an intro to nosql databases
TRANSCRIPT

1
NoSQLNot Only SQL

2

3
Source :- http://wearesocial.net/blog/2015/01/digital-social-mobile-worldwide-2015/

4
3 V
o VELOCITY
o VOLUME
o VARIETY

5

6 6
RELATIONAL DATABASE MANAGEMENT SYSTEM
Relational Model - data represented in terms of tuples (rows).
Key Concepts
o Table - collection of data elements organized in terms of
rows and columns
o Field - column in a table designed to maintain specific
information about every record in the table
o Record - horizontal entity represents set of related data
o Column - vertical entity containing values of particular type

7 7
RELATIONAL DATABASE MANAGEMENT SYSTEM INTEGRITY RULES
o Entity Integrity
o Domain Integrity
o Referential integrity
o User-Defined Integrity
8 8
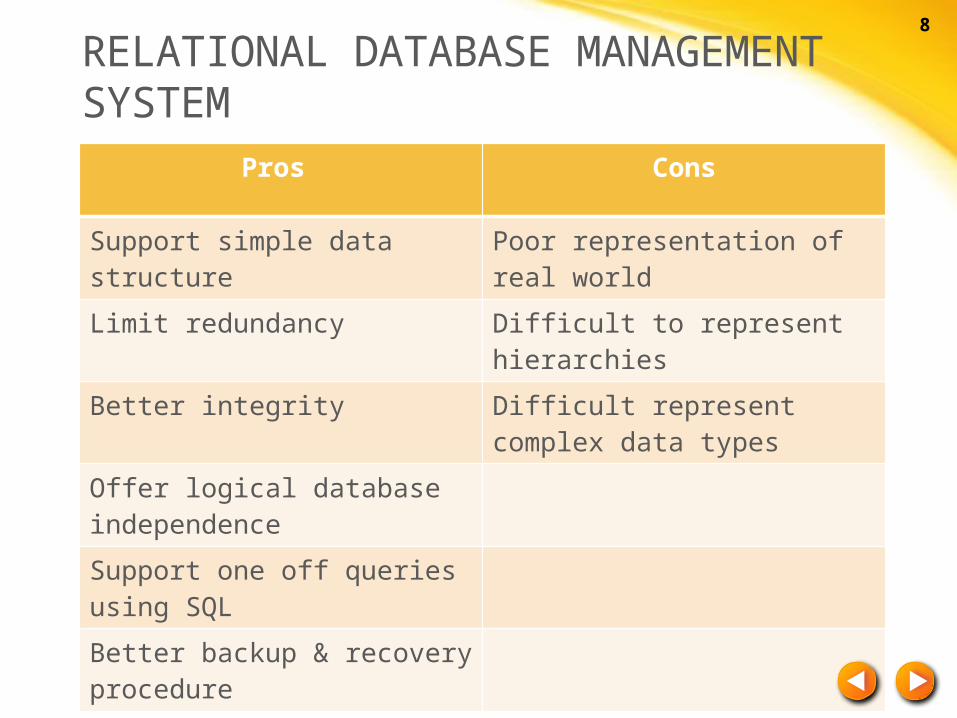
RELATIONAL DATABASE MANAGEMENT SYSTEM
Pros Cons
Support simple data structure
Poor representation of real world
Limit redundancy Difficult to represent hierarchies
Better integrity Difficult represent complex data types
Offer logical database independence
Support one off queries using SQL
Better backup & recovery procedure

9 9
RDBMS VS NOSQL
RDBMS NoSQL
Scale up Scale out
Handle Structured Data Semi-Structured data / Unstructured data
Atomic transaction Eventual consistency
impedance mismatch Object model
Strict schema Schema-less

10 10
DISTRIBUTED SYSTEMSDistributed database system consists of loosely-coupled sites that share no physical components.
Homogeneous DDBMSAll sites have identical software & aware of each other.
work corporately in processing user requests
Heterogeneous DDBMSDifferent sites may use different schema and software.
provide limited facilities for cooperation in transaction processing
11 11
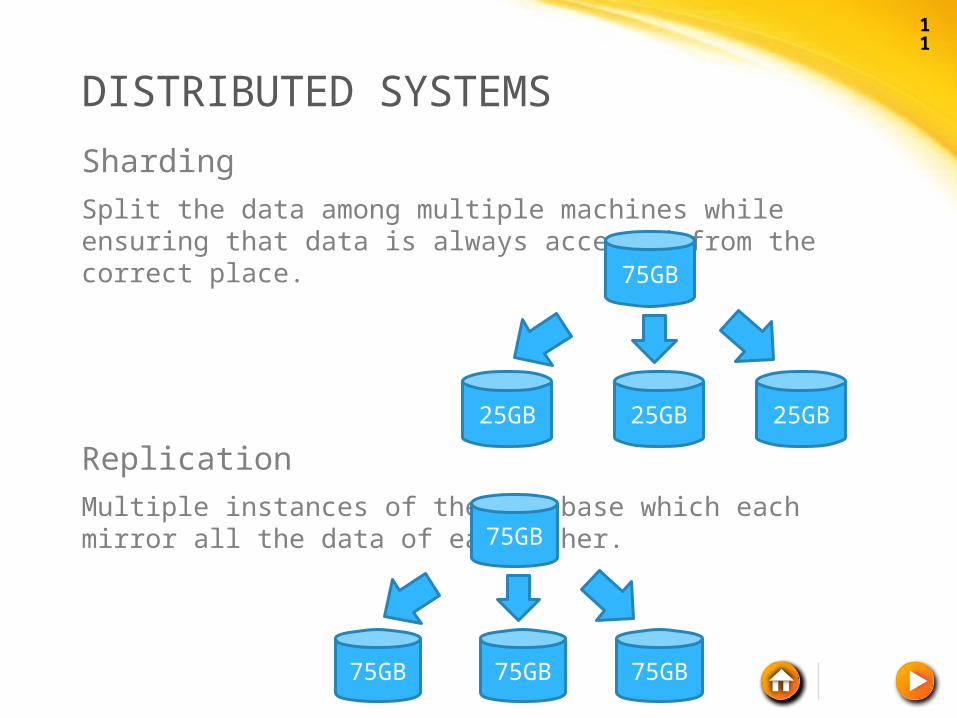
DISTRIBUTED SYSTEMS
Sharding Split the data among multiple machines while ensuring that data is always accessed from the correct place.
ReplicationMultiple instances of the Database which each mirror all the data of each other.
75GB
25GB 25GB 25GB
75GB
75GB 75GB 75GB

