andrew nagy, serials solutions scott garrison, western michigan university
TRANSCRIPT

Andrew Nagy, Serials SolutionsScott Garrison, Western Michigan University

Master’s level private Catholic university
Undergrad enrollment = ~6,000One main library
~850,000 bibliographic records
~300 subscription databases
Voyager, SFX, MetaLib

Carnegie research universityUndergrad enrollment = 25,000+5 libraries serving multiple sites
statewide 1.6M+ bibliographic records 400+ databases 4,500+ print journals 42,000+ online journals
Voyager, SFX, CONTENTdm, Luna


Hasn’t kept up with Web, users’ expectations
Limited customization
Antiquated, rigid search technologies
Designed for known-item searching
Libraries have set expectations, learned to compensate accordingly

More every year in multiple packages
More alternatives, more confusion
Multiple A-Z lists to maintain, use
Interfaces change regularly
Query syntax varied, requires instruction???
“The version of ______ I teach is _______”
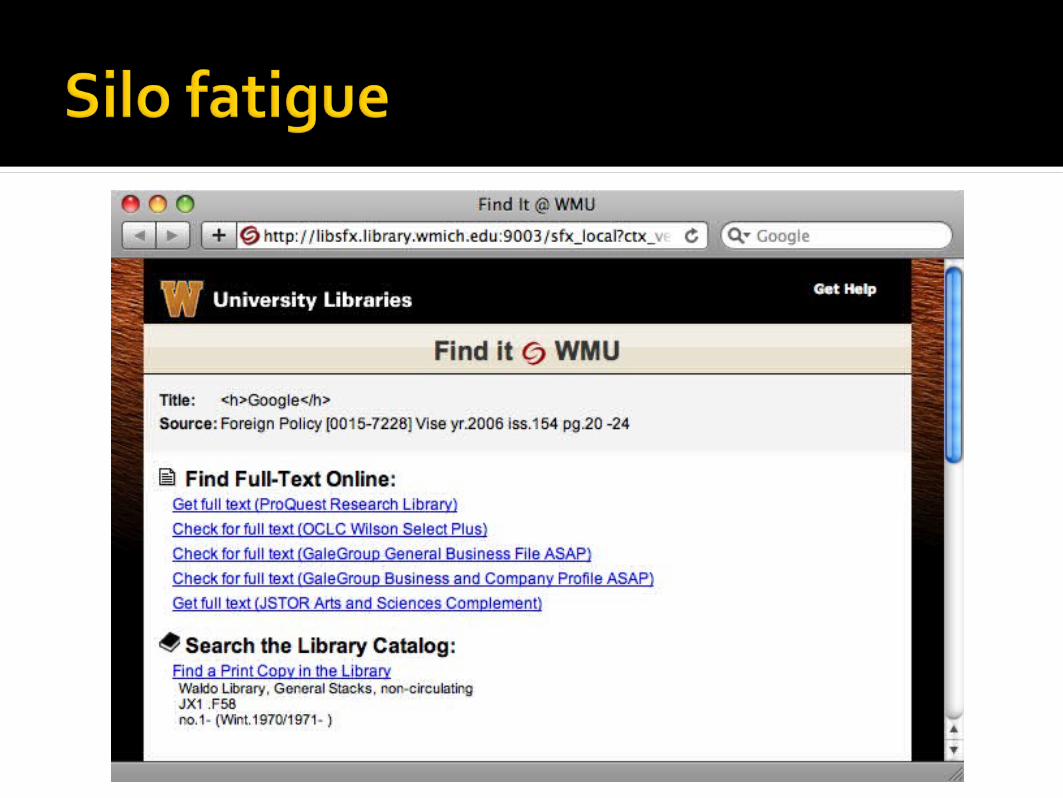

Allows some general, discipline searching
Mixed, incomplete results
As slow as the slower silos
If local, very network-inefficient
Many different metadata schemas, less sophisticated searching

Vendor acquisitions, consolidation, catch-up
Open source options are emerging
Some products are still years away
All of the above leads to great FUD

dis⋅cov⋅er [di-skuhv-er]–verb (used with object)
1. to see, get knowledge of, learn of, find, or find out; gain sight or knowledge of (something previously unseen or unknown): to discover America; to discover electricity.2. to notice or realize: I discovered I didn't have my credit card with me when I went to pay my bill.3. Archaic. to make known; reveal; disclose.

