aquery: a database system for order dennis shasha, joint work with alberto lerner...
TRANSCRIPT

Aquery: A DATABASE SYSTEM
FOR ORDER
Dennis Shasha, joint work with Alberto Lerner
{lerner,shasha}@cs.nyu.edu

MotivationThe need for ordered data
• Queries in finance, signal processing etc.
depend on order.
• SQL 99 has extensions but they are clumsy.

Moving Averages is algorithmically linear but…
Sales(month, total)
SELECT t1.month+1 AS forecastMonth, (t1.total+ t2.total + t3.total)/3 AS 3MonthMovingAverageFROM Sales AS t1, Sales AS t2, Sales AS t3WHERE t1.month = t2.month - 1 AND t1.month = t3.month – 2
Can optimizer make a 3-way (in general, n-way) join linear time?
Ref: Data Mining and Statistical Analysis Using SQLTrueblood and LovettApress, 2001

Moving Averages in SQL99 is awkward
Sales(month, total)
Alberto, please put in SQL 99

Choose query from Jennifer Alberto, I suggest query 2 because that may be hard in sql 99.

MotivationProblems Extending SQL with
Order
• Queries are hard to read
• Cost of execution is often non-linear
(would not pass basic algorithms course)
• Few operators preserve order, so
optimization hard.

Idea
• Whatever can be done on a table can be done on an ordered table (arrable). Not vice versa.
• Aquery – query language on arrables; operations on columns.
• Upward compatible from SQL 92.
• Optimization ideas are new, but natural.

SQL + OrderMoving Averages
Sales(month, total)
SELECT month, avgs(8, total)FROM Sales ASSUMING ORDER month
Execution (Sales is an arrable):1. FROM clause – enforces the order in
ASSUMING clause2. SELECT clause – for each month yields
the moving average (window size 8) ending at that month.
avgs: vector-to-vector function, order-
dependant and size-preserving
order to be used on vector-to-vector
functions

SQL + OrderTop N
Employee(ID, salary)
SELECT first(N, salary) FROM Employee ASSUMING ORDER Salary
first: vector-to-vector function, order-
dependant and non size-preserving
Execution:1. FROM clause – orders arrable by Salary2. SELECT clause – applies first() to the
‘salary’ vector, yielding first N values of that vector given the order. Could get the top earning IDs by saying first(N, ID).
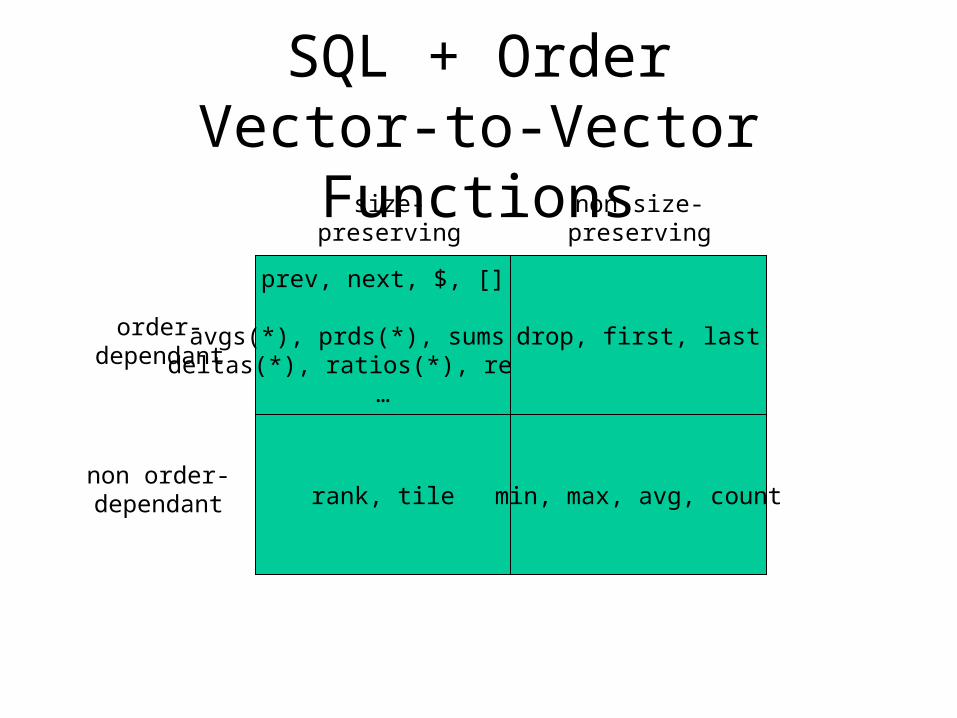
SQL + OrderVector-to-Vector Functions
prev, next, $, []
avgs(*), prds(*), sums(*), deltas(*), ratios(*), reverse,
…
drop, first, lastorder-dependant
non order-dependant
size-preserving
non size-preserving
rank, tile min, max, avg, count

