an iterative semi-explicit rating method for building collaborative recommender systems
TRANSCRIPT

Expert Systems with Applications 36 (2009) 6181–6186
Contents lists available at ScienceDirect
Expert Systems with Applications
journal homepage: www.elsevier .com/locate /eswa
An iterative semi-explicit rating method for building collaborativerecommender systems
Buhwan Jeong a, Jaewook Lee b,*, Hyunbo Cho b
a Data Mining Team, Daum Communications Corp, 1730-8 Odeung, Jeju 690-150, South Koreab Department of Industrial and Management Engineering, Pohang University of Science and Technology (POSTECH), San 31 Hyoja Pohang, Kyungbuk 790-784, South Korea
a r t i c l e i n f o
Keywords:Collaborative filteringData sparsityExplicit ratingRecommender systemSemi-explicit rating
0957-4174/$ - see front matter � 2008 Elsevier Ltd. Adoi:10.1016/j.eswa.2008.07.085
* Corresponding author.E-mail address: [email protected] (J. Lee).
a b s t r a c t
Collaborative filtering plays the key role in recent recommender systems. It uses a user-item preferencematrix rated either explicitly (i.e., explicit rating) or implicitly (i.e., implicit feedback). Despite the explicitrating captures the preferences better, it often results in a severely sparse matrix. The paper presents anovel iterative semi-explicit rating method that extrapolates unrated elements in a semi-supervisedmanner. Extrapolation is simply an aggregation of neighbor ratings, and iterative extrapolations resultin a dense preference matrix. Preliminary simulation results show that the recommendation using thesemi-explicit rating data outperforms that of using the pure explicit data only.
� 2008 Elsevier Ltd. All rights reserved.
1. Introduction
Recommender systems have gained more importance ever be-fore as the increasing popularity of Internet and social networking,e.g., electronic commerce, Web 2.0, and web personalization. Overthe last decade, they are ones of the most successful applicationsboth in academia and in industry. Success stories can be found inrecommending books and CDs at Amazon.com (Linden, Smith, &York, 2003), movies by MovieLens (Miller, Albert, Lam, Konstan,& Riedl, 2003), news by GroupLens (Konstan et al., 1997) and byMONERs (Lee & Park, 2007), ESL reading lessons (Hsu, 2008) andso forth. Nonetheless, current state-of-the-art shows that they re-quire further improvements to make them more effective andapplicable to a broader range of real-life applications. For example,developments of better methods for representing user behaviorand the information about the items to be recommended, more ad-vanced recommendation methods that incorporate various contex-tual information into the recommendation process and utilizemulti-criteria ratings, and less intrusive and more flexible recom-mendation methods require to be further enhanced (Adomavicius& Tuzhilin, 2005). The paper particularly concentrates on animprovement of capturing better user behaviors, i.e., rating theuser preference.
Rating for recommender systems (or collaborative filtering inparticular) results in a user-item preference matrix by means ofeither explicit rating or implicit rating. In the explicit rating, eachuser examines items and assigns them rating values on a ratingscale, while in the implicit rating the rating values are presumed
ll rights reserved.
based on the user’s behaviors such as purchase of the item, accessto the information content, time duration to read the content, ac-tions (e.g., save, print, delete) applied to the content, etc. It is re-ported that the explicit rating captures user preferences to itemsmore accurately than implicit rating does (Nichols, 1998). How-ever, the latent problem of the explicit rating, i.e., data sparsity(which is usually severer than that of the implicit rating), makesit hard to manipulate the rating matrix – i.e., recommending itemsto an active user – in a pragmatic sense.
The paper aims to propose a novel rating method, namely semi-explicit rating (SER), to overcome the sparsity problem. The pro-posed method extrapolates the rating scores of unrated elementsin the principle of semi-supervised learning (Jeong, Lee, Cho, &Lee, 2008; Lee & Lee, 2005, 2006, 2007), in that by manipulating afew labeled/rated elements mathematically a number of the restunlabeled/unrated elements are estimated. Especially to enhancethe recommendation accuracy, the proposed method iteratively up-dates the user-item preference matrix until it becomes stabilized.
The remainder of the paper is organized as follows: Section 2addresses previous works on recommender systems, especiallyon collaborative filtering. Section 3 presents the details of the pro-posed method, followed by preliminary validations via numericalexperiments in Section 4. Finally, the concluding remarks andfuture works are given in Section 5.
