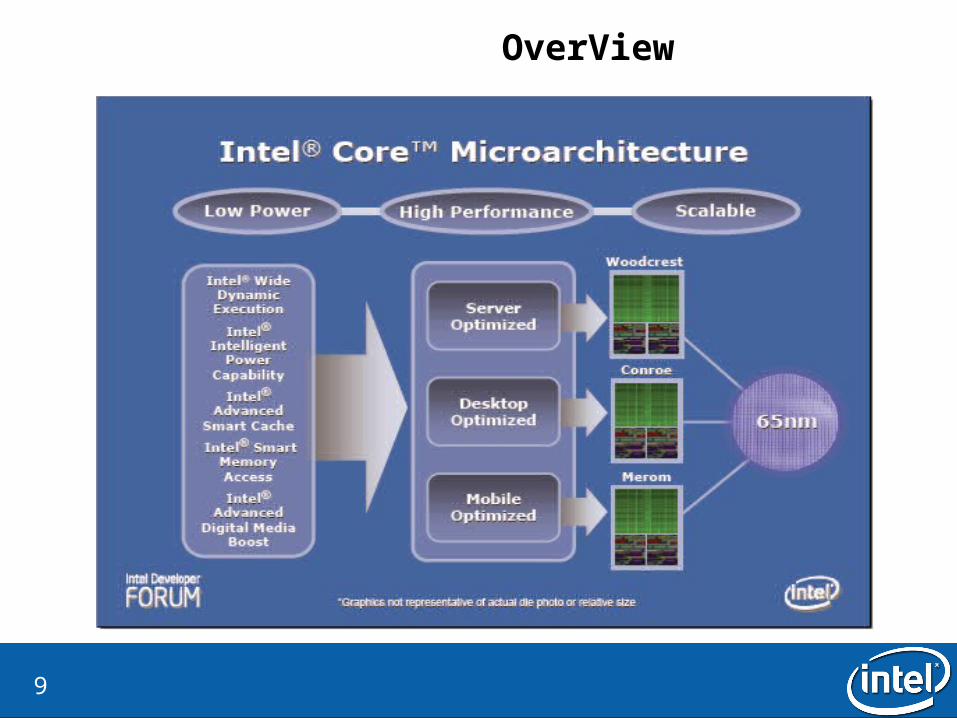
• The Intel Core Microarchitecture is a new foundation for Intel architecture-based desktop, mobile, and mainstream server multi-core processors
• Designed for efficiency and optimized performance across a range of market segments and power envelopes

7
Core Micro-Architecture
Intel Core Microarchitecture based processors:• DP Server
Dual-core Intel® Xeon® 51xx ProcessorsQuad-core codenamed Clovertown
• DesktopDual-core Intel® Core™ 2 Duo ProcessorsQuad-core codenamed Kentsfield
• MobileDual-core Intel® Core™ 2 Duo Processors

8
OverView
9
OverView

10
Architectural Features of Core 2
• Intel Wide Dynamic Execution
• Intel Intelligent Power Capability
• Intel Advanced Smart Cache
• Intel Smart Memory Access
• Intel Advanced Digital Media Boost
11
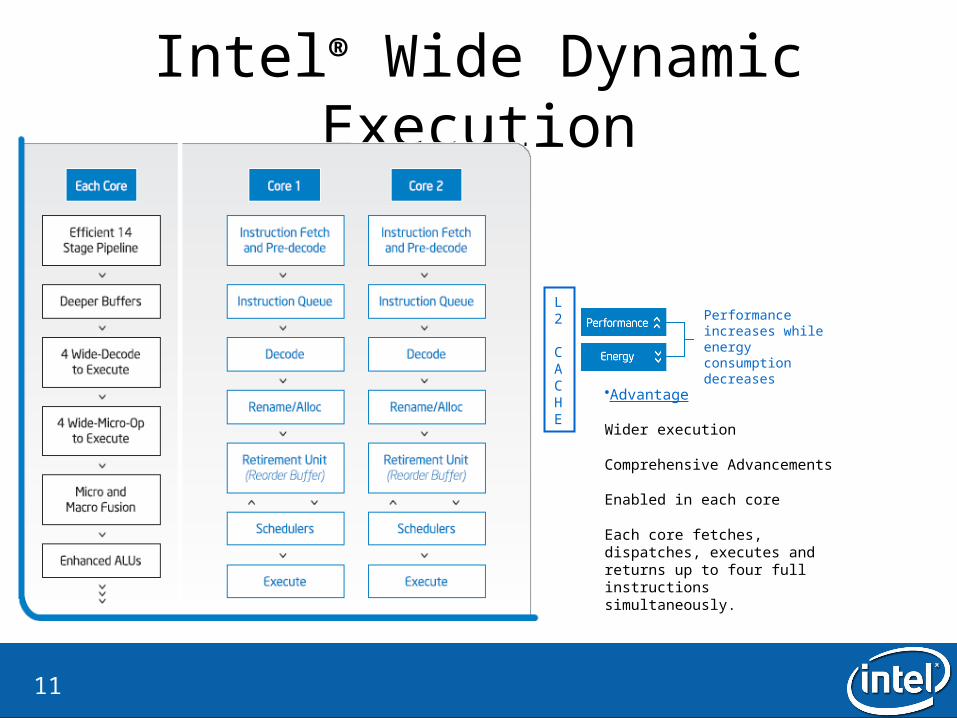
Intel® Wide Dynamic Execution
•Advantage
Wider execution
Comprehensive Advancements
Enabled in each core
Each core fetches, dispatches, executes and returns up to four full instructions simultaneously.
Performance increases while energy consumption decreases
L2
CACHE

12
What is L1 and L2?
• Level-1 and Level-2 caches• The cache memories in a computer• Much faster than RAM• L1 is built on the microprocessor chip itself.• L2 is a seperate chip• L2 cache is much larger than L1 cache
13
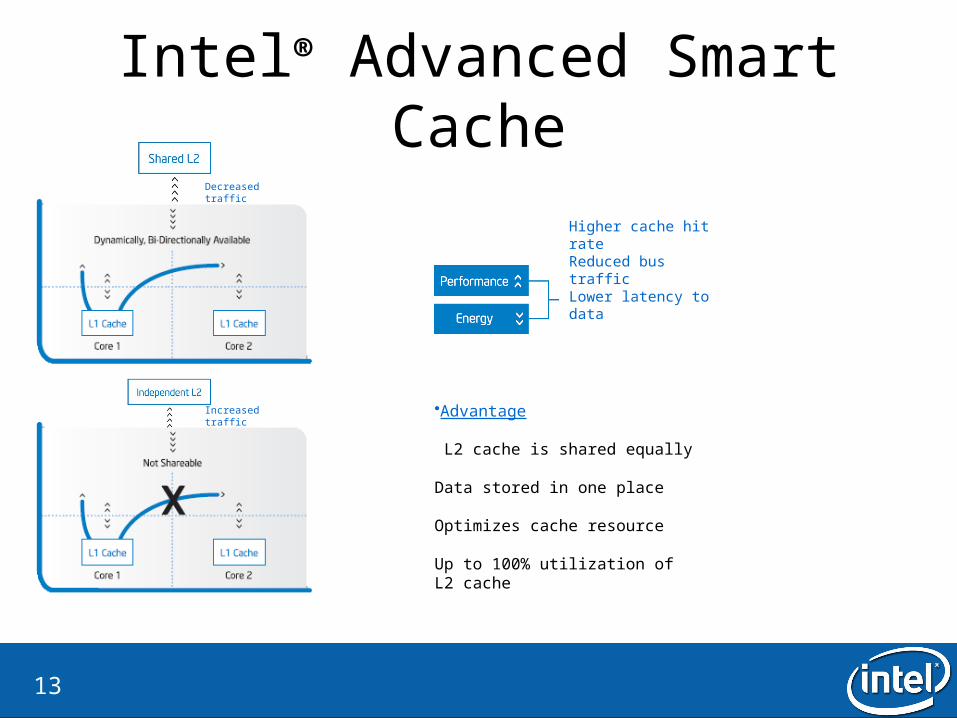
Intel® Advanced Smart Cache
Decreased traffic
Increased traffic
Higher cache hit rateReduced bus trafficLower latency to data
•Advantage
L2 cache is shared equally
Data stored in one place
Optimizes cache resource
Up to 100% utilization of L2 cache
14
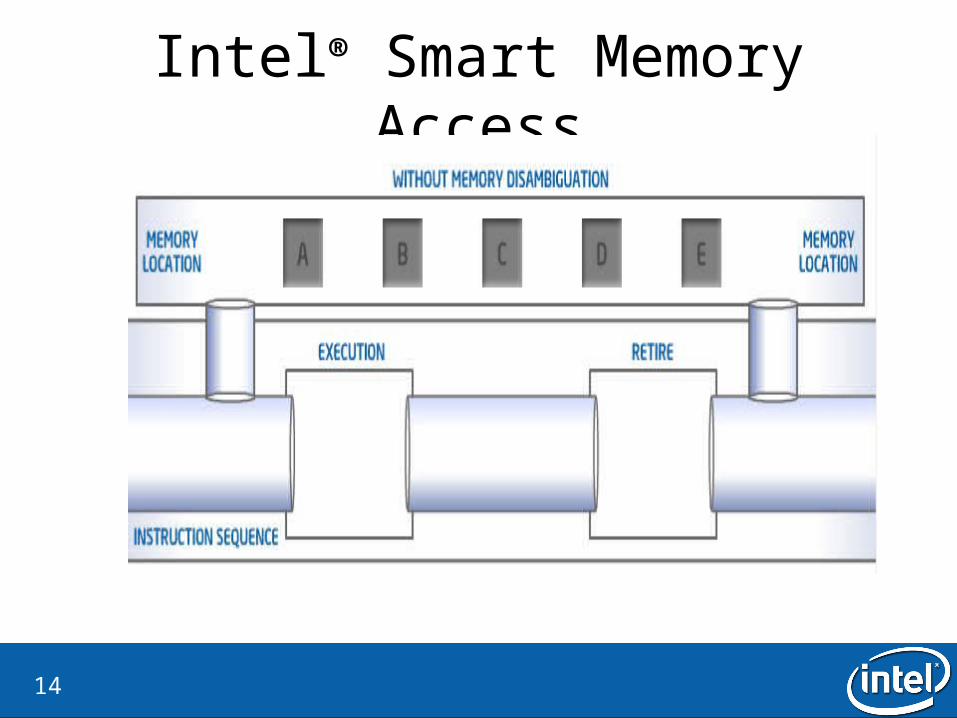
Intel® Smart Memory Access

