apache solr workshop
TRANSCRIPT


2
Agenda
1. What is Solr? Architecture Overview2. Solr schema, config, tokenizers and filters3. Indexing data:
a. From disk using SolrJb. Importing from database(MySQL) with DataImport Handler
4. Querying Solr a. Filters, Faceting, highlighting, sorting, grouping, boosting, range, function and
fuzzy queries)b. Using 'More Like This' component to show similar docsc. Adding 'Auto Suggest' component to auto complete user queriesd. Using 'Clustering' component to cluster similar results.
5. SolrClouda. Architectureb. Setting up a multinode cluster with Zookeeperc. Creating a distributed indexd. Collections API
6. Solr Admin UI7. Understanding Solr performance factors8. Solr vs. ElasticSearch - Overview
3
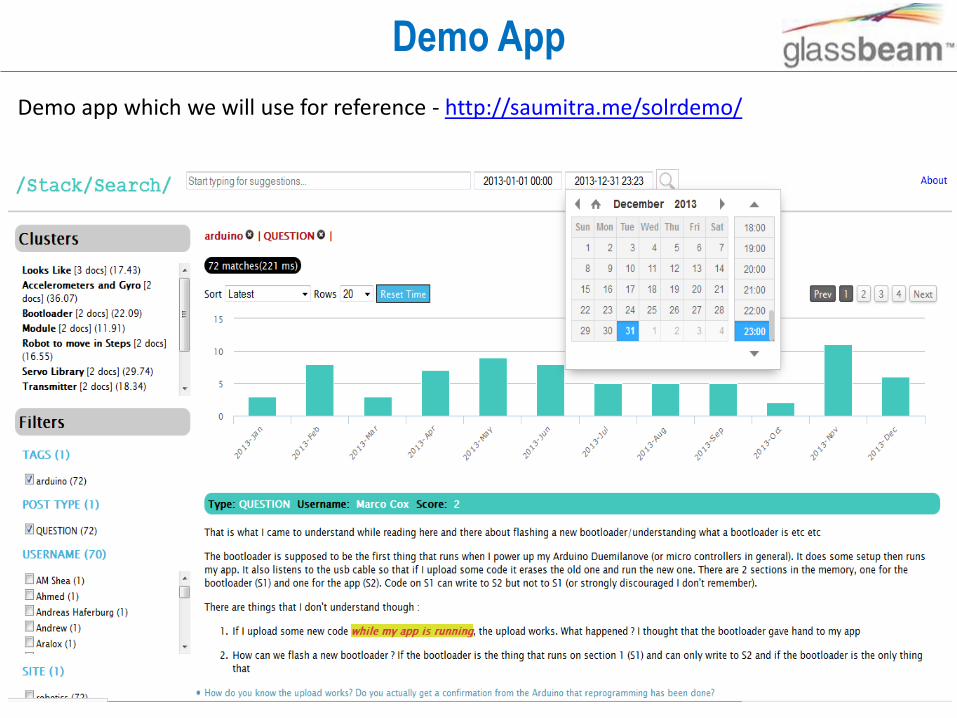
Demo App
Demo app which we will use for reference - http://saumitra.me/solrdemo/

4
Apache Lucene
• Apache Lucene is a high-performance, full-featured text search engine library • Provides API to add search and indexing to your applications• Provides scalable, High-Performance Indexing
• 150GB/hour on modern hardware• small RAM requirements -- only 1MB heap
• Powerful, Accurate and Efficient Search Algorithms• scoring • phrase queries, wildcard queries, proximity queries, range queries • sorting • allows simultaneous update and searching• flexible faceting, highlighting, joins and result grouping• fast, memory-efficient and typo-tolerant suggesters
• With Lucene you need to write code for doing all this.

