an incremental learning method to support the annotation of workflows with data-to-data relations
TRANSCRIPT

1
An incremental learning method to support the annotation of workflows with data-to-data relations
Enrico Daga, Mathieu d’Aquin, Aldo Gangemi, Enrico Motta
Feedback: @enridaga
20th International Conference on Knowledge Engineering and Knowledge Management Bologna, Italy 19-23 November 2016
http://link.springer.com/chapter/10.1007/978-3-319-49004-5_9
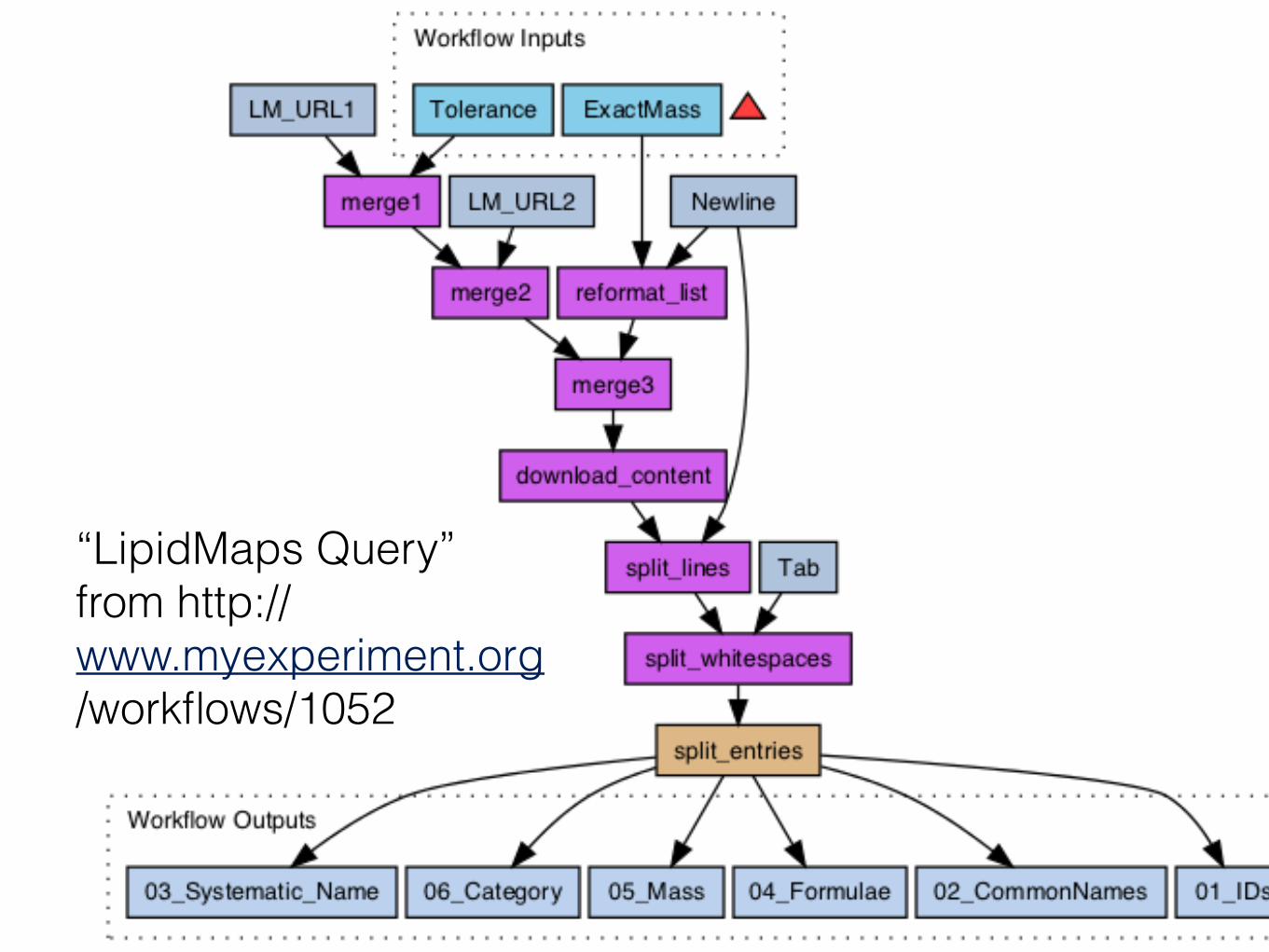
“LipidMaps Query” from http:// www.myexperiment.org /workflows/1052

Workflow models are focused on actions, to support multiple and parametric executions

There are scenarios in which we need to focus on the data…

… and understand how the data is affected by the actions of the workflow.

Data flow (DF): to express the implications of the actions on the data.

Datanode, a taxonomy of the relations between data objects, used for example to support reasoning on policy propagation
http://purl.org/datanode/ns/ Daga, E., d’Aquin, M., Gangemi, A., Motta, E.: Propagation of policies in rich data flows. In: Proceedings of the 8th International Conference on Knowledge Capture, K-CAP 2015 http://doi.acm.org/10. 1145/2815833.2815839

8
Our objective is to derive such data flows from the representation of existing workflows.

9
APPROACH: to learn how to label data-to-data relations using the description of the actions in the workflow.
ASSUMPTION: there is a correlation between the features of a workflow action and the labels.
PROBLEM: Cold start - this requires a pre-existing training set, that we do not have!

