apache hadoop crash course
TRANSCRIPT

ApacheHadoopCrashCourseRafaelCossDataEvangelist@racoss#FutureOfData

2 ©HortonworksInc.2011– 2016.AllRightsReserved
AgendaFutureofData
TraditionalDataArchitectures
What’sApacheHadoop?
DataAccesswithHadoop
LabIntro
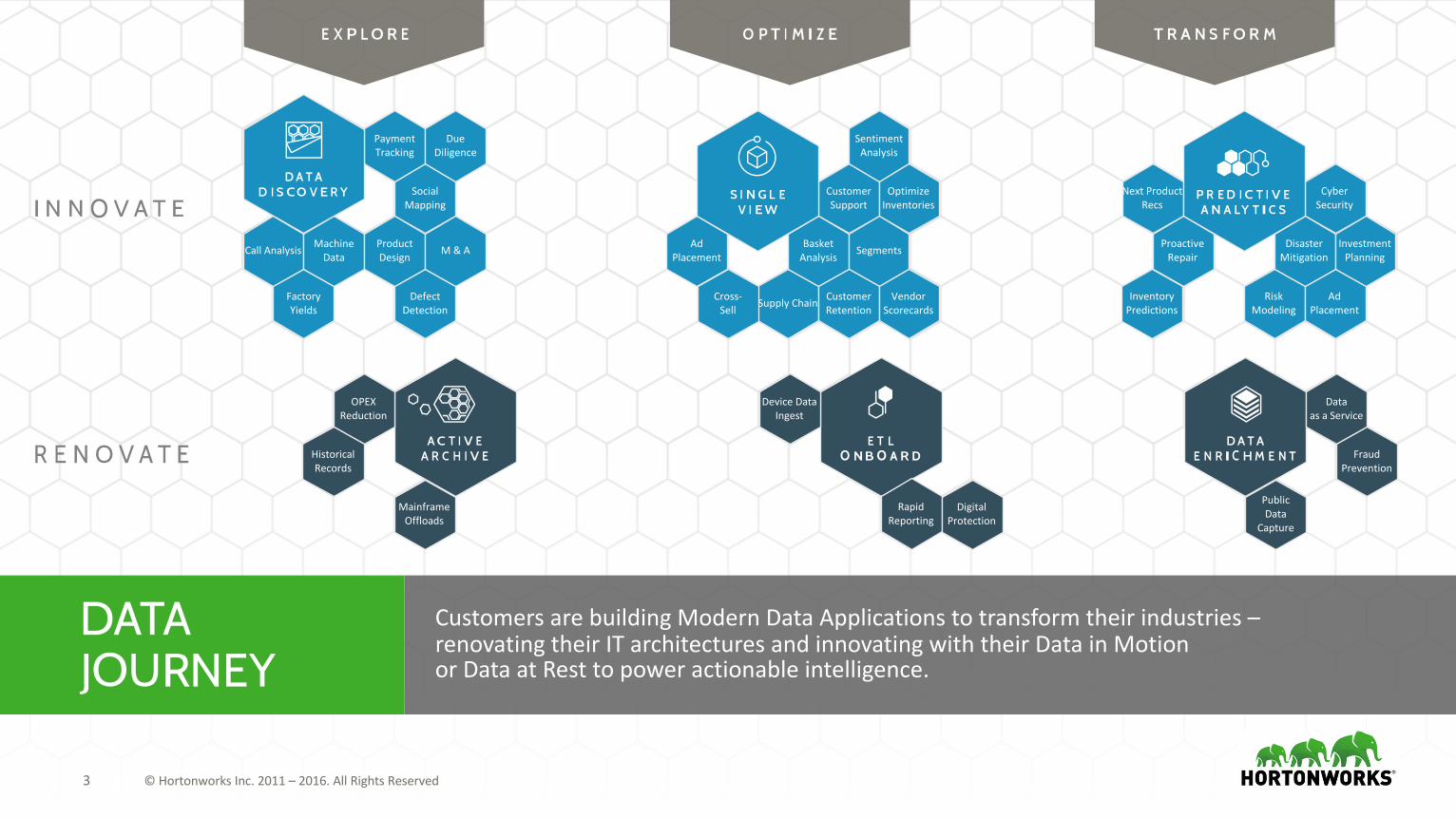
3 ©HortonworksInc.2011– 2016.AllRightsReserved
CustomersarebuildingModernDataApplicationstotransformtheirindustries–renovatingtheirITarchitecturesandinnovatingwiththeirDatainMotionorDataatResttopoweractionableintelligence.
SocialMapping
PaymentTracking
FactoryYields
DefectDetection
CallAnalysis MachineData
ProductDesign M&A
DueDiligence
NextProductRecs
CyberSecurity
RiskModeling
AdPlacement
ProactiveRepair
DisasterMitigation
InvestmentPlanning
InventoryPredictions
CustomerSupport
SentimentAnalysis
SupplyChain
AdPlacement
BasketAnalysis Segments
Cross-Sell
CustomerRetention
VendorScorecards
OptimizeInventories
OPEXReduction
MainframeOffloads
HistoricalRecords
DataasaService
PublicData
Capture
FraudPrevention
DeviceDataIngest
RapidReporting
DigitalProtection
3 © HortonworksInc.2011– 2016.AllRightsReserved

FutureofData

5 ©HortonworksInc.2011– 2016.AllRightsReserved
INTERNETOF
ANYTHING
TheFutureofDataisaboutactionableintelligencederivedfromaconstantlyconnectedsociety,withinteractivesecureaccesstorichdatasetscomingfromtheInternetofAnything
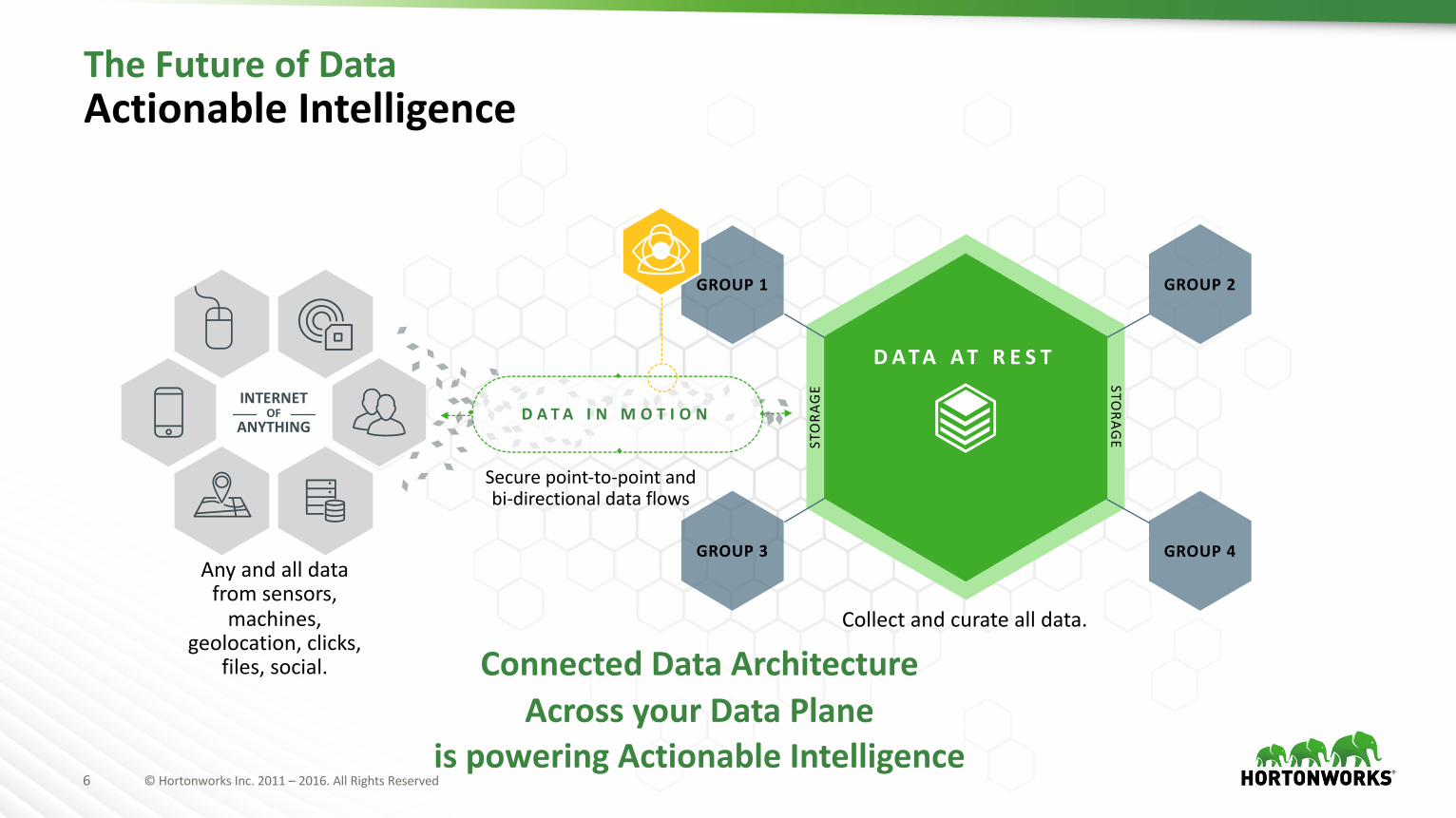
6 ©HortonworksInc.2011– 2016.AllRightsReserved
TheFutureofDataActionableIntelligence
D ATA I N M O T I O N
STORAG
ESTORA
GE
GROUP2GROUP1
GROUP4GROUP3
D ATA AT R E S T
INTERNETOF
ANYTHING
ConnectedDataArchitectureAcrossyourDataPlane
ispoweringActionableIntelligence
Anyandalldatafromsensors,machines,
geolocation,clicks,files,social.
Securepoint-to-pointandbi-directionaldataflows
Collectandcuratealldata.

DataPowersHighwaySafety
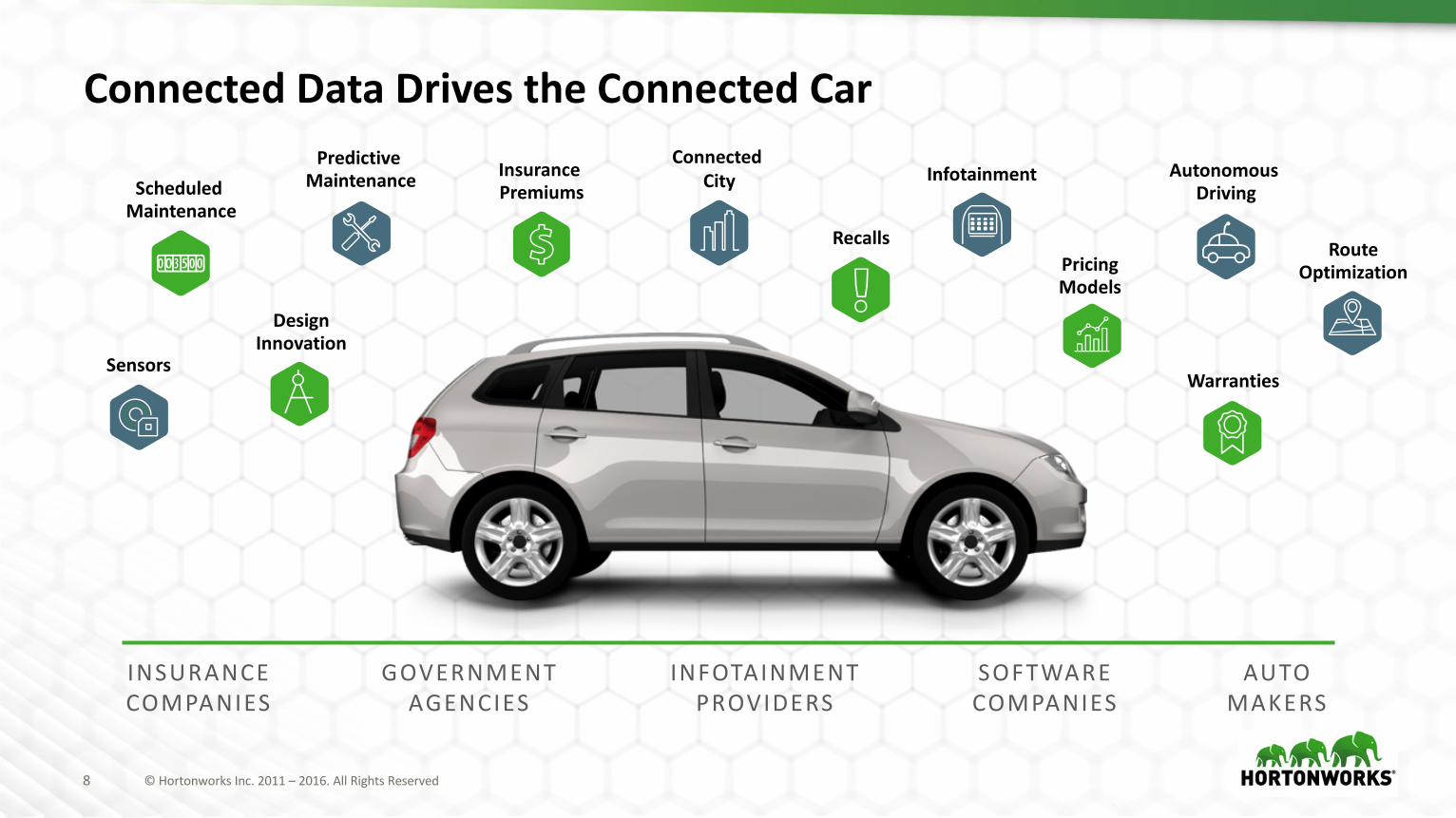
8 ©HortonworksInc.2011– 2016.AllRightsReserved8 ©HortonworksInc.2011– 2016.AllRightsReserved
ConnectedDataDrivestheConnectedCarInsurancePremiums
Warranties
RecallsPricingModels
DesignInnovation
AutonomousDriving
ConnectedCity Infotainment
Sensors
ScheduledMaintenance
PredictiveMaintenance
RouteOptimization
INSURANCECOMPANIES
GOVERNMENTAGENCIES
INFOTAINMENTPROVIDERS
SOFTWARECOMPANIES
AUTOMAKERS
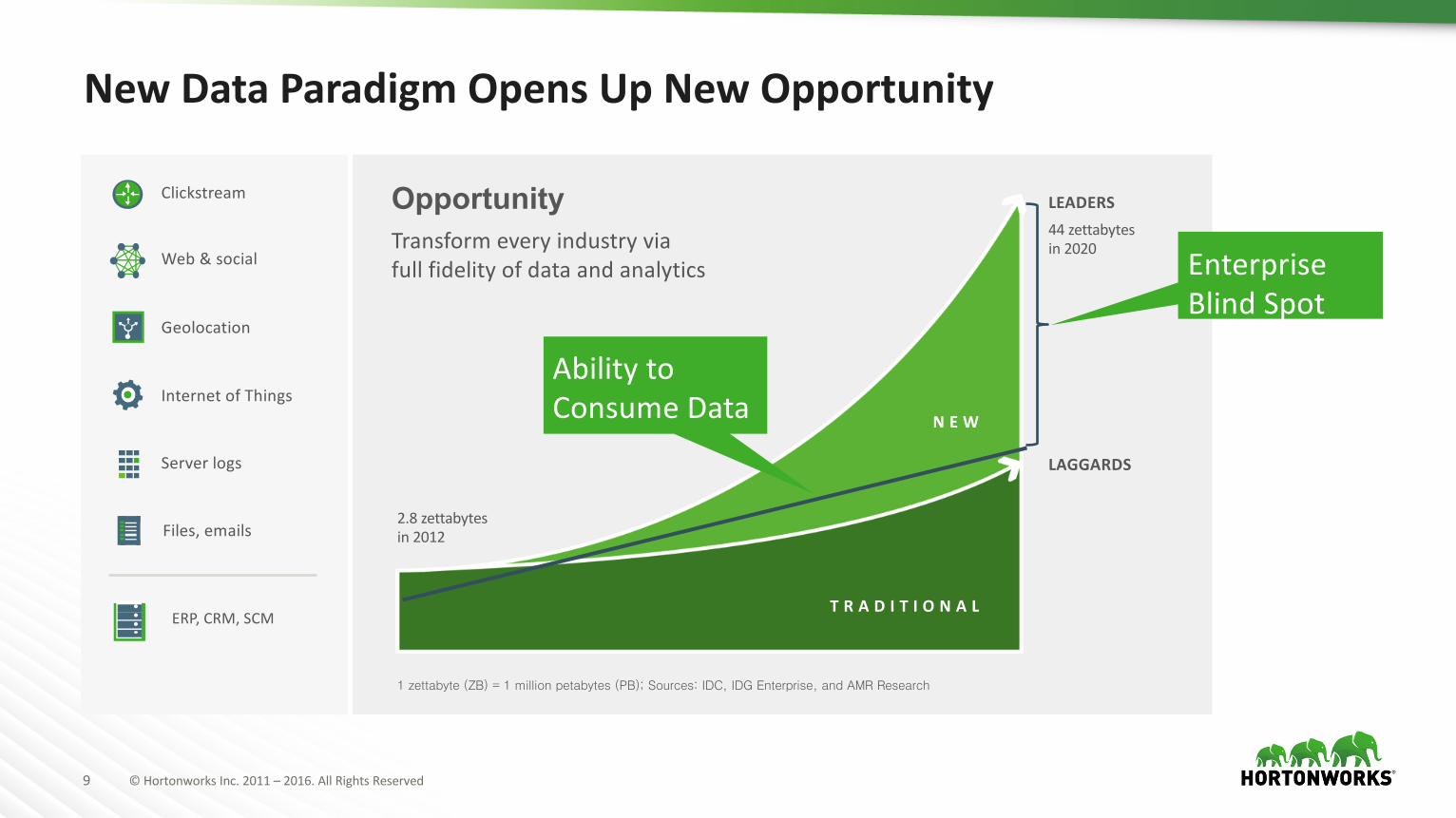
9 ©HortonworksInc.2011– 2016.AllRightsReserved
NewDataParadigmOpensUpNewOpportunity
2.8zettabytesin2012
44zettabytesin2020
N E W
1 zettabyte (ZB) = 1 million petabytes (PB); Sources: IDC, IDG Enterprise, and AMR Research
Clickstream
ERP,CRM,SCM
Web&social
Geolocation
InternetofThings
Serverlogs
Files,emails
Transformeveryindustryviafullfidelityofdataandanalytics
Opportunity
T R A D I T I O N A L
LAGGARDS
LEADERS
AbilitytoConsumeData
EnterpriseBlindSpot

10 ©HortonworksInc.2011– 2016.AllRightsReserved
Whatdisruptedthedatacenter?
?
Data?
11 ©HortonworksInc.2011– 2016.AllRightsReserved
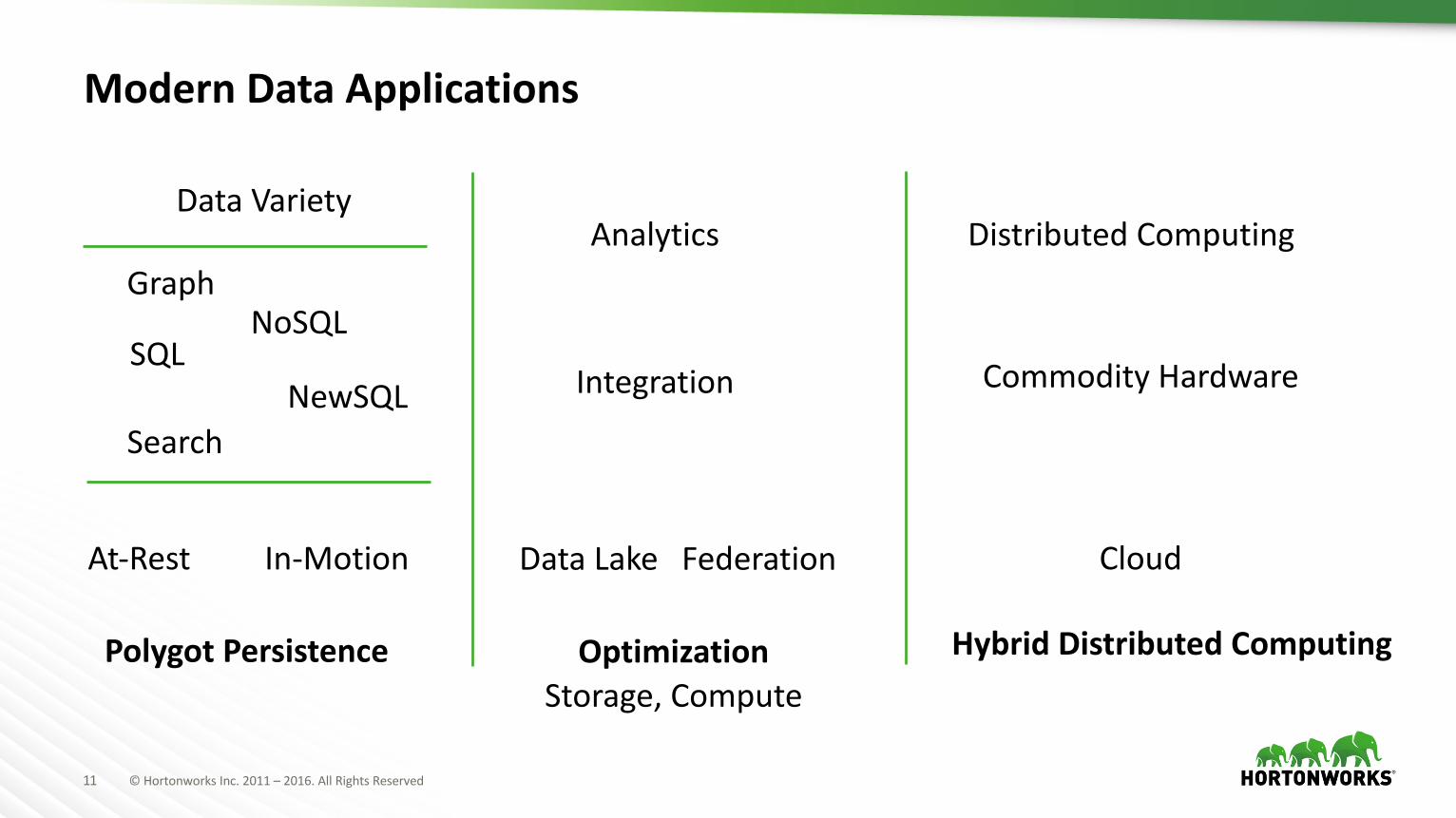
ModernDataApplications
Polygot Persistence
SQLNoSQL
NewSQLSearch
Graph
At-Rest In-Motion
AnalyticsDataVariety
Integration
DataLake Federation
OptimizationStorage,Compute
DistributedComputing
CommodityHardware
Cloud
HybridDistributedComputing