5
Apache Solr
• Search server build on top of Apache Lucene• Provides API to access Lucene over HTTP• Add more features on top of lucene
• Most of the programming tasks in Lucene are configurations in Solr
• Provides SolrCloud which adds• Distributed search and indexing• High Scalability• Replication• Load Balancing• Fault Tolerance
• Solr is NOT a database• Can be used a NoSQL store, as long as it is not abused
• Provides lot of other feature like Faceting, More Like This, Clustering, Data Import Handler, Multiple language support, Rich document support
6
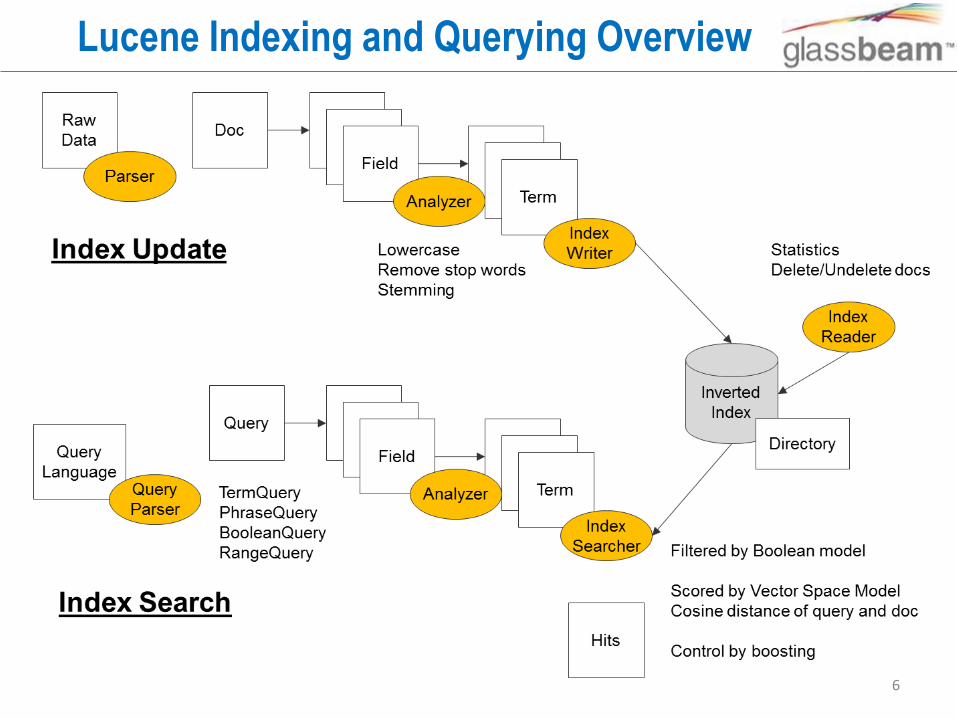
Lucene Indexing and Querying Overview
7
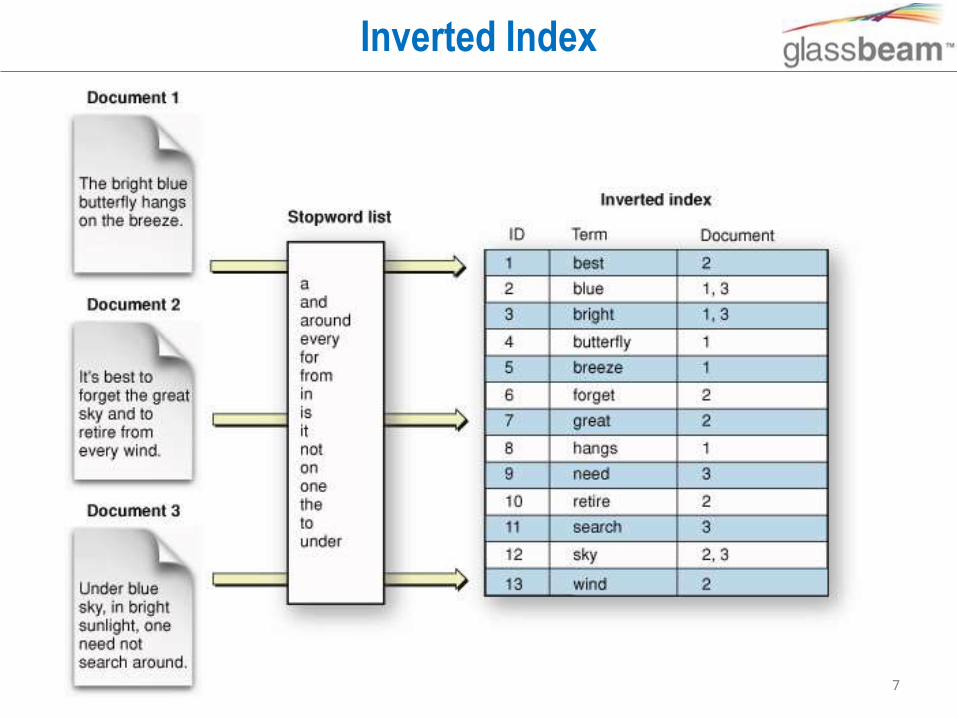
Inverted Index

8
Basic Concepts
• tf (t in d) : term frequency in a document • measure of how often a term appears in the document• the number of times term t appears in the currently scored document d
• idf (t) : inverse document frequency • measure of whether the term is common or rare across all documents, i.e. how often the
term appears across the index• obtained by dividing the total number of documents by the number of documents
containing the term, and then taking the logarithm of that quotient.
• coord : coordinate-level matching • number of terms in the query that were found in the document,• e.g. term ‘x’ and ‘y’ found in doc1 but only term ‘x’ is found in doc2 so for a query of ‘x’ OR
‘y’ doc1 will receive a higher score.
• boost (index) : boost of the field at index-time
• boost (query) : boost of the field at query-time
8

9
Apache Solr architecture

10
Enough talk...lets get our hands dirty

11
Hands-On Activity 1
Objective:
1. Solr directories walkthrough2. Start single node solr instance3. Index some sample documents4. Admin UI overview

12
Getting Started - Start a solr node
• Go to Solr directory• cd /home/solruser/work/solr-4.8.1/
• Make a copy of example folder• cp -r example node0
• Go to node0 and start solr instance. • cd /home/solruser/work/solr-4.8.1/node0• java -jar start.jar• This will launch jetty with the Solr war and the example configs.
• By default solr starts on port 8983. To give a custom port:• java -Djetty.port=9000 -jar start.jar
• Open your browser and point to http://localhost:8983/solr to see Solr Admin UI
• You will see a default collection named collection1.

