an efficient streaming and decoding architecture for stored fgs video yi-shin tung, ja-ling wu,...
Post on 21-Dec-2015
213 views
TRANSCRIPT

An Efficient Streaming and Decoding Architecture for Stored FGS Video
Yi-Shin Tung, Ja-Ling Wu, Po-Kang Hsiao, and Kan-Li Huang
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 12, NO. 8, AUGUST 2002

Outline
Introduction Multiple-Way Bitplane Decoding On-Demand Streaming and Decoding
Scheduling Refined FGS Decoding Architecture
and Experimental Results Conclusions

Introduction
Bitplane decoding’s need for accessing large frame buffer several times.
Enhancement data needs to be queued up until base layer no longer need to be referenced.

Multiple-Way Bitplane Decoding
352*240*5(bits)
352*240(bytes)Add all bitplanes
Inverse zigzag scanIDCT

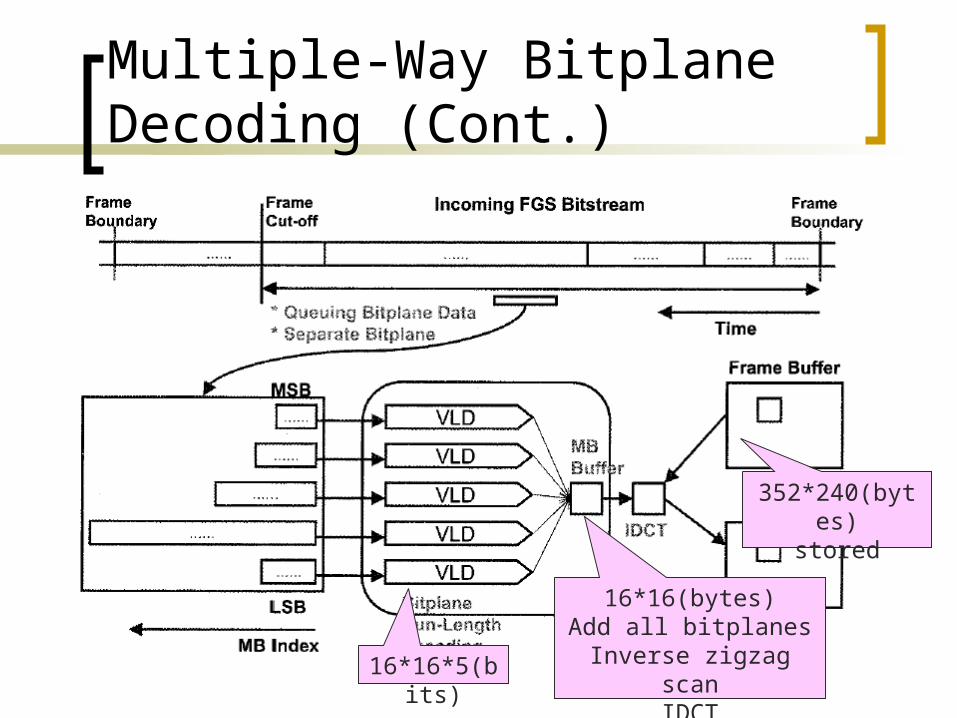
Multiple-Way Bitplane Decoding (Cont.)
When the frame size is large, a cache miss will happen.
Treat all the decoding processes on a macroblock(MB)-basis.
All processes for one MB(VLD, combine bitplanes, idct) are down together and then proceed to the next MB.
Multiple-Way Bitplane Decoding (Cont.)
16*16*5(bits)
16*16(bytes)Add all bitplanes
Inverse zigzag scanIDCT
352*240(bytes)stored

On Demand Streaming and Decoding Scheduling
All FGS-VOPs depend only on their corresponding base-layer VOPs.
In general decoding procedure, we can’t immediately reuse the decoded frame buffer of the base layer.
I B B P
FGSVOP
FGSVOP
FGSVOP
FGSVOP

On Demand Streaming and Decoding Scheduling (Cont.)
The enhancement-layer decoding will be delayed.
The streaming schedule is also modified to save the required decoding buffer.
I B B P
FGSVOP
FGSVOP
FGSVOP
FGSVOP

On Demand Streaming and Decoding Scheduling (Cont.)

On Demand Streaming and Decoding Scheduling (Cont.)

Refined FGS Decoding Architecture and Experimental Results

Refined FGS Decoding Architecture and Experimental Results (Cont.)

Refined FGS Decoding Architecture and Experimental Results (Cont.)

Refined FGS Decoding Architecture and Experimental Results (Cont.)

Conclusions
Remove the bottleneck of cache traffic. The resulting decoding process can
effectively utilize the frame buffers. About 20%~40% performance gain
can be obtained.