application of machine learning in conservation …
TRANSCRIPT

APPLICATION OF MACHINE LEARNING IN CONSERVATION SCIENCE
AND POLICY:
PREDICTION OF DEFORESTATION AND HETEROGENEOUS
TREATMENT EFFECT MODELING
by
Polina Koroleva
A thesis submitted to Johns Hopkins University in conformity with
the requirements for the degree of Master of Science.
Baltimore, Maryland
May 2019
© Polina Koroleva 2019
All rights reserved.

ii
ABSTRACT
In the recent years, conservation faces more challenges, caused by climate change,
population growth and consumption increase. One of the major threats to biodiversity and
ecosystems globally is deforestation. Governments actively search for effective approaches
to protect the forest while minimizing costs and time of the process. Accurate prediction
of deforestation areas and evaluation of protection treatment can be an effective respond
to this need. In this thesis, I use observational data from Costa Rica to test machine
learning methods for deforestation prediction and protection policy evaluation. The data
consists of two cohorts, collected in two different periods, in order to assess the predictive
quality if the models. First, I apply different machine learning techniques to find pick the
one that gives the most accurate predictions of deforestation. I find that the model trained
on the early data using random forest method can predict the future deforestation with the
accuracy of 77%. The method also allows to focus on the prediction quality of one class.
Second, I analyze the effectiveness of protection policy efforts using heterogeneous
treatment effect (HTE) modeling. The motivation for building such models is to be able
to design and target an intervention to maximize outcome. The causal forests method by
Wager and Athey (2018) is applied to evaluate the effect of protection policies on
deforestation rate among the protected units. The average treatment effect for the first
cohort is 0.14 and for the second is 0.03. Heterogeneity of the policy effect allows to target
a sample that is the most responsive to the protection policy. In the early cohort it would
result in the average treatment effect increase by 0.21. These results can be mapped and
used as a guide for effective forest protection targeting. The thesis shows that
heterogeneous treatment effects modeling is a promising approach that can be used in

iii
conservation science for the identification of the units that will benefit the most from the
protection policies.
Academic Advisor: Dr. Paul Ferraro

iv
ACKNOWLEDGMENTS
First and foremost, I would like to express to my research advisor, Dr. Paul Ferraro, my
great appreciation for his support and guidance during my master thesis work. He
challenged me by asking questions and encouraged me along the path of learning.
I would also like to thank Dr. Merlin Hanauer, Sonoma State University. He provided the
data for this thesis and was always ready to guide me through the technical nuances as well
as the general objectives of this work.
I would also like to acknowledge Dr. Victor Chernozhukov, MIT, whose expertise helped
me to overcome the most challenging parts of the work.
Finally, I would like to thank Marisa L. Henry for being my everyday source of support
and inspiration, as well as my parents and my partner for continuous encouragement
throughout this year.

v
TABLE OF CONTENTS
1 Introduction ........................................................................................................................... 1
2 The Data ................................................................................................................................. 3
3 Machine learning: Classification and Prediction .............................................................. 5
3.1 Data Structure .............................................................................................................. 5
3.2 Methods ......................................................................................................................... 6
3.3 Performance Measure ............................................................................................... 11
3.4 Results .......................................................................................................................... 13
4 Heterogeneous Treatment Effects Modeling ................................................................. 20
4.1 Problem Formulation ................................................................................................ 20
4.2 Causal Inference ......................................................................................................... 21
4.3 Causal Inference and Machine learning ................................................................. 24
4.4 Generalized Random Forests ................................................................................... 25
4.4.1 Model building .................................................................................................. 26
4.4.2 Honesty .............................................................................................................. 28
4.4.3 The average treatment effect and heterogeneity .......................................... 29
4.4.4 Model tuning ..................................................................................................... 31
4.4.5 Model assessment ............................................................................................. 32
4.5 Uplift Random Forests ............................................................................................. 35
4.6 Matching ...................................................................................................................... 38
5 Empirical Application in conservation policy ................................................................ 41

vi
5.1 Data Structure ............................................................................................................ 41
5.2 Building the model .................................................................................................... 42
5.3 Results .......................................................................................................................... 43
5.4 Discussion ................................................................................................................... 48
5.5 Future directions ........................................................................................................ 49
6 Conclusions .......................................................................................................................... 50
Bibliography .................................................................................................................................. 55

vii
LIST OF TABLES
Table 1. Early cohort (Cohort 1) and late cohort (Cohort 2) ................................................. 4
Table 2. Confusion matrix .......................................................................................................... 11
Table 3. Results of k-NN analysis for both Cohort 1 and Cohort 2. In confusion matrix
Pred. stands for predictions. ....................................................................................................... 14
Table 4. Results of classification tree prediction analysis for both Cohort 1 and Cohort 2
......................................................................................................................................................... 14
Table 5. Random forest prediction results for both Cohort 1 and Cohort 2 ..................... 16
Table 6. Sensitivity of predictions for both Cohort 1 and Cohort 2. Cutoff (0.5, 0.5)
represents the default cutoff, while cutoff (0.7, 0.3) represents increases the accuracy of
prediction of one class (deforested units). ............................................................................... 18
Table 7. Importance of variables for targeting to increase treatment effect for Cohort 1
(top) and Cohort 2 (bottom). ..................................................................................................... 44

viii
LIST OF FIGURES
Figure 1. Example of k-NN method implementation. In this case of 3-class classification,
any new point would be located on the grid and assigned by the same class, as majority of
15 neighbors (k=15) ...................................................................................................................... 8
Figure 2. Classification tree for the Cohort 1 ............................................................................ 9
Figure 3. Classification tree for deforestation prediction in 1986. The split labels at the top
of the branches indicate the value of covariate, where the split was made. The blue leaves
attribute to class 0 (deforested), green to class 1 (forested). Each node (leaf) shows the
predicted class, probability of being forested and percentage of observations in the node.
......................................................................................................................................................... 15
Figure 4. ROC charts for the Cohort 1 (top) and the Cohort 2 (bottom). AUC for the
Cohort 1 is 0.79, for the Cohort 2 is 0.59 ................................................................................ 17
Figure 5. Variable importance for the Cohort 1 prediction, based on Gini index. ........... 19
Figure 6. Structure of an honest causal tree ............................................................................. 29
Figure 7. Relationship between the top four variables and predicted treatment effects
(preds) for Cohort 1 (top) and Cohort2 (bottom). ................................................................. 45
Figure 8. Evaluation of heterogeneity of Cohort 1 (left) Cohort 2 (right). ......................... 46
Figure 9. Treatment effect for the control and treatment groups. Cohort 1 (top) and
Cohort 2 (bottom). ....................................................................................................................... 47

1
1 INTRODUCTION
Conservation plays a major role in protecting endangered species and setting aside
wilderness areas. The role of the conservation efforts increases in addressing current
challenges of population growth, consumption increase and climate change. Deforestation
is the second leading cause of the climate change and coupled with agriculture produces
about 20% of human-induced carbon dioxide emissions (Karl et al., 2009). At the same
time forests act as carbon sinks: nearly 247 gigatons (billion tons) of carbon was
sequestered in tropical forests (Saatchi, 2011), that is account for ~70% of the gross carbon
sink in the world forests. However, with equally significant gross emissions from tropical
deforestation, tropical forests have been nearly carbon neutral in the recent years (Pan et
al., 2011). That is why good forest management and forest conservation have a significant
potential to lessen the carbon disruption.
One of the most common forest and biodiversity conservation methods is the use of
protected areas (Millennium Ecosystem Assessment, 2005). At the same time,
conservation of forests is a time and cost consuming process: there is a high risk of
protecting areas that are not likely to be deforested. Understanding the performance of
forest management policies, as well as what factors and conservation practices have the
biggest impact over the long term is critical to enhancing their effectiveness (Miller 2017).
In particular, it would be helpful (1) to predict which areas were most likely to be
deforested and (2) to know which areas would benefit most from protection. Since recent
developments in data collection and storage technology have created vast quantities of
data, one method to help make these predictions is using methods developed in ML.

2
In the recent decades, the concept of learning from data (Abu-Mostafa et al., 2012) has
emerged as the task of extracting “implicit, previously unknown, and potentially useful
information from data” (Frawley et al., 1992). In the conservation science settings, machine
learning (ML) methods have the potential to be a convenient tool for the deforestation
prediction. Freely available datasets have been used to generate plausible risk maps of
deforestation in both Mexico and Madagascar (Mayfield et al., 2007). Cushman et al.
(2017) effectively applied machine learning modeling to landscape change modelling in
Borneo. Machine learning proved to be a reliable prediction tool (Abadie, 2017) and
recently became an applicable data-driven approach to select subpopulations with different
average treatment effects and to test hypotheses about the differences between the effects
in different subpopulations (Athey and Imbens, 2015). The idea that “one size may not fit
all” has been increasingly recognized in a variety of disciplines, ranging from economics to
policy making and medicine. Some methods have been proposed in the literature, mostly
in the context of clinical trials and direct marketing (Su et al., 2009; Larsen, 2009; Radcliffe
and Surry, 2011; Qian and Murphy, 2011; Zhao et al., 2012; Jáskowski and Jaroszewicz,
2012), and also for insurance applications (Guelman, 2014) and policy evaluation (Athey
et al. 2016; Andini et al. 2018). In marketing and political science literature, the concept is
referred to as persuasion modeling and uplift modeling. While in economics and social
sciences literature, Heterogeneous Treatment Effects (HTE) modeling notation is
common. This thesis examines how HTE modeling can be applied for conservation
science and policy context. In particular, for deforestation prevention in Costa Rica.
This thesis proceeds as follows. Chapter 2 defines the data used in the thesis. Chapter 3
follows with description of supervised machine learning methods for classification and
prediction. Several machine learning methods are compared in their accuracy of predicting