10
Incremental learning method

11
HYPOTHESIS: the quality of the recommendations improves in time

12

13
WORKFLOW to DATA FLOW
Arcs =
I/O port pairs (1->3 ; 2->3)
1234 Workflows from www.myexperiments.org = 30612 I/O port pairs
14
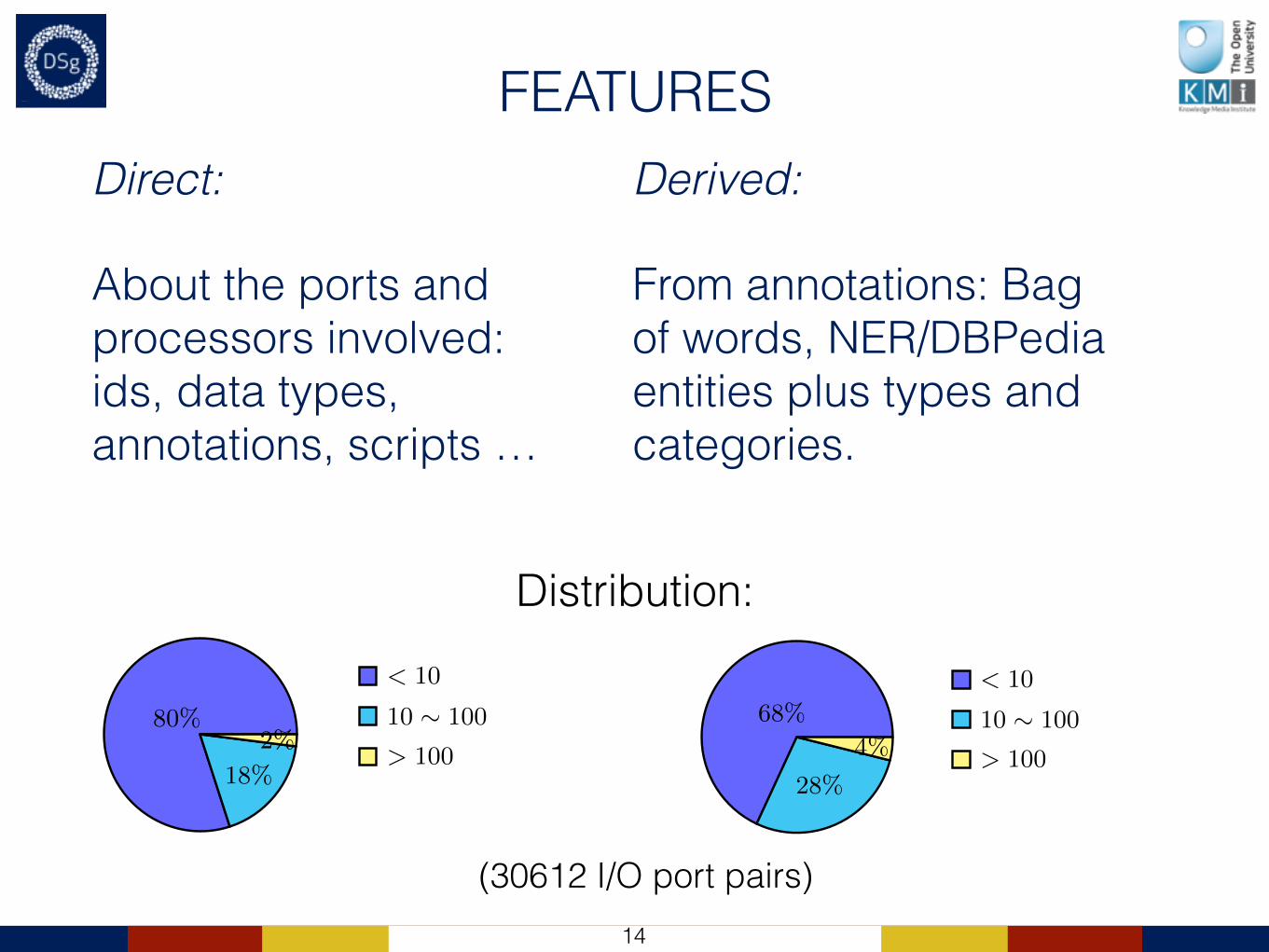
FEATURESDirect:
About the ports and processors involved: ids, data types, annotations, scripts …
Derived:
From annotations: Bag of words, NER/DBPedia entities plus types and categories.
An incremental learning method to support the annotation of workflows 7
Table 2. Example of derived features (bag of words and DBPedia entities) generatedfor the IO port pair 1 ! 3.
Type ValueFrom/FromPortName-word stringTo/ToPortName-word splitFrom/FromLinkedPortDescription-word singleFrom/FromLinkedPortDescription-word possibilitiesFrom/FromLinkedPortDescription-word orbFrom/FromLinkedPortDescription-word massFromToPorts/DbPediaType wgs84:SpatialThingFromToPorts/DbPediaType resource:Text fileFromToPorts/DbPediaType resource:MassFromToPorts/DbPediaType Category:State functionsFromToPorts/DbPediaType Category:Physical quantitiesFromToPorts/DbPediaType Category:Mathematical notation
80%
18%
2%
< 10
10 ⇠ 100
> 100
Fig. 4. Distribution of features ex-tracted from the workflow descriptions.
68%
28%
4%
< 10
10 ⇠ 100
> 100
Fig. 5. Distribution of features (includ-ing derived features).
3.3 Retrieval of association rules and generation of
recommendations
Generating recommendations usually requires an annotated corpus to be avaial-able as training set. While repositories of workflows (especially scientific work-flows) exist, they are not annotated with data-to-data relations. In order toovercome this problem we opted for an incremental approach, where the recom-mendations are produced according to the available annotated items on demand.The rules needed are of the following form:
(f1, f2, ..., fn) ! (a1, a2, ..., an)
where f1, .., fn are the features of the IO port pairs and a1, .., an are the data-to-data relations used to annotate them. Our approach relies on extracting as-sociation rules from a concept lattice built through FCA incrementally. Sucha lattice is built on a formal context of items and attributes. In FCA terms,the items are the IO port pairs and the attributes their features as well as thechosen annotations. Each node of the FCA lattice is a closed concept, mappinga set of items all having a given set of attributes. A FCA concept would thenbe a collection of IO port pairs all having a given set of features and/or annota-tions. In a FCA lattice, concepts are ordered from the top concept (supremum),including all items and (usually) no shared features, to the bottom concept (in-fimum), including all the available features and a (possibly) empty set of items.The lattice is built incrementally using the Godin algorithm [12]. The algorithm
