apache flink - meetupfiles.meetup.com/17066872/flinkmeetup.pdf · · 2014-10-16apache flink fast...
TRANSCRIPT


What is Apache Flink?• Project undergoing incubation in the Apache
Software Foundation
• Originating from the Stratosphere research project started at TU Berlin in 2009
• http://flink.incubator.apache.org
• 59 contributors (doubled in ~4 months)
• Has awesome squirrel logo

What is Apache Flink?
Flink Client Master'
Worker'
Worker'

Current state
• Fast - much faster than Hadoop, faster than Spark in many cases
• Reliable - does not suffer from memory problems

Outline of this talk
• Introduction to Flink
• Distributed PageRank with Flink
• Other Flink features
• Flink roadmap and closing

Where to locate Flink in the Open Source landscape?
5 5"
MapReduce"
Hive"
Flink"
Spark" Storm"
Yarn" Mesos"
HDFS"
Mahout"
Cascading"
Tez"
Pig"
Data$processing$engines$
App$and$resource$management$
Applica3ons$
Storage,$streams$ KaAa"HBase"
Crunch"
…"

Distributed data setsDataSet
A DataSet
B DataSet
C
A (1)
A (2)
B (1)
B (2)
C (1)
C (2)
X
X
Y
Y
Program
Parallel Execution
X Y
Operator X Operator Y

Log Analysis
LogFile
Filter
JoinUsers
Result
1 ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); 2 3 DataSet<Tuple2<Integer, String>> log = env.readCsvFile(logInput) .types(Integer.class, String.class); 4 DataSet<Tuple2<String, Integer>> users = env.readCsvFile(userInput) .types(String.class, Integer.class); 5 6 DataSet<String> usersWhoDownloadedFlink = log 7 .filter( 8 (msg) -> msg.f1.contains(“flink.jar”) 9 ) 10 .join(users).where(0).equalTo(1) 11 .with( 12 (msg,user,Collector<String> out) -> { 14 out.collect(user.f0); 15 } 16 ); 17 18 usersWhoDownloadedFlink.print(); 19 20 env.execute(“Log filter example”);

PageRank• Algorithm which made Google
a multi billion dollar business
• Ranking of search results
• Model: Random surfer
• Follows links
• Randomly selects arbitrary website

How can we solve the problem?
PageRankDS = { (1, 0.3) (2, 0.5) (3, 0.2) }
AdjacencyDS = { (1, [2, 3]) (2, [1]) (3, [1, 2]) }