15
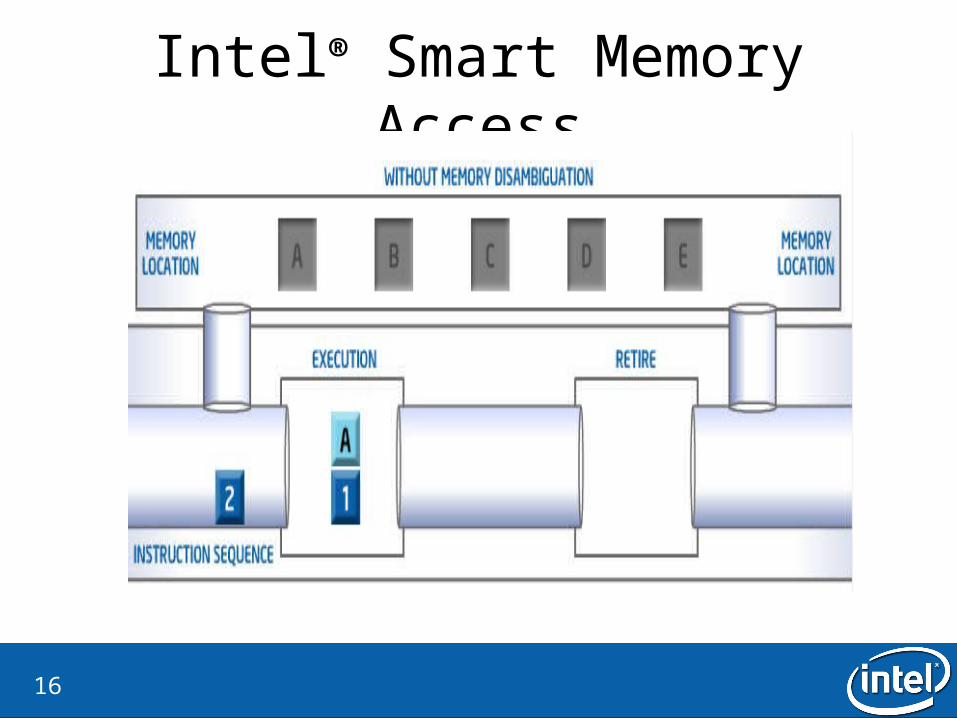
Intel® Smart Memory Access
16
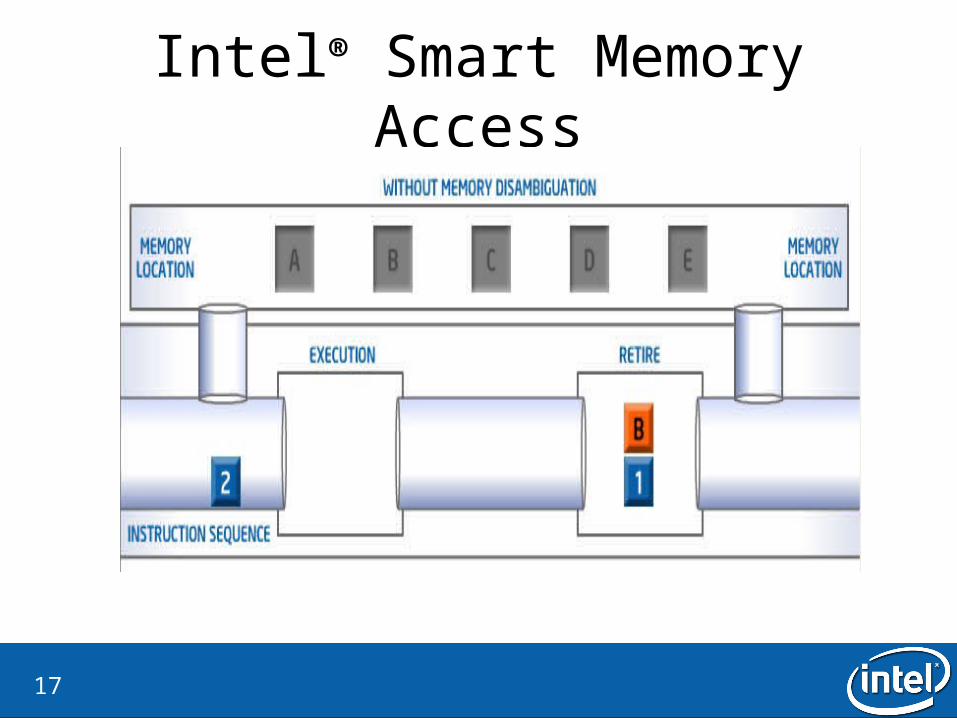
Intel® Smart Memory Access
17
Intel® Smart Memory Access
18
Intel® Smart Memory Access
19
Intel® Smart Memory Access
20
Intel® Smart Memory Access
21
Intel® Smart Memory Access
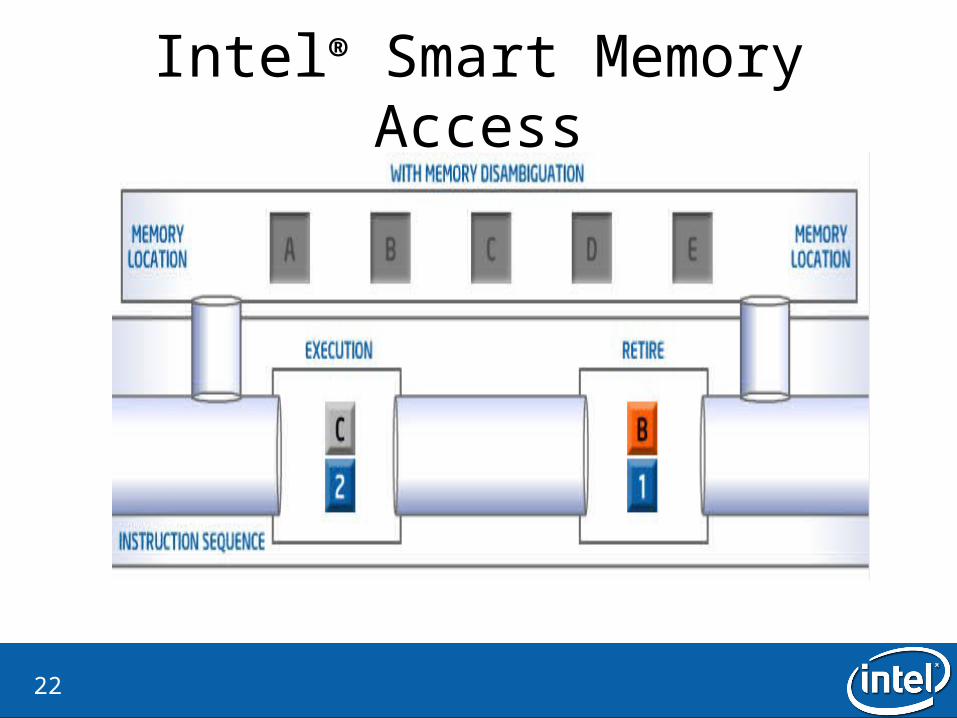
22
Intel® Smart Memory Access

23
Intel® Smart Memory Access
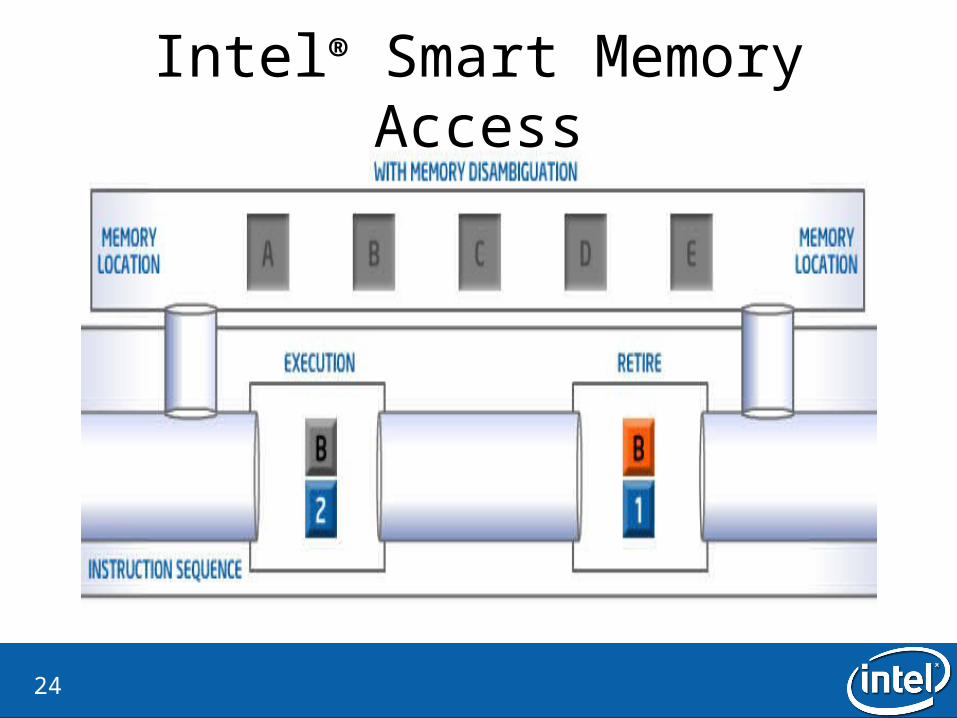
24
Intel® Smart Memory Access
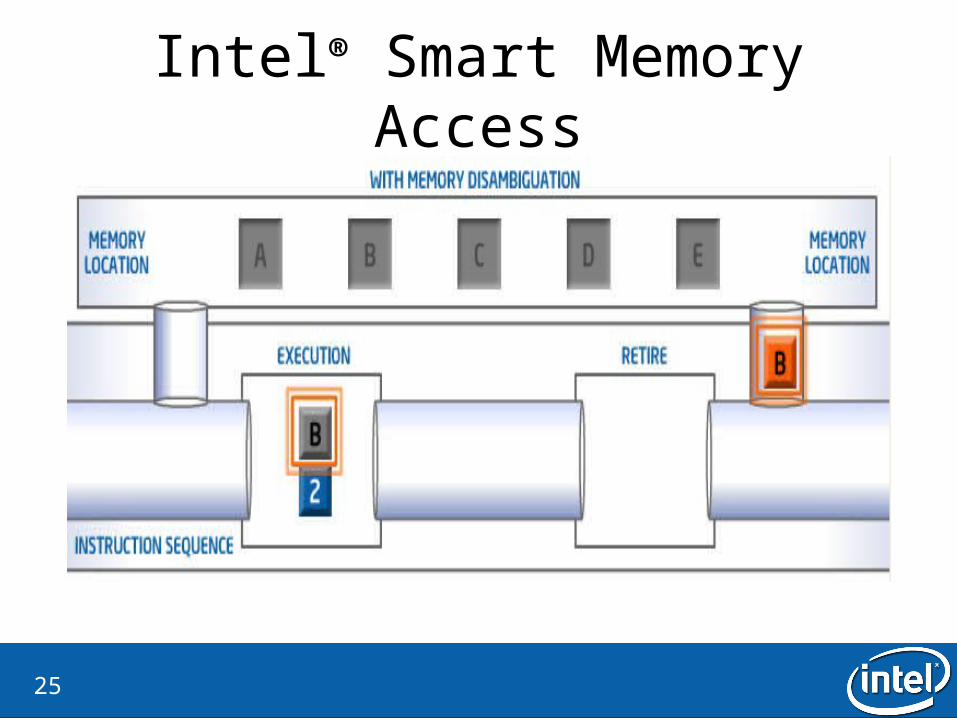
25
Intel® Smart Memory Access

