an effective approach for maintenance of pre-large-based frequent-itemset lattice in incremental...
TRANSCRIPT

Appl IntellDOI 10.1007/s10489-014-0551-z
An effective approach for maintenance of pre-large-basedfrequent-itemset lattice in incremental mining
Bay Vo · Tuong Le · Tzung-Pei Hong · Bac Le
© Springer Science+Business Media New York 2014
Abstract Incremental mining has attracted the attention ofmany researchers due to its usefulness in online applica-tions. Many algorithms have thus been proposed for incre-mentally mining frequent itemsets. Maintaining a frequent-itemset lattice (FIL) is difficult for databases with largenumbers of frequent itemsets, especially huge databases,due to the storage of links of nodes in the lattice. However,generating association rules from a FIL has been shown tobe more effective than traditional methods such as directlygenerating rules from frequent itemsets or frequent closeditemsets. Therefore, when the number of frequent itemsetsis not huge (i.e., they can be stored in the lattice with-out excessive memory overhead), the lattice-based approach
B. Vo (�) · T. LeDivision of Data Science, Ton Duc Thang University, Ho ChiMinh, Vietname-mail: [email protected]
T. Lee-mail: [email protected]
B. Vo · T. LeFaculty of Information Technology, Ton Duc Thang University,Ho Chi Minh, Vietnam
T.-P. HongDepartment of Computer Science and Information Engineering,National University of Kaohsiung, Kaohsiung, Taiwan,Republic of Chinae-mail: [email protected]
T.-P. HongDepartment of Computer Science and Engineering, National SunYat-sen University, Kaohsiung, Taiwan, Republic of China
B. LeDepartment of Computer Science, University of Science, Ho ChiMinh, Vietname-mail: [email protected]
outperforms approaches which mine association rules fromfrequent itemsets/frequent closed itemsets. However, incre-mental algorithms for building FILs have not yet beenproposed. This paper proposes an effective approach forthe maintenance of a FIL based on the pre-large concept inincremental mining. The building process of a FIL is firstimproved using two proposed theorems regarding the pater-nity relation between two nodes in the lattice. An effectiveapproach for maintaining a FIL with dynamically inserteddata is then proposed based on the pre-large and the diffsetconcepts. The experimental results show that the proposedapproach outperforms the batch approach for building a FILin terms of execution time.
Keywords Data mining · Frequent itemsets · Lattice ·Incremental mining · Pre-large concept
1 Introduction
Association rule mining is an important problem in datamining [1, 2, 7–9, 16, 19–22, 26, 28–30]. For mining asso-ciation rules, existing algorithms are often divided into twodistinct phases: (i) mining frequent (closed) itemsets and (ii)generating the association rules from these frequent (closed)itemsets. Phase (ii) is easily implemented but requires a lotof processing time.
Recently, an approach for quickly generating associationrules using a frequent-(closed)-itemset lattice (FIL/FCIL)has been proposed [23–25]. The process of building anFIL/FCIL requires more time and memory (due to storageof links of nodes in the lattice) than those of the traditionalapproach, which directly mines frequent (closed) itemsets.However, generating association rules from a FIL/FCILis more efficient than doing so from frequent (closed)

B. Vo et al.
itemsets [25] or from frequent itemsets using hash tables[23, 24]. For example, the present authors previouslyshowed [24] that for the Mushroom database with minSup= 20 %, the number of frequent itemsets is 53,583 and thenumber of association rules is 19,191,656 (with minConf =0 %). The runtime for mining frequent itemsets and associ-ation rules from these itemsets is 80.83 s whereas that forFIL building and mining association rules from the FIL is14.13 s. Similarly, for the Chess database with minSup =65 %, the number of frequent itemsets is 111,239 and thenumber of association rules is 26,238,988 (with minConf =0 %). The runtime for mining frequent itemsets and asso-ciation rules from these itemsets is 326.12 s whereas thatfor FIL building and mining the association rules from theFIL is 35.66 s. Therefore, mining association rules basedon a FIL/FCIL is more efficient compared to the tradi-tional approach when both phases of mining are considered.However, for huge databases with large numbers of associa-tion rules, the lattice-based approach for mining associationrules is not the best solution. In that case, ranking andselecting useful rules is necessary [3, 6].
In practical applications, databases are typically incre-mental, meaning that transactions may be inserted. There-fore, mining association rules from incremental databaseshas attracted research interest. The first algorithm for min-ing association rules in incremental databases was Fast-UPdate (FUP) [5], an Apriori-based algorithm, which gener-ates the candidates and repeatedly scans the database. Someefficient methods have since been developed, such as meth-ods based on FP-tree [11, 12, 14], IT-tree [17], FIL/FCIL[15] and other methods [27]. Incremental mining in sequen-tial patterns [4, 13] and in high utility patterns [18] have alsobeen developed.
Hong et al. [10] proposed the pre-large concept (seeSection 2.2) for reducing the need for rescanning the orig-inal database. With this concept, the original database doesnot need to be rescanned if the number of new transactionsis equal to or less than a safety threshold. The maintenancecost is thus reduced with the pre-large concept. Althoughmany algorithms have been developed to maintain the asso-ciation rules in incremental databases, the maintenance ofa FIL in incremental mining has received little attention.Compared to the maintenance of frequent itemsets, that ofa FIL is more complex, with the algorithm having to con-sider the relations among the nodes in the lattice and updatethem. The present study proposes an effective approach forthe maintenance of a FIL. The main contributions are:
1. A structure for quickly building a FIL is proposed.2. Tidset-based maintenance of a pre-large FIL (TMPFIL)
algorithm is developed.3. Diffset-based maintenance of a PFIL (DMPFIL) algo-
rithm is developed.
The rest of the paper is organized as follows. Section 2presents the basic concepts. The DMPFIL algorithm isproposed in Section 3. Section 4 presents the results ofexperiments comparing the execution time of DMPFILwith those of TMPFIL and the FIL building algorithm toshow the effectiveness of the proposed algorithm. Finally,Section 5 summarizes the results and offers some futureresearch topics.
2 Basic concepts
2.1 Frequent-itemset lattice
Consider a database D with n transactions, with each trans-action including a set of items belonging to I , where I isthe set of all items in D. An example transaction databaseD1 is presented in Table 1. The support of an itemset X,denoted by σ (X), where X ∈ I , is the number of transac-tions in D which contain all the items in X. An itemset X iscalled a frequent itemset if σ (X) ≥ minSup × n, where min-Sup is a given threshold. An itemset with k items is called ak-itemset.
Vo and Le [23] proposed an algorithm for building aFIL in which each node in the lattice has the form 〈X,Tidset, Children〉, where X is a k-itemset, Tidset is the setof IDs associated with the transactions containing X, andChildren = {Y|Y ∈ (k+1)-itemsets and X ⊂ Y }.
2.2 Tidset-based frequent-itemset lattice building algorithm
When a node XA in a FIL is created, the algorithm pro-posed in [23, 24] has to find all the nodes which are thechildren of XA to update the lattice. This process first visitsall children of X (Y ∈ X.Children). With each Y , the pro-cess visits all children of Y (YB ∈ Y .Children). With eachYB, if XA ⊂YB, then the process updatesYB belonging to thechildren of XA (YB ∈ XA.Children). For example, considerthe lattice in Fig. 1. When the algorithm creates the nodeTC, it has to consider all the child nodes associated with T ,which are AT and TW. Then, the algorithm has to considerall the child nodes associated with AT and TW, which are
Table 1 Example transaction database D1
Transaction Items
1 A, C, T, W, Z
2 C, D, W
3 A, C, T, W
4 A, C, D, W
5 A, C, D, T, W
6 C, D, T