An incremental learning method to support the annotation of workflows 7
Table 2. Example of derived features (bag of words and DBPedia entities) generatedfor the IO port pair 1 ! 3.
Type ValueFrom/FromPortName-word stringTo/ToPortName-word splitFrom/FromLinkedPortDescription-word singleFrom/FromLinkedPortDescription-word possibilitiesFrom/FromLinkedPortDescription-word orbFrom/FromLinkedPortDescription-word massFromToPorts/DbPediaType wgs84:SpatialThingFromToPorts/DbPediaType resource:Text fileFromToPorts/DbPediaType resource:MassFromToPorts/DbPediaType Category:State functionsFromToPorts/DbPediaType Category:Physical quantitiesFromToPorts/DbPediaType Category:Mathematical notation
80%
18%
2%
< 10
10 ⇠ 100
> 100
Fig. 4. Distribution of features ex-tracted from the workflow descriptions.
68%
28%
4%
< 10
10 ⇠ 100
> 100
Fig. 5. Distribution of features (includ-ing derived features).
3.3 Retrieval of association rules and generation of
recommendations
Generating recommendations usually requires an annotated corpus to be avaial-able as training set. While repositories of workflows (especially scientific work-flows) exist, they are not annotated with data-to-data relations. In order toovercome this problem we opted for an incremental approach, where the recom-mendations are produced according to the available annotated items on demand.The rules needed are of the following form:
(f1, f2, ..., fn) ! (a1, a2, ..., an)
where f1, .., fn are the features of the IO port pairs and a1, .., an are the data-to-data relations used to annotate them. Our approach relies on extracting as-sociation rules from a concept lattice built through FCA incrementally. Sucha lattice is built on a formal context of items and attributes. In FCA terms,the items are the IO port pairs and the attributes their features as well as thechosen annotations. Each node of the FCA lattice is a closed concept, mappinga set of items all having a given set of attributes. A FCA concept would thenbe a collection of IO port pairs all having a given set of features and/or annota-tions. In a FCA lattice, concepts are ordered from the top concept (supremum),including all items and (usually) no shared features, to the bottom concept (in-fimum), including all the available features and a (possibly) empty set of items.The lattice is built incrementally using the Godin algorithm [12]. The algorithm
Distribution:
(30612 I/O port pairs)