26
Intel® Smart Memory Access

27
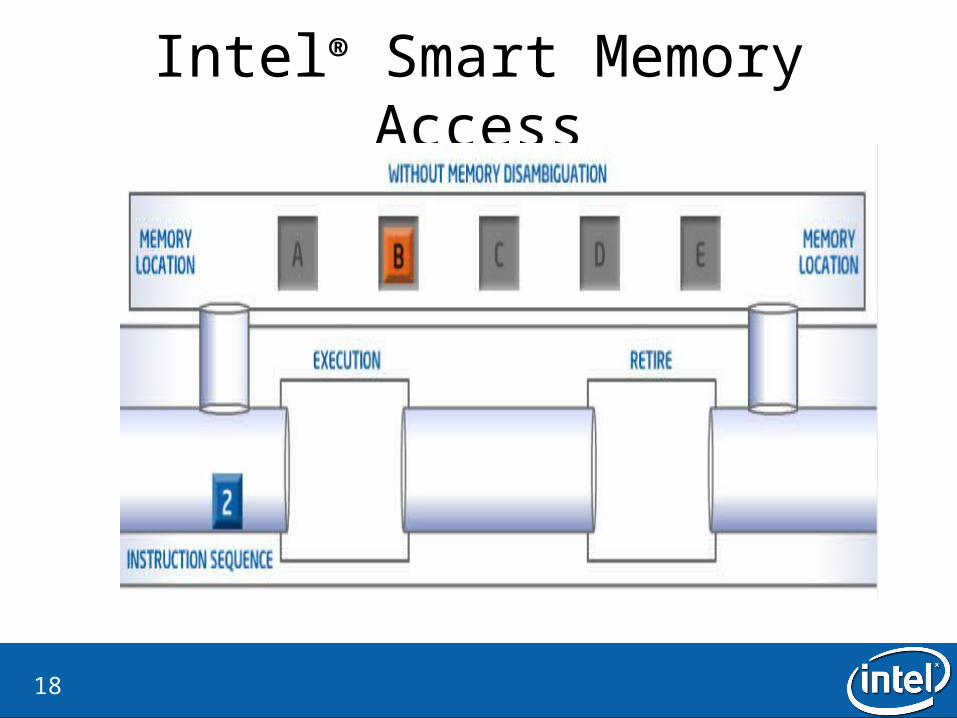
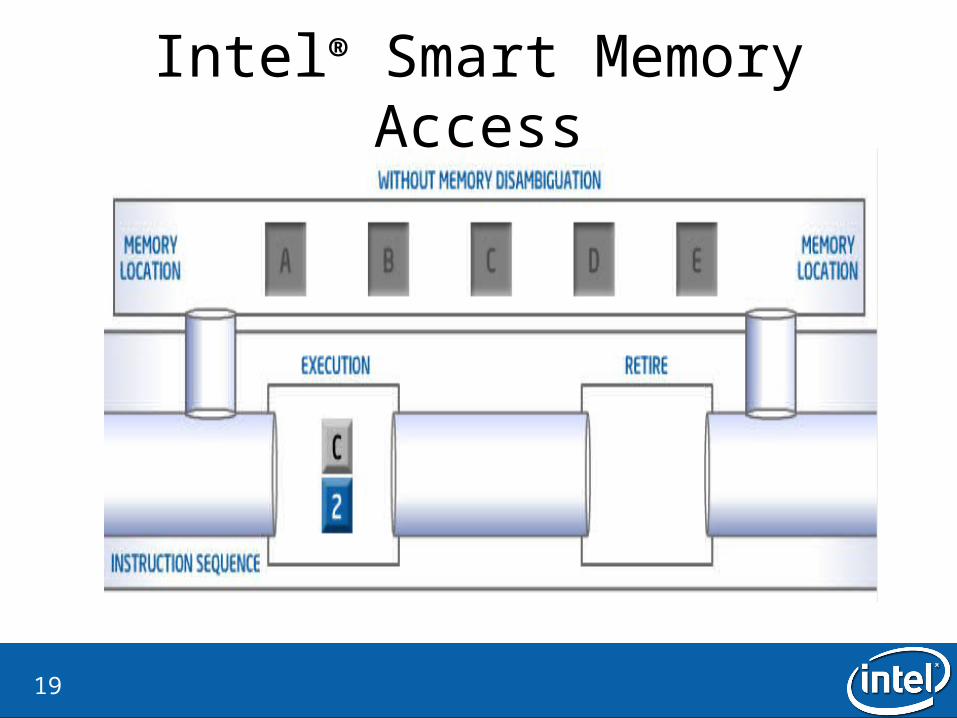
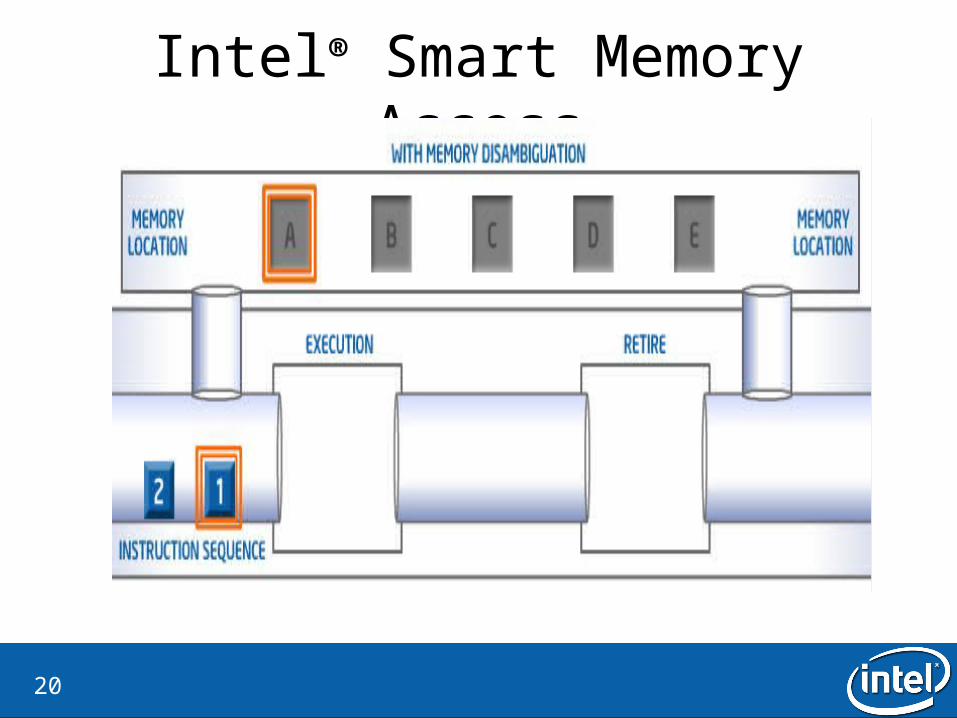
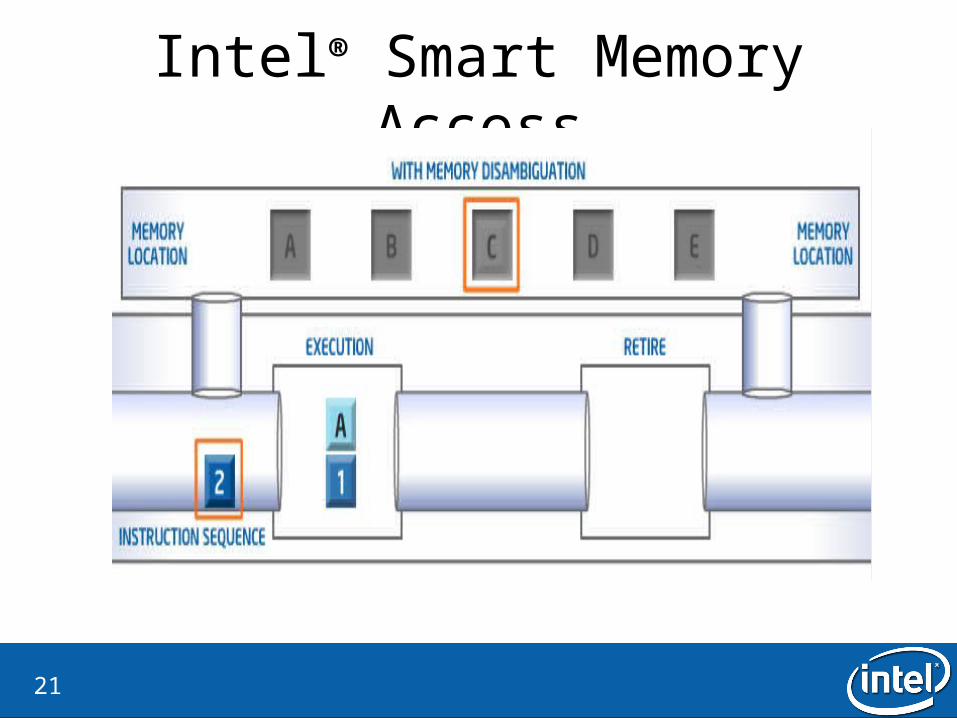
Intel® Smart Memory Access• Why?
– Lost opportunities for out-of-order execution.
• What is the idea?– Ignore the store-load dependecies– If there is a dependency, flash the load instruction
• How is it checked?– Verify by checking all dispatched store addresses in the memory order buffer– There is a watchdog
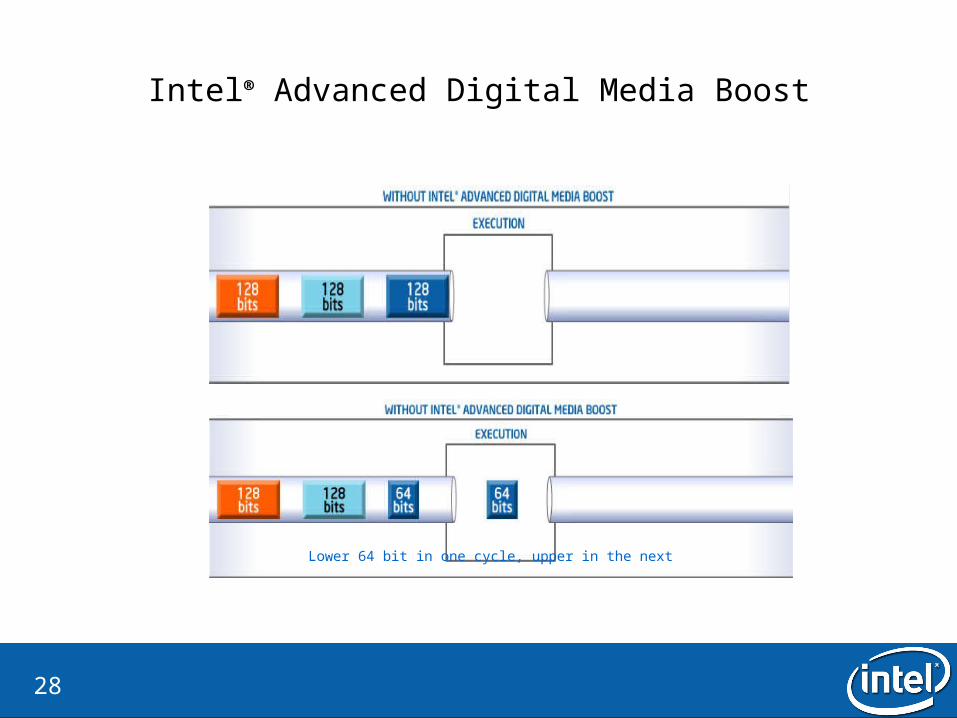
28
Intel® Advanced Digital Media Boost
Lower 64 bit in one cycle, upper in the next