Maintenance of pre-large-based frequent-itemset lattice
Fig. 1 FIL for D1 with minSup= 50 % obtained using thealgorithm in [23, 24]
{ATW, ATC}and {ATW}. However, the process of consider-ing all child nodes of TW does not find any node that is thechild node of TC. The node ATW is a duplicate, and thusthe process of considering all child nodes associated withTW is meaningless. To overcome this weakness, this studyproposes the following structure for a FIL:
Definition 1 Let X be a k-itemset. The child nodes basedon the equivalence class feature associated with X are:
X.ChildrenEC = {XA|∀A ∈ I, A /∈ X} (1)
Definition 2 Let X be a k-itemset. The child nodes basedon the lattice feature associated with X are:
X.ChildrenL = {Y |Y is a (k + 1) - itemset,
Y /∈ X.ChildrenEC, and X ⊂ Y } (2)
Definition 3 Each node in the new lattice structure is atuple:
〈I temset, T idset, ChildrenEC, ChildrenL〉 (3)
where:
– Itemset is a k-itemset.– Tidset is the set of IDs associated with the transactions
containing Itemset.– ChildrenEC contains the child nodes based on the equiv-
alence class feature associated with Itemset.– ChildrenL contains the child nodes based on the lattice
feature associated with Itemset.
Theorem 1 Let XA be a node of a k-itemset. ∀XB ∈X.ChildrenEC and A is before B in the order of fre-quent 1-itemsets (sorted in ascending order of frequency).Then: � Y ∈ XB.ChildrenEC ∪ XB.ChildrenL so that Y ∈XA.ChildrenL.
Proof Assume that there exists the node of (k+1)-itemsetY in the lattice so that Y ∈ XB.ChildrenEC ∪ XB.ChildrenLand Y ∈ XA.ChildrenL. Then:
XA ⊂ Y because Y ∈ XA.ChildrenL (a)
XB ⊂ Y because Y ∈ XB.ChildrenEC ∪ XB.ChildrenL (b)
From (a) and (b), Y can only be XAB. However, thealgorithm used the depth-first-search strategy; therefore,XAB has not yet been created. Therefore, Theorem 1 isproven.
Theorem 2 Let XA be a node of a k-itemset and∀Z ∈ X.ChildrenL. Then: Y ∈ Z.ChildrenL so that Y ∈XA.ChildrenL.
Proof Assume that there exists the node of (k+1)-itemset Yin the lattice so that Y ∈ Z.ChildrenL and Y∈XA.ChildrenL.Then:
XA + {B} = Y, where B is any item because Y ∈XA.ChildrenL (c)
X + {C} = Z, where C is any item because Z ∈X.ChildrenL (d)
Z + {D} = Y, where D is any item because Y ∈Z.ChildrenL (e)
From (d) and (e),
X + {C, D} = Y. (f)
From (c) and (f), there are two cases:
1. C = A and D = B(d)−→ Z = X+ {C}= X+ {A}→ Z
is the same as XA. Therefore, this case is wrong.2. C = B and D = A. Then:
(f)−→ Y = X + {A, B} .