13
Solr Schema
• Before indexing document, you need to define a schema. A schema serves multiple purpose.
• Field related information• Fields in you document• Datatype of those fields• Whether you want to index the field or store it or both• Other configurations for each field like termVectors, termPositions, docValues, etc• Dynamic fields• Copy Fields
• Datatypes• A datatype is a collection of tokenizers and filters which can be chained• It tells Solr what operations to perform on the content of a field• You can define different analyzers for indexing and querying
• Solr also provides a schemaless mode where it can auto-detect the dataypes of fields.

14
Analyzers
• Analyzers are components that pre-process input text at index time and/or at query time.
• You can define separate analyzer for indexing and querying• Make sure that you define indexing and querying analyzers in a compatible
manner.
• Analyzer consists of:• Char Filter• Tokenizers• Token Filters

15
Analyzers
Char Filter
Tokenizers
Token Filters
Char Filter (solr.HTMLStripCharFilterFactory)
Text Data
This is a sample HTML document.
Tokenizer (solr.WhitespaceTokenizerFactory)
[This] [is] [a] [sample] [HTML] [document.]
Token Filters (solr.StopFilterFactory &
solr. LowerCaseFilterFactory)
Tokens Tokens: [sample] [html] [document]
<html> <body><h1> This is a sample HTML document .</h1>
</body></html>
Analyzer Analyzer

16
Analyzers - Example

17
Separate index and query analyzer

18
Char Filters
• Char Filter is a component that pre-processes input characters (consuming and producing a character stream) that can add, change, or remove characters while preserving character position information.
• CharFilters can be chained.
• Example:
<charFilter class="solr.PatternReplaceCharFilterFactory" pattern="([^a-z])" replacement="“
/>

19
Tokenizers
• A Tokenizer splits a stream of characters (from each individual field value) into a series of tokens.
• There can be only one Tokenizer in each Analyzer.
• Solr provides following tokenization factories• solr.KeywordTokenizerFactory• solr.LetterTokenizerFactory• solr.WhitespaceTokenizerFactory• solr.LowerCaseTokenizerFactory• solr.StandardTokenizerFactory• solr.ClassicTokenizerFactory• solr.UAX29URLEmailTokenizerFactory• solr.PatternTokenizerFactory• solr.PathHierarchyTokenizerFactory• solr.ICUTokenizerFactory

20
Token Filters
• Tokens produced by the Tokenizer are passed through a series of Token Filters
• TokenFilters can add, change, or remove tokens.
• The field is then indexed by the resulting token stream.
• Detailed information about analyzers can be obtained from https://cwiki.apache.org/confluence/display/solr/Understanding+Analyzers,+Tokenizers,+and+Filters

21
Dynamic Fields
• Dynamic fields allow Solr to index fields that you did not explicitly define in your schema.
• A dynamic field is just like a regular field except it has a name with a wildcard in it.
• When you are indexing documents, a field that does not match any explicitly defined fields can be matched with a dynamic field.
22
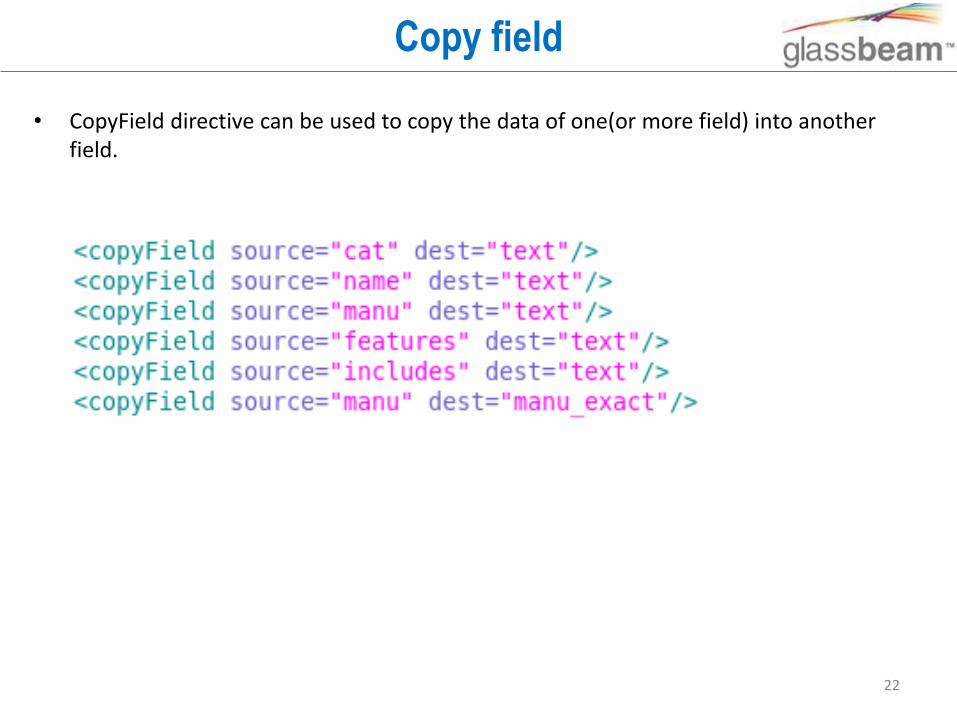
Copy field
• CopyField directive can be used to copy the data of one(or more field) into another field.