29
Intel® Advanced Digital Media Boost
128 bit instruction completed in one cycle

30
Intel® Advanced Digital Media Boost
• Accelerate a broad range of applications– Video, speech, image processing– Encryption– Financial– Engineering and scientific

31
Nehalam Micro-Architecture
• Nehalem is the codename for an Intel processor microarchitecture, successor to the Core microarchitecture.
• Nehalem processors use the 45 nm process.• The first processor released with the Nehalem
architecture was the desktop Core i7

32
Nehalem Micro-Architecture
• Nehalam Based Processors are:
Core I3
Core I5
Core I7
Nehalam Micro-Architecture was Replaced By Sandy-Bridge Micro-Architecture.
3333
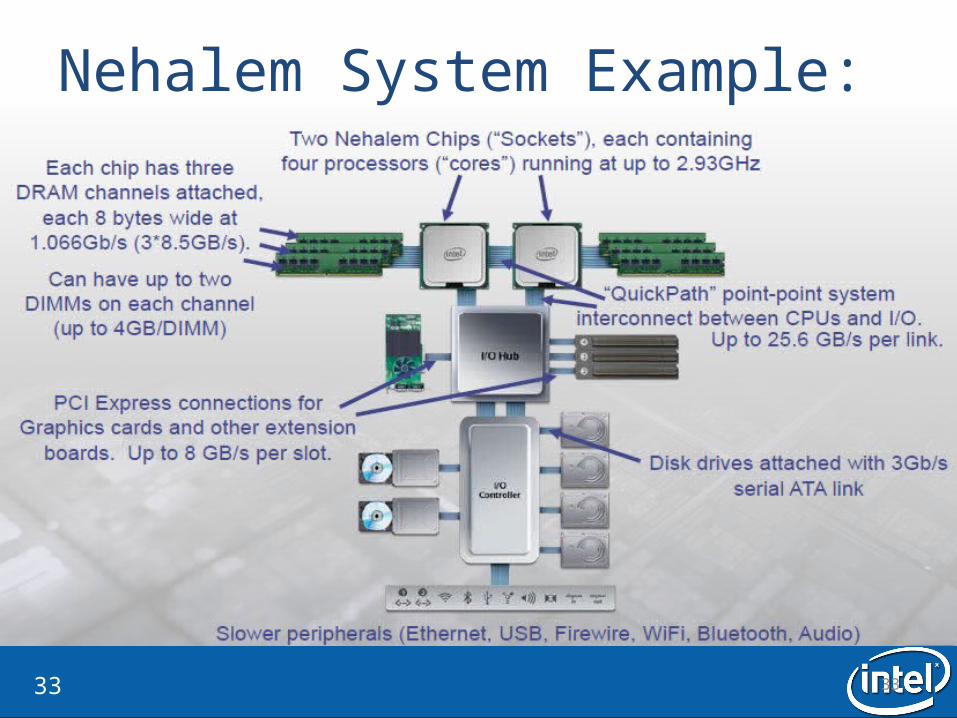
Nehalem System Example:

3434
Building Blocks

3535
Overview of Nehalem Processor Chip• Four identical compute core• UIU: Un-core interface unit• L3 cache memory and data block memory
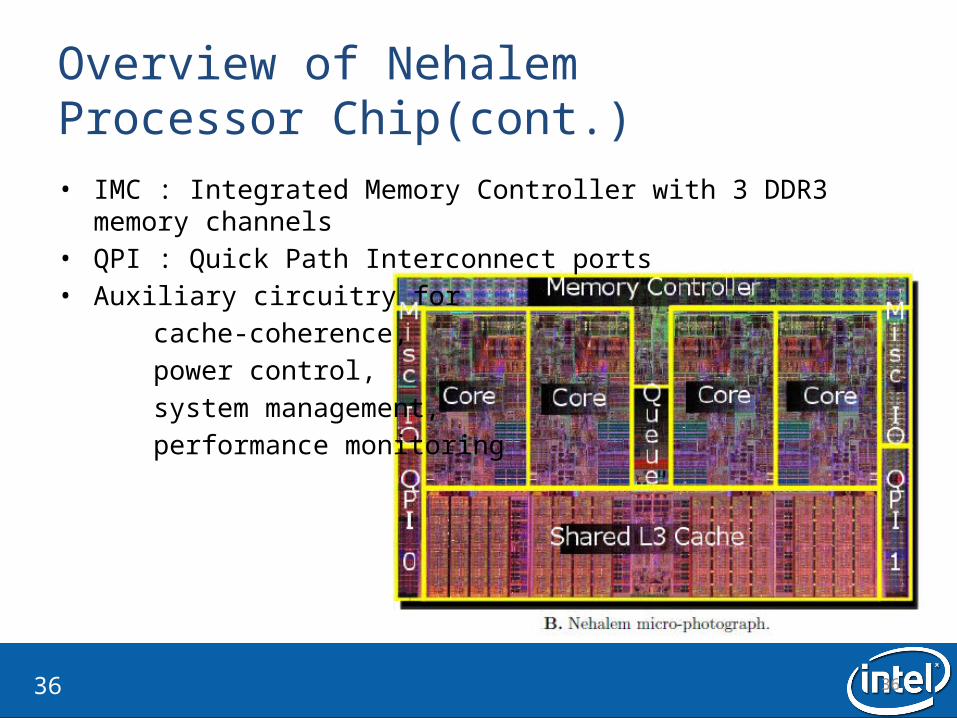
3636
Overview of Nehalem Processor Chip(cont.)• IMC : Integrated Memory Controller with 3 DDR3 memory channels• QPI : Quick Path Interconnect ports• Auxiliary circuitry for cache-coherence, power control, system management, performance monitoring