Searching for the 21st century
Built on 21st century technology
Highly configurable interfaces
Puts our metadata to better use
Works for OPAC and other silos but relies on federated search, though evolving

Broad discovery of both known and unknown items in our collections, not just in their discipline
Be more like Google: simple, easy, fast fewer places to look for more kinds of content big recall is OK as long as most relevant is first get to the actual item in fewest clicks possible


Provides simple, easy access to the library’s local collections
Supplements “classic” OPAC
Refines searches with “facets”
Includes external sources and community features Wikipedia, tagging

Open source VuFind Blacklight eXtensible Catalog built on Lucene/Solr/Drupal
Commercial AquaBrowser WorldCat Local Primo Encore Endeca

Mellon Award for Technology Collaboration winner 2008!
ILS-agnostic, runs alongside OPACWorks for libraries of all sizesUses Apache Solr and AJAXFeature rich
text messaging, Wikipedia author biographies, tagging and commenting, public lists

alpha fall 2008, beta spring 2009, “1.0” fall 2009
Customized the source in a variety of ways
SolrMARC importer, Voyager driver
search definitions, indexes, facet display
Usability tested 2008-2009
Still tweaking our indexes, relevance
“1.2” version coming spring 2010

Has helped us around limitations in Voyager
Recall => huge adjustment for librarians Has prompted us to reconsider how we
workThemes from usability testing
fewer failed searches user less likely to give up searching users curious about things like tagging



Librarians, users will use Amazon to find and discover will use Google to find and discover will use del.icio.us to find and discover
Then they use the library catalog/website to find out if the library has it (link resolver buttons help even if it’s in five silos)

Local index of collections: MARC, OAI, etc.Simple, elegant interfacesCustomizableMashupsTuned relevancy rankingFacetsCitation management toolsLinks to value-adds like ILL,
recommenders

Why only local collections?
What about article content?
What if users want to discover items outside their discipline-specific databases?
Can’t we do better than federated search?


Web-scale dis⋅cov⋅er [web skeyl di-skuhv-er]- adjective-noun pairing
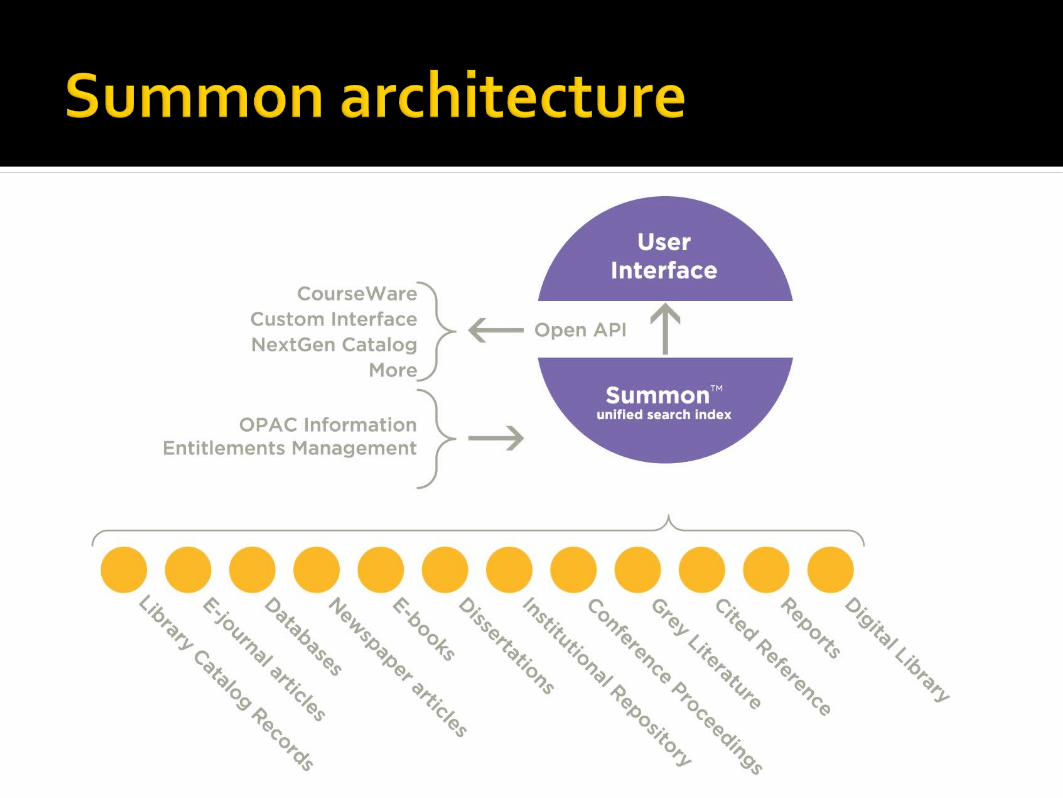
Harvesting, ingesting, and normalizing an extensive amount of container and subcontainer metadata in a scalable infrastructure that many institutions can share rather than traditional “hosted services”.

