algorithms for nlp - cs.cmu.edutbergkir/11711fa17/fa17 11-711 lecture 16... · proposal? en vertu...
TRANSCRIPT

Parsing/ClassificationITaylorBerg-Kirkpatrick– CMU
Slides:DanKlein– UCBerkeley
AlgorithmsforNLP
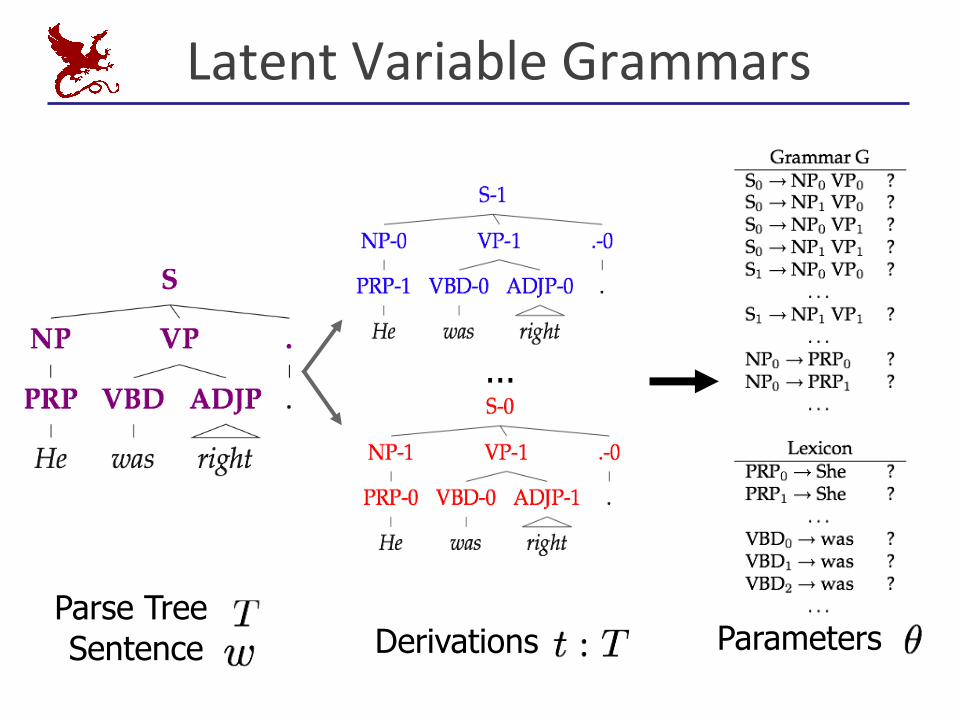
LatentVariableGrammars
Parse Tree Sentence Parameters
...
Derivations

Backward
LearningLatentAnnotations
EMalgorithm:
X1
X2X7X4
X5 X6X3
He was right
.
§ Brackets are known§ Base categories are known§ Only induce subcategories
JustlikeForward-BackwardforHMMs.Forward

0
5
10
15
20
25
30
35
40
NP
VP PP
ADVP S
ADJP
SBAR Q
P
WH
NP
PRN
NX
SIN
V
PRT
WH
PP SQ
CO
NJP
FRAG
NAC UC
P
WH
ADVP INTJ
SBAR
Q
RR
C
WH
ADJP X
RO
OT
LST
NumberofPhrasalSubcategories

NumberofLexicalSubcategories
0
10
20
30
40
50
60
70
NNP JJ
NNS NN VBN RB
VBG VB VBD CD IN
VBZ
VBP DT
NNPS CC JJ
RJJ
S :PR
PPR
P$ MD
RBR
WP
POS
PDT
WRB
-LRB
- .EX
WP$
WDT
-RRB
- ''FW RB
S TO$
UH, ``
SYM RP LS #

LearnedSplits
§ Proper Nouns (NNP):
§ Personal pronouns (PRP):
NNP-14 Oct. Nov. Sept.NNP-12 John Robert JamesNNP-2 J. E. L.NNP-1 Bush Noriega Peters
NNP-15 New San WallNNP-3 York Francisco Street
PRP-0 It He IPRP-1 it he theyPRP-2 it them him