2. Related works
Due to massive diversity in algorithms and applications, thissection briefly reviews the key research branches of the recom-mender systems and collaborative filtering relevant to this paper.For more comprehensive reviews and comparison, see references

6182 B. Jeong et al. / Expert Systems with Applications 36 (2009) 6181–6186
such as Adomavicius and Tuzhilin (2005), Deshpande and Karypis(2004) and Candillier, Meyer, and Boullé (2007).
The recommendation problem is to maximize an active user’ssatisfaction by suggesting him/her a set of items from many.According to the definition by Adomavicius and Tuzhilin (2005),the user satisfaction can be formulated as a utility function u thatmeasures the usefulness of an item g to the user c, i.e., u:C � G ? R, where C is the set of all users, G is the set of all possibleitems that can be recommended, and R is a totally ordered set innonnegative real numbers within a certain range. Note that thesizes of both C and G are very large – up to more than millionsin some cases. Then, for each user c 2 C, the objective is to choosean item g0 2 G such that maximizes the user’s utility, more for-mally, 8c 2 C; g0c ¼ arg maxg2Guðc; gÞ.
The recommender systems can be commonly classified into thefollowing three types based on how recommendations are made:content-based recommendations, in which the user will be recom-mended items similar to the ones the user preferred in the past;collaborative recommendations, in which the user will be recom-mended items that people with similar preferences liked in thepast; and hybrid approaches, in which collaborative and content-based recommendations are mixed. First, the content-based meth-ods utilize user profiles that contain information about users’ tastes,preferences, and needs, and item profiles that are a set of attributescharacterizing an item g. The techniques used in information re-trieval/text mining such as vector space model and term frequency/inverse document frequency (TF-IDF) are used for these recom-mender systems. Second, the collaborative methods (or collabora-tive filtering) predict the utility of items for a particular user-based on the items previously rated by other users. The underlyingassumption is that similar users have similar preferences. A user-item rating matrix R � RjCj�jGj is augmented for collaborative filter-ing systems. According to Breese, Heckerman, and Kadie (1998),algorithms in this type can be classified into memory-based andmodel-based ones. The memory-based algorithms, the mathemati-cal details of which will be provided in the next section, estimatethe value of unknown rating rcg for user c and item g as an aggre-gate of the ratings of some other users for the same item g. On theother hand, the model-based algorithms make a classifier trainedfrom the collection of ratings, and then predict future ratings.Finally the hybrid methods are nothing but an integration ofcollaborative and content-based methods to avoid each other’slimitations. See Adomavicius and Tuzhilin (2005) for the detailedsurvey and exemplary recommender systems.
Specifically the collaborative methods can be categorize into auser-based approach and an item-based approach according tothe searching order. The former user-based approach, more popu-lar at present, first finds a small group of users having similar pref-erences (i.e., nearest neighbors to the active user) and thensuggests the items the group commonly shares (e.g., purchase, ac-cess, read, etc.). Despite its popularity, the user-based approacheshave some problems in practice – data sparsity, scalability, andreal-time performance (Grcar, Mladenic, Fortuna, & Grobelnik,2006; Herlocker, Konstan, Terveen, & Riedl, 2004; Sarwar, Karypis,Konstan, & Reidl, 2001). On the other hand, the recent item-basedapproach directly looks for a set of items similar to an active item.It roughly consists of measuring similarity between items and thenpredicting a recommendation item. The item similarity is oftencomputed in terms of cosine, correlation, and conditional probabil-ity as the user similarity, whereas the prediction employs weightedsum and regression (Herlocker et al., 2004; Lee, Jun, Lee, & Kim,2005; Sarwar et al., 2001).