3
the areas of deforestation. Chapter 4 expends the machine learning prediction model to
the heterogeneity treatment analysis modeling. In particular, it describes generalized
random forest method by Athey, S., Tibshirani, J., & Wager, S. (2019) and compares it to
alternative uplift modeling by Guelman (2014). Chapter 5 follows with empirical
application of generalized random forest method in conservation policy. The model is built
to evaluate the effectiveness of protection policy on deforestation reduction. Finally,
Chapter 6 concludes all the findings obtained in this thesis.
2 THE DATA
Costa Rica has one of the most widely lauded protected areas (Sanchez-Azofeifa G et al.,
2003). The effectiveness of protected policies was examined in various studies (Andam et
al., 2008) and assessments (Naughton-Treves L. et al., 2005; Oliveira P. et al., 2007). Since
the 1960s, more than 150 protected areas have been designated in Costa Rica (Andam et
al., 2008).
The observational data for this study was collected in Costa Rica. It is provided for this
study by Dr. Merlin Hanauer (Sonoma State University, Department of Economics). The
comparable forest-cover data was collected in 1960, 1986 and 1997. It contains a set of
47107 forest units’ observations characterized by 105 biophysical and socioeconomic
covariates, for example distance to the nearest major city, slope and poverty indexes. The
full definition of the variables is included in the Appendix 1.
In order to reduce a potential bias that can arise when using a single baseline for all
protected areas, two cohorts with different years for the baseline forest were used (Andam
et al., 2008). I break up the analysis and modeling into two cohorts. The first cohort uses

4
forested observations from 1960 to predict outcomes for all units in 1986. The second
cohort uses forested observations from 1986 to predict outcomes for all units in 1997.
Each of the cohorts contains 53 covariates. Early cohort has 27770 observations in 1960
and late cohort has 20941 observations in 1986:
Table 1. Early cohort (Cohort 1) and late cohort (Cohort 2)
Subset Parameters
Cohort 1 27770 observations of 53 variables
Cohort 2 20941 observations of 53 variables

5
3 MACHINE LEARNING: CLASSIFICATION AND
PREDICTION
This chapter discusses various machine learning approaches that are used for prediction.
Cushman et al. (2017) demonstrated with their study of Borneo that multiple-scale
modelling is a powerful approach to landscape change modelling. They used landscape
metrics as predictors in a random forest machine learning modelling framework. In this
chapter I compare different machine learning techniques, in particular k-Nearest
Neighbor, Classification Tree, and Random Forest, and how well they can predict
deforestation in Costa Rica. Two different data sets are used. They were collected before
and after 1986 to test how well the model built on the early cohort data can predict the
future deforestation. Cutoff of the prediction probability is adjusted to get a better accuracy
of the class of the units that are predicted to be deforested.
3.1 DATA STRUCTURE
The data consists of two cohorts (Chapter 1). The variables for analysis are defined as
following:
Outcome: – deforestation ( when unit is forested, - deforested)
Covariates: – set of the observed characteristics of forest units
The outcome variable is binary and considered deforested if the canopy cover of the unit
is <80%. The ratio of the classes is Cohort 1 to Cohort 2 varies. Cohort 1 is considered
balanced, as ratio of the classes is 2 to 3. In Cohort 2 the ratio of the classes is 1to 10, that
can affect the prediction quality of the model.
Yi Yi = 1 Yi = 0
X

6
3.2 METHODS
In order to run machine learning analysis, both Cohort 1 and Cohort 2 data sets were
preprocessed in the following steps:
1. Converted to numeric type.
2. Normalized. The values in the dataset are changed to use a common scale, without
distorting differences in the ranges of values of losing information.
3. The rows (observations) were randomized.
4. The data is split to training and test datasets (0.67 and 0.33 accordingly). This step
is required for providing unbiased evaluation of the model. The training data is
used to fit the model, and test data – to evaluate it.
After data preparation is completed, it is used for classification and prediction analysis.
Within the field of machine learning, there are two main types of tasks: supervised and
unsupervised. In the former, the objective is to predict the value of a response variable
based on a collection of observable covariates. In the latter, there is no response variable
to “supervise” the learning process, and the objective is to find structures and patterns
among the covariates. In this thesis I apply supervised learning techniques since the
response variable is available (deforestation indicator).
Classification methods aim to assign class labels to unknown vectors in the test set (1),
based on a training set (2) of labeled points:
(1)
Where
Q = xi{ }
xi ∈Rd

(2)
where and is the known class membership. In this thesis the model is build
using forest parcels (xi) and forested/deforested outcome (C) to predict if a new parcel
will be forested in the future. The methods examined in this thesis include k-Nearest
Neighbor, Classification Tree, and Random Forest.
K-NN
The k-Nearest Neighbor algorithm (k-NN) is a non-parametric method used for
classification and regression. In k-NN classification, the output is a class membership. An
object is classified by a majority vote of its neighbors, with the object being assigned to the
class most common among its k nearest neighbors (Figure 1). Where k is an amount of
the most similar observations, a positive integer, typically small. This parameter can be
changed in order to avoid overfitting (the model is too specific and highly dependent on
the data split set). If k = 1, then the object is simply assigned to the class of that single
nearest neighbor. Since distance is calculated as the Euclidian distance, the k-NN method
requires normalized the data.
T = (xi ,Ci ){ }
xi ∈Rd Ci

!
8
Figure 1. Example of k-NN method implementation. In this case of 3-class classification, any new point would be located
on the grid and assigned by the same class, as majority of 15 neighbors (k=15)
Classification Tree
Classification tree learning uses a decision tree as a predictive model to go from
observations about an item (branches) to conclusions about the item's target value (leaves).
While k-nearest neighbors seek the k closest points to x according to some prespecified
distance measure, in tree-based methods closeness is defined with respect to a decision
tree, and the closest points to x are those that fall in the same leaf as it. In these tree
structures, leaves represent class labels and branches represent conjunctions of features
that lead to those class labels.
The algorithm is based on intuitive way of classifying: asking questions. In our problem
the questions could be the following (Figure 2):
1.� What is the area of the forest unit?
2.� What is the land use capacity?
3.� What is a percentage of segment covered by protection policy?

9
4. How far is the major city from the forested unit?
Figure 2. Classification tree for the Cohort 1
Classification tree models are created in two steps: induction in pruning. For the first step,
suppose observing samples . The algorithm starts by recursively splitting the
feature space until it has partitioned it into a setoff leaves , each of which only contains
a few training samples. Then, given a test point , the prediction is evaluated by
identifying the leaf containing and setting:
(3)
The goal of the algorithm is to minimize impurity of each level or maximize the
homogeneity of presence of one class. This principle to be prone can results in major
overfitting. That is why the second step, pruning, is important. During this process the
unnecessary structure is removed from the decision tree, resulting in its reduced complexity.
(Xi ,Yi )
L
x µ(x)
L(x) x
µ(x) = 1i : Xi ∈L(x){ } ∑
i:Xi∈L(x ){ }Yi

10
Pruning includes changing parameters such as number of nodes, the tree size, features to
consider and etc.
Random Forest
In Random Forest, the processes of finding the root node and splitting the feature nodes
will run randomly. The algorithm operates by constructing a multitude of decision trees at
training time and outputting the class that is the mode of the classes (classification) of the
individual trees. Random decision forests correct for decision trees' habit of overfitting to
their training set (that is why cross validation is not necessary) (Kangrinboqe, 2017).
Random forests make predictions as an average of trees, as follows: (1) For each
, draw a subsample ; (2) Grow a tree via recursive partitioning on
each such subsample of the data, as described in the Classification tree section; and (3) Make
predictions
(4)
Where denotes the leaf of the -th tree containing the training sample .
Random forests can be applied to a wide range of prediction problems and have few
parameters to tune. Aside from being simple to use, the method is generally recognized
for its accuracy and its ability to deal with small sample sizes and high-dimensional feature
spaces (Biau and Scornet, 2018).
b
b = 1,...,B Sb ∈ 1,...,n{ }
µ(x) = 1B b=1
B
∑i=1
n
∑Yi1( Xi ∈Lb(x),i∈Sb{ })i : Xi ∈Lb(x),i∈Sb{ } ,
Lb(x) b x

11
3.3 PERFORMANCE MEASURE
The machine learning models are built using cross-validation: the model learns on the
training data and predicts the target on the test data. Then the prediction is compared to
the ground truth using various assessment measures.
The performance of classification techniques is often measured using a confusion matrix
or a ROC curve. A confusion matrix shows the number of correct and incorrect
predictions made by the classification model compared to the actual outcomes (target
value) in the data (Sayad, 2018). The matrix is where is the number of target
values (classes). Table 2 displays a 2x2 confusion matrix for two classes (Positive and
Negative):
Table 2. Confusion matrix
Positive (1) Negative (0)
Positive (1) a b
Negative (0) c d
Where:
• Accuracy is a proportion of the total number of predictions that were correct:
• Positive Predictive Value (Precision) is a proportion of positive cases that were
correctly identified:
• Negative Predictive Value is a proportion of negative cases that were correctly
identified:
N × N N
(a + d) / a + b+ c + d
a / (a + b)
d / (c + d)

12
• Sensitivity is a proportion of actual positive cases which are correctly identified:
• Specificity is a proportion of actual negative cases which are correctly identified:
The confusion matrix is also a convenient tool to evaluate the balance of the dataset. If
the amount of the observations of one class significantly exceeds the other, a Cohen’s
kappa metrics can be estimated (Cohen 1960):
(5)
where is the empirical probability of agreement on the label assigned to any sample
(the observed agreement ratio), and is the expected agreement when both annotators
assign labels randomly. is estimated using a per-annotator empirical prior over the class
labels (Cohen 1960).
The alternative way to measure the performance of the model is ROC (Receiver Operator
Characteristic) curve. The ROC chart shows false positive rate ( ) on X-axis,
against true positive rate (sensitivity) on Y-axis. In other words, it plots the probability of
target=1 when its true value is 0 against the probability of target=1 when its true value is
1.
Area under ROC curve (AUC) is often used as a measure of quality of the classification
models. A random classifier has an area under the curve of 0.5, while AUC for a perfect
classifier is equal to 1. In practice, most of the classification models have an AUC between
0.5 and 1.
a / (a + c)
d / (b+ d)
k
k = ( po − pe ) / (1− pe )
po
pe
po
1− specificity

13
In order to decrease the time and cost of data collection and analysis, the most important
variables are calculated using Gini index. The mean decrease in Gini coefficient is a
measure of how each variable contributes to the homogeneity of the nodes and leaves in
the resulting random forest. Each time a particular variable is used to split a node, the Gini
coefficient for the child nodes are calculated and compared to that of the original node.
The Gini coefficient is a measure of homogeneity from 0 (homogeneous) to 1
(heterogeneous). The changes in Gini are summed for each variable and normalized at the
end of the calculation. Variables that result in nodes with higher purity have a higher
decrease in Gini coefficient.
3.4 RESULTS
The methods described in Section 3.2 were applied for deforestation prediction for both
Cohort 1 and Cohort 2. R package class, version 7.3-14 and randomForest, version 4.6-14
was used for conducting machine learning analysis.
For k-NN method the optimal amount of neighbors k was 8. Table 3 includes accuracy of
prediction, kappa metrics and confusion matrix (Section 3.3).