12 12
WHY NOSQL
The global NoSQL market is forecast to reach
$3.4 Billion in 2020,
representing a compound
annual growth rate (CAGR) of 21%
for the period
2015 – 2020.
http://www.technologies.org/?p=102http://www.marketresearchmedia.com/?p=568

13 13
BIG USERS

14 14
BIG DATA

15 15
THE INTERNET OF THINGS

16 16
CLOUD COMPUTING

17 17
FLEXIBLE DATA MODEL

18 18
SCALABILITY AND PERFORMANCE

19 19
WHAT IS ACID?
o Atomicity
A transaction is all or nothing
o Consistency
Only valid data is written to the database
o Isolation
Pretend all transactions are happening serially and the data is correct
o Durability
What you write is what you get

20 20
CAP THEOREM
A
PC
Availability :Each client can always read
and write
Partition Tolerance :The system works well despite
physical network partitions.
Consistency :All clients always have the
same view of the data.
You can have at most two of these properties for
any shared Data Systems.

21 21
AN ALTERNATIVE TO ACID IS BASE
o Basic Availability
System seems to work all the time
o Soft-State
It doesn't have to be consistent all the time
o Eventual Consistency
Becomes consistent at some later time
22 22
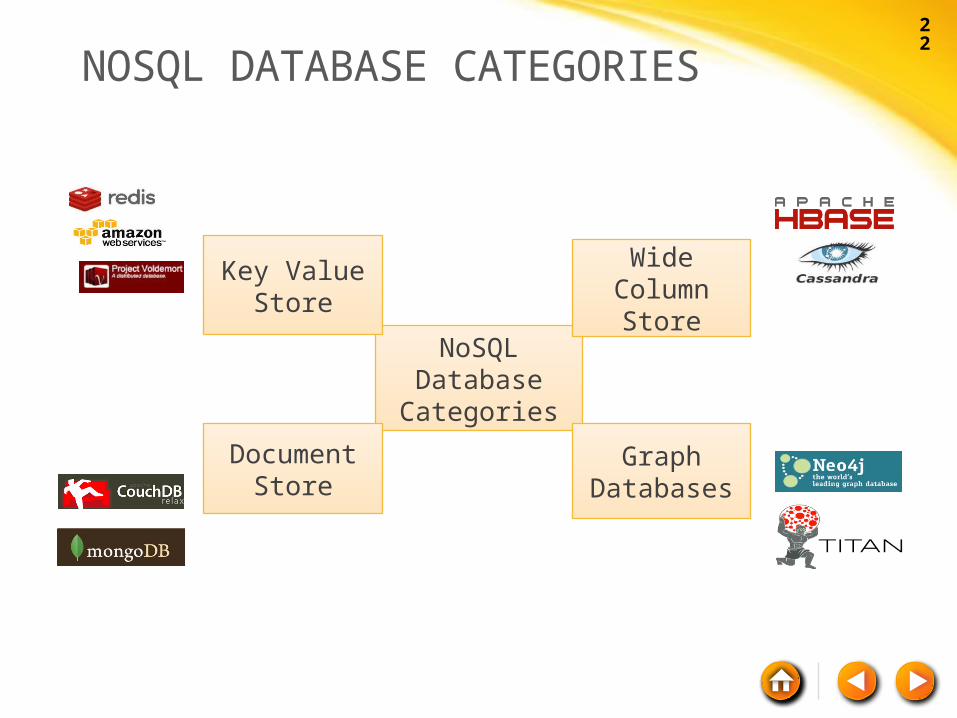
NOSQL DATABASE CATEGORIES
NoSQL Database Categories
Key Value Store
Document Store
Wide Column Store
Graph Databases

23 23
KEY VALUE STORE - OVERVIEW
o Most basic type of NoSQL Database and basis for other three
o Schema-free
o Store data as Key-Value pair
o Key-Value stores can be used as collections, dictionaries, associative arrays etc.
Example DBs: Redis, Project Voldemort, Amazon DyanmoDB
Key: Value Row_Id:100First_Name: SamanLast_Name: SilvaAddress: 123, Galle Rd, BeruwalaLast_Order: 2001

24 24
WIDE COLUMN STORE - OVERVIEW
o Stored data in a columnar format
o Semi-Schematic
o Allow key-value pairs to be stored
o Each key(Super Column) is associate with multiple attributes
o Stores data in column specific file
Example DBs: Apache Hbase, Cassendra, Big Table, Hadoop
Super_Column:Value Sub_Coulmn->Key:Value Sub_Coulmn->Key:Value
Super_Column:Name First_Name:Saman Last_Name:SilvaSuper_Column:Address No:125 Road:Galle Rd City:Beruwala

