ambiguity in performance pay: a real effort...
TRANSCRIPT

Ambiguity in Performance Pay: A Real Effort Experiment
April 20, 2016
David J. Cooper Florida State University
David B. Johnson
University of Central Missouri
Abstract: Many incentive contracts are inherently ambiguous, lacking an explicit mapping between
performance and pay. Using an online labor market, Amazon Mechanical Turk, we study the effect of
ambiguous incentives on willingness to accept contracts to do a real-effort task, the probability of
completing the task, and performance at the task. Even modest levels of ambiguity about the relationship
between performance and pay are sufficient to eliminate the positive selection effect associated with piece
rates, as high ability individuals are no more likely than low ability individuals to accept a contract. Piece
rate contracts significantly improve performance relative to fixed wages, primarily due to selection, but this
positive effect is not present with ambiguous incentive contracts. Modest levels of ambiguity reduce the
probability that subjects accept an incentive contract and all types of ambiguous incentive contracts increase
the probability of quitting after having accepted an incentive contract. Information about individual ability
at the task reduces the probability that subjects choose and complete the task.
Acknowledgements: We would like to thank Javier Cano-Urbina, Yan Chen, Emel Filiz Ozbay, Anastasia
Semykina, and seminar participants at Chapman University, EWEBE, Florida State University, and the
University of Maryland for helpful comments. We would like to thank Joe Stinn for his help as a research
assistant and Sue Isaac for attempting (unsuccessfully) to improve our shaky grasp on the English language.
Keywords: ambiguity, incentives, performance pay, quitting, experiment
JEL Classification: C9, J33, D81

1
1. Introduction: Incentive contracts tying pay to performance are ubiquitous in both the public and
private sectors. In some cases, these contracts are extremely explicit, making the relationship between
performance and pay unambiguous. Sales commissions and piece rate systems are well-known examples
of this sort of incentive contract. At the opposite end of the spectrum are incentive schemes where
employees are completely uninformed about the relationship between their performance and pay. The
“black box” compensation used by some large law firms (i.e. Jones Day) provide a striking example of
this type of incentive contract. Herrmann (2012) describes black box compensation as follows:
“Under this system, the managing partner (or a small committee) sets compensation for each partner in the firm. There is no specific formula for allocating the spoils, and partners are forbidden from discussing their compensation with each other. Each partner is told what he’ll make in the coming year … and the process is over.”
Most incentive schemes fall somewhere between these extremes. While employees have an idea about
what constitutes good performance and what the relationship is between performance and pay, the precise
definitions of good performance and the relationship between performance and pay may be ambiguous. An
example that academics are painfully familiar with is the tenure system. While senior faculty can usually
give general guidance about what is necessary for tenure, could they state a precise rule? More publications
are better than less, but exactly how many are needed to get tenure? Better quality publications count for
more, but exactly how is quality measured?
Continuing the tenure example, novice hires often face uncertainty not just about the incentive system,
but also about their likely performance. Suppose a newly hired economics professor is told that they need
six publications in top field journals or better. It seems unlikely that a newly minted PhD knows precisely
how difficult this task is or exactly how good they are at this task.
The preceding examples suggest that workers face ambiguity as well as risk. If they know neither their
ability at their job nor precisely how their performance will translate into pay, it is hard to imagine that
workers know the probability distribution generating their performance pay. Our primary goal is to study
how ambiguity about incentive contracts affects workers. Specifically, how does ambiguity affect the
willingness of workers to take a job, the likelihood that they quit a job, and their performance at this job?
To address the effects of ambiguous incentive plans, we conduct an online experiment, recruiting
subjects from Amazon Mechanical Turk (AMT). Subjects choose between two real effort tasks: coding
messages drawn from Charness and Dufwenberg (2006) or transcribing printed words into a text box.
Coding messages is a challenging task where it is difficult for a subject to tell how well they are doing,
making it a good task for inducing ambiguity about ability and performance. Subjects who choose the
coding task earn a bonus which varies based on their performance. The transcription task is a sure thing.

2
It takes a fixed amount of time to complete, identical to the time for the coding task, and yields a fixed and
known bonus.
We vary subjects’ information about the coding task along two dimensions: (1) the relationship between
their performance and their bonus and (2) their likely performance. There are five treatments along the first
dimension, two involving no ambiguity and three varying the level of ambiguity. The true bonus system
for all treatments (except the fixed bonus treatment) is a 9¢ piece rate for each message coded correctly.
1. Fixed (FIXED): Subjects receive a fixed and known amount for the coding task.
2. Piece Rate (PR): Subjects receive a known piece rate (9¢) for each message coded correctly. They
know the rule for determining whether a coding is correct.
3. Low Ambiguity (LA): Subjects know the rule for determining whether a message is coded
correctly. They know the minimum ($0.00) and maximum ($1.35) possible bonus and that their
bonus depends on how well they do at coding, but do not know the relationship between the number
of messages coded correctly and the bonus (low ambiguity).
4. High Ambiguity, $1.35 Maximum (HA135): Subjects do not know the rule for determining whether
a message is coded correctly. They know the minimum ($0.00) and maximum ($1.35) possible
bonus but have no information about how this bonus is determined.
5. High Ambiguity, $1.00 Maximum (HA100): This is the same as the preceding treatment, except
subjects are told that the maximum possible bonus is $1.00.
All subjects code five practice messages prior to selecting a task, providing a good measure of their
ability at the coding task. In the fixed, piece rate, and low ambiguity treatments we vary whether subjects
receive feedback about their performance on the practice messages (i.e. how many practice messages they
code correctly). We never give feedback in the high ambiguity treatments as this could undo some of the
ambiguity about the incentive contract in these treatments.
Our experiment is conducted within a real labor market where quitting is a natural feature. The subjects
aren’t in a lab where they could not easily leave and would face psychological discomfort if they did so.1
If our subjects don’t like the experiment or think they could make more money doing something else, they
could switch to another webpage or another task on AMT. This behavior was not uncommon. About 11%
of the subjects who chose the coding task quit before completing it even though the instructions and
materials heavily stress that this means forfeiting their pay. A number of our results involve the effects of
our treatments on the likelihood of quitting.
1 Subjects in lab experiments are routinely told that they can leave at any time with no consequence other than foregone earnings, but few subjects do so. The procedures in lab experiments that come closest to quitting in AMT are real effort experiments where subjects can leave the lab as a natural part of the experiment (i.e. Abeler, Falk, Götte, and Huffman, 2011; Rosaz, Slonim, and Villeval, 2012) or can earn money by not doing the experimental task (i.e. Cooper, D’Adda, and Weber, 2013).

3
Drawing on the smooth ambiguity model of Klibanoff, Marinacci, and Mukerji (2005), adapted to our
experiment, we make several predictions about the experimental results.
1) The probability of choosing and completing the coding task will decrease as ambiguity of the bonus
system increases (holding the maximum possible bonus fixed).
2) The probability of choosing and completing the coding task will decrease in the high ambiguity
treatments when the maximum possible bonus is reduced between HA135 and HA100.
3) The predicted effect of feedback will depend on whether its primary effect is to reduce uncertainty
or to reduce subjects’ overconfidence about their ability at the coding task. In the former case the
effect of feedback on the probability of choosing and completing the coding task is predicted to be
positive while in the latter case a negative effect is predicted.
4) Selection of more able individuals into the coding task will occur for all treatments except FIXED,
but the selection effect will be weakened by ambiguity relative to the piece rate treatment.
5) The number of messages coded correctly, subject to choosing and completing Task A, will decrease
with higher ambiguity.
The data provides mixed support for our predictions about choosing and completing the coding task.
On the positive side, subjects are significantly less likely to select and complete the coding task in the low
ambiguity (LA) treatment than the piece rate (PR) treatment. Also as predicted, willingness to select and
complete the coding task is significantly lower under high ambiguity when the maximum possible bonus is
reduced between HA135 and HA100. Contrary to our prediction, subjects are significantly more likely to
select and complete the coding task in HA135 than LA.
Providing subjects with feedback about their performance on the practice messages significantly lowers
willingness to select and complete the coding task, although only in the cases where performance is relevant
for the bonus (i.e. not FIXED). This suggests the primary effect of giving feedback is to reduce subjects’
overconfidence about their abilities.
High ability individuals (as measured by performance on the practice questions) are significantly more
likely than low ability individuals to choose and complete the coding task under piece rate incentives (PR).
This contrasts with the fixed bonus treatment (FIXED) where there is not selection based on ability. The
positive selection occurring in PR vanishes with ambiguity about the incentive contract. At best we find no
selection with ambiguity (LA and HA135), and in one case (HA100) the effect reverses with high ability
subjects significantly less likely to select and complete the coding task than low ability subjects. If we do
not control for selection, performance on the coding task by subjects who choose and complete it is
significantly higher in PR than in FIXED. This is not true for any of the treatments with ambiguous
incentive contracts. All treatment differences in performance disappear once we control for selection.

4
Our paper contributes to several existing literatures. There is a sizable literature using experiments
with real effort tasks to study the effects of incentive contracts on selection and/or performance. Notable
recent examples include Cadsby, Song, and Tapon (2007), Niederle and Vesterlund (2007), Eriksson,
Teyssier, and Villeval (2009), Dohmen and Falk (2011), Gill, Prowse, and Vlassopoulos (2012), Buser and
Dreber (2015), and Johnson and Weinhardt (2015). Our innovation is to focus on how changing subjects’
information about the relationship between performance and pay affects behavior. Ambiguity about
performance pay affects subjects’ choice on a number of dimensions and on one critical dimension our
results differ considerably from the standard findings. A common result in the literature is that piece rate
incentives improve performance relative to fixed wages. This is largely due to selection as high ability
workers who benefit more from a piece rate system are more likely to take such contracts (e.g. Lazear,
2000; Barro and Beaulieu, 2003; Cadsby, Song, and Tapon, 2007; Dohmen and Falk, 2011). These results
change when there is ambiguity about the relationship between performance and pay. The selection of high
ability types into the coding task vanishes with ambiguity, and the impact of performance pay on
productivity (relative to fixed pay) is no longer significant.
Another innovation of our experiments is to examine an aspect of performance that has received little
previous attention in the experimental literature: quitting the task.2 Quits matter a great deal for real firms.3
An advantage of the piece rate contract relative to a fixed bonus is a significant reduction of the quit rate.
This advantage over fixed pay is weaker with low ambiguity about the relationship between performance
and pay and largely vanishes with high ambiguity.
While not the primary purpose of our work, we contribute to the literature studying choice and
ambiguity. Numerous theories have been developed to explain ambiguity aversion,4 and a number of
experiments have tried to sort out between the various theories. The results indicate a great deal of
heterogeneity, with no one theory explaining the behavior of all subjects.5 The reactions of our subjects to
ambiguity depend on the nature of the ambiguity. The negative effect of low ambiguity on the probability
2 There exist a number of papers in the labor literature on quitting (e.g. Griffeth, Hom, and Gaertner, 2000; Abowd, Kramarz, and Roux, 2006; Abraham, Spletzer, and Harper, 2010; Farber, 2010; Buchinsky, Fougere, Kramarz, and Tchernis, 2010). There also exists a related experimental literature on quitting in tournament settings (Eriksson, Poulsen and Villeval, 2009; Fershtman and Gneezy, 2011; Rosaz, Slonim, and Villeval, 2012). 3 In the United States, somewhat more than two million individuals quit their jobs each month (Bureau of Labor Statistics, 2013). One recent survey reported that “… the number of employees making a New Year's resolution to get a new job jumped to 38 percent [for 2013].” (Perman, 2013). Further, a recent news article reports employee turnover costs the employer approximately 16 to 20 percent of the employee’s annual salary, with percentage being larger for high salaried workers (Lucas, 2012). 4 For examples, see Hurwicz, 1951; Segal, 1987; Gilboa and Schmeidler, 1989; Schmeidler, 1989; Ergin and Gul, 2004; Halevy and Feltkamp, 2005; Ahn, 2008; Klibanoff, Marinacci, and Mukerji, 2005 and 2009; Nau, 2006; Seo, 2009; and Cerreia-Vioglioa, Maccheroni, Marinacci, 2011. 5 See Halevy (2007), Ahn, Choi, Gale, and Kariv (2009), Chen, Katušcák, and Ozdenoren (2007), Binmore, Stewart, and Voorhoeve (2012), Charness, Karni, and Levin (2013), Charness and Gneezy (2010), and Abdellaoui, Baillon, Placido, and Wakker (2011).