PageRank{ node: Int rank: Double }
Adjacency{ node: Int neighbours: List[Int] }


case class Pagerank(node: Int, rank: Double) case class Adjacency(node: Int, neighbours: Array[Int]) ! def main(args: Array[String]): Unit = { val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment ! val initialPagerank:DataSet[Pagerank] = createInitialPagerank(numVertices, env) val adjacency: DataSet[Adjacency] = createRandomAdjacency(numVertices, sparsity, env) ! val solution = initialPagerank.iterate(100){ pagerank => val partialPagerank = pagerank.join(adjacency). where(“node”). equalTo(“node”). flatMap{ // generating the partial pageranks pair => { val (Pagerank(node, rank), Adjacency(_, neighbours)) = pair val length = neighbours.length neighbours.map{ neighbour=> Pagerank(neighbour, dampingFactor*rank/length) } :+ Pagerank(node, (1-dampingFactor)/numVertices) } } ! // adding the partial pageranks up partialPagerank. groupBy(“node”). reduce{ (left, right) => Pagerank(left.node, left.rank + right.rank) } ! } solution.print() env.execute("Flink pagerank.") }
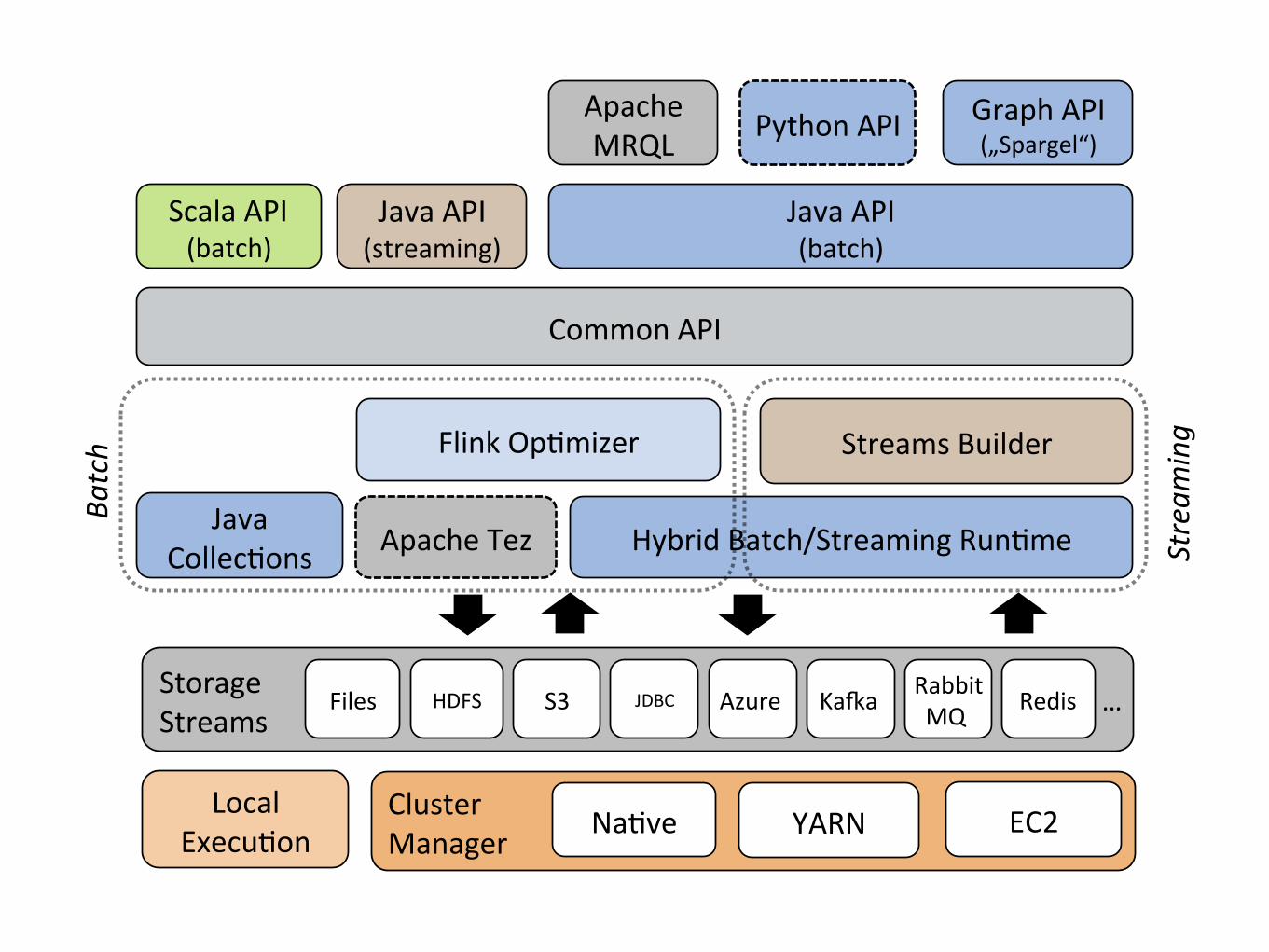
Common%API%
Storage%Streams%
Hybrid%Batch/Streaming%Run;me%
HDFS%!Files%! S3!
Cluster%Manager%! YARN%! EC2%!Na;ve!
Flink%Op;mizer%
Scala%API%(batch)%
Graph%API%(„Spargel“)%
JDBC! Redis%!Rabbit%MQ!KaRa!Azure! …%
Java%Collec;ons%
Streams%Builder%
Apache%Tez%
Python%API%
Java%API%(streaming)%
Apache%MRQL%
Batch!
Stream
ing!
Java%API%(batch)%
Local%Execu;on%
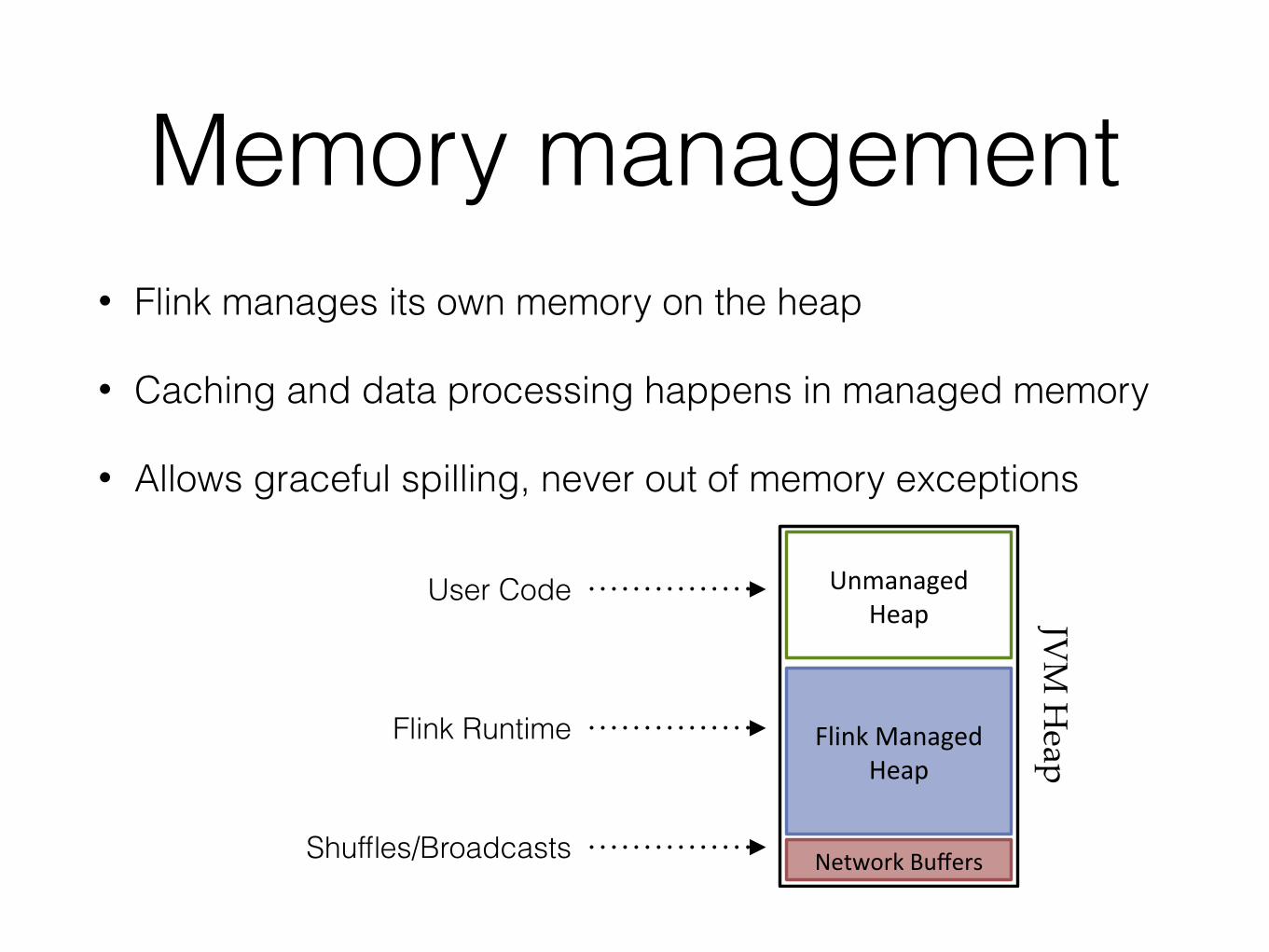
Memory management• Flink manages its own memory on the heap
• Caching and data processing happens in managed memory
• Allows graceful spilling, never out of memory exceptions
JVM$H
eap)
Flink&Managed&Heap&
Network&Buffers&
Unmanaged&Heap&
User Code
Shuffles/Broadcasts
Flink Runtime