12 ©HortonworksInc.2011– 2016.AllRightsReserved
TraditionalDataArchitectures
13 ©HortonworksInc.2011– 2016.AllRightsReserved
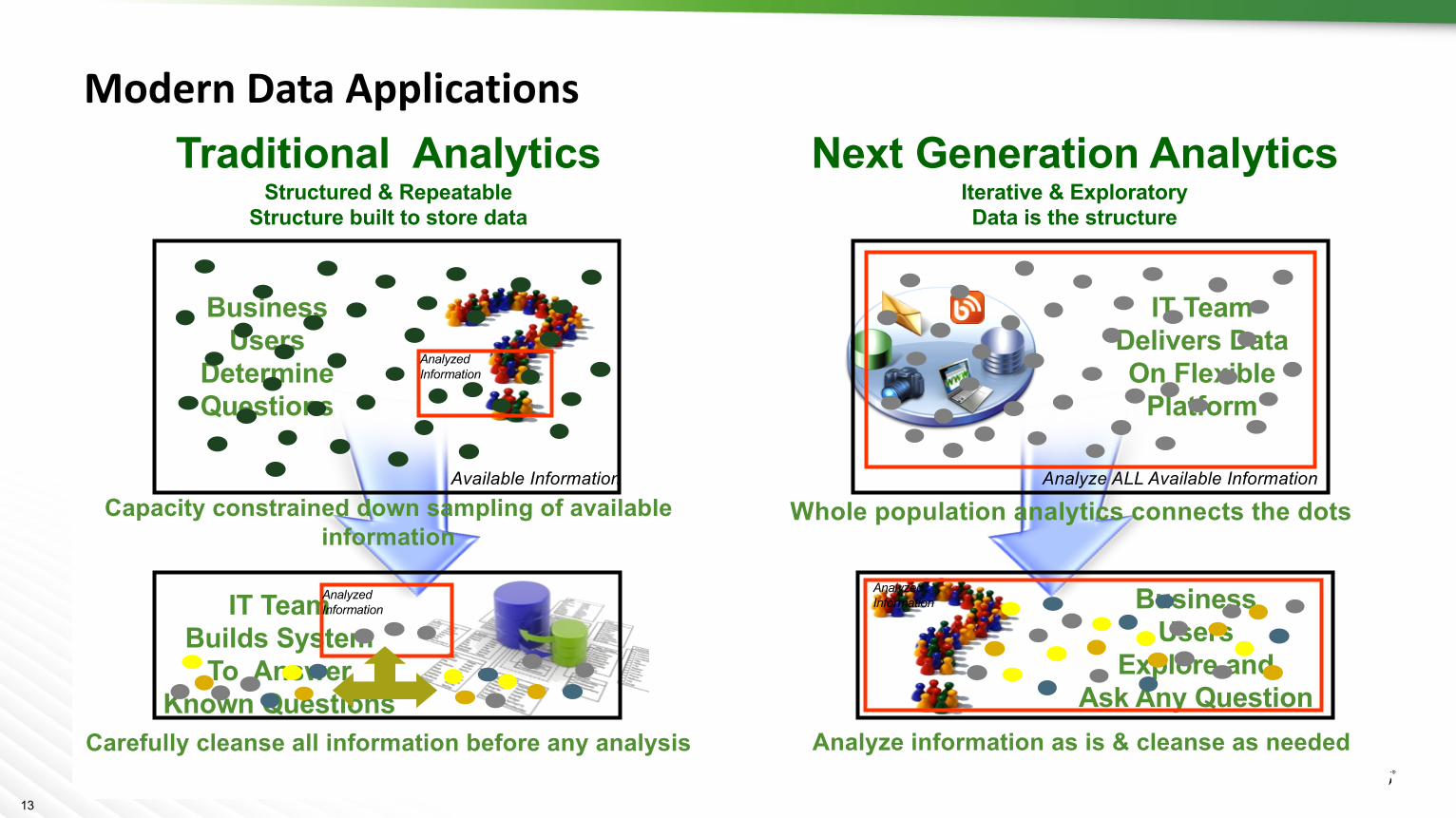
Next Generation AnalyticsIterative & ExploratoryData is the structure
IT TeamDelivers DataOn Flexible
Platform
BusinessUsers
Explore andAsk Any Question
Analyze ALL Available Information
Whole population analytics connects the dots
Traditional AnalyticsStructured & Repeatable
Structure built to store data
BusinessUsers
DetermineQuestions
IT TeamBuilds System
To AnswerKnown Questions
13
Available Information
AnalyzedInformation
Capacity constrained down sampling of available information
Carefully cleanse all information before any analysis
AnalyzedInformation
Analyze information as is & cleanse as needed
AnalyzedInformation
ModernDataApplications
14 ©HortonworksInc.2011– 2016.AllRightsReserved
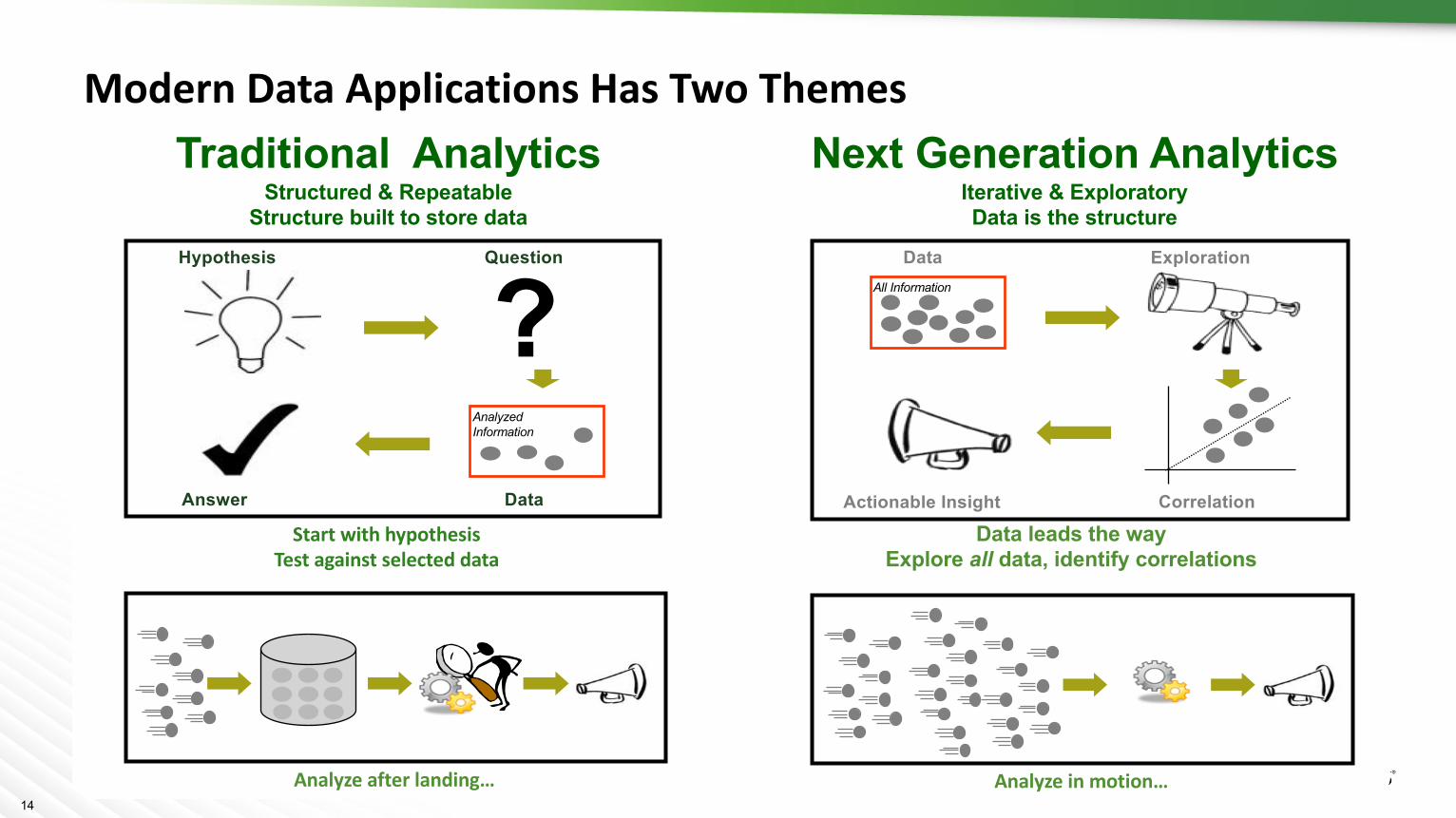
Next Generation AnalyticsIterative & ExploratoryData is the structure
Traditional AnalyticsStructured & Repeatable
Structure built to store data
14
?AnalyzedInformation
Question
DataAnswer
Hypothesis
StartwithhypothesisTestagainstselecteddata
Data leads the way Explore all data, identify correlations
Data
Correlation
All Information
Exploration
Actionable Insight
Analyzeafterlanding… Analyzeinmotion…
ModernDataApplicationsHasTwoThemes
15 ©HortonworksInc.2011– 2016.AllRightsReserved
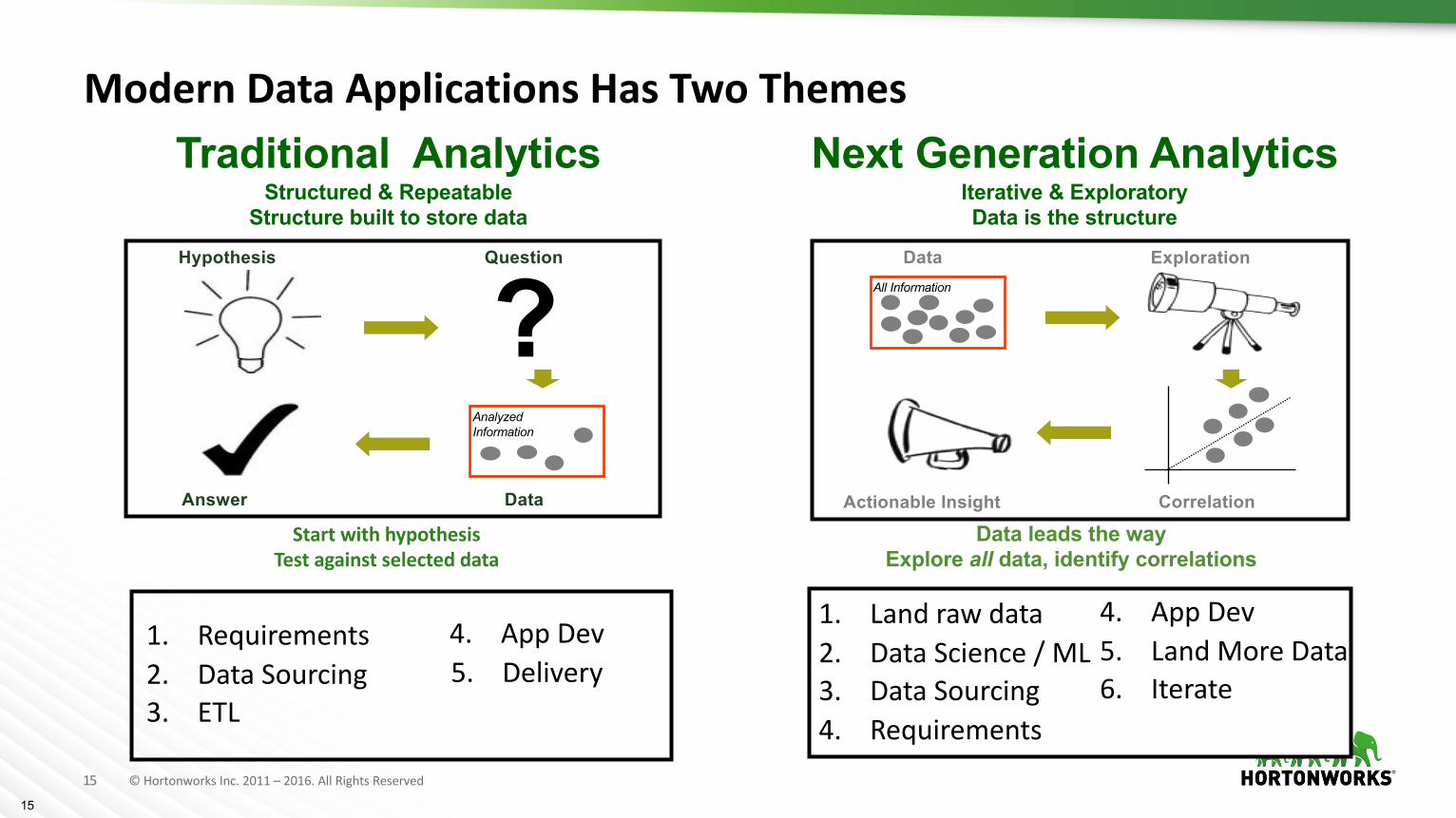
Next Generation AnalyticsIterative & ExploratoryData is the structure
Traditional AnalyticsStructured & Repeatable
Structure built to store data
15
?AnalyzedInformation
Question
DataAnswer
Hypothesis
StartwithhypothesisTestagainstselecteddata
Data leads the way Explore all data, identify correlations
Data
Correlation
All Information
Exploration
Actionable Insight
ModernDataApplicationsHasTwoThemes
4. AppDev5. Delivery
1. Requirements2. DataSourcing3. ETL
4. AppDev5. LandMoreData6. Iterate
1. Landrawdata2. DataScience/ML3. DataSourcing4. Requirements
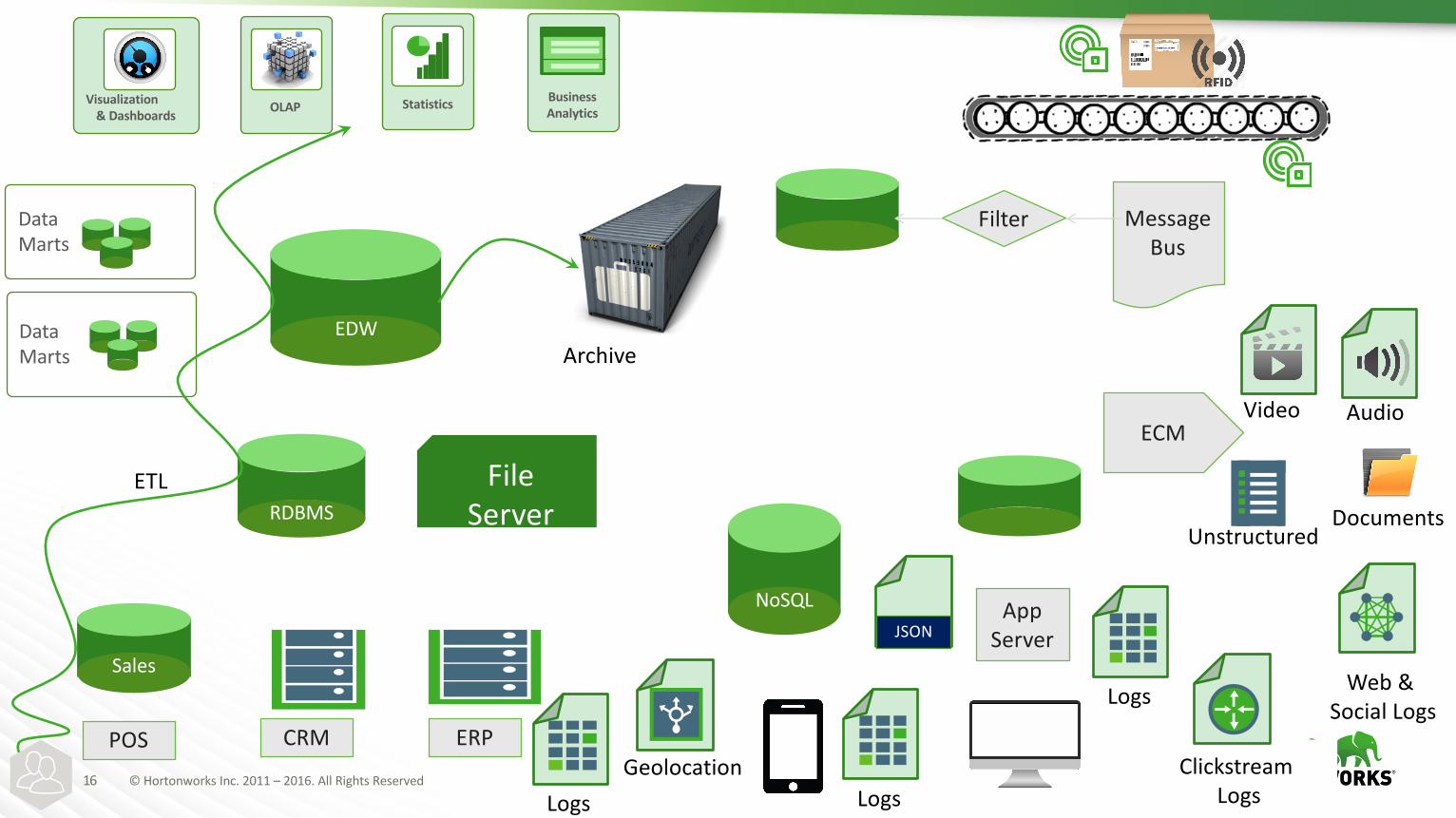
16 ©HortonworksInc.2011– 2016.AllRightsReserved
RDBMS
Sales
NoSQL
Unstructured
Visualization&Dashboards
BusinessAnalytics
DataMarts
DataMarts Archive
StatisticsOLAP
EDW
FileServer
ClickstreamLogs
Web&SocialLogs
AudioVideo
LogsLogs
Logs
Geolocation
JSON
ETL
POS CRM ERP
ECM
Filter
AppServer
MessageBus
Documents

17 ©HortonworksInc.2011– 2016.AllRightsReserved
RDBMS
Sales
NoSQL
Unstructured
Visualization&Dashboards
BusinessAnalytics
DataMarts
DataMarts Archive
StatisticsOLAP
EDW
FileServer
ClickstreamLogs
Web&SocialLogs
AudioVideo
LogsLogs
Logs
Geolocation
JSON
ETL
POS CRM ERP
ECM
Filter
AppServer
MessageBus
Documents
à Tooexpensiveandslowasdatagrowthkeepsaccelerating
à Tooslowtogetthedatapreparedforanalytics
à Analyticsisonlyleveragingalimiteddataset
à Colddatabecomesarchivedandisnolongerusableforanalytics
à DataingestisrigidandslowfornewIoAT datatypes
à Limitedrealtimeinsights
TraditionalDataArchitectureChallengeswithBigData
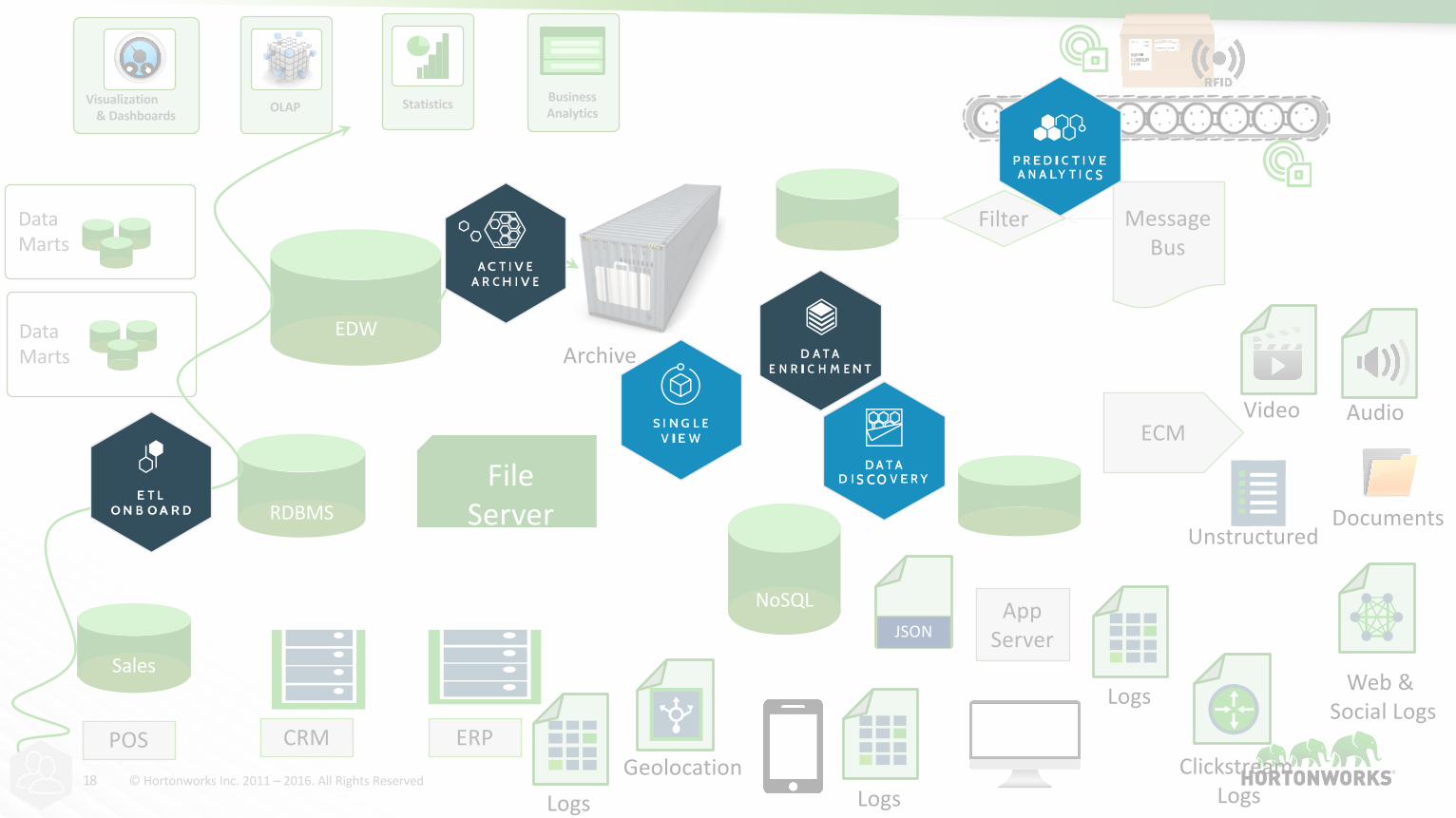
18 ©HortonworksInc.2011– 2016.AllRightsReserved
RDBMS
Sales
NoSQL
Unstructured
Visualization&Dashboards
BusinessAnalytics
DataMarts
DataMarts Archive
StatisticsOLAP
EDW
FileServer
ClickstreamLogs
Web&SocialLogs
AudioVideo
LogsLogs
Logs
Geolocation
JSON
ETL
POS CRM ERP
ECM
Filter
AppServer
MessageBus
Documents