B. Vo et al.
Therefore, Y = XAB. However, the algorithm used thedepth-first-search strategy; therefore, XAB has not yet beencreated. Therefore, this case is also wrong.
From cases 1 and 2, �Y ∈ Z.ChildrenL so that Y ∈XA.ChildrenL. Theorem 2 is proven.
To understand the application of Theorems 1 and 2, theprocess of updating a lattice when the node XA, of a k-itemset, is created is described below. The algorithm in[23, 24] has to consider all nodes Y in the four cases shownin Table 2.
However, Theorems 1 and 2 show that for cases 1, 2, and4 (Table 2), there is no need to find the nodes of k-itemsetY in the current lattice as the child nodes of XA based onthe lattice feature. Therefore, the tidset-based FIL (TFIL)building algorithm can easily find the nodes which belongto XA.ChildrenL. The process first visits all children basedon the lattice feature of X (Y ∈ X.ChildrenL). With each Y ,this process visits all children based on the equivalence classfeature of Y (YB ∈ Y .ChildrenEC). With each YB, if XA ⊂YB, the process updatesYB belonging to the children basedon the lattice feature of XA (YB ∈ XA.ChildrenL). SeparatingChildren into ChildrenEC and ChildrenL makes the TFILalgorithm better than the algorithm in [23, 24] because iteliminates a large number of candidates in cases 1, 2, and 4in Table 2. The TFIL algorithm is presented in Fig. 2.
The TFIL algorithm is applied to the example database inTable 1 with minSup = 50 % to illustrate its use. First, TFILfinds all the frequent 1-itemsets and sorts them in ascendingorder of frequency. The result of this step is I1 = {A, D, T ,W , C}. The algorithm uses the depth-first-search strategyto generate the candidates associated with each equivalenceclass. The frequent (k-1)-itemsets in turn are combined withthe remaining (k-1)-itemsets in this equivalence class to cre-ate the k-itemset candidates. The frequent itemsets fromthese candidates are used to create the frequent (k+1)-itemsets. When each node X in the lattice is created, thealgorithm calls the procedure Update Lattice to update thechild nodes based on the lattice feature associated withX which are created in the previous steps. For instance,the first frequent 1-itemset in I1, A, is combined with theremaining frequent 1-itemsets {D, T , W , C} to create thecandidates {AD, AT, AW, AC}. However, AD is excludedbecause σ (AD) = 2 < minSup × n = 50 % × 6 = 3.The frequent 2-itemsets associated with equivalence class
Table 2 Four cases considered when updating the lattice in [23, 24]
Case Nodes of (k-1)-itemsets Nodes of k-itemsets
1 Z ∈ X.ChildrenEC Y ∈Z.ChildrenEC
2 Z ∈ X.ChildrenEC Y ∈Z.ChildrenL
3 Z ∈ X.ChildrenL Y ∈Z.ChildrenEC
4 Z ∈ X.ChildrenL Y ∈ Z.ChildrenL
A are thus {AT, AW, AC}. Then, the algorithm combinesthe first frequent 2-itemset in this list, AT, with the remain-ing frequent 2-itemsets in this list {AW, AC} to create thefrequent 3-itemsets {ATW, AWC}. ATW is combined withAWC to create the frequent 4-itemset {ATWC}, finishing theprocessing of equivalence class A. The algorithm similarlyprocesses the remaining equivalence class {D, T , W , C}.The results for the example database are shown in Fig. 3.Note that the dashed and solid lines represent ChildrenL andChildrenEC, respectively.
2.3 Diffset-based FIL building algorithm
The diffset definition was first presented by [28]. Theyproposed a method for quickly determining the supportassociated with a k-itemset based on the support of the (k-1)-itemset. Let the tidsets associated with XA, XB, and XABbe t(XA), t(XB), and t(XAB), respectively. Then:
t (XAB) = t (XA) ∩ t (XB) (4)
Let d(XAB) = t(XA) \t(XB) = d(XB)\d(XA) [28] be theTIDs that exist in t(XA) but not in t(XB). d(XAB) is calledthe diffset associated with XAB. The support associated withXAB is determined as:
σ (XAB) = σ (XA) − |d (XAB)| (5)
The diffset concept is used in the diffset-based FIL (DFIL)building algorithm, which is shown in Fig. 4. The functionFIL and the procedure Update Lattice are not shown herebecause they are the same as those in the TFIL algorithm (inFig. 2).
The lattice built using the DFIL algorithm for the exam-ple database with minSup = 50 % is shown in Fig. 5. The lat-tice obtained using the TFIL algorithm (L1) (see Fig. 3) andthat obtained using the DFIL algorithm (L2) (see Fig. 5) arebasically the same. However, L2 has the total size of diff-sets associated with all the frequent itemsets which is lessthan the total size of tidsets associated with all the frequentitemsets in L1. Therefore, using the diffset concept helpsthe DFIL algorithm reduce memory usage and executiontime.
2.4 Pre-large concept in incremental mining
The pre-large concept was proposed in [10]. It is based on asafety threshold f to reduce the need of rescanning the orig-inal database for efficiently maintaining association rules.The safety number f of inserted transactions is derived asfollows:
f =⌊
(SU − SL) × |D|1 − SU
⌋(6)

Maintenance of pre-large-based frequent-itemset lattice
Fig. 2 TFIL algorithm
where SU is the upper threshold, SL is the lower threshold,and |D| is the number of original database D’s transactions.When the number of new transactions is equal to or lessthan f , the algorithm does not need to rescan the originaldatabase.
When two thresholds are used, each itemset has threecases: frequent, pre-large, and infrequent. This divides item-sets in the original and new databases into nine cases [10],as presented in Table 3.
Example 1 Consider the database in Table 1 with |D1|=6. Assume that SU = 70 % and SL = 50 %. Then, if the
number of new transactions is equal to or less than f =⌊(0.7−0.5)×(6)
1−0.7
⌋= 4, the algorithm does not need to rescan
the original database to determine the support of infrequentitemsets which are mined from the original database.
3 Tidset-based maintenance of PFIL algorithm
The tidset-based maintenance of a PFIL (TMPFIL) algo-rithm only uses the tidset concept for two sub-algorithms:TFIL (see Section 2.2) and a tidset-based approach formaintaining a PFIL.