25 25
DOCUMENT STORE - OVERVIEW
o Everything is stored in a Document
o Schema-free
o Data is stored inside documents as JSON or BSON formats
o Document is a Key-Value collection
Example DBs: MongoDb, CouchDB Database: Customers Database: Orders
Document_Id:100First_Name:SamanLast_Name:SilvaAddress:
Order:
Number: 125Road: Galle RdCity: Beruwala
Most_Recent: 2001
Document_Id:2001Price: Rs 450Item1: 1001Item2: 1002
Document_Id:2002Price: Rs 750Item1: 1003Item2: 1001
26 26
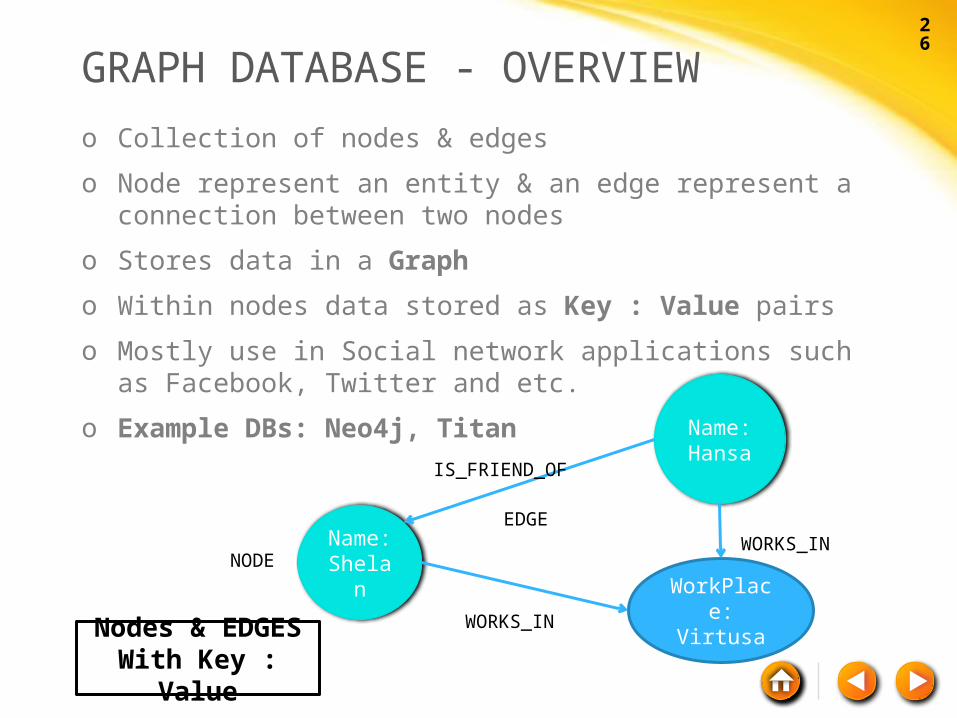
GRAPH DATABASE - OVERVIEWo Collection of nodes & edges
o Node represent an entity & an edge represent a connection between two nodes
o Stores data in a Graph
o Within nodes data stored as Key : Value pairs
o Mostly use in Social network applications such as Facebook, Twitter and etc.
o Example DBs: Neo4j, Titan
Nodes & EDGESWith Key : Value
Name:
Shelan
Name: Hansa
WorkPlace:
Virtusa
NODE
WORKS_IN
WORKS_IN
IS_FRIEND_OF
EDGE

27 27
KEY VALUE STORE
o Most Basic NoSQL Database Type
o Storing data as a dictionary or hash
o Dictionaries contain collection of objects or records
o Different than RDBMS

28 28
KEY VALUE STORE
Database
Customer Order
Row_Id:100First_Name: SamanLast_Name: SilvaAddress: 123, Galle Rd, BeruwalaLast_Order: 2001
Row_Id:101First_Name: NuwanLast_Name: PereraAddress: 1/2, Galle Rd, KalutaraLast_Order: 2002
Row_Id: 2001Price: Rs 450Item1: 1001Item2: 1003Item3: 1005
Row_Id:2002Price: Rs 750Item1: 1001Item2: 1002Item3: 1003

29 29
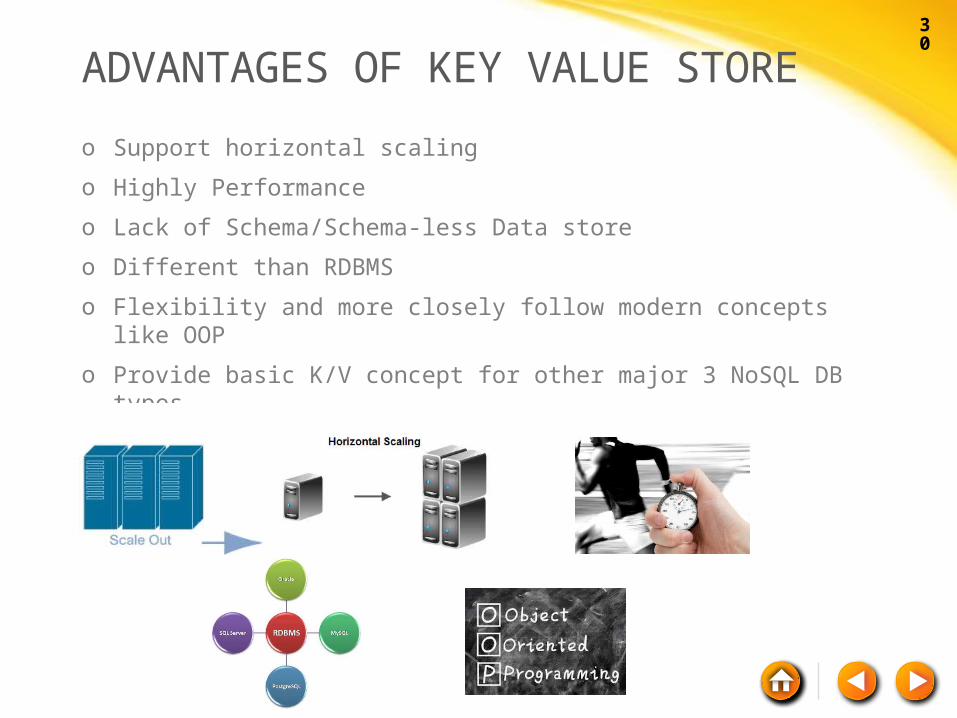
WHEN TO USE KEY VALUE STORE
o Caching: Quickly storing and retrieving
o Queuing: Some K/V stores support lists, sets, queues and more
o Distributing information and tasks
o Keeping live information
30 30
ADVANTAGES OF KEY VALUE STORE
o Support horizontal scaling
o Highly Performance
o Lack of Schema/Schema-less Data store
o Different than RDBMS
o Flexibility and more closely follow modern concepts like OOP
o Provide basic K/V concept for other major 3 NoSQL DB types

31 31
REDIS – KEY STORE VALUE DATABASE
o Open Source, Advanced Key-Value store
o 3 main specialties
o Holds its database entirely in memoryo Has a relatively rich set of data typeso Can replicate data to any number of slaves
o 2 types of Persistence
o RDB Persistenceo AOF Persistence
o 5 Data Types
http://www.redis.iohttp://redis.io/download

32 32
REDIS FEATURES
o Exceptionally Fast
o Support Rich data types
o Operations are Atomic
o MultiUtility Tool