5
of choosing and completing the coding task relative to the piece rate treatment is consistent with our
adaptation of the smooth ambiguity model, but the positive effect of moving from low to high ambiguity
(LA vs. HA135) does not fit well with any standard model. We conjecture that the type of extreme
ambiguity subjects encounter in the high ambiguity treatments leads to the adoption of simple rules of
thumb such as valuing the coding task at the midpoint of the high and low possible bonuses (as implied by
the principle of insufficient reason). The high ambiguity treatment with a low maximum possible bonus
(HA100) is included in the experimental design to examine this hypothesis. The significant difference
between HA135 and HA100 is consistent with our conjecture.
There are a number of potential advantages of ambiguous incentive contracts, including those generally
advanced for incomplete contracts (i.e. reducing the cost of writing complex contracts, flexibility to respond
to unforeseen circumstances) as well as reasons related to other-regarding behavior (i.e. black box
compensation is intended to limit infighting over compensation). The results of our paper suggest that there
are costs to ambiguous incentive contracts as well. The low ambiguity treatment is more realistic than the
high ambiguity treatments since workers typically have an idea about the basis of evaluation, but often
don’t know the precise mapping between performance and pay. Our results imply that low levels of
ambiguity impose costs on firms. The unsurprising cost is that contracts with low ambiguity are
unattractive, implying that it will be more difficult to hire and retain workers. Less obvious, ambiguity
about performance pay removes one of the greatest advantages of piece rate systems as there is no longer
selection in favor of high ability workers. This reduces the quality of workers a firm hires and weakens the
positive effect of performance pay on performance. It remains an open question whether the benefits of
ambiguous incentive contracts outweigh the costs.
2. Procedures, Experimental Design, and Treatments
A. Amazon Mechanical Turk: Our experiment is conducted using the online labor market Amazon
Mechanical Turk (AMT). Workers (our subjects) on AMT complete short jobs, referred to as “Human
Intelligence Tasks” (HITs), and are paid through PayPal. We are not the first researchers to use AMT or
other online labor markets (i.e. Odesk, Elance, Crowdflower, and Guru) as a platform for conducting
experiments, and although this remains relatively rare within economics the platform is being used more
often.6 Using AMT has several advantages for us, listed in ascending order of importance. Our description
of AMT reflects the population, rules, and norms at the time the experiments were run in 2012. As current
users may notice, some details have changed over time.
First, AMT allows us to access a more diverse set of subjects than are typically present in laboratory
experiments. Table 1 summarizes the characteristics of our subjects. Our subjects’ ages range from 18 to
6 Economics studies using online labor markets include Chen, Ho, Kim (2010), Liu, Yang, Adamic, and Chen (2011), Paolacci, Chandler, and Ipeirotis (2010), Horton, Rand, and Zeckhauser (2011), and Dean and McNeill (2014).

6
69. A total of 31 countries are represented with the majority coming from India and a large minority from
the USA. Most are college educated and 40% report incomes in excess of $25,000 per year, a figure which
jumps to 71% for American subjects.7
[Insert Table 1]
Second, we take advantage of AMT’s low costs to run an unusually large number of subjects. This is
especially important for us because we build an instrument into our experimental design and then use a
Heckman correction to correct for the effects of selection on performance in contracts with ambiguity.
Without correcting for selection we have little hope of accurately measuring the effect of contract types on
performance, but using the Heckman correction makes high demands on the power of our study. Using
AMT makes it possible to do this without taking out a second mortgage.
The final and most important advantage of using AMT is that our experiments take place within an
existing labor market. This lets us take advantage of a naturally occurring feature of this market that is
present in many real labor markets, the ability of subjects to quit after accepting a contract. Like many
experiments, our work does not fit neatly into a classification of lab versus field experiments. Our subjects
know that they are participating in a study, but we intentionally use the above feature of the underlying
labor market that was naturally occurring rather than part of the experimental design.
There are several concerns with experiments run on AMT. The scale of payoffs is much lower than
experimenters typically use in laboratory studies. The average subject who completed the experiment only
earned $0.62. This was reasonable compensation by AMT standards at the time, but low compared to what
a college student in the US or Europe typically gets paid for participating in an experiment. Even given
that this was a fast experiment (subjects averaged 23 minutes to complete the entire study), the average
earnings per hour were only $1.62/hour. This raises the possibility that the incentives were not salient for
the subjects. However, virtually all of our subjects (97%) reported that earning money was one of their
motivations for taking HITs on AMT8 and our subjects responded strongly to changes in incentives (see
Result 3). These two observations indicate that the incentives were salient.
Another concern is loss of control due to conducting the study online. Unlike a laboratory study, we
cannot be sure that subjects were not consulting outside sources. We intentionally choose a task where
7 Indian subjects had significantly lower incomes than the other subjects (t = 12.19; p < .01). Only 24% of Indian subjects report an income in excess of $25,000 as opposed to 62% of other subjects. 8 The pre-experimental survey asked subjects why they complete tasks on AMT. Subjects chose from six options (Ipeirotis, 2010). Subjects could check as many or few items as desired. We classify a subject as motivated by earning money if they choose “fruitful way to spend free time and get some cash,” “for ‘primary’ income purposes (e.g. gas, bills, groceries, credit cards)”, “for ‘secondary’ income purposes, pocket change (for hobbies, gadgets, going out),” or “I am currently unemployed, or have only a part time job.” For the final category, a subject is only classified as motivated by earning money if they did not also check a category which was inconsistent with a desire to earn money (i.e. “to kill time” or “I find the tasks to be fun”).

7
consulting the internet would not be helpful. Subjects are not told that Charness and Dufwenberg (2006)
is the source of the game and subjects and are not given any information that would make it easy to find
this information via a Google search.
AMT has a number of specific features that differ from those faced in a typical lab setting. Many
elements of our design are intended to prevent a loss of control due to these features. These AMT specific
modifications are described in Section 2.4.
A number of studies exist comparing AMT and laboratory experiments. In one well known example,
Horton, Rand, and Zeckhauser (2011) replicate a number of standard experiments on AMT and report
results that look little different from the typical results of laboratory experiments. A number of subsequent
papers report similar findings when comparing lab and online studies (Suri and Watts, 2011; Amir and
Rand, 2012; De Winter, Kyriakidis, Dodou, and Happee, 2015; Wang, Huang, Yao, and Chan, 2015). We
doubt that the use of AMT has a major effect, one way or the other, on the conclusions we reach from our
experiments.
B. Tasks: Subjects have the option of participating in two tasks: coding messages (Task A) or a simple
transcription task (Task B).
Figure 1: Trust Game with Hidden Actions
Task A uses data from Charness and Dufwenberg (2006). In the Charness and Dufwenberg
experiments, subjects played the trust game with hidden actions shown in Figure 1. Player A starts the
game by choosing whether to trust Player B (by choosing In) or not (by choosing Out). If Player A chooses
In, Player B can either be trustworthy (by choosing Roll) or not (by choosing Don’t).
The critical feature of the Charness and Dufwenberg data for our experiment is the pre-game messages
sent by Player Bs. These can be used to persuade Player A to choose “In” by promising to choose “Roll”.

8
Charness and Dufwenberg report all of the messages verbatim in the published version of their paper. Task
A asks subjects to code fifteen of these messages. For each message, the subject is shown a JPG image of
a hand-written copy of the text (see Figure 2). We use hand-written copies of the messages as a form of
human verification.9 This makes it more difficult to copy and paste the text into a search engine or a
translation program, as well as making it impossible for an internet bot to complete the task. Subjects are
asked to classify messages into six possible categories, shown below the text of the message (see Figure 2).
These categories are drawn from a pre-experimental coding of the fifteen messages done by the co-authors.
Subjects are free to check multiple categories for a message, a possibility that is stressed in the instructions.
They also have the option to indicate that none of the six categories apply. All subjects who choose Task
A see the same fifteen messages in the same order. The fifteen messages are chosen to vary the content,
length, and difficulty of coding.
Figure 2: Task A Example
We score a message’s coding as correct if it matches the modal coding for subjects who code that
particular message.10 This scoring rule is based on the coding methodology developed by Houser and Xiao
(2011). Coding is an inherently subjective exercise, but for all fifteen questions the modal coding is similar
to what we would choose as informed experts. We think a neutral expert would agree that subjects credited
with more correctly coded messages had performed better.
We choose this particular task, coding messages from experimental data, for several reasons. We want
a real effort task that can easily be done in an online environment, but not one where the subjects can use
access to the internet or their computer to get help. Part of the experimental design involves giving subjects
information (based on practice questions) about their ability to perform the task prior to choosing a task.
9 The messages were hand copied by multiple RAs, so the handwriting varied across messages. Human verification such as CAPTCHAs is designed to verify that information is being entered by human users rather than internet bots. 10 For providing feedback on the practice questions, we used data from an initial set of the sessions without feedback to determine whether a coding was correct. The modal coding of the five practice questions for this subset of the data matches the modal coding for all experimental participants, so the feedback was accurate.

9
We therefore need a task where performance can be evaluated in a clear fashion, but a subject will not be
able to determine their performance without the experimenters giving them information. Given the
subjective nature of coding messages, there is no way a subject could know their performance without being
told. This inherent ambiguity matches the type of situation we have in mind in the real world, where it isn’t
necessarily obvious how well somebody is doing at their job.
The Charness and Dufwenberg game is specifically chosen for several reasons. The messages are
publicly available and de-identified, easing IRB approval of the study. The game is relatively simple and
easy to explain. The messages are short enough to be easily read and coded, but categorization is
sufficiently difficult that subjects were not faced with a trivial task.
In Task B, the transcription task, subjects are shown a series of fifteen words. Each word has to be
typed into a text box. The words are shown as JPG images to prevent copying and pasting or use of bots.
We use typed text for the JPG images rather than hand-written versions to facilitate transcription. The
transcription task is intended to be a sure thing, and we have no cases of incorrect transcription. Task B
takes the same amount of time to complete as Task A, a point which is emphasized to the subjects, and
requires some effort (albeit less than Task A) as the subject must pay attention to new words appearing and
type them correctly into the text box.
C. Procedures and Experimental Design: Experimental “sessions” are posted on AMT in small batches
of 15 to 25 HITs. We do not hide the fact that the HITs are part of a study. Given the large number of
studies posted on AMT and the nature of the tasks subjects are asked to complete, it seems unlikely that
subjects would fail to guess that they are participating in a study.
Subjects are told up front that the experiment consists of two phases lasting 5 minutes and 8 – 10
minutes respectively, with the first phase of the experiment paying a 20 cent flat wage for completing a
survey and the second phase of the experiment paying an unspecified bonus for doing a task.11 It is stressed
to the subjects that they will only be paid if they complete both phases of the experiment.
Figure 3: Experiment Design
Figure 3 illustrates the timing of the experiment. After indicating consent, subjects begin the first phase
of the experiment by filling out a survey. This collects demographic information (age, gender, nationality,
11 The time estimates were optimistic as subjects spent more time than we expected for the second phase.
Survey Practice
Task Feedback/
No-Feedback Task
Selection

10
income, and educational background) and their reasons for working on AMT. The survey also contains a
questionnaire measuring their risk attitudes, and a measure of ambiguity aversion. Seven of the questions
measuring risk attitudes are taken from the German Socio-Economic Panel (GSOEP). These questions ask
about subjects’ willingness to take risks in general as well as in a number of narrower domains (e.g. driving
a car). Dohmen, Falk, Hoffman, Sunde, Schupp, and Wagner (2011) validate these questions as a measure
of risk attitudes. We also measure risk by asking subjects about their willingness to make a risky investment
if they had a financial windfall. This is a hypothetical version of the investment decision used by Gneezy
and Potters (1997). To measure ambiguity aversion, we present subjects with the standard pair of
hypothetical questions used to generate the Ellsberg paradox (Ellsberg, 1961):
“Suppose there is a bag containing 90 balls. You know that 30 are red and the other 60 are a mix
of black and yellow in unknown proportion. One ball is to be drawn from the bag at random. You
are offered a choice to (a) win $100 if the ball is red and nothing if otherwise, or (b) win $100 if
it's black and nothing if otherwise. Which do you prefer?”
“The bag is refilled as before, and a second ball is to drawn from the bag at random. You are
offered a choice to (c) win $100 if the ball is red or yellow, or (d) win $100 if the ball is black or
yellow. Which do you prefer?”
Choices of (a) and (d) are inconsistent with subjective expected utility and can be interpreted as
evidence of ambiguity aversion (e.g. Hogarth and Villeval, 2010; Dominiak, Dürsch, and Lefort, 2012).
Copies of all experimental materials, including the survey, can be seen in Appendix A.
After completing the survey, subjects are given descriptions of Task A (coding) and Task B
(transcription). The description of Task A includes a description of Charness and Dufwenberg’s trust game
with hidden actions, how to perform the coding, and the coding categories. Subjects view several examples
of messages and coding. We intentionally do not give subjects a citation to Charness and Dufwenberg or
the name of the game to make it difficult to search for additional information on the web. The description
of Task B (transcription) is shorter given the trivial nature of the task, and focuses on making it clear that
Task B is a sure thing. Before selecting a task, subjects code five messages for practice. Subjects are then
asked how they thought they did at coding the practice messages in comparison to other subjects. The
wording of this question is deliberately vague to avoid reducing the ambiguity in the high ambiguity
treatments (“How well do you think you performed the practice task in comparison to other Turkers?”).
Responses are on a Likert scale ranging from 0 (“Well below average”) to 4 (“Well above average”), with
2 representing “average” performance. The mean response is 2.42, indicating subjects on average think
they are better than average. Regardless of treatment, subjects do not have information about their
performance on the practice questions prior to answering this question.

11
At this point, subjects begin the second phase of the experiment by choosing between Task A or Task
B. Task B serves as an outside option. It has a fixed and known payoff. We randomly vary the payoff for
Task B between 30, 40, and 50 cents. This is resolved in advance and subjects know the value of the outside
option.12 Based on calibration exercises we expect the average bonus for Task A to be about 40 cents,13 so
the average payoff for Task B is set to roughly match the average for Task A. Varying the payoffs for Task
B gives us an exogenous source of variation that can be used to identify a selection equation. The
instructions stress that Task B is a sure thing and takes the same amount of time as Task A. In other words,
subjects are given no reason to base their task choice on one task taking less time to complete than the other.
The treatments, described in Section 2.E, vary what information subjects have about Task A prior to
choosing a task.
Task A consists of coding 15 messages. Subjects are forced to spend at least 30 seconds on each
message before they can continue. This parallels Task B, where subjects have to spend at least 30 seconds
on each screen before the next word appears. There are 15 words in Task B, so both tasks require 7½
minutes to complete if subjects do not go beyond the required 30 seconds. Although subjects consistently
ran over the required 7½ minutes, the average time to complete the experiment was the same for Task A
and Task B. Consistent with what subjects are told when choosing a task, the two tasks take the same
amount of time.
This is a between subjects design, so each subject participates in a single treatment, and subjects cannot
participate in the experiment more than once. We drop 19% of the observations (167/863) as unusable.
Most of these observations (151/167) are dropped due to subjects failing the screen for English
comprehension as described in Section 2.D.14
Table 2 summarizes the number of subjects recruited for each cell of each treatment and how many
usable observations we have for each cell. With a few exceptions described below, 35 subjects were
recruited for each cell.
[Insert Table 2]
After selecting a task, subjects finish the experiment by performing their selected task. To get paid,
subjects have to complete the task. Unlike a lab experiment, subjects can quit the experiment by leaving
the website or prematurely submitting the HIT. We have 106 observations (out of 696 usable observations)
where subjects quit after starting one of the tasks. The instructions and materials feature prominent
12 Subjects are not told that other values were possible for the outside option to avoid any mistaken impression that the outside option was a gamble. 13 By pure luck, the average bonus for Task A in our data is exactly as calibrated. 14 Eleven subjects are dropped due to filling out less than half of the survey, making their data unusable. Responses to the survey are bimodal. Subjects either fill out the entire survey or, in these eleven cases, almost nothing. Five observations were dropped from subjects who took advantage of a recruiting glitch to participate a second time.