Challenge
• Given a table with securities’ price ticks, ticks(ID, date,
price, timestamp), find the best possible profit if one bought and sold security ‘S’ in a given day
Note that max – min doesn’t work, because must buy before you sell (no selling short).
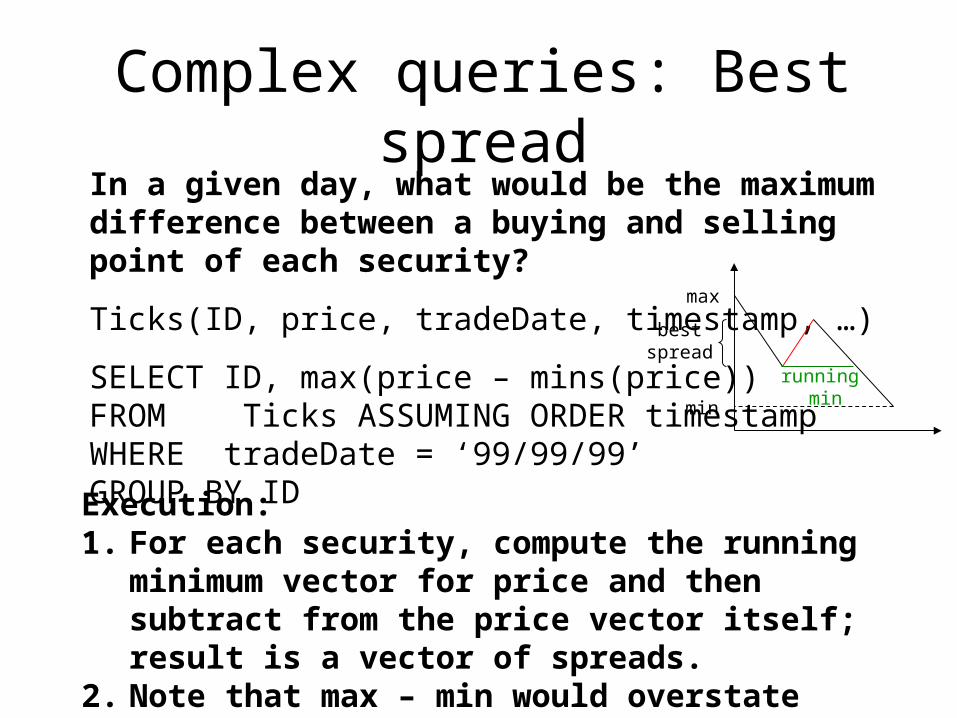
Complex queries: Best spreadIn a given day, what would be the maximum difference between a buying and selling point of each security?
Ticks(ID, price, tradeDate, timestamp, …)
SELECT ID, max(price – mins(price))FROM Ticks ASSUMING ORDER timestampWHERE tradeDate = ‘99/99/99’GROUP BY IDExecution:1. For each security, compute the running
minimum vector for price and then subtract from the price vector itself; result is a vector of spreads.
2. Note that max – min would overstate spread.
max
min
bestspread
running min

Best-profit query
SELECT max(price – mins(price))
FROM ticks
ASSUMING ORDER timestamp
WHERE day = ‘12/09/2002’
AND ID = ‘S’
price 15 19 13 7 4 5 4 7 12 2
mins 15 15 13 7 4 4 4 4 4 4
- 0 4 0 0 0 1 0 3 8 2

Best-profit query comparison
[AQuery]
SELECT max(price–mins(price))
FROM ticks ASSUMING timestamp
WHERE ID=“x”
AND tradeDate='99/99/99'
[SQL:1999]
SELECT max(rdif)
FROM (SELECT ID,tradeDate,
price - min(price)
OVER
(PARTITION BY ID
ORDER BY timestamp
ROWS UNBOUNDED
PRECEDING) AS rdif
FROM Ticks ) AS t1
WHERE ID=“x”
AND tradeDate='99/99/99'

Complex queries: Crossing averages part I
When does the 21-day average cross the 5-month average?
Market(ID, closePrice, tradeDate, …)TradedStocks(ID, Exchange,…)
INSERT INTO temp FROMSELECT ID, tradeDate, avgs(21 days, closePrice) AS a21, avgs(5 months, closePrice) AS a5, prev(avgs(21 days, closePrice)) AS pa21, prev(avgs(5 months, closePrice)) AS pa5FROM TradedStocks NATURAL JOIN Market ASSUMING ORDER tradeDateGROUP BY ID

Complex queries: Crossing averages part uses non 1NF
Execution:1. FROM clause – order-preserving join2. GROUP BY clause – groups are defined
based on the value of the Id column3. SELECT clause – functions are applied;
non-grouped columns become vector fields so that target cardinality is met. Violates first normal form
groups in ID and non-grouped column
grouped ID and non-grouped column
Vector
field
two columns withthe same cardinality

Complex queries: Crossing averages part II
Get the result from the resulting non first normal form relation temp
SELECT ID, tradeDateFROM flatten(temp)WHERE a21 > a5 AND pa21 <= pa5
Execution:1. FROM clause – flatten transforms temp
into a first normal form relation (for row r, every vector field in r MUST have the same cardinality). Could have been placed at end of previous query.
2. Standard query processing after that.

SQL + OrderRelated Work: Research
• SEQUIN – Seshadri et al.– Sequences are first-class objects– Difficult to mix tables and sequences.
• SRQL – Ramakrishnan et al.– Elegant algebra and language– No work on transformations.
• SQL-TS – Sadri et al.– Language for finding patterns in sequence– But: Not everything is a pattern!