33 33
REDIS DATA TYPES
“This is a String Value”
namecustomer:1
address
Hasangi
Hasangi
Hansa HijasRajith
0 Hansa
1 Hasang
i2 Hijas
4 Shelan
3 Rajith
Hasangi Hansa HijasRajith
ShelanBeruwala
customer:2 nameaddress
RajithHomagama
Hashes
Lists
Sets
Sorted Sets
String

34 34
REDIS - STRING
“This is a String Value”
>SET stringvalue “This is a String Value”>OK
>GET stringvalue>“This is a String Value”

35 35
REDIS - LISTS
>LPUSH customer Hansa>(integer)1>LPUSH customer Hasangi>(integer)2>RPUSH customer Rajith>(integer)3>LPUSH customer Hasangi>(integer)4>RPUSH customer Hijas>(integer)5
>LRANGE customer 0 41) “Hasangi”2) “Hasangi”3) “Hansa”4) “Rajith”5) “Hijas”
Hasangi Hasangi Hansa HijasRajith

36 36
REDIS - SETS
>SADD customer Hansa>(integer)1>SADD customer Hasangi>(integer)1>SADD customer Rajith>(integer)1>SADD customer Hasangi>(integer)0>SADD customer Hijas>(integer)1
>SMEMBERS customer1) “Hijas”2) “Rajith”3) “Hasangi”4) “Hansa”
HasangiHansa HijasRajith
37 37
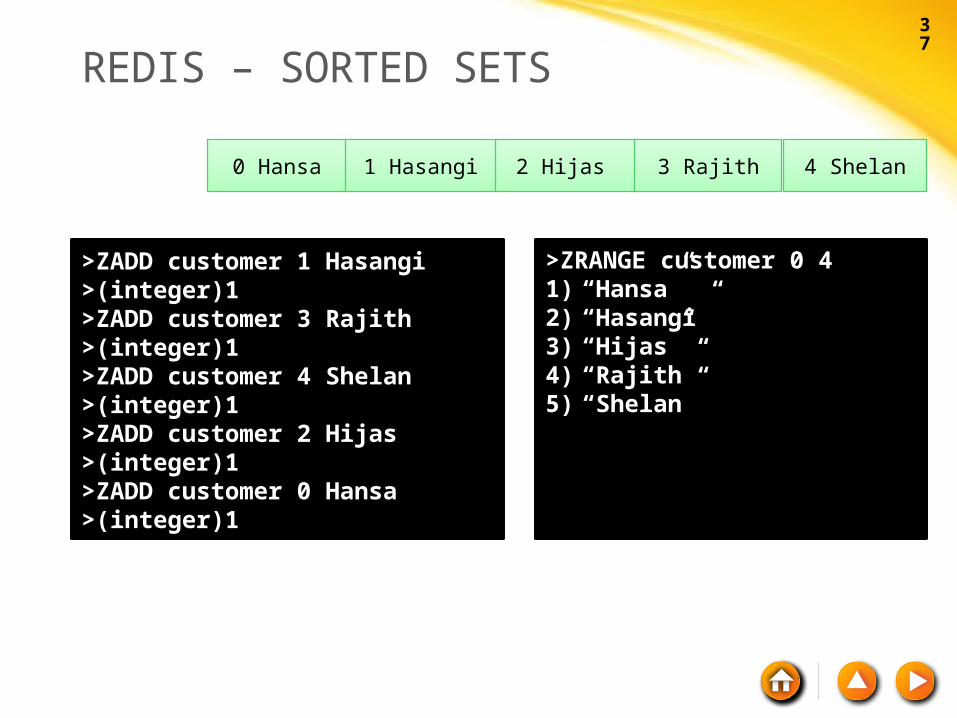
REDIS – SORTED SETS
>ZADD customer 1 Hasangi>(integer)1>ZADD customer 3 Rajith>(integer)1>ZADD customer 4 Shelan>(integer)1>ZADD customer 2 Hijas>(integer)1>ZADD customer 0 Hansa>(integer)1
>ZRANGE customer 0 41) “Hansa”2) “Hasangi”3) “Hijas”4) “Rajith”5) “Shelan”
0 Hansa 1 Hasangi 2 Hijas 4 Shelan3 Rajith

38 38
REDIS - HASHES
>HMSET customer:1 name “Shelan” address “Beruwala”>OK>HMSET customer:2 name “Rajith” address “Homagama”>OK
>HGETALL customer:11) “name”2) “Shelan”3) “address”4) “Beruwala”
namecustomer:1
addressShelan
Beruwala
customer:2name
addressRajith
Homagama
>HGETALL customer:21) “name”2) “Rajith”3) “address”4) “Homagama”

39 39
REDIS – PUBS/SUBS
o Publish and Subscribe to message Channels
o Publisher/s can Subscribe to a channel/s
Publisher
Subscriber SubscriberSubscriber
“RedisChat” ChannelHi, I’m
RedisChat Publisher
Publisher
I’m Another RedisChat Publisher

40 40
REDIS – TRANSACTIONS
o Execute group of command in a single step
o Has 2 properties
o All commands in a transaction are sequentially executed as a single isolated operation
o Redis transaction is also atomic
>MULTI>INCRBY accountA -50>QUEUED>INCRBY accountB +50>QUEUED>EXEC>(integer)50>(integer)150
>SET accountA 100>OK>SET accountB 100>OK>GET accountA >”100”>GET accountB>”100” >GET accountA >”50”>GET accountB>”150”

41 41
REDIS – DISK PERSISTENCE
o Point-in-time snapshot of all dataset
o Compact, ideal for regular backup/archive
o Multiple save-points available
o Faster restarts compared to AOF
o Very good for disaster recovery
o Writes every command like a tape
o Gets re-written when it gets too big
o Can be easily parsed & edited
o AOF files bigger than RDB files
o Slower than RDB
RDB Persistence AOF Persistence

42 42
REDIS – REPLICATIONo Use asynchronous replication
o A master can have multiple slaves
o Slaves accept connection from other slaves
o Non-blocking on both master and slave side
o Redis Sentinel
Redis Master
Redis Slave
Sentinel
Redis Master
Redis Slave Redis Slave
Redis SlaveRedis Slave
• Automatic Failover
• Monitoring
• Notification
• Configuration Provider
High AvailabilityScalability

43 43
WIDE-COLUMN STORE DATABASES
o Stores data as sections of columns of data rather than rows of data
o Ability to hold very large numbers of dynamic columns
o Benefit of storing data in columns, is fast search/ access and data aggregation
o Advantages for data warehouses, customer relationship management (CRM) systems.
o A wide variety of companies and organizations use Hadoop for both research and production.