12
reminders that subjects must complete the entire task to get paid, so we think it is unlikely that many quits
are due to errors. Quitting a HIT is like quitting any job, and presumably reflects the subject’s judgment
that the opportunity cost of completing the HIT outweighs the benefits. We were aware of quitting when
we designed the experiments and view it as a natural feature of this and many employment environments.
Rather than treating quits as a bug, our approach has been to try to understand how the experimental
treatments affect the likelihood of quitting.
Bonuses are paid within a few days of completing the experiment. Subjects know that the payment of
the bonus would be delayed. This is not unusual for AMT and would not have surprised the subjects.
D) AMT Specific Design Issues: Our experiments contain a number of features addressing AMT specific
issues. Our subjects come from all over the world. The experimental materials inform subjects that English
fluency is required to complete the HIT, but this requirement is unenforceable. The survey therefore
includes two questions testing subjects’ English comprehension. Both questions have only one correct
answer and the correct answer is given as part of the question. For example, one of these questions reads,
“Over the weekend, Bob watched two football games. On the scale below, mark the number of football
games Bob watched over the weekend.” Any subject who reads this question carefully and understands
English should be able to answer it correctly.
There has been a persistent problem on AMT with workers who try to complete tasks as fast as possible
to maximize their revenues, clicking buttons rapidly without spending much time to check whether their
responses make any sense. AMT actively tries to screen out workers who have a history of providing poor
quality work. Our HIT is not particularly attractive for this type of worker as it is relatively intricate and
has built in timers that prevent subjects from clicking through as fast as possible. The English
comprehension questions also screen for this sort of behavior. The answers for the two English
comprehension questions are located in different columns. This prevents subjects who are mechanically
checking the first or last columns from passing the comprehension test without actually reading and
understanding the questions.
We drop observations from subjects who do not correctly answer the two English comprehension
questions. We suspect that most dropped subjects comprehend English but weren’t reading the questions
carefully. Given the nature of our experiment, we do not want to use data from subjects who are not actually
reading the material.
Another concern with using AMT is that subjects either use multiple accounts simultaneously to be
paid for a task more than once or collude with other AMT workers by sharing information (e.g. how to code
the messages).15 We took a number of steps to address these concerns. To limit collusion, the posting of
15 Because subjects are paid via their Amazon account (each AMT account has to be linked to a unique email address and PayPal account), the same person can only participate more than by multiple accounts. We explored

13
HITs was scattered over time with only a limited number of slots available at any point in time. This makes
it difficult for a group to collude since only a small number of slots were posted at any given time and the
pool of potential workers is large. We also monitored online forums for evidence that our HIT was being
discussed. We found no evidence that information about the HIT (specifically, information about how to
code the messages or how the bonus was determined) was being shared. Ex post, we checked our data for
autocorrelation. If subjects worked together or simultaneously completed multiple versions of the
experiment, we should see correlation across time of completion. There is no significant autocorrelation
either in task selection or performance.
Workers in AMT can view the HTML file being used to generate the HIT. This creates the possibility
that subjects could eliminate the ambiguity or otherwise game the system by viewing the code. Several
features of the experiment limit this possibility. Each treatment of the experiment uses a different HTML
file. Subjects therefore cannot look at the HTML and gain more information than they were supposed to
have by viewing the instructions for other treatments. Bonus payments are determined manually by the
research team, so the HTML cannot be used to determine the incentive contract or the correct coding for
any particular message. In sessions with feedback, the portion of the HTML used for determining whether
or not the subject correctly coded the practice messages is intentionally convoluted.16 This makes it
extremely difficult to use the HTML to cheat on the practice messages. While there are no incentives to
cheat on the practice messages, we thought it best to eliminate this possibility.
E. Treatments
E.1 Information about Determination of Bonus
Fixed (FIXED): Task A pays 40 cents regardless of performance. This contract is a sure thing and gives
no incentives for performance. This is included to confirm that subjects are responsive to incentives. Even
though both tasks take the same amount of time, we do not expect subjects with fixed pay for Task A to
always choose the task with the higher payoff since subjects may be willing to sacrifice money to do an
easier task or one that is more interesting. Nevertheless, the willingness to do Task A should be a decreasing
function of the pay for the outside option (Task B).
Piece Rate (PR): Subjects are paid a piece rate of 9 cents for each message coded correctly. The
instructions for choosing a task tell subjects the number of messages to be coded, the 9 cent piece rate, and
the minimum ($0.00) and maximum ($1.35) possible bonuses from Task A. They are given detailed
instructions about the rule for determining whether a message is coded correctly. The goal is to eliminate
collecting the IP addresses of subjects as a way of identifying subjects using multiple accounts. This ran into two problems: (1) Our IRB would not allow us to collect this information without telling subjects, which would have made many subjects unwilling to participate, and (2) IP addresses do not uniquely identify individuals. 16 A large amount of extraneous code was added to the HTML. Finding the code that determined whether a specific practice question was correct was equivalent to finding the proverbial needle in a haystack.

14
any ambiguity about the incentive contract. The PR treatment gives us a baseline to determine the effects
of ambiguity about the incentive contract.
Low Ambiguity (LA): Subjects are paid a piece rate of 9 cents for each message coded correctly. The
instructions include a detailed description of the rule for determining whether a message is coded correctly.
Subjects are not told the piece rate, the number of questions, or even that a piece rate system is being used.
Instead, they are informed the bonus will “depend on how well you do at coding messages correctly.” In
other words, subjects know that there is a positive relationship between how many messages are coded
correctly and their bonus, but have no information about what that relationship might be. They are told the
minimum ($0.00) and maximum ($1.35) possible bonuses from Task A, but since they do not know the
number of messages it is not possible to infer the piece rate or even that a piece rate system is being used.
The incentive contract in the LA treatment is more ambiguous than the incentive contract in the PR
treatment. In the PR treatment, a subject who knows the probability of coding a message correctly also
knows the distribution of bonuses. In the LA treatment, knowing the probability of coding a message
correctly is not sufficient to know the distribution of bonuses.
High Ambiguity (HA): Subjects are paid a piece rate of 9 cents for each message coded correctly. The
instructions include the minimum ($0.00) and maximum ($1.00 or $1.35) possible bonuses from Task A.
Subjects are given no additional information about how the bonus is determined. Specifically, subjects are
not told the piece rate (or even that a piece rate system is being used), the number of questions, or the rule
used to determine if a message has been coded correctly. The HA treatment represents a higher level of
ambiguity than the LA treatment, since subjects have no information about how the bonus is determined
beyond the minimum and maximum possible bonus. In the LA treatment subjects know how performance
is measured and that there is a positive relationship between performance and the bonus.
Initially the HA treatment only used the true maximum bonus of $1.35 (HA135). As data accumulated,
we noticed that the take-up rate for Task A was surprisingly high in HA135 given the high level of
ambiguity. We suspected subjects were using simple rules of thumb that would be sensitive to the
maximum possible bonus. To test this, we added the HA100 treatment.
In HA100, subjects are told that the maximum possible bonus is $1.00. This statement is essentially
true; while subjects could earn as much as $1.35 in theory, in reality subjects almost never earn a bonus
more than $0.99.17 Since the purpose of HA100 is to determine the effect of changing the maximum
possible bonus in the HA treatment, it always uses the outside option of 50 cents and we over-sample the
two HA cells with an outside option of 50 cents to generate more power for making this comparison.18
17 One subject in the entire experiment earned $1.05. This happened after we started running HA100 and we had gathered hundreds of observations before beginning HA100. 18 Looking at Table 2, observant readers will notice that one cell of the PR treatment is also over-sampled. This was not intentional – a HIT was accidentally posted twice on AMT. Three other cells are off by a couple of observations,

15
E.2 Treatments: Information about Likely Performance
Feedback: Prior to choosing a task, subjects are told the number of practice messages they coded correctly.
The correlation between the number of practice messages coded correctly and the number of messages
coded correctly in Task A (for subjects who chose and completed Task A) is .51, so the number of practice
messages coded correctly is a good predictor of performance at Task A.19 We do not include cells with
feedback in HA treatments since giving subjects feedback requires giving them the rule for determining
whether a message is coded correctly.
Receiving feedback reduces the uncertainty faced by subjects by reducing their uncertainty about the
likelihood of coding a message correctly. For example, consider a subject in the PR treatment who
considers it equally likely that their probability of coding any given message correctly is either 0, ½, or 1.
If they code one message correctly, the best and worst case scenarios can be eliminated. The subject still
faces risk, but the uncertainty has been eliminated. Feedback also improves subjects’ calibration about
their ability to code messages correctly, an important issue since subjects are overconfident on average.
No Feedback: Subjects do not receive feedback about the number of practice messages coded correctly.
3. Theory and Hypotheses
A. Theory: This paper is not intended to test the various theories of ambiguity aversion, but it is nonetheless
useful to develop a formal model in order to generate hypotheses. We treat subjects who don’t know the
details of how their bonus is determined or their skill at the coding task as facing ambiguity. Multiple priors
correspond in a natural way to the multiple incentive contracts a subject believes could possibly be in effect.
We therefore adapt the smooth ambiguity model of Klibanoff, Marinacci, and Mukerji (2005) to our
experiment. A subject faces a choice between an option with an unknown value (Task A) and a sure thing
(Task B). Let b ∊ [bmin, bmax] be the bonus for Task A. If a subject chooses Task A, they also must choose
an effort e ∊ [emin, emax] to put into coding messages. Let the cost of effort be given by c(e), where c’(e) >
0 and c’’(e) > 0. We assume that costs of effort are known rather than a source of uncertainty. A subject’s
payoff from Task A is given by b – c(e). Let K be the sure payoff from Task B.
A state of the world gives the probability of each possible bonus as a function of effort. We model the
state of the world as having two components, s and α, where α ∊ 0,1 captures ability to perform the task
and s ∊ Δ contains all other elements of the state of the world such as the incentive contract. The objective
probability of earning b in state s α subject to choosing e is given by f(s,α,b,e) and the expected bonus in
state s α is calculated in the usual fashion. Critically, we assume that if α' > α, then f(s,α',b,e) first order
stochastic dominates f(s,α,b,e). Holding s and e fixed, higher ability leads to a higher expected bonus. Let
which aren’t mistakes per se but instead are due to the oddities of how HITs are posted on AMT and our need to pay bonuses in a timely fashion. 19 The correlation between these variables is easily significant at the 1% level.

16
be a differentiable function with ' > 0 and '' < 0 and let ν and μ be the subjective probability distributions
over s and α. The subject’s value for Task A is given by (1). Task A is chosen if this is greater than (K).
max
min maxmin
b1
e e ,e0 s b
max b f s, ,b,e c(e) db d d
(1)
The assumption that is concave implies ambiguity aversion in the following sense: holding effort
fixed, a mean preserving spread (contraction) over the states of the world makes the coding task less (more)
attractive versus a sure outside option. This leads to the following proposition implying that changes in
information that represent a pure reduction in uncertainty (i.e. mean preserving contractions) will lead to
more choices of Task A. Note that this proposition is stated and proved in terms of mean preserving
contractions of μ, but applies equally well to mean preserving spreads of ν.
Proposition 1: Let μ and μ’ be subjective probability distributions over Δ. Suppose a subject chooses the
coding task and effort e* under μ. If μ’ is a mean preserving contraction of μ, the subject will also choose
the coding task under μ’.
Proof: See Appendix B.
The HA135 and HA100 treatments (with an outside option of 50 cents) only differ in what subjects are
told was the maximum possible bonus. A simple way to model this change in information is by holding
beliefs over the state of the world fixed but changing beliefs, subject to the state of the world, by applying
Bayes Rule. Specifically, beliefs are updated so bonuses greater than 100 receive zero weight (see
Appendix B for details). Given this approach, we can prove Proposition 2.
Proposition 2: Assume that for all states the probability distribution of bonuses as a function of effort has
full support over the range [bmin, bmax]. Suppose a subject chooses the sure thing (Task B) with a maximum
bonus of bmax. If the maximum bonus is reduced to b and the subjective probability distribution over states
is unchanged, the subject must still choose the sure thing.
Proof: See Appendix B.
If an individual knows their value of α, it is trivial to show that if they choose Task A with ability α,
they also choose Task A with ability α' > α. More realistically for our experiment, suppose an individual
does not know their ability. Just as having greater ability in the case with known ability implies a greater
willingness to choose Task A, believing you have greater ability (in the sense of first order stochastic
dominance) also implies a greater willingness to choose Task A.