3737
Overview of Nehalem Processor Chip(cont.)
• Chip is divided into two domains: “Un-core” and “core”
• “Core” components operate with a same clock frequency of the actual Core• “Un-Core” components operate with different frequency.
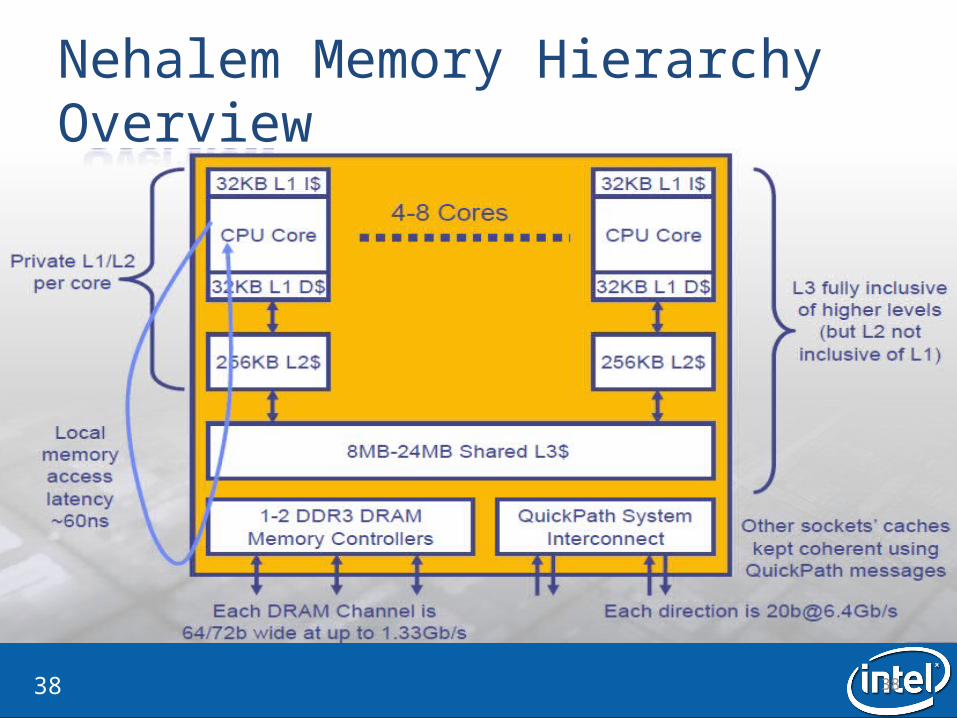
3838
Nehalem Memory Hierarchy Overview

3939
Cache Hierarchy Latencies
• L1 32KB 8-way, Latency 4 cycles• L2 256KB 8-way, Latency < 12 cycles• L3 8MB shared , 16-way, Latency 30-40 cycles (4 core system)• L3 24MB shared, 24-way, Latency 30-60 cycles(8 core system)• DRAM , Latency ~ 180 – 200 cycles
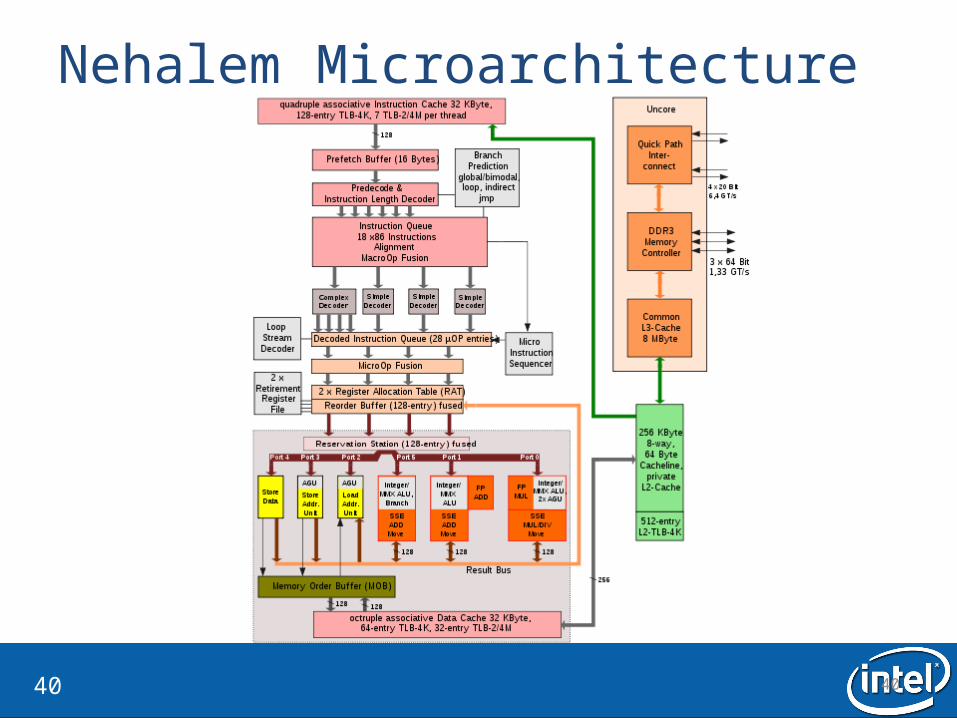
4040
Nehalem Microarchitecture

4141
Instruction Execution
4242
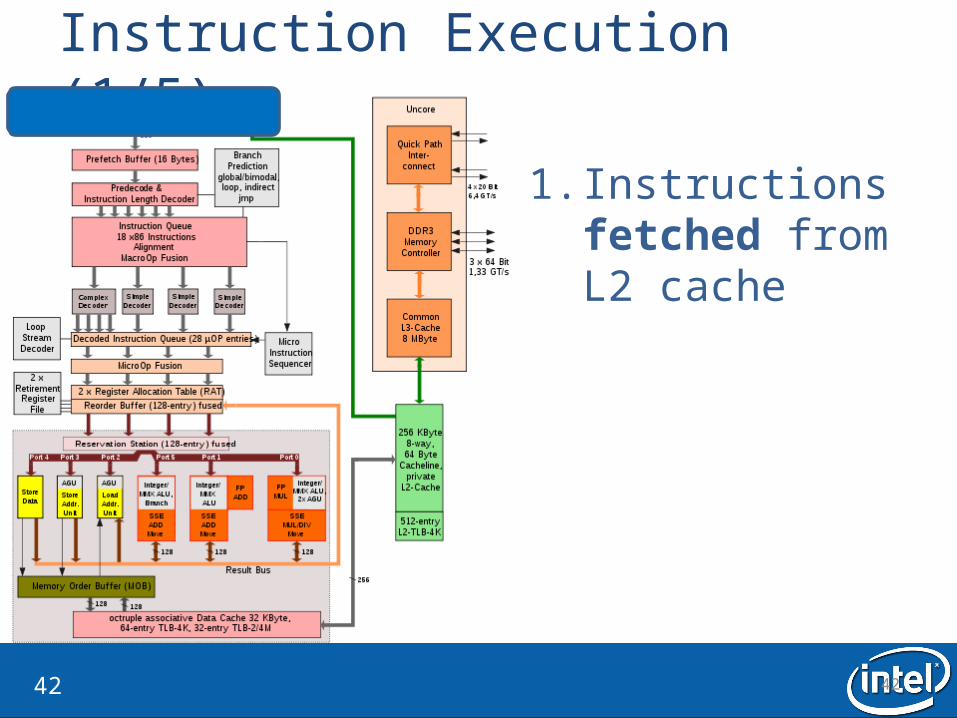
Instruction Execution (1/5)
1. Instructions fetched from L2 cache
4343
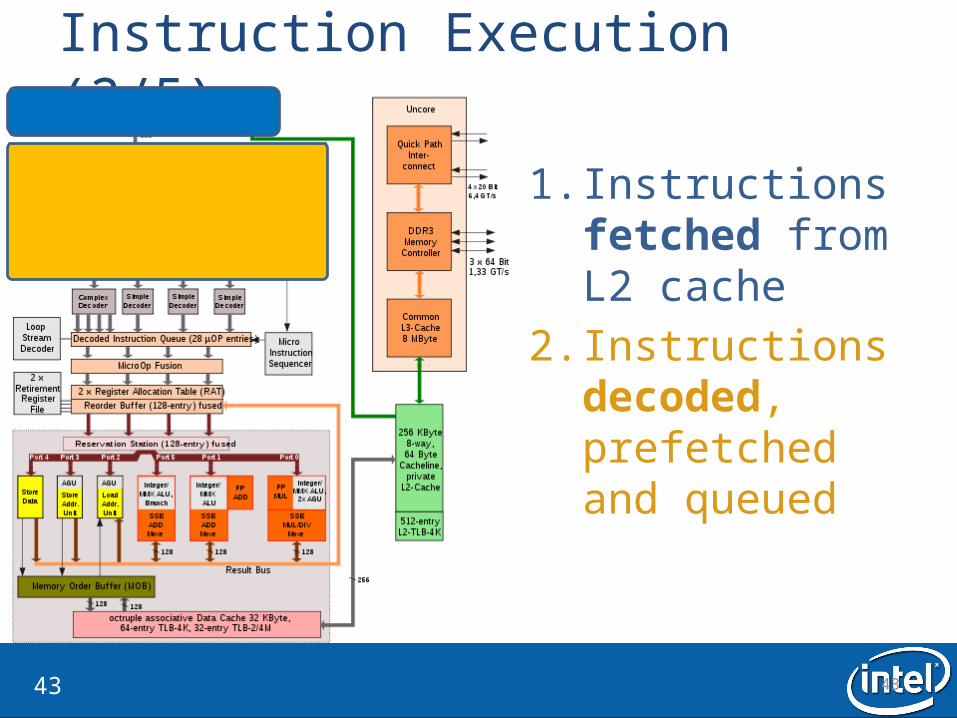
Instruction Execution (2/5)
1. Instructions fetched from L2 cache
2. Instructions decoded, prefetched and queued