What’sApacheHadoop?
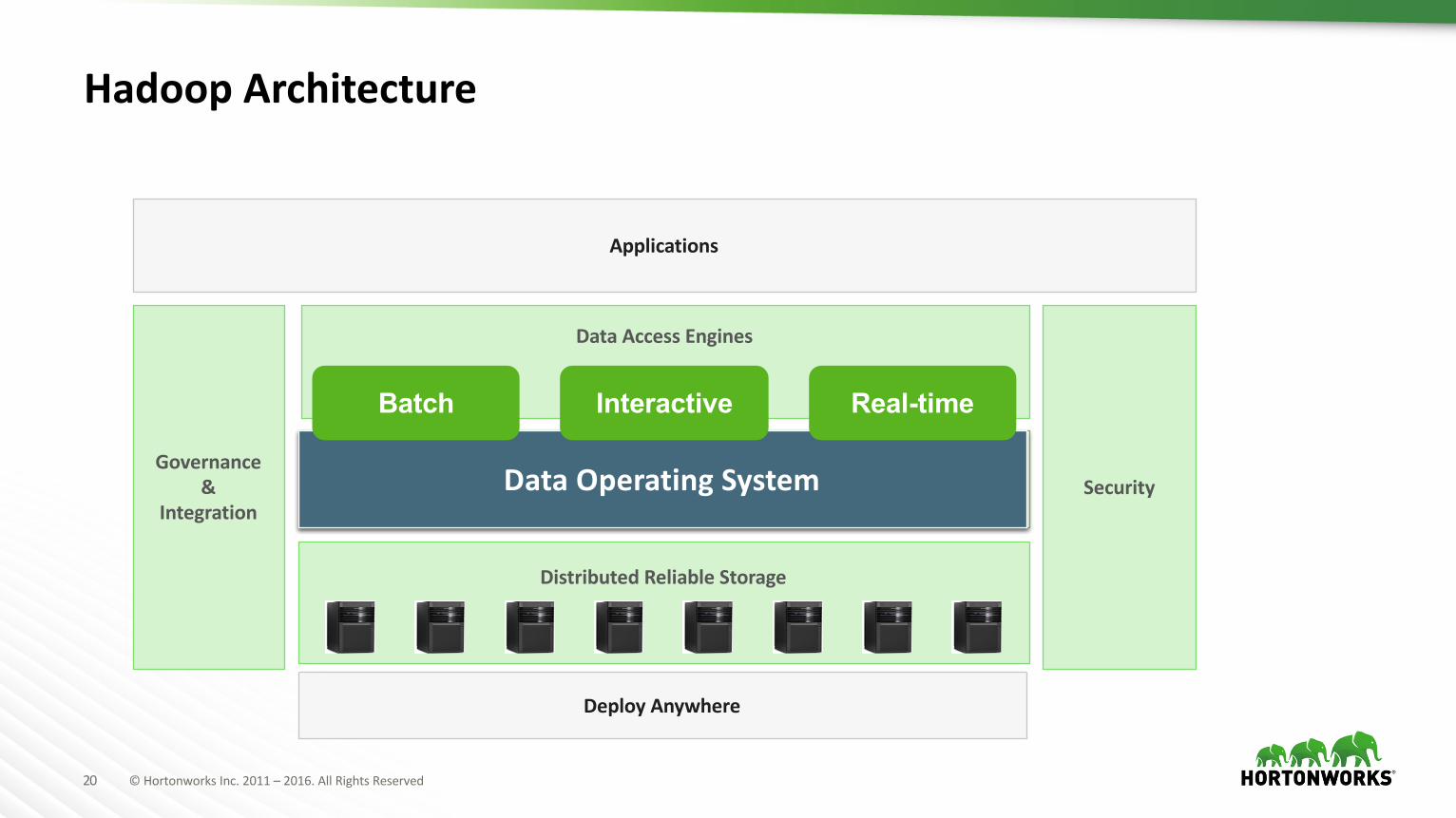
20 ©HortonworksInc.2011– 2016.AllRightsReserved
HadoopArchitecture
DataAccessEngines
DistributedReliableStorage
DistributedComputeFrameworkResourceManagement,DataLocalityDataOperatingSystem
Batch Interactive Real-time
Governance&
IntegrationSecurity
Applications
DeployAnywhere
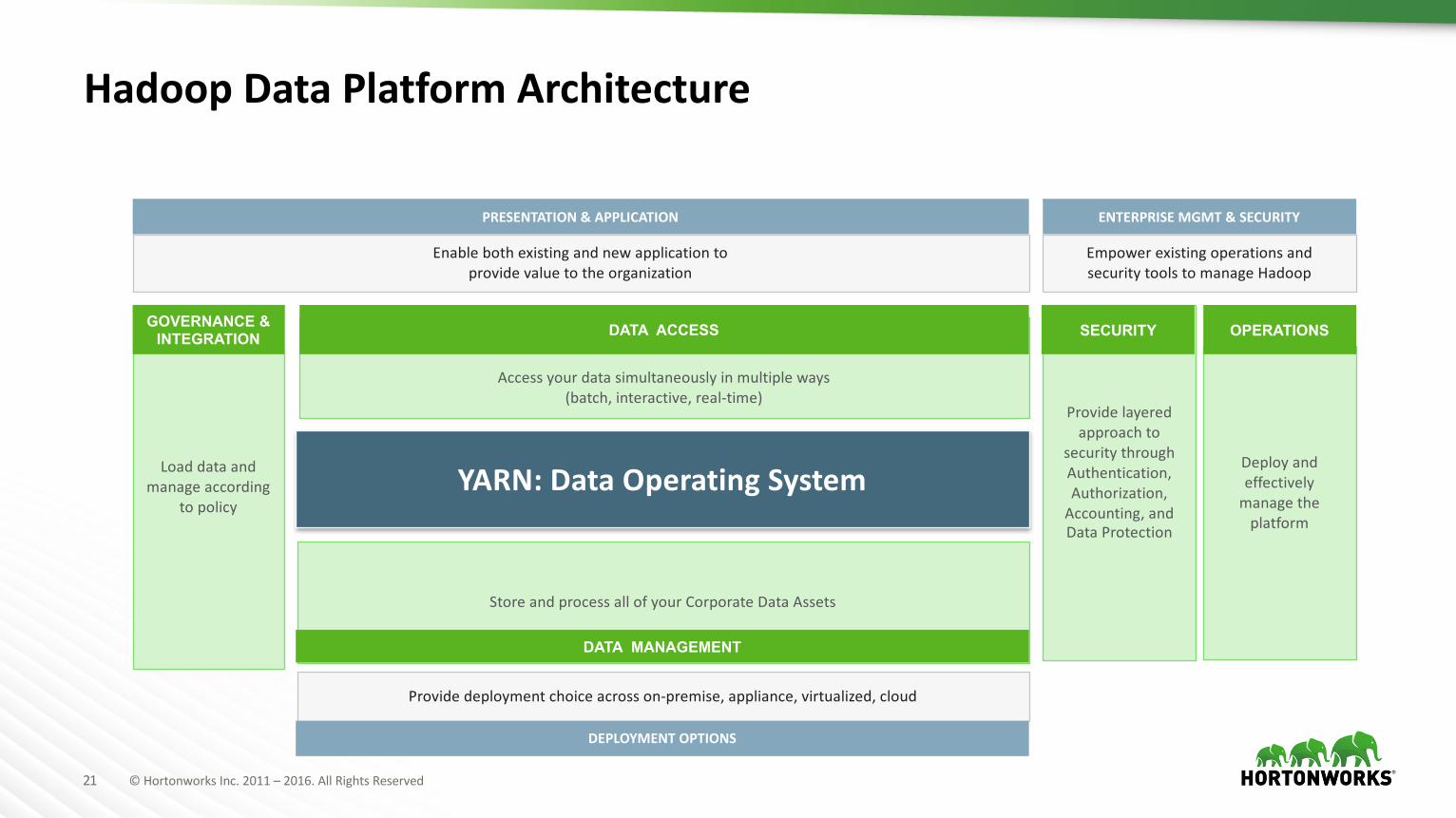
21 ©HortonworksInc.2011– 2016.AllRightsReserved
HadoopDataPlatformArchitecture
StoreandprocessallofyourCorporateDataAssets
YARN:DataOperatingSystem
DATA MANAGEMENT
Providelayeredapproachto
securitythroughAuthentication,Authorization,Accounting,andDataProtection
SECURITY
Accessyourdatasimultaneouslyinmultipleways(batch,interactive,real-time)
DATA ACCESS
Loaddataandmanageaccording
topolicy
GOVERNANCE & INTEGRATION
ENTERPRISEMGMT&SECURITY
EmpowerexistingoperationsandsecuritytoolstomanageHadoop
PRESENTATION&APPLICATION
Enablebothexistingandnewapplicationtoprovidevaluetotheorganization
Providedeploymentchoiceacrosson-premise,appliance,virtualized,cloud
DEPLOYMENTOPTIONS
Deployandeffectivelymanagetheplatform
OPERATIONS
22 ©HortonworksInc.2011– 2016.AllRightsReserved runson
ETL
RDBMSImport/Export
DistributedStorage&ProcessingFramework
SecureNoSQL DB
SQLonHBase
NoSQL DB
WorkflowManagement
SQL
StreamingDataIngestion
ClusterSystemOperations
SecureGateway
DistributedRegistry
ETL
Search&Indexing
EvenFasterDataProcessing
DataManagement
MachineLearning
HadoopEcosystem
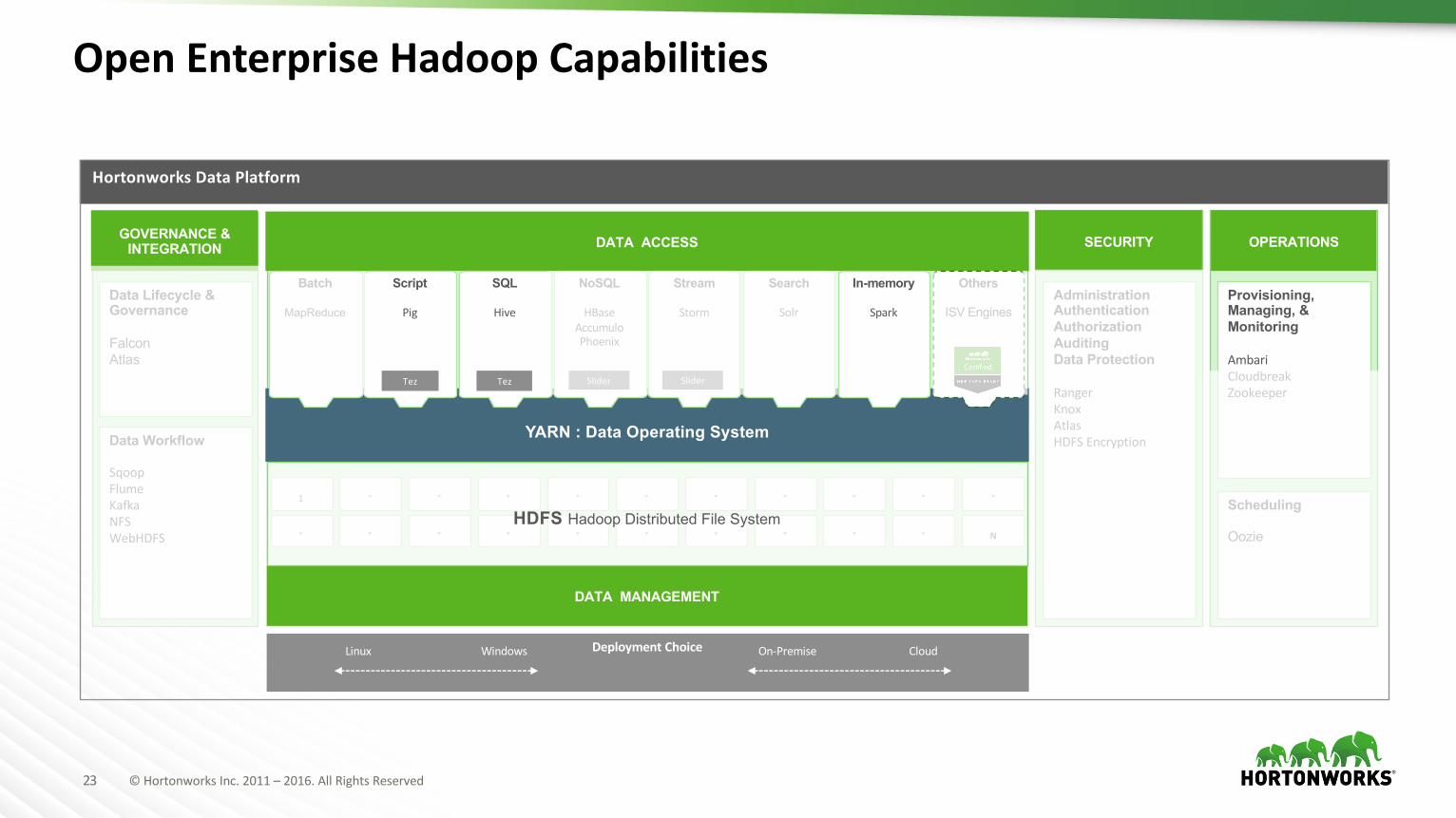
23 ©HortonworksInc.2011– 2016.AllRightsReserved
OpenEnterpriseHadoopCapabilities
YARN : Data Operating System
DATA ACCESS SECURITYGOVERNANCE & INTEGRATION OPERATIONS
1 ° ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° ° °
°
N
Data Lifecycle & Governance
FalconAtlas
AdministrationAuthenticationAuthorizationAuditingData Protection
RangerKnoxAtlasHDFSEncryptionData Workflow
SqoopFlumeKafkaNFSWebHDFS
Provisioning, Managing, & Monitoring
AmbariCloudbreakZookeeper
Scheduling
Oozie
Batch
MapReduce
Script
Pig
Search
Solr
SQL
Hive
NoSQL
HBaseAccumuloPhoenix
Stream
Storm
In-memory
Spark
Others
ISV Engines
Tez Tez Slider Slider
DATA MANAGEMENT
HortonworksDataPlatform
DeploymentChoiceLinux Windows On-Premise Cloud
HDFS Hadoop Distributed File System
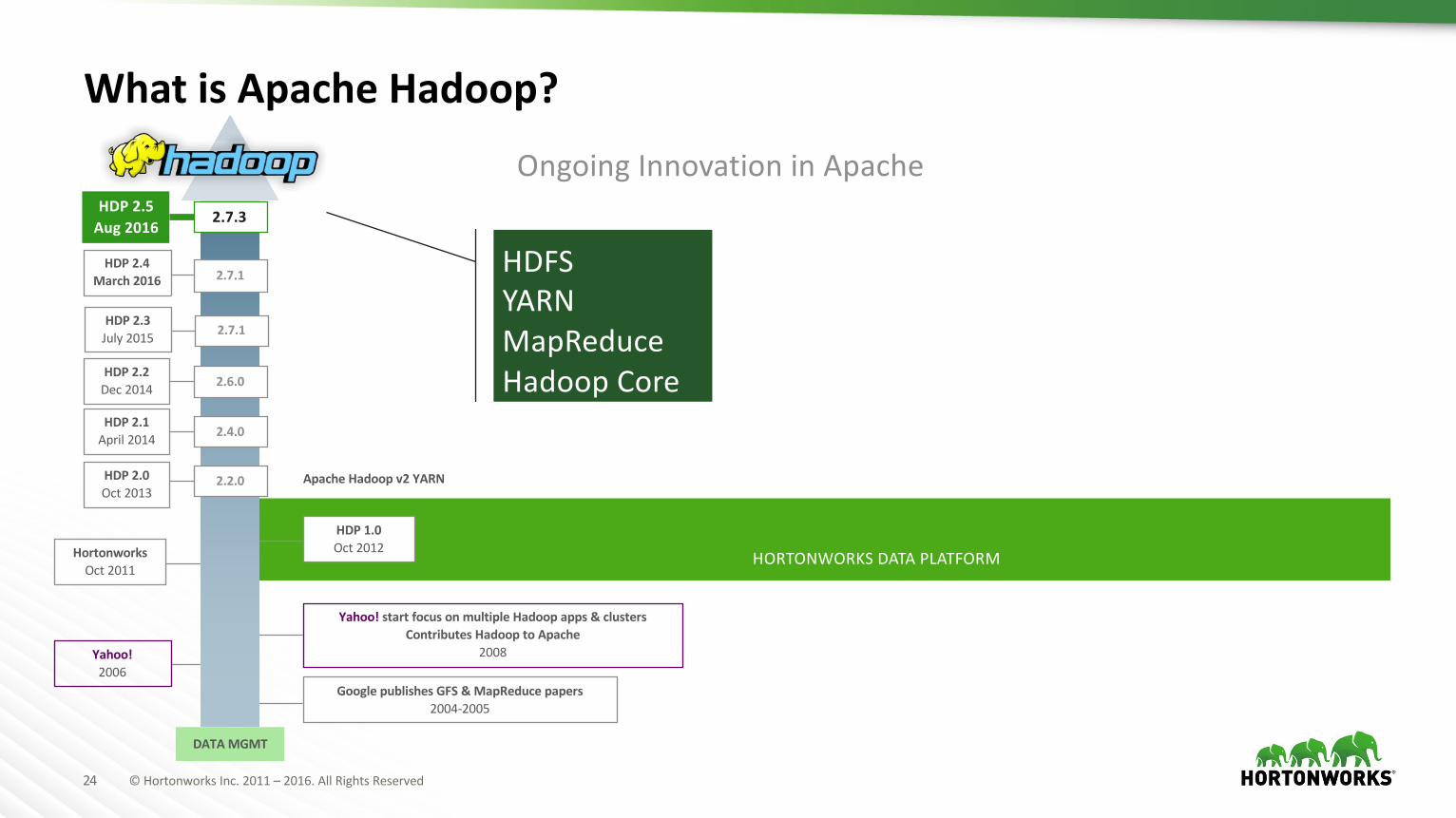
24 ©HortonworksInc.2011– 2016.AllRightsReserved
HORTONWORKSDATAPLATFORM
DATAMGMT
HDP2.2Dec2014
HDP2.1April2014
HDP2.0Oct2013
HDP2.2Dec2014
HDP2.1April2014
HDP2.0Oct2013
2.2.0
2.4.0
2.6.0
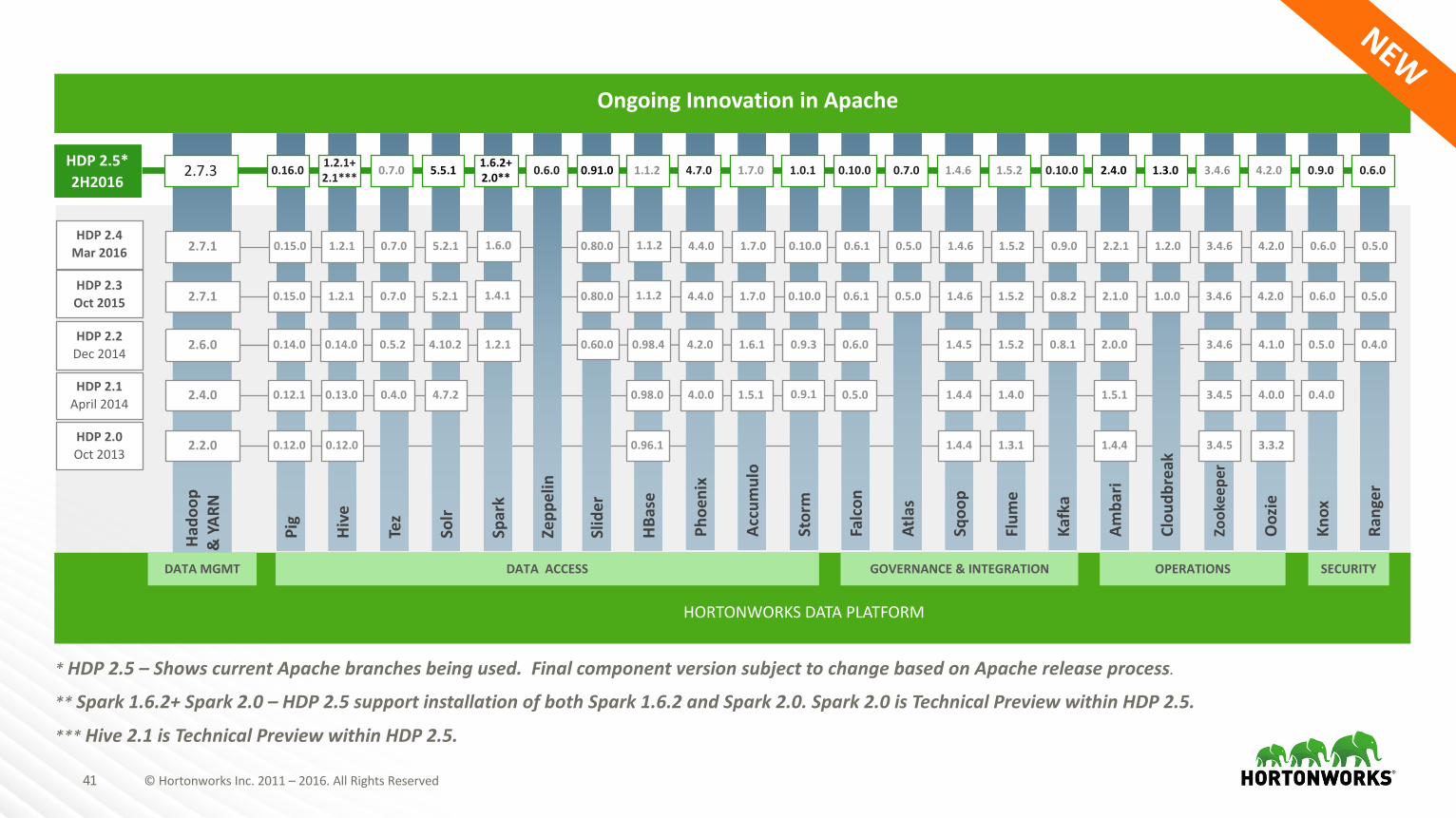
OngoingInnovationinApache
HDFSYARNMapReduceHadoopCore
WhatisApacheHadoop?
Yahoo!2006
HortonworksOct2011
Yahoo!startfocusonmultipleHadoopapps&clustersContributesHadooptoApache
2008
HDP1.0Oct2012
ApacheHadoopv2YARN
GooglepublishesGFS&MapReduce papers2004-2005
HDP2.4March2016 2.7.1
HDP2.2Dec2014HDP2.3July2015 2.7.1
HDP 2.5Aug2016
2.7.3
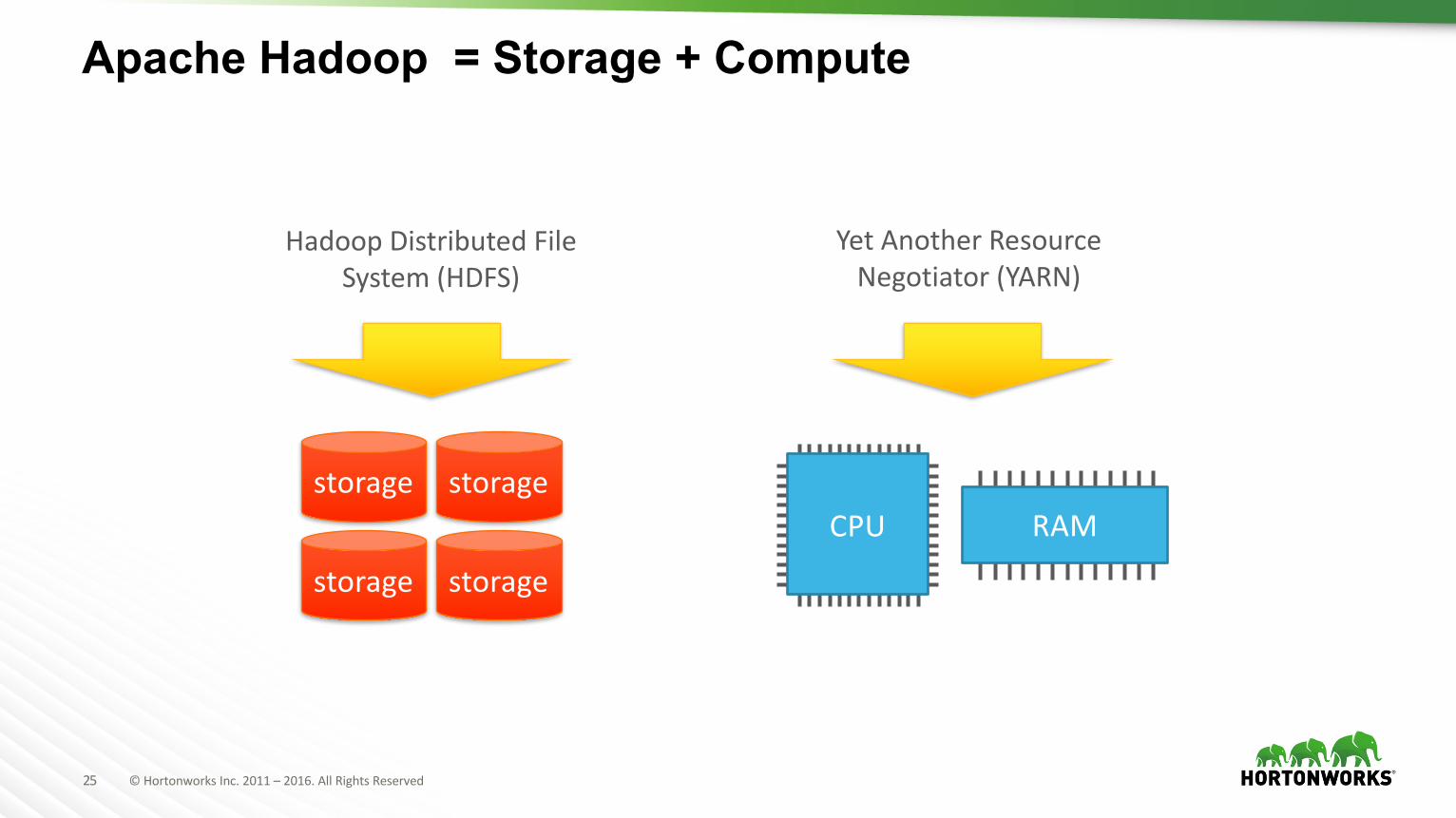
25 ©HortonworksInc.2011– 2016.AllRightsReserved
Apache Hadoop = Storage + Compute
storage storage
storage storage
HadoopDistributedFileSystem(HDFS)
CPU RAM
YetAnotherResourceNegotiator(YARN)
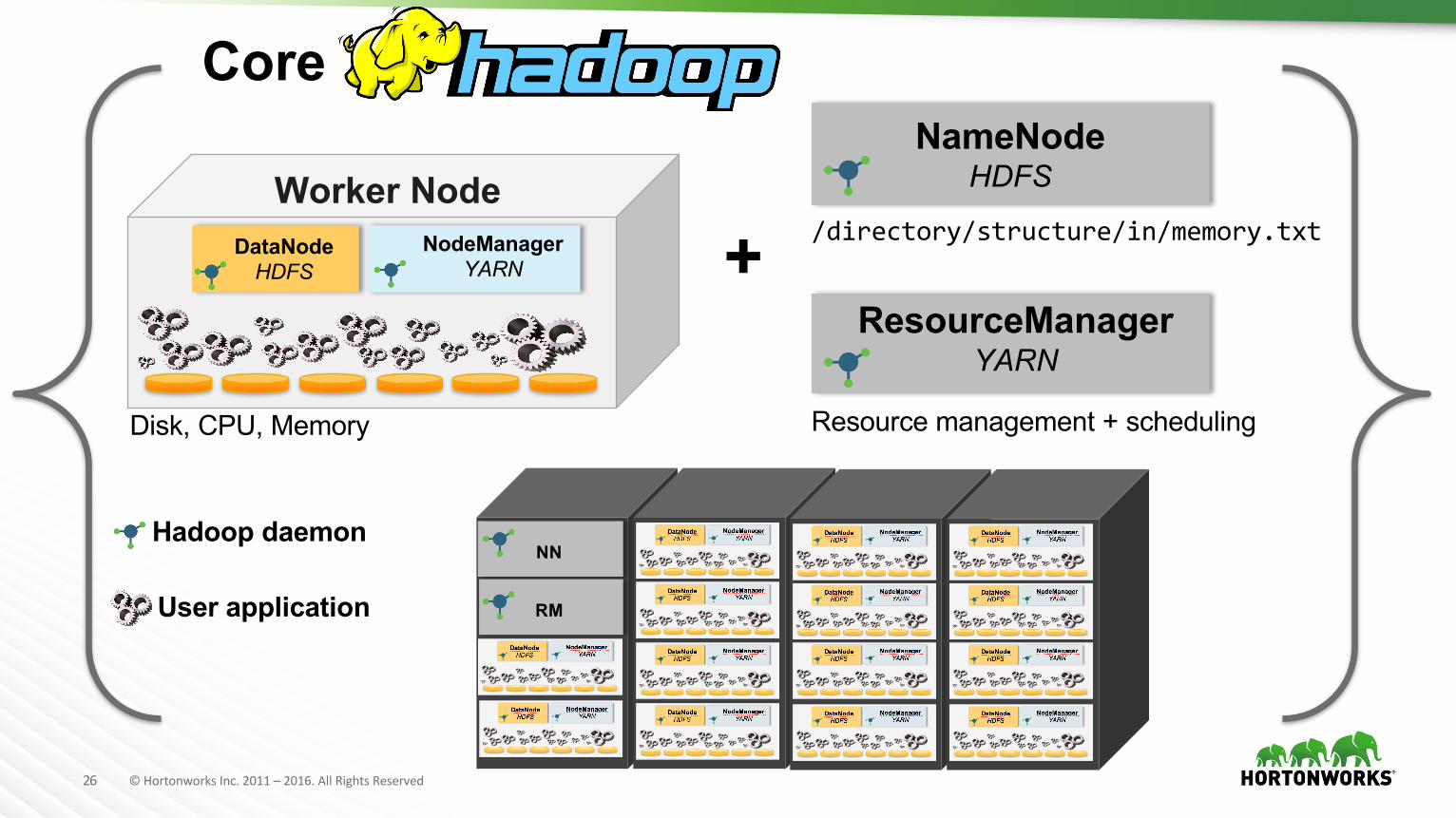
26 ©HortonworksInc.2011– 2016.AllRightsReserved
`
+ /directory/structure/in/memory.txt
Resource management + schedulingDisk, CPU, Memory
CoreNameNode
HDFS
ResourceManagerYARN
Hadoop daemon
User application
NN
RM
DataNodeHDFS
NodeManagerYARN
Worker Node
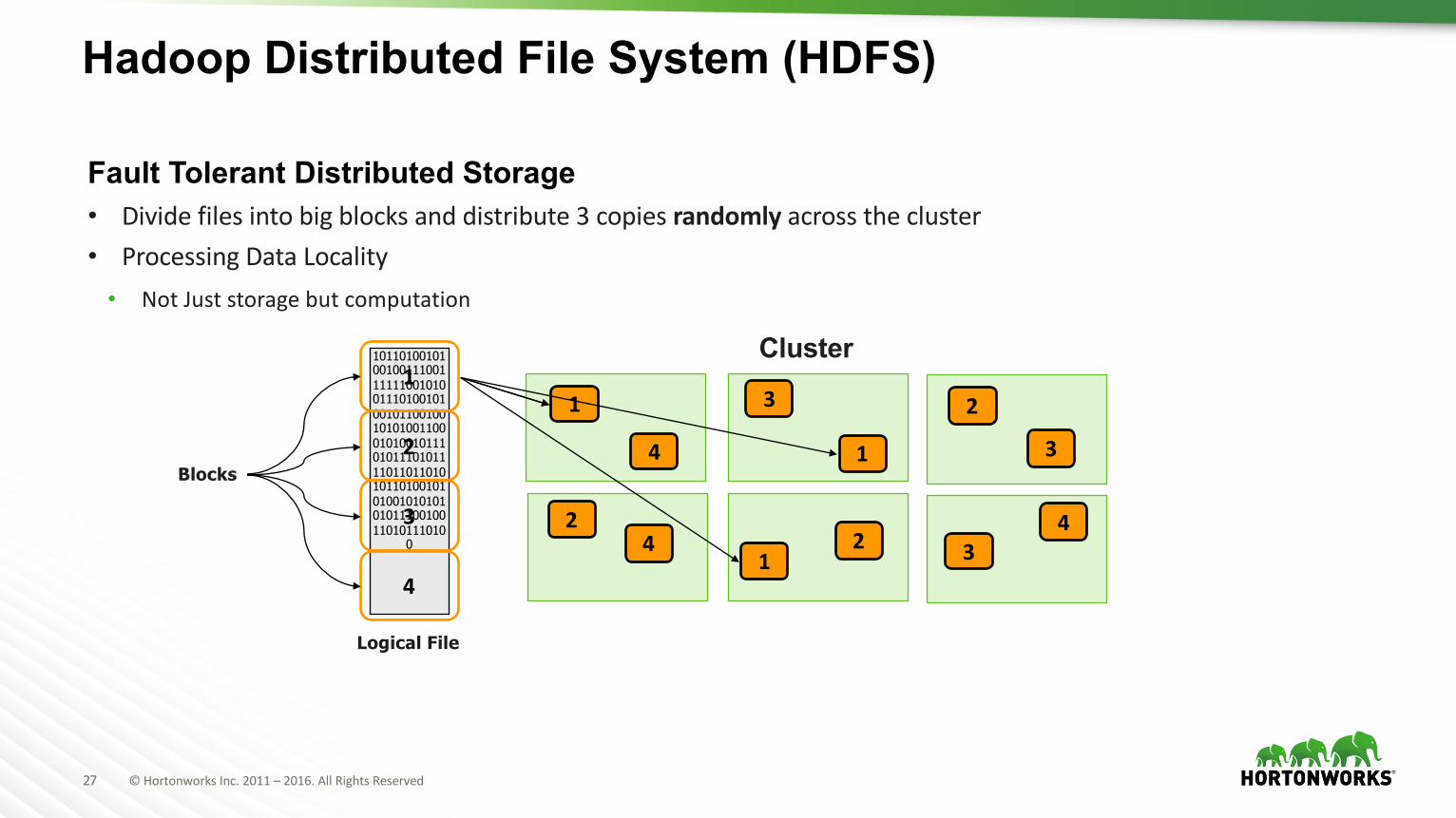
27 ©HortonworksInc.2011– 2016.AllRightsReserved
Hadoop Distributed File System (HDFS)
Fault Tolerant Distributed Storage• Dividefilesintobigblocksanddistribute3copiesrandomly acrossthecluster• ProcessingDataLocality
• NotJuststoragebutcomputation
10110100101001001110011111100101001110100101001011001001010100110001010010111010111010111101101101010110100101010010101010101110010011010111010
0
Logical File
1
2
3
4
Blocks
1
Cluster
1
1
2
22
3
3
34
44
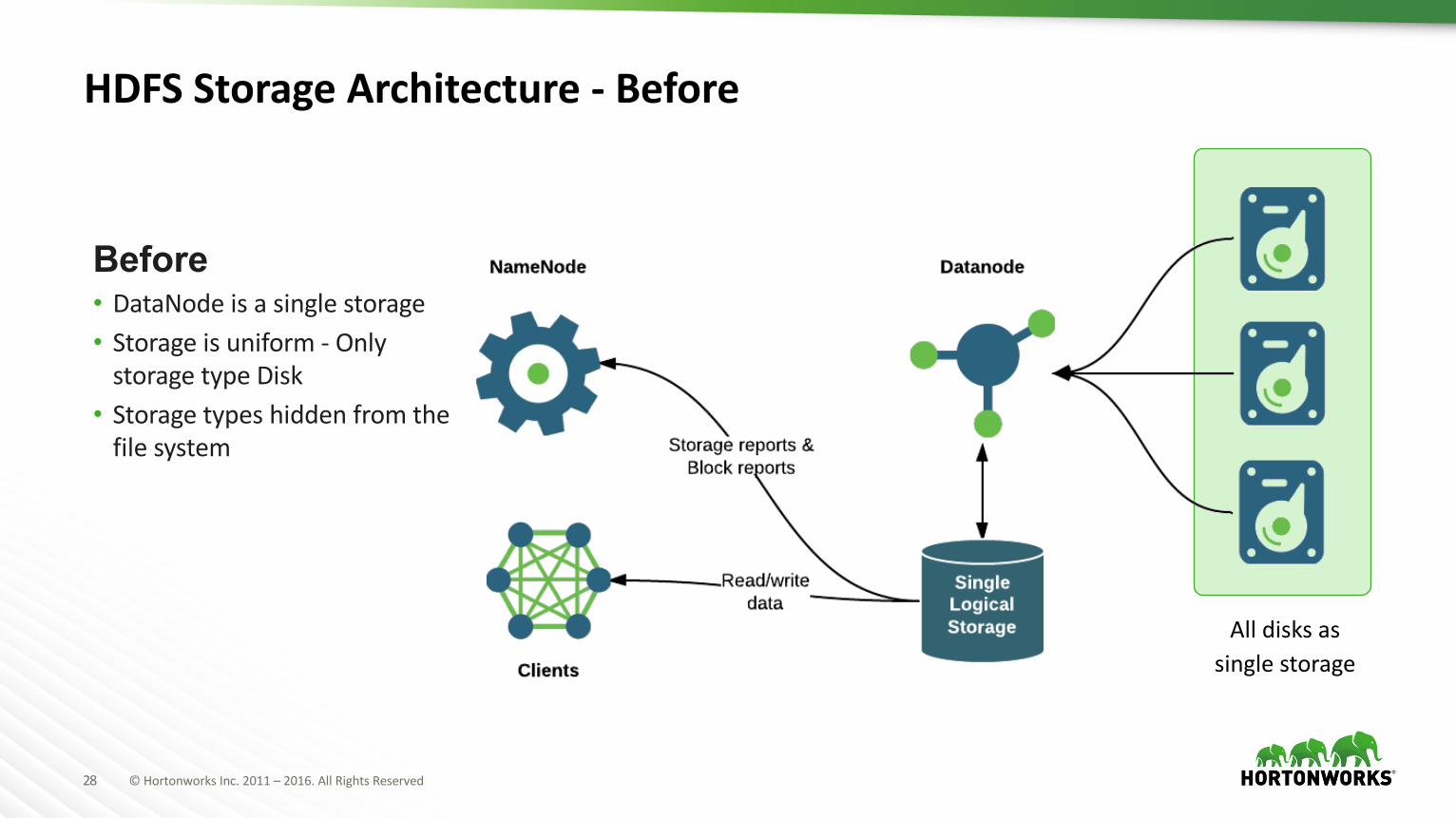
28 ©HortonworksInc.2011– 2016.AllRightsReserved
HDFSStorageArchitecture- Before
Before• DataNode isasinglestorage• Storageisuniform- OnlystoragetypeDisk
• Storagetypeshiddenfromthefilesystem
Alldisksassinglestorage
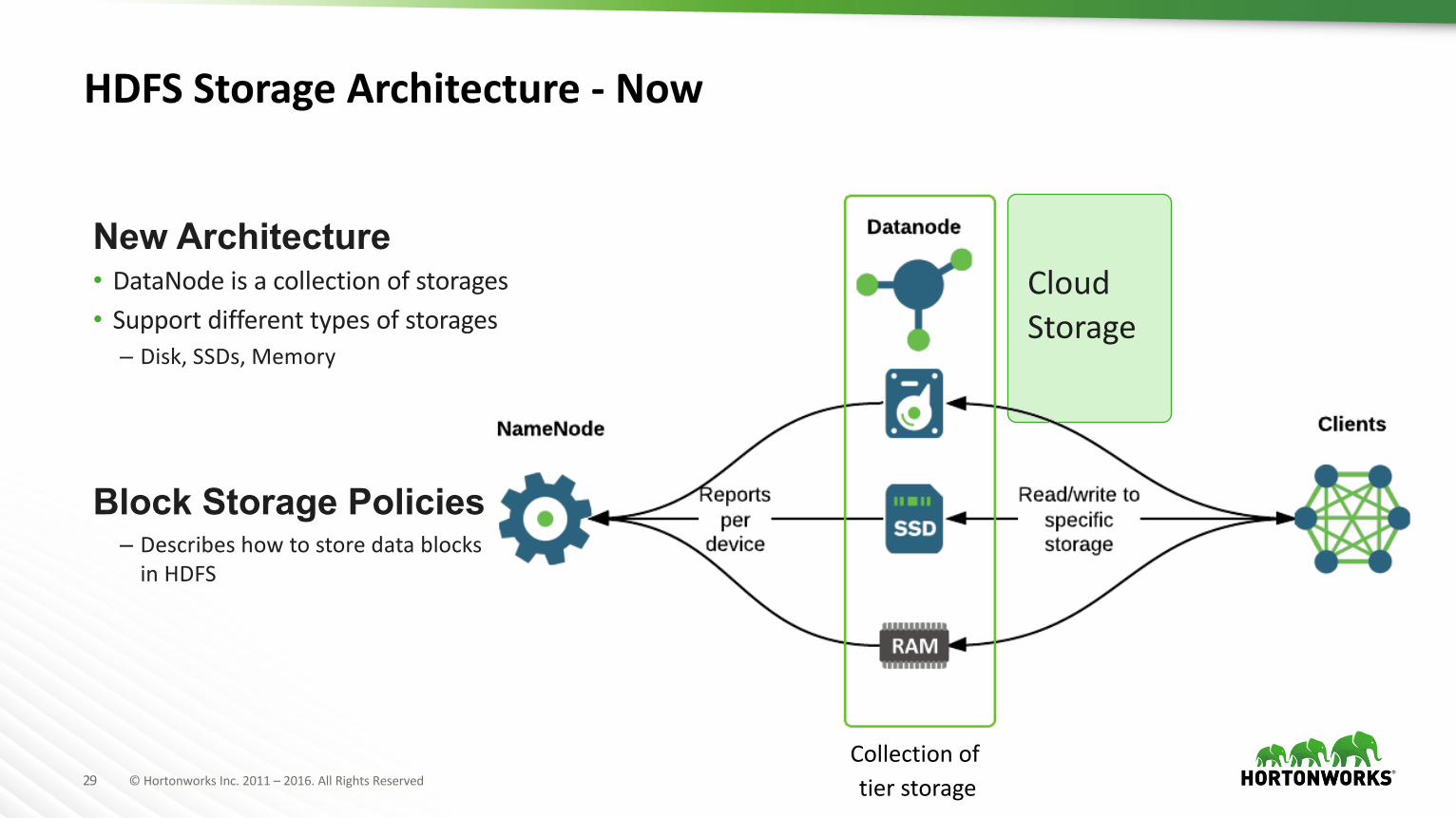
29 ©HortonworksInc.2011– 2016.AllRightsReserved
CloudStorage
HDFSStorageArchitecture- Now
New Architecture• DataNode isacollectionofstorages• Supportdifferenttypesofstorages
– Disk,SSDs,Memory
Block Storage Policies– DescribeshowtostoredatablocksinHDFS
Collectionoftierstorage
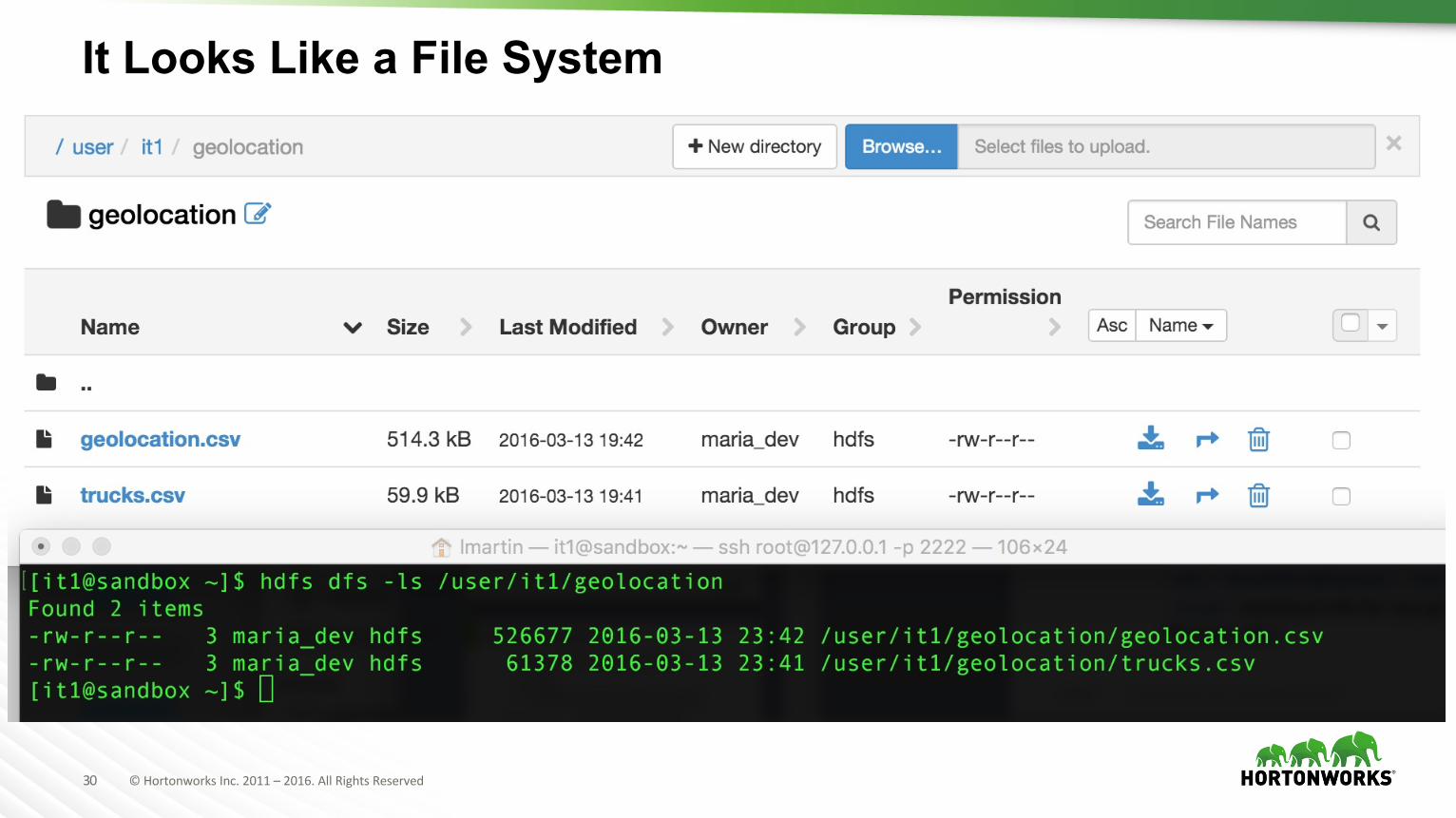
30 ©HortonworksInc.2011– 2016.AllRightsReserved
It Looks Like a File System
31 ©HortonworksInc.2011– 2016.AllRightsReserved
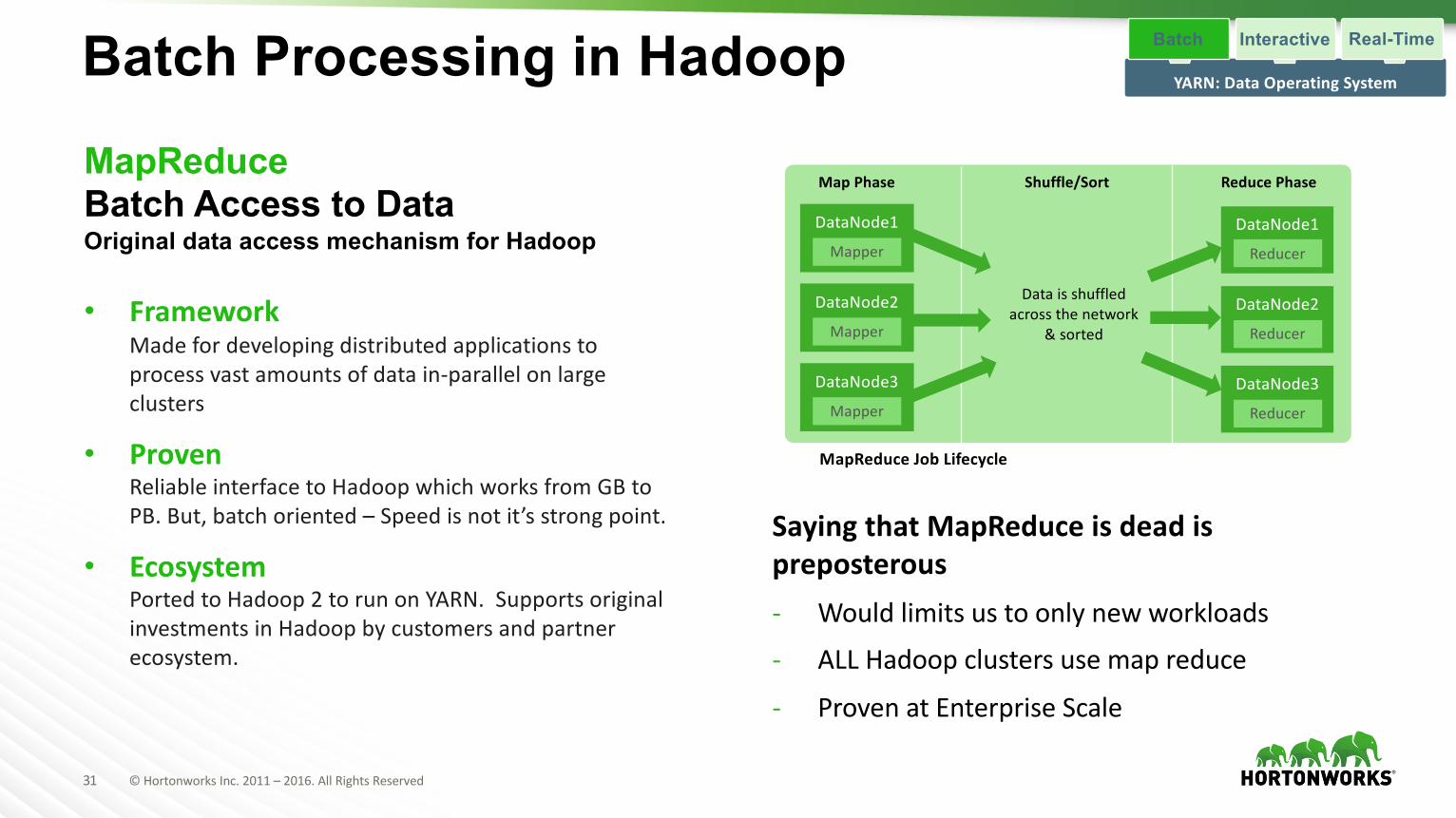
Batch Processing in HadoopMapReduceBatch Access to DataOriginal data access mechanism for Hadoop
• FrameworkMadefordevelopingdistributedapplicationstoprocessvastamountsofdatain-parallelonlargeclusters
• ProvenReliableinterfacetoHadoopwhichworksfromGBtoPB.But,batchoriented– Speedisnotit’sstrongpoint.
• EcosystemPortedtoHadoop2torunonYARN.SupportsoriginalinvestmentsinHadoopbycustomersandpartnerecosystem.
DataNode1
Mapper
Dataisshuffledacrossthenetwork
&sorted
MapPhase Shuffle/Sort ReducePhase
MapReduce JobLifecycle
SayingthatMapReduceisdeadispreposterous- Wouldlimitsustoonlynewworkloads- ALLHadoop clustersusemapreduce
- ProvenatEnterpriseScale
DataNode2
Mapper
DataNode3
Mapper
DataNode1
Reducer
DataNode2
Reducer
DataNode3
Reducer
YARN:DataOperatingSystem
Interactive Real-TimeBatch
32 ©HortonworksInc.2011– 2016.AllRightsReserved
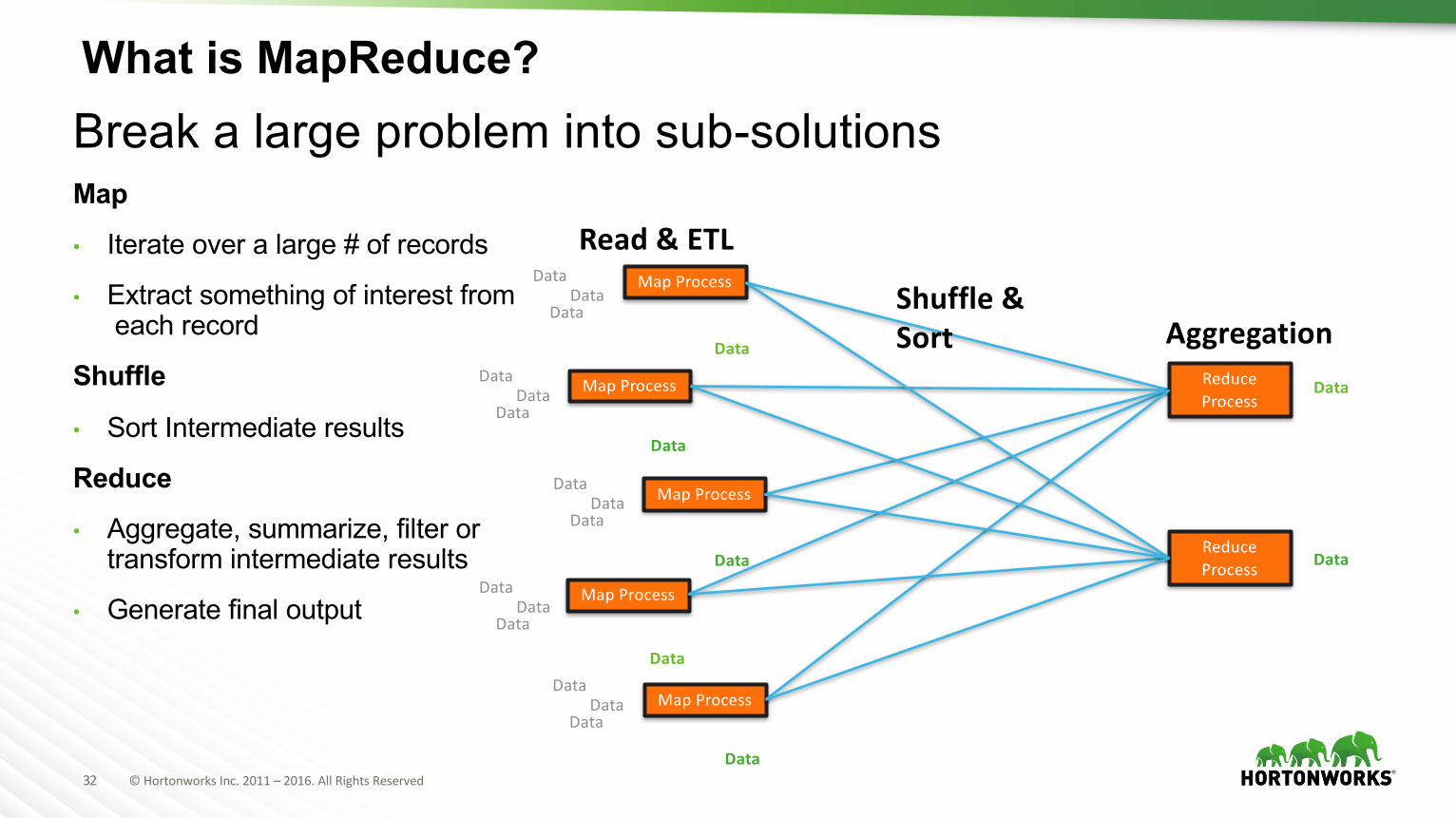
What is MapReduce?Break a large problem into sub-solutionsMap
• Iterate over a large # of records
• Extract something of interest fromeach record
Shuffle
• Sort Intermediate results
Reduce
• Aggregate, summarize, filter or transform intermediate results
• Generate final output
MapProcess
MapProcess
MapProcess
MapProcess
Data
DataData
Data
DataData
DataData
DataData
Data
DataData MapProcess
ReduceProcess
ReduceProcess
Data
Read&ETL
Shuffle&Sort Aggregation
Data
DataData
Data
Data
Data
Data
Data
33 ©HortonworksInc.2011– 2016.AllRightsReserved
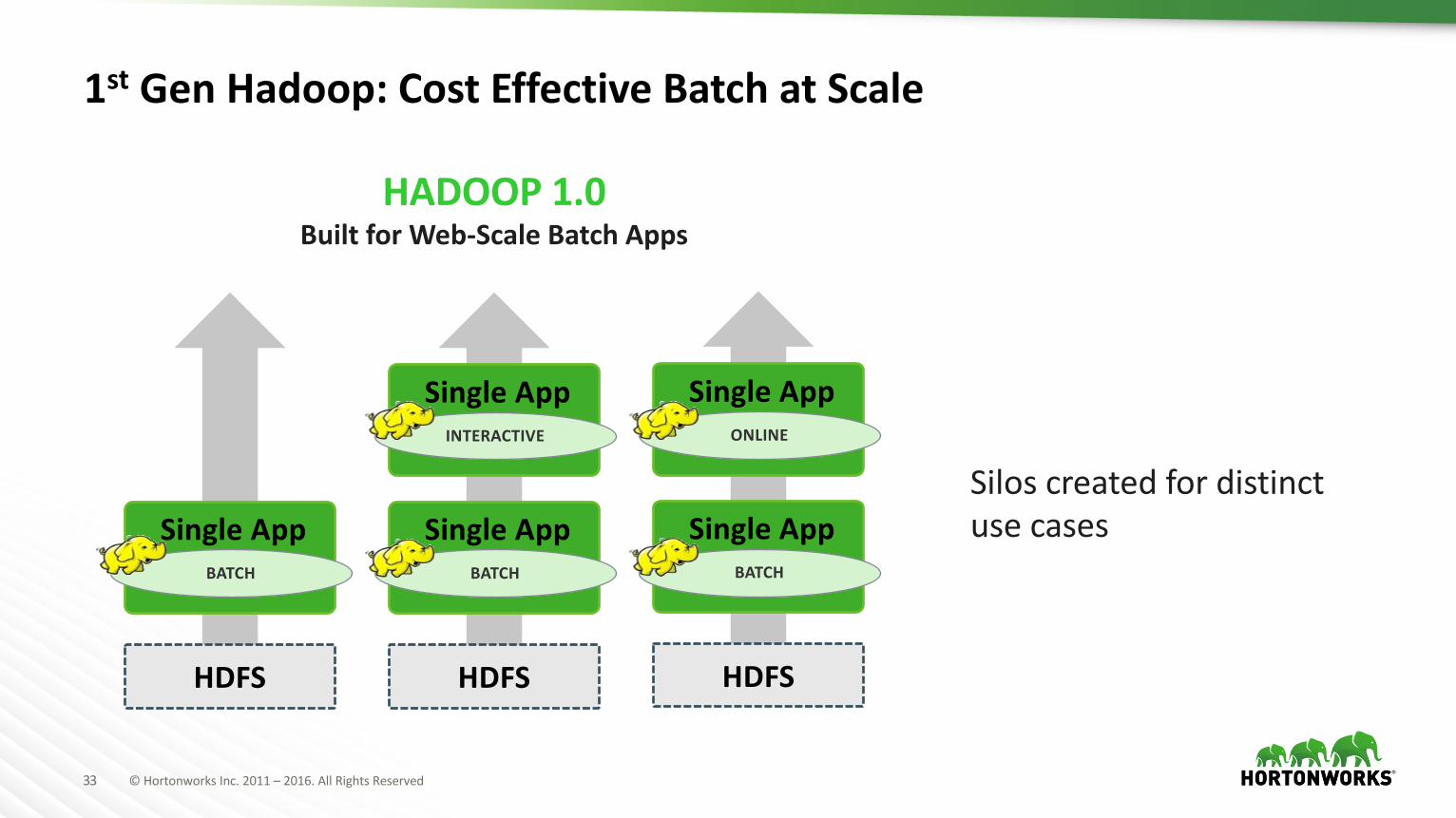
1st GenHadoop:CostEffectiveBatchatScale
HADOOP1.0BuiltforWeb-ScaleBatchApps
SingleAppBATCH
HDFS
SingleAppINTERACTIVE
SingleAppBATCH
HDFS
SiloscreatedfordistinctusecasesSingleApp
BATCH
HDFS
SingleAppONLINE