17
Proposition 3: Let ν and ν' be subjective probability distributions over ability. Suppose a subject chooses
the coding task and effort e* under ν. If ν' first order stochastic dominates ν, the subject will also choose
the coding task under ν'.
Proof: See Appendix B.
B. Hypotheses: Moving from HA135 to LA to PR reduces the uncertainty facing subjects. Comparing
the HA135 and LA treatments, subjects are given two additional pieces of information in the LA
treatment: (1) the rule for how performance is evaluated and (2) the bonus is an increasing function of
performance. This eliminates extreme rules such as automatically giving all subjects the worst possible
bonus or automatically giving all subjects the highest possible bonus. If the primary effect of moving
from HA135 to LA is to reduce the subjective probability of extreme states, as seems likely, Proposition 1
implies that the coding task becomes more attractive. Likewise, under the LA treatment there are an
infinite number of monotonically increasing rules for determining the bonus. Some of these rules are
quite bad for subjects (i.e a step function giving the maximum possible if all messages are correctly and
zero otherwise) while others are more desirable (i.e. a step function giving the maximum possible bonus if
any message is coded correctly). If moving from LA to PR primarily affects behavior by moving weight
away from extreme states, Proposition 1 again implies that the coding task becomes more attractive.
Our discussion of the theory focused on the likelihood of initially choosing Task A, but also applies
to quitting after having chosen Task A. As each new message is presented for coding, subjects face a
decision to either continue with the coding task or take their outside option by leaving the experiment.
They have not received any additional information about the payoff rule beyond what they knew when
choosing a task, although presumably they have learned more about the difficulty of the coding task.
When making quit decisions, the payoff rules affect the ambiguity of the continuation payoff in the same
manner the payoffs from Task A were affected when choosing between Tasks A and B. Our predictions
about completing Task A, subject to choosing Task A, mirror our predictions about choosing Task A.
Hypothesis 1: Controlling for subject characteristics and the value of the outside option, the probability
of choosing and completing Task A is increasing as we shift from the HA135 treatment to the LA treatment
to the PR treatment.
Proposition 2 implies Hypothesis 2. Foreshadowing the results, Hypothesis 1 fails when we compare
LA and HA135. Even though Hypothesis 2 is generated from the model, evidence in favor of Hypothesis
2 does not validate the model. Rather, it helps us understand why Hypothesis 1 did not hold.

18
Hypothesis 2: Controlling for subject characteristics and holding the value of the outside option fixed, the
probability of choosing and completing Task A is decreasing as we shift from the HA135 treatment to the
HA100 treatment.
In FIXED, the bonus does not depend on performance at Task A and subjects face no ambiguity. If
incentives are salient, we expect choice of Task A to respond to the size of the outside option.
Hypothesis 3: As the payment for Task B increases in FIXED, choice of Task A is reduced.
Proposition 3 implies that subjects who believe they are more able are more likely to choose and
complete Task A. If there is positive correlation between a subject’s actual ability and their beliefs,
Hypothesis 4 follows.
Hypothesis 4: For PR, LA, HA135, and HA100, the probability of choosing and completing Task A is an
increasing function of coding task ability as measured by performance on the practice questions.
Hypothesis 4 predicts positive selection in the PR, LA, HA135, and HA100 treatments, but does not
predict how strong this relationship will be. We can develop some intuition for possible differences
between treatments by noting that positive selection relies on subjects perceiving links between ability and
bonuses – higher ability leads to higher performance leads to higher bonuses. The link between
performance and bonuses is transparent in the PR treatment. In the treatments with ambiguity (LA, HA135,
and HA100), we expect that subjects’ beliefs put weight on incentive contracts where the relationship
between performance and bonuses is weak or non-existent. This leads to the following conjecture:
Conjecture 1: The relationship between ability and choosing and completing Task A will weaken as
ambiguity becomes greater shifting from the PR to the LA to the HA135 treatment.
Giving subjects feedback has two effects. It reduces subjects’ uncertainty about their ability. Coding
is an unfamiliar task for our subjects, chosen to create ambiguity. They are unlikely to know how good
they are at this task, but giving them feedback should reduce this uncertainty. If this functions as a mean
reducing spread of ν, reducing uncertainty without affecting expected ability, Task A becomes more
attractive as was the case when ambiguity about the incentive contract was reduced. However, feedback
may also improve the calibration of subjects’ beliefs about their ability. Recall that, on average, subjects
thought they were above average at the coding task. Feedback should reduce their overconfidence. Because
reducing the uncertainty and reducing overconfidence work in opposite directions, we make no firm
prediction about the effect of feedback on the likelihood of choosing Task A. If we assume the effect of
reducing uncertainty is smaller than the effect of reducing overconfidence, Conjecture 2 follows. This is a
placeholder, since we have no way of knowing ex ante whether the effect of reducing uncertainty or
overconfidence is larger.

19
Conjecture 2: Controlling for subject characteristics, the value of the outside option, and information
about the incentive contract, the probability of choosing and completing Task A should decrease when
feedback is provided in treatments where the bonus depends on performance (PR and LA).
Using the model to predict how the treatments affect the number of messages coded correctly subject
to choosing and completing Task A is equivalent to predicting how the optimal choice of effort is affected
by the treatments. Unfortunately, this requires knowing the sign of the third derivative of and there is no
basis for assuming the sign is either positive or negative. We therefore make no formal prediction.
That said, we conjecture that reducing ambiguity increases the number of messages coded correctly
subject to choosing Task A. Intuitively, the marginal cost of increased effort is a sure thing while the
marginal return is uncertain. A decrease in uncertainty should make the marginal return more attractive.
Conjecture 3: Controlling for selection and subject characteristics, the number of messages coded
correctly subject to choosing Task A should be increasing as we shift from the HA135 treatment to the LA
treatment to the PR treatment.
4. Results: Table 3 summarizes the data by treatment. The percentage of quits is subject to choosing
Task A and the number of messages coded correctly is subject to choosing and completing Task A.
[Insert Table 3]
A. Task Selection and Completion: Ambiguity about the incentive contract affects task selection and
completion, but not exactly as expected. Subjects are less likely to choose Task A, more likely to quit after
choosing Task A, and less likely to choose and complete Task A in the LA treatment than the PR treatment.
All of the preceding observations are consistent with Hypothesis 1, but the high rate of subjects choosing
Task A in the HA135 treatment relative to the LA treatment runs contrary to Hypothesis 1. Quitting is
more likely in HA135 than LA, consistent with Hypothesis 1, but this is sufficiently weak that subjects are
also more likely to choose and complete Task A in HA135 than in LA, contrary to Hypothesis 1.
Task selection under high ambiguity is sensitive to the maximum possible payoff, as predicted by
Hypothesis 2, with choice of Task A less common in HA100 than HA135. This difference remains large
if we limit the data to observations with an outside option of 50 cents (56.9% select Task A in HA135 vs.
36.7% in HA100). Quitting is more common in HA100, so it is also less common to choose and complete
Task A in HA100 than HA135.
Comparing outside options of 30, 40, and 50 cents, the percentages choosing Task A are 47.4%, 35.0%,
and 20.0% respectively in FIXED, the only treatment where the incentives are completely unambiguous.
This supports Hypothesis 3, providing strong evidence that the incentives are salient for subjects. It is
mildly surprising that many subjects choose Task A even when it unambiguously lowers earnings, but
presumably these subjects derive enjoyment from doing the more interesting task.

20
Feedback lowers the percentage of subjects who choose Task A. Quits increase with feedback, so the
probability of choosing and completing Task A is also lowered by feedback. This effect is larger in the
pooled data from the PR and LA treatments, where performance is relevant for a subject’s earnings, than in
FIXED. Conjecture 2 is supported by the data, suggesting that the primary effect of feedback is a reduction
of overconfidence.
We are surprised by the relatively high rate of quitting in FIXED. Two features of the data provide a
possible explanation for this oddity: (1) The ability (as measured by performance on the practice questions)
of subjects choosing Task A is lower in FIXED than other treatments and (2) The quits in FIXED come
disproportionately from subjects who have high outside options (40 or 50 cents).20 The latter observation
suggests that subjects who quit in FIXED often choose Task A because they think it will be more interesting
than Task B. In reality it is rather tedious, presumably more so for subjects who aren’t very good at the
task. Once they realize that Task A isn’t very interesting, subjects who have no monetary reason for
choosing it in the first place are prime candidates to quit.
Definitive conclusions about task selection and quitting should not be drawn from the raw data
summarized in Table 3. By design the value of the outside option varies between subjects. This was
intended to be balanced between treatments, but the random pattern of who fails the English screen as well
as oversampling in the HA treatment means that the sample is not truly balanced. Likewise, even with
random assignment there is variation in subjects’ demographic characteristics across treatments. To make
statistically valid statements about the effects of the treatments on task selection and completion, Table 4
reports the results of regressions examining whether subjects choose Task A, quit subject to having chosen
Task A, and, combining task selection and quits, choose and complete Task A.
[Insert Table 4]
All regressions on Table 4 include a dummy for subjects who do not indicate that earning money is
among their reasons for completing tasks on AMT. These subjects are significantly less likely to select
Task A and significantly more likely to quit if they chose Task A. These estimates are not reported to save
space, but full copies of the regression output are available from the authors upon request. Table 4 reports
parameter estimates, not marginal effects.
Models 1 and 2 are probits with a dummy for whether the subject chooses Task A as the dependent
variable. Robust standard errors are reported in parentheses. Model 1 estimates treatment effects while
controlling for the value of the outside option. The base is the PR treatment without feedback. Note that
there are two separate dummies for feedback, with the effect for the FIXED treatment estimated separately
20 Quit rates in FIXED are 18.5%, 28.6% and 36.4% for outside options of 30, 40, and 50 cents respectively. This positive correlation does not occur for the other treatments.

21
from the effect for the PR and LA treatments. Since performance does not affect the bonus in FIXED, we
predicted a weaker effect from feedback in this treatment.
The parameter estimate for LA is negative and significant at the 5% level in Model 1. Consistent with
Hypothesis 1, low ambiguity lowers subjects’ willingness to choose Task A. HA135 has a positive effect
relative to the PR treatment, although not significant, but the difference between the parameter estimates
for the LA and HA135 treatments is significant at the 1% level (z = 3.14; p ≤ .01). Holding the maximum
possible bonus fixed, high ambiguity raises willingness to choose Task A relative to low ambiguity. This
is not consistent with Hypothesis 1. Task selection under high ambiguity is sensitive to the maximum
possible bonus, consistent with Hypothesis 2, as the difference between the estimates for HA135 and HA
100 is significant at the 5% level (z = 2.15; p ≤ .05). Both parameter estimates for the effect of feedback
are negative, but neither is significant and the magnitudes are similar. This is inconsistent with Conjecture
2. Both dummies for the outside option are significant and the difference between the dummies for outside
options of 40 and 50 cents is also significant (z = 2.43; p < .05). If the dataset is limited to observations
from FIXED, the dummy for having an outside option of 50 cents is negative and significant at the 1% level
(z = 2.97; p < .01) as is the difference between outside options of 40 and 50 cents (z = 1.99; p < .05).
Subjects respond strongly to incentives consistent with Hypothesis 3.
Model 2 adds controls for subject demographics: age, gender, nationality, income, and education. For
nationality we include dummies for India and the USA, with all other nationalities serving as the base.
Given that Indians and Americans make up 88% of the sample, this captures most of the variation by
nationality. The survey questions for income and education only allow for categorical answers, so the
independent variables are dummies for the various categories.
Model 2 also adds controls for the subject’s risk and ambiguity attitudes as well as a control for their
confidence in their ability to perform Task A. The survey on risk attitude includes seven questions on risk
attitudes drawn from the GSOEP as well as a hypothetical investment question based on the investment
decision used by Gneezy and Potters (1997). The answers for the seven GSOEP questions are highly
correlated, so we combine them into a single measure using factor analysis.21 We classify subjects as
ambiguity averse, ambiguity neutral, or ambiguity loving based on their answers to the two Ellsberg
questions. Subjects who are ambiguity averse are coded as a 1 while those who are ambiguity loving are
coded as a -1. After completing the practice questions subjects are asked about their performance relative
to other Turkers.22 We use this as our measure of confidence. The number of practice questions answered
21 The use of a single factor is based off of the Kaiser criterion which suggests only keeping factors with eigenvalues greater than or equal to one (Yeomans and Golder, 1982). 22 The question asked, “How well do you think you performed the practice task in comparison to other Turkers?” Subject marked their answer using a 5 point Likert scale ranging from well below average to well above average.