44 44
HADOOP
o Its not a software. Its a framework of tools.
o Objective is to running applications on big data.
o Open source set of tools distributed under Apache license.
o A distributed file system (HDFS)
o An environment to run Map-Reduce tasks – typically Batch mode
o NOSQL Database – HBase
o Real Time Query Engine (Impala)

45 45
HADOOP’S APPROACH
Big Data is broken into pieces
Computation
Computation
Computation
Computation
Combined Result

46 46
HADOOP ARCHITECTURE
Map Reduce
File System(HDFS)
Projects(Set of Hadoop Tools)
AmbariCassandr
aHBase Mahout Spark
ZooKeeper

47 47
HADOOP DISTRIBUTED MODEL
Commodity Hardware
Task Tracker
Data Node
Task Tracker
Data Node
Task Tracker
Data Node
Task Tracker
Data Node
Slave Computers
Task Tracker
Data Node
Job Tracker
Name Node
Master Computer/s

48 48
HADOOP DISTRIBUTED MODEL
Commodity Hardware
Task Tracker
Data Node
Task Tracker
Data Node
Task Tracker
Data Node
Task Tracker
Data Node
Slave Computers
Task Tracker
Data Node
Job Tracker
Name Node
Master Computer/s

49 49
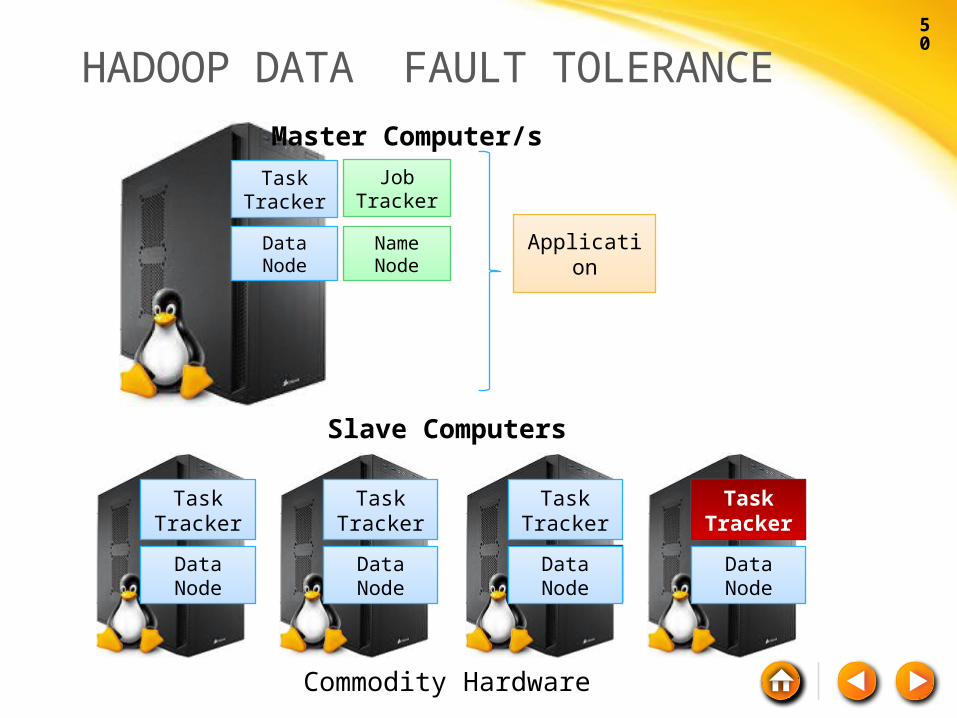
HADOOP DATA ACCESS
Commodity Hardware
Task Tracker
Data Node
Task Tracker
Data Node
Task Tracker
Data Node
Task Tracker
Data Node
Slave Computers
Task Tracker
Data Node
Job Tracker
Name Node
Master Computer/s
Application
50 50
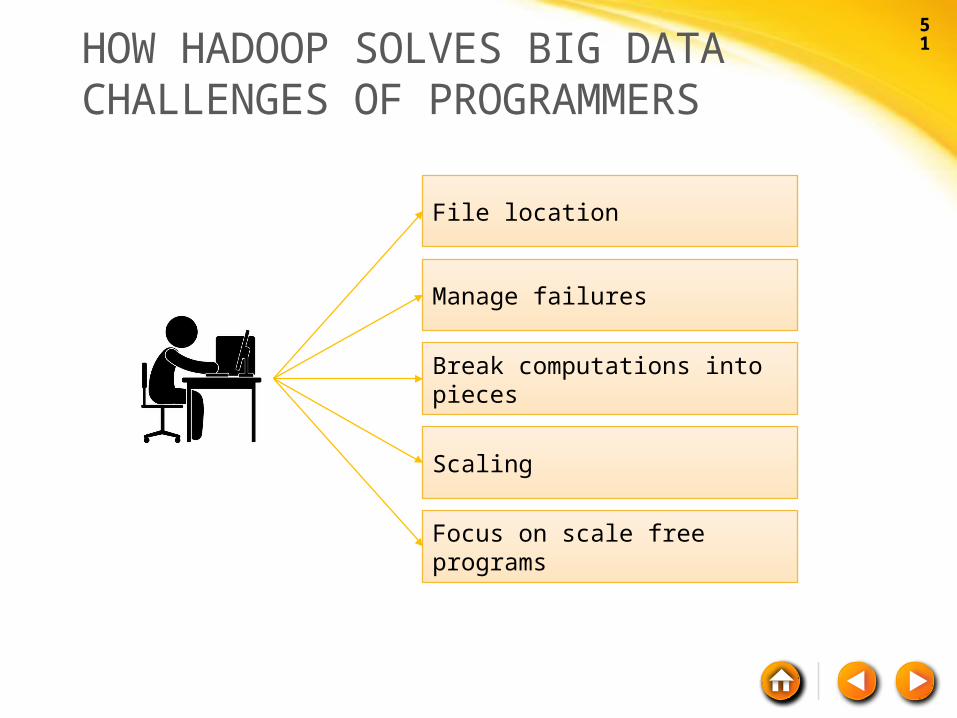
HADOOP DATA FAULT TOLERANCE
Commodity Hardware
Task Tracker
Data Node
Task Tracker
Data Node
Task Tracker
Task Tracker
Data Node
Slave Computers
Task Tracker
Data Node
Job Tracker
Name Node
Master Computer/s
Application
Data NodeData NodeData Node
Task Tracker
51 51HOW HADOOP SOLVES BIG DATA
CHALLENGES OF PROGRAMMERS
File location
Manage failures
Break computations into pieces
Scaling
Focus on scale free programs