SQL + OrderRelated Works: Products
• RISQL – Red Brick– Some vector-to-vector, order-dependent, size-
preserving functions– Low-hanging fruit approach to language design.
• Analysis Functions – Oracle 9i– Quite complete set of vector-to-vector functions– But: Can only be used in the select clause; poor
optimization (our preliminary study)
• KSQL – Kx Systems– Arrable extension to SQL but syntactically
incompatible. – No cost-based optimization.

Order-related optimization techniques
• Starburst’s “glue” (Lohman, 88) and Exodus/Volcano “Enforcers” (Graefe and McKeena, 93)
• DB2 Order optimization (Simmen et al., 96)• Top-k query optimization (Carey and Kossman,
97)• Hash-based order-preserving join (Claussen et al.,
01)• Temporal query optimization addressing order and
duplicates (Slivinskas et al., 01)
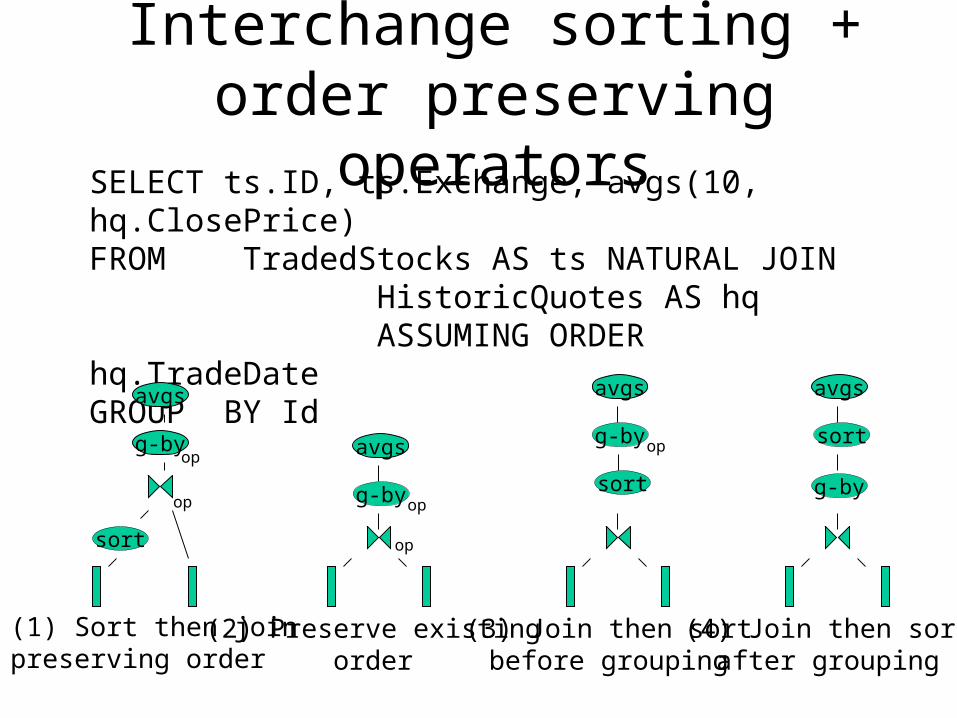
SELECT ts.ID, ts.Exchange, avgs(10, hq.ClosePrice)FROM TradedStocks AS ts NATURAL JOIN HistoricQuotes AS hq ASSUMING ORDER hq.TradeDateGROUP BY Id
Interchange sorting + order preserving operators
(1) Sort then joinpreserving order