22
correctly is also included as an independent variable. This allows us to separate the effect of confidence
from the effects of skill at Task A. To save space, Table 2 does not report all of the added variables in
Models 2, 4, and 6, focusing on the variables of greatest economic interest. Full regression output is
available from the authors upon request.
The main results are little changed between Models 1 and 2. The parameter estimates for FIXED and
LA are still negative and significant, and the difference between HA135 and LA remains significant at the
1% level (z = 2.79; p ≤ .01). The difference between HA135 and HA100 is slightly weaker, narrowly
missing significance at the 5% level (z = 1.95; p ≤ .10). Looking at the control variables, gender has a
weakly significant effect as men are more likely to choose Task A than women. Neither the risk nor
ambiguity measures are statistically significant.
Models 3 and 4 look at the decision to quit subject to having selected Task A. These are probits with
a Heckman correction since there is selection into the population of subjects that choose Task A. For the
Heckman model to be identified, we need an exogenous source of variation that is correlated with decisions
to select Task A but not with actions subject to choosing Task A. By design, the value of the outside option
serves this purpose. The base is the PR treatment. The independent variables in Models 3 and 4 are the
same as those in Models 1 and 2. Model 3 is a basic regression that only controls for the treatment while
Model 4 adds controls for demographics and the behavioral measures.
Looking at Model 3, the HA100, and HA135 treatments both significantly increase the frequency of
quitting (the difference between the estimates for HA100 and HA135 is not significant). The LA treatment
also increases quits, but this effect is not significant. Feedback increases the frequency of quitting, albeit
weakly, in the treatments where task performance is payoff relevant (PR and LA). The treatment with the
strongest effect on quits is FIXED, with the estimate easily significant at the 1% level.
The results are little changed by the inclusion of additional control variables in Model 4. The HA100
and HA135 treatments remain statistically significant at the 5% and 10% levels respectively. Feedback in
the PR and LA treatments is now significant at the 5% level. Looking at the control variables, subjects who
are less risk averse (as measured by the hypothetical investment question) or less ambiguity averse are
significantly more likely to quit.23 Subjects who are more confident about their ability to code messages
quit significantly less.
The dependent variable for Models 5 and 6 is a dummy for whether the subject select and complete
Task A, combining the effects reported in Models 1 – 4. The specifications are identical to Models 1 and
2 respectively, and the results are similar to those reported in Models 1 and 2. This similarity is unsurprising
since relatively few subjects quit. One notable exception is the negative effect of feedback in the PR and
23 Given how the measures are constructed, a positive change on the hypothetical investment question corresponds to less risk aversion while a positive change on the ambiguity measure corresponds to more ambiguity aversion.

23
LA treatments, which is now significant at the 5% level in both models. Feedback in these two treatments
weakly decreases the proportion of subjects choosing Task A and increases the percentage who quit. The
combination of these two weak effects yields a strong effect on the probability of choosing and completing
Task A. The effects of ambiguity attitudes and overconfidence on quitting are sufficiently strong that both
variables have a weakly significant, positive effect on the probability of choosing and completing Task A.
Our main results on task selection and completion are summarized as follows:
Result 1: Relative to the PR treatment, the LA treatment lowers the probability of choosing and completing
Task A. This is consistent with Hypothesis 1. Relative to the LA treatment, the HA135 treatment
significantly raises the probability of choosing and completing Task A. This effect is due to a higher
probability of choosing Task A and is not consistent with Hypothesis 1.
Result 2: The HA100 treatment lowers the probability of choosing and completing Task A relative to
HA135. This is consistent with Hypothesis 2.
Result 3: Consistent with Hypothesis 3, the probability of choosing Task A decreases as the payoff from the
outside option (Task B) increases.
Result 4: For the PR and LA treatments (pooled), feedback about performance on the practice questions
lowers the probability of choosing and completing Task A. This is consistent with Conjecture 2.
B. Selection: Results 1 – 3 establish that the treatments affect whether people choose and complete Task
A. A related question is whether they affect what type of people choose and complete Task A. In particular,
a manager should be interested in whether there is selection by skill level.
A natural measure of skill in our experiments is performance on the practice coding questions. Recall
that before choosing a task, all subjects are given five practice questions. There is a strong relationship
between performance on the practice questions and performance in Task A (see regressions results in
Section 4.C). Although the practice questions are not incentivized, subjects have good reason to take them
seriously since they will be choosing whether or not to do similar tasks for pay.
Figure 4 illustrates the relationship between performance on the practice questions and task selection.
Performance on the practice questions is broken into three categories (0 – 1 correct, 2 correct, 3 – 4 correct)
that roughly divide our data into thirds.24 For each treatment we display, by category of performance on
the practice questions, the percentage of subjects choosing and completing Task A.
In the piece rate treatment, low ability types (0 – 1 practice questions correct) are much less likely to
choose and complete Task A. This is true whether or not feedback is given. For FIXED, LA, and HA 135,
there is no obvious relationship between ability and the likelihood of choosing and completing Task A, and
the relationship is reversed in HA100 with high ability types less likely to choose and complete Task A.
24 No subjects got all five practice questions correct.
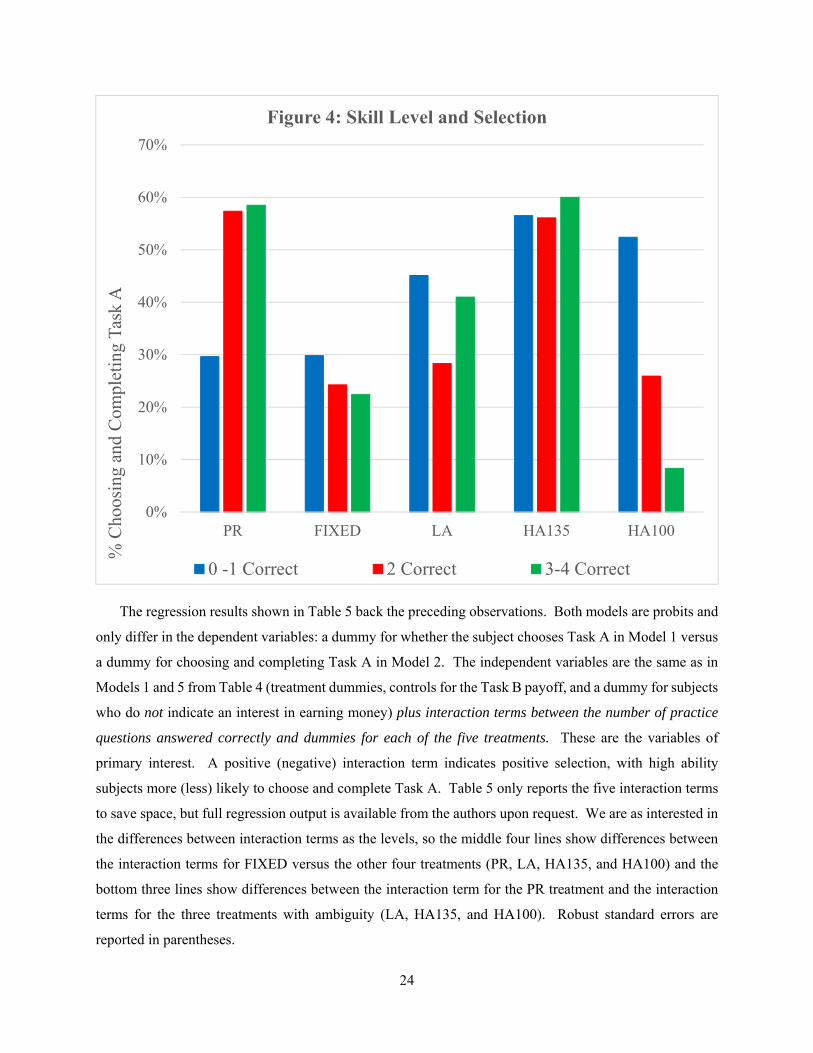
24
The regression results shown in Table 5 back the preceding observations. Both models are probits and
only differ in the dependent variables: a dummy for whether the subject chooses Task A in Model 1 versus
a dummy for choosing and completing Task A in Model 2. The independent variables are the same as in
Models 1 and 5 from Table 4 (treatment dummies, controls for the Task B payoff, and a dummy for subjects
who do not indicate an interest in earning money) plus interaction terms between the number of practice
questions answered correctly and dummies for each of the five treatments. These are the variables of
primary interest. A positive (negative) interaction term indicates positive selection, with high ability
subjects more (less) likely to choose and complete Task A. Table 5 only reports the five interaction terms
to save space, but full regression output is available from the authors upon request. We are as interested in
the differences between interaction terms as the levels, so the middle four lines show differences between
the interaction terms for FIXED versus the other four treatments (PR, LA, HA135, and HA100) and the
bottom three lines show differences between the interaction term for the PR treatment and the interaction
terms for the three treatments with ambiguity (LA, HA135, and HA100). Robust standard errors are
reported in parentheses.
0%
10%
20%
30%
40%
50%
60%
70%
PR FIXED LA HA135 HA100
% C
hoos
ing
and
Com
plet
ing
Task
AFigure 4: Skill Level and Selection
0 -1 Correct 2 Correct 3-4 Correct

25
(Insert Table 5)
In both models, the interaction term for the PR treatment is positive and significant. This matches our
impression from Figure 4. High ability subjects are more likely to choose (or choose and complete) Task
A in the PR treatment. In no other treatment is there a positive and significant interaction effect.
Comparing differences in interaction terms between FIXED and the other treatments measures whether
selection into Task A is improved relative to a fixed payment. As expected, PR significantly improves
selection. The only other treatment that generates a significant improvement is HA135, and this is weak
from a statistical point of view and vanishes once we consider choosing and completing Task A. Looking
at the differences in interaction effects between PR and the treatments with ambiguity, these are always
negative and almost always significant. Positive selection is significantly stronger with an explicit piece
rate than ambiguous incentives. It is particularly striking that this holds for the LA treatment, where
subjects know that higher performance yields a higher bonus.
To summarize, use of an explicit piece rate generates positive selection, with high ability types more
likely to choose (or choose and complete) Task A. This vanishes with ambiguity. At best no selection on
skill level takes place and in some cases selection is reversed to favor low ability types choosing Task A.25
Result 5: In the PR treatment, high ability types are more likely to choose and complete Task A. This
selection effect is eliminated and possibly reversed with ambiguity. Other than the PR treatment, the data
is not consistent with Hypothesis 4 but does support Conjecture 1.
C. Performance: Our measure of performance is how many messages are coded correctly in Phase 2. A
message is counted as correct if the subject’s coding matches the modal coding for the population.26 This
is the criterion that is used in the experiment to determine whether or not a subject is paid the piece rate for
coding a message correctly.
Returning to Table 3, the number of messages coded correctly by subjects who choose and complete
Task A is higher in the PR treatment than in FIXED either with or without feedback. Performance in the
LA treatment falls between FIXED and PR either with or without feedback. Performance in the HA135
and HA100 treatments is only slightly higher than in FIXED without feedback (recall that feedback was
never provided in the high ambiguity treatments).
The preceding suggests that piece rate contracts and, to a lesser extent, incentive contracts with low
ambiguity improve performance. However, this may reflect the effect of selection rather than any direct
effect on subjects’ effort. As suggested by the analysis in Section 4.B, there are large differences between
treatments in the ability level of subjects who choose and complete Task A. This is documented in Table
6. The first column displays average performance by treatment on the five practice questions, limiting the
25 We have checked whether feedback affects selection into Task A, but find no significant results. 26 The population is subjects who are included in the dataset and coded the message in question.

26
sample to subjects who chose and completed Task A. As a point of comparison, the first row reports
average performance on the practice questions by all 696 subjects (this includes all subjects whether or not
they choose Task A). The next two columns give the results of t-tests comparing performance on the
practice questions with average performance across all subjects and performance by subjects who choose
and complete Task A in FIXED. Among subjects who choose and complete Task A, ability (as measured
by performance on the practice questions) is highest in the PR treatment, significantly higher than either
the population average or FIXED. None of the other treatments significantly improve ability over these
two benchmarks, and ability is significantly worse in HA100. This is admittedly crude statistical analysis,
but it should nonetheless reinforce the point that the selection processes differ between treatments.
[Insert Table 6 here]
The regressions reported in Table 7 examine how the treatments affect performance, measured by the
number of questions coded correctly in Task A by subjects who choose and complete Task A, and whether
these treatment effects change when we correct for selection. Model 1 is an OLS regression.27 The base is
the FIXED treatment without feedback, and the only independent variables are treatment dummies as well
as the usual control for subjects who did not indicate an interest in earning money. This regression measures
the treatment effects without controlling for selection effects. Compared to the base, the PR treatment
yields a significant increase in performance. There are no other significant treatment effects.
[Insert Table 7 here]
To control for selection, Models 2 and 3 include the number of practice questions answered correctly
as an independent variable. Model 3 also adds controls for demographics (age, income, education, and
gender), risk and ambiguity attitudes, and confidence. As an additional means of accounting for
selection, both regressions are Heckman selection models using the value of the outside option (the fixed
payment for Task B) as an instrument.
The parameter estimate for performance on the practice messages is large, positive, and easily
significant at the 1% level in Models 2 and 3. Controlling for selection, none of the treatments have an
effect on performance relative to FIXED. The effect of the PR treatment on coding performance is due to
selection effects, similar to the results of Dohmen and Falk (2011).
Result 6: Relative to the FIXED treatment, subjects who choose and complete Task A code more messages
correctly in the PR treatment. This treatment effect is due to selection and vanishes after controlling for
performance on the practice questions. The results do not support Conjecture 3.
27 There is little censoring in the data. Among subjects who complete Task A, only 10 of 281 (3.6%) code zero messages correctly and none coded all fifteen messages correctly. Running a tobit model has little effect on the results reported in Model 1.