B. Vo et al.
Fig. 3 FIL for D1 with minSup= 50 % obtained using TFILalgorithm
3.1 TMPFIL algorithm
Consider the following two comments on the pre-large FIL:
1. When the paternity relations based on the lattice featureare ignored, the lattice becomes a frequent-itemset treethat contains all the itemsets in the lattice. Therefore,the algorithm traverses only the paternity relationsbased on the equivalence class feature to visit all thenodes of frequent itemsets.
2. When the algorithm finds the direct child node of XAand XB in the lattice where A is before B in the order
Fig. 4 DFIL algorithm
of frequent 1-itemsets sorted in ascending order of fre-quency, the algorithm only needs to find XAB fromChildrenEC of XA and from ChildrenL of XB becauseXAB can only be in ChildrenEC of XA (by Definition 1)and ChildrenL of XB (by Definition 2). Note that thedirect child node of XA and XB is only XAB if XAB’ssupport satisfies the threshold.
Based on these comments, the TMPFIL algorithm is pro-posed. For each increment, the process of this algorithm isas follows:
1. If the original database is empty, the algorithmuses the lower threshold SL to build a PFIL andrecalculates the safety threshold f for incrementaldatabase D′.
2. If the number of transactions in incremental database D′is larger than f , the algorithm uses SL to build a PFILand recalculates the safety threshold f for D + D′.
3. If the number of transactions in incremental databaseD′ is equal to or less than f , the algorithm updates thePFIL without scanning the database.
Fig. 5 FIL for database D1 with minSup = 50 % obtained using DFILalgorithm

Maintenance of pre-large-based frequent-itemset lattice
Table 3 Nine cases of itemsets
Case Original – new Result
1 frequent – frequent frequent
2 frequent – pre-large frequent/pre-large, determined from existing itemsets
3 frequent – in frequent frequent/pre-large/infrequent, determined from existing itemsets
4 pre-large – frequent pre-large/frequent, determined from existing itemsets
5 pre-large – pre-large pre-large
6 pre-large – infrequent pre-large/infrequent, determined from existing itemsets
7 infrequent – frequent pre-large/infrequent, rescan the original if the number of inserted transactions is larger than f
8 infrequent – pre-large infrequent/pre-large, rescan the original if the number of inserted transactions is larger than f
9 infrequent – infrequent infrequent
4. The original database is updated as D = D + D′.
The TMPFIL algorithm is presented in Fig. 6.
3.2 Illustration of TMPFIL algorithm
In this section, an example is given to illustrate the pro-cess of TMPFIL in three rounds of updating the databasewith the initial database D = ∅, SL = 50 %, andSU = 65 %.
First round (D1 with the six transactions in Table 1)Because the condition in line 1 is true, the algorithm per-forms lines 2 and 3. The result of this increment is thePFIL shown in Fig. 3. Then, the algorithm updates f =⌊
(SU−SL)×(|D|)1−SU
⌋=
⌊(0.65−0.5)×(6)
1−0.65
⌋= 2 and D = ∅ + D1.
Second round (D2 with two transactions in Table 4)Because |D2|= 2 = f , the algorithm performs lines 8, 9,10, and 11 in the procedure INCREMENTAL-FIL.
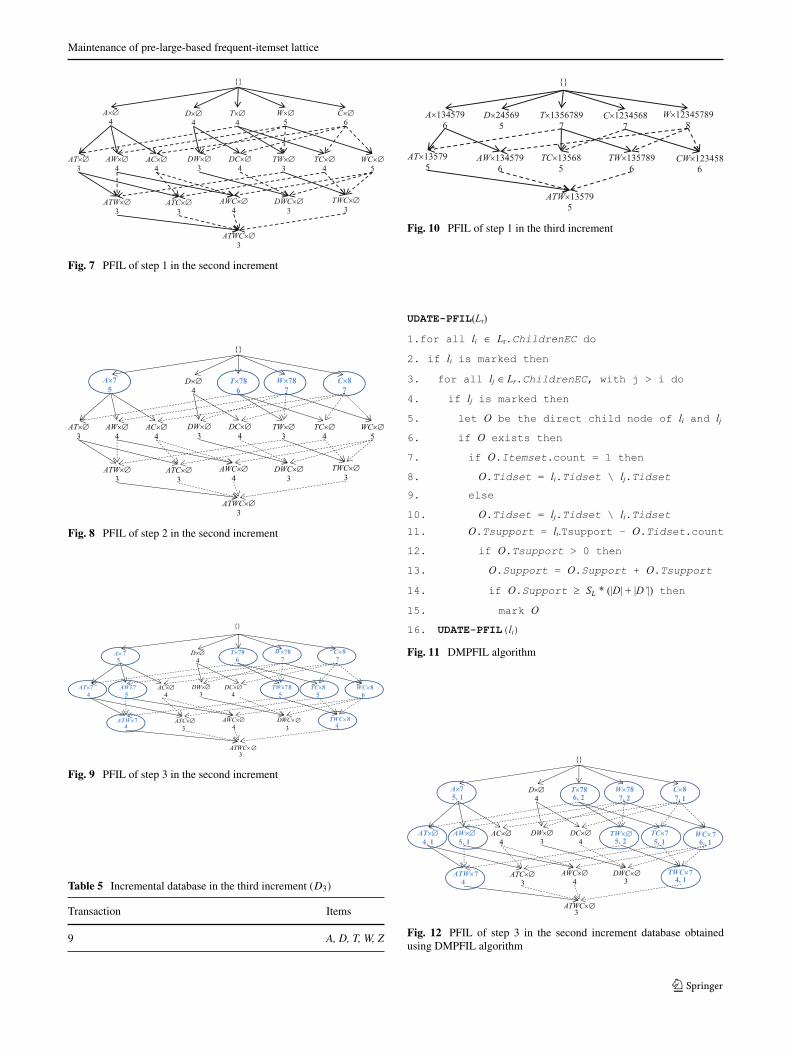
1. The algorithm clears all the tidset information associ-ated with all the nodes in the PFIL (see Fig. 7).
2. The algorithm inserts the tidset information (only fortransactions 7 and 8) associated with the frequent 1-itemsets in the PFIL and then marks the updated nodes(Fig. 8).
3. The algorithm calls the procedure UPDATE-PFIL,which is called recursively in depth-first search, toupdate the tidset information of all nodes in the PFIL.The result of this step is shown in Fig. 9.
4. The algorithm updates the safety threshold f = f -|D2|= 2 – 2 = 0.
5. The algorithm updates the database D = D1 + D2.
Figure 9 shows that only a small number of nodes whichhave their tidset information updated in the PFIL are usedto update the lattice.
Third round (D3 with one transaction in Table 5) Because|D|>0 and |D3|= 1 >f = 0, the algorithm performs lines5 and 6 in the procedure INCREMENTAL-FIL.
1. The algorithm calls the function FIL to create the PFILwith D with the nine transactions in Tables 1, 4 and 5.The result of this step is shown in Fig. 10.
2. The algorithm calculates the safety threshold f =⌊(SU−SL)×(|D|)
1−SU
⌋=
⌊(0.65−0.5)×(9)
1−0.65
⌋= 3. Therefore,
for the fourth increment, if |D4|≤ 3, the algorithmupdates the PFIL without scanning the database.
4 Diffset-based maintenance of PFIL algorithm
In this section, the diffset-based maintenance of a PFIL(DMPFIL) algorithm is proposed (see Fig. 11). Onlythe diffset concept for two sub-algorithms, DFIL (seeSection 2.3) and a diffset-based approach for maintaininga PFIL, are used. Note that only the procedure UPDATE-PFIL is given since the other procedures are the same asabove (Fig. 6).
To use the diffset concept, each node in the lattice hasa temporal support (Tsupport) field. The Tsupport asso-ciated with a node of a frequent 1-itemset is the numberof items in a tidset (only for inserted transactions). TheTsupport associated with a node of frequent k-itemset XAB(k >1) is determined using equation (5). It can be re-writtenas follows:
XAB.T support = XA.T support − |XAB.T idset |
where A is before B in the order of frequent 1-itemsetsand |XAB.Tidset| is the number of elements in the diffset ofXAB.
To illustrate the DMPFIL algorithm, the PFIL of step 3in the second increment database from Section 3.2 is shownin Fig. 12.