Unifies local and subscription content digital or physical books, e-journal articles,
databases, etc. library catalog, publishers, open access, etc.
Web-scale repositoryHighly tuned relevancyPluggable API for “shopping mall”
access

March 2009: became beta partnerApril 2009: delivered catalog recordsMay 2009: had Summon instance June 2009: used internally, refined e
holdingsSummer 2009: kept improvingSeptember 2009: linked to it on our siteFall 2009: user testing


Even bigger adjustment for library staffHas reminded us of record problemsShows known OpenURL target problemsHow to present it along with VuFind?
the NGC is a subset of the W-sD we’ve already tweaked the NGC pretty far W-sD’s interface is similar to NGC how to incorporate link resolver data?

Keep the NGC for containers and W-sD for everything else use limits in query string to exclude
containers means two separate, different interfaces
to choose from



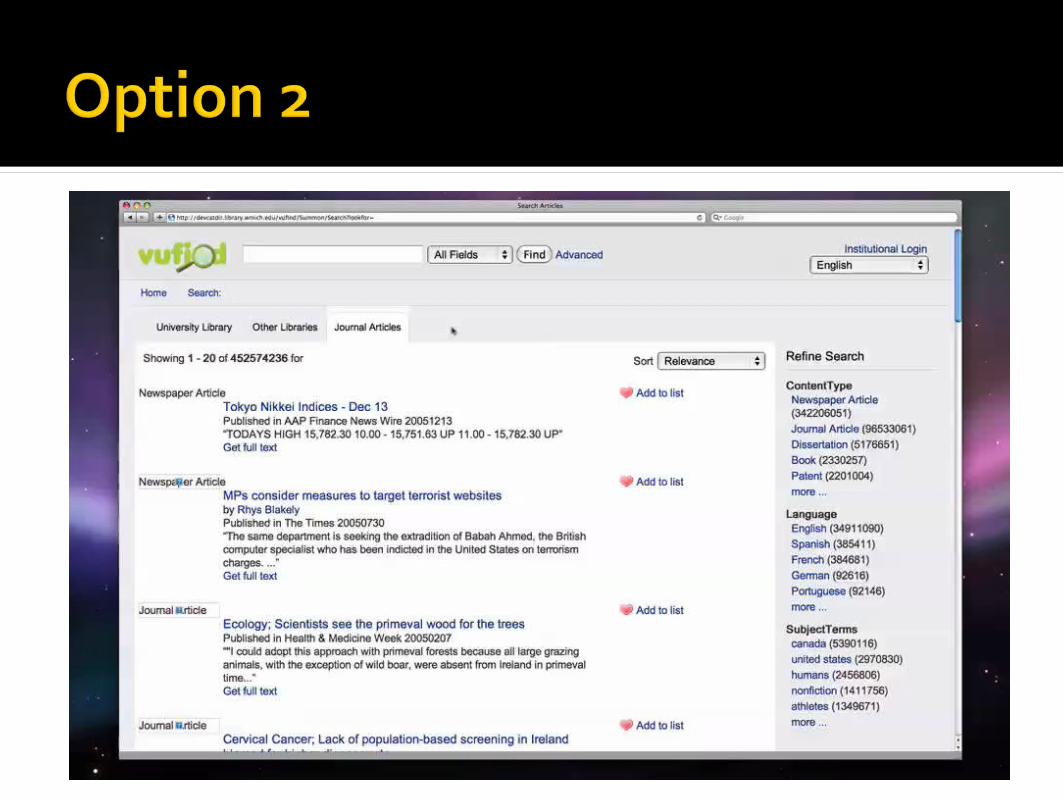
Use your NGC’s interface to query the W-sD’s index radio button for containers vs. non? unified results, or tabs? limits you to NGC’s interface? Toggle? opportunity to tweak the NGC closer to
W-sD subjects and other facets likely vary
between them

Use only the W-sD and scrap the NGC impractical after heavy NGC investment
and adjustment

Use the APIs you have for the NGC, W-sD, and link resolver and build your own mashup of all of them requires a heavy investment of resources involves merging functional requirements
for three separate systems into one requires very careful project
management, keeping scope creep, long tail issues to a minimum