15
FEATURESAn incremental learning method to support the annotation of workflows 7
Table 2. Example of derived features (bag of words and DBPedia entities) generatedfor the IO port pair 1 ! 3.
Type ValueFrom/FromPortName-word stringTo/ToPortName-word splitFrom/FromLinkedPortDescription-word singleFrom/FromLinkedPortDescription-word possibilitiesFrom/FromLinkedPortDescription-word orbFrom/FromLinkedPortDescription-word massFromToPorts/DbPediaType wgs84:SpatialThingFromToPorts/DbPediaType resource:Text fileFromToPorts/DbPediaType resource:MassFromToPorts/DbPediaType Category:State functionsFromToPorts/DbPediaType Category:Physical quantitiesFromToPorts/DbPediaType Category:Mathematical notation
80%
18%
2%
< 10
10 ⇠ 100
> 100
Fig. 4. Distribution of features ex-tracted from the workflow descriptions.
68%
28%
4%
< 10
10 ⇠ 100
> 100
Fig. 5. Distribution of features (includ-ing derived features).
3.3 Retrieval of association rules and generation of
recommendations
Generating recommendations usually requires an annotated corpus to be avaial-able as training set. While repositories of workflows (especially scientific work-flows) exist, they are not annotated with data-to-data relations. In order toovercome this problem we opted for an incremental approach, where the recom-mendations are produced according to the available annotated items on demand.The rules needed are of the following form:
(f1, f2, ..., fn) ! (a1, a2, ..., an)
where f1, .., fn are the features of the IO port pairs and a1, .., an are the data-to-data relations used to annotate them. Our approach relies on extracting as-sociation rules from a concept lattice built through FCA incrementally. Sucha lattice is built on a formal context of items and attributes. In FCA terms,the items are the IO port pairs and the attributes their features as well as thechosen annotations. Each node of the FCA lattice is a closed concept, mappinga set of items all having a given set of attributes. A FCA concept would thenbe a collection of IO port pairs all having a given set of features and/or annota-tions. In a FCA lattice, concepts are ordered from the top concept (supremum),including all items and (usually) no shared features, to the bottom concept (in-fimum), including all the available features and a (possibly) empty set of items.The lattice is built incrementally using the Godin algorithm [12]. The algorithm
An incremental learning method to support the annotation of workflows 7
Table 2. Example of derived features (bag of words and DBPedia entities) generatedfor the IO port pair 1 ! 3.
Type ValueFrom/FromPortName-word stringTo/ToPortName-word splitFrom/FromLinkedPortDescription-word singleFrom/FromLinkedPortDescription-word possibilitiesFrom/FromLinkedPortDescription-word orbFrom/FromLinkedPortDescription-word massFromToPorts/DbPediaType wgs84:SpatialThingFromToPorts/DbPediaType resource:Text fileFromToPorts/DbPediaType resource:MassFromToPorts/DbPediaType Category:State functionsFromToPorts/DbPediaType Category:Physical quantitiesFromToPorts/DbPediaType Category:Mathematical notation
80%
18%
2%
< 10
10 ⇠ 100
> 100
Fig. 4. Distribution of features ex-tracted from the workflow descriptions.
68%
28%
4%
< 10
10 ⇠ 100
> 100
Fig. 5. Distribution of features (includ-ing derived features).
3.3 Retrieval of association rules and generation of
recommendations
Generating recommendations usually requires an annotated corpus to be avaial-able as training set. While repositories of workflows (especially scientific work-flows) exist, they are not annotated with data-to-data relations. In order toovercome this problem we opted for an incremental approach, where the recom-mendations are produced according to the available annotated items on demand.The rules needed are of the following form:
(f1, f2, ..., fn) ! (a1, a2, ..., an)
where f1, .., fn are the features of the IO port pairs and a1, .., an are the data-to-data relations used to annotate them. Our approach relies on extracting as-sociation rules from a concept lattice built through FCA incrementally. Sucha lattice is built on a formal context of items and attributes. In FCA terms,the items are the IO port pairs and the attributes their features as well as thechosen annotations. Each node of the FCA lattice is a closed concept, mappinga set of items all having a given set of attributes. A FCA concept would thenbe a collection of IO port pairs all having a given set of features and/or annota-tions. In a FCA lattice, concepts are ordered from the top concept (supremum),including all items and (usually) no shared features, to the bottom concept (in-fimum), including all the available features and a (possibly) empty set of items.The lattice is built incrementally using the Godin algorithm [12]. The algorithm
6 E. Daga, M. d’Aquin, A. Gangemi, E. Motta
Fig. 3. This processor has three ports: two input ports (1 and 2) and one output port(3). We can translate this model into a graph connecting the data objects of the inputsto the one of the output.
Table 1. Sample of the features extracted for the IO port pair 1 ! 3 in the exampleof Figure 3.
Type ValueFrom/FromPortName stringTo/ToPortName splitActivity/ActivityConfField scriptActivity/ActivityType http://ns.taverna.org.uk/2010/
activity/beanshell
Activity/ActivityName reformat listActivity/ConfField/derivedFrom http://ns.taverna.org.uk/2010/
activity/localworker/org.embl.
ebi.escience.scuflworkers.java.
SplitByRegex
Activity/ConfField/script List split = new ArrayList();if(!string.equals(””)) { String regexString =”,”; if (regex != void) ...
Processor/ProcessorType ProcessorProcessor/ProcessorName reformat list
However, the objective of these feature sets is to support the clustering ofthe annotated IO port pair through finding similarities with IO port pairs to beannotated. At this stage of the study we performed a preliminary evaluation ofthe distribution of the features extracted. We discovered that very few of themwere shared between a significant number of port pairs (see Figure 4). In orderto increase the number of shared features we generated a set of derived fea-tures by extracting bags of words from lexical feature values and by performingNamed Entity Recognition on the features that constituted textual annotations(labels and comments), when present. Moreover, from the extracted entities wealso added the related DBPedia categories and types as additional features. Asexample, Table 2 shows a sample of the bag of words and entities extracted fromthe features listed in the previous Table 1.
The generation of derived features increased the number of total featuressignificantly (up to 59217), while making the distribution of features less sparse,as reported in Figure 5.
An incremental learning method to support the annotation of workflows 7
Table 2. Example of derived features (bag of words and DBPedia entities) generatedfor the IO port pair 1 ! 3.
Type ValueFrom/FromPortName-word stringTo/ToPortName-word splitFrom/FromLinkedPortDescription-word singleFrom/FromLinkedPortDescription-word possibilitiesFrom/FromLinkedPortDescription-word orbFrom/FromLinkedPortDescription-word massFromToPorts/DbPediaType wgs84:SpatialThingFromToPorts/DbPediaType resource:Text fileFromToPorts/DbPediaType resource:MassFromToPorts/DbPediaType Category:State functionsFromToPorts/DbPediaType Category:Physical quantitiesFromToPorts/DbPediaType Category:Mathematical notation
80%
18%
2%
< 10
10 ⇠ 100
> 100
Fig. 4. Distribution of features ex-tracted from the workflow descriptions.
68%
28%
4%
< 10
10 ⇠ 100
> 100
Fig. 5. Distribution of features (includ-ing derived features).
3.3 Retrieval of association rules and generation of
recommendations
Generating recommendations usually requires an annotated corpus to be avaial-able as training set. While repositories of workflows (especially scientific work-flows) exist, they are not annotated with data-to-data relations. In order toovercome this problem we opted for an incremental approach, where the recom-mendations are produced according to the available annotated items on demand.The rules needed are of the following form:
(f1, f2, ..., fn) ! (a1, a2, ..., an)
where f1, .., fn are the features of the IO port pairs and a1, .., an are the data-to-data relations used to annotate them. Our approach relies on extracting as-sociation rules from a concept lattice built through FCA incrementally. Sucha lattice is built on a formal context of items and attributes. In FCA terms,the items are the IO port pairs and the attributes their features as well as thechosen annotations. Each node of the FCA lattice is a closed concept, mappinga set of items all having a given set of attributes. A FCA concept would thenbe a collection of IO port pairs all having a given set of features and/or annota-tions. In a FCA lattice, concepts are ordered from the top concept (supremum),including all items and (usually) no shared features, to the bottom concept (in-fimum), including all the available features and a (possibly) empty set of items.The lattice is built incrementally using the Godin algorithm [12]. The algorithm
Direct: Derived:
Distribution:
(30612 I/O port pairs)

