apache storm and kafka boston storm user group september 25, 2014 p. taylor goetz, hortonworks...
TRANSCRIPT

Apache Storm and KafkaBoston Storm User Group
September 25, 2014
P. Taylor Goetz, Hortonworks@ptgoetz

What is Apache Kafka?

A pub/sub messaging system.
Re-imagined as a distributed commit log.

Apache Kafka
Fast
“A single Kafka broker can handle hundreds of megabytes of reads and writes per second from thousands of clients.”
http://kafka.apache.org

Apache Kafka
Scalable
“Kafka is designed to allow a single cluster to serve as the central data backbone for a large organization. It can be elastically and transparently expanded without downtime.”
http://kafka.apache.org

Apache Kafka
Durable
“Messages are persisted on disk and replicated within the cluster to prevent data loss. Each broker can handle terabytes of messages without performance impact.”
http://kafka.apache.org

Apache Kafka
Distributed
“Kafka has a modern cluster-centric design that offers strong durability and fault-tolerance guarantees.”
http://kafka.apache.org

Apache Kafka: Use Cases
• Stream Processing
• Messaging
• Click Streams
• Metrics Collection and Monitoring
• Log Aggregation

Apache Kafka: Use Cases
• Greek letter architectures
• Which are really just streaming design patterns

Apache Kafka: Under the Hood
Producers/Consumers(Publish-Subscribe)

Apache Kafka: Under the Hood
Producers write data to Brokers
Consumers read data from Brokers
This work is distributed across the cluster

Apache Kafka: Under the Hood
Data is stored in topics.
Topics are divided into partitions.
Partitions are replicated.

Apache Kafka: Under the Hood
Topics are named feeds to which messages are published.
http://kafka.apache.org/documentation.html

Apache Kafka: Under the Hood
Topics consist of partitions.
http://kafka.apache.org/documentation.html

Apache Kafka: Under the Hood
A partition is an ordered and immutablesequence of messages that is continually appended to.
http://kafka.apache.org/documentation.html

Apache Kafka: Under the Hood
A partition is an ordered, immutablesequence of messages that is continually appended to.
http://kafka.apache.org/documentation.html

Apache Kafka: Under the Hood
Sequential disk access can be faster than RAM!
http://kafka.apache.org/documentation.html

Apache Kafka: Under the Hood
Within a partition, each message is assigned a uniqueID called an offset that identifies it.
http://kafka.apache.org/documentation.html

Apache Kafka: Under the Hood
http://kafka.apache.org/documentation.html
ZooKeeper is used to store cluster state
information and consumer offsets.

Storm and KafkaA match made in heaven.

Data Source Reliability
• A data source is considered unreliable if there is no means to replay a previously-received message.
• A data source is considered reliable if it can somehow replay a message if processing fails at any point.
• A data source is considered durable if it can replay any message or set of messages given the necessary selection criteria.

Data Source Reliability
• A data source is considered unreliable if there is no means to replay a previously-received message.
• A data source is considered reliable if it can somehow replay a message if processing fails at any point.
• A data source is considered durable if it can replay any message or set of messages given the necessary selection criteria.
Kafka is a durable data source.

Reliability in Storm• Exactly once processing requires a durable data
source.
• At least once processing requires a reliable data source.
• An unreliable data source can be wrapped to provide additional guarantees.
• With durable and reliable sources, Storm will not drop data.
• Common pattern: Back unreliable data sources with Apache Kafka (minor latency hit traded for 100% durability).

Storm and KafkaApache Kafka is an ideal source for Storm topologies. It provides everything necessary for:
• At most once processing
• At least once processing
• Exactly once processing
Apache Storm includes Kafka spout implementations for all levels of reliability.
Kafka Supports a wide variety of languages and integration points for both producers and consumers.

Storm-Kafka Integration
• Included in Storm distribution since 0.9.2
• Core Storm Spout
• Trident Spouts (Transactional and Opaque-Transactional)

Storm-Kafka Integration
Features:
• Ingest from Kafka
• Configurable start time (offset position):
• Earliest, Latest, Last, Point-in-Time
• Write to Kafka (next release)

Use Cases

Core Storm Use Case
Cisco Open Security Operations Center(OpenSOC)

Analyzing 1.2 Million Network Packets Per Second in Real Time

OpenSOC: Intrusion Detection
Breaches occur in sec./min./hrs.,but take days/weeks/months to discover.