B. Vo et al.
Fig. 6 TMPFIL algorithm
The PFIL in Fig. 12 is clearly better than that in Fig. 9 interms of memory usage, which also speeds up the executiontime. Hence, DMPFIL is more effective than TMPFIL.
Table 4 Incremental database in the second increment (D2)
Transaction Items
7 A, T, W, Z
8 C, T, W, Z
5 Experimental results
All experiments presented in this section were performedon a laptop with an Intel i3-3110 M 2.4-GHz CPU and4 GB of RAM running Windows 8. All the programs werecoded in C# (version 4.5.50709). The experiments wereconducted using the following UCI databases1: Accidents,
1http://fimi.cs.helsinki.fi/data/
Maintenance of pre-large-based frequent-itemset lattice
Fig. 7 PFIL of step 1 in the second increment
Fig. 8 PFIL of step 2 in the second increment
Fig. 9 PFIL of step 3 in the second increment
Table 5 Incremental database in the third increment (D3)
Transaction Items
9 A, D, T, W, Z
Fig. 10 PFIL of step 1 in the third increment
Fig. 11 DMPFIL algorithm
Fig. 12 PFIL of step 3 in the second increment database obtainedusing DMPFIL algorithm
B. Vo et al.
Fig. 13 Execution time ofTMPFIL, DMPFIL (SU = 80 %and SL = 78 %) and TFIL, DFIL(SU = 80 %) for Accidents
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
333379 334059 334739 335419 336099 336779 337459 338139 338819 339499
TFIL
DFIL
TMPFIL
DMPFIL
Exec
u�on
�m
e (s
econ
ds)
Number of transac�ons
0
2
4
6
8
10
12
14
16
TFIL DFIL TMPFIL DMPFIL
Exec
u�on
�m
e (s
econ
ds)
Algorithm
Fig. 14 Execution time ofTMPFIL, DMPFIL (SU = 95 %and SL = 93 %) and TFIL,DFIL (SU = 95 %) for Connect
0
1
2
3
4
5
6
66205 66340 66475 66610 66745 66880 67015 67150 67285 67420
TFIL
DFIL
TMPFIL
DMPFIL
Exec
u�on
�m
e (s
econ
ds)
Number of transac�ons
0
5
10
15
20
25
30
35
40
45
50
TFIL DFIL TMPFIL DMPFIL
Exec
u�on
�m
e (s
econ
ds)
Algorithm

