analizzare e gestire flussi di dati in tempo reale - amazon s3 · pdf fileanalizzare e gestire...
TRANSCRIPT

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Milano, 14 Aprile 2016
Analizzare e gestire flussi di dati in tempo reale
Michele Alessandrini, Solutions Architect, AWS
Francesco Furiani, CTO, ClickMeter

Streaming Data Scenarios Across Industries

Real-Time Analytics
Real-time Ingest
• Highly Scalable
• Durable
• Elastic
• Replay-able Reads
Continuous Processing
• Load-balancing incoming streams
• Fault-tolerance, Checkpoint / Replay
• Elastic
• Enable multiple apps to process in parallel
Continuous data flow
Low end-to-end latency
Continuous, real-time workloads
+

Two main processing patterns
Stream processing (real time)• Real-time response to events in data streams
Examples:• Proactively detect hardware errors in device logs
• Notify when inventory drops below a threshold
Micro-batching (near real time)• Near real-time operations on small batches of events in data streams
Examples:• Identify fraud from activity logs
• Monitor performance SLAs

Common Streaming Data Design Pattern
EMR
Spark Streaming
Redshift
S3 CSV
Data Pipeline
S3 Raw
Kinesis
Streams
ingest
batch
streaminvocation
Lambda Firehose
Clients
Clients
BI Tools
SQS
S3 ParquetWeb
Frontend on
Elastic Beanstalk
DP Activity 1
LOAD/MERGE
Clients
Presto/Hive

Common Micro-batching Data Design Pattern
Redshift
S3 Raw
ingest
batch
streaminvocation
FirehoseClients
Clients
BI Tools
S3 ProcessedWeb
Frontend on
Elastic Beanstalk
Clients
Presto/Hive
EMR EMR
Elastic
Search
Clients
Search

Client-side SDKs/ Mobile Device Logs
Gaming telemetry from Servers
User engagement Metrics
Attribution partners
Other 3rd parties
Glu Mobile: Streaming Data in Gaming

Glu’s Streaming Data Architecture
4-6 MM Daily Actives
1 B+ Global Installs
700MM to 2B+ Events per day
600 bytes/ event
1-2TB/ day
47
Shards[4] C4.2XL, [2]
M3.Large (ZK), [1]
M3.Xlarge (Nimbus)

Sonos Connected Devices
Firmware Device Logs
Application Telemetry
Music Service Usage Metrics
Cloud Applications Logs
Performance Indicators

Sonos’ Streaming Data Architecture
Collect Store Process Consume
100K+ device
Install base
1.5 B Events
3 TB/ day
25 Shards
2KB / event
[5] C4.2XL
KCL

Ad exchanges
Re-targeting platforms
RTB Platforms
Publishers
DataXu: Real-time Ad Tech

DataXu’s Streaming Data
Architecture
303M Events
12 TB/ Week
100 Shards
42KB / event
6.5 M Events
0.5 TB/ Week
41 Shards
86KB / event

“…Alert me when the Internet is Down…”/ Keith Homewood, Nordstorm
Nordstrom's Online Stylist

Amazon Kinesis Deep Dive

Amazon Kinesis: Streaming Data Platform on AWS
• Pay as you go, no up front costs
• Elastically scalable
• Choose the service, or combination of
services, for your specific use cases.
• Real-time latencies
Deploy • Easy to provision, deploy, and manage

Amazon Kinesis
Streams
• For Technical Developers
• Build your own custom
applications that process
or analyze streaming
data
• GA at re:Invent 2013
Amazon Kinesis
Firehose
• For all developers, data
scientists
• Easily load massive
volumes of streaming data
into S3 and Redshift
• GA at re:Invent 2015
Amazon Kinesis
Analytics
• For all developers, data
scientists
• Easily analyze data
streams using standard
SQL queries
• Coming soon
Amazon Kinesis: Streaming Data Made EasyServices make it easy to capture, deliver and process streams on AWS

Data Sources
App.4
[Machine Learning]
AW
S En
dp
oin
t
App.1
[Aggregate & De-Duplicate]
Data Sources
Data Sources
Data Sources
App.2
[Metric Extraction]
S3
Redshift
App.3[Sliding Window Analysis]
Availability
Zone
Shard 1
Shard 2
Shard N
Availability
ZoneAvailability
Zone
Amazon Kinesis StreamsManaged Service for Real-Time Streaming
Lambda
EMR

Sending & Reading from Kinesis Streams
AWS SDK
LOG4J
Flume
Fluentd
Get* APIs
Kinesis Client Library
+
Connector Library
Apache Storm
Amazon Elastic
MapReduce
Sending Consuming
AWS Mobile
SDK
Kinesis
Producer
Library
AWS Lambda
Apache Spark