4444
Instruction Execution (3/5)
1. Instructions fetched from L2 cache
2. Instructions decoded, prefetched and queued
3. Instructions optimized and combined
4545
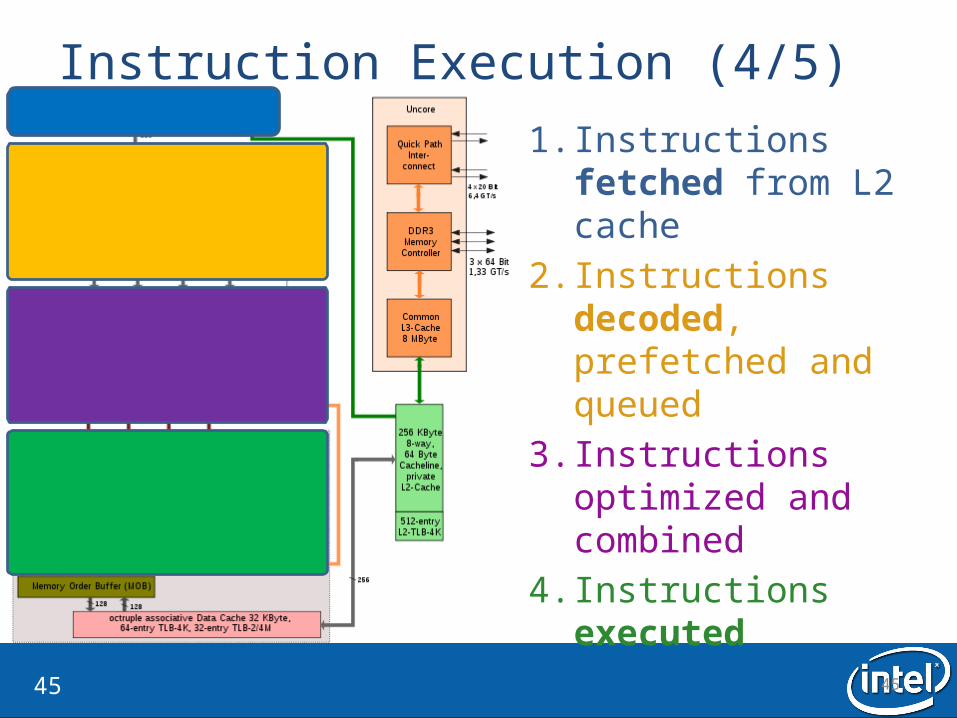
Instruction Execution (4/5)1. Instructions fetched
from L2 cache2. Instructions
decoded, prefetched and queued
3. Instructions optimized and combined
4. Instructions executed
4646
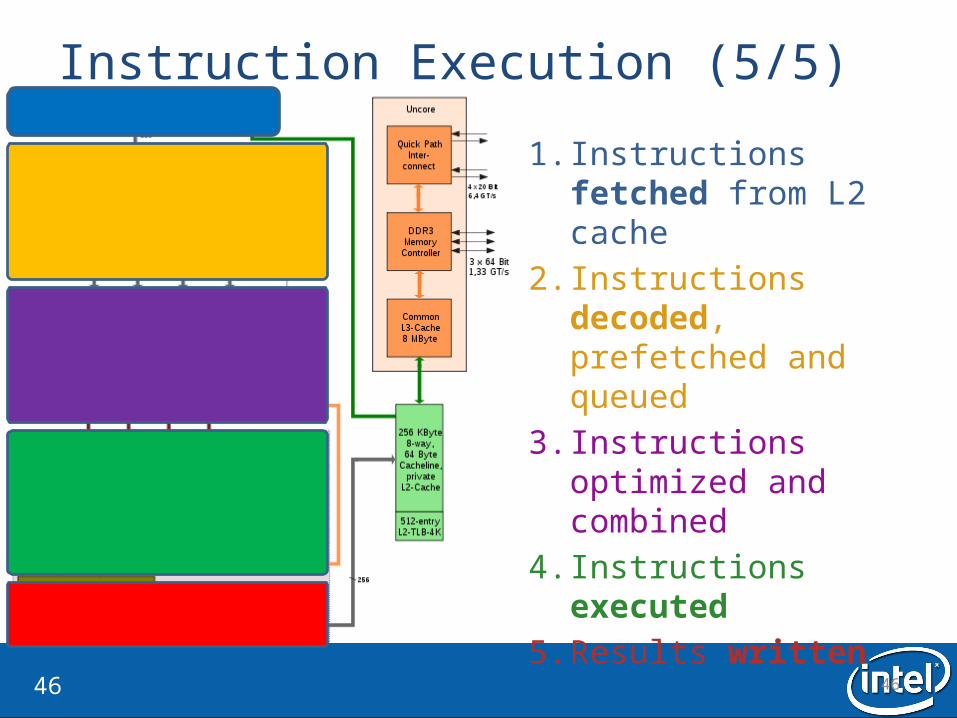
Instruction Execution (5/5)
1. Instructions fetched from L2 cache
2. Instructions decoded, prefetched and queued
3. Instructions optimized and combined
4. Instructions executed5. Results written
4747
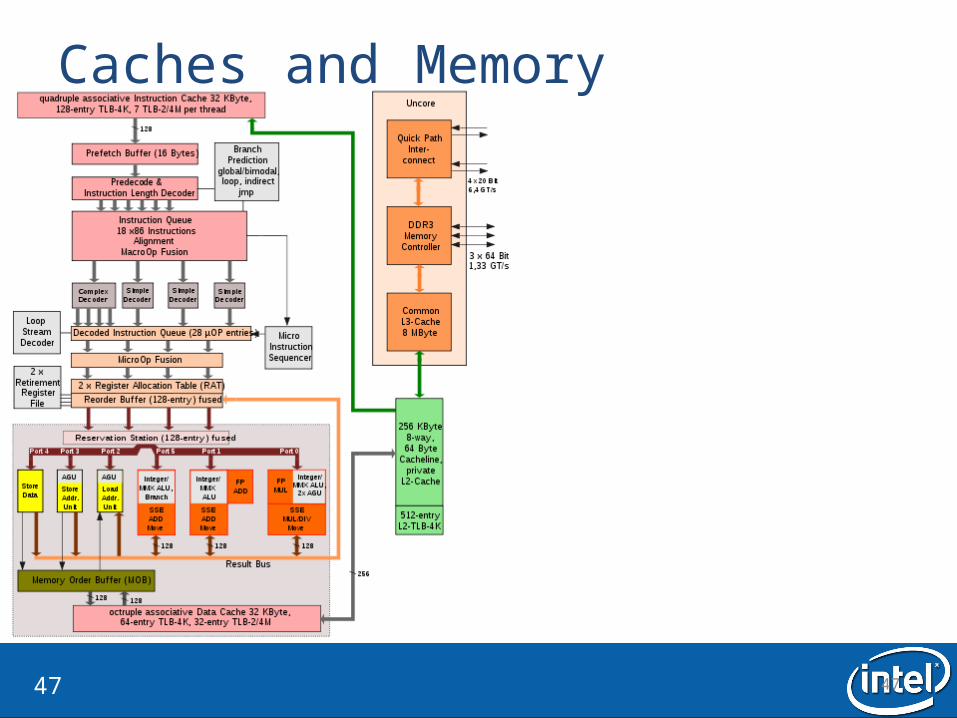
Caches and Memory
4848
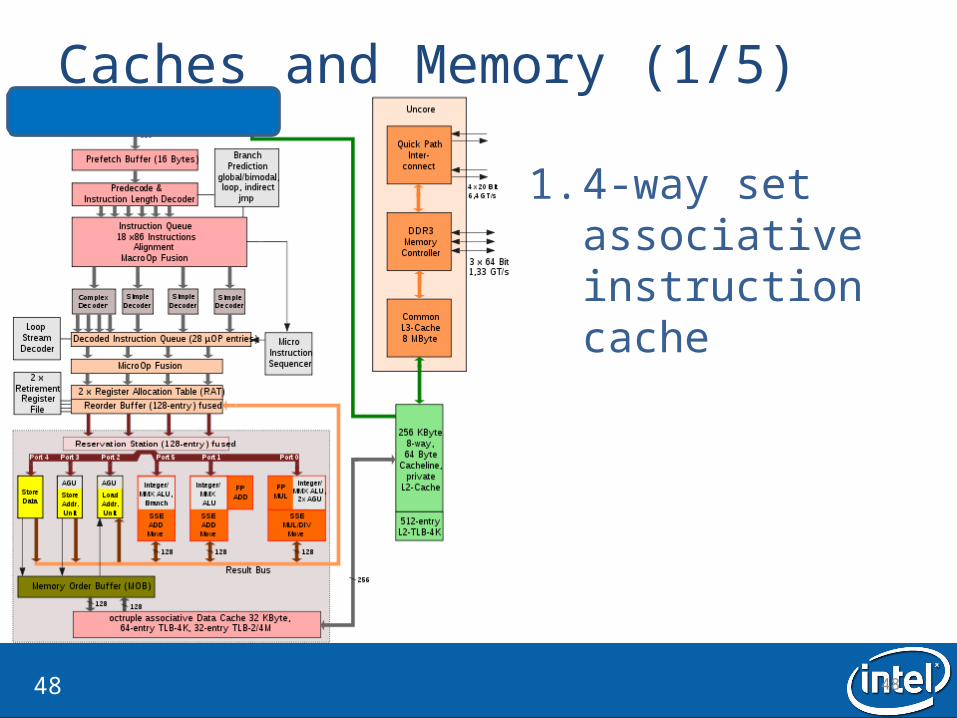
Caches and Memory (1/5)
1. 4-way set associative instruction cache
4949
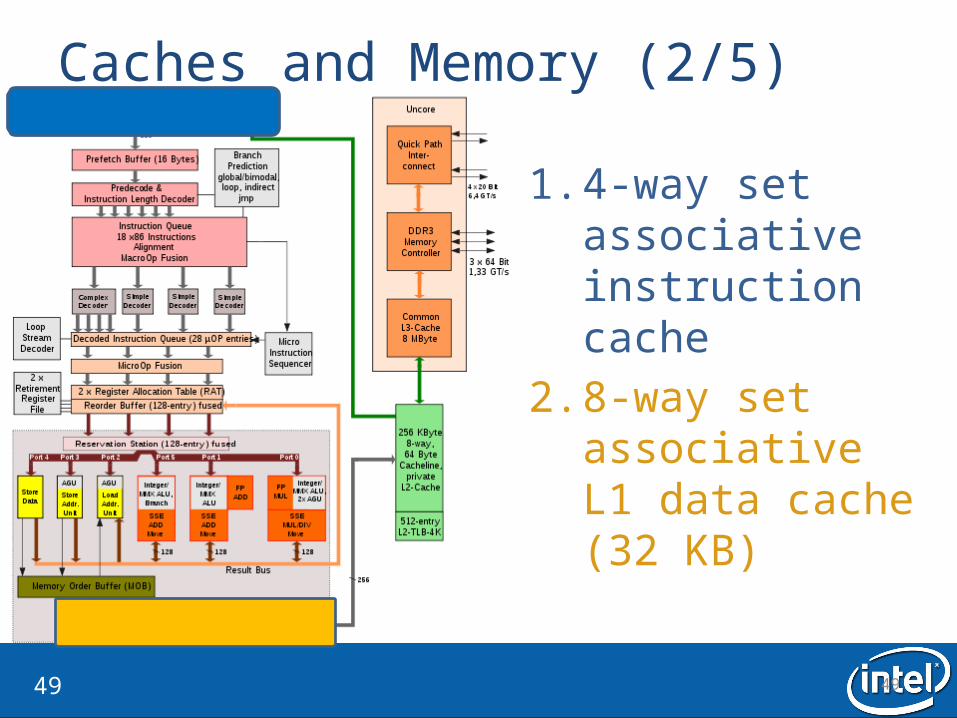
Caches and Memory (2/5)
1. 4-way set associative instruction cache
2. 8-way set associative L1 data cache (32 KB)
5050
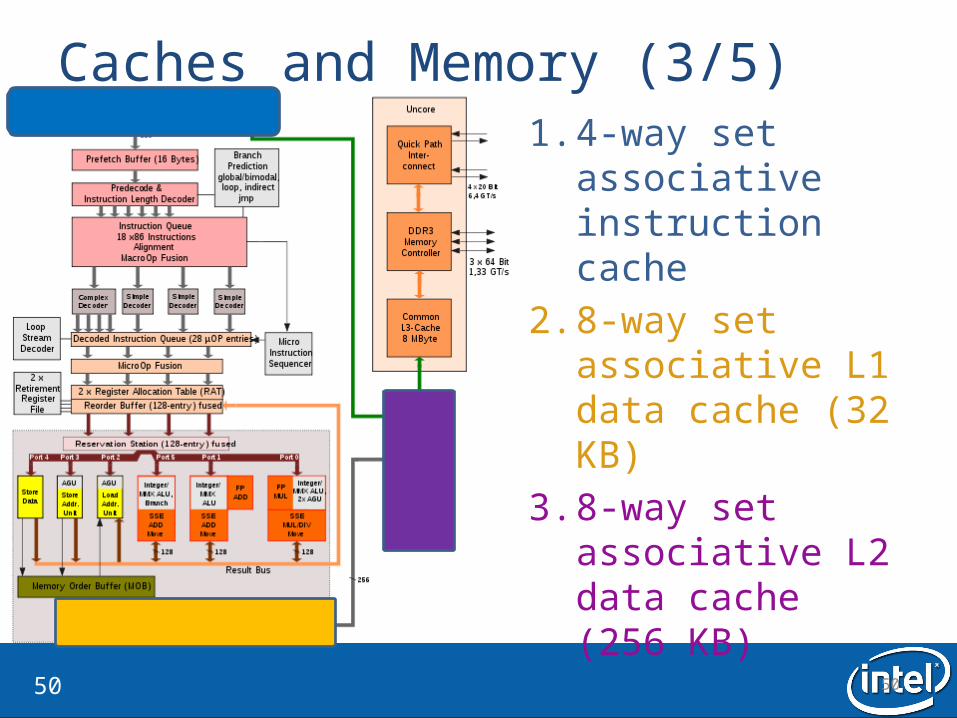
Caches and Memory (3/5)1. 4-way set
associative instruction cache
2. 8-way set associative L1 data cache (32 KB)
3. 8-way set associative L2 data cache(256 KB)
5151
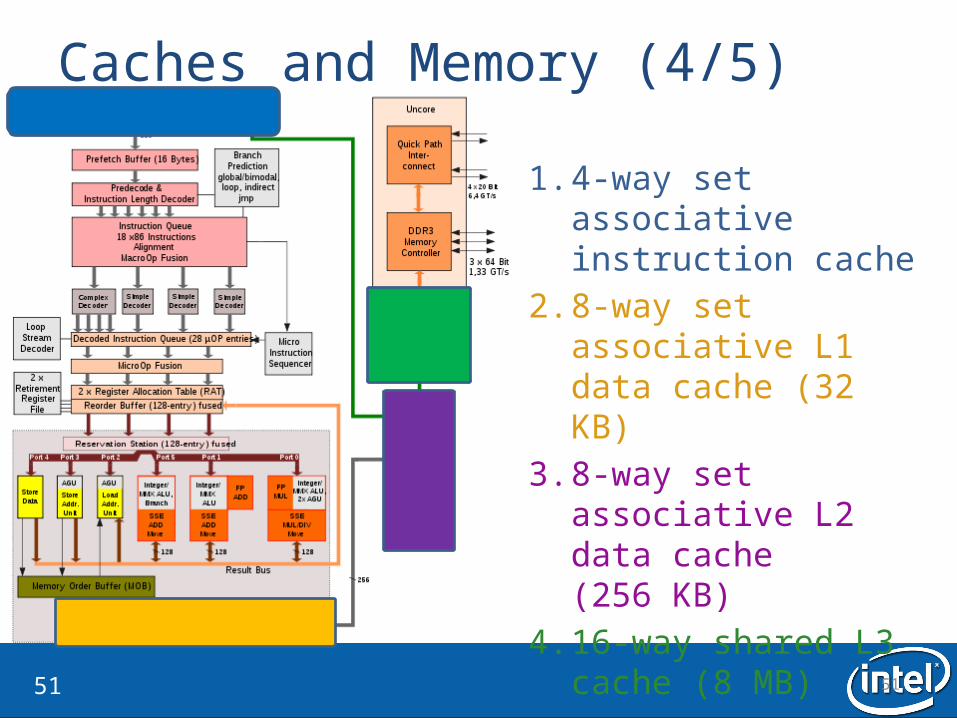