27
5. Conclusions: Ambiguity is a common feature of real world incentive contracts. We show that it has
non-trivial effects on who accepts these contracts and how they perform. The most important effect is the
impact on selection. We replicate the common finding that piece rate contracts increase performance, with
the effect due to selection of high ability individuals into the piece rate contract. This positive selection
vanishes with all of the varieties of ambiguity we study, along with the associated bump in performance.
Low levels of ambiguity are quite natural in an incentive contract. Subjects in our LA treatment know that
better performance will yield higher pay, know how performance is measured, and even know the range of
possible bonuses. This is likely more than workers know in many settings. Yet even a low level of
ambiguity is sufficient to vastly reduce the efficacy of performance pay.
Low levels of ambiguity reduce the likelihood of accepting an incentive contract. All types of
ambiguity are associated with higher rates of quitting, with the effect being significant in the two high
ambiguity treatments. Given that conducting a hiring search is expensive, and having to replace workers
is even more expensive, this is further evidence that ambiguity harms the efficacy of performance pay.
Feedback about performance on the practice questions reduces the likelihood of choosing and
completing an incentive contract, suggesting that the effect of feedback on overconfidence is more
important than any associated reduction in uncertainty. We might expect feedback to help the firm in the
long run by reducing quits (due to overconfident workers never taking up the incentive contract rather than
accepting it, learning they aren’t as good at the job as they thought, and subsequently quitting). Our data
is not consistent with this conjecture as quitting is more frequent with feedback. Feedback is apparently a
complement for learning about one’s ability from experience rather than a substitute.
The positive effect of high ambiguity on willingness to choose Task A is not predicted by our model of
ambiguity. Holding the maximum payoff fixed, removing virtually all information about how bonuses
were determined increased the willingness to accept incentive contracts. The sensitivity of this result to the
maximum payoff suggests the use of a simple rule of thumb (consistent with the principle of insufficient
reason) under high ambiguity. Testing theories of ambiguity is not a primary purpose of this paper, but this
result does suggest that how individuals react to ambiguity varies with the nature of the uncertainty.
The usual caveats about generalizing results from experiments conducted in one specific setting apply
here, and we don’t expect the effects of ambiguous incentive contracts to be the same across all labor
markets. We anticipate that stronger effects will occur in entry level labor markets. This conjecture stems
from the nature of the ambiguity. Like our subjects, we expect that many workers face uncertainty about
the relationship between performance and pay as well as uncertainty about their likely performance. As
workers gain experience, they presumably learn along both of these dimensions, reducing any effects due
to ambiguity.

28
Our work raises a number of questions for future research. We find clear differences between the piece
rate and low ambiguity contracts. It is straight forward to design contracts that lie between these two cases,
such as specifying that the piece rate lies within a range rather than indicating a precise value. Knowing
how much ambiguity is needed to disrupt the strong positive selection observed with piece rate contracts
would help us understand how fragile the positive selection result is. On a different dimension, there are
benefits to the firm from having an ambiguous incentive contract. For instance, preserving flexibility is an
obvious advantage of an ambiguous incentive contract. Work is needed to determine the relative costs and
benefits of ambiguity in incentive contracts.

29
Bibliography
Abdellaoui, M., Baillon, A., Placido, L., & Wakker, P. P. (2011). The rich domain of uncertainty: Source functions and their experimental implementation. The American Economic Review, 101(2), 695-723.
Abeler, J., Falk, A., Goette, L., and Huffman, D. (2011). Reference Points and Effort Provision. American Economic Review, 101(2), 470-92.
Abowd, J. M., Kramarz, F., & Roux, S. (2006). Wages, Mobility and Firm Performance: Advantages and Insights from Using Matched Worker–Firm Data*. The Economic Journal, 116(512), F245-F285
Abraham, K. G & Spletzer, J. R., & Harper, M., (2010). Labor in the New Economy, NBER Books, National Bureau of Economic Research, Inc.
Ahn, D. S. (2008). Ambiguity without a state space. The Review of Economic Studies, 75(1), 3-28.
Ahn, D., Choi, S., Gale, D., & Kariv, S. (2009). Estimating ambiguity aversion in a portfolio choice experiment.
Amir, O., & Rand, D. G. (2012). Economic games on the internet: The effect of $1 stakes. PloS one, 7(2), e31461.
Barro, J., & Beaulieu, N. (2003). Selection and improvement: Physician responses to financial incentives (No. w10017). National Bureau of Economic Research.
Binmore, K., Stewart, L., & Voorhoeve, A. (2012). How much ambiguity aversion?. Journal of risk and uncertainty, 45(3), 215-238.
Buchinsky, M., Fougere, D., Kramarz, F., & Tchernis, R. (2010). Interfirm mobility, wages and the returns to seniority and experience in the United States. The Review of Economic Studies, 77(3), 972-1001
Buser, T., & Dreber, A. (2015). The flipside of comparative payment schemes. Management Science.
Cadsby, C. B., Song, F., & Tapon, F. (2007). Sorting and incentive effects of pay for performance: An experimental investigation. Academy of Management Journal, 50(2), 387-405.
Cerreia-Vioglio, S., Maccheroni, F., Marinacci, M., & Montrucchio, L. (2011). Uncertainty averse preferences. Journal of Economic Theory, 146(4), 1275-1330.
Charness, G., & Dufwenberg, M. (2006). Promises and partnership. Econometrica, 74(6), 1579-1601.
Charness, G., & Gneezy, U. (2010). Portfolio choice and risk attitudes: An experiment. Economic Inquiry, 48(1), 133-146.
Charness, G., Karni, E., & Levin, D. (2013). Ambiguity attitudes and social interactions: An experimental investigation. Journal of Risk and Uncertainty, 46(1), 1-25.
Chen, Y., Ho, T. H., & Kim, Y. M. (2010). Knowledge market design: A field experiment at google answers. Journal of Public Economic Theory, 12(4), 641-664.
Chen, Y., Katuščák, P., & Ozdenoren, E. (2007). Sealed bid auctions with ambiguity: Theory and experiments. Journal of Economic Theory, 136(1), 513-535.
Cooper, D., D’Adda, G., and Weber, R. (2013). Leadership in an Incentivized Real Effort Experiment. Florida State University working paper, May 2013.
De Winter, J. C. F., Kyriakidis, M., Dodou, D., & Happee, R. (2015). Using CrowdFlower to study the relationship between self-reported violations and traffic accidents. Procedia Manufacturing, 3, 2518-2525.
Dean, M., & McNeill, J. (2014). Preference for Flexibility and Random Choice: an Experimental Analysis (No. 2014-10).

30
Dohmen, T., & Falk, A. (2011). Performance pay and multidimensional sorting: Productivity, preferences, and gender. The American Economic Review, 101(2), 556-590.
Dohmen, T., Falk, A., Huffman, D., Sunde, U., Schupp, J., & Wagner, G. G. (2011). Individual risk attitudes: Measurement, determinants, and behavioral consequences. Journal of the European Economic Association, 9(3), 522-550.
Dominiak, A., Dürsch, P., & Lefort, J. P. (2012). A dynamic Ellsberg urn experiment. Games and Economic Behavior, 75(2), 625-638.
Ellsberg, D. (1961). Risk, ambiguity, and the Savage axioms. The Quarterly Journal of Economics, 643-669.
Ergin, H., & Gul, F. (2004). A subjective theory of compound lotteries. Journal of Economic Theory, 144, 899-929.
Eriksson, T., Poulsen, A., & Villeval, M. C. (2009). Feedback and incentives: Experimental evidence. Labour Economics, 16(6), 679-688
Eriksson, T., Teyssier, S., & Villeval, M. C. (2009). Self‐Selection and the Efficiency of Tournaments. Economic Inquiry, 47(3), 530-548.
Farber, H. S. (2010). Job loss and the decline in job security in the United States. In Labor in the New Economy (pp. 223-262). University of Chicago Press.
Fershtman, C., & Gneezy, U. (2011). The Tradeoff between Performance and Quitting in High Power Tournaments. Journal of the European Economic Association, 9(2), 318-336.
Gilboa, I., & Schmeidler, D. (1989). Maxmin expected utility with non-unique prior. Journal of mathematical economics, 18(2), 141-153.
Gill, D., Prowse, V., & Vlassopoulos, M. (2012). Cheating in the workplace: An experimental study of the impact of bonuses and productivity. Available at SSRN 2109698.
Gneezy, U., & Potters, J. (1997). An experiment on risk taking and evaluation periods. The Quarterly Journal of Economics, 631-645.
Griffeth, R. W., Hom, P. W., & Gaertner, S. (2000). A meta-analysis of antecedents and correlates of employee turnover: Update, moderator tests, and research implications for the next millennium. Journal of management, 26(3), 463-488
Halevy, Y. (2007). Ellsberg revisited: An experimental study. Econometrica, 75(2), 503-536.
Halevy, Y., & Feltkamp, V. (2005). A Bayesian approach to uncertainty aversion. The Review of Economic Studies, 72(2), 449-466.
Herrmann, M. (2012). Inside Straight: Analyzing “Black-Box” compensation. Above the Law. Retrieved 9/2012. From http://abovethelaw.com/2012/08/inside-straight-analyzing-black-box-compensation/
Hogarth, R., & Villeval, M. C. (2010). Intermittent reinforcement and the persistence of behavior: Experimental evidence.
Horton, J. J., Rand, D. G., & Zeckhauser, R. J. (2011). The online laboratory: Conducting experiments in a real labor market. Experimental Economics, 14(3), 399-425.
Houser, D., & Xiao, E. (2011). Classification of natural language messages using a coordination game. Experimental Economics, 14(1), 1-14
Hurwicz, L. (1951). Optimality criteria for decision making under ignorance. Cowles commission papers, 370.

31
Ipeirotis, P. (2010). Demographics of mechanical turk.
Job Openings and Labor Turnover Summary. (2013). Economic News Release, Bureau of Labor Statistics, Government of United States. Retrieved May 8, 2013, from http://www.bls.gov/news.release/jolts.nr0.htm.
Johnson, D., & Weinhardt, J. (2015). The effect of financial goals and incentives on labor. An experimental test in an online market (No. 2014-85). Department of Economics, University of Calgary.
Klibanoff, P., Marinacci, M., & Mukerji, S. (2005). A smooth model of decision making under ambiguity. Econometrica, 73(6), 1849-1892.
Klibanoff, P., Marinacci, M., & Mukerji, S. (2009). Recursive smooth ambiguity preferences. Journal of Economic Theory, 144(3), 930-976.
Lazear, E. (2000). Performance Pay and Productivity. American Economic Review, 90(5), 1346-1361.
Liu, T. X., Yang, J., Adamic, L. A., & Chen, Y. (2011). Crowdsourcing with all‐pay auctions: A field experiment on Taskcn. Proceedings of the American Society for Information Science and Technology, 48(1), 1-4.
Lucas, S. (2012). How much does it cost companies to lose employees?. cbsnews. Retrieved 5/2013. From http://www.cbsnews.com/8301-505125_162-57552899/how-much-does-it-cost-companies-to-lose-employees/
Nau, R. F. (2006). Uncertainty aversion with second-order utilities and probabilities. Management Science, 52(1), 136-145
Niederle, M., & Vesterlund, L. (2007). Do women shy away from competition? Do men compete too much?. The Quarterly Journal of Economics, 122(3), 1067-1101.
Paolacci, G., Chandler, J., & Ipeirotis, P. (2010). Running experiments on amazon mechanical turk. Judgment and Decision Making, 5(5), 411-419.
Perman, C. (January, 2013). 2013 May be the Year Employees say ‘I Quit!’. CNBC. Retrieved 4/2013. From http://www.cnbc.com/id/100359891
Rosaz, J., Slonim, R., & Villeval, M. C. (2012). Quitting and peer effects at work.
Schmeidler, D. (1989). Subjective probability and expected utility without additivity. Econometrica: Journal of the Econometric Society, 571-587.
Segal, U. (1987). The Ellsberg paradox and risk aversion: An anticipated utility approach. International Economic Review, 175-202.
Seo, K. (2009). Ambiguity and Second‐Order Belief. Econometrica, 77(5), 1575-1605.
SOEP Group. (2001). The German Socio-Economic Panel (GSOEP) after more than 15 years-overview. Vierteljahrshefte zur Wirtschaftsforschung, 70(1), 7-14.
Suri, S., & Watts, D. J. (2011). Cooperation and contagion in web-based, networked public goods experiments. PLoS One, 6(3), e16836.
Wang, S., Huang, C. R., Yao, Y., & Chan, A. (2015). Mechanical Turk-based Experiment vs Laboratory-based Experiment: A Case Study on the Comparison of Semantic Transparency Rating Data.
Yeomans, K. A., & Golder, P. A.. (1982). The Guttman-Kaiser Criterion as a Predictor of the Number of Common Factors. Journal of the Royal Statistical Society. Series D (the Statistician), 31(3), 221–229.