• Streams are made of Shards
• Each Shard ingests data up to 1MB/sec,
and up to 1000 TPS
• Each Shard emits up to 2 MB/sec
• All data is stored for 24 hours
• Extend data retention
• Scale Kinesis streams using scaling util
• Replay data inside of 24Hr. Window
Amazon Kinesis StreamsManaged ability to capture and store data

Simple Put Interface to put Data in Amazon
Kinesis Producers use a PUT call to store data in a
Stream. Each record <= 1 MB
PutRecord {Data,StreamName,PartitionKey}
PutRecords {Records{Data,PartitionKey}, StreamName}
A Partition Key is supplied by producer and used to
distribute (MD5 hash) the PUTs across (hash key range)
of Shards
A unique Sequence # is returned to the Producer upon
a successful PUT call
Putting Data into Amazon Kinesis Streams

Streaming Data Ingestion

Putting Data into Amazon Kinesis Streams
Determine your Partition Key strategy• Managed buffer or a streaming MapReduce• Ensure High Cardinality for your shards
Provision Adequate Shards• For ingress needs• Egress needs for all consuming applications: if more
than 2 simultaneous applications• Include head-room for catching up with data in stream

Record Order and Multiple Shards
Unordered processing
• Randomize partition key to distribute events over many shards and use multiple workers
Exact order processing
• Control the partition key to ensure events are grouped onto the same shard and read by the same worker.
Need both? Get global sequence number
Producer
Get Global
SequenceUnordered
Stream
Campaign Centric
Stream
Fraud Inspection
Stream
Get Event
Metadata

Scaling Amazon Kinesis Shards
https://github.com/awslabs/amazon-kinesis-scaling-utils
Options: • stream-name - The name of the Stream to be scaled
• scaling-action - The action to be taken to scale. Must be one of "scaleUp”, "scaleDown" or “resize”
• count - Number of shards by which to absolutely scale up or down, or resize to or:
• pct - Percentage of the existing number of shards by which to scale up or down
java -cp
KinesisScalingUtils.jar-complete.jar
-Dstream-name=MyStream
-Dscaling-action=scaleUp
-Dcount=10
-Dregion=eu-west-1 ScalingClient

Putting Data in Amazon Kinesis
Amazon Kinesis Agent• http://docs.aws.amazon.com/firehose/latest/dev/writing-with-agents
.html
Pre-batch before Puts for better efficiency• Consider Flume,FLuntD as collectors/agents
https://github.com/awslabs/aws-fluent-plugin-kinesis
Make a tweak to your existing logging• log4j appender optionhttps://github.com/awslabs/kinesis-log4j-appe
nder

Amazon Kinesis Producer Library
• Writes to one or more Amazon Kinesis Streams with an automatic and configurable Retry Mechanism
• Collect Records and uses PutRecords to write multiple records to multiple shards per Request
• Aggregates user records to increase payload size and improve throughput
• Integrates seamlessly with the Amazon KCL to de-aggregate Batched Records
• Submits Amazon CloudWatch metrics on your behalf to provide visibility into producer performance
• https://github.com/awslabs/amazon-kinesis-producer/tree/master/java

Streaming Data Processing

Amazon Kinesis Client Library
• Build Kinesis Application with Client Library
• Open source client library available for Java, Ruby, Python, Node.JS dev
• Deploy on your set of EC2 instances
• KCL Application includes 3 components:
• Record Processor Factory – Creates the record processor
• Record Processor – The processor unit that processes data from a shard from Amazon Kinesis Stream
• Worker – The processing unit that maps to each application instance

IRecordProcessor: The heart of Kinesis Client Library
Class TwitterTrendsShardProcessor implements IRecordProcessor {
public TwitterTrendsShardProcessor() { … }
@Override
public void initialize(String shardId) { … }
@Override
public void processRecords(List<Record> records,
IRecordProcessorCheckpointer checkpointer) { … }
@Override
public void shutdown(IRecordProcessorCheckpointer checkpointer,
ShutdownReason reason) { … }
}
KCL uses IRcordProcessor interface to communicate with your application
A Kinesis application must implement KCL’sIRecordProcessor interface
Contains the business logic for processing thedata retrieved from the Kinesis stream

State Management with Kinesis Client Library
• One record processor maps to one shard and processes data records from that shard
• One worker maps to one or more record processors
• Balances shard-worker associations when worker / instance counts change
• Balances shard-worker associations when shards split or merge