Caches and Memory (4/5)
1. 4-way set associative instruction cache
2. 8-way set associative L1 data cache (32 KB)
3. 8-way set associative L2 data cache(256 KB)
4. 16-way shared L3 cache (8 MB)
5252
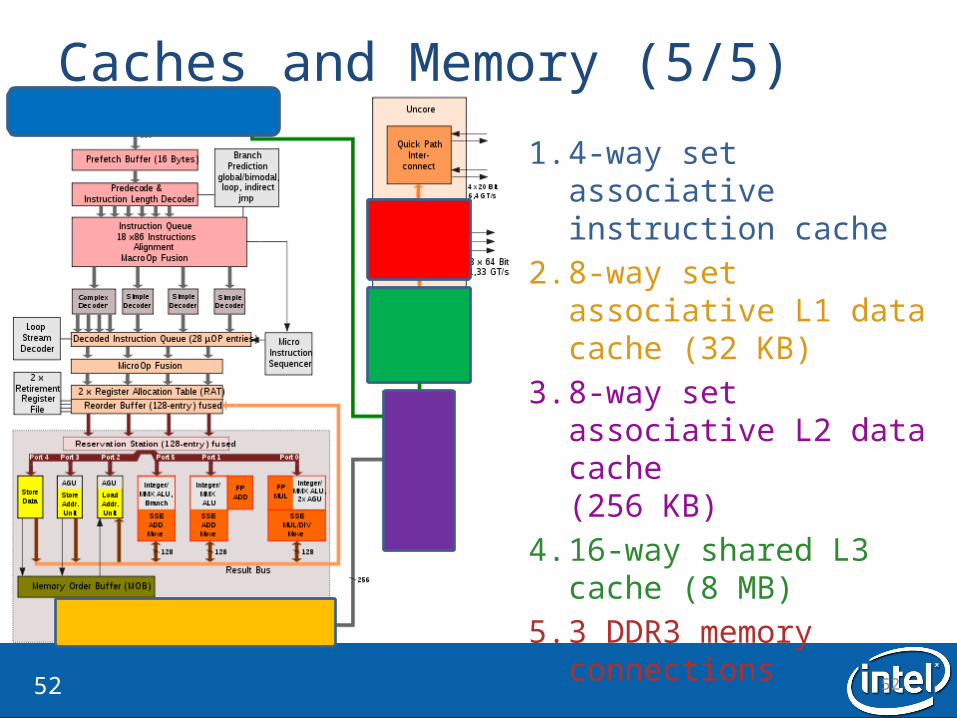
Caches and Memory (5/5)
1. 4-way set associative instruction cache
2. 8-way set associative L1 data cache (32 KB)
3. 8-way set associative L2 data cache(256 KB)
4. 16-way shared L3 cache (8 MB)
5. 3 DDR3 memory connections
5353
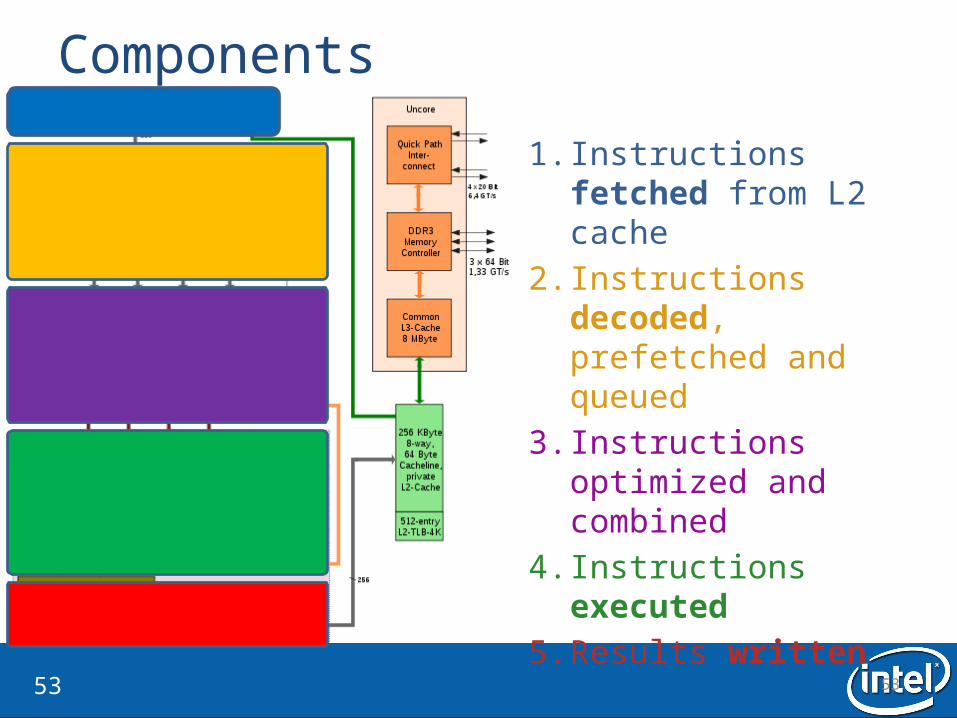
Components
1. Instructions fetched from L2 cache
2. Instructions decoded, prefetched and queued
3. Instructions optimized and combined
4. Instructions executed5. Results written
5454
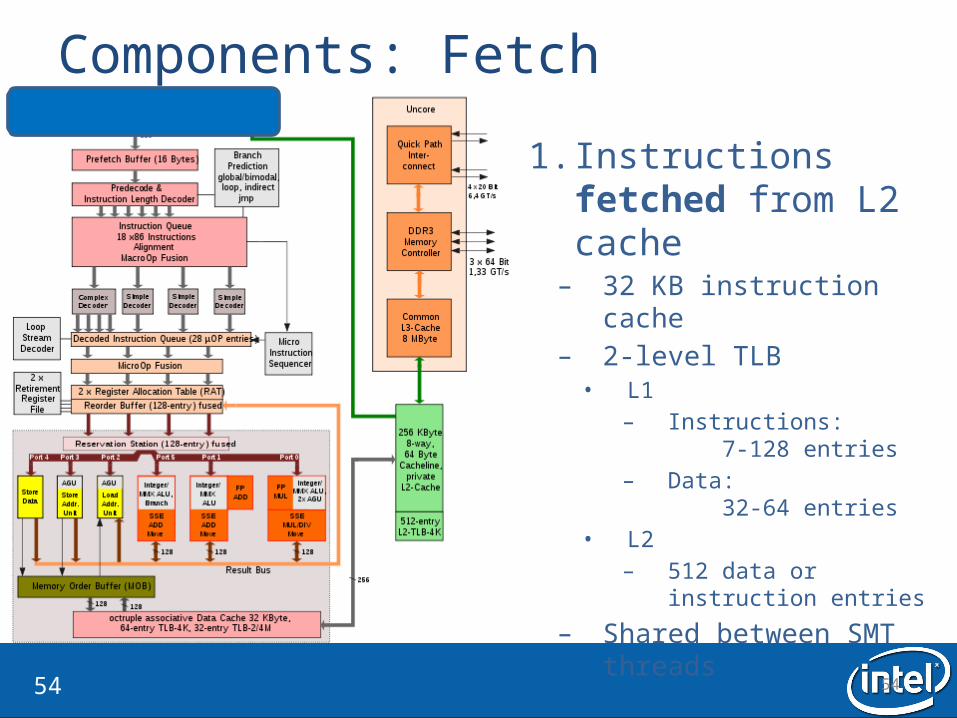
Components: Fetch
1. Instructions fetched from L2 cache– 32 KB instruction cache– 2-level TLB• L1
– Instructions: 7-128 entries
– Data: 32-64 entries
• L2– 512 data or
instruction entries
– Shared between SMT threads
5555
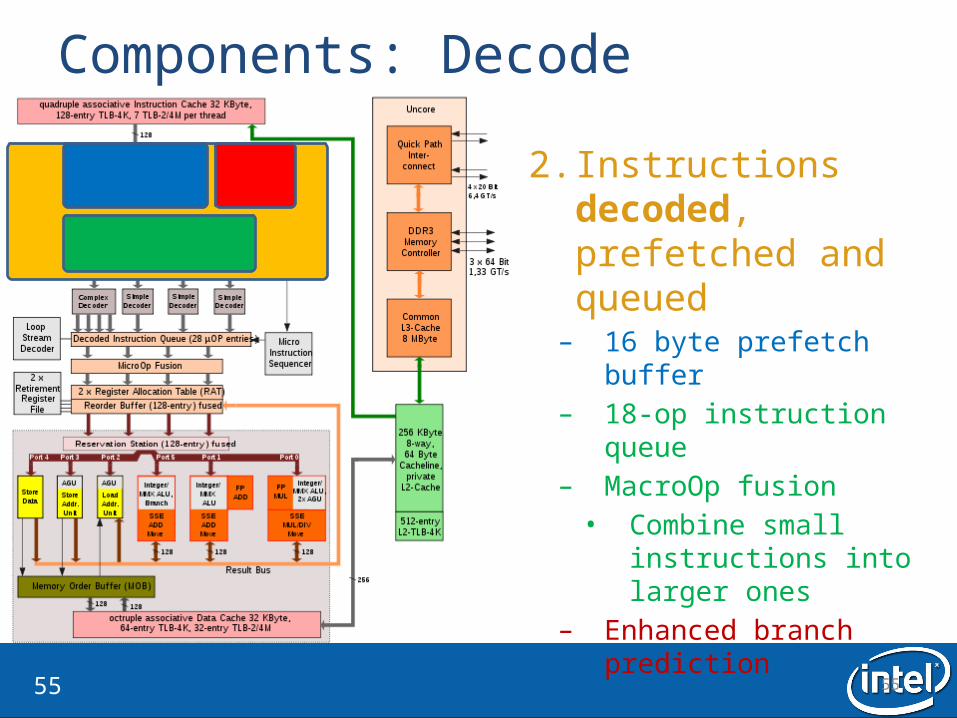
Components: Decode
2. Instructions decoded, prefetched and queued– 16 byte prefetch buffer– 18-op instruction queue– MacroOp fusion• Combine small
instructions into larger ones
– Enhanced branch prediction