16

17
Formal Concept Analysis (FCA)
• FCA is a clustering method for association rule mining • Lattice of ordered closed item sets - concepts • Item: I/O port pair <-> features + annotations• FCA Concept:
• Extent (I/O port pairs) • Intent (features, annotations)
• Incremental lattice construction (Godin algorithm). • Lattice is reconstructed on each item addition.

18
Step 0At the beginning, the user adds a single item, without support. The lattice contains a single concept.

19
Step 1By adding new annotations, the lattice allows to derive association rules.
(f1, f2, ..., fn) → (a1, a2, ..., an)

20
Step 2By adding new annotations, the lattice grows… allowing to generate recommendations.
(f1, f2, ..., fn) → (a1, a2, ..., an)

21
Step 3By adding new annotations, the lattice grows… allowing to generate more recommendations.
(f1, f2, ..., fn) → (a1, a2, ..., an)
22
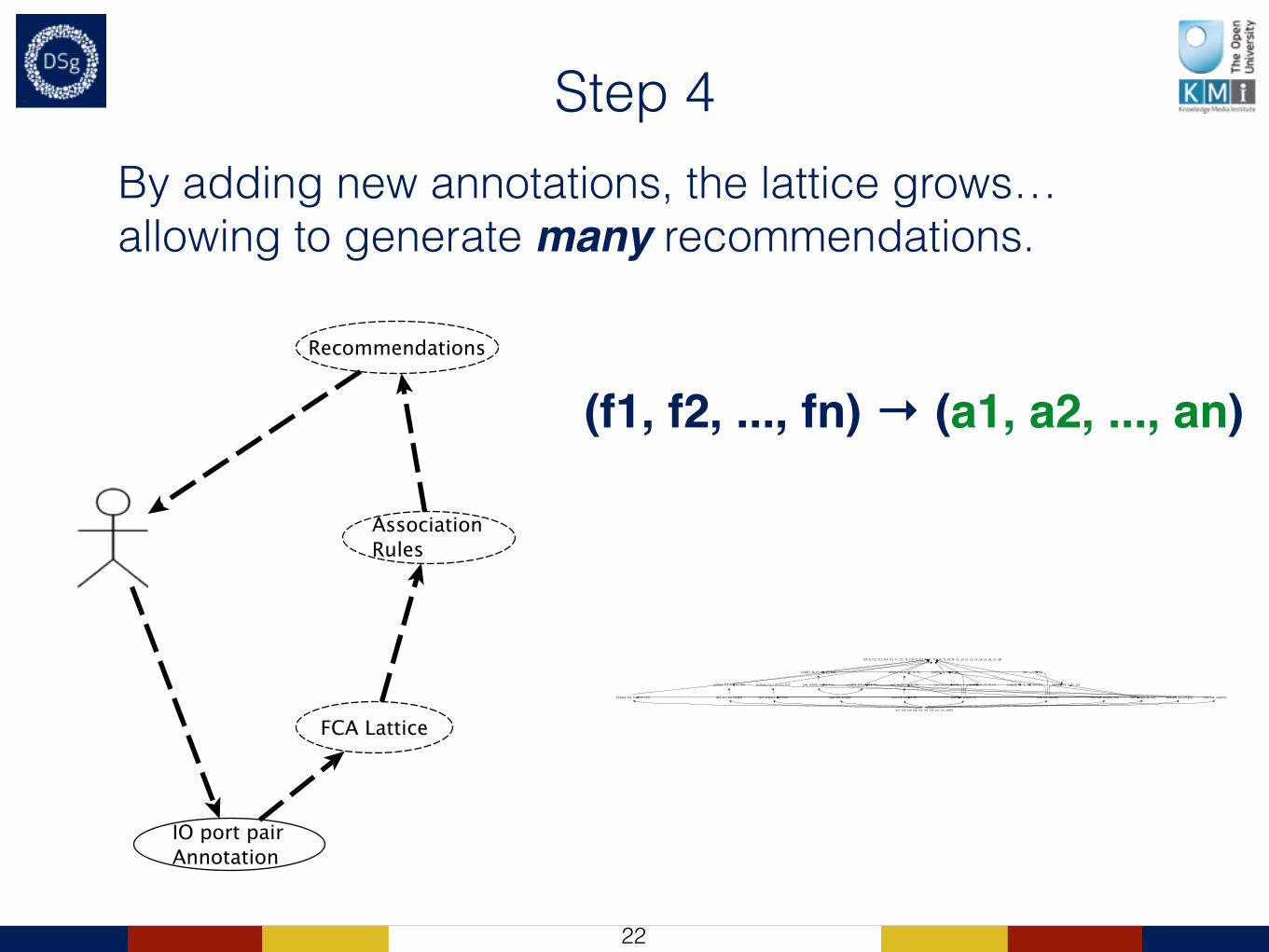
Step 4By adding new annotations, the lattice grows… allowing to generate many recommendations.
(f1, f2, ..., fn) → (a1, a2, ..., an)

