apache spark
TRANSCRIPT

APACHE SPARKINTRODUCTION
Apache spark is an open source cluster computing system that focus data analytics fast and both to run and fast to
write.Apache Spark is a fast, in-memory data processing engine with smart and expressive development APIs in Scala, Java, Python, and R that allow data workers to efficiently execute
machine learning algorithms that require fast iterative access to datasets .

Speed
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
Apache Spark has an advanced DAG execution engine that supports cyclic data flow and in-memory computing.

Ease of Use
Write applications quickly in Java, Scala, Python, R.
Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python and R shells

Generality
Compound SQL, streaming, and complex analytics.
Spark powers a stack of libraries including SQL and DataFrames,MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
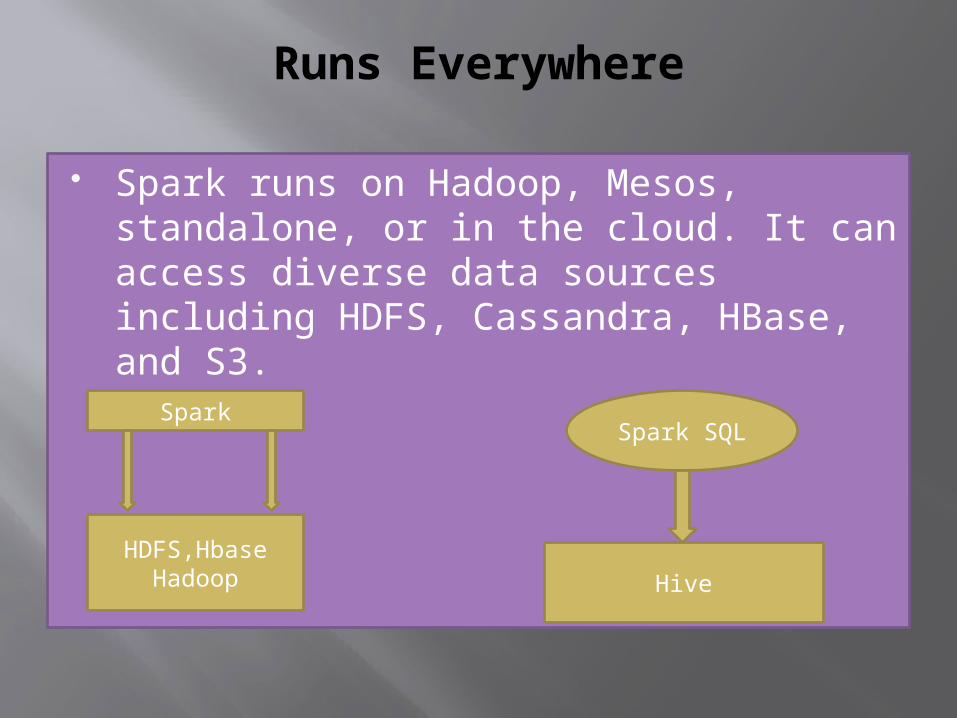
Runs Everywhere
Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.
Spark
HDFS,HbaseHadoop
Spark SQL
Hive

Spark is very easy to get started writing powerful Big Data applications
Spark uses different data storage model, resilient distributed datasets (RDD), uses a clever way of guaranteeing fault tolerance that minimizes network I/O
Spark has become another data processing engine in Hadoop ecosystem and which is good for all businesses and community as it provides more capability to Hadoop stack.
Spark enables applications in Hadoop clusters to run up to 100x faster in memory, and 10x faster even when running on disk. Spark makes it possible by reducing number of read/write to disc. It stores this intermediate processing data in-memory.

Spark SQL
Spark SQL is a component on top of Spark Core that introduces a new data abstraction called SchemaRDD, which provides support for structured and semi-structured data.

Spark advantages Iterative Algorithms in Machine Learning Interactive Data Mining and Data Processing Spark is a fully Apache Hive-compatible data
warehousing system that can run 100x faster than Hive.
Stream processing: Log processing and Fraud detection in live streams for alerts, aggregates and analysis
Sensor data processing: Where data is fetched and joined from multiple sources, in-memory dataset really helpful as they are easy and fast to process.

Spark Shell
Spark provides an interactive shell − a powerful tool to analyze data interactively. It is available in either Scala or Python language. Spark’s primary abstraction is a distributed collection of items called a Resilient Distributed Dataset (RDD). RDDs can be created from Hadoop Input Formats (such as HDFS files) or by transforming other RDDs.

RDD Transformations RDD transformations returns pointer to
new RDD and allows you to create dependencies between RDDs. Each RDD in dependency chain (String of Dependencies) has a function for calculating its data and has a pointer (dependency) to its parent RDD.
Spark is lazy, so nothing will be executed unless you call some transformation or action that will trigger job creation and execution