Data 3V is not getting any smaller…

"Traditional Security analytics tools scale up, not out.”
"OpenSOC is a software application that turns a conventional big data platform into a security analytics platform.”
- James Sirota, Cisco Security Solutions
https://www.youtube.com/watch?v=bQTZ8OgDayA
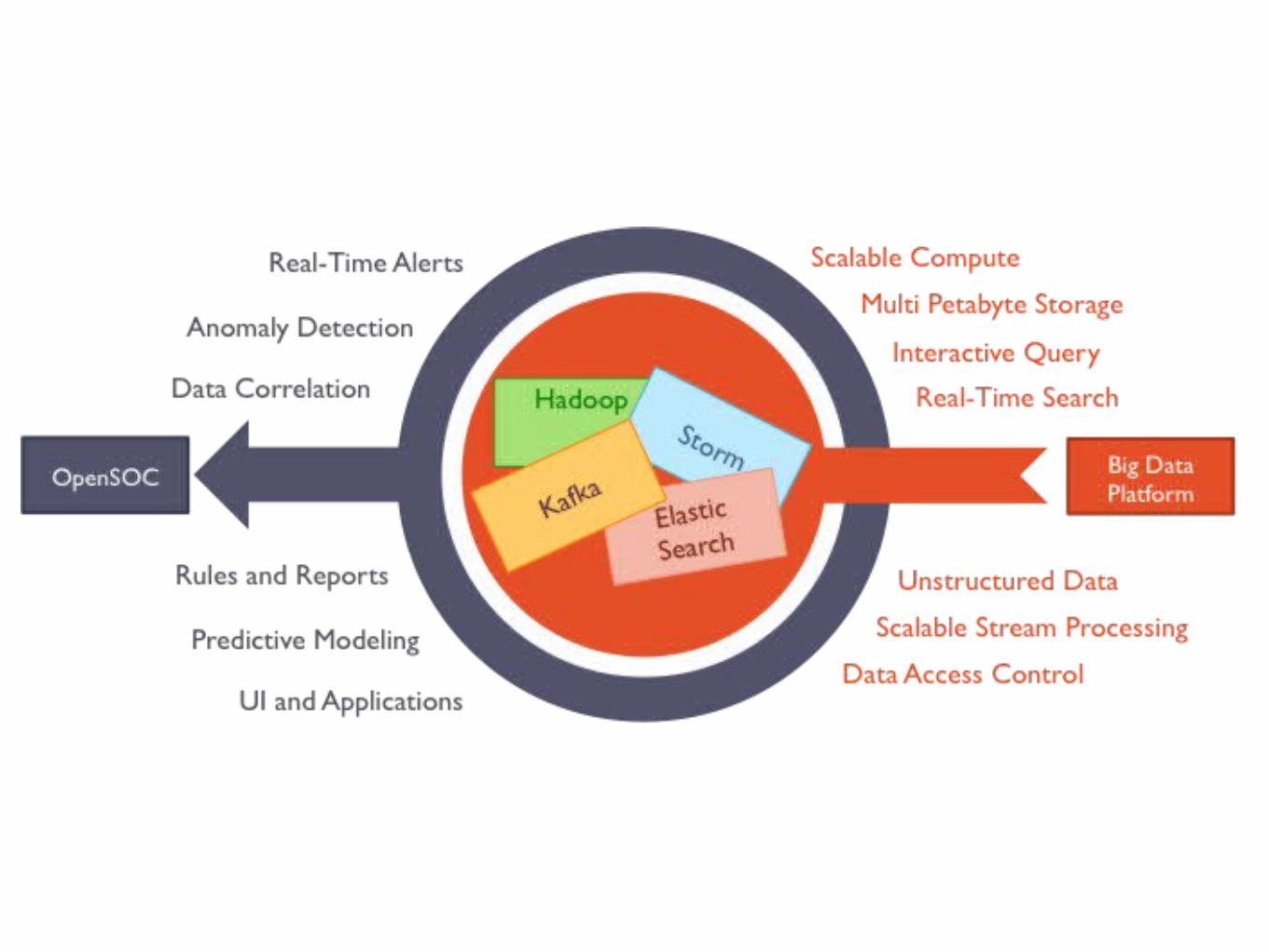
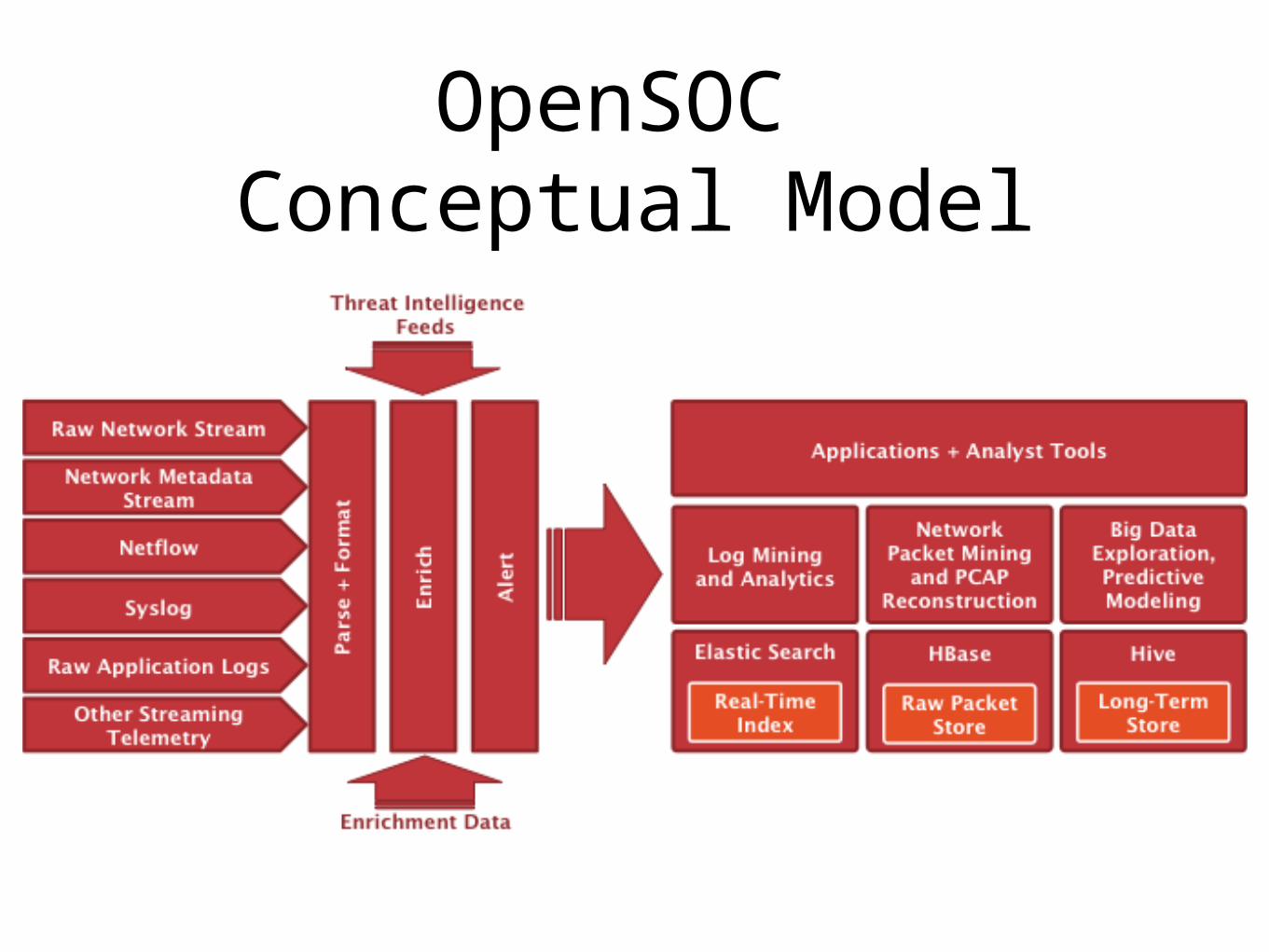
OpenSOC Conceptual Model
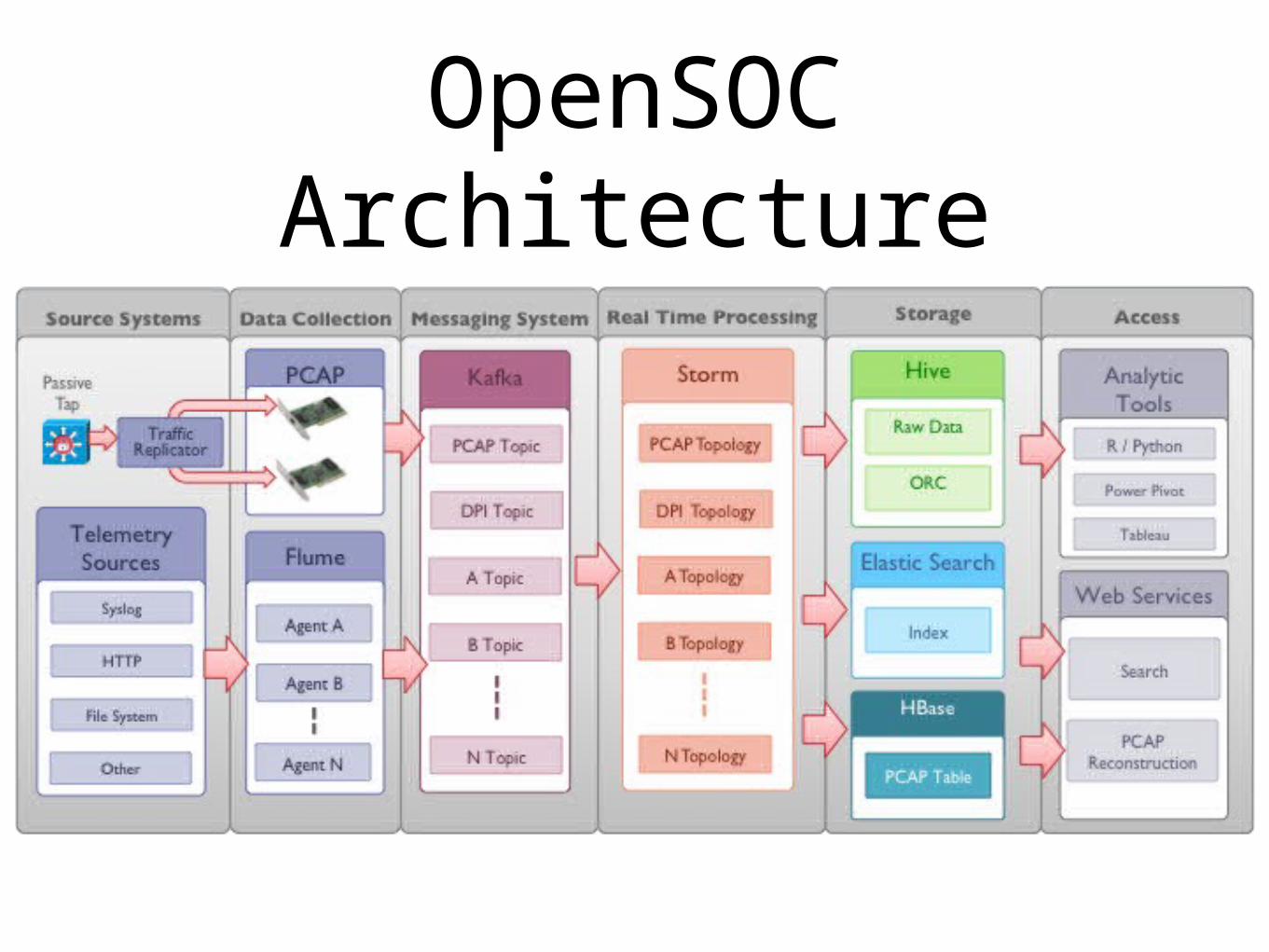
OpenSOC Architecture