(2) Preserve existingorder
(3) Join then sortbefore grouping
op
sort
g-by
avgs
op avgs
g-by
op
op
avgs
g-byop
sort
(4) Join then sortafter grouping
avgs
g-by
sort
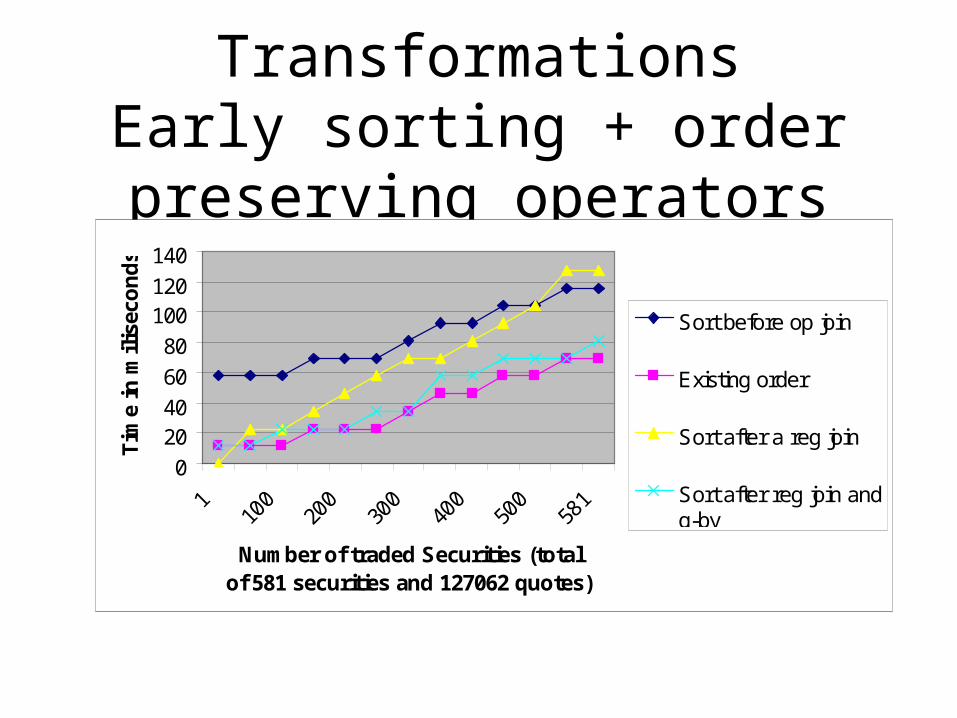
TransformationsEarly sorting + order preserving
operators
0
2040
60
80
100120
140
110
020
030
040
050
058
1
Number of traded Securities (total of 581 securities and 127062 quotes)
Tim
e in
mil
isec
on
ds
Sort before op join
Existing order
Sort after a reg join
Sort after reg join andg-by
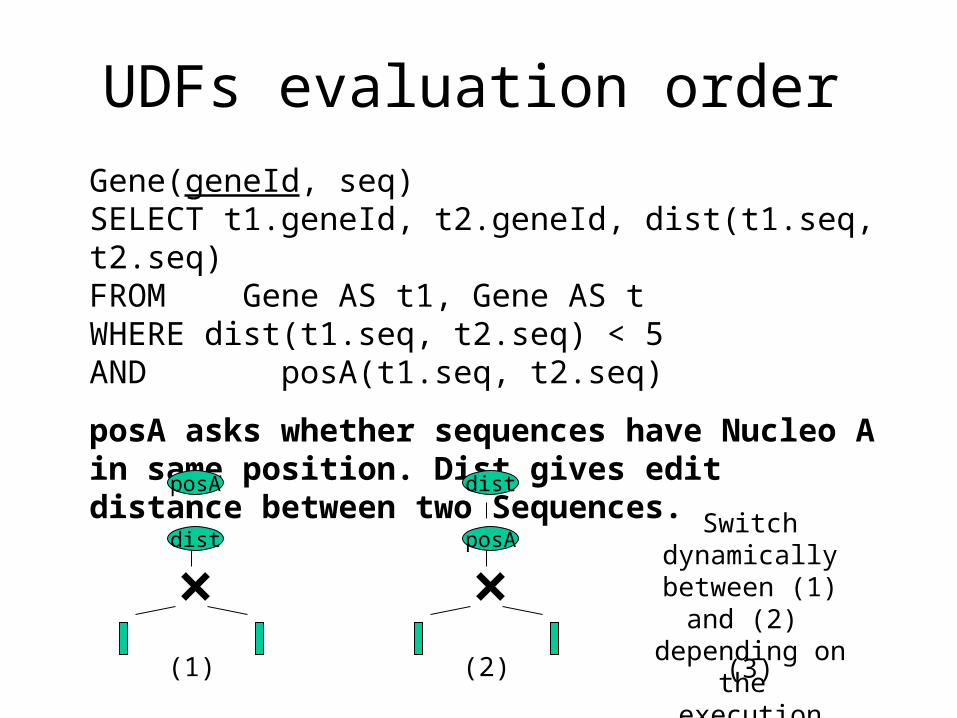
UDFs evaluation order
Gene(geneId, seq)SELECT t1.geneId, t2.geneId, dist(t1.seq, t2.seq)FROM Gene AS t1, Gene AS tWHERE dist(t1.seq, t2.seq) < 5 AND posA(t1.seq, t2.seq)
posA asks whether sequences have Nucleo A in same position. Dist gives edit distance between two Sequences.
posA
dist
dist
posA
(2)(1) (3)
Switch dynamically
between (1) and (2)
depending on the
execution history
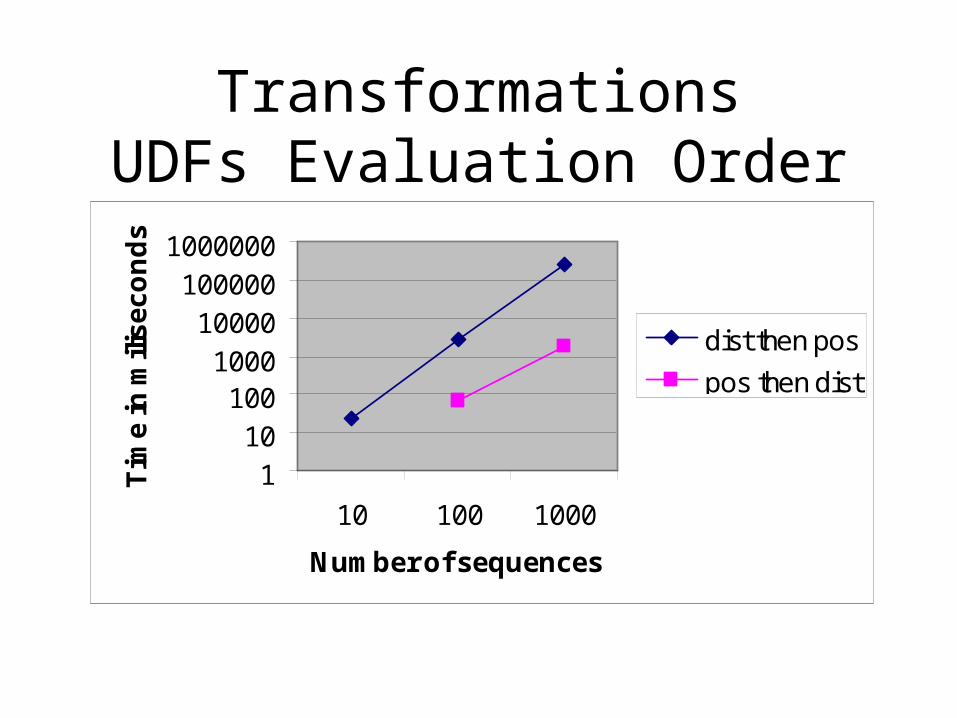
TransformationsUDFs Evaluation Order
110
1001000
10000100000
1000000
10 100 1000
Number of sequences
Tim
e in
mili
se
co
nd
s
dist then pos
pos then dist