34 ©HortonworksInc.2011– 2016.AllRightsReserved
HadoopemergedasfoundationofnewdataarchitectureApacheHadoopisanopensourcedataplatformformanaginglargevolumesofhighvelocityandvarietyofdata
• BuiltbyYahoo!tobetheheartbeatofitsad&searchbusiness
• DonatedtoApacheSoftwareFoundationin2005withrapidadoptionbylargewebproperties&earlyadopterenterprises
• Incrediblydisruptivetocurrentplatformeconomics
TraditionalHadoopAdvantages
ü Managesnewdataparadigmü Handlesdataatscaleü Costeffectiveü Opensource
TraditionalHadoopHadLimitations
Batch-onlyarchitectureSinglepurposeclusters,specificdatasetsDifficulttointegratewithexistinginvestmentsNotenterprise-grade
Application
StorageHDFS
Batch ProcessingMapReduce

35 ©HortonworksInc.2011– 2016.AllRightsReserved
YARNextendsHadoopintodatacenterleaders
YARNThe Architectural Center of Hadoop
• Common data platform, many applications
• Support multi-tenant access & processing
• Batch, interactive & real-time use cases
• Supports 3rd-party ISV tools
(ex. SAS, Syncsort, Actian, etc.)
YARN Ready Applications Facilitates ongoing innovation and enterprise adoption via ecosystem of new and existing “YARN Ready” solutions
YARN : Data Operating System
BATCH, INTERACTIVE & REAL-TIME DATA ACCESS
1 ° ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° ° °
°
N
HDFS Hadoop Distributed File System
DATA MANAGEMENT
Batch
MapReduce
Script
Pig
Search
Solr
SQL
Hive
NoSQL
HBaseAccumuloPhoenix
Stream
Storm
In-memory
Spark
Others
ISV Engines
Tez Tez Slider Slider

36 ©HortonworksInc.2011– 2016.AllRightsReserved
WhatdoesiOS 6andWindows3.1haveincommon?
37 ©HortonworksInc.2011– 2016.AllRightsReserved
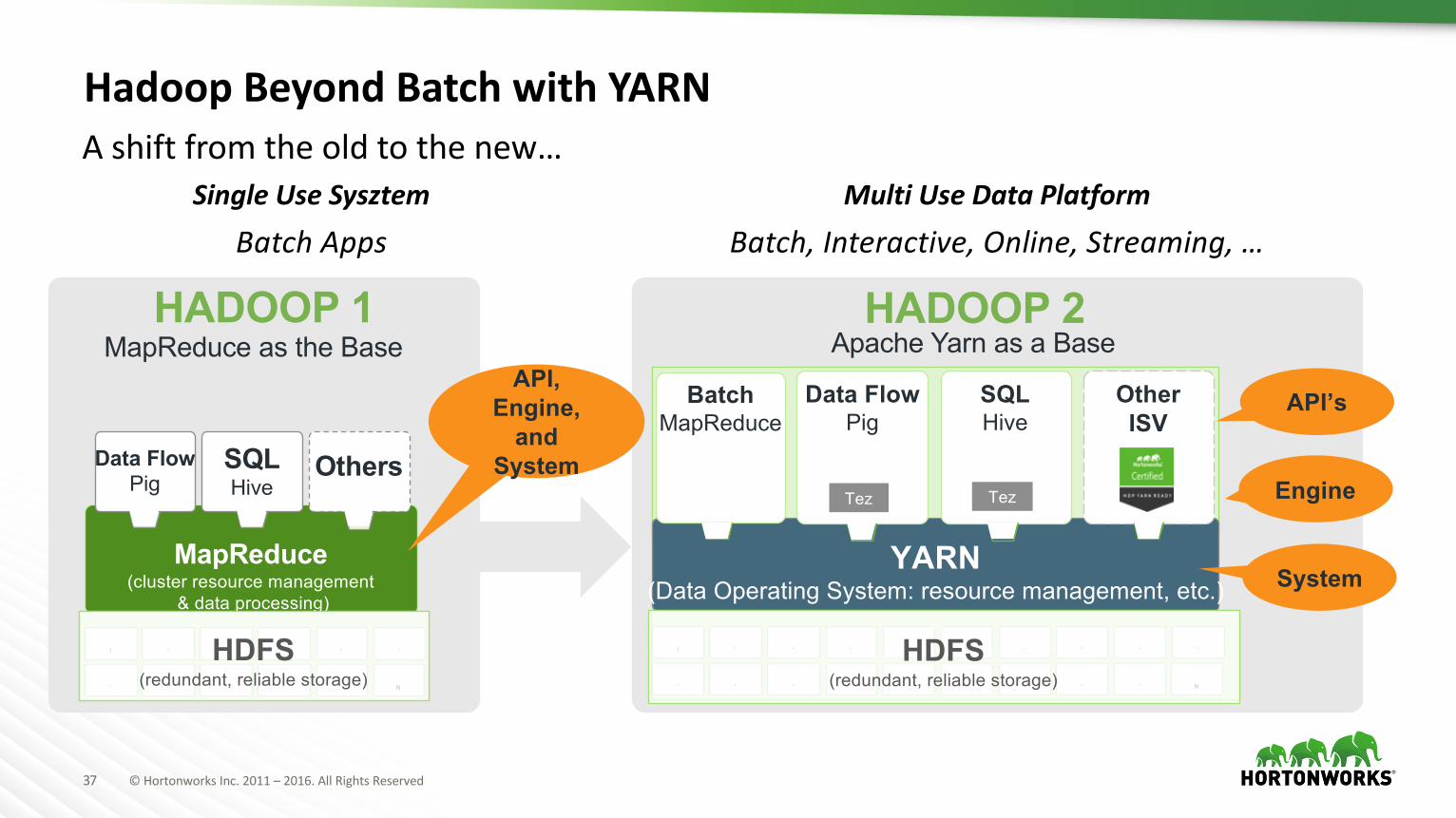
HadoopBeyondBatchwithYARN
SingleUseSysztemBatchApps
MultiUseDataPlatformBatch,Interactive,Online,Streaming,…
Ashiftfromtheoldtothenew…
HADOOP 1
MapReduce(cluster resource management
& data processing)
Data FlowPig
SQLHive
Others
API,Engine,
andSystem
YARN(Data Operating System: resource management, etc.)
Data FlowPig
SQLHive
OtherISV
Apache Yarn as a Base
System
Engine
API’s
1 ° ° ° ° °
° ° ° ° ° N
HDFS (redundant, reliable storage)
1 ° ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° ° N
HDFS (redundant, reliable storage)
BatchMapReduce
Tez Tez
MapReduce as the BaseHADOOP 2
38 ©HortonworksInc.2011– 2016.AllRightsReserved
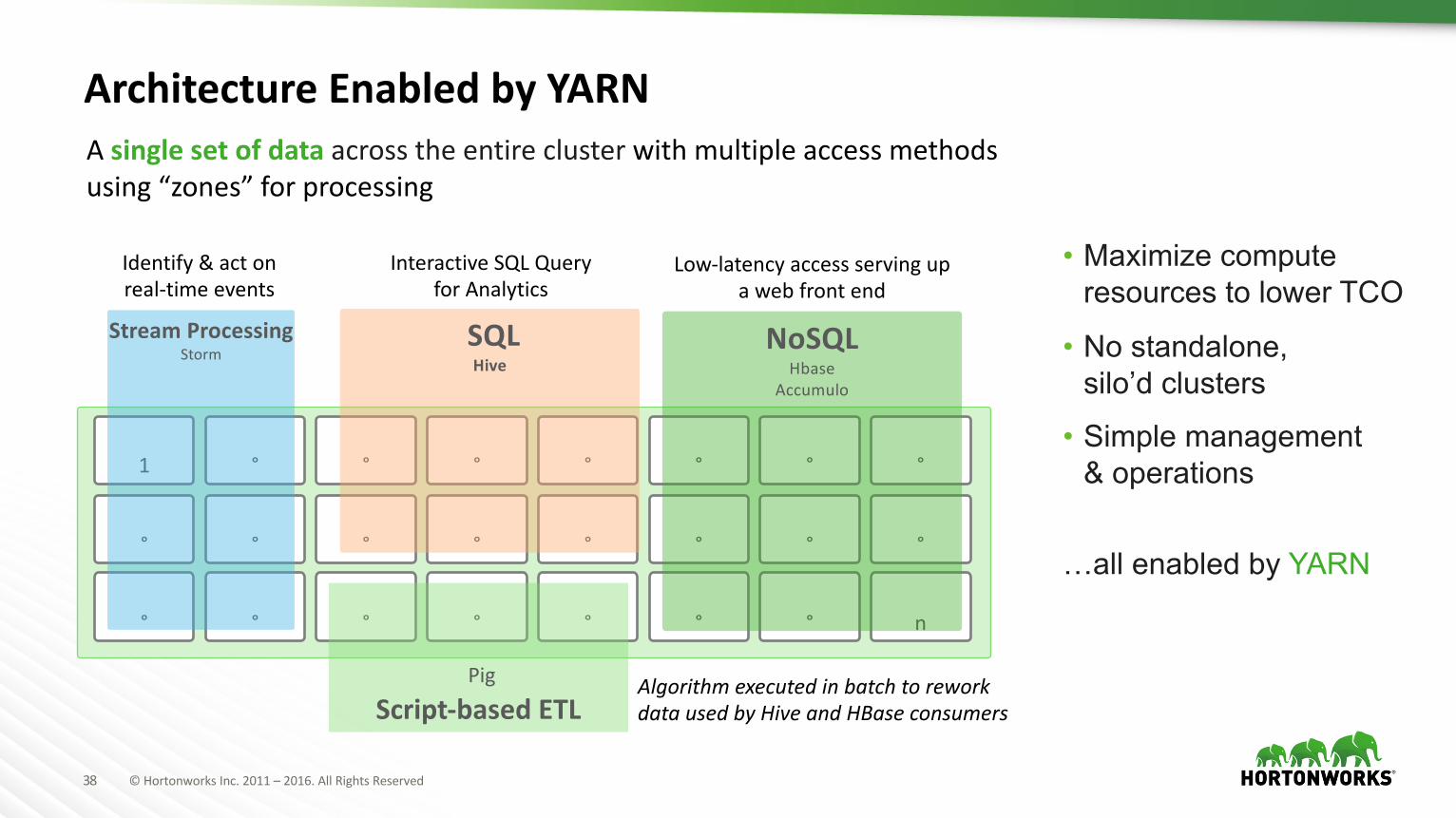
ArchitectureEnabledbyYARNAsinglesetofdataacrosstheentireclusterwithmultipleaccessmethodsusing“zones”forprocessing
1 ° ° ° ° ° ° °
° ° ° ° ° ° ° °
° ° ° ° ° ° ° n
SQLHive
InteractiveSQLQueryforAnalytics
Pig
Script-basedETLAlgorithmexecutedinbatchtoreworkdatausedbyHiveandHBaseconsumers
• Maximize compute resources to lower TCO
• No standalone, silo’d clusters
• Simple management & operations
…all enabled by YARN
StreamProcessingStorm
Identify&actonreal-timeevents
NoSQLHbase
Accumulo
Low-latencyaccessservingupawebfrontend
39 ©HortonworksInc.2011– 2016.AllRightsReserved
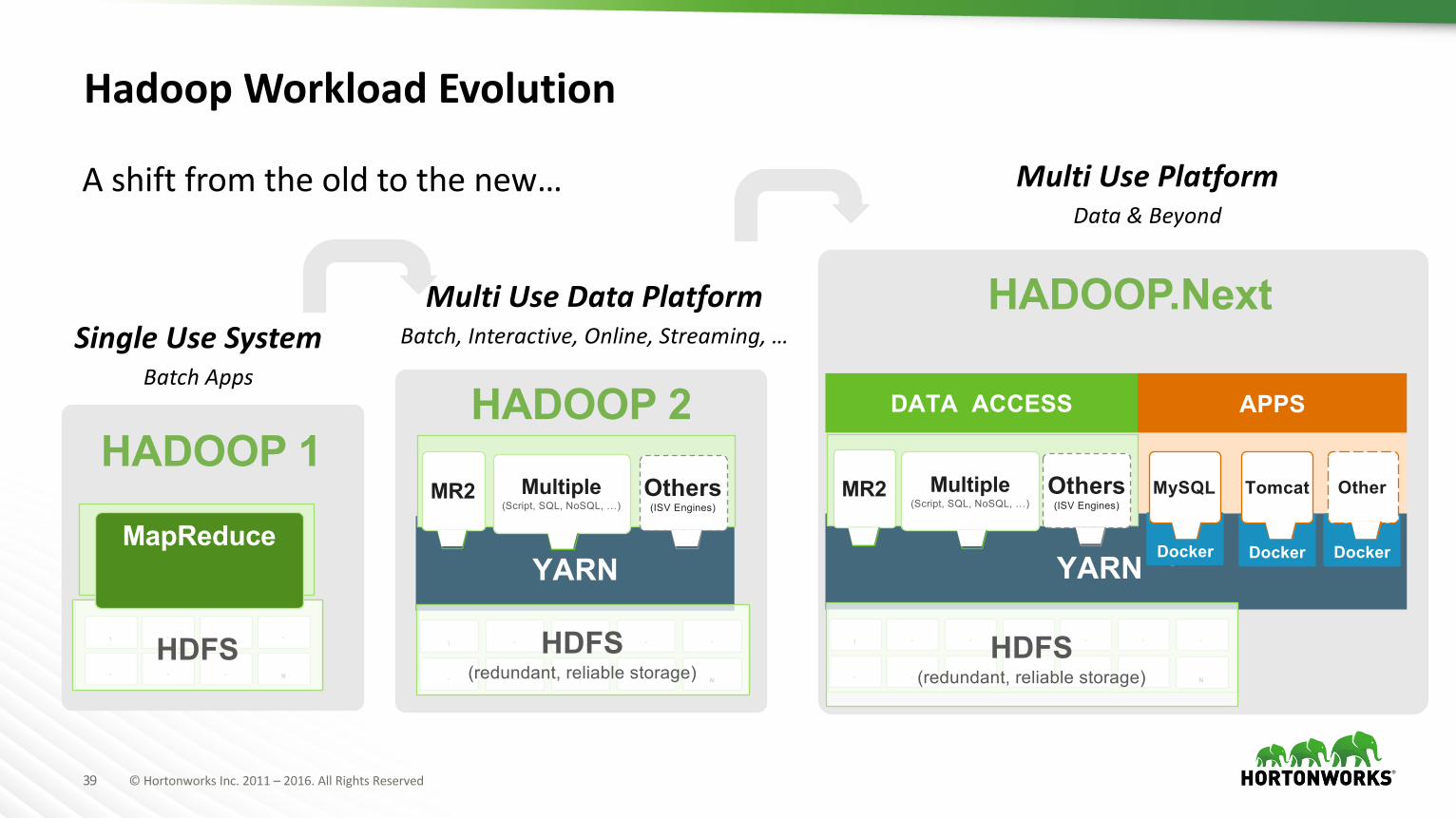
HadoopWorkloadEvolution
SingleUseSystemBatchApps
MultiUseDataPlatformBatch,Interactive,Online,Streaming,…
Ashiftfromtheoldtothenew… MultiUsePlatformData&Beyond
HADOOP 1
YARN
HADOOP 2
1 ° ° ° °
° ° ° ° N
HDFS (redundant, reliable storage)
1 ° ° °
° ° ° N
HDFS
MapReduce
HADOOP.Next
YARN ‘
1 ° ° ° ° ° °
° ° ° ° ° ° N
HDFS (redundant, reliable storage)
DATA ACCESS APPS
Docker
MySQLMR2 Others(ISV Engines)
Multiple(Script, SQL, NoSQL, …)
MR2 Others(ISV Engines)
Multiple(Script, SQL, NoSQL, …)
Docker
Tomcat
Docker
Other