§ Relativeadverbs(RBR):
§ CardinalNumbers(CD):
RBR-0 further lower higherRBR-1 more less MoreRBR-2 earlier Earlier later
CD-7 one two ThreeCD-4 1989 1990 1988CD-11 million billion trillionCD-0 1 50 100CD-3 1 30 31CD-9 78 58 34
LearnedSplits
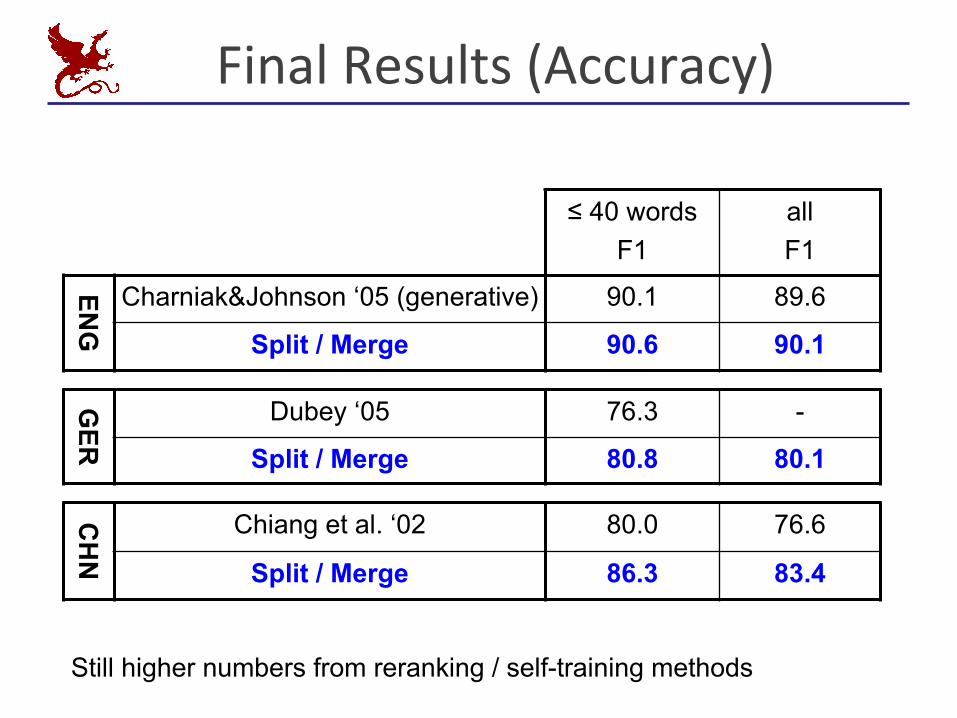
FinalResults(Accuracy)
≤ 40 wordsF1
all F1
ENG
Charniak&Johnson ‘05 (generative) 90.1 89.6
Split / Merge 90.6 90.1
GER
Dubey ‘05 76.3 -
Split / Merge 80.8 80.1
CH
N
Chiang et al. ‘02 80.0 76.6
Split / Merge 86.3 83.4
Still higher numbers from reranking / self-training methods