PCAP Topology
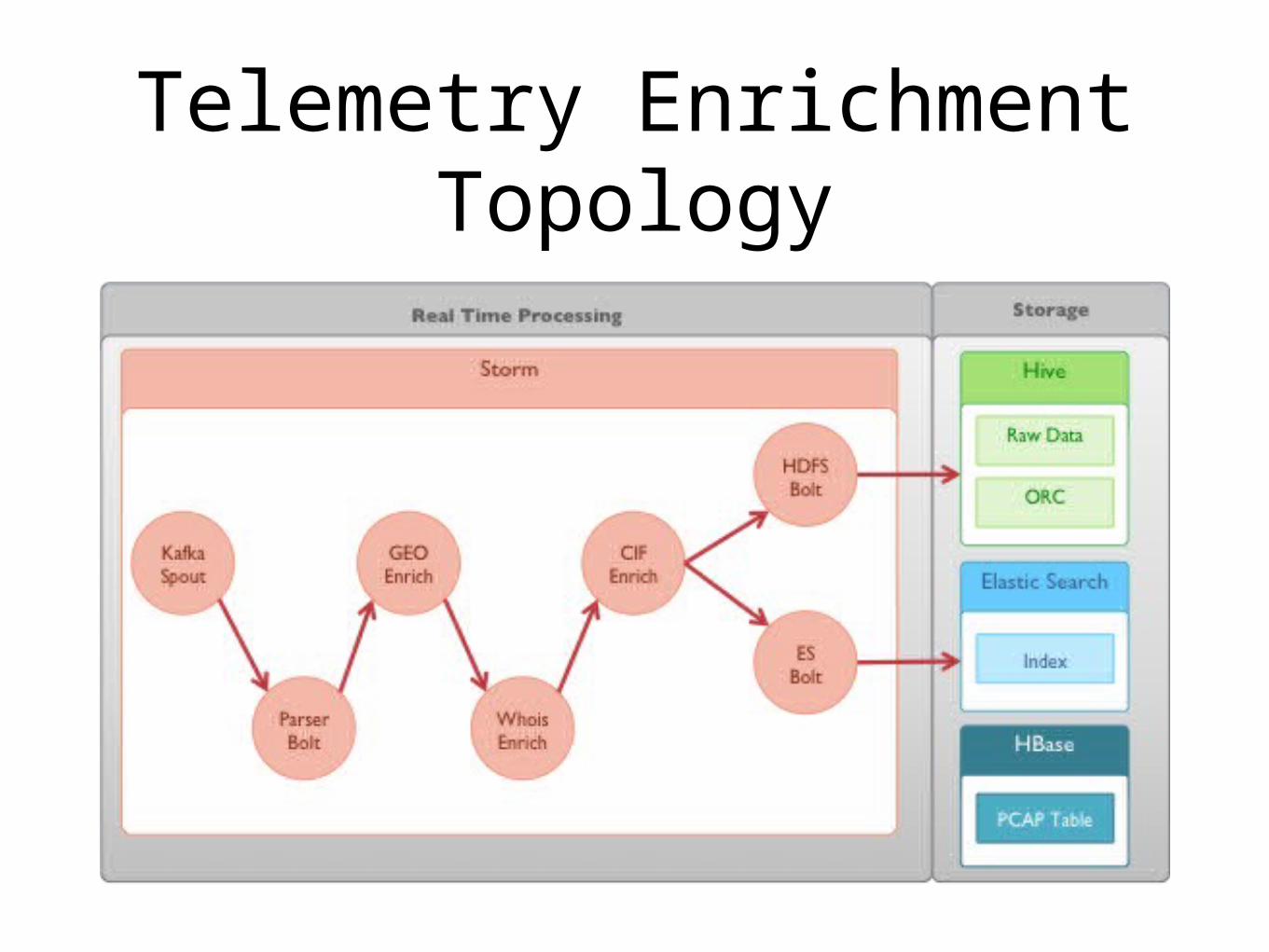
Telemetry Enrichment Topology