23
ASSOCIATION RULE MINING
Generating all association rules on each iteration is expensiveWe query the lattice to retrieve only rules applicable to a given I/O port pair.• only rules that have annotations in the rule consequence:
• This: (f1, f2, ..., fn) → (a1, a2, ..., an) • Not these: (f1, f2, a6) → (f3, f4), (f1, f2, a6) → (f3, a4)
• avoid redundancies (select the best for a certain head) • rank the rules according to: support, confidence and relevance.
24
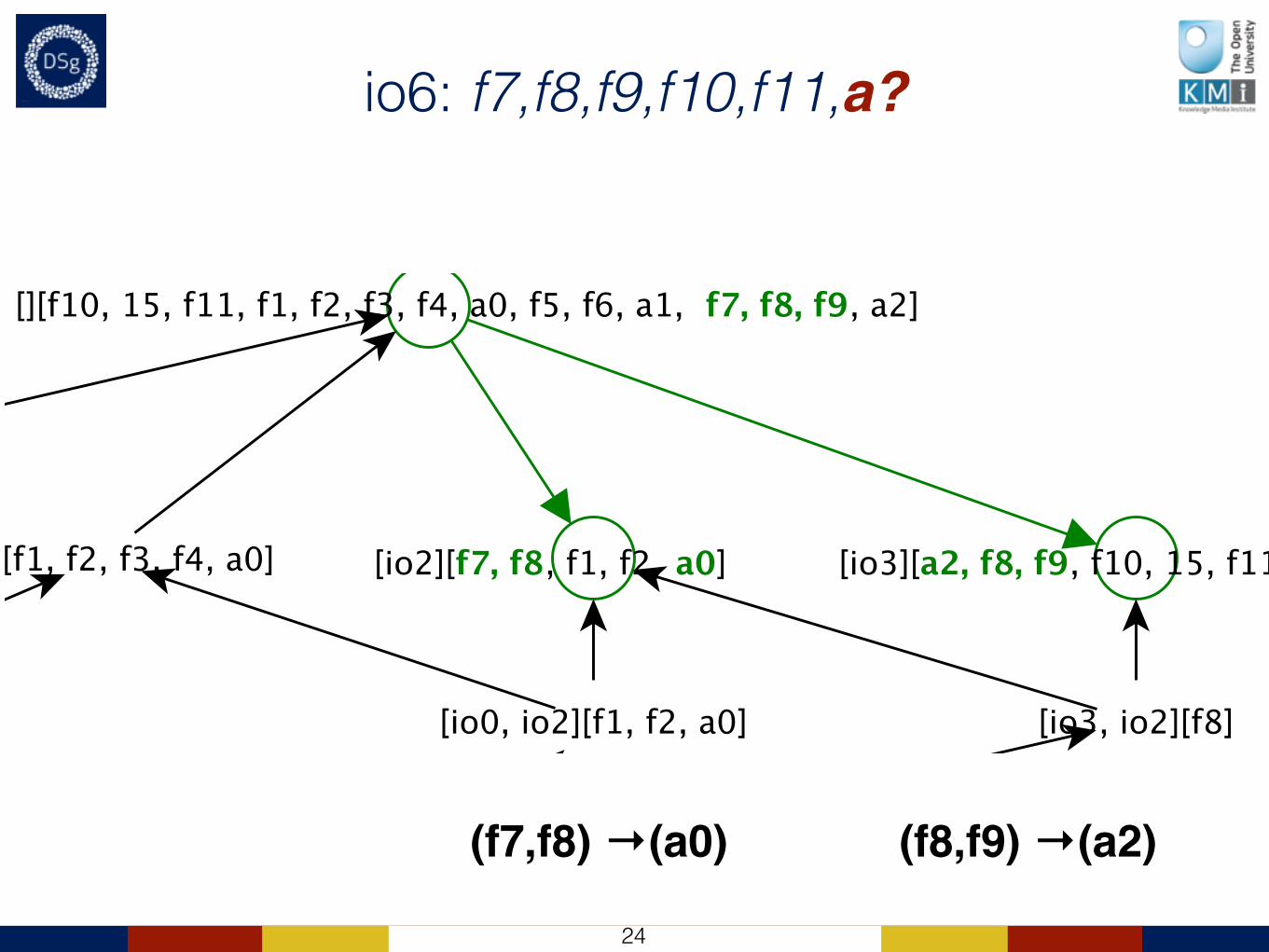
io6: f7,f8,f9,f10,f11,a?
(f7,f8) →(a0) (f8,f9) →(a2)