40 ©HortonworksInc.2011– 2016.AllRightsReserved
Gartner:WhatisHadoop?
à CommonApacheProjects– ALL=7(6)– Exceptfor1=3(5)– Exceptfor2=4(4)² About14CommonProjects
à UncommonProjects– Only1=9(1)– Only2=7 (2)– Only3=6 (3)² About22UncommonProjects
http://blogs.gartner.com/merv-adrian/2015/07/02/now-what-is-hadoop/
ODPi
ODPi
ODPi
ODPi
ODPi ODPi ODPi
41 ©HortonworksInc.2011– 2016.AllRightsReserved
HORTONWORKSDATAPLATFORM
Hado
op&YAR
N
Flum
e
Oozie
HDP2.3isApacheHadoop;not“basedon”Hadoop
Pig
Hive
Tez
Sqoo
p
Clou
dbreak
Amba
ri
Slider
Kafka
Knox
Solr
Zookeepe
r
Spark
Falcon
Ranger
HBase
Atlas
Accumulo
Storm
Phoe
nix
4.10.2
DATAMGMT DATAACCESS GOVERNANCE&INTEGRATION OPERATIONS SECURITY
HDP2.2Dec2014
HDP2.1April2014
HDP2.0Oct2013
HDP2.2Dec2014
HDP2.1April2014
HDP2.0Oct2013
0.12.0 0.12.0
0.12.1 0.13.0 0.4.0
1.4.4 1.4.4 3.3.23.4.5
0.4.00.5.0
0.14.0 0.14.0 3.4.6 0.5.0 0.4.00.9.30.5.2
4.0.04.7.2
1.2.1 0.60.0 0.98.4 4.2.0 1.6.1 0.6.0 1.5.21.4.5 4.1.02.0.0
1.4.0 1.5.1 4.0.0
1.3.1
1.5.1 1.4.4 3.4.5
2.2.0
2.4.0
2.6.0
2.7.1 1.4.6 1.0.0 0.6.0 0.5.02.1.00.8.2 3.4.61.5.25.2.1 0.80.0 0.5.01.7.04.4.0 0.10.0 0.6.10.7.01.2.10.15.0HDP2.3Oct2015 4.2.0
0.96.1
0.98.0 0.9.1
0.8.1
1.4.1 1.1.2
2.7.3 1.4.6 1.3.0 0.9.0 0.6.02.4.00.10.0 3.4.61.5.25.5.1 0.91.0 0.7.01.7.04.7.0 1.0.1 0.10.00.7.01.2.1+2.1***0.16.0
HDP2.5*2H2016
4.2.01.6.2+2.0** 1.1.2
2.7.1 1.4.6 1.2.0 0.6.0 0.5.02.2.10.9.0 3.4.61.5.25.2.1 0.80.0 0.5.01.7.04.4.0 0.10.0 0.6.10.7.01.2.10.15.0HDP2.4Mar2016 4.2.01.6.0 1.1.2
Zepp
elin
OngoingInnovationinApache
0.6.0
*HDP2.5– ShowscurrentApachebranchesbeingused.FinalcomponentversionsubjecttochangebasedonApachereleaseprocess.
**Spark1.6.2+Spark2.0– HDP2.5supportinstallationofbothSpark1.6.2andSpark2.0.Spark2.0isTechnicalPreviewwithinHDP2.5.
***Hive2.1isTechnicalPreviewwithinHDP2.5.
42 ©HortonworksInc.2011– 2016.AllRightsReserved
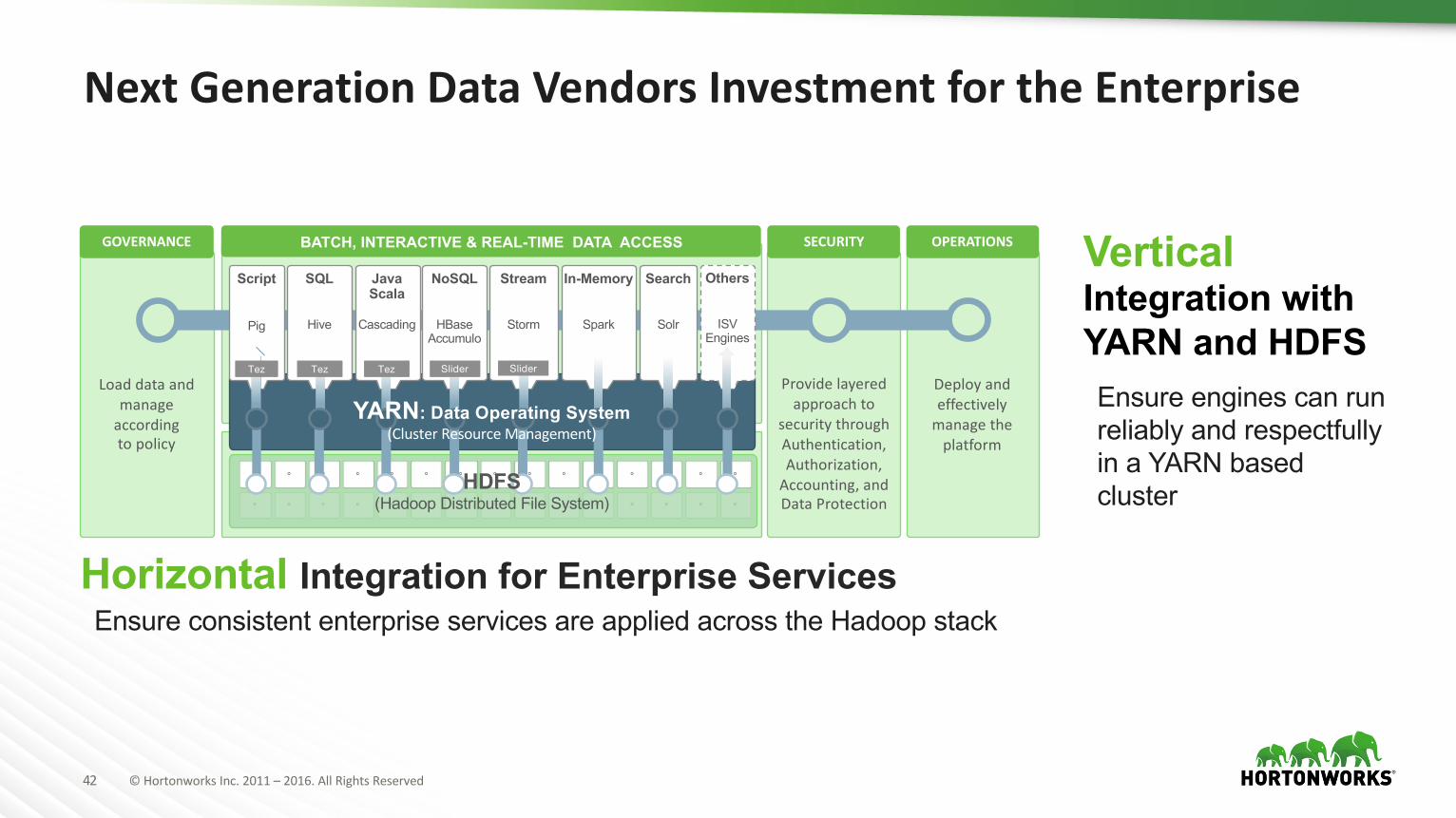
NextGenerationDataVendorsInvestmentfortheEnterprise
VerticalIntegration with YARN and HDFSEnsure engines can run reliably and respectfully in a YARN based cluster
Provision, Manage & Monitor
AmbariZookeeper
Scheduling
Oozie
Loaddataandmanageaccordingtopolicy
Providelayeredapproachto
securitythroughAuthentication,Authorization,Accounting,andDataProtection
SECURITYGOVERNANCE
Deployandeffectivelymanagetheplatform
° ° ° ° ° ° ° ° ° ° ° ° ° ° °
Script
Pig
SQL
Hive
JavaScala
Cascading
Stream
Storm
Search
Solr
NoSQL
HBaseAccumulo
BATCH, INTERACTIVE & REAL-TIME DATA ACCESS
In-Memory
Spark
Others
ISV Engines
1 ° ° ° ° ° ° ° ° ° ° ° ° ° °
YARN: Data Operating System(ClusterResourceManagement)
HDFS (Hadoop Distributed File System)
Tez Slider SliderTez Tez
OPERATIONS
Horizontal Integration for Enterprise ServicesEnsure consistent enterprise services are applied across the Hadoop stack

43 ©HortonworksInc.2011– 2016.AllRightsReserved
Whatdodistributionsdo?
à Defineastackofcomponents• RichandlatestsetofApacheProjects(opensource&opencommunity)withoutlockin
à VerticalandHorizontalintegrationofcomponents• Vertical:BestSpeedandScale• Horizontal:OpenEnterpriseReady
à ProvisionandUpgradestack• Robust,EasyandAnywhere
à Acceleratetimetovalue(easyofuse)• NewFaceofHadoopwithUis fromAmbari,AmbariViews,Ranger,Falcon,Atlas
à PartnerEcosystem• RichandDeep
à Support• Industry’sbest,SmartSense andinfluencecommunity

HadoopOperations&Tools
45 ©HortonworksInc.2011– 2016.AllRightsReserved
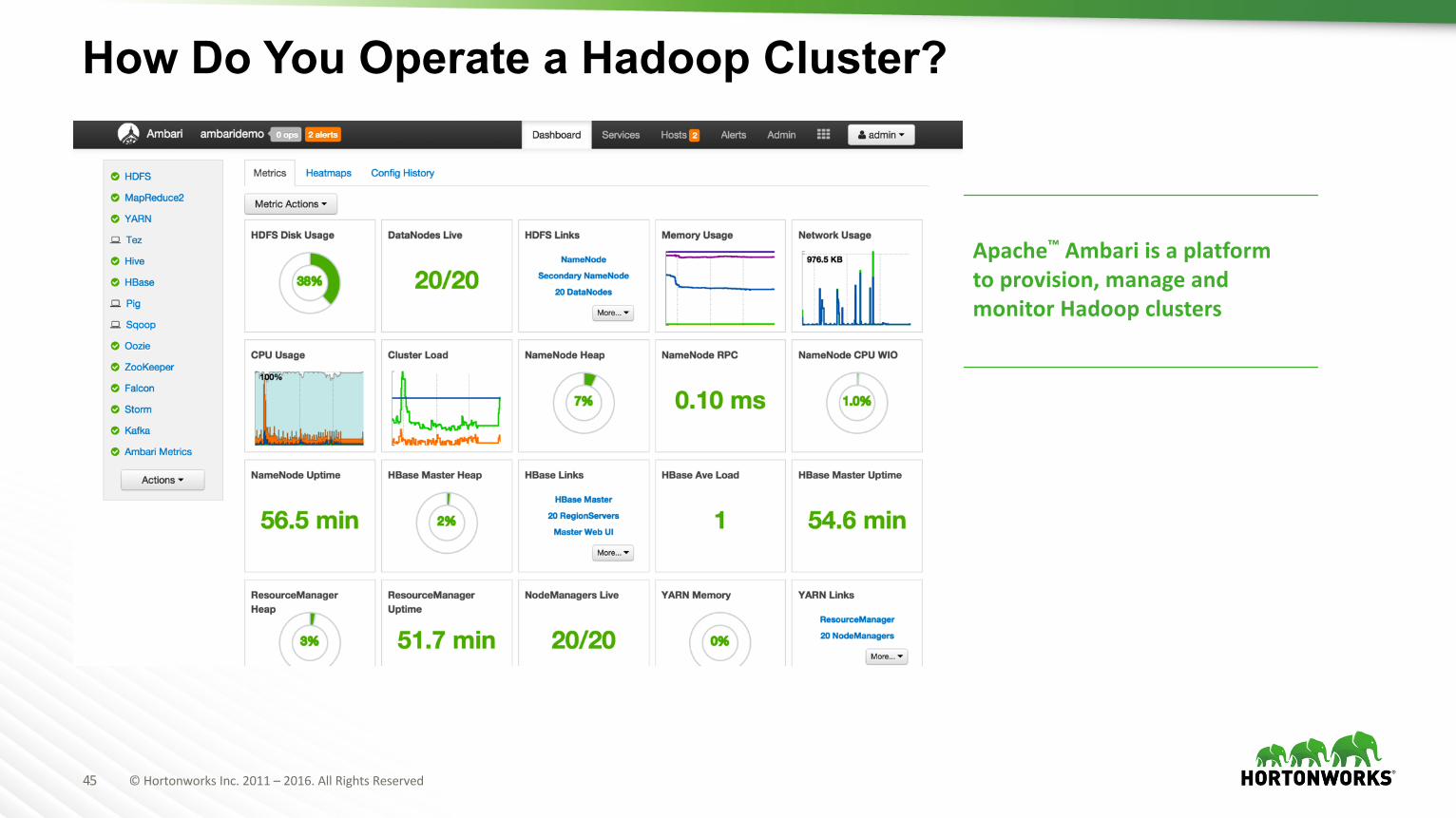
How Do You Operate a Hadoop Cluster?
Apache™ Ambari isaplatformtoprovision,manageandmonitorHadoopclusters
46 ©HortonworksInc.2011– 2016.AllRightsReserved
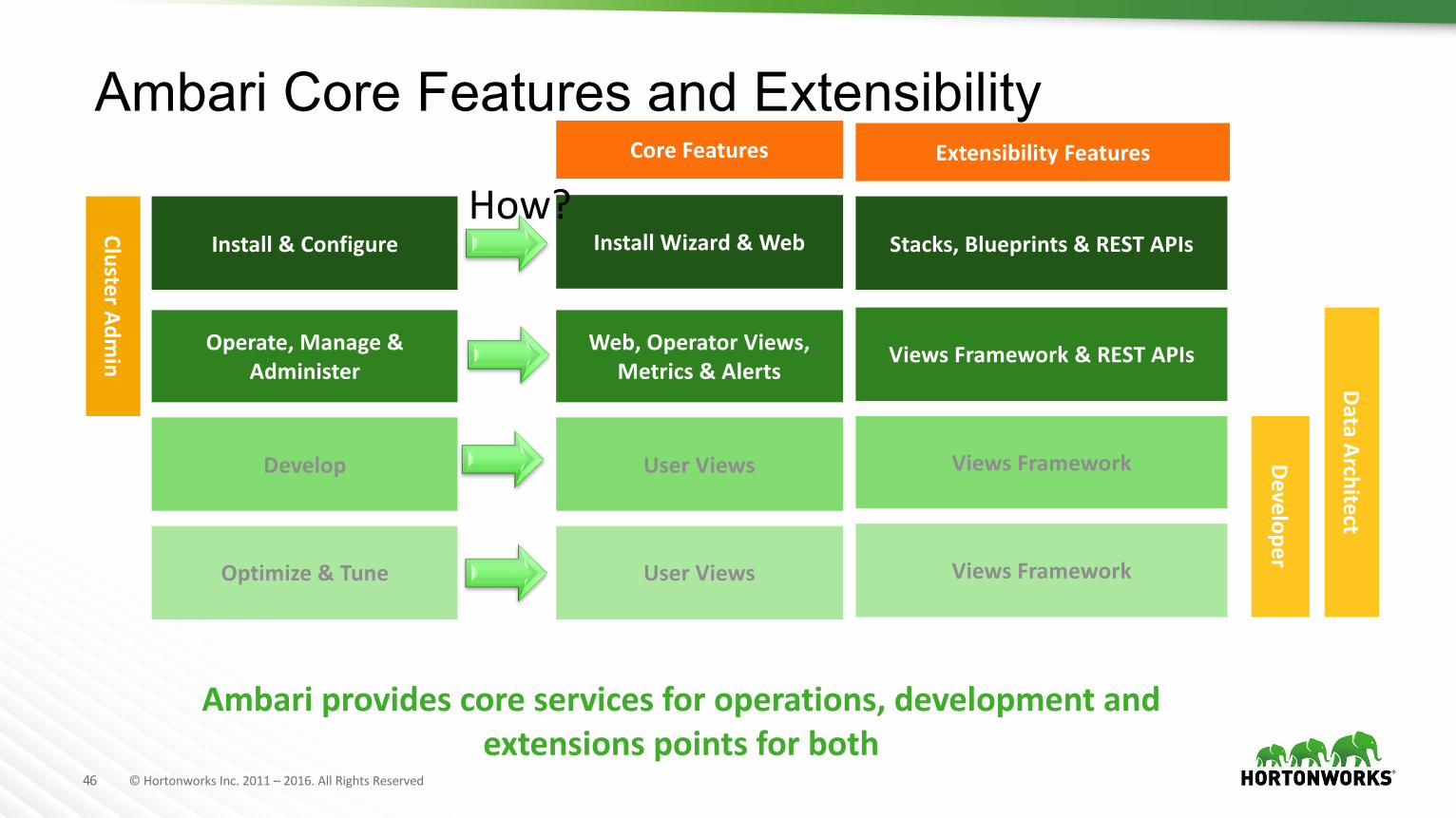
Ambari Core Features and Extensibility
Install&Configure
Operate,Manage&Administer
Develop
Optimize&Tune
Developer
DataArchitect
Ambariprovidescoreservicesforoperations,developmentandextensionspointsforboth
ExtensibilityFeatures
Stacks,Blueprints&RESTAPIs
CoreFeatures
InstallWizard&Web
Web,OperatorViews,Metrics&Alerts
UserViews
UserViews
ViewsFramework&RESTAPIs
ViewsFramework
ViewsFramework
How?
ClusterAdmin
47 ©HortonworksInc.2011– 2016.AllRightsReserved
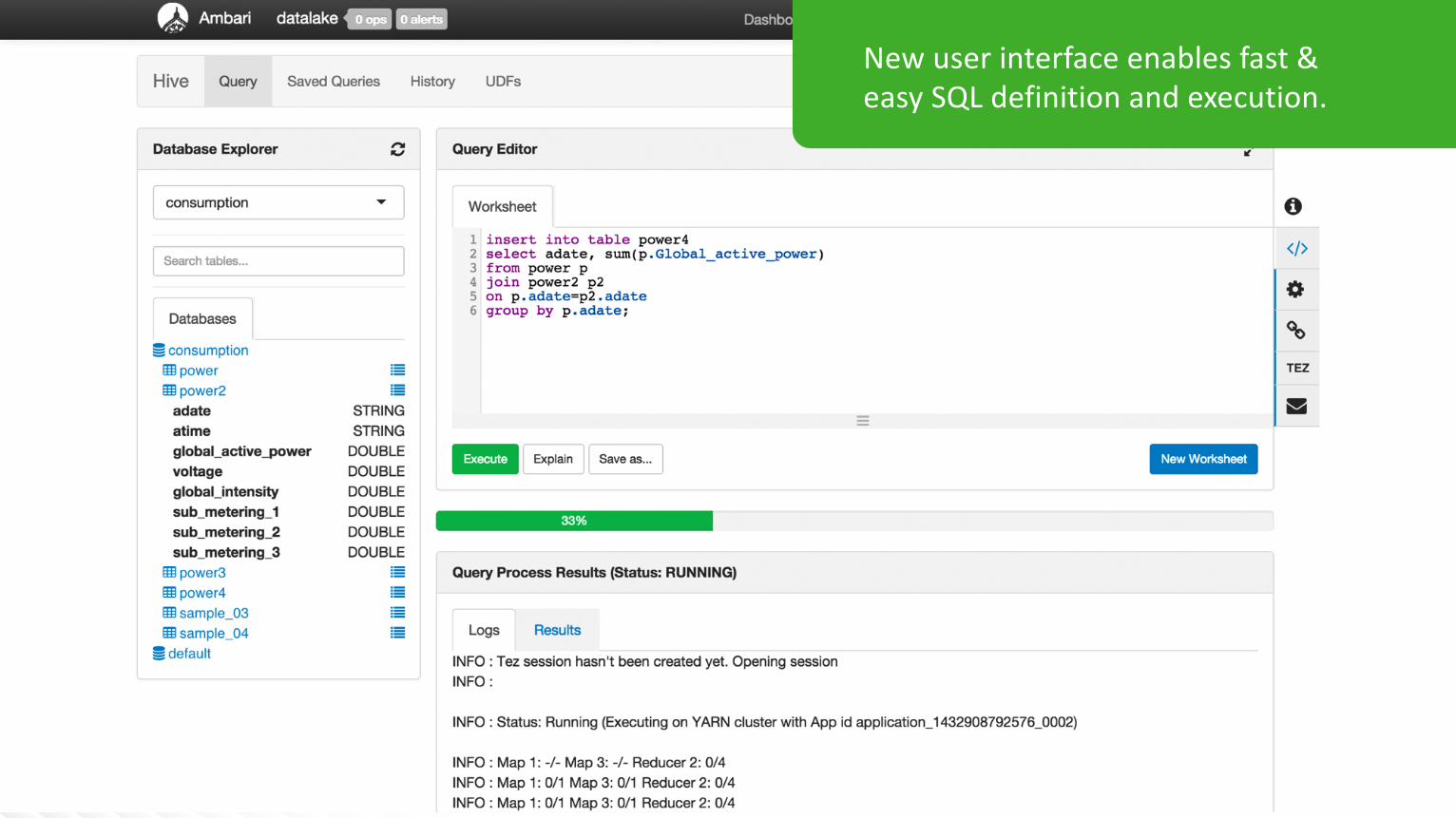
Newuserinterfaceenablesfast&easySQLdefinitionandexecution.
48 ©HortonworksInc.2011– 2016.AllRightsReserved
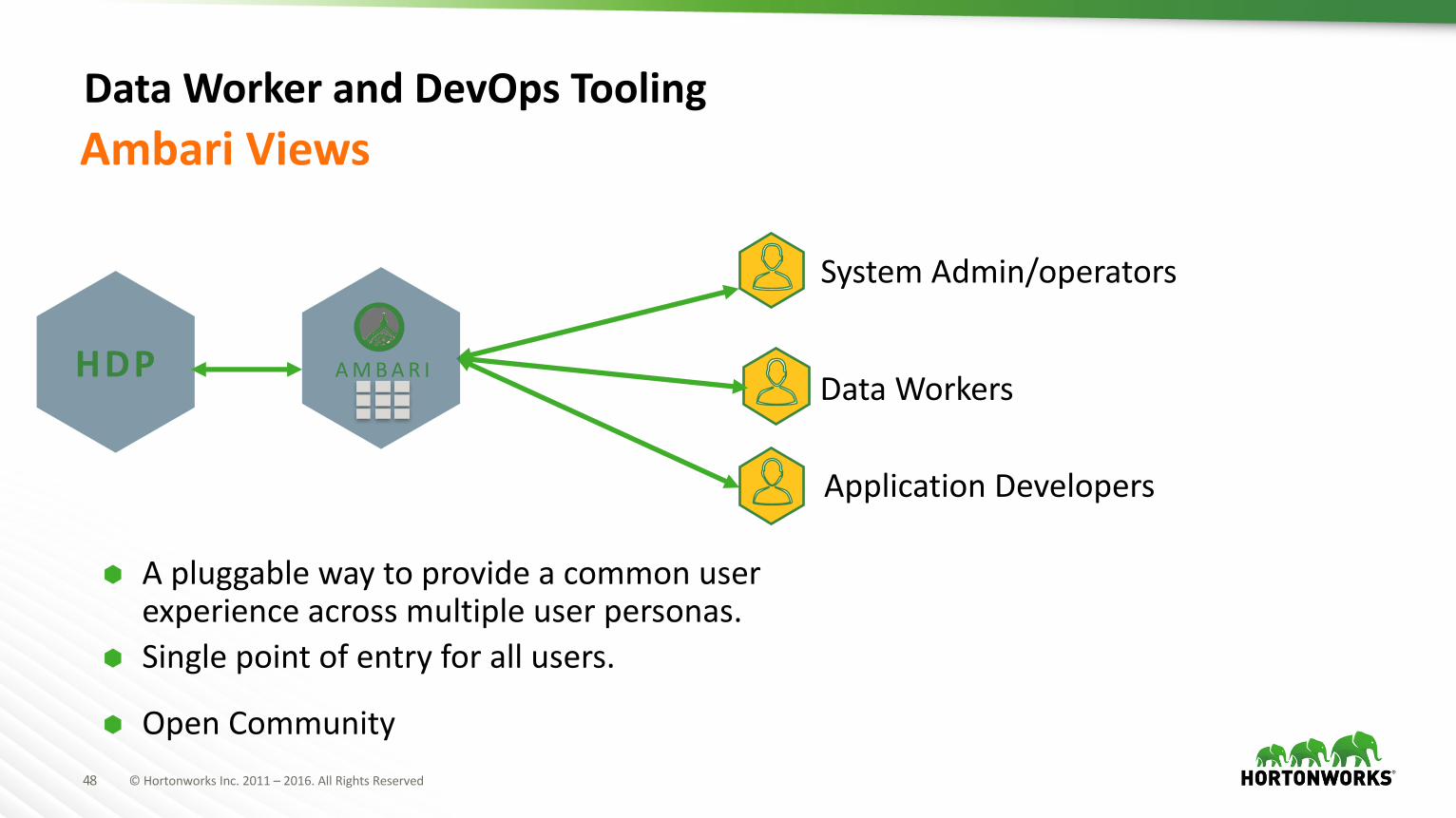
DataWorkerandDevOpsTooling
à Apluggablewaytoprovideacommonuserexperienceacrossmultipleuserpersonas.
Ambari Views
HDP
SystemAdmin/operators
DataWorkers
ApplicationDevelopers
AMBAR I
à Singlepointofentryforallusers.
à OpenCommunity
49 ©HortonworksInc.2011– 2016.AllRightsReserved
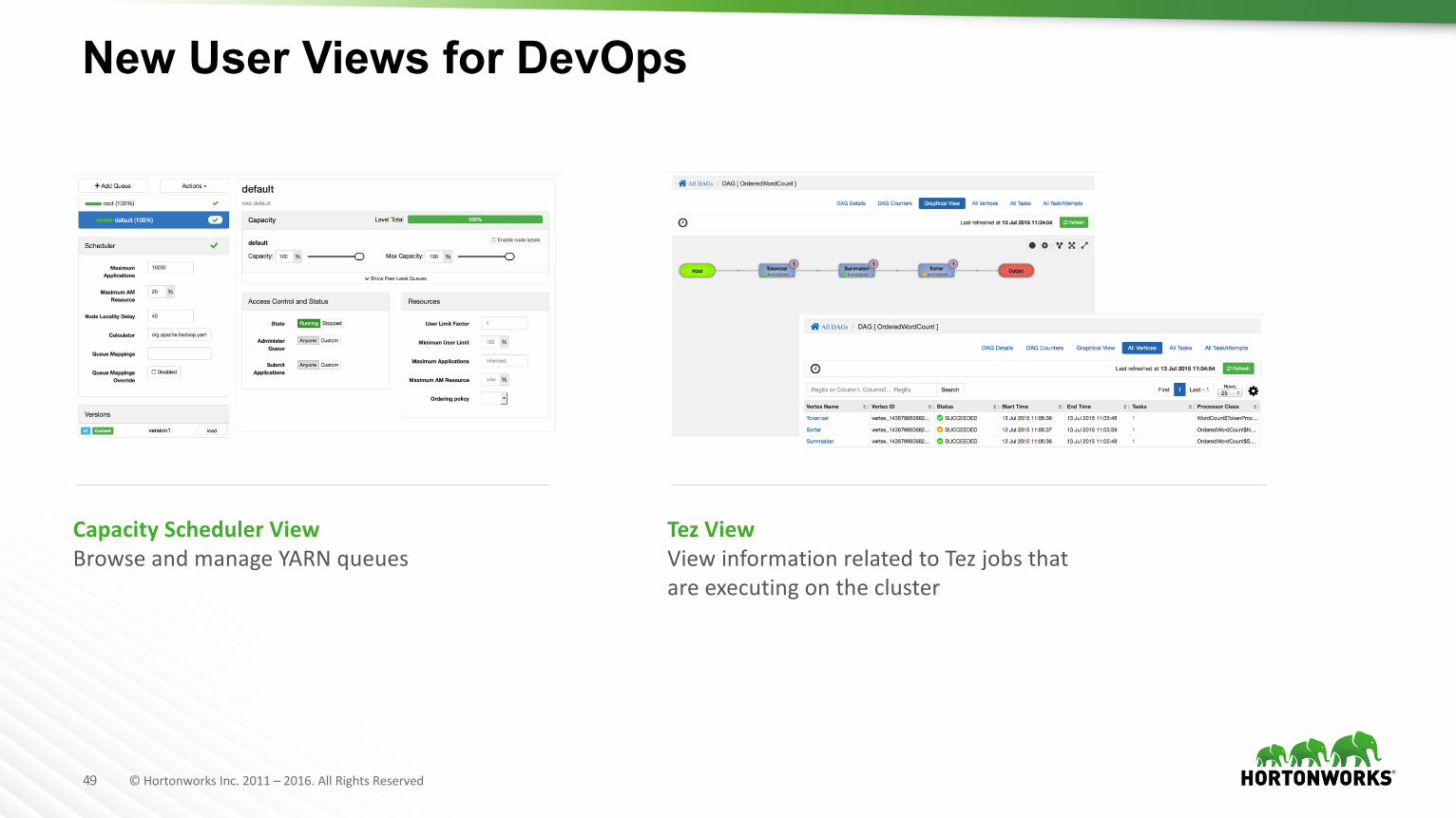
New User Views for DevOps
CapacitySchedulerViewBrowseandmanageYARNqueues
Tez ViewViewinformationrelatedtoTez jobsthatareexecutingonthecluster

50 ©HortonworksInc.2011– 2016.AllRightsReserved
NewUserViewsforDevelopment
PigViewAuthorandexecutePigScripts.
HiveViewAuthor,executeanddebugHive
queries.
FilesViewBrowseHDFSfilesystem.