Hadoop compatibility• Flink supports out of the box
• Hadoop data types (Writables)
• Hadoop input/output formats
• Hadoop functions and object model
Input& Map& Reduce& Output&
DataSet DataSet DataSet Red Join
DataSet Map DataSet
Output&S
Input&

Flink StreamingExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); !DataSet<Tuple2<String, Integer>> result = env .readTextFile(input) .flatMap(sentence -> asList(sentence.split(“ “))) .map(word -> new Tuple2<>(word, 1)) .groupBy(0) .aggregate(SUM, 1);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); !DataStream<Tuple2<String, Integer>> result = env .readTextFile(input) .flatMap(sentence -> asList(sentence.split(“ “))) .map(word -> new Tuple2<>(word, 1)) .groupBy(0) .sum(1);
Word count with Java API
Word count with Flink Streaming
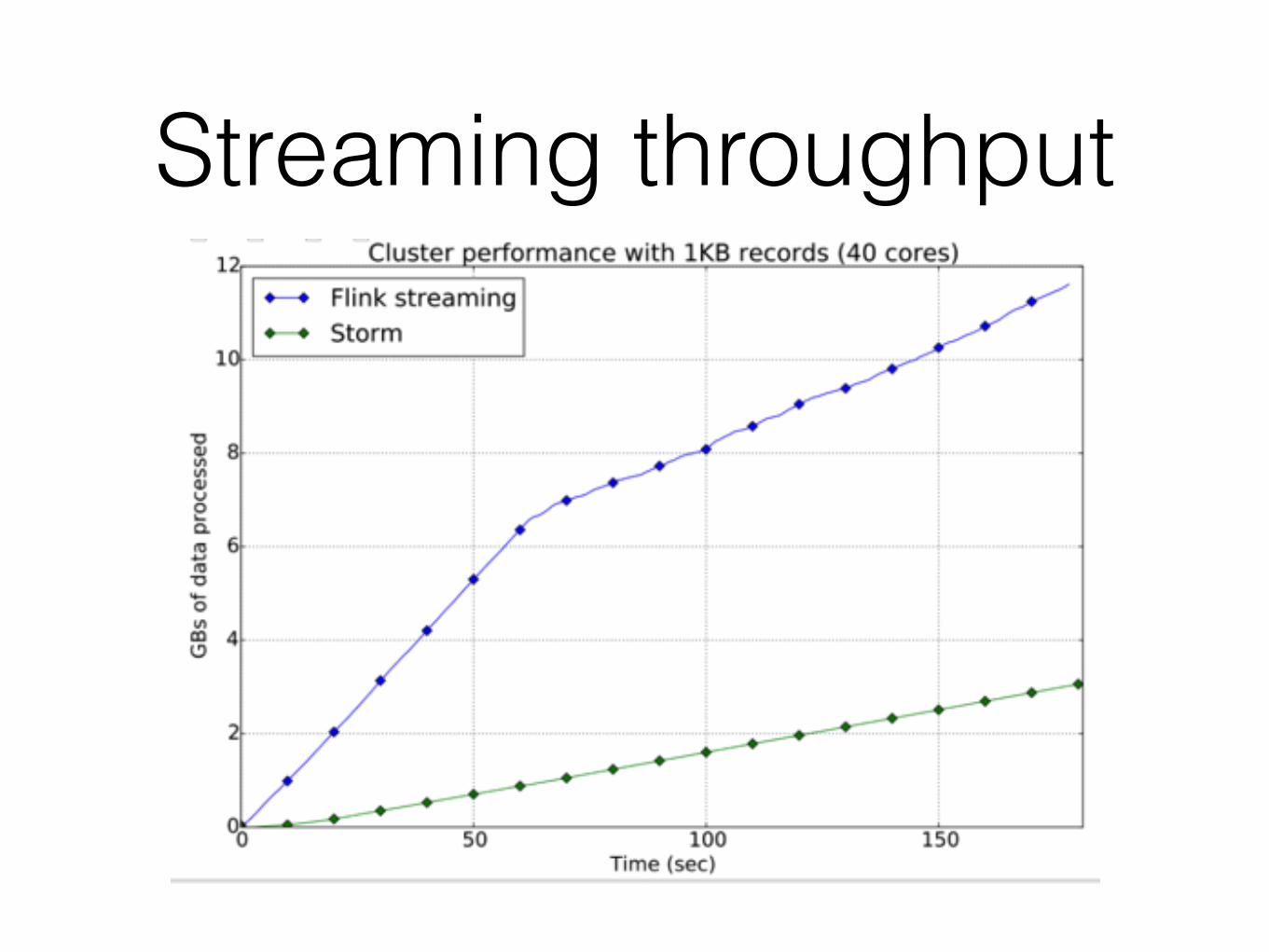
Streaming throughput