25
EVALUATION
• Expectation: the quality of the recommendations improves in time.
• EXPERIMENT:
• Dinowolf (Datanode in workflows) http://github.com/enridaga/dinowolf Uses SCUFL2, Apache Taverna, Apache Lucene, DBPedia Spotlight
• 6 users to annotate 20 workflows from www.myexperiments.org for a total of 260 I/O port pairs.

26
RESULTS
140 E. Daga et al.
to complete all portpairs of a workflow before moving to the next; (c) to onlyperform an action when confident of the decision, otherwise to postpone thechoice (using the“Later” action); (d) to select the most specific relation avail-able - for example, to privilege processedInto over hasDerivation, when possible.Each user worked on an independent instance of the tool (and hence lattice) andperformed the annotations without interacting with other participants. Duringthe experiment the system monitored a set of measures:
– the time required to annotate an IO port pair;– how many annotations were selected from recommendations;– the average rank of the recommendations selected, calculated as a percentageof the overall size of the recommendation list; and
– the average of the relevance score of the recommendations selected.
Figures 6, 7, 8 and 9 illustrate the results of our experiments with respect ofthe above measures. In all diagrams, the horizontal axis represents the actionsperformed in chronological order, placing on the left the initial phase of theexperiment going towards the right until all 260 IO port pairs were annotated.The diagrams ignore the actions marked as “Later”, resulting on few jumps inusers’ lines, as we represented in order all actions including at least one annota-tion from at least a single user. Figure 6 shows the evolution of the time spent byeach user on a given annotation page of the tool before a decision was made. Thediagram represents the time (vertical axis) in logarithmic scale, showing how, asmore annotations are made and therefore more recommendations are generated,the effort (time) required to perform a decision is reduced. Figure 7 illustratesthe progress of the ratio of annotations selected from recommendations. Thisincludes cases where a subrelation of a recommended relation has been selectedby the user. While it shows how recommendations have an impact from the verybeginning of the activity, it confirms our hypothesis that the cold-start problemis tackled through our incremental approach. Figure 8 depicts the average rankof selected recommendations. The vertical axis represents the score placing atthe top the first position. This confirms our hypothesis that the quality of rec-ommendations increases, stabilizing within the upper region after a critical massof annotated items is produced, reflecting the same behavior observed in Fig. 7.
20 40 60 80 100 120 140 160 180 200 220 240 260
5s
20s1m
5m10m
Fig. 6. Evolution of the time spent by each user on a given annotation page of the toolbefore a decision was made.
An Incremental Learning Method to Support the Annotation of Workflows 141
20 40 60 80 100 120 140 160 180 200 220 240 2600.00.2
0.50.7
1.0
Fig. 7. Progress of the ratio of annotations selected from recommendations.
20 40 60 80 100 120 140 160 180 200 220 240 260
0.00.2
0.50.7
1.0
Fig. 8. Average rank of selected recommendations. The vertical axis represents thescore placing at the top the first position.
20 40 60 80 100 120 140 160 180 200 220 240 2600.00.2
0.50.7
1.0
Fig. 9. Progress of the average relevance score of picked recommendations.
Finally, we illustrate in Fig. 9 how the average relevance score of picked recom-mendations changes in time. The relevance score, computed as the portion offeatures matching a given recommendation that overlaps with the features of theitem to be annotated, increases partly because the rules become more abstract(contain less features), partly reflecting the behavior of the ranking algorithmand matching the result of Fig. 8.
6 Conclusions
In this article we proposed a novel approach to support the semantic annota-tion of workflows with data centric relations. We showed through applying thisapproach on a set of workflows from the My Experiments repository that itcan effectively reduce the effort required to achieve this task for data managersand workflow publishers. We plan to integrate the presented approach with themethodology described in [4] in order to support Data Hub managers in the anno-tation of the data manipulation processes required to compute the propagation ofpolicies associated with the data involved. We have enough confidence to believe
Time required to make a choice:
Selections from recommendations:Effort reduced.
Cold start problem tackled.