Transformations Building Blocks• Order optimization
– Simmens et al. `96 – push-down sorts over joins, and combining and avoiding sorts
• Order preserving operators– KSQL – joins on vector– Claussen et al. `00 – OP hash-based join
• Push-down aggregating functions– Chaudhuri and Shim `94, Yan and Larson `94 – evaluate aggregation
before joins
• UDF evaluation– Hellerstein and Stonebraker ’93 – evaluate UDF according to its
((output/input) – 1)/cost per tuple– Porto et al. `00 – take correlation into account
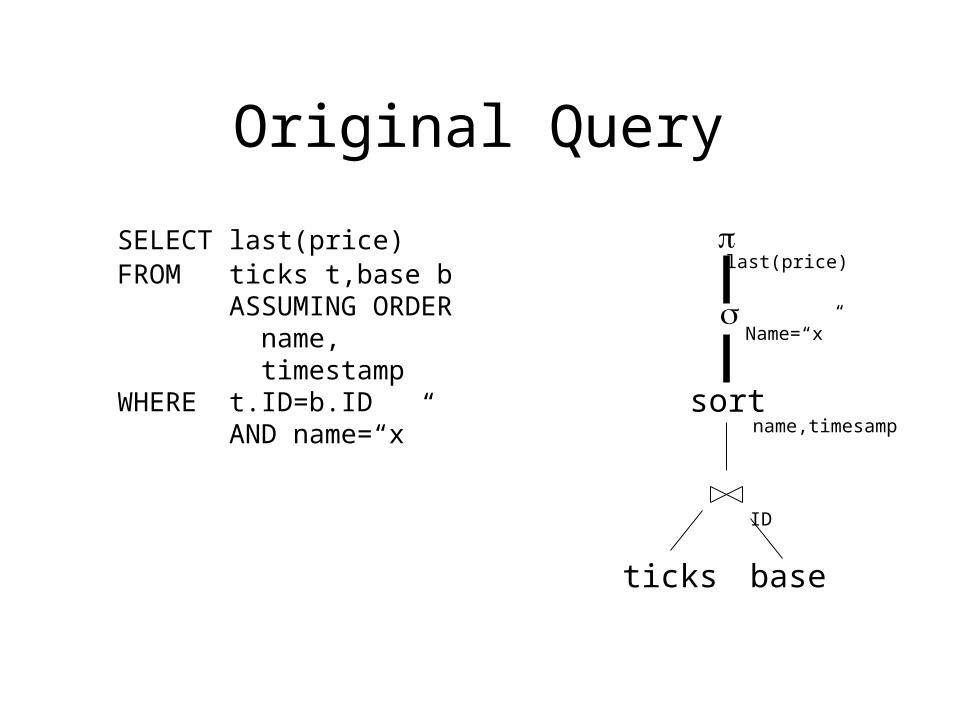
Original Query
SELECT last(price)FROM ticks t,base b ASSUMING ORDER name, timestampWHERE t.ID=b.ID AND name=“x”
sort
baseticks
ID
name,timesamp
Name=“x”
last(price)
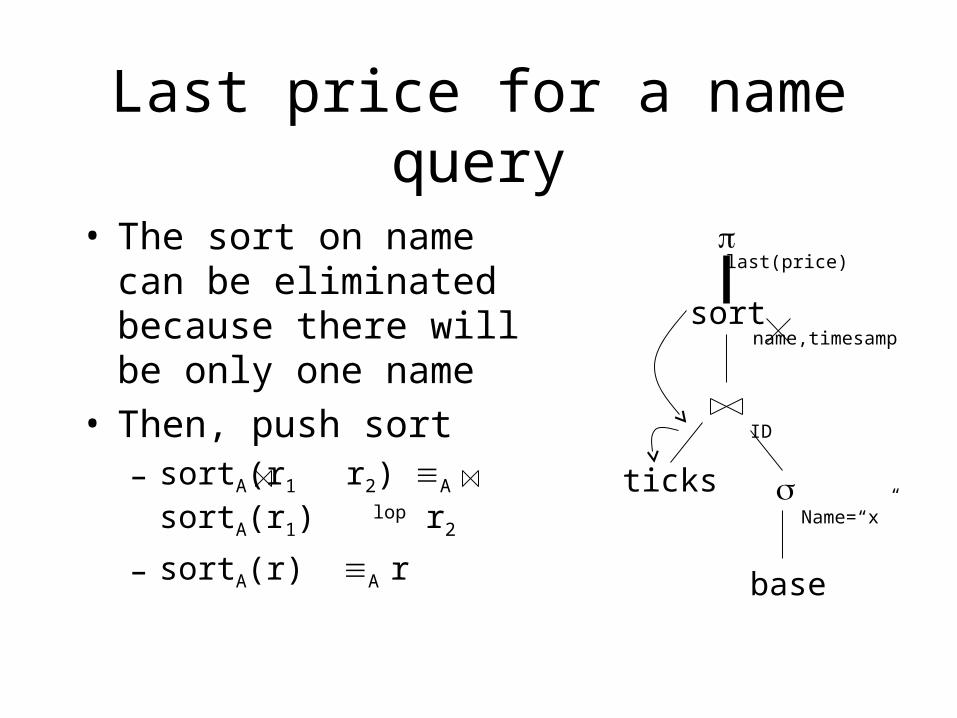
Last price for a name query
• The sort on name can be eliminated because there will be only one name
• Then, push sort– sortA(r1 r2) A sortA(r1) lop r2
– sortA(r) A r
sort
base
ticks
ID
name,timesamp
Name=“x”
last(price)