32
Table 1: Subject Characteristics and Task Performance
Variable Obs Mean StDev
Male 696 0.57 0.50
Age 696 31.58 9.94
Indian 696 0.58 0.49
American 696 0.29 0.46
College Graduate 696 0.75 0.43
Income < $12.5K 696 0.37 0.48
Income ≥ $25K 696 0.40 0.49
Primary Income 696 0.24 0.43
Motivated by Earning Money 696 0.97 0.16
Table 2: Count of Subjects by Treatment
Recruited Usable Observations
Outside Option $0.30 $0.40 $0.50 $0.30 $0.40 $0.50
Piece Rate, No Feedback 35 35 35 29 26 30
Piece Rate, Feedback 35 35 50 23 31 36
Fixed Pay, No Feedback 35 35 35 28 27 24
Fixed Pay, Feedback 35 37 35 29 33 31
Low Ambiguity, No Feedback 35 34 35 30 24 32
Low Ambiguity, Feedback 35 35 35 28 28 30
High Ambiguity (Max = $1.35) 35 34 73 31 28 58
High Ambiguity (Max = $1.00) 0 0 75 0 0 60

33
Table 3: Summary of Results by Treatment
Choose Task A Quit (if choosing
Task A) Choose and complete
Task A # Correct (if choosing
and completing Task A)
Piece Rate, No Feedback 55.3% 0.0% 55.3% 4.74
Piece Rate, Feedback 47.7% 9.3% 43.3% 4.97
Fixed Pay, No Feedback 39.2% 22.6% 30.4% 3.63
Fixed Pay, Feedback 30.1% 28.6% 21.5% 4.30
Low Ambiguity, No Feedback 46.5% 7.5% 43.0% 4.41
Low Ambiguity, Feedback 36.0% 9.7% 32.6% 4.68
High Ambiguity (Max = $1.35) 63.2% 9.5% 57.3% 4.06
High Ambiguity (Max = $1.00) 36.7% 13.6% 31.7% 3.63

34
Table 4: Regression Analysis of Treatment Effects on Choosing and Completing of Task A
Model 1 Model 2 Model 3 Model 4 Model 5 Model 6
Dependent Variable Select Task A Dropout from Task A Select and Complete Task A
Fixed Pay -0.469** (0.188)
-0.580*** (0.198)
1.264*** (0.377)
1.205*** (0.387)
-0.689*** (0.191)
-0.784*** (0.201)
Low Ambiguity -0.287** (0.138)
-0.308** (0.143)
0.392 (0.325)
0.214 (0.320)
-0.324** (0.139)
-0.331** (0.144)
High Ambiguity (Max = $1.35) 0.252
(0.171) 0.184
(0.175) 0.748** (0.323)
0.650* (0.376)
0.110 (0.169)
0.070 (0.173)
High Ambiguity (Max = $1.00) -0.202 (0.216)
-0.231 (0.219)
0.921** (0.464)
0.976** (0.468)
-0.344 (0.218)
-0.358 (0.223)
Feedback * Fixed -0.238 (0.199)
-0.166 (0.209)
0.149 (0.379)
0.316 (0.391)
-0.264 (0.209)
-0.222 (0.215)
Feedback * (Piece Rate + Low Ambiguity)
-0.215 (0.138)
-0.234 (0.143)
0.536* (0.315)
0.614** (0.313)
-0.276** (0.138)
-0.311** (0.145)
Outside 40 -0.338***
(0.130) -0.378***
(0.134)
-0.369*** (0.131)
-0.410*** (0.134)
Outside 50 -0.643***
(0.125) -0.710***
(0.131)
-0.600*** (0.126)
-0.659*** (0.133)
Male 0.177
(0.105)*
0.054 (0.234)
0.177* (0.106)
SOEP Risk Questions (Factor)
0.030
(0.060)
.103 (.125)
.003
(.061) Hypothetical Investment
Question
0.002 (0.002)
0.007* (0.004)
0.001
(0.002)
Ambiguity Aversion 0.043
(0.081)
-0.385** (0.178)
0.148* (0.082)
Confidence 0.056
(0.062)
-0.274** (0.128)
0.114* (0.065)
Log Pseudo Likelihood -449.12 -434.56 -549.58 -521.57 -435.83 -419.86
Notes: All regressions are based on 696 observations. Numbers in parentheses are robust standard errors. Three (***), two (**), and one (*) stars indicate statistical significance at the 1%, 5%, and 10% levels.
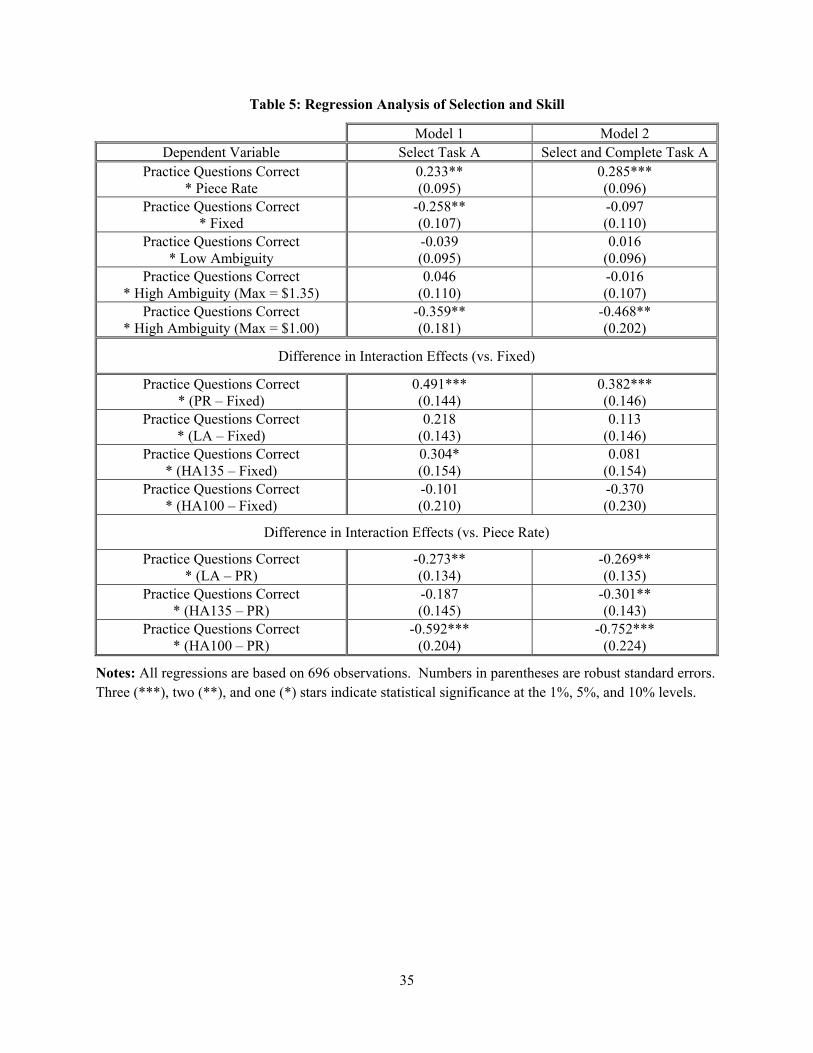
35
Table 5: Regression Analysis of Selection and Skill
Model 1 Model 2 Dependent Variable Select Task A Select and Complete Task A
Practice Questions Correct * Piece Rate
0.233** (0.095)
0.285*** (0.096)
Practice Questions Correct * Fixed
-0.258** (0.107)
-0.097 (0.110)
Practice Questions Correct * Low Ambiguity
-0.039 (0.095)
0.016 (0.096)
Practice Questions Correct * High Ambiguity (Max = $1.35)
0.046 (0.110)
-0.016 (0.107)
Practice Questions Correct * High Ambiguity (Max = $1.00)
-0.359** (0.181)
-0.468** (0.202)
Difference in Interaction Effects (vs. Fixed)
Practice Questions Correct * (PR – Fixed)
0.491*** (0.144)
0.382*** (0.146)
Practice Questions Correct * (LA – Fixed)
0.218 (0.143)
0.113 (0.146)
Practice Questions Correct * (HA135 – Fixed)
0.304* (0.154)
0.081 (0.154)
Practice Questions Correct * (HA100 – Fixed)
-0.101 (0.210)
-0.370 (0.230)
Difference in Interaction Effects (vs. Piece Rate)
Practice Questions Correct * (LA – PR)
-0.273** (0.134)
-0.269** (0.135)
Practice Questions Correct * (HA135 – PR)
-0.187 (0.145)
-0.301** (0.143)
Practice Questions Correct * (HA100 – PR)
-0.592*** (0.204)
-0.752*** (0.224)
Notes: All regressions are based on 696 observations. Numbers in parentheses are robust standard errors. Three (***), two (**), and one (*) stars indicate statistical significance at the 1%, 5%, and 10% levels.

36
Table 6: Ability by Treatment Subject to Choosing and Completing Task A
Average Practice Correct T-test vs. Population Average T-Test vs. Fixed
All Subjects 1.93 --- --- PR 2.26 3.10*** 2.68*** FIXED 1.75 1.09 --- LA 2.05 0.80 1.33 HA135 1.81 0.93 0.26 HA100 1.21 2.90*** 1.79*
Notes: Average reported for “All Subjects” based on all subjects whether or not they choose Task A. Three (***), two (**), and one (*) stars indicate statistical significance at the 1%, 5%, and 10% levels.
37
Table 7: Analysis of Performance
Model 1 Model 2 Model 3
Model Type OLS Heckman Correction
Piece Rate 1.128** (0.547)
0.520 (0.605)
0.065 (0.675)
Low Ambiguity 0.887
(0.566) 0.516
(0.552) 0.062
(0.573)
High Ambiguity (Max = $1.35) 0.455
(0.491) 0.308
(0.577) -0.095 (0.647)
High Ambiguity (Max = $1.00) 0.079
(0.662) 0.624
(0.555) 0.335
(0.560)
Feedback * Fixed 0.661
(0.684) 0.576
(0.641) 0.065
(0.633)
Feedback * (Piece Rate + Low Ambiguity)
0.193 (0.439)
0.134 (0.414)
0.261 (0.441)
Correct Practice 1.113*** (0.110)
0.959*** (0.125)
Notes: Model 1 is based on 281 observations. Models 2 and 3 are based on 696 observations. Numbers in parentheses are robust standard errors. Three (***), two (**), and one (*) stars indicate statistical significance at the 1%, 5%, and 10% levels.

38
For Online Publication
Appendix A: Full Test of Hit
Consent
Informed Consent: I chose to voluntarily to participate in this research project. The purpose of this work is to study the use of crowd sourcing to perform basic data analysis tasks. I have been recruited for this study through Mechanical Turk. Only persons 18 years of age or older may participate, and I affirm that I am 18 years of age or older. This study involves reading hand written messages in English. Only individuals who read and write English may participate. I affirm that I can read and write in English.
The initial phase of this study will take about 5 minutes to complete and will involve me answering a number of survey questions. If I complete the first phase of the study, I will be eligible for a second phase where I can earn a bonus by either completing a basic data analysis task, coding verbal responses, or performing a transcription task. The second phase of the study will last 8 - 10 minutes.
I will earn 20 cents (USA) for successfully completing the first phase of the study. I will then be given details on the second phase of the study, including an explanation of what bonuses I will be eligible to earn.
I am free to withdraw from the study at any time and without incurring the ill will of the researchers. I will only be paid if I complete both phases of the task.
There are no known risks or benefits from this study beyond those from any typical activity you might do in an online environment. This study will benefit society by helping researchers to better understand the use of crowd sourcing to analyze data.
The confidentiality of any personal information will be protected to the extent allowed by law. To the extent allowed by law, only the researcher and any research assistants conducting this experiment will have access to the data from this study. My name will not be reported with any results related to this research.
I can obtain further information from David Johnson ([email protected]). If I have questions concerning my rights as a research subject, I can call the FSU Human Subjects Committee office at 1-850-644-8836 or email them at [email protected].
I may ask questions at any time via email ([email protected]). Please feel free to contact us at this email address if you have any questions. Should new information become available during the course of this study about risks or benefits that might affect my willingness to continue in this research project, it will be given to me as soon as possible.
By clicking on the checkbox below, you indicate consent to participate in this study.
Phase 1
1. What is your gender?
2. What is your age?
3. What country do you currently live in?

39
4. What is your Nationality?
5. Which of the following best describes your highest achieved education level? Dropdown box. Categories are: (1) High School; (2) High School Graduate; (3) Some college, no degree; (4) Associates degree; (5) Bachelors degree; (6) Graduate degree (Masters, Doctorate, etc.).
6. Over the weekend, Bob watched 2 football games. On the scale below, mark the number of football games Bob watched over the weekend. Scale goes from 0 to 4.
7. What is the total income of your household? Dropdown box. Categories are: (1) 12,500; (2) 12,500 - 24,999; (3) 25,000 - 37,499; (4) 37,500-49,999; (5) 50,000 - 62,499; (6) 62,500 - 74,999; (7) 75,000 - 87,499; (8) 87,500-99,999; (9) 100,000 or more.
8. Why do you complete tasks in Mechanical Turk? Please check any of the following that applies: Categories are: (1) Fruitful way to spend free time and get some cash; (2) for primary income purposes (e.g. gas, bills, groceries, credit cards; (3) for secondary income purposes, pocket change (for hobbies, gadgets, going out); (4) to kill time; (5) I find the task to be fun; and (6) I am currently unemployed, or have only a part time job.
9. Next year, Jack and Jill are planning on visiting Disneyland. Jill has been to Disneyland many times while Jack has never been (0 times). On the scale below, mark how often Jack has been to Disneyland. Scale goes from 0 to 4.
10. How do you see yourself: Are you generally a person who is fully prepared to take risks or do you try to avoid taking risks? Please tick a box on the scale, where the value 0 means: "risk averse" and the value 10 means: "fully prepared to take risks". You can use the values in between to make your estimate.
11. People can behave differently in different situations. How would you rate your willingness to take risks in the following areas? Please tick a box on the scale, where the value 0 means: "risk averse" and the value 10 means: "fully prepared to take risks". You can use the values in between to make your estimate. The six categories are: (1) while driving; (2) in financial matters; (3) during leisure and sport; (4) in your occupation; (5) with your health; (6) your faith in other people.
12. Please consider what you would do in the following situation: Imagine that you had won 100,000 dollars in the lottery. Almost immediately after you collect the winnings, you receive the following financial offer from a reputable bank, the conditions of which are as follows: There is the chance to double the money within two years. It is equally possible that you could lose half of the amount invested. You have the opportunity to invest the full amount, part of the amount or reject the offer. What share of your lottery winnings would you be prepared to invest in this financially risky, yet lucrative investment? Please tick a box in each line of the scale
13. Suppose there is a bag containing 90 balls. You know that 30 are red and the other 60 are a mix of black and yellow in unknown proportion. One ball is to be drawn from the bag at random. You are offered a choice to (a) win $ 100 if the ball is red and nothing if otherwise, or (b) win $100 if it's black and nothing if otherwise. Which do you prefer?