14
Table 3. Results of k-NN analysis for both Cohort 1 and Cohort 2. In confusion matrix Pred. stands for predictions.
Data Accuracy Kappa Confusion Matrix Cohort 1 0.7743 0.5275
Reference 0 1
Pred. 0 2577 984 1 1084 4519
Cohort 2 0.7572 0.1813
Reference 0 1
Pred. 0 1172 3563 1 1521 14685
In the analysis using classification tree the most accurate prediction is obtained limiting the
tree to 11. In order to avoid overfitting of the model, the tree is pruned, so that it
automatically stops growing when the error stops to decrease.
Table 4. Results of classification tree prediction analysis for both Cohort 1 and Cohort 2
Data Accuracy Kappa Confusion Matrix Cohort 1 0.7742 0.5184
Reference 0 1
Pred. 0 2399 945 1 1124 4696
Cohort 2 0.733 0.177
Reference 0 1
Pred. 0 1310 4209 1 1383 14039

15
Classification tree (Figure 3) is a convenient tool for understanding the splitting procedure:
Figure 3. Classification tree for deforestation prediction in 1986. The split labels at the top of the branches indicate the
value of covariate, where the split was made. The blue leaves attribute to class 0 (deforested), green to class 1 (forested).
Each node (leaf) shows the predicted class, probability of being forested and percentage of observations in the node.

16
Table 5. Random forest prediction results for both Cohort 1 and Cohort 2
Data Accuracy Kappa Confusion Matrix Cohort 1 0.7966 0.572
Reference 0 1 Pred. 0 2631 933
1 931 4669
Cohort 2 0.7678 0.2049
Reference 0 1 Pred. 0 1219 3388
1 1474 14860
The most accurate method is random forest. The prediction also is more accurate for the
Cohort 1, than for Cohort 2. It is expected because the prediction of Cohort 2 was based
on the model, built on the data of Cohort 1.
In the random forest method, the predictions are based on probabilities. By default, an
instance will be assigned to class 1 if its probability is higher than 0.5. However, this cut
off can be changed according to the goal of classification. In this study the main goal is to
reduce the error in classification of deforestation, that is increase the number of correct
predictions of “0” in confusion matrix. To obtain the optimal sensitivity-specificity ratio,
the ROC curve is examined (Figure 4). Ideally, the curve will climb quickly toward the top-
left meaning the model correctly predicted the cases. The diagonal line is for a random
model. For Cohort 1 ROC curve shows that model predicted very well. In 1997 the
prediction is less accurate, but it is still higher than a random classifier.

17
Figure 4. ROC charts for the Cohort 1 (top) and the Cohort 2 (bottom). AUC for the Cohort 1 is 0.79, for the Cohort
2 is 0.59
Figure 4 helps to find the optimal tradeoff of sensitivity- specificity ratio in order to find
an optimal cutoff. In this study, the optimal ration is 0.7 to 0.3. Thus, a forest unit will be
assigned with deforested label only if the probability is higher that 70%. The results with
initial and manual cutoffs are the following (Table 6):
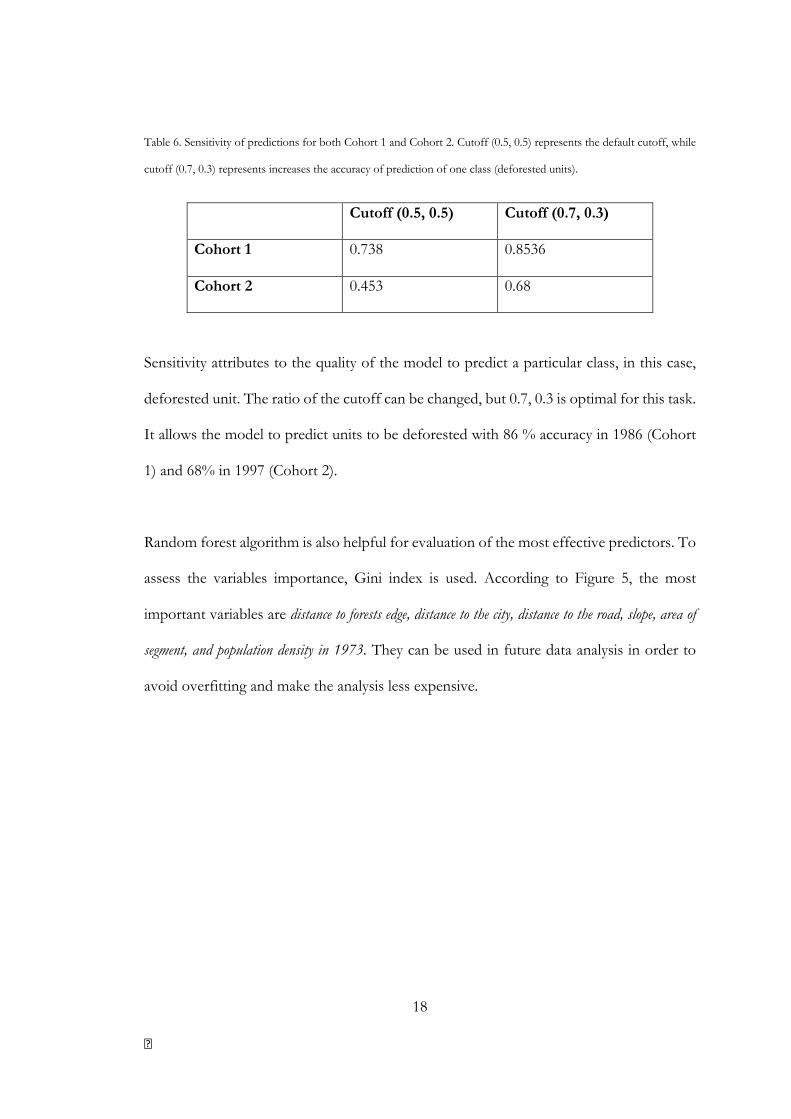
18
Table 6. Sensitivity of predictions for both Cohort 1 and Cohort 2. Cutoff (0.5, 0.5) represents the default cutoff, while
cutoff (0.7, 0.3) represents increases the accuracy of prediction of one class (deforested units).
Cutoff (0.5, 0.5) Cutoff (0.7, 0.3)
Cohort 1 0.738 0.8536
Cohort 2 0.453 0.68
Sensitivity attributes to the quality of the model to predict a particular class, in this case,
deforested unit. The ratio of the cutoff can be changed, but 0.7, 0.3 is optimal for this task.
It allows the model to predict units to be deforested with 86 % accuracy in 1986 (Cohort
1) and 68% in 1997 (Cohort 2).
Random forest algorithm is also helpful for evaluation of the most effective predictors. To
assess the variables importance, Gini index is used. According to Figure 5, the most
important variables are distance to forests edge, distance to the city, distance to the road, slope, area of
segment, and population density in 1973. They can be used in future data analysis in order to
avoid overfitting and make the analysis less expensive.

19
Figure 5. Variable importance for the Cohort 1 prediction, based on Gini index.
The prediction of deforestation using machine learning methods is more accurate than a
random classifier. Random forest model in particular gives the most accurate prediction.
It helps to avoid overfitting and decreases bias and noise from the single tree, resulting in
substantial increase in power when the dimension of the feature space is even moderately
large. The accuracy of prediction of the deforestation can be increased by using a different
cutoff in probabilities. The tradeoff for that is less accurate prediction of the forested units.
The optimal threshold can be obtained depending on the goals of the prediction task and
cost- benefit analysis.