51 ©HortonworksInc.2011– 2016.AllRightsReserved
ApacheZeppelin
• Web-basednotebookfordataengineers,dataanalystsanddatascientists• Bringsinteractivedataingestion,data
exploration,visualization,sharingandcollaborationfeaturestoHadoopandSpark
• Moderndatasciencestudio• ScalawithSpark• PythonwithSpark• SparkSQL• ApacheHive,andmore.

HadoopDataAccess
53 ©HortonworksInc.2011– 2016.AllRightsReserved
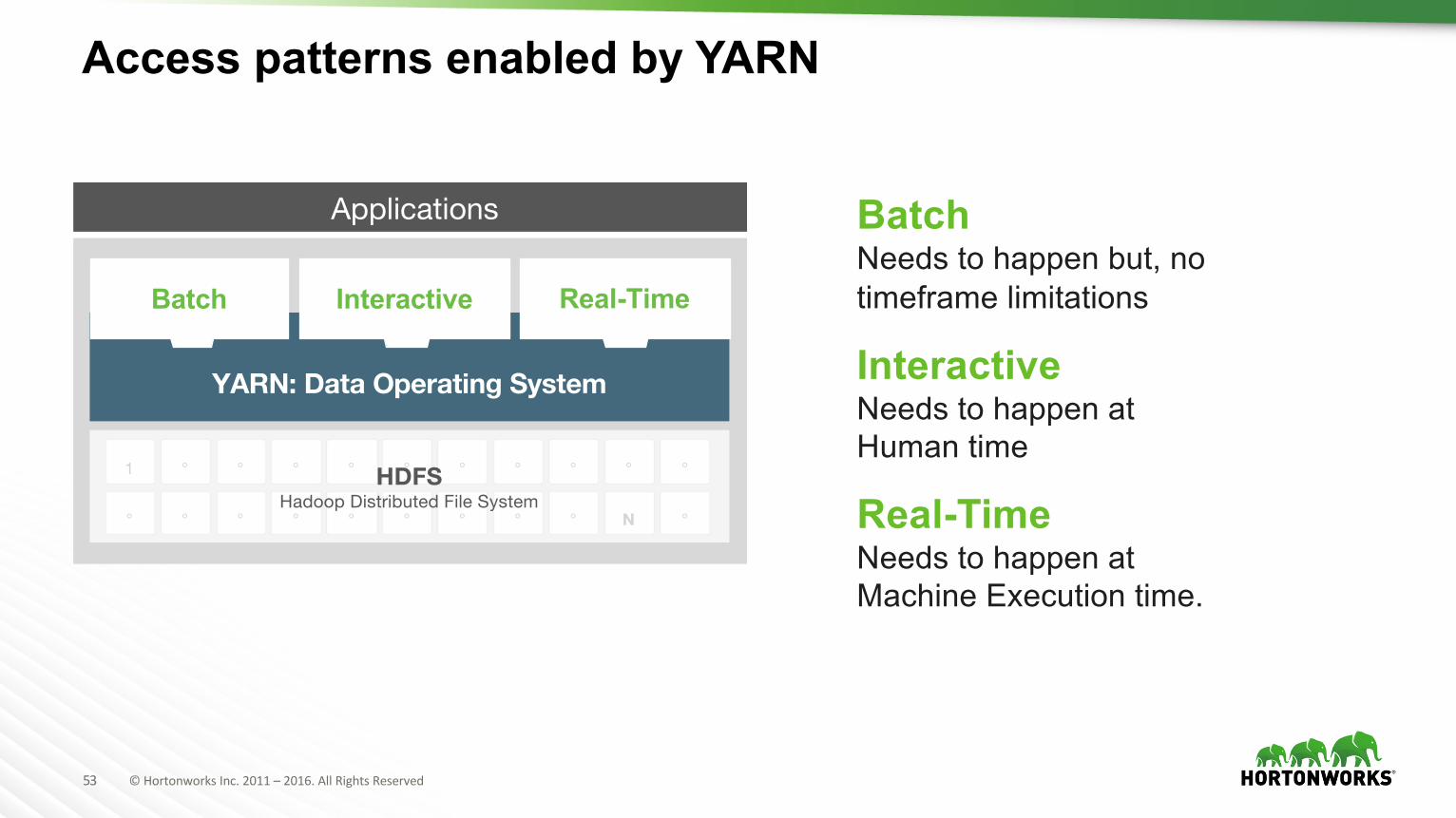
Access patterns enabled by YARN
YARN: Data Operating System
1 ° ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° °
°
°N
HDFS Hadoop Distributed File System
Interactive Real-TimeBatch
Applications BatchNeeds to happen but, no timeframe limitations
InteractiveNeeds to happen at Human time
Real-Time Needs to happen at Machine Execution time.

54 ©HortonworksInc.2011– 2016.AllRightsReserved
Apache Hive: SQL in Hadoop
• Created by a team at Facebook
• Provides a standard SQL interface to data stored in Hadoop
• Quickly find value in raw data files
• Proven at petabyte scale
• Compatible with ALL major BI tools such as Tableau, Excel, MicroStrategy, Business Objects, etc…
SensorMobile
WeblogOperational
/MPP
SQLQueries
Page 55 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
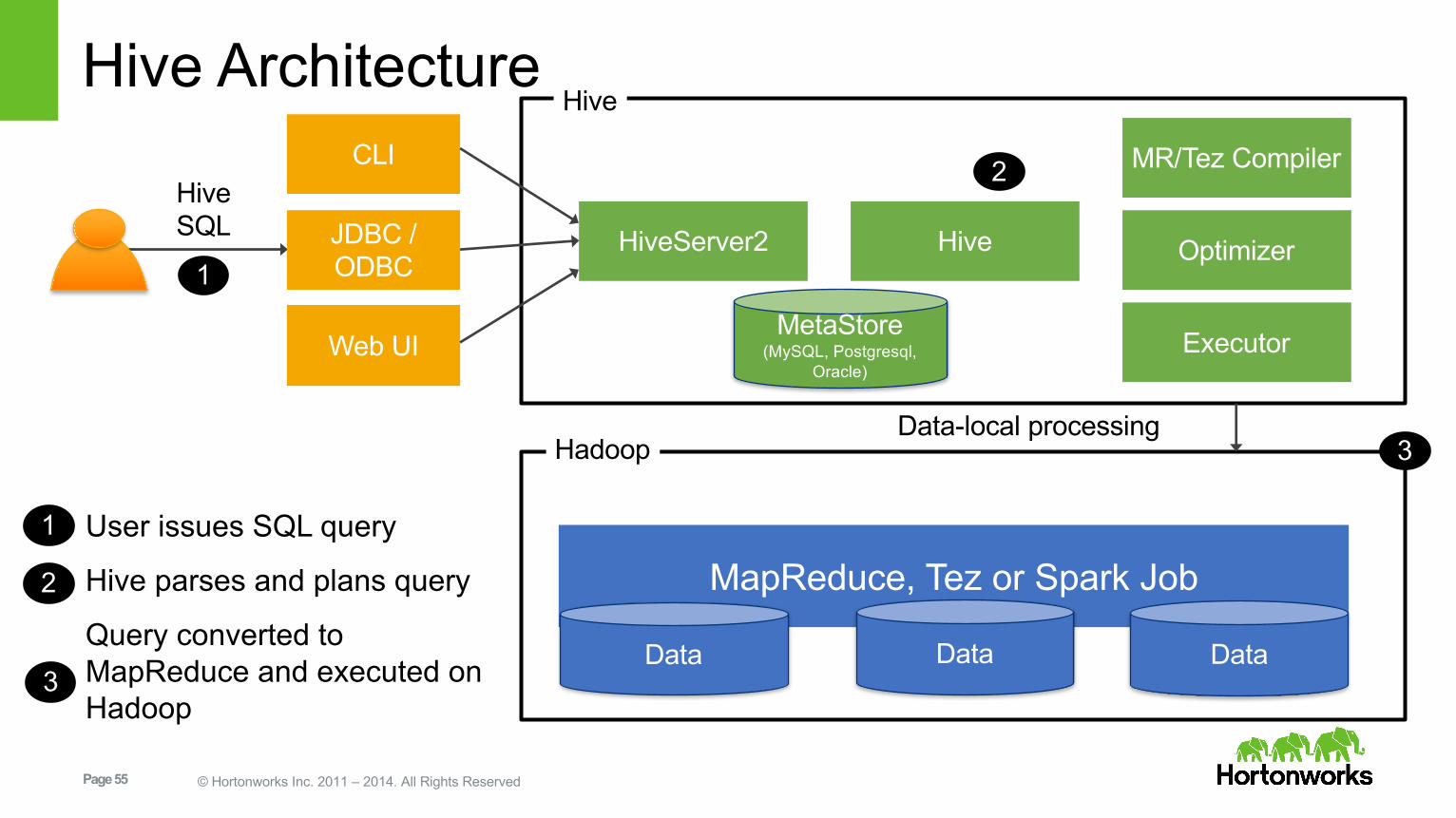
Hive Architecture
User issues SQL query
Hive parses and plans query
Query converted to MapReduce and executed on Hadoop
2
3
Web UI
JDBC / ODBC
CLIHiveSQL
1
1HiveServer2 Hive
MR/Tez Compiler
Optimizer
Executor
2
Hive
MetaStore(MySQL, Postgresql,
Oracle)
MapReduce, Tez or Spark Job
Data DataData
Hadoop 3Data-local processing
56 ©HortonworksInc.2011– 2016.AllRightsReserved
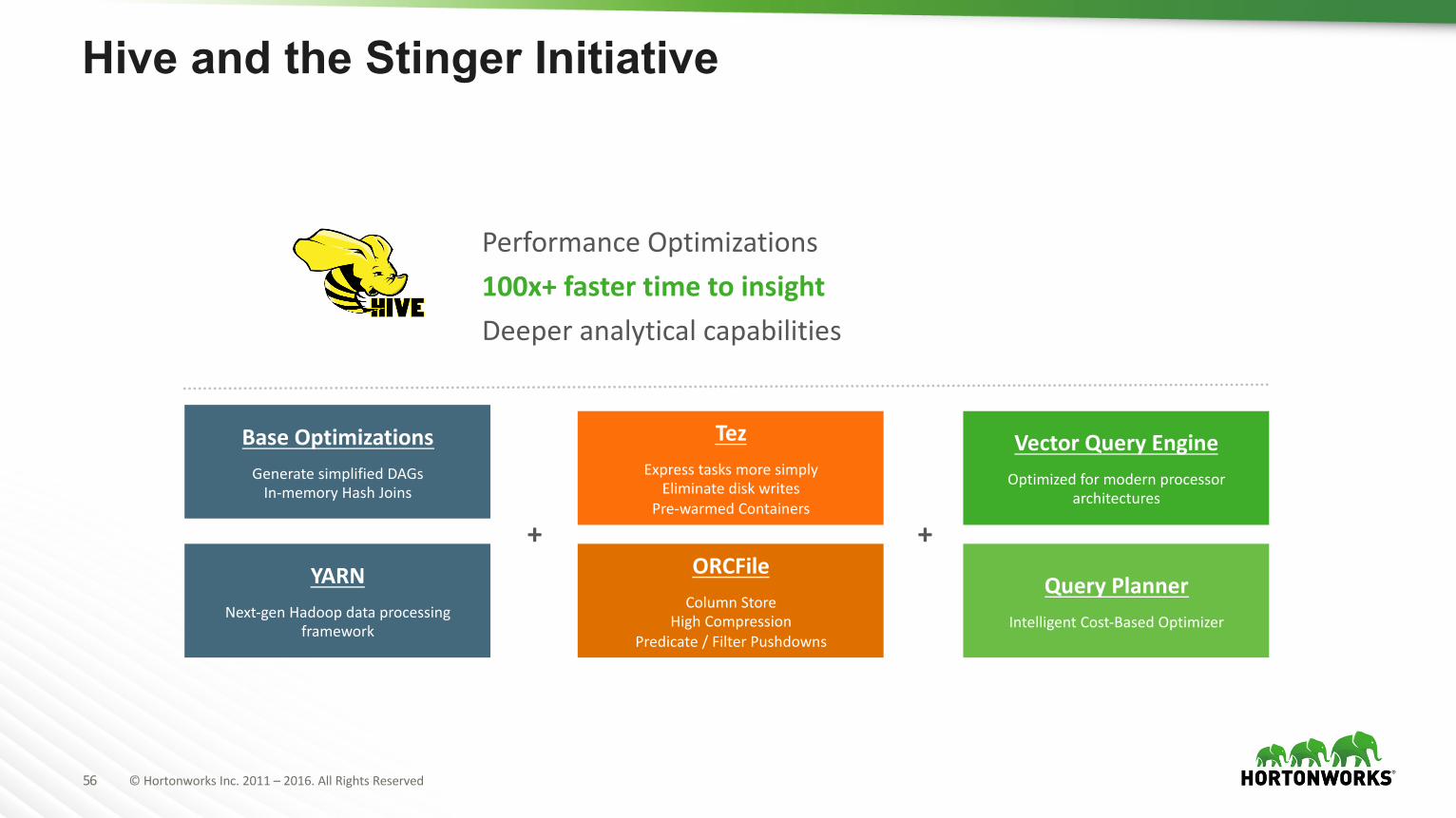
Hive and the Stinger Initiative
BaseOptimizationsGeneratesimplifiedDAGsIn-memoryHashJoins
VectorQueryEngineOptimizedformodernprocessor
architectures
TezExpresstasksmoresimply
EliminatediskwritesPre-warmedContainers
ORCFileColumnStore
HighCompressionPredicate/FilterPushdowns
YARNNext-genHadoopdataprocessing
framework
+ +
QueryPlannerIntelligentCost-BasedOptimizer
PerformanceOptimizations100x+fastertimetoinsightDeeperanalyticalcapabilities

57 ©HortonworksInc.2011– 2016.AllRightsReserved
Stinger.next andSub-SecondSQL
Emergence of LLAP brings Sub-Second SQL response times within reach with Hive.
BATCH & INTERACTIVE BATCH & INTERACTIVE BATCH, INTERACTIVE & SUB-SECONDSPEED
DELIVERY
SQL
UPDATES
ENGINES
STINGERD E L I V E R E D
PROGRESSD E L I V E R E D FINALVERSION
HDP 2.1VERSION
0.13VERSION
HDP 2.3VERSION
1.2.1
SQL:2003+ SQL:2011 SUBSET
READ-ONLY SQL INSERT/UPDATE/DELETE
MR, TEZ MR, TEZ
F U T U R ES T I N G E R N E X T
COMPLETE ACID SUPPORT INCLUDING MERGE
COMPREHENSIVE SQL:2011 BASED ANALYTICS
MR, TEZ, LLAP
DELIVERED IN DEVELOPMENT
TieredDataStorage
Stinger.next Phase3
YARN:ContainerizedApplications
58 ©HortonworksInc.2011– 2016.AllRightsReserved
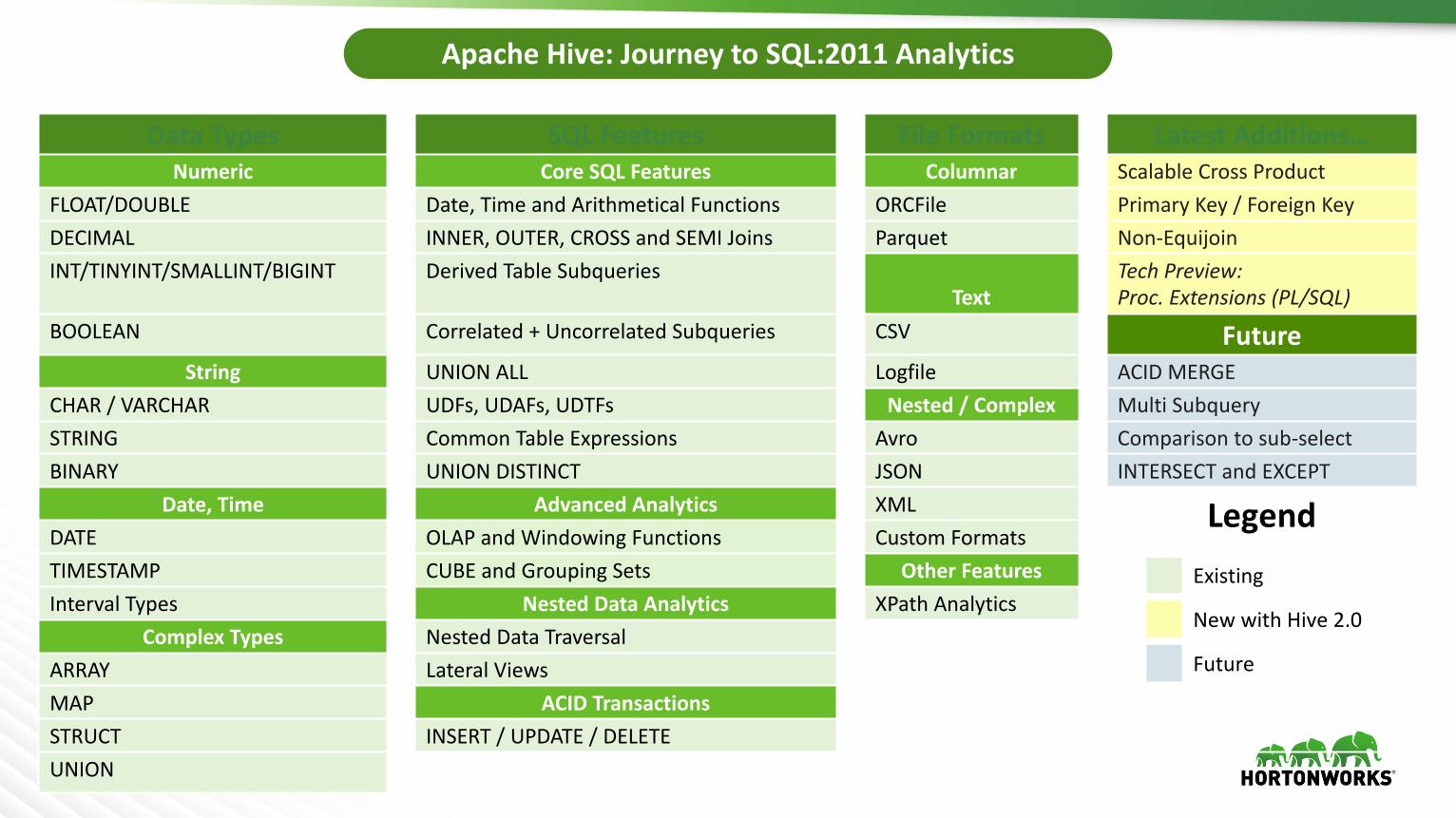
DataTypes SQL Features File Formats Latest Additions…Numeric CoreSQLFeatures Columnar ScalableCrossProduct
FLOAT/DOUBLE Date,Time andArithmeticalFunctions ORCFile PrimaryKey/Foreign KeyDECIMAL INNER,OUTER,CROSSandSEMIJoins Parquet Non-EquijoinINT/TINYINT/SMALLINT/BIGINT DerivedTableSubqueries
TextTechPreview:Proc.Extensions(PL/SQL)
BOOLEAN Correlated+ UncorrelatedSubqueries CSV FutureString UNIONALL Logfile ACIDMERGE
CHAR/VARCHAR UDFs, UDAFs,UDTFs Nested/Complex MultiSubquerySTRING CommonTableExpressions Avro Comparisontosub-selectBINARY UNIONDISTINCT JSON INTERSECT andEXCEPT
Date, Time AdvancedAnalytics XMLDATE OLAPandWindowingFunctions CustomFormatsTIMESTAMP CUBE andGroupingSets OtherFeaturesIntervalTypes NestedDataAnalytics XPath Analytics
ComplexTypes NestedDataTraversalARRAY LateralViewsMAP ACIDTransactionsSTRUCT INSERT/UPDATE/DELETEUNION
ApacheHive:JourneytoSQL:2011Analytics
LegendExisting
Future
NewwithHive2.0
59 ©HortonworksInc.2011– 2016.AllRightsReserved
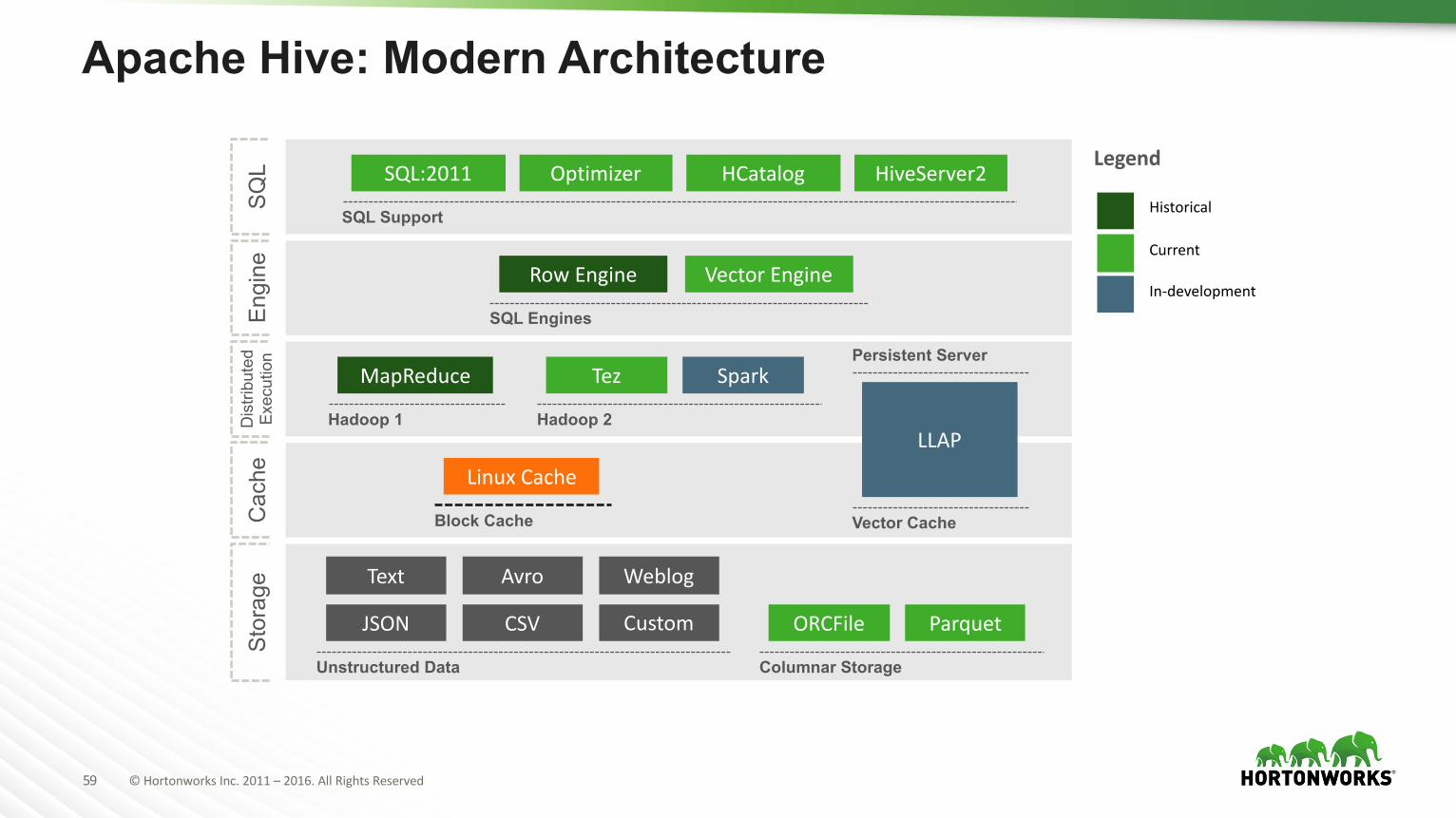
Stor
age
Columnar Storage
ORCFile Parquet
Unstructured Data
JSON CSV
Text Avro
Custom
Weblog
Engi
ne
SQL Engines
RowEngine VectorEngineSQ
L
SQL Support
SQL:2011 Optimizer HCatalog HiveServer2
Cac
he
Block Cache
LinuxCache
Dis
tribu
ted
Exec
utio
n
Hadoop 1
MapReduce
Hadoop 2
Tez Spark
Vector Cache
LLAP
Persistent Server
Historical
Current
In-development
Legend
Apache Hive: Modern Architecture