One of the most important issues in collaborative filtering forrecommendation accuracy is how to prepare the user-item prefer-ence matrix. The matrix can be filled either explicitly or implicitly,and hybrid rating is also possible. The explicit rating constructs the
user-item matrix with users’ explicit rating scores on a certain rat-ing scale, so that it can exactly express users’ tastes and prefer-ences. However, it has some crucial weaknesses: ambiguity inthe use of appropriate scales, difficulty in providing motivationand incentives for evaluators, detecting biased and malicious eval-uators, and achieving a critical mass of users to avoid data sparsity(Nichols, 1998). Users tend to rate an item more frequently if theyfeel it is good, and not to rate otherwise. On the other hand, the im-plicit rating constructs the user-item matrix by observing users’behaviors such as whether or not an action (e.g., purchase, access,save, print, reply) is performed to the item, how long they spendtime on reading, for example, the item, and how many times theyhave browsed the item, and so on (Lee et al., 2005; Nichols, 1998).The resulting matrix is usually less sparse, but the scores are as-sumed/implicit thereby less informative. The explicit rating pro-vides a better user-item matrix for plausible predictions aboutthe interests of a user, provided that every user is even, rational,unbiased, and correct.
The focus of this paper is to overcome the data sparsity problemin the user-item matrix. Widely used ways to deal with this prob-lem are to use dimension reduction techniques such as a naïvemethod to select relevant users and/or items only (e.g., eliminatesparse rows/columns from the user-item matrix), or a more sophis-ticated method based on linear algebra and statistical analysis suchas the singular value decomposition (SVD, or named as LSA/LSI (La-tent Semantic Analysis/Indexing) in many applications) and princi-pal components analysis (PCA) (Grcar et al., 2006). Thesedimension reduction techniques not only resolve the data sparsityand scalability problems, but also improve recommendation accu-racy. In addition, the item-based collaborative filtering is known tobe very effective in dealing with such sparse data (Grcar et al.,2006; Sarwar et al., 2001). Other approaches include horting, clus-tering, and Bayesian networks (Grcar et al., 2006). Nonetheless, theoriginal matrix still remains sparse.
3. Semi-explicit rating and recommendation prediction
This section presents a novel extrapolation method, namelysemi-explicit rating (SER), that estimates unrated elements in theuser-item preference matrix. The method is based on the semi-supervised learning principle, in that a number of unrated ele-ments are filled by numerical inference of a few (sparse) explicitratings.
3.1. Basic idea to extrapolate unrated elements
The user-item preference matrix Rð¼ ½rij�Þ � RN�M contains Nusers’ preferences to M items, i.e., an element rij represents useri’s rating of item j, as shown in Fig. 1. To extrapolate an unrated ele-ment rij, we employ the memory-based approaches that infer therating from neighbor users’ ratings rlj by a formulation of rij = f(rlj, -SimU(i, l)), where l(–i & 6N) is the index of the users who rated theactive item j, f(�) is an aggregation function, and SimU(i,l) is the sim-ilarity between users i and l. Some examples of the aggregationfunction are
rij ¼ jc
X
l
SimUði; lÞ � rlj ð1Þ
rij ¼ �ri; þ jc
X
l
SimUði; lÞ � ðrlj � �ri;Þ; ð2Þ
where multiplier jc serves as a normalizing factor and is usually se-lected as jc ¼ 1=
PljSimUði; lÞj, and where �ri; in (2) is the average rat-
ing of the active user i. Eq. (1) is the most common aggregationfunction where the similarity measure SimU(i, l) is used as a weight,but it has a shortcoming in that different users may use different

rij
1 2 ... j ...
1
2
...
i
...
M
N
k
l
Fig. 3. Mixture of item- and user-perspective extrapolations.
rij
rlj
1 2 ... j ...
1
2
...
i
...
l
M
Sim(i, l)
...
N
Fig. 1. Notation and extrapolation of an unrated element.
B. Jeong et al. / Expert Systems with Applications 36 (2009) 6181–6186 6183
rating scale (Adomavicius & Tuzhilin, 2005). The aggregation func-tion in Eq. (2) overcomes it by using deviations from the averagerating of the corresponding user (Resnick, Iacovou, Suchak,Bergstorm, & Riedl, 1994).
An important factor to the equations above is how to measuresimilarity SimU(i, l) between users. Popular similarity measuresbased on their ratings of items that both users have rated includecorrelation-based, cosine-based, adjusted cosine-based, and condi-tional probability-based measures. Firstly, the correlation-basedmeasure is defined in terms of the Pearson correlation coefficientthat evaluates the degree of linear relationship between two users(Grcar et al., 2006). Secondly, the cosine-based one treats the usersas M-dimensional vectors and compute the cosine of the angle be-tween them. Thirdly, the adjusted cosine-based one incorporatesthe difference in rating scale between different users (Sarwaret al., 2001). Finally, the conditional probability-based one simplyuses the ratio of common items two user share (Deshpande &Karypis, 2004).