52 52
SCALABILITY
No of Computers
Pro
cess
ing
Sp
ee
d
… …
Master
Slave
Cost

53 53
HBASE
An open-source, distributed, versioned, non-relational database modeled after Google's Big Table.
Features
o Linear and modular scalability.
o Strictly consistent reads and writes.
o Automatic and configurable sharding of tables
o Automatic failover support between Region Servers.
o Convenient base classes for backing Hadoop MapReduce jobs with Apache HBase tables.
o Easy to use Java API for client access.
o Block cache and Bloom Filters for real-time queries.

54 54
What is a Graph ?
Follows
Shelan
Hansa
Follows
HijazFollows
Follows
Hasangi Follows
Follows
@Hansa #nosql
Writes To
GRAPH DATABASES

55 55
What is a Graph Database?Database that uses graph structures to represent & store data.
Key-Featureso Excellent in dealing with relationships
o High Performance
o Flexible
o Query language support
RajithName:RajithCity:KottawaMarried:false
Works forSince:2014/11/24
VirtusaName:VirtusaCity:Colombo
GRAPH DATABASES
56 56
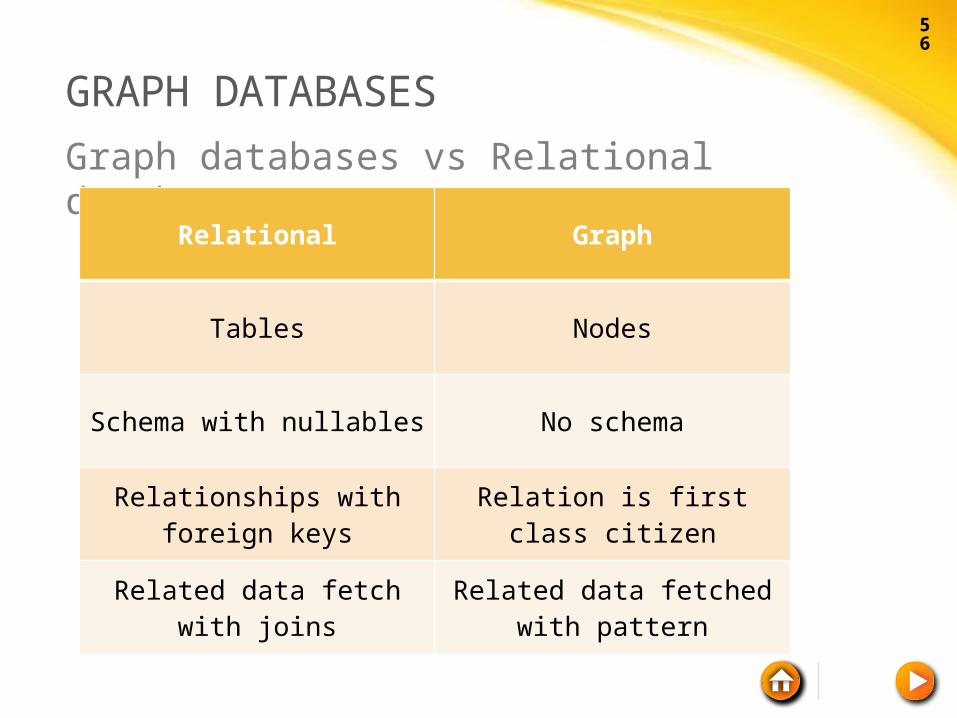
GRAPH DATABASES
Graph databases vs Relational databases
Relational Graph
Tables Nodes
Schema with nullables No schema
Relationships with foreign keys
Relation is first class citizen
Related data fetch with joins
Related data fetched with pattern

57 57
NEO4J
ACIDGraph
DB JAVAEnterprise Features
Billions of
EntitiesRest API

58 58
NEO4J
What is Cypher?
Graph Query
LanguageDeclarative Pattern
matchingClauses

59 59
NEO4J
Cypher Basic Syntax
(a) - [ r ] - > (b)
a br
nodesrelation

60 60
NEO4J - CYPHER
Node with properties
( a { name : “rajith”, born : 1989 } )
Relationships with properties
( a ) - [:WORKED_IN { roles:[“ASE”] } ] - > ( b )
Labels
( a : Person { name: “rajith”} )

61 61
NEO4J - CYPHERQuering with Cypher
MATCH ( a ) - - > ( b )
RETURN a, b;
MATCH ( a ) – [ r ] – > ( b )
RETURN a.name, type ( r );
Using Clauses
MATCH ( a : Person)
WHERE a.name = “rajith”
RETURN a;

62 62
DOCUMENT STORE
o A collection of documents
o Data in this model is stored inside documents.
o A document is a key value collection where the key allows access to its value.
o Documents are not typically forced to have a schema and therefore are flexible and easy to change.
o Documents are stored into collections in order to group different kinds of data.
o Documents can contain many different key-value pairs, or key-array pairs, or even nested documents.
o Usually use JSON (BSON) like interchange model then application logic can be write easily.

63 63
WHAT IS MONGODB ?
o Scalable High-Performance Open-source, Document-orientated database written in C++.
o Built for Speed
o Rich Document based queries for Easy readability
o Full Index Support for High Performance
o Replication and Failover for High Availability
o Auto Sharding for Easy Scalability.
o Map / Reduce for Aggregation.