60 ©HortonworksInc.2011– 2016.AllRightsReserved
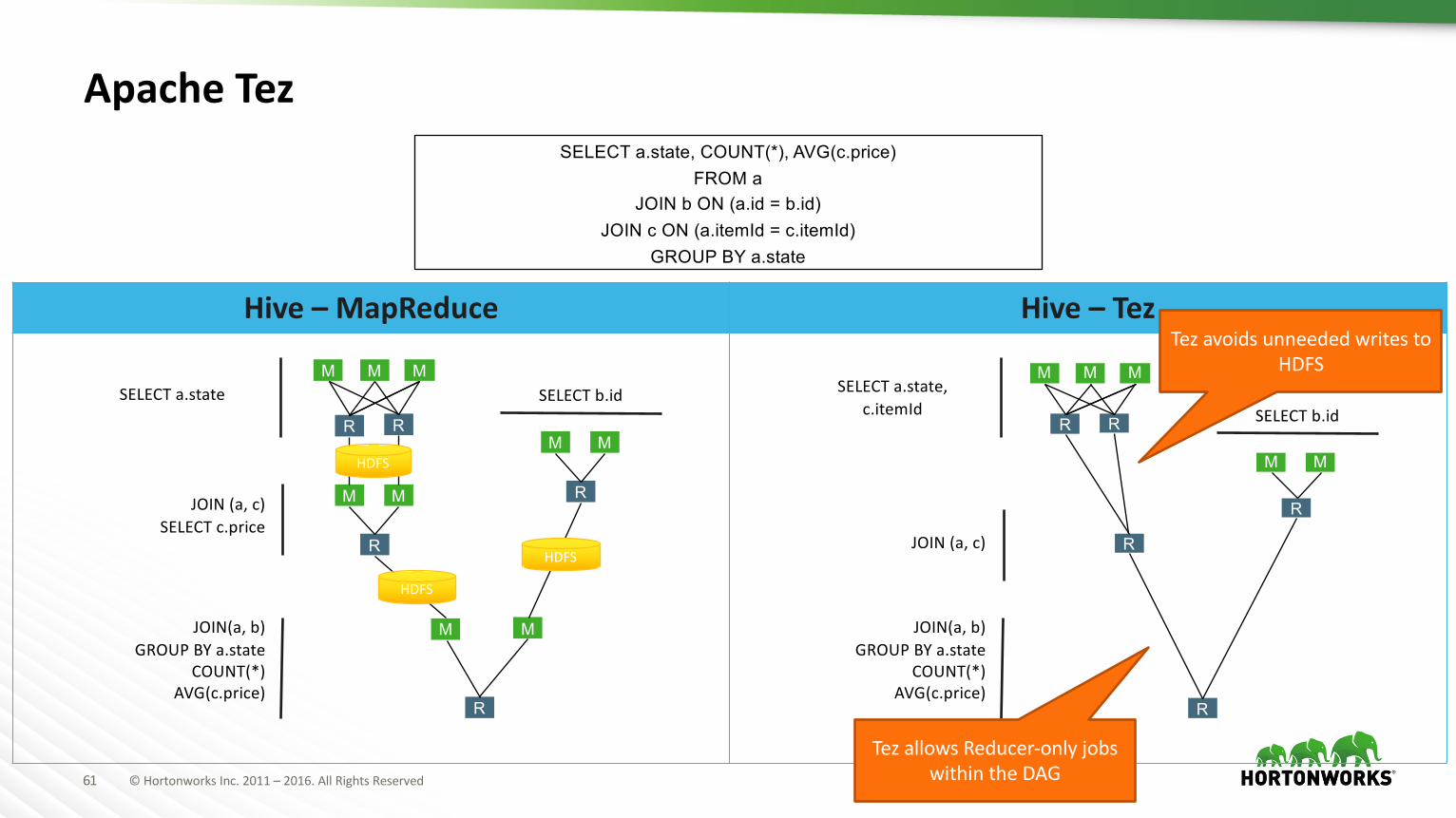
ApacheTezisacriticalinnovationoftheStingerInitiative.
• Along with YARN, Tez not only improves Hive, but improvesallthingsbatchand interactiveforHadoop;Pig,Cascading…
• More Efficient Processing than MapReduce
• Reduceoperationsandcomplexityofbackendprocessing• AllowsforMapReduceReducewhichsavesharddiskoperations• Implementsa“service”whichisalwayson,decreasingstarttimesofjobs• AllowsCachingofDatainMemory
YARN
Dev
Cascading/ Scalding
WhyisTez Important?
°1 ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° °
°
°°
° ° ° ° ° ° °
° ° ° ° ° ° N
HDFS (Hadoop Distributed File
System)
Scripting
Pig
SQL
Hive
Tez Tez
Applications
Tez
YARN:DataOperatingSystem
Interactive Real-TimeBatch
61 ©HortonworksInc.2011– 2016.AllRightsReserved
ApacheTez
Hive– MapReduce Hive– Tez
SELECT a.state, COUNT(*), AVG(c.price) FROM a
JOIN b ON (a.id = b.id)JOIN c ON (a.itemId = c.itemId)
GROUP BY a.state
SELECTa.state
JOIN(a,c)SELECTc.price
SELECTb.id
JOIN(a,b)GROUPBYa.state
COUNT(*)AVG(c.price)
M M M
R R
M M
R
M M
R
M M
R
HDFS
HDFS
HDFS
M M M
R R
R
M M
R
R
SELECTa.state,c.itemId
JOIN(a,c)
JOIN(a,b)GROUPBYa.state
COUNT(*)AVG(c.price)
SELECTb.id
Tez avoidsunneededwritestoHDFS
Tez allowsReducer-onlyjobswithintheDAG

62 ©HortonworksInc.2011– 2016.AllRightsReserved
Sub-secondQueriesinHive:LLAP(LiveLongandProcess)
à Persistentdaemons– Savestimeonprocessstartup(eliminatescontainerallocationandJVMstartuptime)– AllcodeJITed withinaqueryortwo
à Datacachingwithanasync I/Oelevator– Hotdatacachedinmemory(columnaraware,soonlyhotcolumnscached)– Whenpossibleworkscheduledonnodewithdatacached,ifnotworkwillberuninothernode
à OperatorscanbeexecutedinsideLLAPwhenitmakessense– Large,ETLstylequeriesusuallydon’tmakesense– UsercodenotruninLLAPforsecurity
à Workingoninterfacetoallowotherdataenginestoreadsecurelyinparallel
à Betain2.0
63 ©HortonworksInc.2011– 2016.AllRightsReserved
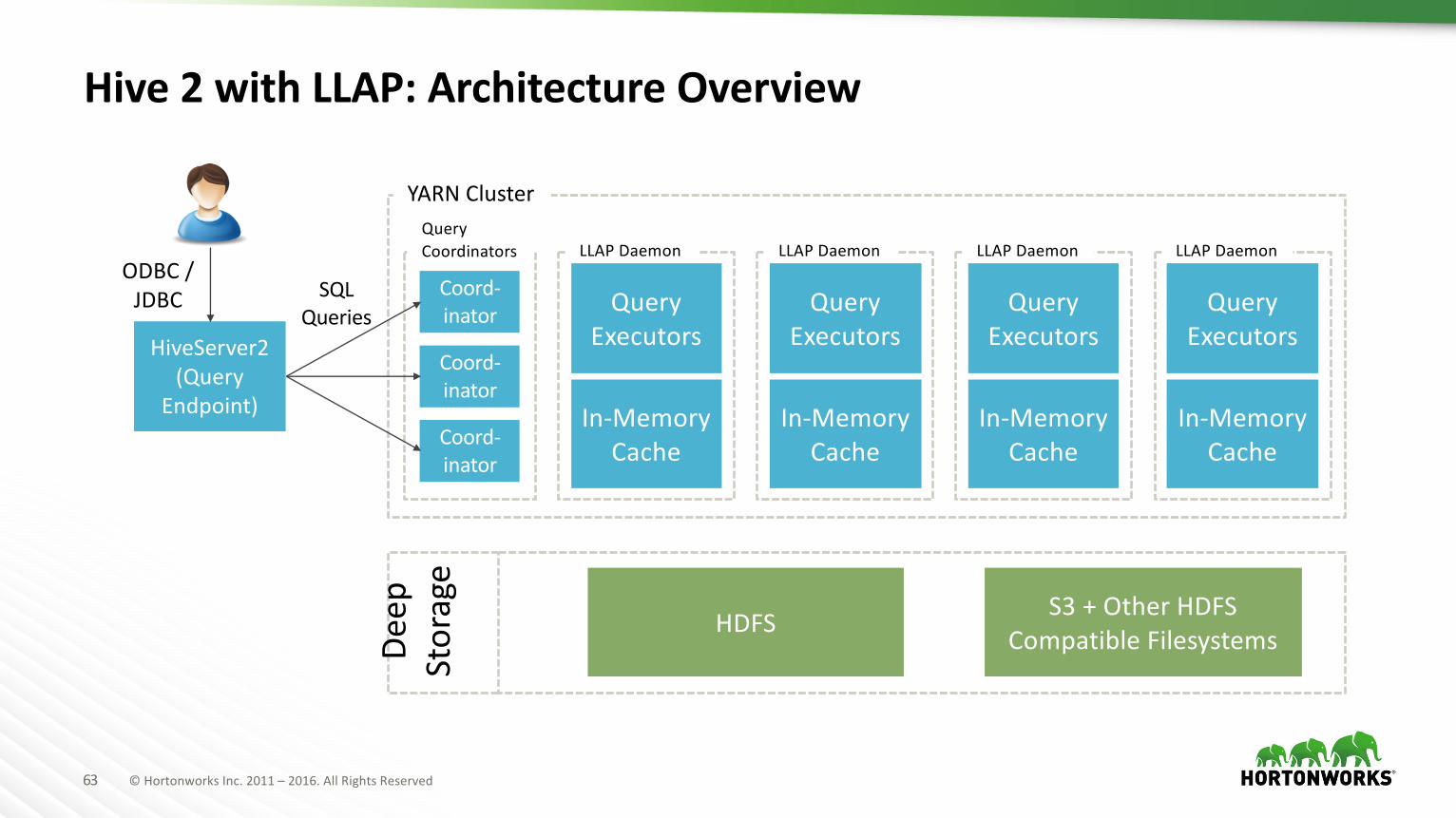
Hive2withLLAP:ArchitectureOverview
Deep
Storage
HDFS S3+OtherHDFSCompatibleFilesystems
YARNCluster
LLAPDaemon
QueryExecutors
In-MemoryCache
LLAPDaemon
QueryExecutors
In-MemoryCache
LLAPDaemon
QueryExecutors
In-MemoryCache
LLAPDaemon
QueryExecutors
In-MemoryCache
QueryCoordinators
Coord-inator
Coord-inator
Coord-inator
HiveServer2(Query
Endpoint)
ODBC/JDBC SQL
Queries
64 ©HortonworksInc.2011– 2016.AllRightsReserved
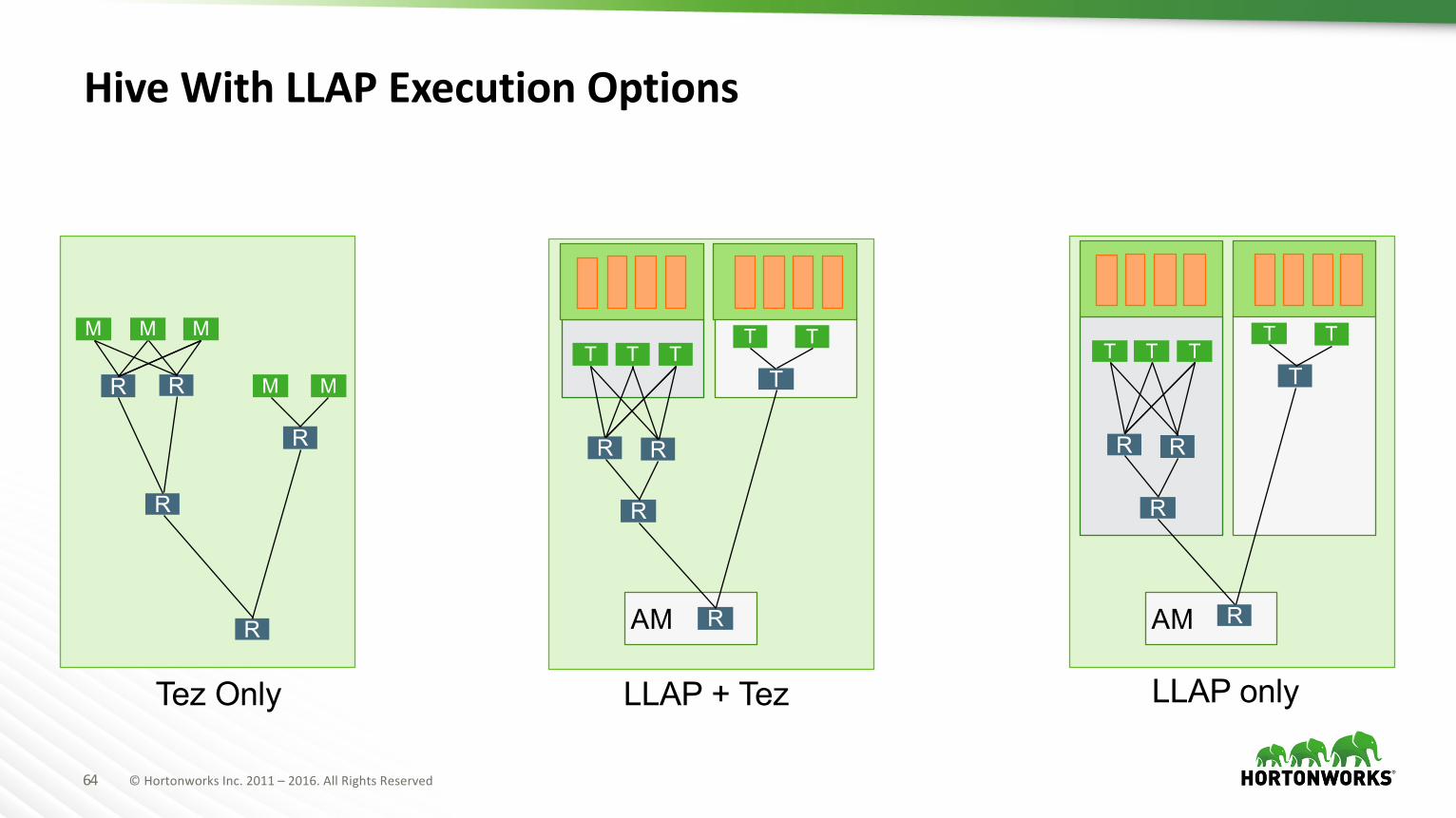
HiveWithLLAPExecutionOptions
AM AM
T T T
R R
R
T T
T
R
M M M
R R
R
M M
R
R
Tez Only LLAP + Tez
T T T
R R
R
T T
T
R
LLAP only

65 ©HortonworksInc.2011– 2016.AllRightsReserved
Scripting Data Pipeline & ETLApache Pig
• Dataflowengineandscriptinglanguage(PigLatin)• Allowsyoutotransform dataanddatasets
Advantages over MapReduce• Reducestimetowritejobs• Communitysupport• PiggybankhasasignificantnumberofUDF’stohelpadoption• TherearealargenumberofexistingshopsusingPIG
YARN:DataOperatingSystem
Interactive Real-TimeBatch

66 ©HortonworksInc.2011– 2016.AllRightsReserved
PigLatin
• Pigexecutesinauniquefashion:oDuringexecution,eachstatementisprocessedbythePiginterpreteroIfastatementisvalid,itgetsaddedtoalogicalplan builtbytheinterpreter
oThestepsinthelogicalplandonotactuallyexecuteuntilaDUMPorSTOREcommandisused

67 ©HortonworksInc.2011– 2016.AllRightsReserved
WhyusePig?
• Maybewewanttojointwodatasets,fromdifferentsources,onacommonvalue,andwanttofilter,andsort,andgettop5sites

68 ©HortonworksInc.2011– 2016.AllRightsReserved
Resource Management
Storage
Elegant Developer APIsDataFrames, Machine Learning, and SQL
Made for Data ScienceAll apps need to get predictive at scale and fine granularity
Democratize Machine LearningSpark is doing to ML on Hadoop what Hive did for SQL on Hadoop
CommunityBroad developer, customer and partner interest
Realize Value of Data Operating SystemA key tool in the Hadoop toolbox
ApacheSparkenthusiasm
Applications
SparkCoreEngine
ScalaJava
Pythonlibraries
MLlib(Machinelearning)
SparkSQL*
SparkStreaming*
SparkCoreEngine
69 ©HortonworksInc.2011– 2016.AllRightsReserved
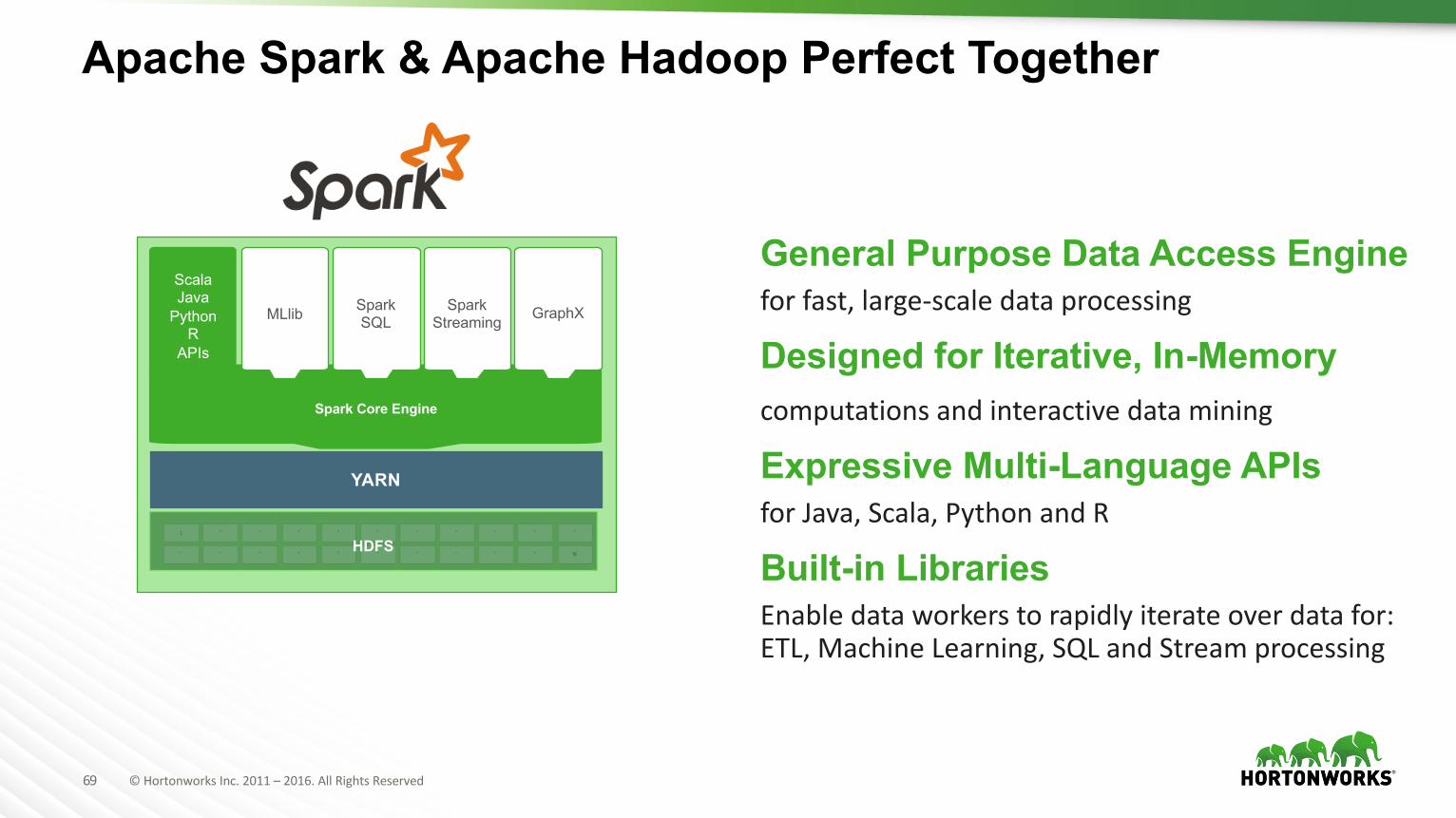
Apache Spark & Apache Hadoop Perfect Together
General Purpose Data Access Engineforfast,large-scaledataprocessing
Designed for Iterative, In-Memorycomputationsandinteractivedatamining
Expressive Multi-Language APIsforJava,Scala,PythonandR
Built-in LibrariesEnabledataworkerstorapidlyiterateoverdatafor:ETL,MachineLearning,SQLandStreamprocessing
YARN
ScalaJava
PythonR
APIs
Spark Core Engine
Spark SQL
Spark StreamingMLlib GraphX
1 ° ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° ° °
°
NHDFS
70 ©HortonworksInc.2011– 2016.AllRightsReserved
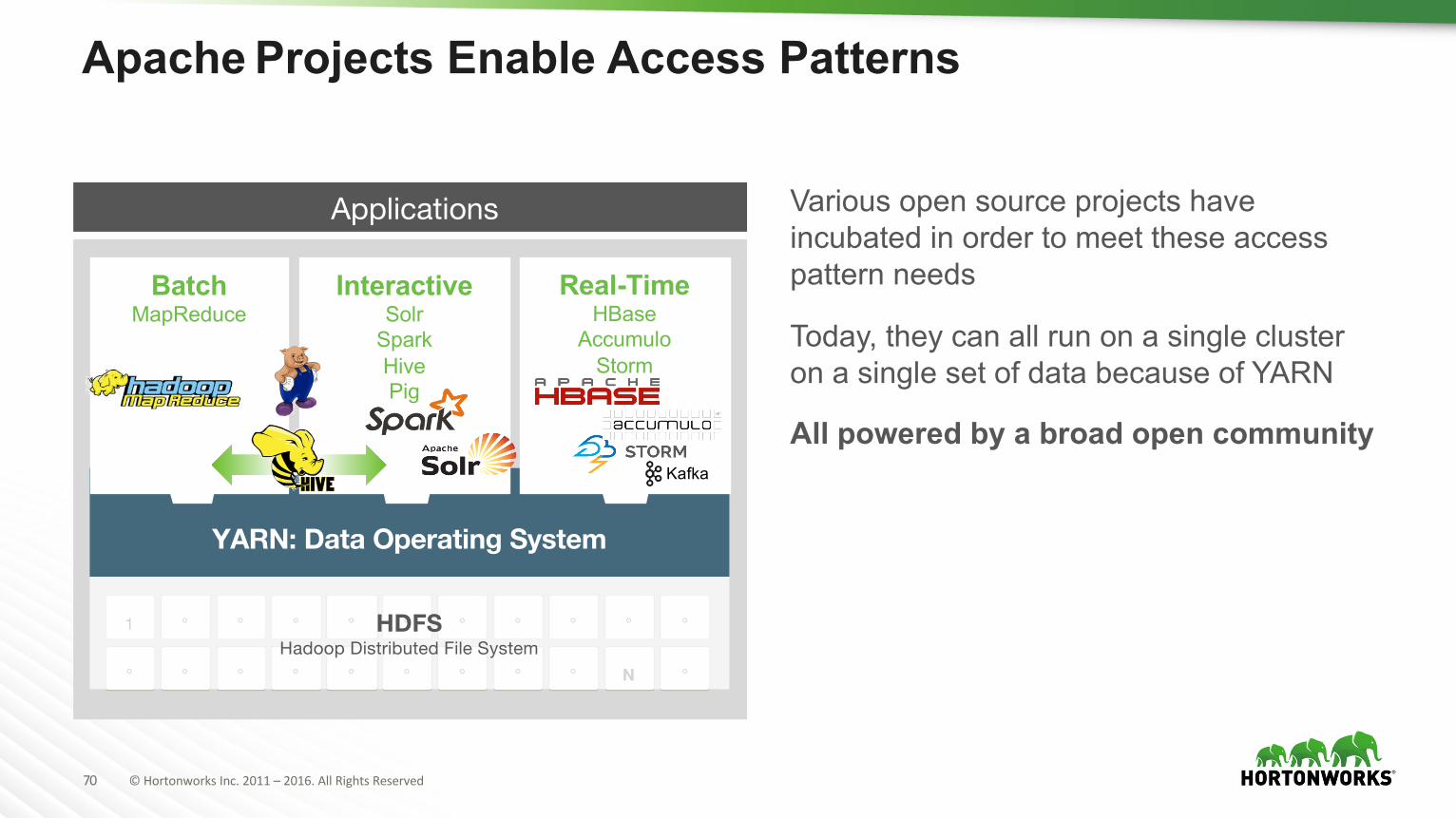
Apache Projects Enable Access Patterns
Various open source projects have incubated in order to meet these access pattern needs
Today, they can all run on a single cluster on a single set of data because of YARN
All powered by a broad open community
YARN: Data Operating System
1 ° ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° °
°
°N
HDFS Hadoop Distributed File System
InteractiveSolr
SparkHivePig
Real-TimeHBase
AccumuloStorm
BatchMapReduce
Applications
Kafka

71 ©HortonworksInc.2011– 2016.AllRightsReserved
ConnectedDataArchitecture
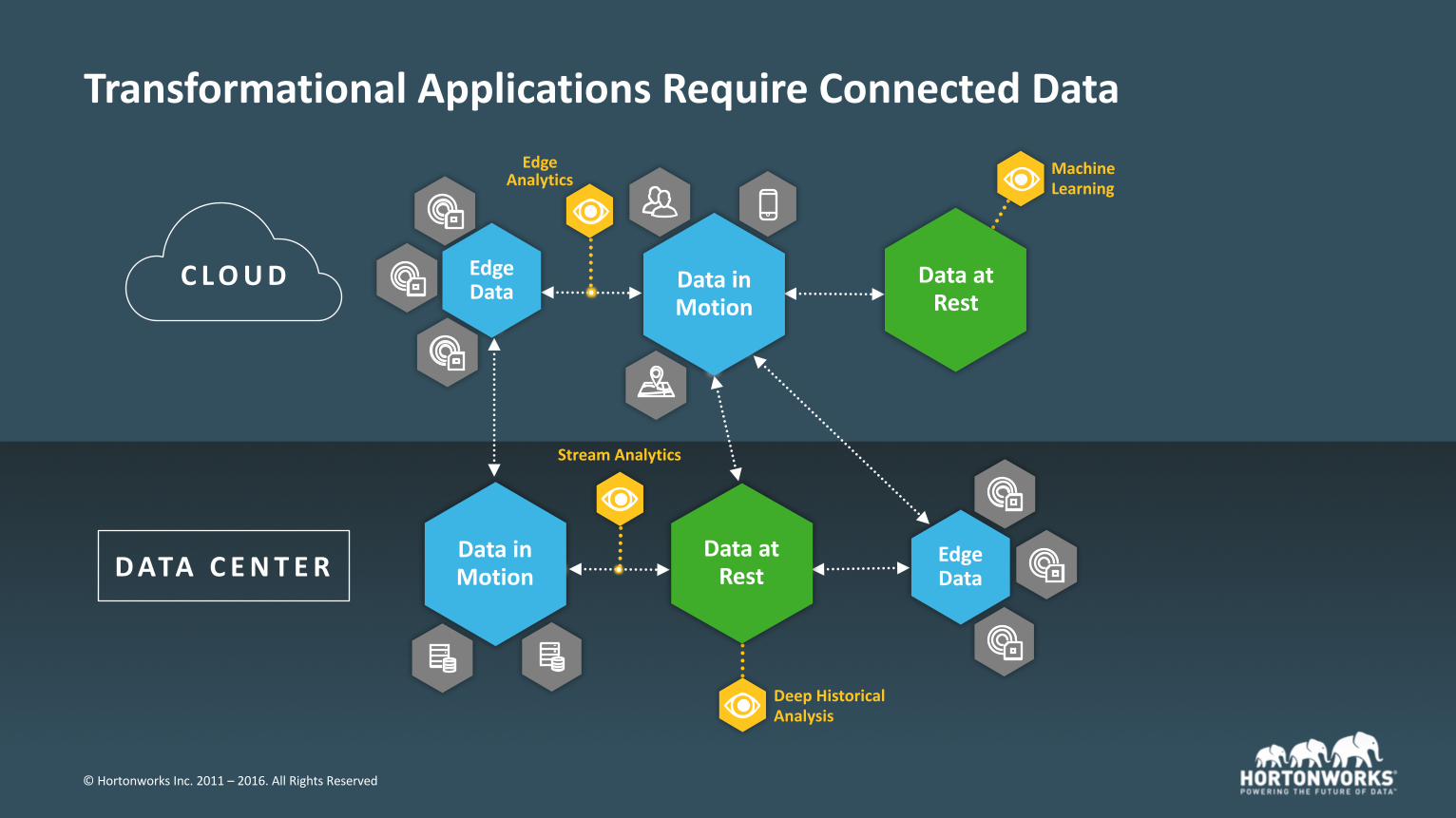
©HortonworksInc.2011– 2016.AllRightsReserved
DatainMotion
DataatRest
DeepHistoricalAnalysis
DATA C ENTER
StreamAnalytics
EdgeData
DatainMotion
MachineLearning
C LOUD EdgeData
EdgeAnalytics
DataatRest
TransformationalApplicationsRequireConnectedData
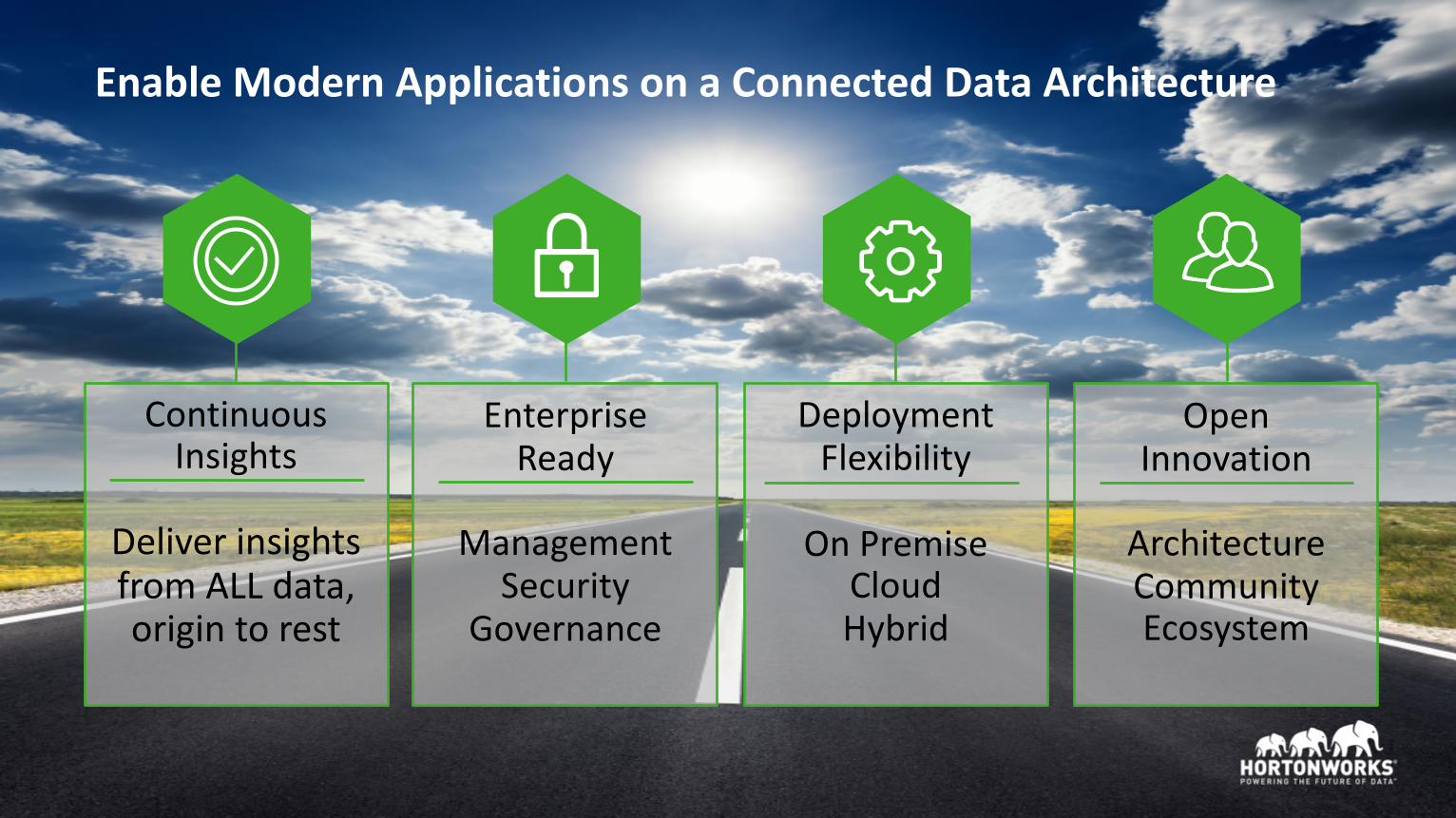
EnableModernApplicationsonaConnectedDataArchitecture
ContinuousInsights
DeliverinsightsfromALLdata,origintorest
EnterpriseReady
ManagementSecurity
Governance
DeploymentFlexibility
OnPremiseCloudHybrid
OpenInnovation
ArchitectureCommunityEcosystem