EfficientParsingforHierarchicalGrammars

Coarse-to-FineInference§ Example:PPattachment
?????????
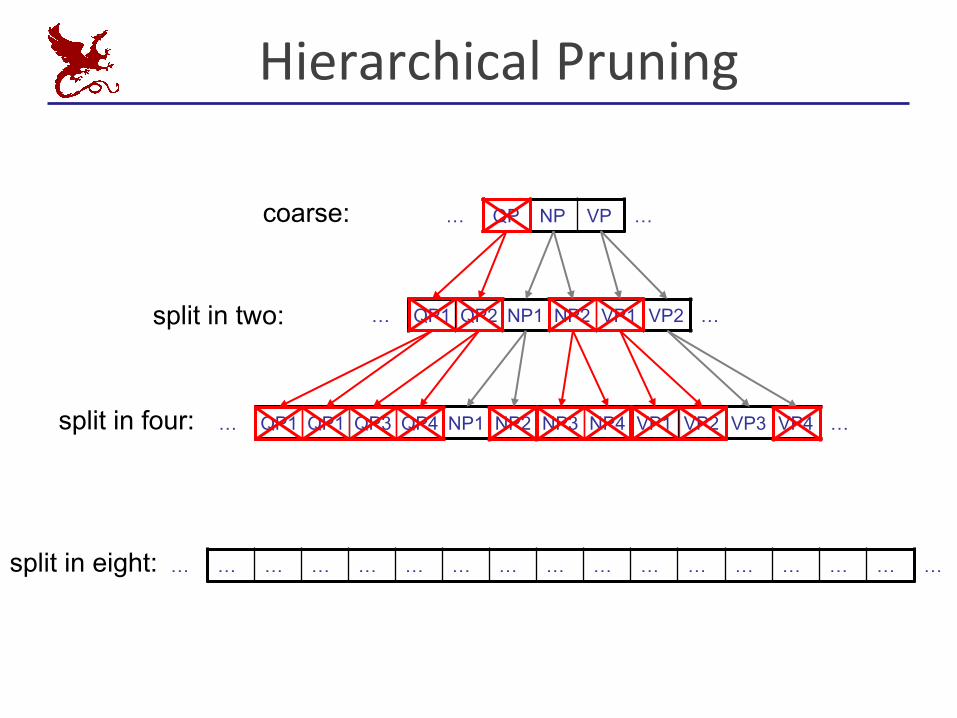
HierarchicalPruning
… QP NP VP …coarse:
split in two: … QP1 QP2 NP1 NP2 VP1 VP2 …
… QP1 QP1 QP3 QP4 NP1 NP2 NP3 NP4 VP1 VP2 VP3 VP4 …split in four:
split in eight: … … … … … … … … … … … … … … … … …
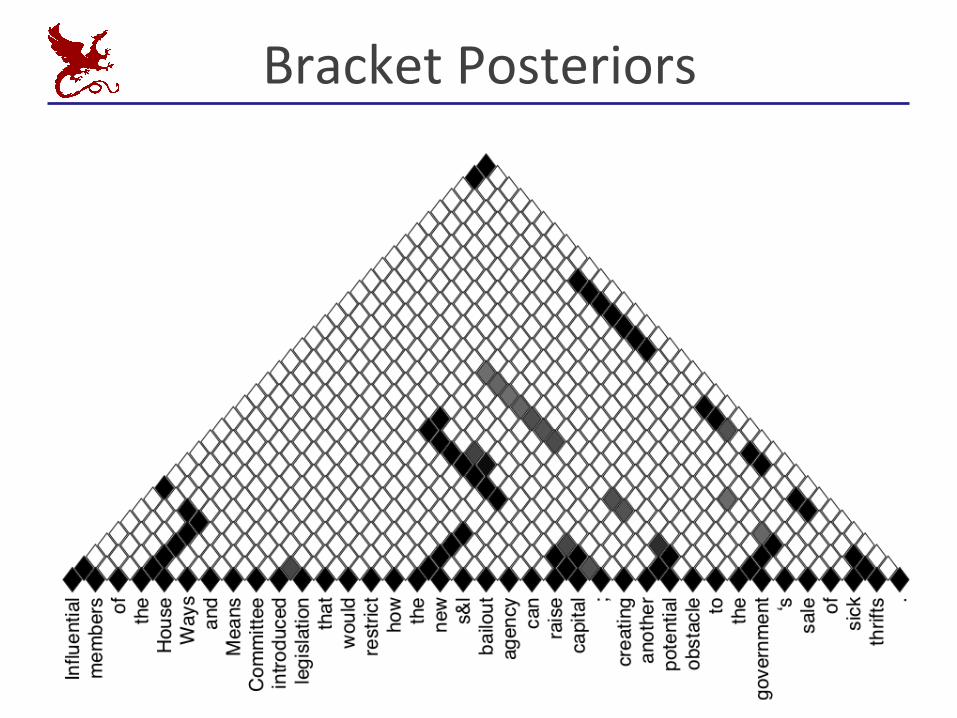
BracketPosteriors

1621min111min35min
15min(nosearcherror)

OtherSyntacticModels
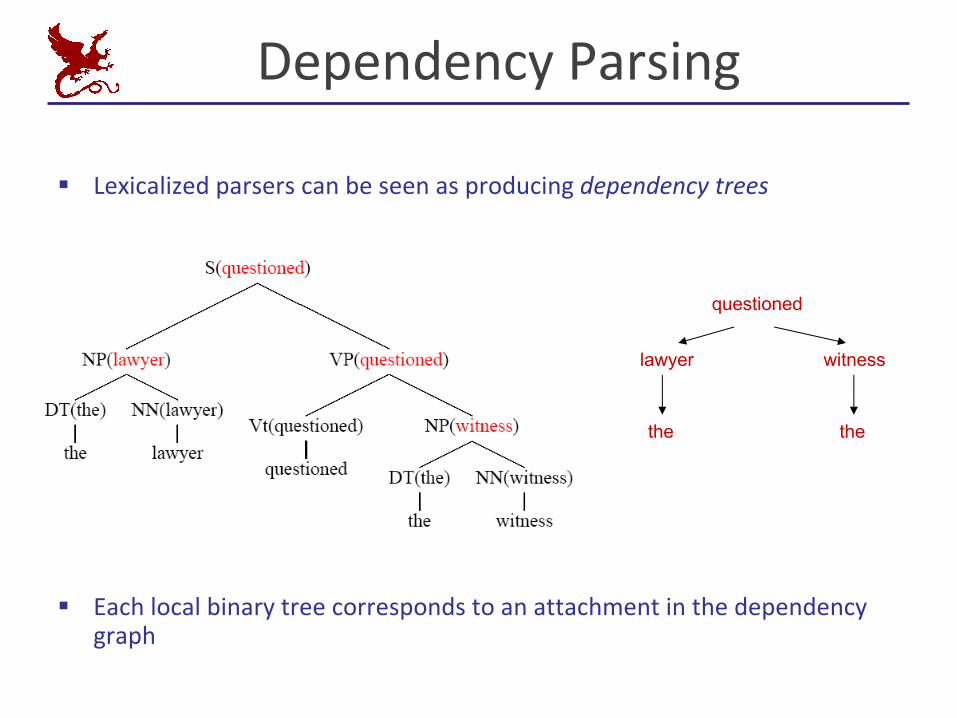
DependencyParsing
§ Lexicalizedparserscanbeseenasproducingdependencytrees
§ Eachlocalbinarytreecorrespondstoanattachmentinthedependencygraph
questioned
lawyer witness
the the