20
4 HETEROGENEOUS TREATMENT EFFECTS
MODELING
The machine learning prediction model described above can be used to find the parts of
the forests that are under the highest risk to be deforested. Then the conservation agencies
can target those areas and prevent deforestation. However, ML prediction model does not
provide any information on the effectiveness of such efforts. For instance, some areas
would be deforested anyway due to the urban area extension or agricultural purposes.
Therefore, a different model is needed for targeting forest units where the protection
policies will have a higher effect. In this chapter I discuss in detail a method, that is widely
used for heterogeneous treatment effect estimation: a nonparametric causal forest
developed by S. Wager and S. Athey (2018). Then I compare it with an alternative method
- uplift modeling by G. Guelman (2014).
4.1 PROBLEM FORMULATION
Heterogeneous treatment effect modeling is used for estimation of the intervention effect
on some outcome. In the setting of this thesis, I use this method to evaluate what areas in
the forest would benefit the most from the protection policies. The underlying motivation
for heterogeneous treatment effects (HTE) modeling is that the response of the individuals
(units) to the treatment often varies. Thus, making an accurate treatment choice for each
subject becomes essential. HTE modeling is both a causal inference and machine learning
problem (Gutierrez et al. 2016). It is a causal inference problem because one needs to
estimate the difference between two outcomes that are mutually exclusive for one unit
(Section 4.2). For that, the data is split to the treatment and control groups and ensure

21
covariate “balance” between them (using such methods as matching and propensity
scores) (Section 4.6). Heterogeneous treatment effects modeling is also a machine learning
problem as one needs to train different models and select the one that yields the most
reliable treatment effect prediction according to some performance metrics. This requires
sensible cross-validation strategies along with potential feature adjustments. While in
traditional machine learning approach the objective is to predict a response variable with
high accuracy, in HTE modeling selecting the optimal treatment for each unit based on its
characteristics becomes an ultimate goal.
4.2 CAUSAL INFERENCE
The causal inference model was first formalized by Rubin (1974, 1977, 1978, 2005). At the
core of the model are the notions of potential outcomes under treatment alternatives, only
one of which is observed for each subject. It is called potential because one can only
observe one type of outcome (the forest unit cannot be forested and deforested at the
same time), but both are required outcomes to estimate the treatment effect for each unit.
This counter-factual nature is called the “fundamental problem of causal inference”
(Holland, 1986). The estimation of causal effects can also be viewed as a missing data
problem (Rubin, 1976), where goal is to predict the unobserved potential outcomes. This
aspect makes this problem unique within the discipline of learning from data.
In the study I consider a framework with forest units indexed by . The
notation introduced below will be used throughout the thesis, except where indicated
otherwise. The upper-case letters are used to denote random variables and lower-case
letters to denote values of the random variables. Let be the binary indicator for
N i = 1,...,N
Wi ∈ 0,1{ }

22
the treatment, with indicating that unit i received the control treatment, and
indicating that unit received the active treatment. Let be a -component vector of
features (covariates), known not to be affected by the treatment. Since one can observe
the outcome for only one possible scenario, potential outcome is assumed to be
if treatment was assigned or if it was not. Thus, the data is characterized by triple
, for . Under the assumption of randomization, treatment
assignment W ignores its possible impact on the outcomes and , and hence
they are independent – using the notation of Dawid (1979), . In this
context, causal effect tI on a unit is defined in terms of the difference between an observed
outcome and its counterfactual and is defined as . The average treatment
effect (ATE) function is:
(6)
In many circumstances, subjects can show significant heterogeneity in response to
treatments, in which case the ATE is of limited value (Guelman, 2014). For that the
conditional average treatment effect (CATE) - the expected causal effect of the active
treatment for a subgroup in the population (Gutierrez, 2016). Conditional stands for the
difference in the potential responses between the two treatments, conditional on the
covariates . This concept is also referred as personalized treatment effect (PTE) in
Guelman (2014). In this paper we will use CATE notation as defined in Athey and Wager
(2015):
Wi = 0 Wi = 1
i Xi L
Yi Yi(1)
Yi(0)
(Yiobs ,Xi ,Wi ) i = 1,...,N
Yi(0) Yi(1)
{Yi(1),Yi(0)} ⊥ W
τ i = Yi(1)−Yi(0)
τ = Ε[Y i(1)−Yi(0)]
X

23
(7)
Then unit i’s observed outcome would be (Gutierrez and
Gérardy, 2016). It is important to assume that the treatment Wi is independent of
outcomes and) conditional on . This assumption is called
Unconfoundedness Assumption and holds true when treatment assignment is random
conditional on :
Assumption 1. (Unconfoundedness)
(8)
The assignment mechanism plays a fundamental role in causal inference. No probabilistic
statements about causal effects can be made without an assumption about the nature of
the mechanism (Little, Rubin 2000). The ideal design for a causal inference model would
involve random selection of subjects and random allocation of treatments to those
subjects. However, it is not feasible with observational studies – they may involve random
sampling of the target units set but not a random allocation of treatments or conditions to
be studied. Thus, the key step in an observational study is to assemble data such that, the
covariate distribution for those in the control group is approximately the same as the
treatment group. Various covariate balancing methods such as matching and propensity
score methods can be helpful to create balanced control and treatment groups in
observational studies. They will be described in detail in Section 4.6.
τ (x) = E[Yi(1)−Yi(0) | Xi = x]
Yiobs = WiYi(1) + (1 -Wi )Yi(0)
Yi(0) Yi(1) Xi
Xi
{Yi(1),Yi(0)} ⊥ Wi|Xi

24
4.3 CAUSAL INFERENCE AND MACHINE LEARNING
The prediction of treatment effects using machine learning differs from traditional
machine learning approach in several points. In machine learning, the standard is to use
cross-validation: separate the data into a training and a test datasets; learn on the training
data, predict the target on the test data and compare to the ground truth (Sections 3.2 and
3.3). In HTE modeling, cross validation is still a valid idea but there is no more ground
truth because one can never observe the unit to be treated and not treated at the same
time. (Gutierrez, Gérardy 2016). However, there are several methods discussed in the
literature that overcome this problem to estimate treatment effect.
The literature on HTE estimation generally classifies the methods under two types: indirect
estimation methods and direct estimation methods (Guelman, 2014). Indirect estimation
methods propose a systematic two-stage procedure to estimate the HTE. In the first stage,
they attempt to achieve high accuracy in predicting the outcome Y conditional on the
covariates X and treatment W. In the second stage, they subtract the predicted value of Y
under each treatment to obtain a HTE estimate. Direct estimation methods attempt to
directly estimate the difference in the potential responses between
the two treatments conditional on the covariates X.
HTE literature has proposed three main approaches to estimate tI (Xi ) despite the absence
of the ground truth (Gutierrez and Gérardy, 2016). It includes Two-Model approach
(building two models on the treatment and control group data exclusively), Class Variable
Transformation (Rzepakowski and Jaroszewicz, 2012) and modification of machine
learning algorithms such as decision tree (Rzepakowski and Jaroszewicz (2012), Athey and
Imbens (2015), random forest (So ltys et al., 2015), (Wager and Athey, 2015) or SVM
E Y (1)−Y (0) | X = x⎡⎣ ⎤⎦

25
(Support Vector Machines, Zaniewicz and Jaroszewicz, 2013). Previous studies (Jacob and
Sunitha, 2015) demonstrate that random forest often bring dramatic improvements in
performance, turning useless single trees into highly capable ensembles. In this thesis I
will focus on this approach that consists in modifying existing machine learning algorithms
to directly infer a treatment effect.
In this thesis I extend application the machine learning random forest approach from
Chapter 3 to the heterogeneous treatment effect estimation using random forests. There
are two commonly used packages implemented in R for this purpose, such as grf and
Uplift. The first one is based on generalized random forest method developed by Athey et
al. (2018). The second one is developed by Guelman (2014) and includes both uplift
random forests and causal conditional inference forests (CCIF). The causal forests by
Athey et al (2018) and uplift forests by Guelman (2014) have similar algorithms but
different statistical motivation. Sections 4.4 and 4.5 discuss the main statistical attributes
of the methods.
4.4 GENERALIZED RANDOM FORESTS
Generalized random forests (Athey, S., Tibshirani, J., & Wager, S., 2019) is a method for
non-parametric statistical estimation based on random forests (Breiman, 2001) that can be
used for estimating other statistical quantities besides the expected outcome. It addresses
the problem of average treatment effect estimation based on a variant of augmented
inverse-propensity weighting. Causal forest proposed by Wager and Athey (2018) is a
special case of a generalized random forest (GRF) approach discussed in Athey, S.,
Tibshirani, J., & Wager, S. (2019). Whereas the generalized random forest approach is
applicable to a broad pool of such statistical tasks as nonparametric quantile regression,

26
conditional average partial effect estimation and heterogeneous treatment effect estimation
via instrumental variables, causal forests are used to address standard problem of
heterogeneous treatment effect estimation under unconfoundedness. Throughout the
thesis both of the notations (generalized random forest and causal forests notations) are
used for this standard HTE estimation problem case. The practical guide for GRF
algorithm implementation is available at github.com/grf-labs/grf/reference (Athey,
Tibshirani, and Wager, 2019; Wager and Athey, 2018) that is discussed in detail Athey, S.,
Tibshirani, J., & Wager, S. (2019).
Causal forest method trains a model optimized on a treatment’s causal effect. Unlike
random forest model that predicts the outcome , generalized
random forest extends this idea to allow for estimating other statistical quantities. In
particular, causal forest estimates conditional average treatment effects (6) – ATE after
being conditioned on the covariate (see Section 4.2). The method allows to select sub
populations with different average treatment effects and to test hypotheses about the
differences between the effects in different subpopulations (Athey and Imbens, 2015). The
objective of causal forest analysis is to provide heterogeneous treatment effect estimation
that yields valid asymptotic confidence intervals for the true underlying treatment effect.
(Wager and Athey, 2018)
4.4.1 Model building
Causal forest is based on the random forest ensemble model principle: it is composed of
a group of decision trees (Section 3.2). The estimation process of building a causal forest
consists of three main steps: train, prediction (on a separate test set) and out-of-bag
prediction. During training, a number of trees are grown on random subsamples of the
µ(x) = Ε Yi | Xi = x⎡⎣ ⎤⎦

27
dataset. Individual trees are trained through the same steps, as classic random forest
algorithm, except of the way the quality of a split is measured. In causal forests, the
goodness of a split relates to maximizing the difference between two nodes’ response to
the treatment. Each leaf node contains both treatment and control groups, and the local
treatment effect is computed at each leaf node.
Each node is split using the following algorithm:
Algorithm 1. Building a causal tree.
• A random subset of variables X are selected as candidates to split on.
• For each of these variables X the algorithm looks at all of possible split values v
and pick the one with the best value, that is defined as maximized difference
between the two child nodes.
• All examples with values for the split variable X that are less than or equal to split
value are placed in a child left node, those that a greater – to the right child node.
• If the splitting of the node won’t result in an improved fit, it forms a leaf of the
final tree
For computational efficiency of the split process, the Athey, Tibshirani, and Wager (2019)
propose to take the gradient of the objective and optimize a linear approximation to the
criterion. This function is already included in the algorithm.
The second step of the algorithm is to use the model built during the training step, to make
predictions on the separate test set. The algorithm for prediction comes as follows:

28
Algorithm 2. Making a prediction on a test set.
• For each tree of the forest, the test example is ‘pushed down’ to determine what
leaf it falls in.
• Based on the information, the algorithm creates a list of neighboring training
examples, weighted by how many times the test example resulted in the same leaf
as a training example.
• A prediction is made using this weighted list of neighbors. In causal prediction, the
treatment effect is calculated using the outcomes and treatment status of the
neighbor examples.
If the test set is not provided, one can use out-of-bag prediction. In this case the algorithm
identifies the trees that were not used for the training and then calculates prediction using
only these new trees. This method is also used for understanding the model’s goodness-
of-fit, as the ATE prediction based on out-of-bag sample should be consistent with the
test sample.
4.4.2 Honesty
In a classic random forest, a single subsample is used both to choose a tree's splits, and for
the leaf node examples used in making predictions. In order to avoid overfitting and reduce
bias in trees predictions, Wager and Athey (2018) propose honest forest approach. First,
the training subsample is split in half, and only the first half is used to grow a tree (perform
splitting). Following Athey and Imbens (2016), the splits of the tree are chosen by
maximizing the variance of The second half is then used to make predictions at the
leaves of the tree (to populate the tree's leaf nodes): each new example is 'pushed down'
τ (xi )

29
the tree and added to the leaf in which it falls. In a sense, the leaf nodes are 'repopulated'
after splitting using a fresh set of examples. Then the tree is honest if, for each training
example , it only uses the response to estimate the within-leaf treatment effect τ or to
decide where to place the splits, but not both. (Wager and Athey, 2018). The algorithm of
building such tree is the following (Figure 6):
Figure 6. Structure of an honest causal tree
Through this approach the bias is reduced by using different subsamples for constructing
the tree and for making predictions.
4.4.3 The average treatment effect and heterogeneity
The main outcome of the causal forests is the average treatment effect across the training
population. It is calculated in more advanced way than just averaging personalized
treatment effects across training examples. More accurate estimate can be obtained by
plugging causal forest predictions into a doubly robust average treatment effect estimator.
As discussed in Chernozhukov et al. (2018), such approaches can yield semiparametrically
efficient average treatment effect estimates and accurate standard error estimates under
considerable generality. Thus, in order to avoid splitting both on features that affect
treatment effects and those that affect propensities, the authors ‘orthogonalized’ the forest
i Yi

30
following the Robinson’s transformation (Robinson, 1988). That is, prior to running causal
forest model, the estimates of the propensity scores and expected
marginal outcome are computed. If the conditional average
treatment effect function is constant, i.e., for all , then the estimator
tau.hat is semiparametrically efficient for tau under unconfoundedness (7):
(9)
assuming that and are o(n−1/4)-consistent for and respectively in root-mean-
squared error, that the data is independent and identically distributed, and that there is an
overlap, i.e., that propensities e(x) are uniformly bounded away from 0 and 1. The
superscripts denote “out-of-bag” or “out-of-fold” predictions meaning that, e.g., Yi was
not used to compute (Athey and Wager, 2019).
The causal forest model is trained several times to try various parameters and compare the
results, choosing the ones that make out-of-bag estimates of the objective minimized in
as small as possible, where is defined as (10):
(10)
Where is a regularizer that controls the complexity of . According to Athey
and Wager (2019), if the true conditional average treatment effect function is simpler
e(x) = Ρ[Wi | Xi = x]
m(x) = Ε[Yi | Xi = x]
τ (x) = τ x ∈X
τ =
1n∑n
i=1
(Yi − m(− i) (Xi ))(Wi − e
(− i) (Xi ))
1n∑n
i=1
(Wi − e(− i) (Xi ))
2
m e m e
(− i)
m(− i) (Xi )
τ∧
(.) τ∧
(.)
τ∧
(·) = argminτ ∑n
i=1
((Yi −m∧ (− i)
(Xi )−τ (Xi )(Wi − e∧
(Xi )))2 + Λn(τ (.))
⎧⎨⎪
⎩⎪
⎫⎬⎪
⎭⎪
Λn(τ (.)) τ∧
(.)
τ (.)

31
than the main effect function or the propensity function , the function learned
by optimizing (9) may converge faster than the estimates for or used to form the
objective function.
Concretely, the grf implementation of causal forests starts by fitting two separate
regression forests to estimate and It then makes out-of-bag predictions using
these two first-stage forests, and computes the outcome ) and residual
treatment . Then we train causal forest on these residuals. If propensity
scores or marginal outcomes are known through prior means, they can be specified on the
model.
The package grf provides the dedicated function average_treatment_effect to compute
these estimates. By default, the average treatment effect function implements augmented
inverse-propensity weighting (Robins et al., 1994) estimation. The package also has four
treatment effect estimation options: ATE, average treatment effect on treated, ATE on
control and ATE overlap (used with high propensity scores).
4.4.4 Model tuning
According to Tibshirani et al. (2018), the accuracy of a forest can be sensitive to the choice
of the parameters. A first step for model accuracy adjustment is to apply cross-validation
procedure that selects values of theses parameters to use in training. Causal forests have
several tuning parameters that can be adjusted in the model. They include the number of
trees that are grown during the training, the number of variables considered during each
split, minimum size of the leaf, maximum imbalance of a split and imbalance penalty. An
m(.) e(.) τ∧
(.)
m(.) e(.)
m(.) e(.)
Y = Y −m(x)
W =W − e(x)

32
important feature of the causal trees is that each node should have balanced amount of
treated and controlled examples, that can be specified in the minimum.node.size
parameter. Grf package provides tune.parameters funcition, that works as follows:
Algorithm 3. Parameter tuning.
• Draw a number of random points in the space of possible parameter values. By
default, 100 distinct sets of parameter values are chosen.
• For each set of parameter values, train a forest with these values and compute the
out-of-bag error.
• For tuning to be computationally tractable, one only trains 'mini forests' composed
of 10 trees. With such a small number of trees, the out-of-bag error gives a biased
estimate of the final forest error. Therefore, the error is debiased through a simple
variance decomposition.
• While the notion of error is straightforward for regression forests, it can be more
subtle in the context of treatment effect estimation. For causal forests, a measure
of error developed in Nie and Wager (2017) is used and motivated by residual-on-
residual regression (Robinson, 1988).
• Finally, given the debiased error estimates for each set of parameters, the algorithm
applies a smoothing function to determine the optimal parameter values
4.4.5 Model assessment
In the classical random forest approach in order to obtain prediction, one should hold out
a test set (Section 3.2). The method then will be considered as good as its error rate is on
this test set. However, in the settings where observation of both the control and treatment
outcomes is not feasible, obtaining a loss measure becomes a separate challenge.

33
There are a few alternative ways for robust checks if the model is trained well and provides
satisfactory predictions. Athey and Imbens (2016) proposed indirect approaches to mimic
test-set evaluation for causal inference. They include measures based on the transformed
outcome and matching. However, these approaches require an estimate of the true
treatment effects and/or treatment propensities for all the observations in the test set,
which creates a new set of challenges (Wager and Athey, 2018). In the absence of an
observable ground truth in a test set, statistical theory plays a more central role in evaluating
the noise in estimates of causal effects than in the standard prediction context. Athey and
Imbens (2016) propose minimazing the expected mean squared error (MSE) of predicted
treatment effects, rather than infeasible MSE itself, is equivalent to maximizing the
variance of treatment effect across leaves minus a penalty for within – leaf variance. While
the notion of error is straightforward for regression forests, it can be more subtle in the
context of treatment effect estimation. The theoretical explanation of measure of error
used in causal forest method is described in Nie and Wager (2017), motivated by residual-
on-residual regression (Robinson, 1988). Following that, Wager and Athey (2018)
developed and incorporated in the causal forest algorithm an asymptotic normality theory
enabling to do statistical inference using random forest predictions. In this thesis, in order
to evaluate if causal forest has succeeded in accurately estimating treatment heterogeneity,
I apply two approaches proposed by Athey (2019) for observational data analysis
purposes.
A first, simple approach to testing for heterogeneity involves grouping observations
according to whether their out-of-bag CATE estimates are above or below the median
CATE estimate, and then estimating average treatment effects in these two subgroups
separately using the doubly robust approach. This procedure is somewhat heuristic, but as

34
the subgroup definition does not directly depend on the outcomes or treatments (Yi,Wi)
themselves, it appears that this approach can provide at least qualitative insights about the
strength of heterogeneity.
Evaluation of predictive quality and heterogeneity is motivated by the “best linear
predictor” method of Chernozhukov, Demirer, Duflo, and Fernandez-Val (2018), that
seeks to fit the CATE as a linear function of the out-of-bag causal forest estimates
. Instead of attempting to get consistent estimate and uniformly valid inference
on CATE itself, they suggest focusing on providing valid estimation and inference for
features of CATE. First, a ML proxy predictor of CATE is built, and then develop valid
inference for features of the CATE based on this proxy predictors. Thus, one can find out
if there is detectable heterogeneity in the treatment effect based on observables, and if
there is any, what is the treatment effect for different bins.
Concretely, following (8), two synthetic predictors are created:
and where is the average of the out-of-bag treatment
effect estimates, and regress against and . The coefficient of is a
measure of the quality of the estimates of treatment heterogeneity, while absorbs the
average treatment effect. The coefficient = 1 suggests that the mean forest prediction
is correct. If the coefficient on is 1, then the treatment heterogeneity estimates are well
calibrated, while if the coefficient is significant and positive, then at least there is
evidence of a useful association between the synthetic predictor and actual treatment
τ (− i) (Xi )
Ci = τ Wi − e − i( ) Xi( )( )Di = (τ − i(Xi )−τ ) Wi − e − i( ) Xi( )( )
Y −m(Xi) Ci Di Di
Ci
Ci
Di
Di