Amazon Kinesis Connector Library
ITransformer
• Defines the transformation of records from the Amazon Kinesis stream in order to suit the user-defined data model
IFilter
• Excludes irrelevant records from the processing
IBuffer
• Buffers the set of records to be processed by specifying size limit (# of records)& total byte count
IEmitter
• Makes client calls to other AWS services and persists the records stored in the buffer
S3
DynamoDB
Redshift
Kinesis

Spark and Amazon Kinesis
Apache Spark is an in-memory analyticscluster using RDD for fast processing
Spark streaming can read directly from an Amazon Kinesis stream
Amazon software license linking – Add ASL dependency to SBT/MAVEN project (artifactId= spark-streaming-kinesis-asl_2.10)
KinesisUtils.createStream(‘twitter-stream’).filter(_.getText.contains(”Open-Source")).countByWindow(Seconds(5))
Counting tweets on a sliding window
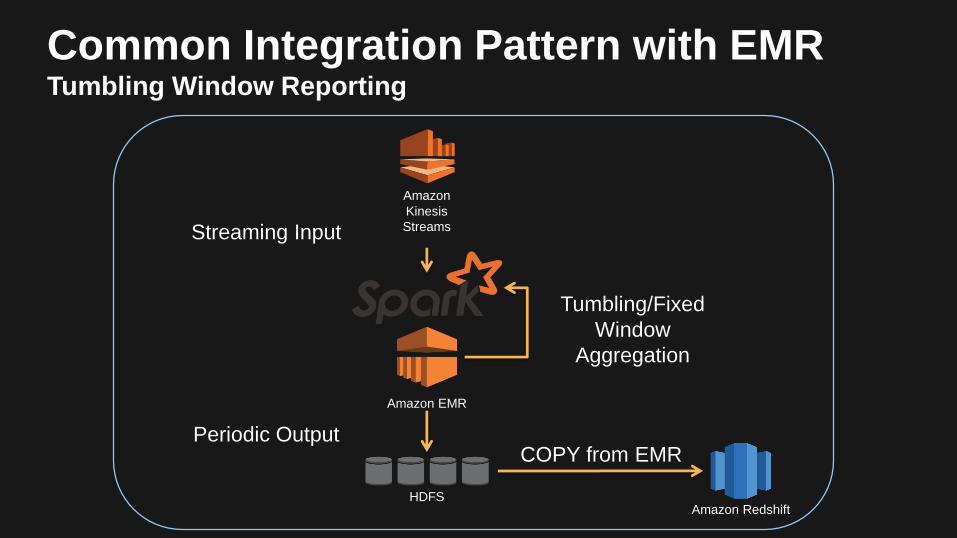
Amazon EMR
Amazon
Kinesis
StreamsStreaming Input
HDFS
Tumbling/Fixed
Window
Aggregation
Periodic Output
Amazon Redshift
COPY from EMR
Common Integration Pattern with EMRTumbling Window Reporting

Optimizing Spark Streaming and Kinesis
Streams
• Number of Amazon Kinesis Receivers are multiple of executors so they are load balanced
• Total processing time is less than the batch interval• Number of executors are number of cores per executor parameters • Spark streaming uses default of 1 sec with KCL • Enable Spark-based checkpoints• Use Spark 1.6+ with EMRFS consistent view option – if you use Amazon
S3 as storage for Spark checkpoint• DynamoDB table name – Make sure there is only one instance of the
application running with Spark Streaming.

Common Integration Pattern with Lambda

AWS Lambda Architecture

Lambda Application
Amazon Kinesis Firehose:
Zero-Maintenance Data
Ingestion at Scale

Amazon Kinesis FirehoseLoad massive volumes of streaming data into Amazon S3 and Amazon Redshift
Zero administration: Capture and deliver streaming data into S3, Redshift, and
other destinations without writing an application or managing infrastructure.
Direct-to-data store integration: Batch, compress, and encrypt streaming data
for delivery into data destinations in as little as 60 secs using simple configurations.
Seamless elasticity: Seamlessly scales to match data throughput w/o intervention
Capture and submit
streaming data to Firehose
Analyze streaming data using your
favorite BI tools
Firehose loads streaming data
continuously into S3 and Redshift

Amazon Kinesis Streams is a service for workloads that requires customprocessing, per incoming record, with sub-1 second processing latency,and a choice of stream processing frameworks.
Amazon Kinesis Firehose is a service for workloads that require zeroadministration, ability to use existing analytics tools based on S3 orRedshift, and a data latency of 60 seconds or higher.