Last price for a name query
• The projection is carrying an implicit selection: last(price) = price[n], where n is the last index of the price array f(r.col[i])(r) order(r)
f(r.col)(pos()=i(r))
base
ticks
ID
Name=“x”
last(price)
lop
pos()=last
price
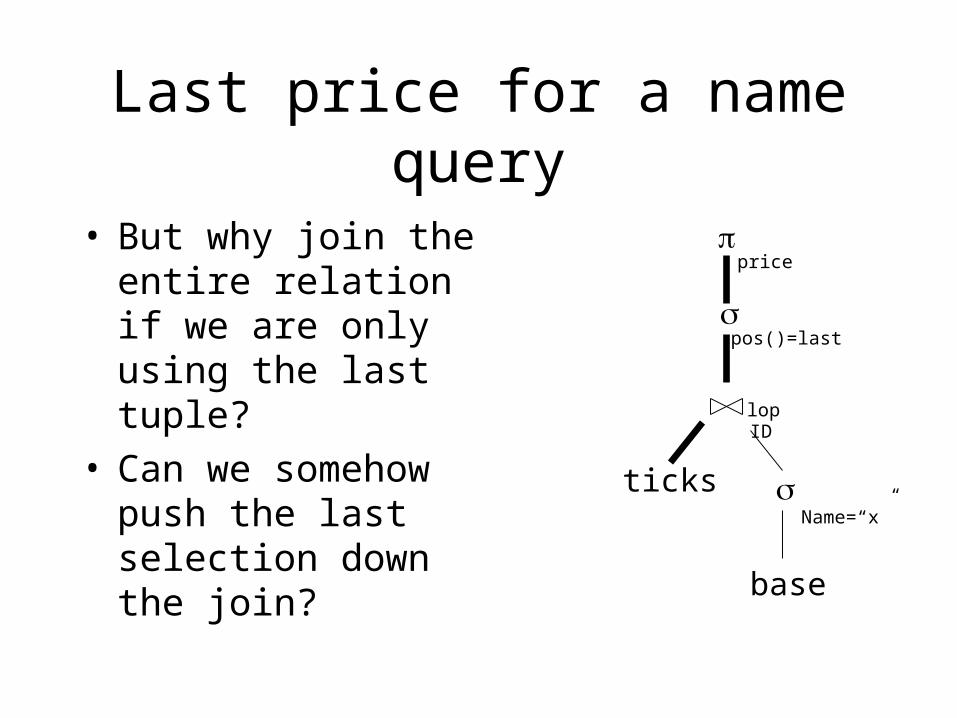
Last price for a name query
• But why join the entire relation if we are only using the last tuple?
• Can we somehow push the last selection down the join?
base
ticks
ID
pos()=last
Name=“x”
price
lop
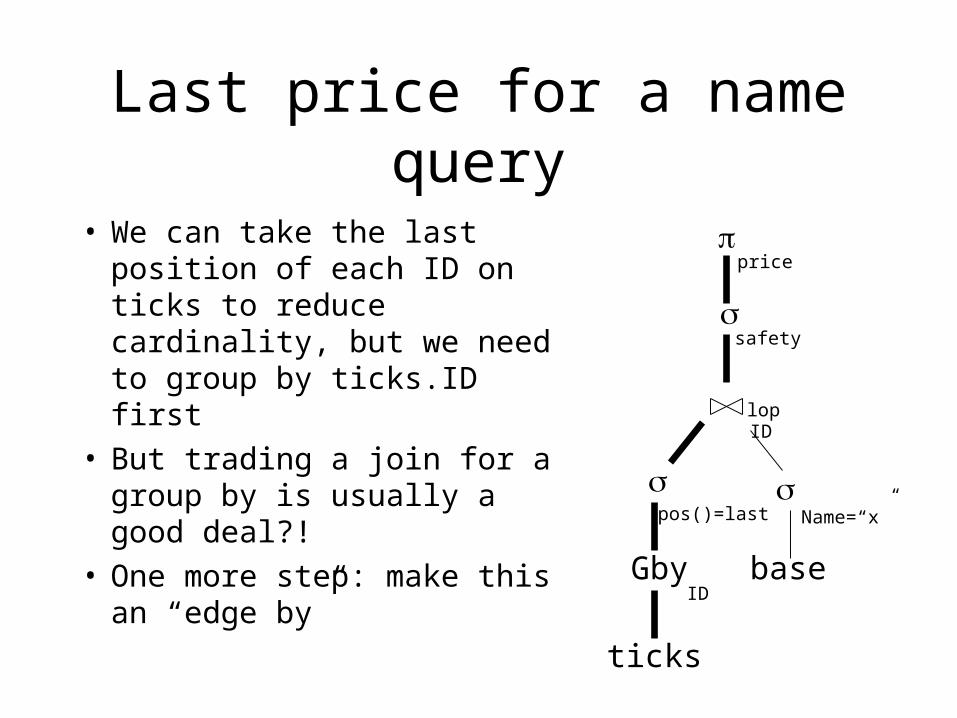
Last price for a name query
• We can take the last position of each ID on ticks to reduce cardinality, but we need to group by ticks.ID first
• But trading a join for a group by is usually a good deal?!
• One more step: make this an “edge by”
base
ticks
ID
safety
Name=“x”
price
lop
pos()=last
GbyID