27
RESULTS
An Incremental Learning Method to Support the Annotation of Workflows 141
20 40 60 80 100 120 140 160 180 200 220 240 2600.00.2
0.50.7
1.0
Fig. 7. Progress of the ratio of annotations selected from recommendations.
20 40 60 80 100 120 140 160 180 200 220 240 260
0.00.2
0.50.7
1.0
Fig. 8. Average rank of selected recommendations. The vertical axis represents thescore placing at the top the first position.
20 40 60 80 100 120 140 160 180 200 220 240 2600.00.2
0.50.7
1.0
Fig. 9. Progress of the average relevance score of picked recommendations.
Finally, we illustrate in Fig. 9 how the average relevance score of picked recom-mendations changes in time. The relevance score, computed as the portion offeatures matching a given recommendation that overlaps with the features of theitem to be annotated, increases partly because the rules become more abstract(contain less features), partly reflecting the behavior of the ranking algorithmand matching the result of Fig. 8.
6 Conclusions
In this article we proposed a novel approach to support the semantic annota-tion of workflows with data centric relations. We showed through applying thisapproach on a set of workflows from the My Experiments repository that itcan effectively reduce the effort required to achieve this task for data managersand workflow publishers. We plan to integrate the presented approach with themethodology described in [4] in order to support Data Hub managers in the anno-tation of the data manipulation processes required to compute the propagation ofpolicies associated with the data involved. We have enough confidence to believe
An Incremental Learning Method to Support the Annotation of Workflows 141
20 40 60 80 100 120 140 160 180 200 220 240 2600.00.2
0.50.7
1.0
Fig. 7. Progress of the ratio of annotations selected from recommendations.
20 40 60 80 100 120 140 160 180 200 220 240 260
0.00.2
0.50.7
1.0
Fig. 8. Average rank of selected recommendations. The vertical axis represents thescore placing at the top the first position.
20 40 60 80 100 120 140 160 180 200 220 240 2600.00.2
0.50.7
1.0
Fig. 9. Progress of the average relevance score of picked recommendations.
Finally, we illustrate in Fig. 9 how the average relevance score of picked recom-mendations changes in time. The relevance score, computed as the portion offeatures matching a given recommendation that overlaps with the features of theitem to be annotated, increases partly because the rules become more abstract(contain less features), partly reflecting the behavior of the ranking algorithmand matching the result of Fig. 8.
6 Conclusions
In this article we proposed a novel approach to support the semantic annota-tion of workflows with data centric relations. We showed through applying thisapproach on a set of workflows from the My Experiments repository that itcan effectively reduce the effort required to achieve this task for data managersand workflow publishers. We plan to integrate the presented approach with themethodology described in [4] in order to support Data Hub managers in the anno-tation of the data manipulation processes required to compute the propagation ofpolicies associated with the data involved. We have enough confidence to believe
Rank of selected recommendations:
Relevance score of selected recommendations:
Quality of recommendations increases.

28
CONCLUSIONS• Supporting users on annotating workflows with data-to-data
relations with recommendations is problematic because of the lack of an initial training set (cold start problem). We tackled this issue by means of an incremental learning process that leverages FCA and an information retrieval approach to ARM.
• Future work:
• Integrate this approach in Data Hub metadata management to support policy propagation.
• Study the quality and consistency of annotations.
• Agreement/disagreement between users.
• The solution is domain independent, can be applied to other scenarios.

29
Thank you
Enrico Daga
Feedback: @enridaga
http://link.springer.com/chapter/10.1007/978-3-319-49004-5_9

30
REFERENCES• Daga, E., d’Aquin, M., Adamou, A., Motta, E.: Addressing exploitability of smart city data.
In: 2016 IEEE Second International Smart Cities Conference (ISC2). IEEE (2016)
• Daga, E., d’Aquin, M., Gangemi, A., Motta, E.: Describing semantic web applica- tions through relations between data nodes. Technical report kmi-14-05, Knowledge Media Institute, The Open University, Walton Hall, Milton Keynes (2014). http:// kmi.open.ac.uk/publications/techreport/kmi-14-05
• Daga, E., d’Aquin, M., Gangemi, A., Motta, E.: Propagation of policies in rich data flows. In: Proceedings of the 8th International Conference on Knowledge Capture, K-CAP 2015, New York, NY, USA, pp. 5:1–5:8 (2015). http://doi.acm.org/10. 1145/2815833.2815839
• Godin, R., Missaoui, R., Alaoui, H.: Incremental concept formation algorithms based on galois (concept) lattices. Comput. Intell. 11(2), 246–267 (1995)
• Poelmans,J.,Elzinga,P.,Viaene,S.,Dedene,G.:Formalconceptanalysisinknowl- edge discovery: a survey. In: Croitoru, M., Ferr ́e, S., Lukose, D. (eds.) ICCS 2010. LNCS (LNAI), vol. 6208, pp. 139–153. Springer, Heidelberg (2010). doi:10.1007/ 978-3-642-14197-3 15