3.2. Various views of rating extrapolation
As described above, the memory-based collaborative methodcomputes an unknown rating rij of an item j for the active user iby solving either Eq. (1) or Eq. (2). That is, the solution rij is aweighted average of the ratings rlj by the neighbors who have al-ready rated for the item, where the weight is set by the user sim-ilarity SimU(i, l) between the active user and his/her neighbors in
rij
1 2 ... j ...
1
2
...
i
...
M
N
l
A
Fig. 2. Item-/column-perspective and u
terms of the portion of common items they have rated. This canbe viewed as item-perspective extrapolation because the esti-mated rating is an aggregation of the ratings of the item. Sincethe item is expressed in a column vector, this is also named as col-umn-oriented computation, as shown in Fig. 2A.
Another insight is that the rating rij may be written as aweighted aggregation of the ratings the active user previously eval-uated. This sets the unknown rating by a default value. In this case,the weight in the equations above is replaced with item similaritySimI(j,k), by the same computation as follows:
rij ¼jg
X
k
SimIðj; kÞ � rkj ð3Þ
rij ¼�r;j þ jg
X
k
SimIðj; kÞ � ðrik � �r;jÞ; ð4Þ
where �r;j is an average rating of the active item j, and jg ¼1=P
kjSimIðj; kÞj is the normalizing factor. Alternatively, we mayuse jg = 1/Ki, where Ki is the number of items rated by the user i,to give a penalty to unrated elements. This approach is illustratedin Fig. 2B, and named as user-/row-perspective extrapolation.
Our proposed method combines both the item-perspective anduser-perspective extrapolations as depicted in Fig. 3. Specifically,we take a weighted average as in Eq. (5). Since the user-perspectiveextrapolation rc
ij represents the default value for a user c, we canmodify Eq. (2) into Eq. (6) as follows:
1 2
rij
... j ... M
k
B
ser-/row-perspective extrapolation.

6184 B. Jeong et al. / Expert Systems with Applications 36 (2009) 6181–6186
rij ¼arUij þ ð1� aÞrI
ij ð5Þ
rij ¼rUij þ j
X
l
SimIði; lÞ � ðrlj � rUij Þ; ð6Þ
where rUij and rI
ij represent the estimated rij by user- and item-per-spective extrapolations, respectively, and a 6 1 is the weight con-trol parameter.
3.3. Graphical representation of extrapolation
Before reaching the final stage of the proposed method, wewant to mention another intuition about the extrapolation in agraphical view. The extrapolation of an unrated element is repre-sented in a graphical model depicted in Fig. 4. Abstractly, theextrapolation is expressed as a typical Sum-Product form. Furtherstudies need to be investigated in a graphical manipulation ofthe rating extrapolation.
3.4. Iterative procedure of semi-explicit rating
The unrated elements filled by the extrapolation method de-scribed above are neither complete nor stable since, as unrated ele-ments are filled with new extrapolated values, the similarity, bothuser similarity SimU(i, l) and item similarity SimI(j,k) change and somust be adjusted. The latter fact involves complex processes tocomplete a user-item preference matrix because (i) every extrapo-lation requires its own extravagant similarity computations, and(ii) the extrapolation procedure is recursive, i.e., next extrapola-tions affect previous extrapolation results. To facilitate this pro-cess, we envision an iterative semi-explicit rating procedure, inwhich an iteration fills all the unrated elements with initial simi-larity matrices, and the next iteration starts with re-computed sim-ilarity matrices. The procedure terminates when the user-itemmatrix becomes stable. Note that periodic updates are requiredfor incorporating new users, items, and explicit ratings. The itera-tive extrapolation procedure is detailed below:
Step 0: Given a user-item preference matrix, compute both usersimilarity matrix Sc � RN�N and item similarity matrix Sg �RM �M.Step 1: Extrapolate the user-item preference matrix using thesimilarity matrices and the explicit ratings. Note that the expli-cit ratings that the users explicitly evaluated never change.Step 2: Check the stability, i.e., the difference between previouspreference matrix and resulting matrix. Terminate the proce-dure if the matrix is stable. Otherwise, go to step 1 with newlycomputed user similarity and item similarity matrices.
r1j r2j rlj2j rNj
rij
Sim(i, l)
User (C)
Fig. 4. Graphical representatio
3.5. Recommendation
It is now evident to suggest recommendations (either only oneitem or top-N items) to the active user using the preference matrixgenerated by the proposed method. Since the proposed method ex-tends the memory-based approach, we simply select the top-Nhighest rating items (except those the user already has). Or, wemay build a classifier (or a prediction model) using the rating ma-trix as the model-based approach does. Item-based approaches arealso applicable.