Maintenance of pre-large-based frequent-itemset lattice
Table 6 Statistical summary of experimental databases
Database # of trans # of items
Accidents 340,183 468
Chess 3,196 76
Mushroom 8,124 120
Pumsb star 49,046 7,117
Retail 88,162 16,470
Chess, Mushroom, Pumsb star, and Retail. A statisticalsummary of these databases is shown in Table 5.
In this section, the total execution times of the DMPFIL,TMPFIL, TFIL, and DFIL algorithms are compared. Notethat TFIL and DFIL used upper threshold SU to build theFIL.
5.1 Execution time comparison
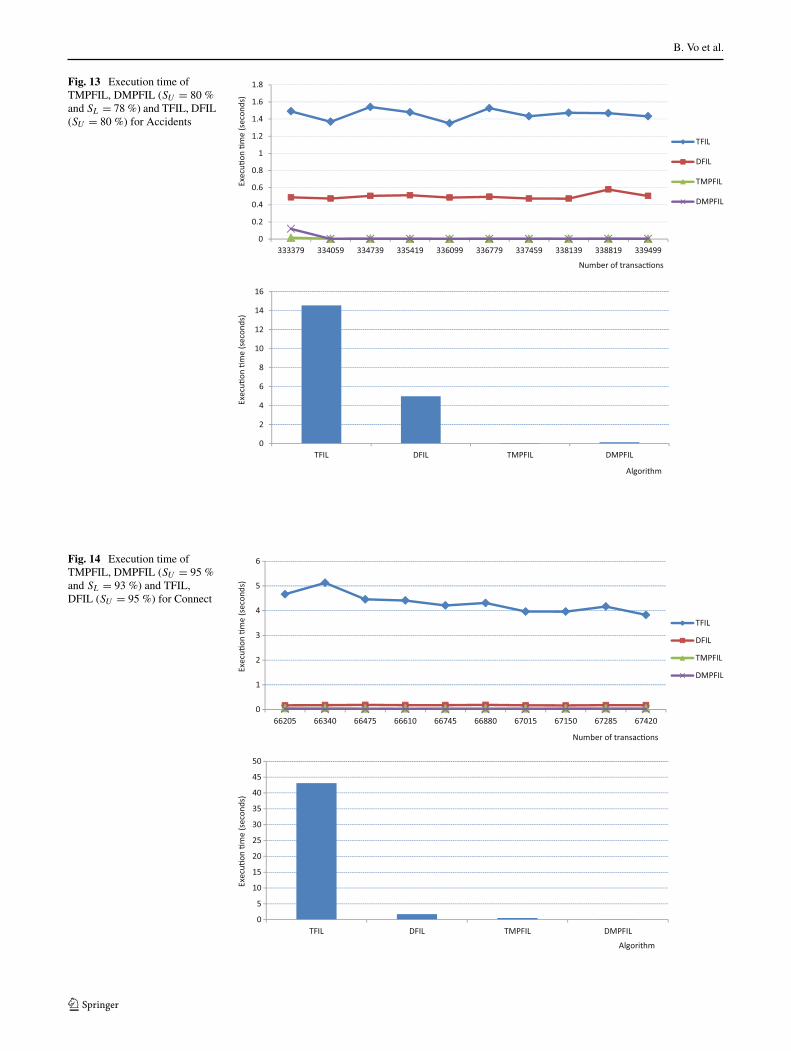
Figure 13 compare the execution time of four algorithms,namely TFIL, DFIL, TMPFIL, and DMPFIL, for the Acci-dents database. Results show that the time for PFIL main-tenance is smaller than that for building a FIL using thebatch way. For 10 runs, the total execution times for TFIL,DFIL, TMPFIL, and DMPFIL were 14.563, 4.982, 0.064,
and 0.144 s. In this case, updating the lattice using diffset isslightly slower than using tidset because only 680 transac-tions were inserted in each increment, which is a very smallnumber of transactions compared to those in the originaldatabase (Table 6).
For the Connect database (Fig. 14), the execution timefor updating the lattice using diffset is less than that usingtidset. The total times for the four algorithms are 43.009,1.759, 0.521, and 0.114 s, respectively.
Similar results were obtained for Mushroom andPumsb star (Figs. 15 and 16, respectively). Updating the lat-tice when the database is inserted is often faster than usingthe batch way. Using diffset is often more efficient thanusing tidset.
Figure 17 shows a case for which the proposed approachperforms poorly. When SL is very small, our approach maybe slower than the batch way. In this very sparse database(Retail), using diffset is also sometimes slower than usingtidset.
5.2 Execution time comparison between tidset-basedand diffset-based approaches
The lower support thresholds were changed to comparethe execution times for updating the lattice using tidset-based and diffset-based approaches (Figs. 18, 19, 20, 21,and 22). SU was fixed and SL was changed according to
Fig. 15 Execution time ofTMPFIL, DMPFIL (SU = 30 %and SL = 28 %) and TFIL, DFIL(SU = 30 %) for Mushroom
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
7961 7977 7962 7978 7963 7979 7964 7980 7965 7981
DFIL
TMPFIL
DMPFIL
TFIL
Exec
u�on
�m
e (s
econ
ds)
Number of transac�ons
0
0.5
1
1.5
2
2.5
3
3.5
TFIL DFIL TMPFIL DMPFIL
Exec
u�on
�m
e (s
econ
ds)
Algorithm

B. Vo et al.
Fig. 16 Execution time ofTMPFIL, DMPFIL (SU = 60 %and SL = 58 %) and TFIL, DFIL(SU = 60 %) for Pumsb star
0
0.05
0.1
0.15
0.2
0.25
0.3
48065 48163 48066 48164 48067 48165 48068 48166 48069 48167
TFIL
DFIL
TMPFIL
DMPFIL
Exec
u�on
�m
e (s
econ
ds)
Number of transac�ons
0
0.5
1
1.5
2
2.5
3
TFIL DFIL TMPFIL DMPFIL
Exec
u�on
�m
e (s
econ
ds)
Algorithm
Fig. 17 Execution time ofTMPFIL, DMPFIL (SU = 0.5 %and SL = 0.495 %) and TFIL,DFIL (SU = 0.5 %) for Retail
0
0.2
0.4
0.6
0.8
1
1.2
86398 86574 86750 86926 87102 87278 87454 87630 87806 87982
TFIL
DFIL
TMPFIL
DMPFILExec
u�on
�m
e (s
econ
ds)
Number of transac�ons
0
2
4
6
8
10
12
TFIL DFIL TMPFIL DMPFIL
Exec
u�on
�m
e (s
econ
ds)
Algorithm