Enrichment

Analytics Dashboards

OpenSOC Deployment @ Cisco

Trident Use CaseHealth Market Science
Master Data Management

Health Market Science
• “Master File” database of every healthcare practitioner in the U.S.
• Kept up-to-date in near-real-time
• Represents the “truth” at any point in time (“Golden Record”)

Health Market Science
• Build products and services around the Master File
• Leverage those services to gather new data and updates

Master Data Management


Data In

Data Out

MDM Pipeline

Polyglot PersistenceChoose the right tool for the job.

Data Pipeline

Why Trident?
• Aggregations and Joins
• Bulk update of persistence layer (Micro-batches)
• Throughput vs. Latency

CassandraCqlState
public void commit(Long txid) {BatchStatement batch = new
BatchStatement(Type.LOGGED); batch.addAll(this.statements); clientFactory.getSession().execute(batch); }
public void addStatement(Statement statement) { this.statements.add(statement); } public ResultSet execute(Statement statement){ return clientFactory.getSession().execute(statement); }

CassandraCqlStateUpdater
public void updateState(CassandraCqlState state, List<TridentTuple> tuples, TridentCollector collector) {
for (TridentTuple tuple : tuples) { Statement statement = this.mapper.map(tuple); state.addStatement(statement); } }

Mapper Implementation
public Statement map(List<String> keys, Number value) {Insert statement = QueryBuilder.insertInto(KEYSPACE_NAME, TABLE_NAME);statement.value(KEY_NAME, keys.get(0));statement.value(VALUE_NAME, value);return statement;
}
public Statement retrieve(List<String> keys) {Select statement = QueryBuilder.select()
.column(KEY_NAME).column(VALUE_NAME)
.from(KEYSPACE_NAME, TABLE_NAME)
.where(QueryBuilder.eq(KEY_NAME, keys.get(0))); return statement;}

Storm Cassandra CQL
[email protected]:hmsonline/storm-cassandra-cql.git
{tuple} <— <mapper> —> CQL Statement
Trident Batch == CQL Batch

Customer Dashboard

Thanks!
P. Taylor Goetz, Hortonworks@ptgoetz