The advantages of the proposed method is that we can not onlycope with the data sparsity problem of the explicit rating, but alsoprovide scalability and real-time performance. Clearly, the finalrating matrix has no null element, so that the rating matrix be-comes dense. Also, since the rating matrix is constructed in off-line,the real-time applications does not require extra time in computa-tion, except selecting recommendations.
4. Preliminary experiments
4.1. Simulation setting
Preliminary simulations are conducted to validate the under-pinning concept of the proposed method. The simulation is limitedfor it is intended only to show the validity of using the method. Thedataset used is the MovieLens (ML) data, which contain 100,000explicit ratings (on 1–5 rating scale) from 943 users and 1682items (Sarwar et al., 2001). Note that the ML data are very sparse:the sparsity level is about 93.7% (i.e., 1� nonzero entries
total entries ¼ 1� 100;000943�1682).
For the underlying performance evaluation metric, we use themean absolute error (MAE) between ratings and predictions. TheMAE is a widely used metric, and measures the deviation of recom-mendations from their true user-specified values. For each pair oftrue rating and prediction (tv,pv), the MAE is defined asMAE ¼
PVv¼1jtv � pvj=V , where V is the total number of correspond-
ing rating-prediction pairs. The lower the MAE is, the more accu-rately the recommender system predicts user ratings. We alsouse the correlation coefficient as an annexed metric. In this exper-iment, we use the cosine similarity, the user-based recommenda-tion algorithm (Eq. (1)), and the modified weighted aggregationfunction (Eq. (6)). For a validation, we resort to 10-fold cross vali-dation. Many of the other simulation parameters (e.g., training/testdata ratio = 0.8) are set to follow the pre-test results in Sarwar etal. (2001), if not specified. Recall that the simulation aims to showthe validity of the rating method, not to compare the performanceof recommendation algorithms, even though they are critical in a
ri1 rik riM
Sim(j, k)
Item(G)
n of rating extrapolation.
0.72
0.74
0.76
0.78
0.80
0.82
MA
E
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 α
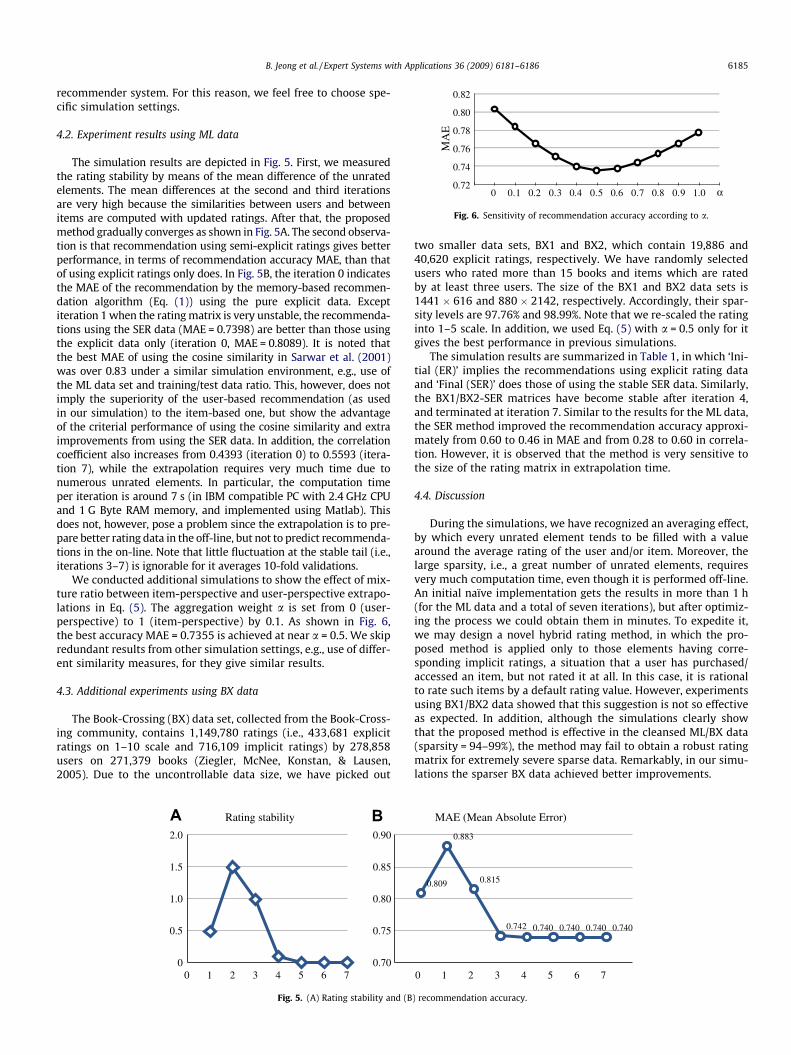
Fig. 6. Sensitivity of recommendation accuracy according to a.