23
Fields Parameters
1. Indexed2. Stored3. Multivalued4. DocValues5. OmitNorms6. TermVectors7. TermPositions8. TermOffsets

24
Hands-On Activity 2
Objective:
1. Create a new collection2. Understand schema.xml contents3. Create a custom datatype4. Create schema for stackexchange data5. Learn how to use Admin UI to analyze and tune fieldTypes

25
Solr Schema-less mode

26
Indexing Data
• You can modify a Solr index by POSTing commands to Solr to add (or update) documents, delete documents, and commit pending adds and deletes.
• Add:
• ID field is the uniqueKey (aka primary key). In some cases you don’t need it. But you should always define one. ID can be autogenerated.http://wiki.apache.org/solr/UniqueKey
curl http://localhost:8983/solr/update?commit=true -H "Content-Type: text/xml“--data-binary '<add><doc>
<field name="id">id1</field> <field name=“content">My First Doc</field>
</doc></add>'

27
Indexing Data (cont...)
• Solr natively supports indexing structured documents in XML, CSV and JSON.
• Provides multiple request handlers called index handlers to add, delete and update documents to the index.
• There is a unified update request handler that supports XML, CSV, JSON, and javabinupdate requests:
• You can define new requestHandlers and register them in solrconfig.xml.
• https://cwiki.apache.org/confluence/display/solr/Uploading+Data+with+Index+Handlers
<requestHandler name="/update" class="solr.UpdateRequestHandler" />

28
Atomic Updates
• Sending an update request with an existing ID will overwrite that document.
• Solr also supports simple atomic updates where you can modify only parts of a single document.
• Solr supports several modifiers that atomically update values of a document. 1. set – set or replace a particular value, or remove the value if null is specified as
the new value2. add – adds an additional value to a list3. inc – increments a numeric value by a specific amount
curl http://localhost:8983/solr/update
-H 'Content-type:application/json'
-d '[{
"id" : “message1",
“source" : {"set":“error_log"},
“count" : {"inc":4},
“tags" : {"add":“apache"}
}]'

29
Solr Clients
• There are lot of clients for indexing and querying Solr. http://wiki.apache.org/solr/IntegratingSolr
• Clinet Languages• Ruby • PHP • Java • Scala• Python• .NET • Perl • JavaScript

30
Indexing with SolrJ
• SolrJ is a java client to access solr. It offers a java interface to add, update, and query the solr index.
SolrServer server = new HttpSolrServer("http://HOST:8983/solr/");
SolrInputDocument doc1 = new SolrInputDocument();
doc1.addField( "id", “doc1");
doc1.addField( “content", “This is first document” );
SolrInputDocument doc2 = new SolrInputDocument();
doc2.addField( "id", “doc2")
.addField( “content", “This is second document” );
Collection<SolrInputDocument> docs = new
ArrayList<SolrInputDocument>();
docs.add( doc1 );
docs.add( doc2 );
server.add(docs);
server.commit();

31
Indexing with SolrJ (cont…)
• SolrJ includes a client for SolrCloud, which is ZooKeeper aware
• To interact with SolrCloud, you should use an instance of CloudSolrServer, and pass it your zooKeeper host(s).
• More on SolrCloud later.
CloudSolrServer server = new CloudSolrServer("localhost:2181");
server.setDefaultCollection(“mycollection");
SolrInputDocument doc = new SolrInputDocument();
....
....
server.commit();

32
Transaction Log and Commit
• Transaction log(tlog):• File where the raw documents are written for recovery purposes• On update, the entire document gets written to the tlog
• Commits:• Hard commit• Soft Commit
• Soft commits are about visibility, hard commits are about durability.
• More on this when we discuss SolrCloud