35
effect. This approach is generic and agnostic in a way that it does not make unrealistic or
hard-to-check assumptions.
4.5 UPLIFT RANDOM FORESTS
Uplift random forests are a tree-based method proposed by Guelman et al. (2015) to
estimate personalized treatment effects (heterogeneous treatment effects in econometrics
literature). This method is also based on the standard random forest (Breiman, 2001), but
the split criteria differs from the one proposed by Athey and Imbens (2015). Guelman et
al. (2015) follows the split criteria proposed by Rzepakowski and Jaroszewicz (2012). In
Guelman (2014) author proposes both uplift forest and causal forests methods, as well as
their realizations in R package Uplift. The main difference between uplift forests and causal
forests is that uplift forests try to find regions in feature space with a large divergence
between the treated and control outcome distributions, whereas causal forests directly
target treatment heterogeneity (Guelman, 2014). That is why the Causal Conditional
Inference Forest function in the uplift package looks more similar to causal forests by
Wager and Athey (2018).
Uplift forests are grown following the Algorithm 1, but the split criteria are based on the
objective of maximizing the distance in the class distributions of the response Y between
the treatment and control groups. Rzepakowski and Jaroszewicz (2012) proposed three
new criteria based on information theory of the form:
(11) Δgain = Dafter _ split (PT ,PC )− Dbefore_ split (P
T ,PC )

36
Where D(.) is a divergence measure, PT is the probability distribution of the outcome in
the treated group and PC is the probability distribution of the outcome in the control group.
The criterion is thus the gain in divergence following the split (Gutierrez and Gérardy,
2016). Guelman (2014) follows the concept of distributional divergence from information
theory and uses Kullback-Leibler distance (KL) or relative entropy (Cover and Thomas,
1991, p. 19) as a measure of distributional divergence:
Where k indicates a leaf where one computes and ,
where the difference between two is the average treatment effect .
Causal conditional inference forest was developed by Guelman (2014) in order to tackle
overfitting and the selection bias issues towards covariates with many possible splits. The
author followed the unbiased recursive partitioning method proposed by Hothorn et al.
(2006) to considerably improve the generalization performance of uplift random forests.
The key to the solution is separating the variable selection and the splitting procedure,
coupled with a statistically motivated and computationally efficient stopping criterion
based on the theory of permutation tests developed by Strasser and Weber (1999).
In uplift models, as well as in generalized random forests, loss functions cannot be
evaluated at the individual observational unit (a subject cannot be simultaneously treated
and not- treated). Some methods of performance assessment can be used for both grf and
uplift models. The method commonly used in the literature (Radcliffe 2007; Radcliffe and
KL(P :Q) =left ,right∑ pk log
pk
qk
p = i∑Yi
obsWi
i∑Wi
q = i∑Yi
obs(1−Wi )
i∑(1−W )i
τ

37
Surry 2011) consists in scoring both the treatment and control groups using the estimated
model. One can split the obtained HTE estimations into deciles, and then estimate the
model uplift at each decide by subtracting the average value of the response on the control
observations from the average value of the response on the treatment observations in the
same decile. One then can draw cumulative decile chart, where the first bar corresponds
to the uplift in the first 10 percent, the following bar corresponds to the 20 first percent
and so on. A well performing model features large values in the first quantiles and
decreasing values for larger ones.
The second method, applicable in Uplift models but not available in grf package yet, is
Gains curve and its associated Gini coefficient from conventional models. An incremental
gains curve is a plot of the cumulative number of incremental responses relative to the
cumulative number of targets (both expressed as a percentage of the total targets)
(Guelman et al, 2015). This curve represents the incremental gain from using the model to
target outreach. The comparative baseline is a diagonal line that corresponds to a random
targeting scenario. It corresponds to a scenario where n-persent of the population is
randomly targeted and expected to obtain n-percent of incremental responses relative to
targeting the entire population. The Qini coefficient then is obtained by subtracting the
area under the random curve from the area under under the incremental gains curve. It is
similar to the AUC measured for model assessment in a binary classification setup (Section
3.4). Gini charts help to determine what part of population to target to get the optimal
gain.

38
4.6 MATCHING
In order to replicate a randomized experiment as closely as possible using observational
data, one needs to obtain treated and control groups with similar covariate distributions.
Covariate balancing methods address this need. Covariate balancing methods can be used
for both cases when the outcome values are not yet available (is used to select subjects for
follow up), and when the outcome data is available. In this setting covariate balancing
methods are used to reduce bias in the estimation of the treatment effect. Even though
the outcomes are available in our case, they are not used in the matching process (Stuart,
2010).
One of the most popular covariate balancing methods is matching. Matching divides a
group of N subjects into pairs to minimize covariate differences within pairs. Stuart (2010)
defines “matching” to be any method that aims to equate the distribution of covariates in
the treated and control groups. This may involve 1:1 matching, weighting, or
subclassification, that are actively used in various fields for the study design. In recent
papers this broad set of approaches is often referred as “propensity score methods”. The
propensity score is the conditional probability of assignment to the treatment condition
given the pre-treatment covariates . In this paper I use propensity score
notation only if a method actually implies propensity scores, and the broad set of
approaches is referred as “covariate balancing methods”.
Covariate balancing methods have four key steps (Stuart, 2010), that include: defining
“closeness”, implementation of a matching method, quality assessment of the resulting
matched samples and analysis of the outcome (estimation of the treatment effect). In the
first step I choose and include all the covariates related to both treatment assignment and
π (Xi) = P(Wi = 1| Xi)

39
the outcome (cited in Stuart, 2010). In this thesis I used the same variables as in Andam et
al. (2008): land use productivity (based on climate, soil and slope), distance to forest edge,
distance to roads, and distance to nearest major city. I added one socioeconomic
characteristic covariate – poverty index.
The second step is defining a “distance”: a measure of the similarity between two
individuals. There are four primary ways to measure this distance: exact, Mahalanobis,
propensity score and linear propensity score. For this analysis I use Mahalanobis distance
matching method, as it resulted in the best balance compare to other method (Andam et
al. 2008). I used 1:1 matching with followed up with regression adjustments using the
matched samples. These two methods have been shown to work well together and
regression adjustment is used to “clean up” small residual covariate imbalance between the
groups (cited in Stuart, 2010). In order to decrease bias, I used matching with replacement
– controls were used as matches for more than one treated individual. The last step of the
matching process is to assess the covariate balance in matched group: evaluation of
similarity of the empirical distributions of the full set of covariates in the matched treated
and control group. This step is particularly important because the treatment should be
unrelated to the covariates. Without satisfying balance between matched set future analysis
cannot be continued.
The process for estimating the HTE from a matched randomized design can be formulated
as follows. Suppose a matched pair is composed of subjects l1 and l2 who have been
assigned to treatment (W = 1) and control (W = 0), respectively. For each of these subjects
the value of the response under the assigned treatment is known, but not the
counterfactual response. By applying matching, one expects them to be similar in terms of

40
their covariates. In other words, it can be addressed as the “missing data problem” by
filling in the observed response on one subject of the pair in “missing” counterfactual
response for the other subject of the pair. That is, one can use the observed response of
subject l1 under W= 1 to fil in the unobserved response of subject l2 under that treatment.
An estimate of the subject-level treatment effect is then obtained by simply differencing
the observed and (imputed) counterfactual responses between subjects of a matched pair.
After that, the matching data set is randomized and can be used for ATE estimation, as
well as HTE modeling. It helps to reduce the variance of unbiased estimate, and the
adjusted estimate of the ATE is more precise when covariates are more nearly balanced
(Snedecor and Cochran, 1980, p. 368).

41
5 EMPIRICAL APPLICATION IN CONSERVATION
POLICY
In this chapter I apply the generalized random forest by Athey et al (2019) to the data
collected in Costa Rica (Chapter 1). In the causal forest analysis, the model is trained on
the expected HTE for every forest parcel and then applied to future potential targets. As
a result, it allows to predict which areas will benefit the most from protection. In this
section I provide the exact implementation of the treatment effect estimation strategy with
causal forests, described in Section 4.4. All the analyses are carried out using the R package
grf, version 0.10.2 (Tibshirani et al., 2018; R Core Team, 2017).
5.1 DATA STRUCTURE
The observational data for this analysis was collected in Costa Rica and is described in
detail in Chapter 2. For the heterogeneous treatment effect estimation, the treatment
indicator becomes a separate variable:
Outcome: – deforestation ( when unit is forested, - deforested)
Covariates: – set of the observed characteristics of forest units
Treatment: – assigned protection of the forest unit areas
The analysis is based on the two cohorts of the data: Cohort 1 and Cohort 2 (Chapter 2).
First, I apply robustness checks by excluding protected areas established in 1981–1985
from Cohort 2 and protected areas established in 1981–1984 Cohort 1. The final sample
of Cohort 1 results in 23413 observations and Cohort 2 contains 16313. Second, to obtain
Yi Yi = 1 Yi = 0
X
Wi