64 64
KEYWORDS COMPARISON
RDBMS MongoDB
Database Database
Table, View
Collection
Row Document (JSON, BSON)
Column Field
Index Index
Join Embedded Document
Foreign Key
Reference
Partition Shard
> db.user.findOne({age:39}){ "_id" : ObjectId("5114e0bd42…"), "first" : "John", "last" : "Doe", "age" : 39, "interests" : [ "Reading", "Mountain Biking ] "favorites": { "color": "Blue", "sport": "Soccer"} }

65 65
MONGODB ADVANCED FEATURES
o Replication
o Indexing
o Aggregation
o Sharding
o Capped Collections

66 66
REPLICATION
o Replication is the process of synchronizing data across multiple servers
o Replication provides redundancy and increases data availability
Primary DB
Secondary DB
Arbiter DB
Minimum Replica set in MongoDB
REPLICA SET
67 67
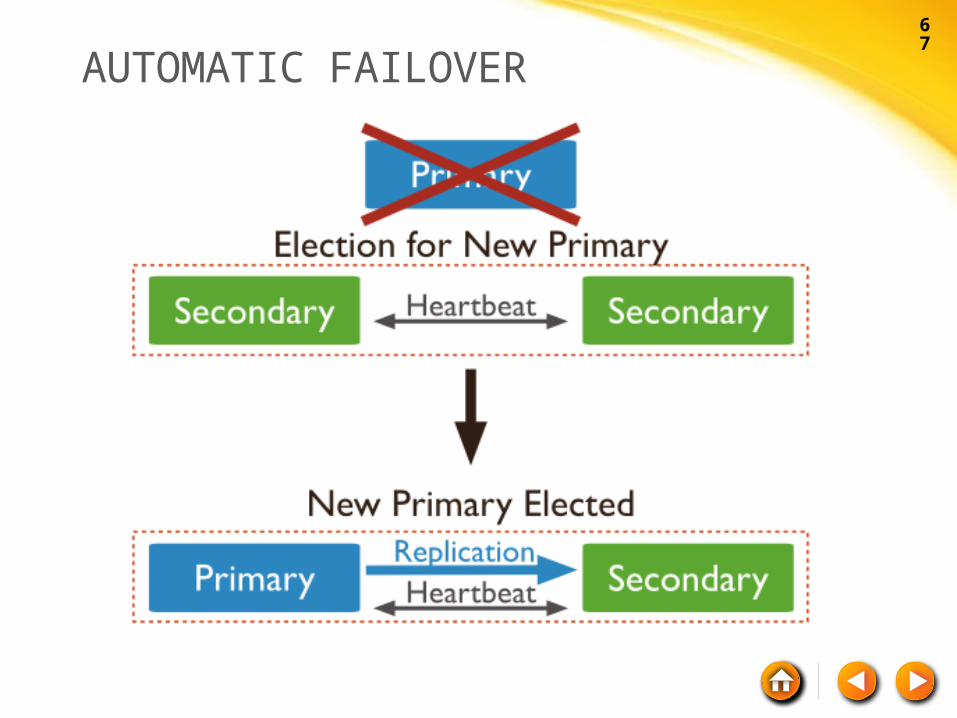
AUTOMATIC FAILOVER

68 68INDEXING
o Indexes support the efficient execution of queries in MongoDB
o MongoDB can use the index to limit the number of documents it must inspect
o Indexes use a B-tree data structure.o Using “ensureIndex” method can create index.
>db.COLLECtION_NAME.ensureIndex({KEY:1})
o Key is the name of field on which want to create index.o 1 is for ascending order.o -1 is for descending order.
69 69
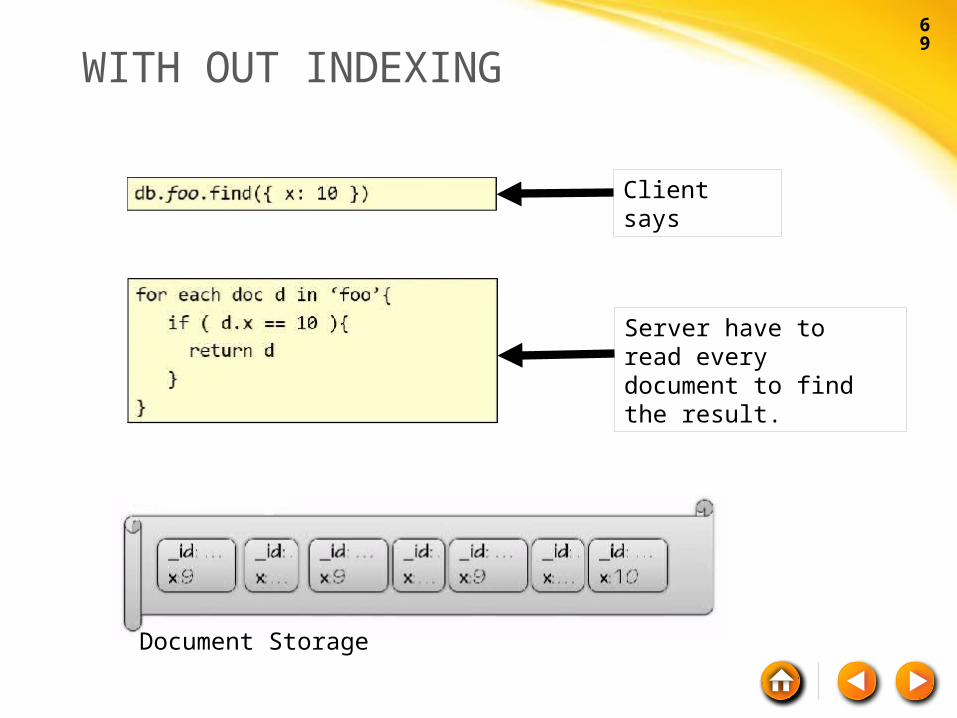
WITH OUT INDEXING
Client says
Server have to read every document to find the result.
Document Storage

70 70
WITH INDEXING

71 71
INDEX TYPES
o Default _id Index
o Single Field Index
o Compound Index
o Multikey Index
o Geo Index
o Text Index
o Hashed Index

72 72
AGGREGATIONS
Aggregations are operations that process data records and return computed results.
MongoDB provides a rich set of aggregation operations.
Aggregation concepts
o Aggregation Pipelines
o Map-Reduce
o Single Purpose Aggregation Operation