33
Hands-On Activity 3
Objective:
1. Creating a java project and add SolrJ dependency2. Indexing single doc using SolrJ3. Indexing in batch mode4. Understand commit

34
Data Import Handler
• DataImportHandler provides a configuration driven way to import data from external source into Solr
• External sources can be:• Databases• ftp, scp, etc• XML, JSON, etc
• Provides options for full or delta imports

35
Data Import Handler (cont...)
• A SolrRequestHandler must be defined in solr-config.xml
• The data source can be added inline, or it can be put directly into the data-config.xml
• data-config.xml tells Solr:1. How to fetch data (queries,url etc)2. What to read ( resultset columns, xml fields etc)3. How to process (modify/add/remove fields)
https://cwiki.apache.org/confluence/display/solr/Uploading+Structured+Data+Store+Data+with+the+Data+Import+Handler
<requestHandler name="/dataimport"
class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>

36
Data Import Handler - Script Transformers
• You can specify different types of transformation on data read from external source before indexing in Solr
• Can be used to index dynamic fields using data import handlers
<dataConfig>
<script><![CDATA[
function WareAttributes(row){
row.put('attr_' + row.get('id'), row.get('raw_value') );
row.remove('id');
row.remove('raw_value');
return row;
}
]]></script>
...
<entity
name="attrs"
query="SELECT attribute_id as id, raw_value
FROM
ware_wareattribute WHERE ware_id = ${ware.id}"
transformer="script:WareAttributes"/>
</entity>
</document>
</dataConfig>

37
Objective:
1. Create MySQL tables for storing stackechange data• Posts• Users• Comments
2. Load stackexchange dumps in MySQL
3. Define a data import handler• Adding dependency and request handler in solrconfig.xml• Define a data-config.xml file for solr to mysql fields mapping
4. Index document in Solr using data import handler• Full import• Delta import
5. Defining transformer
Hands-On Activity 4

38
Querying
• Solr supports multiple query syntaxes through query parser plugins
• A Query Parser is a component responsible for parsing the textual query and convert it into corresponding Lucene Query objects.
• Solr provides a lot of in-built parsers• lucene - The default "lucene" parser • dismax - allows querying across multiple fields with different weights • edismax - builds on dismax but with more features • Func• Boost
and many more (https://wiki.apache.org/solr/QueryParser)
• There are multiple ways to select which query parser to use for a certain request1. defType - The default type parameter selects which query parser to use by default
for the main query. Example: &q=foo bar&defType=lucene
2. LocalParams - Inside the main q or fq parameter you can select query parser using the localParam syntax. Example: &q={!dismax}foo bar

39
Defining a search handler

40
Querying (cont...)
• Simple text search• http://localhost:8983/solr/collection1/stacksearch?q=da
ta
• Change number of rows retrieved• http://localhost:8983/solr/collection1/stacksearch?q=da
ta&rows=20
• Pagination• http://localhost:8983/solr/collection1/stacksearch?q=da
ta&rows=20&start=50

41
Querying (cont...)
• Searching on a field• http://localhost:8983/solr/collection1/stacksearch?q=st
_post:data
• http://localhost:8983/solr/collection1/stacksearch?q=st
_posttype:data
• Specifying list of fields to be retrieved• http://localhost:8983/solr/collection1/stacksearch?q=st
_post:data&fl=id,st_post,st_tags
• Delete all documents• http://localhost:8983/solr/collection1/update?stream.body=<delete><query>*:*
</query></delete>&commit=true

42
Querying (cont...)
• Searching multiple fields• http://localhost:8983/solr/collection1/stacksearch?q=st
_post:data AND st_posttype:QUESTION
• NOT query• http://localhost:8983/solr/collection1/stacksearch?q=NO
T st_post:data
• Boolean query• http://localhost:8983/solr/collection1/stacksearch?q=st_post:(data+sensor)• http://localhost:8983/solr/collection1/stacksearch?q=st_post:(data OR sensor)
• Sort Query• http://localhost:8983/solr/collection1/stacksearch?q=st_post:data&fl=id,st_post,s
t_score&sort=st_score desc

43
Querying - Faceting

44
Querying - Faceting
• Enable faceting on 2 fields• http://localhost:8983/solr/collection1/stacksearch?q=st
_post:data&facet=true&facet.field=st_posttype&facet.fie
ld=st_tags
• Changing limit and mincount• http://localhost:8983/solr/collection1/stacksearch?q=st
_post:data&facet=true&facet.field=st_posttype&facet.fie
ld=st_tags&facet.limit=1000&facet.mincount=1
• Changing facet method• http://localhost:8983/solr/collection1/stacksearch?q=st
_post:data&facet=true&facet.field=st_posttype&facet.fie
ld=st_tags&facet.limit=1000&facet.mincount=1&facet.meth
od=enum