42
groups of exposed and unexposed units, as well as to make sure they are comparing as
similar as possible, the matching is applied (Section 4.5). It results two final versions of
Cohort 1 and Cohort 2 subsets. Cohort 1 contains 4500 observations in the treated group
and 4776 in the control. Cohort 2 now contains 4308 treated observations and 4308
controlled. For each forest unit i = 1, ..., n, a binary treatment indicator Wi is obsrerved, a
real-valued outcome Yi, as well as 55 categorical or real-valued covariates in each subset.
The covariates were measured before treatment before the outcome.
5.2 BUILDING THE MODEL
First, the matched data is randomized and split to the train and train subsets with 0.77 to
0.33 ratio. Then I build the model using the train subset and get predictions from the test
set. The same procedure is applied for both Cohort 1 and Cohort 2. The measured
treatment effect is the difference between the change in forest cover on protected plots
and the change in forest cover on matched unprotected plots in the same period. In causal
inference notation, the estimand in this study is the average treatment effect on treated
(ATT), since the interest is to see if protection policy decreases deforestation rate among
the protected units.
I start with training two separate forests: the Y.forest and W.forest. For Y forest, in order
to get a better predictive performance in the presence of strong, smooth effect, the local
linear forest is applied. It enables to improve on asymptotic rates of convergence for
random forests with smooth signals, and provides substantial gains in accuracy (Friedberg,
Tibshirani, Athey, 2018). After calculating Y.forest and W.forest, they are fit into a training
a pilot causal forest, that includes all features. Then the final causal forest is trained on only
those features that saw a reasonable number of splits in the first step. This enables trees to

43
make more splits on the most important features in low-signal situations. Both pilot and
final causal forests are “honest”. The algorithm is provided in Appendix 2.
5.3 RESULTS
The conditional average treatment effects for both Cohorts are the following. For the
Cohort 1 (pre-1979 subset), the CATE is 0.14 [95% CI: +/- 0.016] and CATT is 0.11 [95%
CI: +/- 0.028]. In order for conditional average treatment effects to be properly identified,
a dataset's propensity scores must be bounded away from 0 and 1. In this study the
propensity score distribution is concentrated closer to extremes. S Athey, Tibshirani, and
Wager (2019) suggests using overlap ATE estimation for the cases where propensity score
is too high. In this case CATE is 0.15 [95% CI: +/- 0.038].
I assess the predictive quality of the model by using metrics discussed in Section 4.4.5.
According to these metrics, for Cohort1 the model predicts the CATE very well ( =
0.94) but underestimates the heterogeneity ( = 1.7). The difference between highest
and lowest estimates of CATE is 0.21 [ 95% CI: +/-0.032].
For the Cohort 2 the estimated treatment propensities go as high as 0.994 which means
that treatment effects for some treated units may not be well identified. That is why the
overlap function is used and results in CATE is 0.03 [95% CI: +/- 0.025]. At the same
time test calibration indicates that the point estimates are not well consistent with presence
of heterogeneity ( = -0.04) and underestimates them ( = 1.7). The reason for that
can be the violation of the overlap assumption, because the data is concentrated at the
extremes.
Ci
Di
Ci Di

44
Causal Forest method allows to examine the nature of heterogeneity and understand what
variables are useful for targeting based on treatment effect. (White, 2018). The top ten
variables that contributed the most in the Cohort 1 and 2 include (Table 7):
Table 7. Importance of variables for targeting to increase treatment effect for Cohort 1 (top) and Cohort 2 (bottom).
In order to ensure that our findings do not violate the priors we plot the relationship
between top four variables from the Table 7 and the predicted treatment effect using linear
regression (Figure 9):

45
Figure 7. Relationship between the top four variables and predicted treatment effects (preds) for Cohort 1 (top) and
Cohort2 (bottom).

46
These graphs show the relationship between the variables and the treatment effect. They
can help to give some insight about targeting in case it is not feasible to use the model
directly. For instance, one can expect protection policy to be more effective at the land
most suitable for agriculture (Figure 7, top, luc4per). However, no conclusions should be
drowned directly from these relationships because variables do not exist independently,
and their interactions are complex.
Moving further, I evaluate the heterogeneity of the effect. Plotting predicted treatment
effects by their rank (Figure 8) shows that treatment effect for the early cohort is
significantly more heterogeneous than for the later cohort.
Figure 8. Evaluation of heterogeneity of Cohort 1 (left) Cohort 2 (right).

47
One more approach of HTE model evaluation consists in sorting treated and untreated
test observations in ascending order of predicted uplift, separately. Both groups are then
binned into deciles and the model performance is evaluated through the pairwise
difference in the uplift average per decile. I applied this approach to the both of the cohorts
(Figure 9):
Figure 9. Treatment effect for the control and treatment groups. Cohort 1 (top) and Cohort 2 (bottom).

48
The uplift bins show the consistency of the treatment effect prediction, as well as the
difference between ATE within the treated and control groups.
5.4 DISCUSSION
The results show that the effect of protection policies on deforestation reduction are much
higher for the early cohort. The difference in the effect of protection can be explained by
the clearing that occurred between 1960 and 1980, and the protection decision for the later
cohort were made on the forest land that was not suitable for clearing (Andam et al. 2008).
The analysis for the early cohort claims to find very strong heterogeneity in τ(x) that can
accurately be estimated. At the same time, the assessment of the model for the late cohort
shows that it does not fully capture the treatment effect and underestimates heterogeneity.
One of the reasons for that can be violation of propensity overlap assumption. The main
challenge of HTE modeling is that is that it is not possible to observe both the control and
the treatment outcomes for an individual, which makes it difficult to find a loss measure
for each observation. Nevertheless, there are various assessment techniques that
consistently evaluate the quality of the model, as well as its ability to capture to capture
heterogeneity. The “best linear predictor” evaluation method by Chernozhukov et al.
(2018) proved to be the most convenient tool for adjusting the model parameters, while
uplift bins and other graphical models help to visualize and detect heterogeneity.

49
5.5 FUTURE DIRECTIONS
The potential application of the results obtained in this paper is a heat map with the forest
units with the highest TE from the protection policy. It can be used as a helping tool for
conservation agencies to apply protection policies more effectively.

50
6 CONCLUSIONS
This thesis discusses two potential application of machine learning methods in
conservation science and policy. In particular, the effectiveness of machine learning
techniques when applied to prediction of the forest deforestation and protection policies
evaluation. First, traditional machine learning prediction model was applied to find the
parts of the forests that are under the highest risk of deforestation. With this information
the conservation entities can be aware of the forest areas to be deforested, and then use
their resources to prevent deforestation. To assess the effectiveness of protection efforts,
I applied heterogeneous treatment effect modeling. This model can be used to predict
what parts of the forest would actually benefit from being protected. With this information
conservation agencies can have a better understanding of its capabilities and distribute their
efforts in a more efficient way.

51
APPENDICES
APPENDIX 1: Definition of the variables
names(main) Description 1 id2 unique ID for the point/pixel/parcel 2 dmcity distance to nearest city (km) 3 drd distance to nearest major road 1969 4 drd.00 distance to nearest major road 2000 5 dfedge.60 distance to edge of forest 1960 6 dfedge.86 "" 1986 7 dfedge.97 "" 1997 8 for.60 1 if parcel was forested in 1960 9 for.86 "" 1986 10 for.97 "" 1997 11 luc land use capacity number (1= highly suitable for ag, 8 very low suitability for ag ) 12 luc123 1 if luc 1, 2, or 3 (high suitability) 13 luc4 1 if luc 4 (medium suitability) 14 luc567 1 if luc 5, 6, or 7 (low suitability) 15 slope slope of parcel (degrees) 16 prot 1 if parcel protected prior to 1980 17 prot.a80 1 if parcel protected after 1980 18 seg.id unique ID of segmento (census tract) in which parcel lies 19 seg.area area of segment (m2) 20 pop.2000 population 2000 21 for60per percentage of segmento covered by forest in 1960 22 luc123per percentage of segmento covered my high quality land 23 luc4per percentage of segmento covered my medium quality land 24 luc567per percentage of segmento covered my low quality land 25 seg.areakm area of segmento 26 poptot2000 redundant The following are household characteristics from the 1973 and 2000 censuses. Most names are self explanatory 27 pct.hombre2000 percentage of household that is male 28 dependratio2000 ratio of dependants to adults (non-dependants) 29 pct.adultprimorno2000 30 pct.illiterate2000 percentage of household that illiterate 31 pct.employed2000 percentage of household that is employed 32 pct.badcond2000 percentage of houses in segmento that are in "bad condition"

52
33 pct.crowding2000 percentage of houses in segmento that are "crowded" 34 pct.dirtfloor2000 percentage of houses in segmento that have dirt floors 35 pct.nosewer2000 percentage of houses in segmento that have no formal sewer connection 36 pct.waterpuboth2000 percentage of houses in segmento that are connected to public water 37 pct.noelect2000 percentage of houses in segmento without electricity 38 pct.charcwood2000 percentage of houses in segmento that use charcoal wood for cooking 39 pct.notoilet2000 percentage of houses in segmento without toilet 40 pct.norefrig2000 percentage of houses in segmento without refrigerator 41 pct.notelefono2000 percentage of houses in segmento without telephone 42 pct.nowashmach2000 percentage of houses in segmento without washing machine 43 pct.nohotwat2000 percentage of houses in segmento without hot water 44 hombre.v2000 levels of each of the previous variables 45 dependratio.v2000 46 adultprimorno.v2000 47 illiterate.v2000 48 employed.v2000 49 badcond.v2000 50 crowding.v2000 51 dirtfloor.v2000 52 nosewer.v2000 53 waterpuboth.v2000 54 noelect.v2000 55 charcwood.v2000 56 notoilet.v2000 57 norefrig.v2000 58 notelefono.v2000 59 nowashmach.v2000 60 nohotwater.v2000 61 clpovindex2000 POVERTY INDEX FOR 2000 62 pct.hombre73 see description from previous variables 63 dependratio73 64 pct.adultprimorno73 65 pct.illiterate73 66 pct.employed73 67 pct.badcond73 68 pct.crowding73 69 pct.dirtfloor73 70 pct.nosewer73 71 pct.waterpuboth73 72 pct.noelect73