HandsonLabOverview
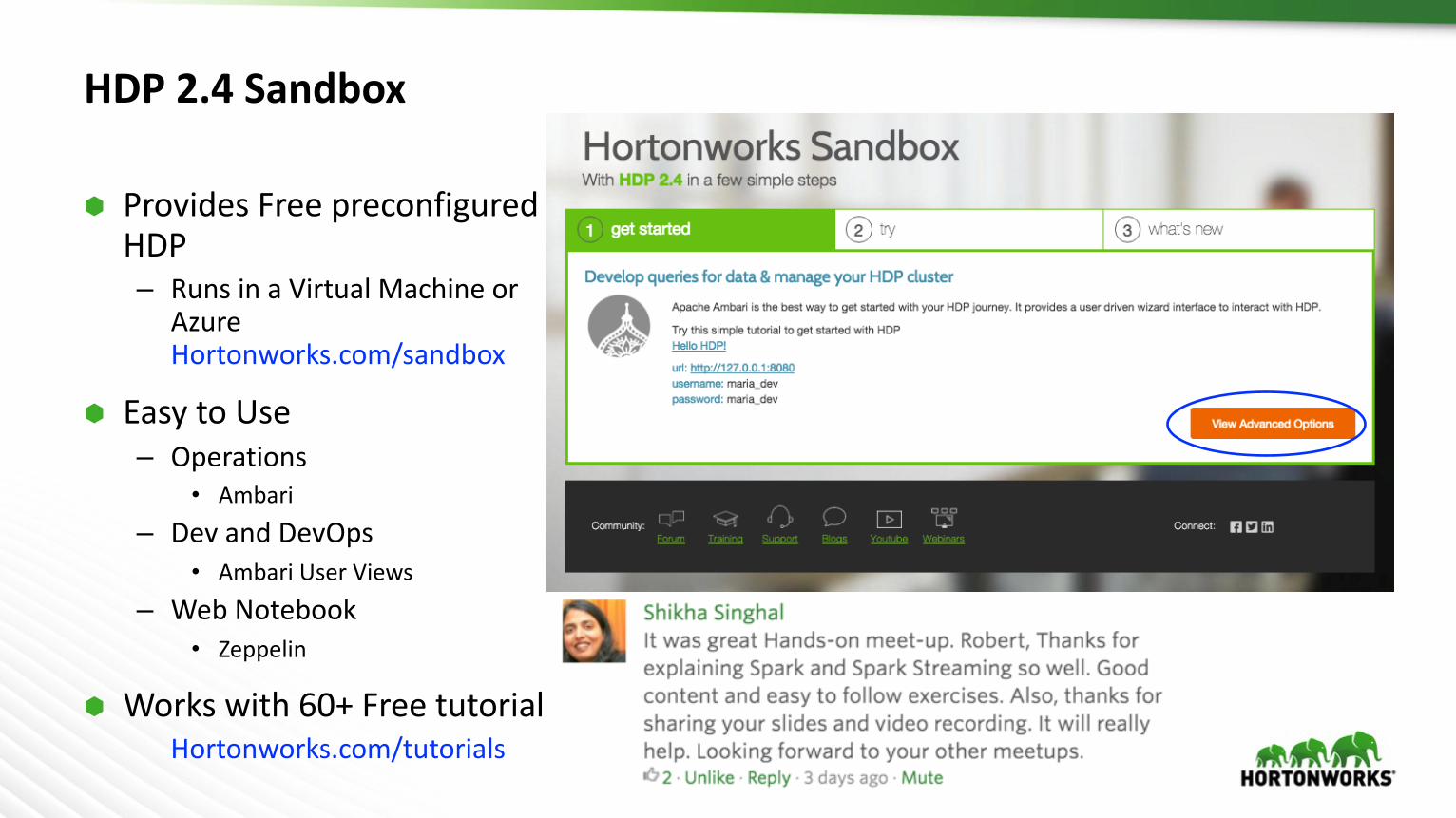
HDP2.4Sandbox
à ProvidesFreepreconfiguredHDP– RunsinaVirtualMachineor
AzureHortonworks.com/sandbox
à EasytoUse– Operations
• Ambari– DevandDevOps
• AmbariUserViews– WebNotebook
• Zeppelin
à Workswith60+FreetutorialHortonworks.com/tutorials

DataDiscoveryLab• Elefante WineCompanyhasafleetofover100trucks.
• Thegeolocationdatacollectedfromthetruckscontainseventsgeneratedwhilethetruckdriversaredriving.
• Thecompany’sgoalwithHadoopistoMitigateRisk:o Understandcorrelationsbetweenmilesdrivenandeventso Computetheriskfactorforeachdriverbasedonmileage&events
o LabEnvo Sandbox2.4
o LabDoco URL:http://goo.gl/14OAato LoadDatao QueryDatao ProcessData

Elefante Wine Current Challenges
The CompanyElefante Wine is a boutique wine fulfillment company with a large fleet of trucks. It delivers wine in a highly-regulated industry with stringent transportation requirements.
The SituationRecently a number of driver violations led to fines and increased insurance rates
The Challenges• Rising Operational Costs• Driver Safety• Risk Management• Logistics Optimization
© Hortonworks Inc. 2012 Professional Services
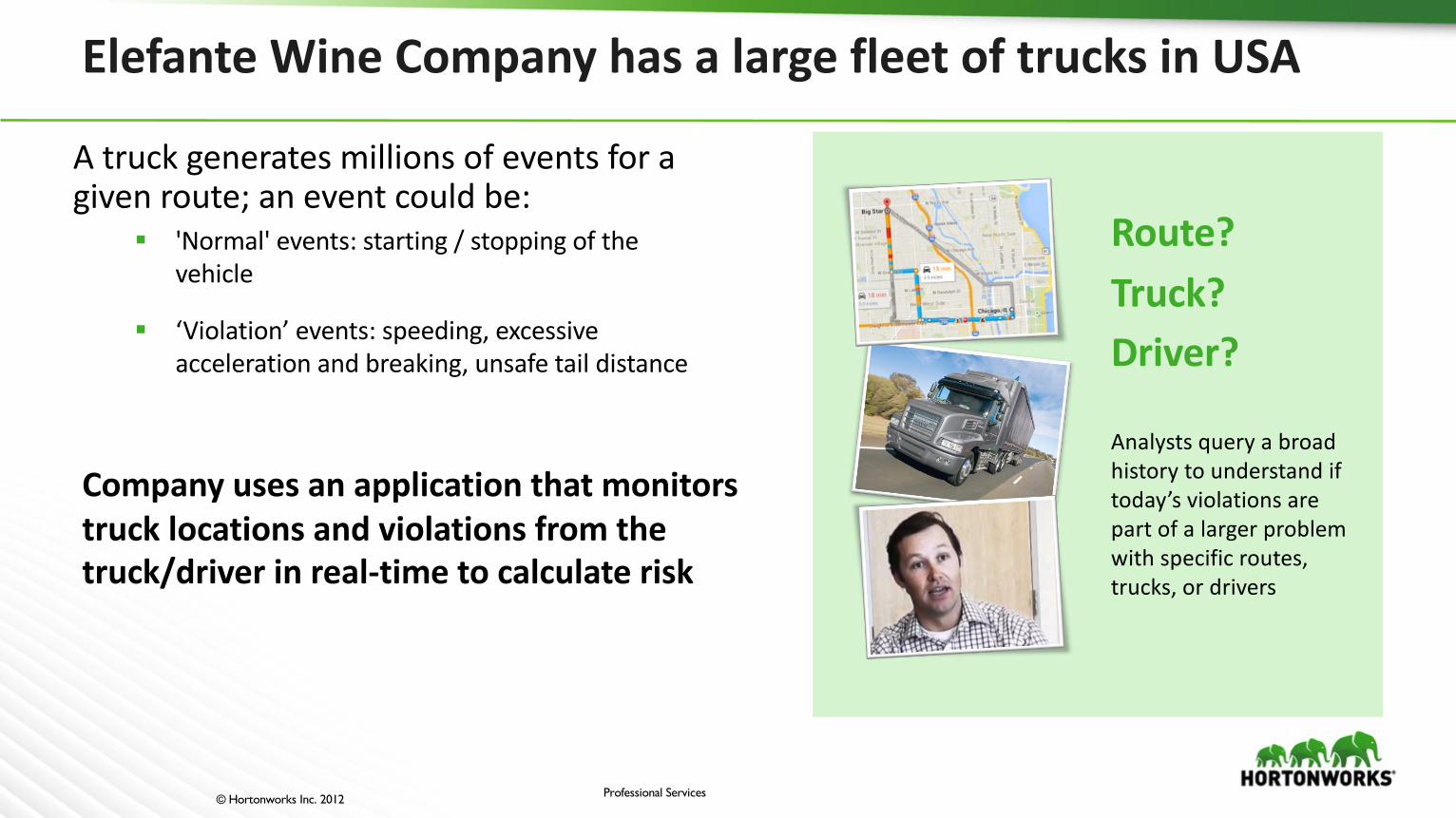
Elefante WineCompanyhasalargefleetoftrucksinUSA
Atruckgeneratesmillionsofeventsforagivenroute;aneventcouldbe:
§ 'Normal'events:starting/stoppingofthevehicle
§ ‘Violation’events:speeding,excessiveaccelerationandbreaking,unsafetaildistance
Companyusesanapplicationthatmonitorstrucklocationsandviolationsfromthetruck/driverinreal-timetocalculaterisk
Route?Truck?Driver?
Analystsqueryabroadhistorytounderstandiftoday’sviolationsarepartofalargerproblemwithspecificroutes,trucks,ordrivers
Elefante Wine Risk and Driver Safety Challenges
Trucksoutfittedwithnewsensorsgeneratinglargevolumesofnewdata:
• Location
• Speed
• DriverViolations
Needtobeintegratereal-time&historicaldata
Increase safety and reduce liabilitiesAnticipate driver violations BEFORE they happen and take precautionary actionsFindpredictivecorrelationsindriverbehavioroverlargevolumesofreal-timedata
Difficult to deliver timely insights to the right people and systems to take action
Data DiscoveryUncover new findings
Predictive Analytics Identify your next best action
Better Understandingof the Past
Better Prediction of the Future

What’sourgoal?
à Solution:– CollectadditionaldataviasensorsintruckstobetterunderstandRiskFactors
à How:– Quicklystorenewsensordatainacommonrepository– Preparethedataforanalysis– Explorethedata– CalculateRisk– Generateareport
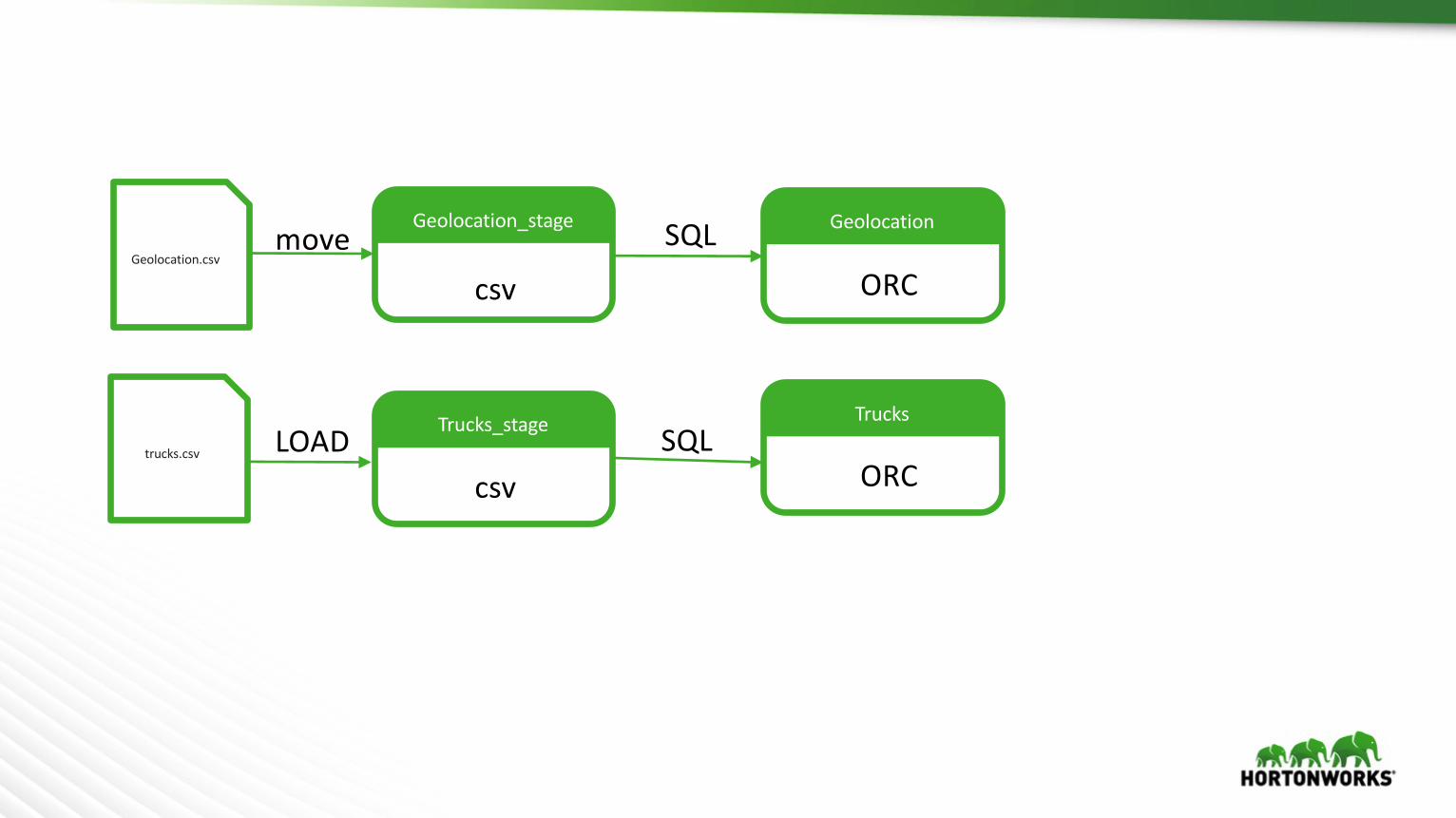
Move Data Into Hadoop
Geolocation.csv
trucks.csv
Geolocation_stage Geolocation
Trucks_stage Trucks
csv
csv ORC
ORCSQL
SQL
move
LOAD
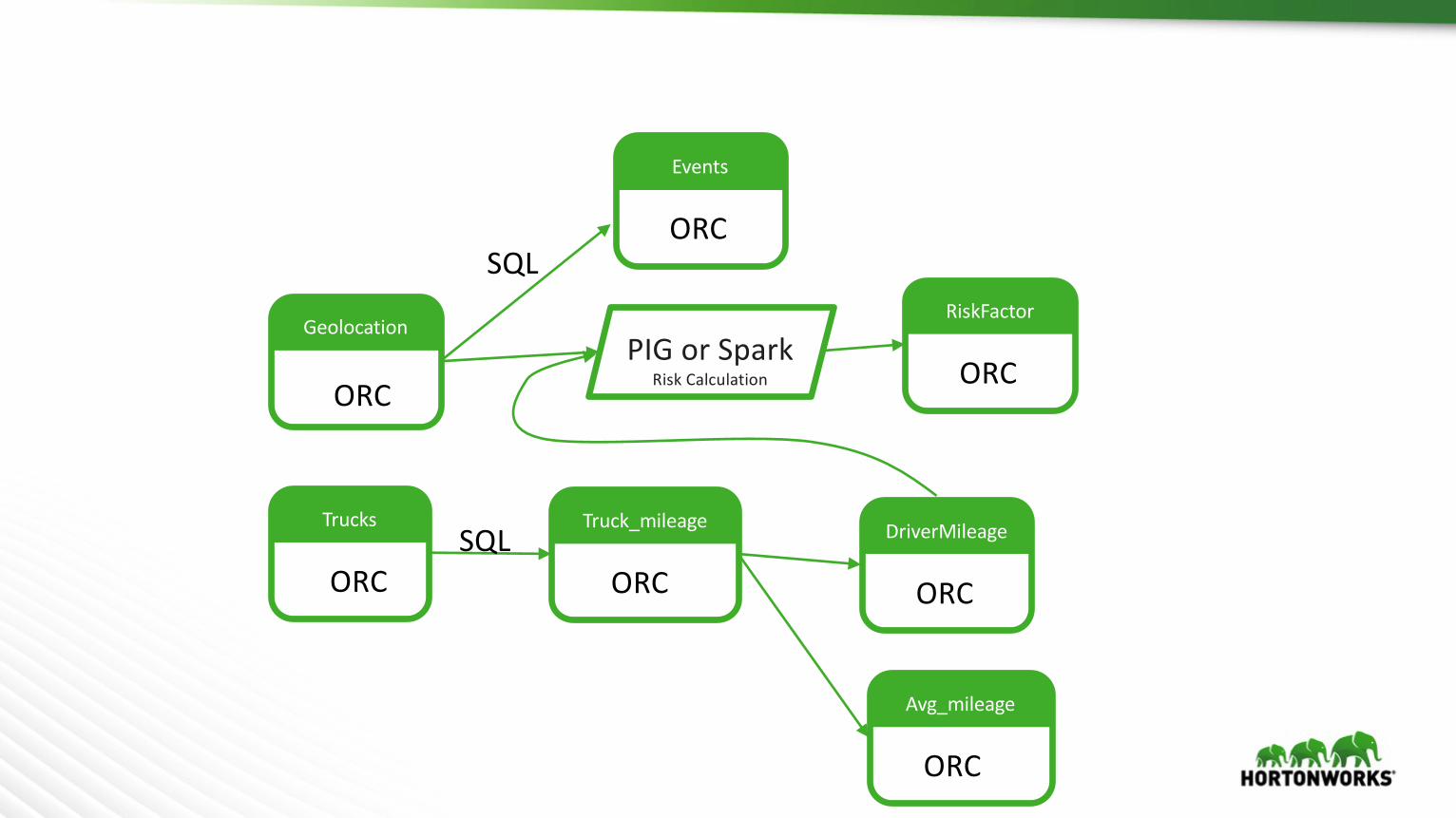
Geolocation
Trucks
ORC
ORC
SQL
SQL
PIGorSparkRiskCalculation
Truck_mileage
ORC
Avg_mileage
ORC
DriverMileage
ORC
RiskFactor
ORC
Events
ORC
Trucking Risk Analysis – Hadoop ELT
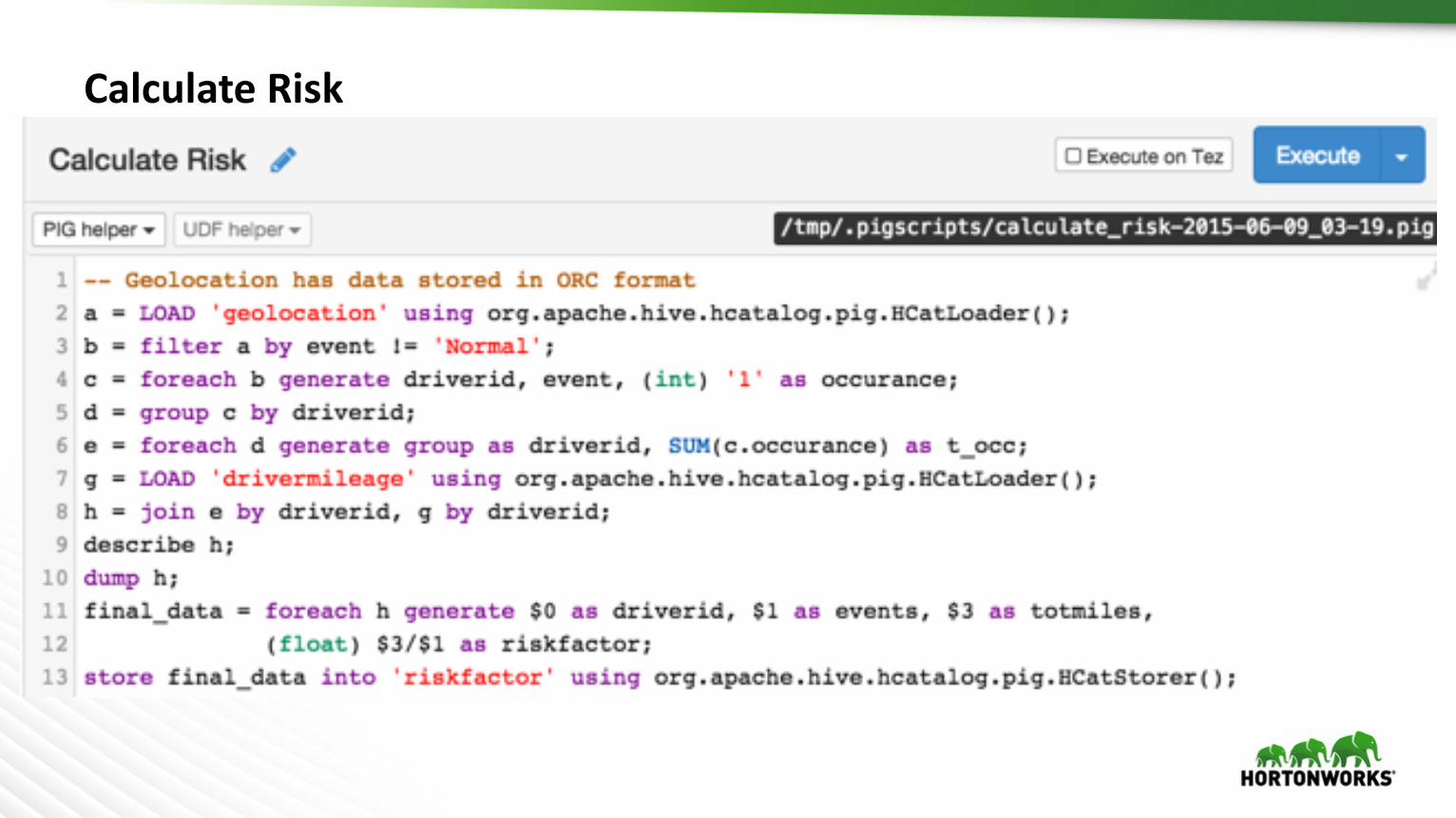
CalculateRisk

GettingStartedResources

85 ©HortonworksInc.2011– 2016.AllRightsReserved
developer.hortonworks.com
86 ©HortonworksInc.2011– 2016.AllRightsReserved
HortonworksNourishestheCommunityHORTONWORKS
COMMUN I T Y CONNECT IONHORTONWORKS PARTNERWORKS
https://community.hortonworks.com

88 ©HortonworksInc.2011– 2016.AllRightsReserved
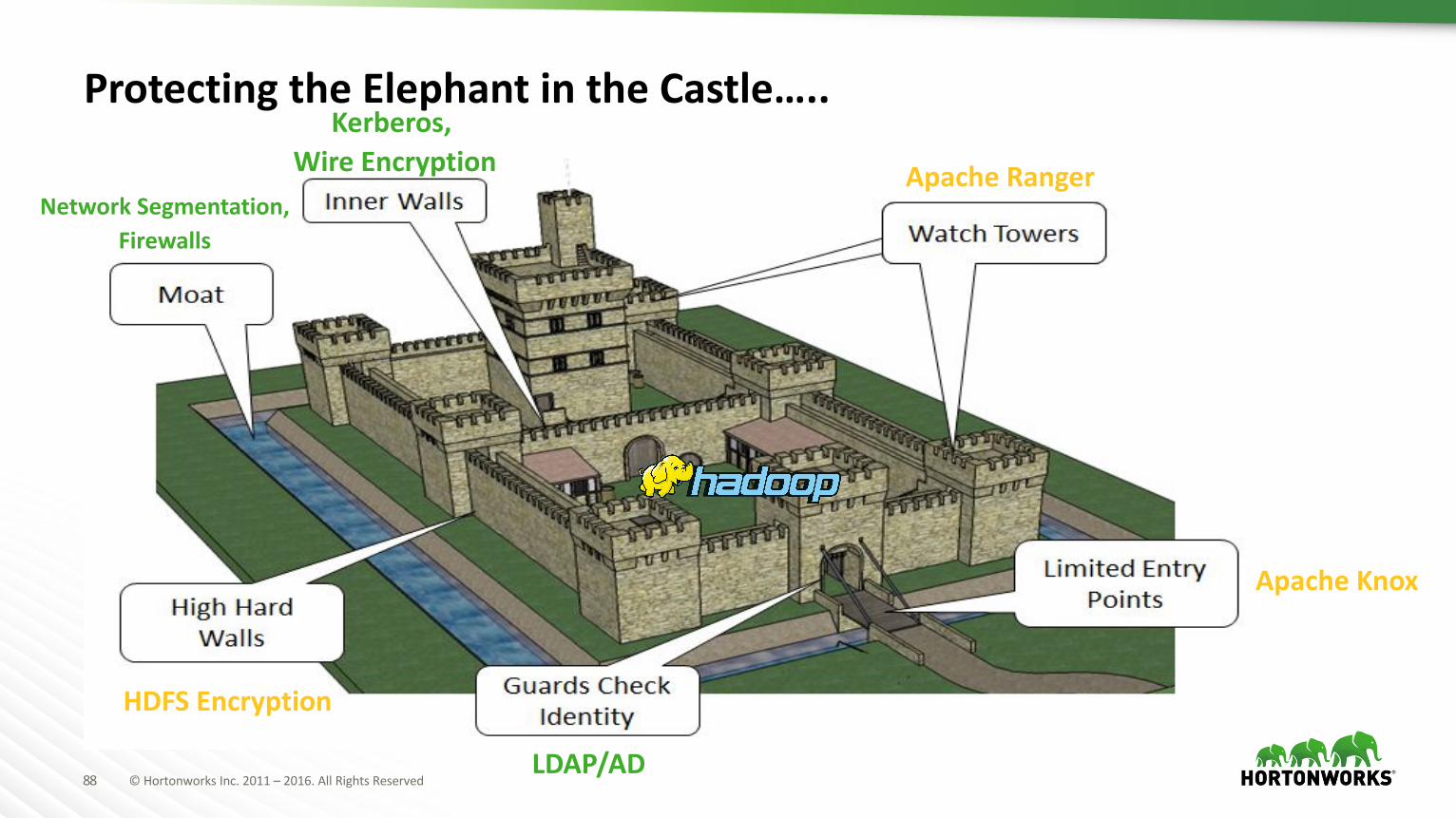
ProtectingtheElephantintheCastle…..Kerberos,
WireEncryption
HDFS Encryption
ApacheRangerNetworkSegmentation,
Firewalls
LDAP/AD
ApacheKnox