45
Stats query
• http://localhost:8983/solr/collection1/select?q=*:*&rows=0&
stats=true&stats.field=st_creationdate

46
Facet Range Query
http://localhost:8983/solr/collection1/select?q=*:*&rows=0&facet=true&facet.range=st_creationdate&facet.range.start=2011-03-22T01:33:06Z&facet.range.end=2014-03-22T01:33:06Z&facet.range.gap=%2B1YEAR

47
Range, Boosting, Fuzzy, Proximity Query
• Range• http://localhost:8983/solr/collection1/select?q=st_scor
e:[1 TO 3]&fl=id,st_score
• Boosting on a field• http://localhost:8983/solr/select/?defType=dismax&q=dat
a&bq=st_posttype:QUESTION^5.0&qf=st_post
• Fuzzy Search• http://localhost:8983/solr/collection1/select?defType=d
ismax&q=electromagnet~0.9&qf=st_post
• Proximity search• http://localhost:8983/solr/collection1/stacksearch?q=“c
alculating coordinates”~2

48
Function Queries
• Function queries enable you to generate a relevancy score using the actual value of one or more numeric fields.
• Examples:
1. http://localhost:8983/solr/collection1/select?q=*:*&fl=
sum(st_score,st_favoritecount),st_score,st_favoritecoun
t
2. http://localhost:8983/solr/collection1/select?q=*:*&fl=
max(st_score,st_favoritecount),st_score,st_favoritecoun
t
3. http://localhost:8983/solr/collection1/select?q=*:*&fl=
ms(NOW,st_creationdate),st_creationdate
4. http://localhost:8983/solr/collection1/select?q=st_titl
e:*&fl=norm(st_title),st_title
• https://cwiki.apache.org/confluence/display/solr/Function+Q
ueries

49
Group and Term Query
• Term• http://localhost:8983/solr/collection1/terms?terms.fl=s
t_post&terms.prefix=data
• Group• http://localhost:8983/solr/collection1/select?q=st_post
:*&group=true&group.field=st_site

50
More Like This
• The MoreLikeThis search component enables users to query for documents similar to a document in their result list.
• It uses terms from the original document to find similar documents in the index.
• Ways to use MLT:1. Request handler2. Search component3. MoreLikeThisHandler - request handler with externally supplied text
http://localhost:8983/solr/collection1/select?
q=id:windowsphone_197
&mlt.count=5
&mlt=true
&mlt.fl=st_post
&mlt.interestingTerms=data

51
Clustering
• Solr uses Carrot library for clustering search results and documents
• Clustering can be used to:• summarize a whole bunch of results/documents• group together semantically related results/documents
• To use clustering:• Add ClusteringComponent in solrconfig.xml• Reference the clustering component in request handler
• Supports 3 algorithm:• Lingo• STC• BisectingKMeans
http://localhost:8983/solr/collection1/stacksearch?q=st_post:
data&clustering=true&clustering.results=true&carrot.title=st_
post&rows=20
52
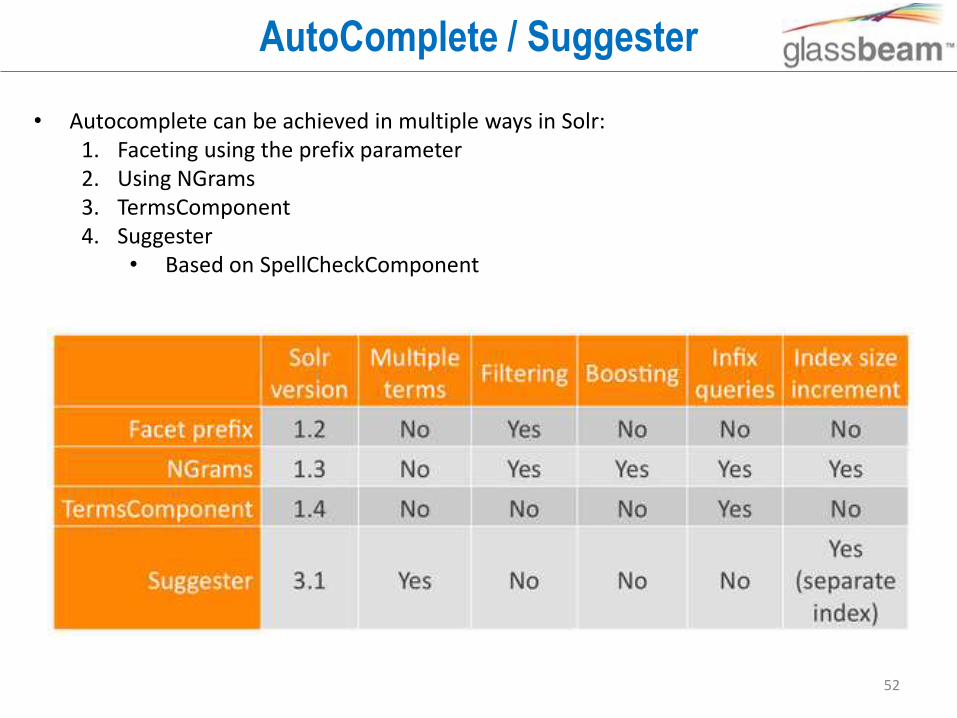
AutoComplete / Suggester
• Autocomplete can be achieved in multiple ways in Solr:1. Faceting using the prefix parameter2. Using NGrams3. TermsComponent4. Suggester
• Based on SpellCheckComponent