40
14. The bag is refilled as before, and a second ball is to drawn from the bag at random. You are offered a choice to (c) win $ 100 if the ball is red or yellow, or (d) win $ 100 if the ball is black or yellow. Which do you prefer?
Phase 2
Thank you for completing the survey. In the next part of the HIT you will have the option of completing one of two possible tasks. Completing either of the tasks will earn you a bonus beyond the 20 cents you earned for completing the survey. You will only be paid if you complete both phases of the HIT.
In the first Task (Task A) you will be asked to classify a series of short messages sent by players participating in a social science experiment involving monetary incentives, trust, and reciprocity. You will get more instructions concerning this on the next page.
In the second Task (Task B), you will be asked to type a word that appears in an image. We have calibrated the tasks so that each task takes about the same amount of time. The words are fairly simple. If you are paying attention, you should have no problem typing all of the words correctly.
Before you make your selection, we have some messages that we would like you to classify for practice. Please use these practice messages to become familiar with Task A. After you have completed the practice messages you will be asked to select between Task A and B. Your bonus will be paid in addition to the amount that you made completing the survey. When you are ready, please click the "Begin Practice" button.
As previously discussed in this HIT, you will be asked to classify short messages sent by players participating in a social science experiment. In this experiment, subjects were randomly grouped into pairs to play a single game. The game had two roles, an A and B player.
The game is shown in the tree below. At the start of the game the A player had the option to select IN or OUT. If the A player selected OUT, both A and B earned 5 dollars. If A selected IN, the B player was then given the option to choose ROLL or DON'T ROLL. If the B player selected DON"T ROLL, the B player would earn 14 dollars and the A player would earn 0.

41
Alternatively if the B player selected ROLL, the B player would earn 10 dollars while a 6 sided dice would be rolled to determine the A player’s earning. If the dice came up 1, the A player would earn 0; if the dice came up 2 through 6, the A player would earn 12 dollars. The game ended when payoffs were assigned. Subjects were paid their earnings, in cash, and had no further interaction with the other player (or any other experimental subject).
The messages you are coding were sent by B players to A players. These were sent at the beginning of the game, before the A player decided whether or not they would select IN or OUT. The players did not know each other’s identities (i.e. play was anonymous) and had no opportunity to communicate other than the pre-game message by the B player.
Before you begin coding, please look carefully at the description of the game to make certain you understand this material. If you would like clarification, you can email [email protected] with questions.
MAIN INSTRUCTIONS:
Please classify each of these handwritten messages using the key located below the handwritten text. You can classify a message by clicking the checkbox adjacent to the classification. Note, each message may have more than one possible classification. You should check all that you think apply.
A description of the available classifications for the messages follows. Please read through this material carefully. Before you begin it is important for you to know how to code the messages. If you would like clarification, you may email [email protected] with questions.
Promise to roll (explicit or implied): Check this box if the message being sent either explicitly states that the sender will choose Roll or implies that the sender will choose Roll.

42
Appeal for Trust: Check this box if the message sent is asking the recipient, either explicitly or implicitly, to trust the sender of the message.
Appeal for Individual Monetary Incentive: Check this box if the message being sent asks the subject to make a selection that would be in the recipient's own monetary interest.
Appeal to joint payoffs: Check this box if the message being sent by the sender suggests that the recipient make a decision that will result in both individuals making more money.
Appeal to fairness: Check this box if the message being sent by the sender suggests that the recipient make a fair decision such as a decision that results in both players earning a more equal amount.
Attempt to build rapport (e.g. jokes, friendly banter): Check this box if the message being sent is an attempt to establish a personal connection with the recipient through the use of jokes or friendly banter.
None of the Above: Check this box if none of the above classifications are applicable to the message.
Before you begin, please consider the examples below:
Example 1
This example would be coded for two categories, “Promise to roll” and “Appeal to joint payoffs.”
Example 2
This example would be coded as one category, “Promise to roll.”
Please begin when you are ready. When you are finished, please hit the "NEXT" button. If you have trouble reading the text, you can zoom in by holding "Ctrl" and pressing "+".
Practice Questions
1) I’m going to roll 2) Take a risk 3) I have laundry to do tonight and I really don’t want to do it1 but I don’t have clean underwear left and I
don’t want to go commando tomorrow. We’ll see what I decide tonight. This man acts funny doesn’t he? But he seems cool, he’s quite the character. All this mystery is kinda cool.

43
4) The fairest thing to do is if you opt “In”. Then I will proceed to choose “roll”. That way you and I have 5/6 chance to make money for the both of us. That is much better than just making $ 5.00 each increase both our chances. Thanks.
5) Choose in, I will roll dice, your are 5/6 likely to get 2,3,4,5, or 6 → $ 12. This way both of us will win something. How well do you think you performed the practice task in comparison to other Turkers? Subject marked their answer using a Likert scale ranging from well below average to well above average. If in feedback they see the following pop-up box:
-------------------------------------------------------------------
FIXED
You will now select between the two tasks. Task A consists of coding messages like what you did during in the practice task. However, Task A will have more messages and will not include any messages you saw during the practice task. In Task B you will type a word in the textbox below the word. Remember, each task takes about the same amount of time to complete.
If you select Task A, you will earn a bonus of 40 cents for certain for completing the task (i.e. coding all of the messages).
If you select Task B, you will be paid a bonus of 50 cents if you successfully type all of the words. Task B is designed to be sufficiently easy that you will earn this bonus for certain as long as you pay attention. Your bonus will be paid in addition to the amount that you made

44
completing the survey. You will only be paid if you complete either Task A or Task B in the second phase of the HIT.
Please select the task that you wish to complete.
---------------------------------------------------------------------
HA
You will now select between the two tasks. Task A consists of coding messages like what you did during in the practice task. However, Task A will have more messages and will not include any messages you saw during the practice task. In Task B you will type a word in the textbox below the word. Remember, each task takes about the same amount of time to complete.
If you select Task A, you will earn a bonus somewhere between 0 and 135 cents for completing the task (i.e. coding all of the messages).
If you select Task B, you will be paid a bonus of 30 cents if you successfully type all of the words. Task B is designed to be sufficiently easy that you will earn this bonus for certain as long as you pay attention. Your bonus will be paid in addition to the amount that you made completing the survey. You will only be paid if you complete either Task A or Task B in the second phase of the HIT.
Please select the task that you wish to complete.
-----------------------------------------------------
LA
You will now select between the two tasks. Task A consists of coding messages like what you did during in the practice task. However, Task A will have more messages and will not include any messages you saw during the practice task. In Task B you will type a word in the textbox below the word. Remember, each task takes about the same amount of time to complete.
If you select Task A, you will earn a bonus somewhere between 0 and 135 cents for completing the task (i.e. coding all of the messages). The precise bonus you earn will depend on how well you do at coding messages correctly.
A message is counted as "correct" if your coding matches the coding chosen by the most people participating in this study. Consider the example shown below:

45
Example 1
Suppose that 50% of participants code "Promise to Roll", and "Appeal to Joint Payoffs", 20% code only "Promise to Roll", 15% code only "Appeal to Joint Payoffs", and 15 % code "None of the Above". To get credit for a correct coding you must code both "Promise to Roll" and "Appeal to Joint Payoffs".
Example 2
Suppose that 35% of participants code "Promise to Roll", 25% "Appeal to Joint Payoffs" and
"Promise to Roll", 30% code only "Appeal to Joint Payoffs", and 10 % code "None of the Above". To get credit for a correct coding you must code only "Promise to Roll."
If you select Task B, you will be paid a bonus of 30 cents if you successfully type all of the words. Task B is designed to be sufficiently easy that you will earn this bonus for certain as long as you pay attention. Your bonus will be paid in addition to the amount that you made completing the survey. You will only be paid if you complete either Task A or Task B in the second phase of the HIT.
Please select the task that you wish to complete.
----------------------------------------------------------------------------------------------
PR
You will now select between the two tasks. Task A consists of coding messages like what you did during in the practice task. However, Task A will have more messages and will not include any messages you saw during the practice task. In Task B you will type a word in the textbox below the word. Remember, each task takes about the same amount of time to complete.
If you select Task A, you will earn a bonus of 9 cents for each message you code correctly. There are 15 messages, so if you select Task A, you will earn a bonus somewhere between 0 and 135 cents for completing the task (i.e. coding all of the messages).

46
A message is counted as "correct" if your coding matches the coding chosen by the most people participating in this study. Consider the example shown below:
Example 1
Suppose that 50% of participants code "Promise to Roll", and "Appeal to Joint Payoffs", 20% code only "Promise to Roll", 15% code only "Appeal to Joint Payoffs", and 15 % code "None of the Above". To get credit for a correct coding you must code both "Promise to Roll" and "Appeal to Joint Payoffs".
Example 2
Suppose that 35% of participants code "Promise to Roll", 25% "Appeal to Joint Payoffs" and
"Promise to Roll", 30% code only "Appeal to Joint Payoffs", and 10 % code "None of the Above". To get credit for a correct coding you must code only "Promise to Roll."
If you select Task B, you will be paid a bonus of 30 cents if you successfully type all of the words. Task B is designed to be sufficiently easy that you will earn this bonus for certain as long as you pay attention. Your bonus will be paid in addition to the amount that you made completing the survey. You will only be paid if you complete either Task A or Task B in the second phase of the HIT
Messages if Worker Selected Task A
1) You can have the 2 extra dollars. I’ll be nice and choose to roll. 2) Stay IN, I really need the money. 3) Tee hee, this is kinda Twilight Zone – ism; Why not “go for it”, eh? I hope you have a lovely
evening as well. 4) Please choose In so we can get paid more. 5) If you choose in I’ll roll. P In R Why? If you choose out, we walk out with $10 each. If you
choose IN & I choose IN then both of us coin. So it’s a compromise. By agreeing to this I guarantee myself more $ than risking you choose out. So if you choose out I get $10 ($5 diff.) if you choose in I get $15 vs. $19 ($4 diff.). that’s why
6) Hello fair stranger, anonymous partner _ _ _ Choose whatever you want. Far be it from me to influence your decision, but I think you should choose “in” and I should choose “roll” and we should take the chance at both earning as much as we can. 5 chances out of 6 say it’ll work, and

47
I’m totally broke, looking to rake in stray cash however I can. I feel the luck in the air. E In R I don’t really have much else to say. Hope you’re doing well, whoever you are. Yes. That’s all. Random note from random human
7) Have a Happy day 8) If you stay in, the chances of the die coming up other than 1 are 5 in 6 – pretty good. Otherwise,
we’d both be stuck at $5. (If you opt out) 9) If you will choose “In”, I will choose to roll. This way, we both have an opportunity to make
more than $5! 10) You’ll still be gaining more than if I had chosen Don’t roll. 11) Good luck I do not know what I’m going to do, so I have no hints on how to advise you on
choosing “in” or “out.” Though it would be beneficial for me to pick don’t roll and hope you pick “in”, I also like to give you a chance to gain some cash. Who knows?
12) Choose “In” so we can both make some $$ What are the chances me rolling a 1? I’ll try my best. 13) If I roll a 2–6 (you’ll know when you receive the $, you will give $5.00 to a stranger. P In R
[[[then there is a line, under which is written “Sign here if you are so kind]]] Thanks. 14) Hi, well I’m going to Roll so you have at least a shot for more money. I hope it works out. 15) CHOOSE IN, SO WE CAN ROLL AND GET $12 AND $10.
Words if worker selected Task B
1) Automobile 2) Calamari 3) Dinosaur 4) Hootenanny 5) Juxtapose 6) Luminary 7) Mallard 8) Molasses 9) Plateau 10) Rupture 11) Subliminal 12) Turtle 13) Unleaded 14) Zombie 15) Attention

48
Appendix B: Proofs of Propositions
Proof of Proposition 1: Let e** be the optimal effort if Task A is chosen under μ’. Since is a concave
function, (A.1) must be true.
max max
min min
b b
s b s b
b f s,b,e* c(e*) db d ' b f s,b,e* c(e*) db d > K
(A.1)
By revealed preference, (A.2) must be true and the result follows. Q.E.D.
max max
min min
b b
s b s b
b f s,b,e** c(e**) db d ' b f s,b,e* c(e*) db d '
(A.2)
In the setup for Proposition 2, when the bonus rate is restricted to be less than b, the probability distribution
for bonuses (subject to s and e) is derived from the original probability distribution via Bayes Rule. For
each s Δ let f(s,b,e,b) objective probability of earning b in state s subject to choosing e and restricting the
bonus to be weakly less than b where b < bmax. Equation (5) derives f(s,b,e,b) from f(s,b,e) via Bayes
Rule:
min
b
b
f s,b,ef s,b,e, b if b b
f s, ,e d
0 if b > b
Proof of Proposition 2: Let EB(s,e,b) be the objective expected bonus in state s subject to choosing e
and restricting the bonus to be weakly less than b. For every state of the world j, EB(s,e,b) < EB(s,e).
Suppose the subject chooses Task A with the restricted bonus. Since is an increasing function, the
value of Task A must be strictly higher without the restriction. A contradiction follows Q.E.D.
The preceding assumes that all states of the world remain possible with restriction of the maximum
bonus, but having some states become impossible is easily incorporated into the theory. Assign zero
subjective probability to all states of the world that never yield a payoff less than or equal to b. Update the
subjective probability of the remaining states of the world using Bayes Rule. For all remaining states,
update the probability of each possible bonus using Bayes Rule as above. Proposition 2 extends to this
richer version of the model.

49
Proof of Propostion 3: Holding e fixed, the term below is an increasing function of ability (α).
max
min
b
s b
b f s, ,b,e c(e) db d
If ν' first order stochastic dominates ν, the preceding implies that the following relationship is true hold e
fixed.
max max
min min
b b1 1
0 s b 0 s b
b f s, ,b,e c(e) db d d ' b f s, ,b,e c(e) db d d
Suppose that e solves an individual’s optimization problem under ν. The preceding implies that the
individual has a strictly higher value for Task A using e under ν'. By revealed preference, the value of
Task A must again be (weakly) higher if the individual is optimizing under ν'. Since (K) is unaffected
by changes in the subjective distribution over ability, the result follows. Q.E.D.