B. Jeong et al. / Expert Systems with Applications 36 (2009) 6181–6186 6185
recommender system. For this reason, we feel free to choose spe-cific simulation settings.
4.2. Experiment results using ML data
The simulation results are depicted in Fig. 5. First, we measuredthe rating stability by means of the mean difference of the unratedelements. The mean differences at the second and third iterationsare very high because the similarities between users and betweenitems are computed with updated ratings. After that, the proposedmethod gradually converges as shown in Fig. 5A. The second observa-tion is that recommendation using semi-explicit ratings gives betterperformance, in terms of recommendation accuracy MAE, than thatof using explicit ratings only does. In Fig. 5B, the iteration 0 indicatesthe MAE of the recommendation by the memory-based recommen-dation algorithm (Eq. (1)) using the pure explicit data. Exceptiteration 1 when the rating matrix is very unstable, the recommenda-tions using the SER data (MAE = 0.7398) are better than those usingthe explicit data only (iteration 0, MAE = 0.8089). It is noted thatthe best MAE of using the cosine similarity in Sarwar et al. (2001)was over 0.83 under a similar simulation environment, e.g., use ofthe ML data set and training/test data ratio. This, however, does notimply the superiority of the user-based recommendation (as usedin our simulation) to the item-based one, but show the advantageof the criterial performance of using the cosine similarity and extraimprovements from using the SER data. In addition, the correlationcoefficient also increases from 0.4393 (iteration 0) to 0.5593 (itera-tion 7), while the extrapolation requires very much time due tonumerous unrated elements. In particular, the computation timeper iteration is around 7 s (in IBM compatible PC with 2.4 GHz CPUand 1 G Byte RAM memory, and implemented using Matlab). Thisdoes not, however, pose a problem since the extrapolation is to pre-pare better rating data in the off-line, but not to predict recommenda-tions in the on-line. Note that little fluctuation at the stable tail (i.e.,iterations 3–7) is ignorable for it averages 10-fold validations.
We conducted additional simulations to show the effect of mix-ture ratio between item-perspective and user-perspective extrapo-lations in Eq. (5). The aggregation weight a is set from 0 (user-perspective) to 1 (item-perspective) by 0.1. As shown in Fig. 6,the best accuracy MAE = 0.7355 is achieved at near a = 0.5. We skipredundant results from other simulation settings, e.g., use of differ-ent similarity measures, for they give similar results.
4.3. Additional experiments using BX data
The Book-Crossing (BX) data set, collected from the Book-Cross-ing community, contains 1,149,780 ratings (i.e., 433,681 explicitratings on 1–10 scale and 716,109 implicit ratings) by 278,858users on 271,379 books (Ziegler, McNee, Konstan, & Lausen,2005). Due to the uncontrollable data size, we have picked out
0
0.5
1.0
1.5
2.0
0 1 2 3 4 5 6 7
Rating stability
0.70
0.75
0.80
0.85
0.90
A B
Fig. 5. (A) Rating stability and (B
two smaller data sets, BX1 and BX2, which contain 19,886 and40,620 explicit ratings, respectively. We have randomly selectedusers who rated more than 15 books and items which are ratedby at least three users. The size of the BX1 and BX2 data sets is1441 � 616 and 880 � 2142, respectively. Accordingly, their spar-sity levels are 97.76% and 98.99%. Note that we re-scaled the ratinginto 1–5 scale. In addition, we used Eq. (5) with a = 0.5 only for itgives the best performance in previous simulations.