53
Hands-On Activity 5
Objective:
1. Define a search handler named stacksearch and declare 1. defaults2. appends3. last-components
2. Try out different queries from the queries note and understand the response format & content
3. Define a suggester component for ‘autocomple’ using ‘post’ field as source

54
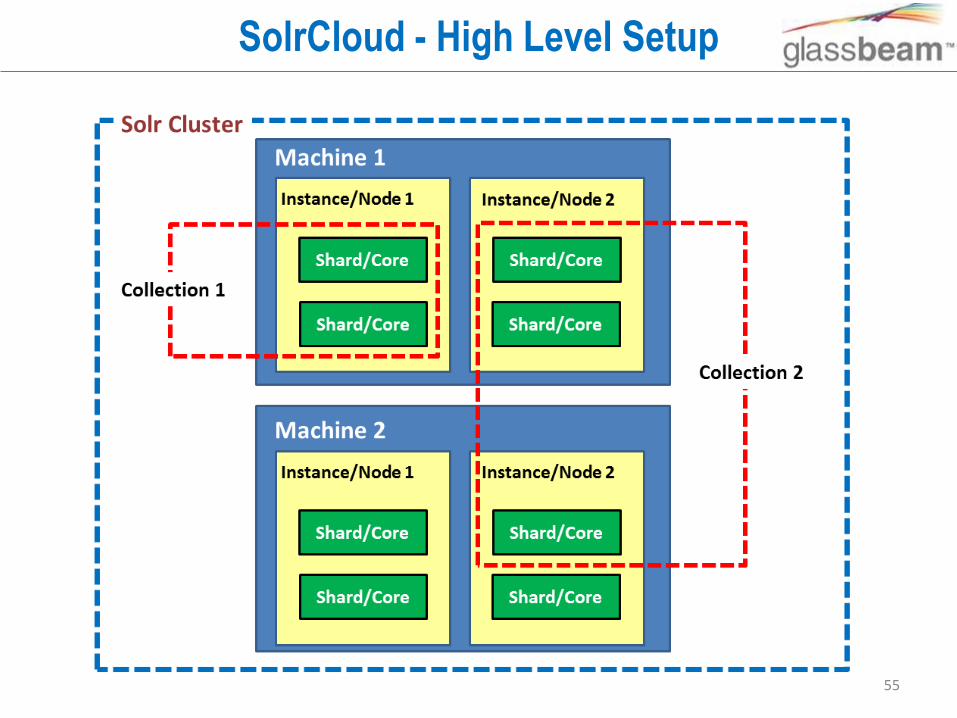
SolrCloud
• SolrCloud is NOT Solr deployed on cloud
• SolrCloud provides the ability to setup cluster of Solr servers that combines fault tolerance and high availability and provides distributed indexing and search capabilities.
• Subset of optional features in Solr to enable and simplify horizontal scaling a search index using sharding and replication.
• SolrCloud provides1. performance2. scalability3. high-availability4. simplicity5. elasticity
55
SolrCloud - High Level Setup
56
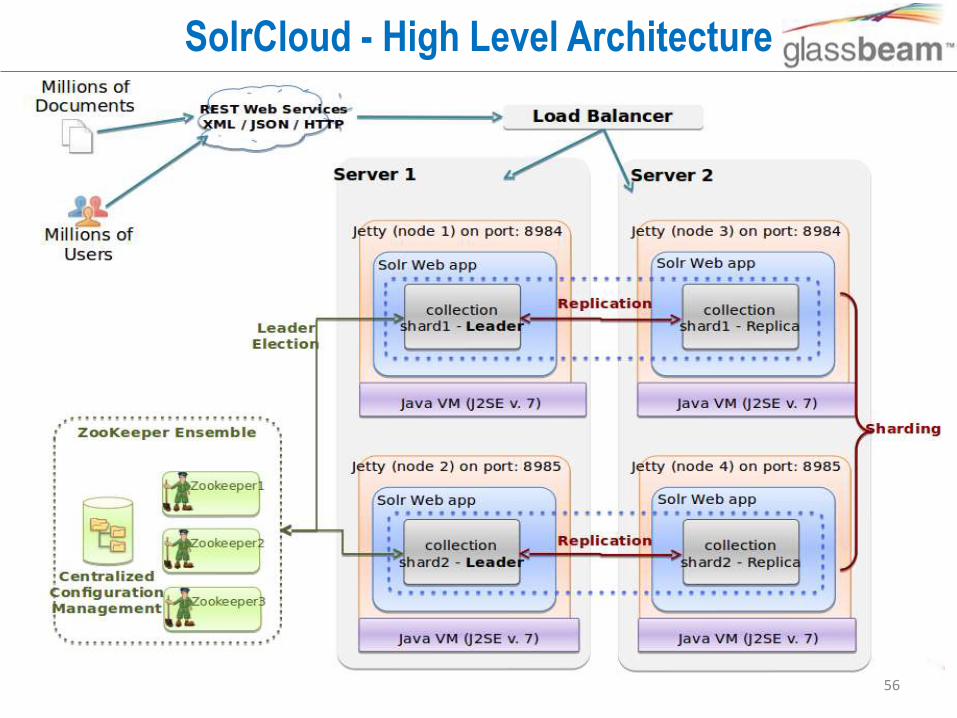
SolrCloud - High Level Architecture