The “edgeby” operator
• The pattern edge condition(Gby(r)) can be efficiently implemented without grouping the whole arrable
• An edgeby is a kind of scan that take as parameters the grouping column(s), the direction to scan, a position, and if that position is the last (scan up to) or the first one the group (scan from this on).
• In the previous example, to find the last rows for each ID in ticks one would use, respectively, `ID,' `backwards,' ` 1,' and 'up to.'

Conclusion
• Arrable-based approach to ordered databases may be scary – dependency on order, vector-to-vector functions – but it’s expressive and fast.
• SQL extension that includes order is possible and reasonably simple.
• Optimization possibilities are vast.

Streaming
• Aquery has no special facilities for streaming data, but it is expressive enough.
• Idea for streaming data is to split the tables into tables that are indexed with old data and a buffer table with recent data.
• Optimizer works over both transparently.

Arrables’ Shape Properties
• The cardinality of an arrable’s array-columns must be the same
• An arrable’s tuple can contain single or array-valued column values.
– A 1NF arrable contains only single values
– A flatten-able ¬1NF arrable may contain array-valued columns, but they have the same cardinality
– A non-flatten-albe ¬1NF arrable is one that is not in the previous categories

Arrables Primitives
• Single-value indexingr[k] retrieves the tuple formed by the k-th position value of each of the arrables array-columns
• Multi-value indexingr[k1 k2 … kn] is similar to forming an arrable by insertion of r[k1], r[k2], …, r[kn]

Array-columns Expressions
• Expressions in AQuery are column-oriented, as opposed to row-oriented
pricexyz
> scalar =
resultTFT
pricexyz
-
prev(price)-xy
=
result-
y-xz-y

Built-in functions
• prevv[i] = null, if i=0 or v[i-1], for 0<i|v|-1
• firstv,n[i] = v[i], for 0i<n
• minsv[i] = v[i], if i=0 or min(v[i],mins[i-1]), for 0<i|v|-1
• indexbv[i] = i such that bv[i] is true

Each modifier
• Built-in functions are applied over array-columns
• The each keyword makes the function application occur in each tuple level

Group and flatten operations
• An arrable can be grouped over a grouping expression that assigns a group value to each row. The net effect is to nest an 1NF arrable into a flatten-able ¬1F one
• The flatten operation undoes the operation
• But there are data-ordering issues!

AQuery syntax and execution
• It’s just SQL, really. But column-oriented.SELECTFROMASSUMING ORDERWHEREGROUP BYHAVING

AQuery syntax and execution
• It’s just SQL, really. But column-oriented.SELECT
FROMASSUMING ORDERWHEREGROUP BYHAVING
Arrables mentioned in the FROM clause are combined using cartesian product. This is operation is order-oblivious

AQuery syntax and execution
• It’s just SQL, really. But column-oriented.SELECTFROMASSUMING ORDERWHEREGROUP BYHAVING
The ASSUMING ORDER is enforced. From this point on any order-dependent expression can be used, regardless of the clause.

AQuery syntax and execution
• It’s just SQL, really. But column-oriented.SELECTFROMASSUMING ORDERWHEREGROUP BYHAVING
The WHERE expression is executed. It must generate a boolean vector that maps each row of the current arrable to true or false. The false rows are eliminated and the resulting arrable is passed along.

AQuery syntax and execution
• It’s just SQL, really. But column-oriented.SELECTFROMASSUMING ORDERWHEREGROUP BYHAVING
The GROUP BY expression is computed. It must map each tuple to a group. The resulting arrable has as many rows as there are groups. The columns that did not participate on the grouping expression now have array-valued values

AQuery syntax and execution
• It’s just SQL, really. But column-oriented.SELECTFROMASSUMING ORDERWHEREGROUP BYHAVING
The HAVING clause expression must result in a boolean vector that maps each group, i.e, row, to a boolean value. The rows that map to false are excluded.