53
73 pct.charcwood73 74 pct.notoilet73 75 pct.norefrig73 76 pct.notelefono73 77 pct.nowashmach73 78 pct.nohotwat73 79 vivocupada1973 80 pobtot1973 81 hombre.v73 82 dependratio.v73 83 adultprimorno.v73 84 illiterate.v73 85 employed.v73 86 badcond.v73 87 crowding.v73 88 dirtfloor.v73 89 nosewer.v73 90 waterpuboth.v73 91 noelect.v73 92 charcwood.v73 93 notoilet.v73 94 norefrig.v73 95 notelefono.v73 96 nowashmach.v73 97 nohotwater.v73 98 clpovindex73 POVERTY INDEX 1973 99 empty.2000 100 popden73 population density 1973 101 popden2000 population density 2000 102 pro.bef80per percentage of segmento covered by PA established prior to 1980 103 pro.before2000per percentage of segmento covered by PA established prior to 2000 104 pro.aft80per percentage of segmento covered by PA established after to 1980 105 popgrowth population growth from 1973 to 2000

54
APPENDIX 2: Estimating treatment effects with causal forests
Algorithm 4. ATE estimation with causal forest
Y.forest = local_linear_forest(X,Y) Y.hat = predict(Y.forest)$predictions W.forest = regression_forest(X,W) W.hat = predict (W.forest)$predictions cf.raw = causal_forest(X,Y,W, Y.hat = Y.hat, W.hat = W.hat, honesty = TRUE, tune.parameters = TRUE) varimp = variable_importance(cf.raw) selected.idx = which (varimp > mean(varimp)) cf = causal_forest (X[,selected.idx], Y, W, Y.hat = Y.hat, W.hat = W.hat, honesty = TRUE) tau.hat = predict(cf)$predictions

55
BIBLIOGRAPHY
Abadie, A., & Kasy, M. (2017). The Risk of Machine Learning. Retrieved from
arxiv.org/abs/1703.10935
Andam K.S. et al (2008) Measuring the effectiveness of protected area networks in
reducing deforestation, PNAS, pnas.org/cgi/doi/10.1073/pnas.0800437105.
Athey, S., & Imbens, G. W. (2015). Machine Learning Methods for Estimating Heterogeneous
Causal Effects *. Retrieved from arxiv.org/pdf/1504.01132v1.pdf
Athey, S. & Imbens, G. (2016). Recursive partitioning for heterogeneous causal
effects. Proceedings of the National Academy of Sciences.
Athey, S., Tibshirani, J., & Wager, S. (2019). Generalized random forests. The Annals of
Statistics, 47(2), 1148–1178. https://doi.org/10.1214/18-AOS1709
Athey, S., & Wager, S. (2019). Estimating Treatment Effects with Causal Forests: An Application.
Retrieved from arxiv.org/pdf/1902.07409.pdf
Breiman, L. (2001). Statistical modeling: The two cultures. Statistical Science, 16(3):199–
215
Chernozhukov, V., Demirer, M., Duflo, E., & Fernandez-Val, I. (2018.). Generic Machine
Learning Inference on Heterogenous Treatment Effects in Randomized Experiments. Retrieved
from arxiv.org/pdf/1712.04802.pdf

56
Cohen J. (1960). “A coefficient of agreement for nominal scales”. Educational and
Psychological Measurement 20(1):37-46. doi:10.1177/001316446002000104.
Cover T. and Thomas J., Elements of Information Theory, Wiley & Sons, New York, 1991.
Second edition, 2006
Cushman, S. A., Macdonald, E. A., Malhi (2017). Multiple-scale prediction of forest loss
risk across Borneo. Landscape Ecol, 32, 1581–1598. doi.org/10.1007/s10980-017-
0520-0
Dawid, A. (1979). Conditional Independence in Statistical Theory. Journal of the Royal
Statistical Society. Series B (Methodological),41(1), 1-31. Retrieved from
jstor.org/stable/2984718
Ferraro P.J., Hanauer M.M., Sims K.R.E. (2011) Conditions associated with protected area
success in conservation and poverty reduction, PNAS. August 2011, Volume 108,
No.34, 13913-13918
Franco, J. L. de A. (2013). O conceito de biodiversidade e a história da biologia da
conservação: da preservação da wilderness à conservação da biodiversidade. História
(São Paulo), 32(2), 21–48. doi.org/10.1590/S0101-90742013000200003
Friedberg, R., Tibshirani, J., Athey, S., & Wager, S. (2018). Local Linear Forests. Retrieved
from gssdataexplorer.norc.org/variables/191/vshow
Guelman, L. (2014). Optimal personalized treatment learning models with insurance
applications. Retrieved from tdx.cat

57
Guelman, L, Montserrat Guillén & Ana M. Pérez-Marín (2015) Uplift Random Forests,
Cybernetics and Systems, 46:3-4, 230-248, DOI: 10.1080/01969722.2015.1012892.
Retrieved from doi.org/10.1080/01969722.2015.1012892
Gutierrez, P., & Gérardy, J.-Y. (2016). Causal Inference and Uplift Modeling A review of the
literature (Vol. 67). Retrieved from
proceedings.mlr.press/v67/gutierrez17a/gutierrez17a.pdf
Hothorn, T., Hornik, K., & Zeileis, A. (2006). Unbiased Recursive Partitioning: A Conditional
Inference Framework. Retrieved from statmath.wu-
wien.ac.at/~zeileis/papers/Hothorn+Hornik+Zeileis-2006.pdf
Irizarry, R. A., & Love, M. I. (2015). Summary for Policymakers. Climate Change 2013 - The
Physical Science Basis, 1–30. doi.org/10.1017/CBO9781107415324.004
Jaskowski, Maciej, and Szymon Jaroszewicz. "Uplift modeling for clinical trial data." ICML
Workshop on Clinical Data Analysis. 2012.
James, G. D. Witten, T. H. Robert Tibshirani. An Introduction to Statistical Learning: with
Applications in R. New York: Springer, 2013
Karl, T. R., Melillo, J. M., Peterson, T. C., & Hassol, S. J. (Eds.). (2009). Global climate change
impacts in the United States. Cambridge University Press.
Liaw, Andy, and Matthew Wiener. "Classification and regression by randomForest." R
news 2.3 (2002): 18-22.
Localio, A. R., Ross, M. E., Kreider, A. R., Rubin, D. M., Huang, Y.-S., & Matone, M.
(2015). Propensity Score Methods for Analyzing Observational Data Like

58
Randomized Experiments: Challenges and Solutions for Rare Outcomes and
Exposures. American Journal of Epidemiology, 181(12), 989–995,
doi.org/10.1093/aje/kwu469
Mayfield H. et al. (2017). Use of freely available datasets and machine learning methods in
predicting deforestation. Environmental Modelling & Software. Volume 87, January
2017, Pages 17-28.
Millennium Ecosystem Assessment (2005) Ecosystems and Human Well-Being: Policy Responses
(Island Press, Washington, DC).
Miller, Daniel C., Pushpendra Rana, and Catherine Benson Wahlén. "A crystal ball for
forests?: Analyzing the social-ecological impacts of forest conservation and
management over the long term." Environment and Society 8.1 (2017): 40-62.
Nie, X., & Wager, S. (2017). Quasi-Oracle Estimation of Heterogeneous Treatment Effects.
Retrieved from arxiv.org/pdf/1712.04912.pdf
Pan, Y., Birdsey, R. A., Fang, J., Houghton, R., Kauppi, P. E., Kurz, W. A., … Hayes, D.
(2011). A Large and Persistent Carbon Sink in the World’s Forests. Science, 333(6045),
988 LP-993. doi.org/10.1126/science.1201609
Robinson, P. (1988). Root-N-Consistent Semiparametric Regression. Econometrica, 56(4),
931-954. doi:10.2307/1912705
Rubin, D. B. (1974). Estimating causal effects of treatments in randomized and
nonrandomized studies. Journal of Educational Psychology 66 688-70

59
Rubin, D. B. (1976). Inference and missing data (with discussion). Biometrika 63 581-592.
MR0455196
Saatchi, S.S. (2011, June 14) Benchmark map of forest carbon stocks in tropical regions
across three continents. Proceedings of the National Academy of Sciences, Vol. 108, No. 24,
9899–9904.
Sayad S. An Introduction to Data Science: Confusion Matrix. URL:
saedsayad.com/model_evaluation_c.htm. Accessed on 19 March 2019
Snedecor, G. W. and Cochran, W. G. (1980). Statistical Methods. Iowa State University
Press, Ames, IA, 7th edition
Strasser, H., & Weber, C. (1999). On the asymptotic theory of permutation statistics. Retrieved
from
citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.41.7071&rep=rep1&type=pdf
Stuart, E. A. (2010). Matching Methods for Causal Inference: A Review and a Look
Forward. Statistical Science, 25(1), 1–21. doi.org/10.1214/09-sts313
J. Tibshirani, S. Athey, R. Friedberg, V. Hadad, L. Miner, S. Wager, and M. Wright. grf:
Generalized Random Forests (Beta), 2018. URL https://github.com/grf-labs/grf. R
package version 0.10.2
White H. White (2018). Explicitly Optimizing on Causal Effects via the Causal Random
Forest: A Practical Introduction and Tutorial. URL:
www.Markhw.Com/blog/causalforestintro. Accessed on 9 May 2019

60
CURRICULUM VITAE
Polina Koroleva was born in 1994 in Saint Petersburg, Russia.
Polina completed her undergraduate studies in Saint Petersburg State University,
Liberal Arts and Science Department. She majored in Complex Systems. During her
undergraduate studies she spent a semester abroad at Bard College, USA. Her desire to
pursue graduate education in the USA was a inspired by that visit. She completed bachalors
thesis on “Application of the Complex Systems Methods to the Clustering Vegetation
Blocks” and graduated with honors.
In 2017 Polina began her Master program at Johns Hopkins University,
Environmental Health and Engineering Department. She joined Paul’s Ferraro lab, the
Environmental Program Innovations Collaborative, that is focused on creating evidence-
based program designs for acheiveing improved environmental outcomes. Within this
group and with guidance of Dr. Paul Ferraro, Polina conducted her research on machine
learning and causal inference in conservation science.