57
SolrCloud - Terminology
• ZooKeeper: Distributed coordination service that provides centralized configuration, cluster state management, and leader election
• Node: JVM process bound to a specific port on a machine; hosts the Solr web application
• Collection: Search index distributed across multiple nodes; each collection has a name, shard count, and replication factor
• Replication Factor: Number of copies of a document in a collection
• Shard: Logical slice of a collection; each shard has a name, hash range, leader, and replication factor. Documents are assigned to one and only one shard per collection using a hash-based document routing strategy
• Replica: Solr index that hosts a copy of a shard in a collection; behind the scenes, each replica is implemented as a Solr core
• Leader: Replica in a shard that assumes special duties needed to support distributed indexing in Solr; each shard has one and only one leader at any time and leaders are elected using ZooKeeper

58
SolrCloud - Collections
• A collection is a distributed index defined by:
1. named configuration stored in ZooKeeper
2. number of shards: documents are distributed across N partitions of the index
3. document routing strategy: how documents get assigned to shards
4. replication factor: how many copies of each document in the collection

59
SolrCloud - Sharding
• Collection has a fixed number of shards• existing shards can be split
• When to shard?• Large number of docs• Large document sizes• Parallelization during indexing and queries• Data partitioning (custom hashing)

60
SolrCloud - Replication
• Why replicate?• High-availability• Load balancing
• How does it work in SolrCloud?• Near-real-time, NOT master-slave• Leader forwards to replicas in parallel, • waits for response• Error handling during indexing is tricky

61
SolrCloud - Document Routing
• Each shard covers a hash-range
• Default: Hash ID into 32-bit integer, map to range• leads to balanced (roughly) shards
• Custom-hashing
• Tri-level: app!user!doc
• Implicit: no hash-range set for shards

62
SolrCloud - Distributed Indexing

63
SolrCloud - Distributed Querying

64
SolrCloud - Shard Splitting
• Can split shards into two sub-shards
• Live splitting. No downtime needed.
• Requests start being forwarded to sub-shards automatically
• Expensive operation: Use as required during low traffic

65
Collections API
• https://cwiki.apache.org/confluence/display/solr/Collections+API
• API’s to create and perform operations on collections:1. CREATE: create a collection2. RELOAD: reload a collection3. SPLITSHARD: split a shard into two new shards4. CREATESHARD: create a new shard5. DELETESHARD: delete an inactive shard6. CREATEALIAS: create or modify an alias for a collection7. DELETEALIAS: delete an alias for a collection8. DELETE: delete a collection9. DELETEREPLICA: delete a replica of a shard10. ADDREPLICA: add a replica of a shard11. CLUSTERPROP: Add/edit/delete a cluster-wide property12. MIGRATE: Migrate documents to another collection 13. ADDROLE: Add a specific role to a node in the cluster14. REMOVEROLE: Remove an assigned role15. OVERSEERSTATUS: Get status and statistics of the overseer16. CLUSTERSTATUS: Get cluster status17. REQUESTSTATUS: Get the status of a previous asynchronous request

66
Hands-On Activity 6
Objective:
1. Setup a 2 instance zookeeper quorum2. Launch a 4 node Solr cluster3. Upload a configSet to zookeeper4. Create a 2 shard 2 replica collection using Collections API5. Index document with SolrJ using CloudSolrServer

67
Solr Performance Factors

68
Solr vs
ElasticSearch

69
Thanks!
• Solr references• https://cwiki.apache.org/confluence/display/solr/Apache+Solr+Reference
+Guide• https://www.youtube.com/user/LuceneSolrRevolution/videos
• Mailing List• User - [email protected]• Dev - [email protected]
• Attributions• Shalin Mangar - @shalinmangar• Erik Hatcher - @ErikHatcher• Timothy Potter - @thelabdude• Yonik Seeley - @lucene_solr