Maintenance of pre-large-based frequent-itemset lattice
Fig. 18 Total execution time ofTMPFIL and DMPFIL withSU = 70 % and SL = SU − �s
for Accidents
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
333379 334059 334739 335419 336099 336779 337459 338139 338819 339499
TMPFIL(0.5)
DMPFIL(0.5)
TMPFIL(1)
DMPFIL(1)
TMPFIL(1.5)
DMPFIL(1.5)
TMPFIL(2)
DMPFIL(2)Ex
ecu�
on �
me
(sec
onds
)
Number of transac�ons
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
TMPFIL(0.5) DMPFIL(0.5) TMPFIL(1) DMPFIL(1) TMPFIL(1.5) DMPFIL(1.5) TMPFIL(2) DMPFIL(2)
Exec
u�on
�m
e (s
econ
ds)
Algorithm
Fig. 19 Total execution time ofTMPFIL and DMPFIL withSU = 90 % and SL = SU − �s
for Connect
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
66205 66340 66475 66610 66745 66880 67015 67150 67285 67420
TMPFIL(0.5)
DMPFIL(0.5)
TMPFIL(1)
DMPFIL(1)
TMPFIL(1.5)
TMPFIL(1.5)
TMPFIL(2)
DMPFIL(2)
Exec
u�on
�m
e (s
econ
ds)
Number of transac�ons
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
TMPFIL(0.5) DMPFIL(0.5) TMPFIL(1) DMPFIL(1) TMPFIL(1.5) DMPFIL(1.5) TMPFIL(2) DMPFIL(2)
Exec
u�on
�m
e (s
econ
ds)
Algorithm

B. Vo et al.
Fig. 20 Total execution time ofTMPFIL and DMPFIL withSU = 20 % and SL = SU − �s
for Mushroom
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
7961 7977 7962 7978 7963 7979 7964 7980 7965 7981
TMPFIL(0.5)
DMPFIL(0.5)
TMPFIL(1)
DMPFIL(1)
TMPFIL(1.5)
DMPFIL(1.5)
TMPFIL(2)
DMPFIL(2)Ex
ecu�
on �
me
(sec
onds
)
Number of transac�ons
0
0.2
0.4
0.6
0.8
1
1.2
TMPFIL(0.5) DMPFIL(0.5) TMPFIL(1) DMPFIL(1) TMPFIL(1.5) DMPFIL(1.5) TMPFIL(2) DMPFIL(2)
Exec
u�on
�m
e (s
econ
ds)
Algorithm
Fig. 21 Total execution time ofTMPFIL and DMPFIL withSU = 45 % and SL = SU − �s
for Pumsb star
0
0.2
0.4
0.6
0.8
1
1.2
48065 48163 48066 48164 48067 48165 48068 48166 48069 48167
TMPFIL(0.5)
DMPFIL(0.5)
TMPFIL(1)
DMPFIL(1)
TMPFIL(1.5)
DMPFIL(1.5)
TMPFIL(2)
DMPFIL(2)
Exec
u�on
�m
e (s
econ
ds)
Number of transac�ons
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
TMPFIL(0.5) DMPFIL(0.5) TMPFIL(1) DMPFIL(1) TMPFIL(1.5) DMPFIL(1.5) TMPFIL(2) DMPFIL(2)
Exec
u�on
�m
e (s
econ
ds)
Algorithm

Maintenance of pre-large-based frequent-itemset lattice
Fig. 22 Total execution time ofTMPFIL and DMPFIL withSU = 0.5 % and SL = SU − �s
for Retail
1
1.05
1.1
1.15
1.2
1.25
1.3
86398 86574 86750 86926 87102 87278 87454 87630 87806 87982
TMPFIL(0.005)
DMPFIL(0.005)
TMPFIL(0.01)
DMPFIL(0.01)
TMPFIL(0.015)
DMPFIL(0.015)
TMPFIL(0.02)
DMPFIL(0.02)Ex
ecu�
on �
me
(sec
onds
)
Number of transac�ons
10.811
11.211.411.611.8
1212.212.412.6
Exec
u�on
�m
e (s
econ
ds)
Algorithm
SL = SU − �s. For example, with the Accidents database,SU was fixed at 70 % and �s was 0.5 %, 1 %, 1.5 %,and 2 %, giving SL values of 69.5 %, 69 %, 68.5 %, and68 %, respectively. Figure 18 shows that when �s = 0.5 %,the total time is highest because this process must rebuildthe PFIL at the 9th increment. When �s = 1 %, the totaltime is lowest because the PFIL does not need to be rebuiltand the number of nodes that need to be considered in thelattice is smaller than those for �s = 1.5 % and 2 %(Fig. 18).
Consider the Connect database (Fig. 19). The best resultwas obtained with �s = 0.5 % because in this case, the
algorithm does not rebuild the lattice. The total executiontimes for updating the lattice with TMPFIL and DMPFILare 2.394 and 0.763 s with �s = 0.5 %, 2.841 and 0.955 swith �s = 1 %, 3.353 and 1.250 s with �s = 1.5 %, and3.959 and 1.461 s with �s = 2 %, respectively.
This section compares the execution time when thenumber of inserted transactions is changed. Figures 23,24, 25 and 26 show that DMPFIL is always better thanTMPFIL in all cases. However, Fig. 27 shows a case forwhich the proposed approach performs poorly. In this verysparse database (Retail), DMPFIL is sometimes slower thanTMPFIL.
Fig. 23 Execution time ofTMPFIL and DMPFIL (SU =70 % and SL = 68 %) forAccidents with Row start =300,000 and Row end =340,183

B. Vo et al.
Fig. 24 Execution time ofTMPFIL and DMPFIL (SU =90 % and SL = 88 %) forConnect with Row start =64,000 and Row end = 67,557
Fig. 25 Execution time ofTMPFIL and DMPFIL (SU =20 % and SL = 18 %) forMushroom with Row start =8,000 and Row end = 8,124
Fig. 26 Execution time ofTMPFIL and DMPFIL (SU =45 % and SL = 43 %) forPumsb star with Row start =45,000 and Row end = 49,046
Fig. 27 Execution time ofTMPFIL and DMPFIL (SU =0.5 % and SL = 0.495 %) forRetail with Row start = 85,000and Row end = 88,162