The simulation results are summarized in Table 1, in which ‘Ini-tial (ER)’ implies the recommendations using explicit rating dataand ‘Final (SER)’ does those of using the stable SER data. Similarly,the BX1/BX2-SER matrices have become stable after iteration 4,and terminated at iteration 7. Similar to the results for the ML data,the SER method improved the recommendation accuracy approxi-mately from 0.60 to 0.46 in MAE and from 0.28 to 0.60 in correla-tion. However, it is observed that the method is very sensitive tothe size of the rating matrix in extrapolation time.
4.4. Discussion
During the simulations, we have recognized an averaging effect,by which every unrated element tends to be filled with a valuearound the average rating of the user and/or item. Moreover, thelarge sparsity, i.e., a great number of unrated elements, requiresvery much computation time, even though it is performed off-line.An initial naïve implementation gets the results in more than 1 h(for the ML data and a total of seven iterations), but after optimiz-ing the process we could obtain them in minutes. To expedite it,we may design a novel hybrid rating method, in which the pro-posed method is applied only to those elements having corre-sponding implicit ratings, a situation that a user has purchased/accessed an item, but not rated it at all. In this case, it is rationalto rate such items by a default rating value. However, experimentsusing BX1/BX2 data showed that this suggestion is not so effectiveas expected. In addition, although the simulations clearly showthat the proposed method is effective in the cleansed ML/BX data(sparsity = 94–99%), the method may fail to obtain a robust ratingmatrix for extremely severe sparse data. Remarkably, in our simu-lations the sparser BX data achieved better improvements.
0 1 2 3 4 5 6 7
0.809
0.883
0.815
0.742 0.740 0.740 0.740 0.740
MAE (Mean Absolute Error)
) recommendation accuracy.

Table 1Brief descriptions of ML/BX1/BX2 data sets and summary of simulation results
ML BX1 BX2
Dataset description No. of explicit ratings 100,000 19,886 40,620Matrix size 943 � 1682 1441 � 616 1880 � 2142Sparsity (%) 93.69 97.76 98.99
MAE Initial (ER) 0.8089 0.5830 0.6019Final (SER) 0.7398 0.4645 0.4573
Correlation coefficient Initial (ER) 0.4393 0.2846 0.2645Final (SER) 0.5593 0.6101 0.5840
Computation time per iteration (s) 7 3 25
6186 B. Jeong et al. / Expert Systems with Applications 36 (2009) 6181–6186
5. Conclusion
The recommender systems, or collaborative filtering in particu-lar, have been omnipresent in various applications such as prod-ucts recommendation, spams filtering, web personalization, etc.As the amount of information content grows, the importance ofaccurate recommender systems increases. The availability of cor-rect user-item preference matrices is critical to build a better sys-tem. The explicit rating method usually gives a better preferencematrix than the implicit rating methods does. However, the prefer-ence matrix by the explicit rating is often much sparser. We haveproposed a generative rating method, namely iterative semi-expli-cit rating (SER), that extrapolates unrated elements with neighborratings. The underlying computation of extrapolation is the sameas that of the memory-based algorithm. By visiting all the unratedelements and iteratively extrapolating them, we finally construct afull preference matrix. The preliminary simulations show that rec-ommendation using the data constructed by the proposed methodoutperforms the method using the pure explicit data only. To val-idate the proposed method, we have experimented a relativelysmall data set only. Exhaustive experiments with much larger datafrom real applications needs to be further investigated. We also ex-pect diverse further studies in the semi-supervised rating ap-proach. For example, instead of using all the related ratings ri
*
and r*j, we may extrapolate using partial ratings from a group of
similar users and items after co-clustering (e.g., Araujo, Trielli, Or-air, Ferreira, & Guedes, 2006).
Acknowledgements
Thanks to Shyong Lam and Jon Herlocker for cleaning up andgenerating the MovieLens (ML) data set, and to Cai-Nicolas Zieglerand Ron Hornbaker for the Book-Crossing (BX) data set. This workwas supported partially by the Korea Research Foundation underthe Grant No. KRF-2008-314-D00483 and partially by the KOSEFunder the Grant No. R01-2007-000-20792-0.