AQuery syntax and execution
• It’s just SQL, really. But column-oriented.SELECTFROMASSUMING ORDERWHEREGROUP BYHAVING
Finally, each expression on the SELECT clause is executed, generating a new array-column. The resulting arrable is achieved by “zipping” these arrays side-by-side.
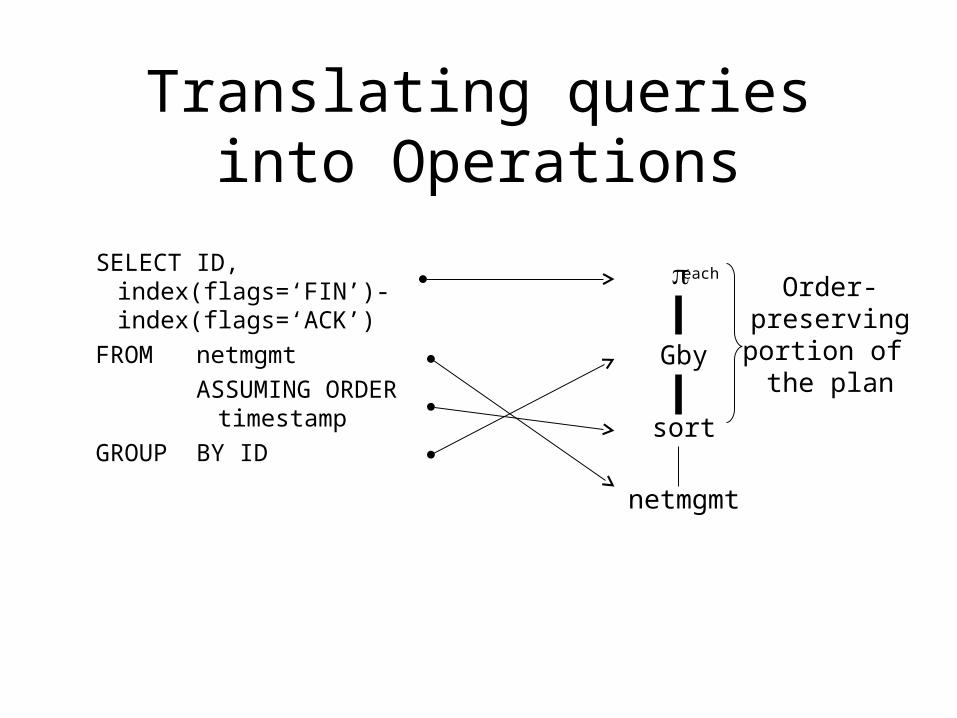
Translating queries into Operations
SELECT ID, index(flags=‘FIN’)-index(flags=‘ACK’)
FROM netmgmt
ASSUMING ORDER timestamp
GROUP BY ID
Gby
sort
netmgmt
Order-preservingportion of
the plan
each

Non- and Order-preserving Variations
• Operators may or may not be required to be preserve order, depending on their location.
• For instance:– a group by based on hashing is an implementation of a
non-order preserving group-by
– A nested-loops join is an implementation of a left-order preserving join
• There are performance implications in preserving or not order

Pick the best
• Early sort and order-preserving group by
• Early, non-order preserving group by and sort
GbysessionID
sorttimestamp
netmgmt
GbysessionID
sorttimestamp
netmgmt
each
eacheach

AQuery Optimization
• Optimization is cost based
• The main strategies are:– Define the extent of the order-preserving region of the plan,
considering (correctness, obviously, and) the performance of variation of operators
– Apply efficient implementations of patterns of operators
• There are generic techniques yet each query category presents unique opportunities and challenges
• Equivalence rules between operators can be used in the process

Order Equivalence
• Let Order(r) return the attributes that the arrable r is “ordered by.”
• Two arrables r1 and r2 are order-equivalent with respect to the list of attributes A, denoted r1 A r2 if A is a prefix of Order(r1) and of Order(r2), and some permutation of r1 is identical to r2
• We denote by r1 {} r2 the case where r1 and r2 are multiset-equivalent (i.e. they contain the same setof tuples and for each tuple in the set, they contain the same number of instances of that tuple).

Sort Elimination
• Often sort can be eliminated or can be done over less fields– sortA(r) A r
if A is prefix of Order(r)– sortA•B(r) A•B sort’A(r)
if B is prefix of Order(r) and sort’ is stable– sortA(sortB(r)) A•B sortA
if A B is a valid functional dependency– sortA(sortB(r)) A•B sortA•(B-A) (r)– oper-path(sort(r)) {} oper-path(r)
if oper-path has no order-dependent operation

Conclusion
• Arrables offer a simple way to express order-based predicates and expressions
• Queries tend to be lucid, concise and, consequently, order idioms stand out
• Optimization naturally extend the know corpus of rules
• New possibility of operator implementing algorithm that take order into consideration

Order preserving joinsselect lineitem.orderid, avgs(10, lineitem.qty), lineitem.lineidfrom order, lineitem assuming order lineidwhere order.date > 45and order.date < 55 and lineitem.orderid = order.orderid
• Basic strategy 1: restrict based on date. Create hash on order. Run through lineitem, performing the join and pulling out the qty.
• Basic strategy 2: Arrange for lineitem.orderid to be an index into order. Then restrict order based on date giving a bit vector. The bit vector, indexed by lineitem.orderid, gives the relevant lineitem rows.The relevant order rows are then fetched using the surviving lineitem.orderid.
Strategy 2 is often 3-10 times faster.