Conclusion
• Amazon Kinesis – Managed Service to build applications, Streaming Data Ingestion and Continuous Processing
• Ingest aggregate data – Use Amazon Producer Library
• Processing data – Use Amazon Connector Library and open source connectors available
• Determine your partition key strategy
• Try out Amazon Kinesishttp://aws.amazon.com/kinesis/

Ingesting clicks data for analytics Francesco Furiani, C.T.O. @ ClickMeter (PositiveADV srl)

ClickMeter
42Ingesting clicks data for analytics
• Take control of marketing links and maximize conversion rates
• Tool to monitor, compare and optimize all their links in one place
Some stats:
• 100k+ customers
• Getting events for customers from 10 to 3000 req/sec (raw are way higher)
• Parse all of those :)

Ingesting the data
43Ingesting clicks data for analytics
• Click on our links
• View our pixels
ClickMeter receives data anytime someone:
• Inside a famous app the day of the big release ✔
• Advertising on an extremely big video portal ✔
• A tiny travel blog ✔
• A physical device for advertising ✔
Our customers uses links/pixels:

The challenge
44Ingesting clicks data for analytics
• Unless the customer informs us beforehand (unlikely to happen)
These type of situation are not really predictable
• Scale up (customers get angry in case of errors or data not showing)
• Parse data to show to the customers for better insight (they love it)
• Do it as fast as possible
• Do it as cheap as possible
We need to:

How to do it
45Ingesting clicks data for analytics
• Elastic Beanstalk
We obviously need some edge servers to keep answering to those HTTP events
Or how we thought to do it…
• Elastic Beanstalk, Amazon Kinesis, Amazon SQS, Amazon DynamoDB
We need to write this stuff somewhere
• Amazon Kinesis + Reactor/Kinesix, Amazon Pipeline + Amazon EMR, Amazon S3
We need to parse/enrich this data (either in real-time or in batch)
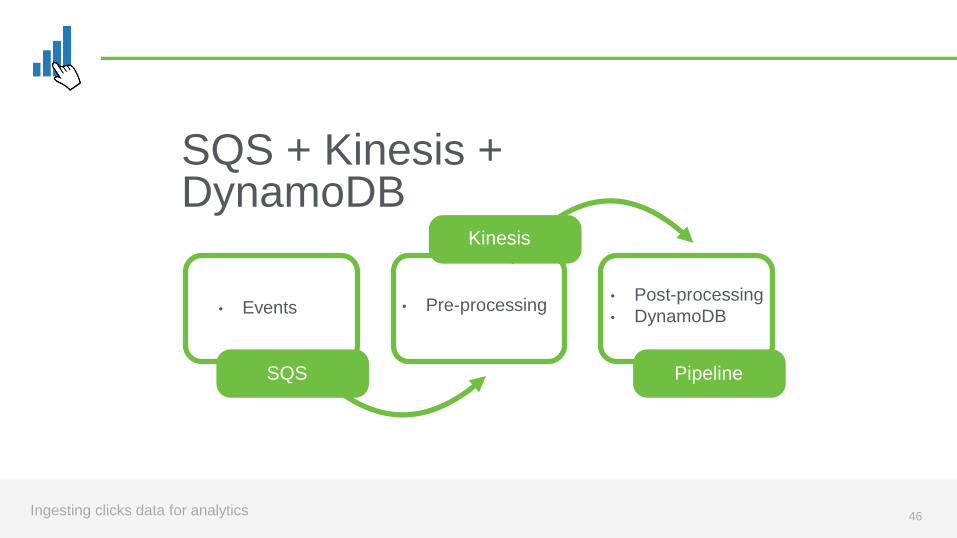
SQS + Kinesis + DynamoDB
46Ingesting clicks data for analytics
SQS Pipeline
Kinesis
• Events • Pre-processing• Post-processing
• DynamoDB

47Ingesting clicks data for analytics
Pipeline + EMR

Benefits
48Ingesting clicks data for analytics
• Architecture is scalable via CloudWatch Metrics and Scaling Groups
• Customers are happy and they bring more customers
• More data incoming means a better way for us to research and deliver more insight
• Sleep at night or as the tech says it «High Availability»

Benefits
49Ingesting clicks data for analytics
• We’re faster in delivering new features
AWS takes care of some operations that would require a dedicated DevOps
• We don’t need to buy machines in advance to scale to deal with peaks
AWS gives us the possibility to scale up without increasing (much) the IT budget
• Services and Instances can go down but they get replaced/rerouted easily
Amazon Route53 + ELB are very helpful in making our customers have the best experience

Future plans on AWS
50Ingesting clicks data for analytics
• Better than plain Hadoop, waiting for PIG on Spark compatibility
Amazon EMR + Spark
• Seems a very nice integration to explore
Amazon DynamoDB Streams + AWS Lambda
• Better data insight
AWS Machine Learning (prototypes to be ported upon)

Grazie a tutti!