Write once, run everywhere!
Cluster((Batch)(Cluster((Streaming)(
Local(Debugging(
Flink&Run)me&or&Apache&Tez&
As(Java(Collec;on(Programs(
Embedded((e.g.,(Web(Container)(
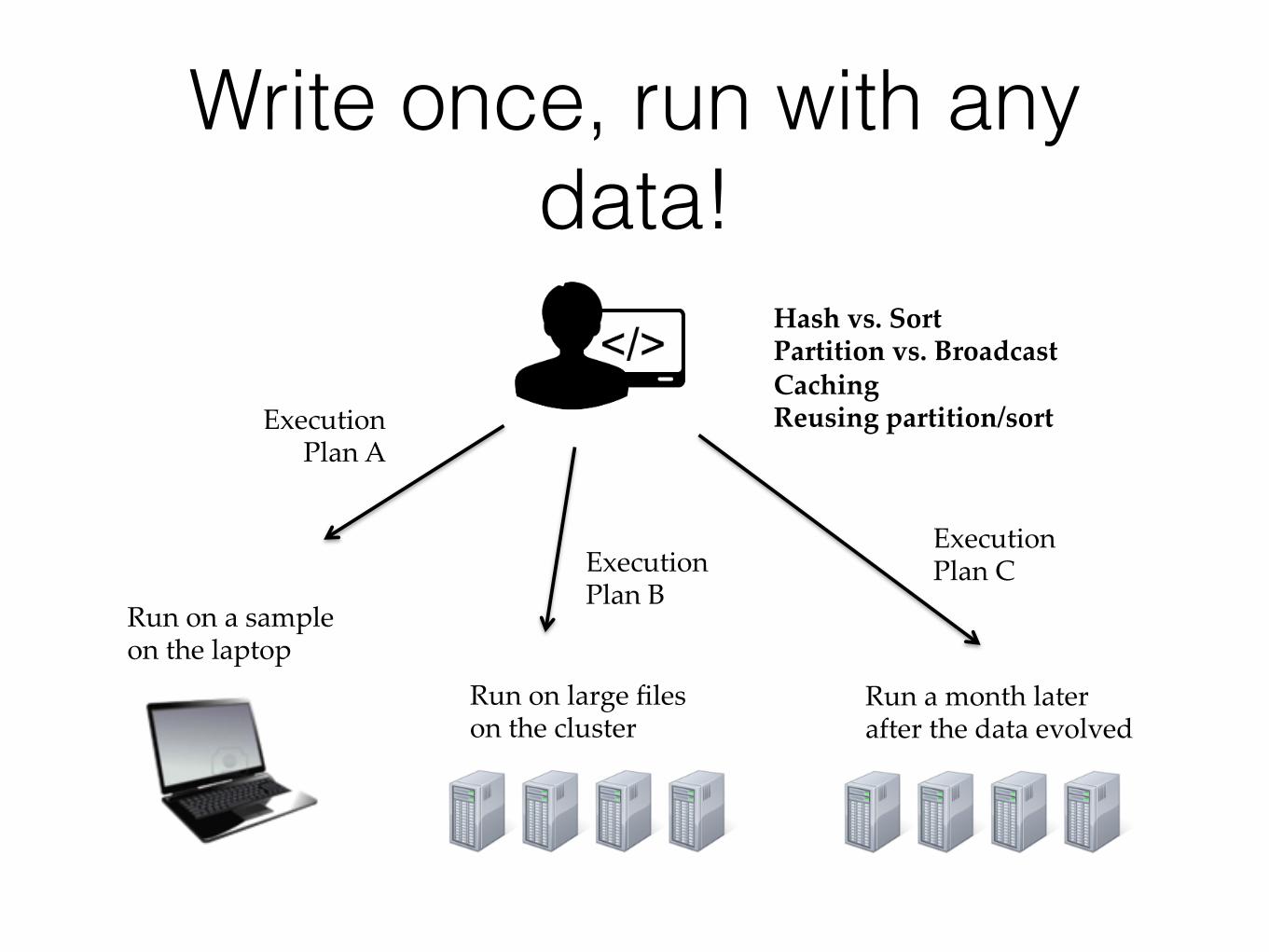
Write once, run with any data!
Run$on$a$sample$on$the$laptop.
Run$a$month$later$after$the$data$evolved$.
Hash%vs.%Sort,Partition%vs.%Broadcast,Caching,Reusing%partition/sort,Execution$
Plan$A.
Execution$Plan$B.
Run$on$large$files$on$the$cluster.
Execution$Plan$C.

Little tuning required
• Requires no memory thresholds to configure
• Requires no complicated network configs
• Requires no serializers to be configured
• Programs adjust to data automatically

Flink roadmap• Flink has a major release every 3 months
• Finer grained fault-tolerance
• Logical (SQL-like) field addressing
• Python API
• Flink Streaming, Lambda architecture support
• Flink on Tez
• ML on Flink (Mahout DSL)
• Graph DSL on Flink
• … and much more

http://flink.incubator.apache.org !
github.com/apache/incubator-flink !
@ApacheFlink