References
Adomavicius, G., & Tuzhilin, A. (2005). Toward the next generation of recommendersystems: A survey of the state-of-the-art and possible extensions. IEEETransactions on Knowledge and Data Engineering, 17(6), 734–749.
Araujo, R., Trielli, G., Orair, G., Ferreira, W. M., Jr., R., & Guedes, D. (2006).ParTriCluster: A scalable parallel algorithm for gene expression analysis. InProceedings of the 18th international symposium on computer architecture andhigh performance computing (SBAC-PAD’06) (pp. 3–10).
Breese, J. S., Heckerman, D., & Kadie, C. (1998). Empirical analysis of predictivealgorithms for collaborative filtering. In Proceedings of the 14th conference onuncertainty in artificial intelligence (UAI-98) (pp. 43–52).
Candillier, L., Meyer, F., & Boullé, M. (2007). Comparing state-of-the-artcollaborative filtering systems. Machine Learning and Data Mining in PatternRecognition LNCS, 4571, 548–562.
Deshpande, M., & Karypis, G. (2004). Evaluating collaborative filtering recommendersystems. ACM Transactions on Information Systems, 22(1), 143–177.
Grcar, M., Mladenic, D., Fortuna, B., & Grobelnik, M. (2006). Data sparsity issues inthe collaborative filtering framework. Advances in Web Mining and Web UsageAnalysis LNAI, 4198, 58–76.
Herlocker, J. L., Konstan, J. A., Terveen, L. G., & Riedl, J. T. (2004). Item-based top-nrecommendation algorithms. ACM Transactions on Information Systems, 22(1),5–53.
Hsu, M.-H. (2008). A personalized English learning recommender system for ESLstudents. Expert Systems with Applications, 34(1), 683–688.
Jeong, B., Lee, D., Cho, H., & Lee, J. (2008). A novel method for measuring semanticsimilarity for xml matching. Expert Systems with Applications, 34(3), 1651–1658.
Konstan, J. A., Miller, B. N., Maltz, D., Herlocker, J. L., Gordon, L. R., & Riedl, J. (1997).GroupLens: Applying collaborative filtering to usenet news. Communication ofACM, 40(3), 77–87.
Lee, J.-S., Jun, C.-H., Lee, J., & Kim, S. (2005). Classification-based collaborativefiltering using market basket data. Expert Systems with Applications, 29(3),700–704.
Lee, J., & Lee, D. (2005). An improved cluster labeling method for support vectorclustering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 27(3),461–464.
Lee, J., & Lee, D. (2006). Dynamic characterization of cluster structures for robustand inductive support vector clustering. IEEE Transactions on Pattern Analysisand Machine Intelligence, 28(11), 1869–1874.
Lee, D., & Lee, J. (2007). Equilibrium-based support vector machine for semi-supervised classification. IEEE Transactions on Neural Networks, 18(2), 578–583.
Lee, H., & Park, S. (2007). MONERS: A news recommender for the mobile web. ExpertSystems with Applications, 32(1), 143–150.
Linden, G., Smith, B., & York, J. (2003). Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet Computing, 7(1), 76–80.
Miller, B., Albert, I., Lam, S., Konstan, J., & Riedl, J. (2003). MovieLens unplugged:Experiences with an occasionally connected recommender system on fourmobile devices. In Proceedings of the 17th annual human–computer interactionconference (HCI 2003) (pp. 263–266).
Nichols, D. (1998). Implicit rating and filtering. In Proceedings of the fifth DELOSworkshop on filtering and collaborative filtering (pp. 31–36).
Resnick, P., Iacovou, N., Suchak, M., Bergstorm, P., & Riedl, J. (1994). GroupLens: Anopen architecture for collaborative filtering of netnews. In Proceedings of 1994ACM conference on computer supported cooperative work (pp. 175–186).
Sarwar, B. M., Karypis, G., Konstan, J. A., & Reidl, J. (2001). Item-based collaborativefiltering recommendation algorithms. In Proceedings of the 10th internationalconference on world wide web (pp. 285–295).
Ziegler, C.-N., McNee, S. M., Konstan, J. A., & Lausen, G. (2005). Improvingrecommendation lists through topic diversification. In Proceedings of the 14thinternational world wide web conference (WWW’05) (pp. 22–32).