73 73
AGGREGATION PIPELINES
The pipeline provides efficient data aggregation using native operations within MongoDB, and is the preferred method for data aggregation in MongoDB
74 74
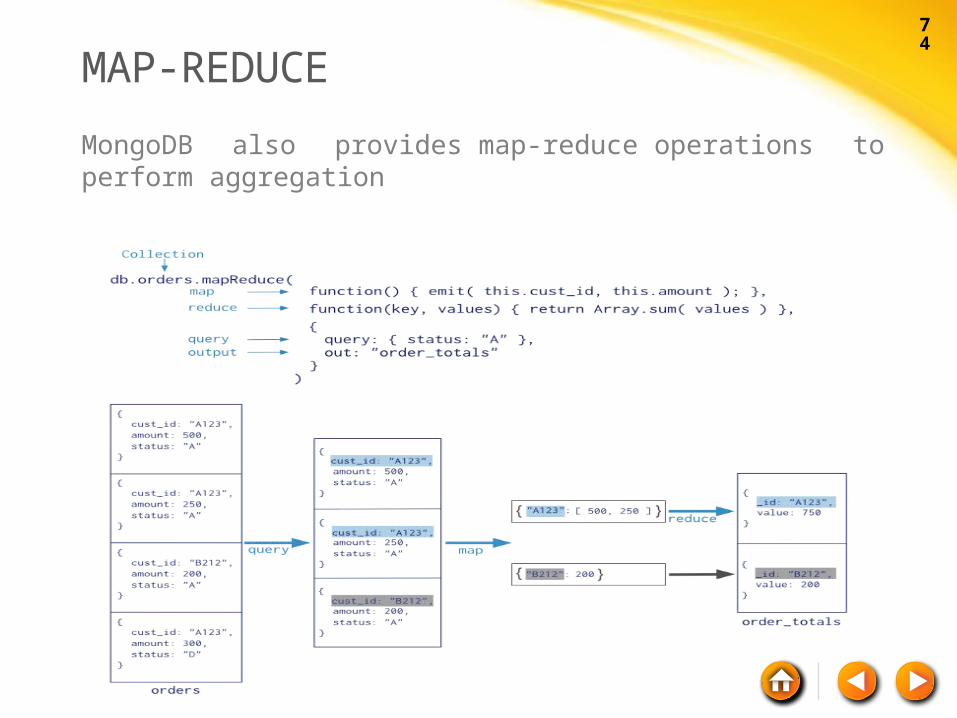
MAP-REDUCE
MongoDB also provides map-reduce operations to perform aggregation

75 75SINGLE PURPOSE AGGREGATION
OPERATIONMongoDB provides special purpose database commands.
All of operations aggregate documents from a single collection.
Common aggregation operations are:
o returning a count of matching documents
o returning the distinct values for a field
o grouping data based on the values of a field

76 76
SHARDING
Sharding is a method for storing data across multiple machines.
MongoDB uses sharding to support deployments with very large data sets and high throughput operations.

77 77
CAPPED COLLECTIONS
o It is fixed-size circular collections that follow the insertion order to support high performance for create, read and delete operations.
o Capped collections restrict updates to the documents if the update results in increased document size.
o Capped collections are best for storing log information, cache data or any other high volume data.

78 78
NOSQL DATABASE CATEGORIES
NoSQL Database Categories
Key Value Store
Document Store
Wide Column Store
Graph Databases

79 79
NOSQL DATABASES SUMMARY
Name HBase MongoDB Neo4j Redis
Database model
Wide column store
Document store Graph DBMS Key-value store
Initial release 2008 2009 2007 2009
License Open Source Open Source Open Source Open Source
DBaaS no no no no
Implementation language
Java C++ Java C
Server operating systems
• Linux• Unix• Windows
• Linux• OS X• Solaris• Windows
• Linux• OS X• Windows
• BSD• Linux• OS X• Windows
Data scheme schema-free schema-free schema-free schema-free
Source :-http://db-engines.com/en/system/HBase%3BMongoDB%3BNeo4j%3BRedis

80 80
NOSQL DATABASES SUMMARY
Name HBase MongoDB Neo4j Redis
2nd indexes no yes yes no
SQL no no no no
APIs and other access methods
Java APIRESTful HTTPThrift
proprietary protocol using JSON
Cypher query languageJava APIRESTful HTTP
proprietary protocol
Supported programming languages
CC#C++GroovyJavaPHPPythonScala
Actionscript, C, C#, C++, Clojure, ColdFusion, D, Dart, Delphi, Erlang, Go, Groovy, Haskell, Java, JavaScript, Lisp, Lua, MatLab, Perl, PHP, PowerShell, Prolog, Python, R, Ruby, Scala, Smalltalk
.NetClojureGoGroovyJavaJavaScriptPerlPHPPythonRubyScala
C, C#, C++, Clojure, DartErlang, Go, Haskell, JavaJavaScript, Lisp, LuaObjective-C, Perl, PHP, Python, Ruby,Scala, Smalltalk, Tcl
Source :-http://db-engines.com/en/system/HBase%3BMongoDB%3BNeo4j%3BRedis

81 81
NOSQL DATABASES SUMMARY
Name HBase MongoDB Neo4j Redis
Triggers yes no yes no
Partitioning methods Sharding Sharding none Sharding
Replication methods
selectable replication factor
Master-slave replication
Master-slave replication
Master-slave replication
MapReduce yes yes no no
Consistency concepts
• Immediate• Consistency
• Eventual• Consistency• Immediate• Consistency
• Eventual• Consistency
configurable in High Availability
• Cluster setupImmediate Consistency
• Eventual• Consistency
Source :-http://db-engines.com/en/system/HBase%3BMongoDB%3BNeo4j%3BRedis

82 82
NOSQL DATABASES SUMMARY
Name HBase MongoDB Neo4j Redis
Foreign keys no no yes no
Transaction concepts no no ACID optimistic
locking
Concurrency yes yes yes yes
Durability yes yes yes yes
In-memory capabilities yes
User concepts Access Control Lists (ACL)
Access rights for users and roles no
very simple password-based access control
Source :-http://db-engines.com/en/system/HBase%3BMongoDB%3BNeo4j%3BRedis

83 83
THANK YOU