Maintenance of pre-large-based frequent-itemset lattice
6 Conclusions and future work
This paper proposed an effective algorithm for the main-tenance of a FIL. The proposed approach has two phases:(i) building the FIL and (ii) maintaining the PFIL. For thefirst phase, two theorems were proposed and the diffset con-cept was used for quickly building a FIL. For the secondphase, the DMPFIL algorithm uses the pre-large and diffsetconcepts for the maintenance of the PFIL. The experimen-tal results show that DMPFIL is more effective than TFIL,DFIL, and TMPFIL in terms of execution time.
A disadvantage of the proposed method is that it mustbuild the FIL based on the whole database (original andinserted) when the number of inserted transactions is largerthan the safety threshold. Besides, using pre-large concept,we have to maintain a small number of infrequent itemsetsin the lattice. In future work, we will study how to storemore information to avoid rescanning the original databaseand avoid storing a number of infrequent itemsets in thelattice for fast maintaining the FIL. Using a FCIL for gener-ating association rules is very effective; therefore, a methodfor updating the FCIL when the database is changed will bedeveloped. In addition, how to update a FIL for huge andvery dense databases will be studied.
References
1. Agrawal R, Imielinski T, Swami AN (1993) Mining associationrules between sets of items in large databases. In: SIGMOD’93.pp 207–216
2. Agrawal R, Srikant R (1994) Fast algorithms for mining associa-tion rules. In: VLDB’94. pp 487–499
3. Cai R, Tung AKH, Zhang Z, Hao Z (2011) What is unequal amongthe equals? Ranking equivalent rules from gene expression data.IEEE Trans Knowl Data Eng 23(11):1735–1747
4. Chen H, Yan X, Han J (2004) IncSpan: Incremental miningof sequential patterns in large databases. In: KDD’04. pp 527–532
5. Cheung DW, Han J, Ng VT, Wong CY (1996) Maintenance ofdiscovered association rules in large databases: an incrementalupdating approach. In: ICDE’96. pp 106–114
6. Cong G, Tan K-L, Tung AKH, Xu X (2005) Mining Top-k cov-ering rule groups for gene expression data. In: SIGMOD’05. pp670–681
7. Dong J, Han M (2007) BitTableFI: an efficient mining frequentitemsets algorithm. Knowl Based Syst 20(4):329–335
8. Grahne G, Zhu J (2005) Fast algorithms for frequent itemsetmining using FP-trees. IEEE Trans Knowl Data Eng 17:1347–1362
9. Han J, Pei J, Yin Y (2000) Mining frequent patterns withoutcandidate generation. In: SIGMOD’00. pp 1–12
10. Hong TP, Wang CY, Tao YH (2001) A new incremental data min-ing algorithm using pre-large itemsets. Int Data Anal 5(2):111–129
11. Hong TP, Lin CW, Wu YL (2008) Incrementally fast updatedfrequent pattern trees. Expert Syst Appl 34(4):2424–2435
12. Hong TP, Lin CW, Wu YL (2009) Maintenance of fast updatedfrequent pattern trees for record deletion. Comput Stat Data Anal53(6):2485–2499
13. Hong TP, Wang CY, Tseng SS (2011) An incremental min-ing algorithm for maintaining sequential patterns using pre-largesequences. Expert Syst Appl 38(5):7051–7058
14. Koh JL, Shied SF (2004) An efficient approach for maintain-ing association rules based on adjusting FP-tree structures. In:DASFAA’04. pp 417–424
15. La PT, Le B, Vo B (2014) Incrementally building frequent closeditemset lattice. Expert Syst Appl 41(5):2703–2712
16. Le T, Vo B (2014) MEI: an efficient algorithm for mining erasableitemsets. Eng Appl Artif Int 27:155–166
17. Le TP, Hong TP, Vo B, Le B (2012) An efficient incrementalmining approach based on IT-tree. In: RIVF’12. pp 57–61
18. Lin CW, Hong TP, Lan GC, Wong JW, Lin WY (2014) Incremen-tally mining high utility patterns based on pre-large concept. ApplInt 40(2):343–357
19. Pasquier N, Bastide Y, Taouil R, Lakhal L (1999) Efficient min-ing of association rules using closed Itemset lattices. Inform Syst24(1):25–46
20. Shie BE, Philip SY, Tseng VS (2013) Mining interesting userbehavior patterns in mobile commerce environments. Appl Int38(3):418–435
21. Song W, Yang B, Xu Z (2008) Index-BitTableFI: an improvedalgorithm for mining frequent itemsets. Knowl-Based Syst21:507–513
22. Song W, Liu Y, Li J (2014) Mining high utility itemsetsby dynamically pruning the tree structure. Appl Int 40(1):29–43
23. Vo B, Le B (2009) Mining traditional association rules usingfrequent itemsets lattice. In: CIE’09. pp 1401–1406
24. Vo B, Le B (2011) Interestingness measures for association rules:Combination between lattice and hash tables. Expert Syst Appl38(9):11630–11640
25. Vo B, Hong TP, Le B (2013) A lattice-based approach for miningmost generalization association rules. Knowl-Based Syst 45:20–30
26. Yen SJ, Lee YS (2013) Mining non-redundant time-gap sequentialpatterns. Appl Int 39(4):727–738
27. Yen SJ, Lee YS, Wang CK (2013) An efficient algorithmfor incrementally mining frequent closed itemsets. Appl Int.doi:10.1007/s10489-013-0487-8 (in press)
28. Zaki MJ, Gouda K (2003) Fast vertical mining using diffsets. InKDD’03. pp 326–335
29. Zaki MJ, Hsiao CJ (2005) Efficient algorithms for mining closeditemsets and their lattice structure. IEEE Trans Knowl Data Eng17(4):462–478
30. Zaki MJ, Parthasarathy S, Ogihara M, Li W (1997) New algo-rithms for fast discovery of association rules. In: KDD’97. pp 283–286