5656
Components: Optimization
3. Instructions optimized and combined– 4 op decoders• Enables multiple
instructions per cycle
– 28 MicroOp queue• Pre-fusion buffer
– MicroOp fusion• Create 1 “instruction”
from MicroOps
– Reorder buffer• Post-fusion buffer
5757
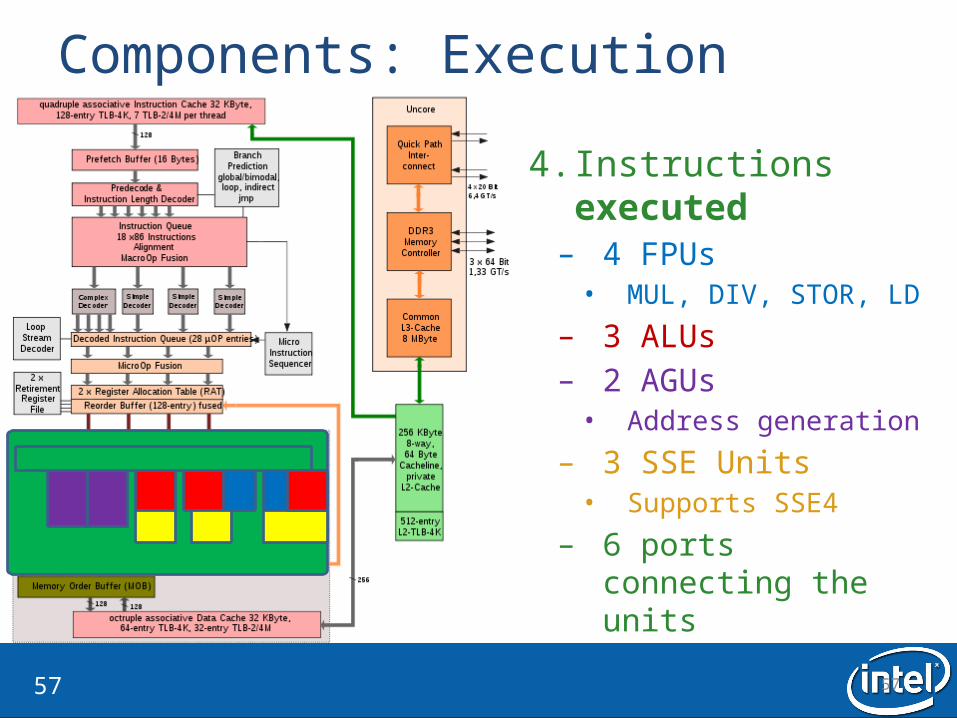
Components: Execution
4. Instructions executed– 4 FPUs• MUL, DIV, STOR, LD
– 3 ALUs– 2 AGUs• Address generation
– 3 SSE Units• Supports SSE4
– 6 ports connecting the units
5858
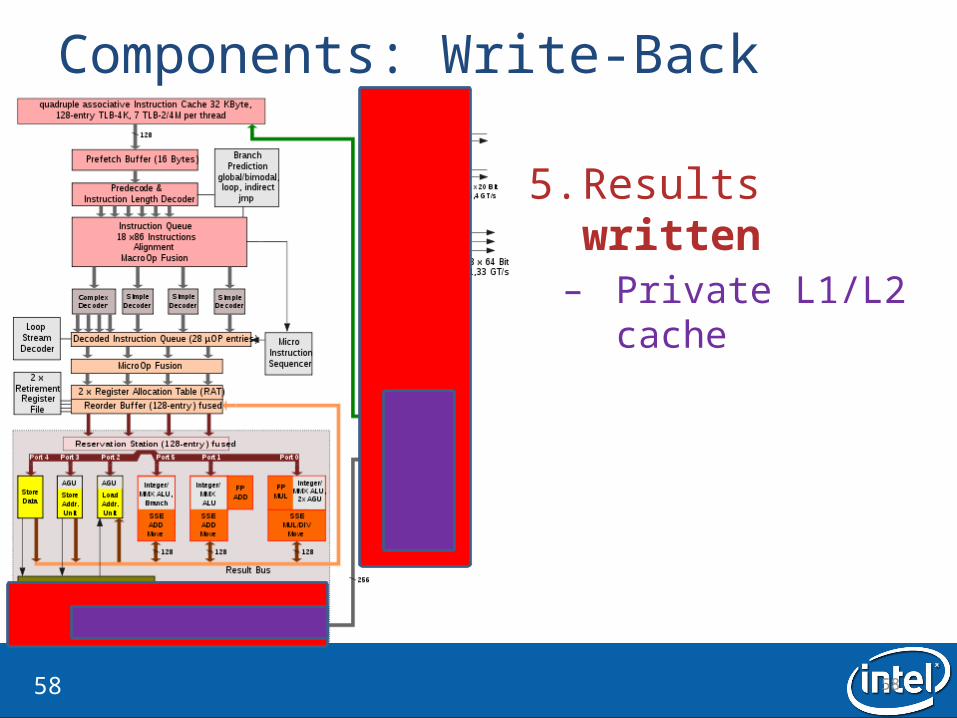
Components: Write-Back
5. Results written– Private L1/L2 cache

5959
Components: Write-Back
5. Results written– Private L1/L2 cache– Shared L3 cache– QuickPath• Dedicated channel to
another CPU, chip, or device
• Replaces FSB