DependencyParsing
§ Puredependencyparsingisonlycubic[Eisner99]
§ Someworkonnon-projective dependencies§ Commonin,e.g.Czechparsing§ CandowithMSTalgorithms[McDonaldandPereira05]
Y[h] Z[h’]
X[h]
i h k h’ j
h h’
h
h k h’

Shift-ReduceParsers
§ Anotherwaytoderiveatree:
§ Parsing§ Nousefuldynamicprogrammingsearch§ Canstillusebeamsearch[Ratnaparkhi97]
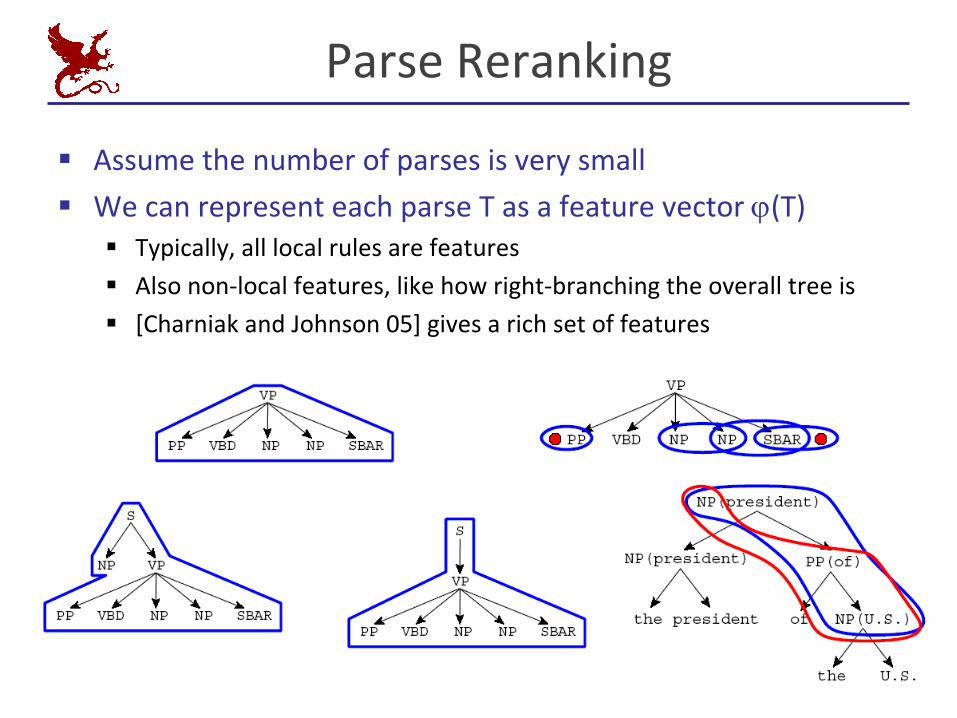
ParseReranking
§ Assumethenumberofparsesisverysmall§ WecanrepresenteachparseTasafeaturevectorj(T)
§ Typically,alllocalrulesarefeatures§ Alsonon-localfeatures,likehowright-branchingtheoveralltreeis§ [Charniak andJohnson05]givesarichsetoffeatures

Classification

Classification§ Automaticallymakeadecisionaboutinputs
§ Example:document® category§ Example:imageofdigit® digit§ Example:imageofobject® objecttype§ Example:query+webpages® bestmatch§ Example:symptoms® diagnosis§ …
§ Threemainideas§ Representationasfeaturevectors§ Scoringbylinearfunctions(ornot,actually)§ Learningbyoptimization

SomeDefinitions
INPUTS
CANDIDATES
FEATURE VECTORS
closethe____
CANDIDATE SET
yoccursinx
“close”inx Ù y=“door”x-1=“the”Ù y=“door”
TRUE OUTPUTS
{door,table,…}
table
door
x-1=“the”Ù y=“table”

Features

FeatureVectors
§ Example:webpageranking(notactuallyclassification)
xi = “Apple Computers”

BlockFeatureVectors
§ Sometimes,wethinkoftheinputashavingfeatures,whicharemultipliedbyoutputstoformthecandidates
… win the election …
“win” “election”
… win the election …
… win the election …
… win the election …

Non-BlockFeatureVectors§ Sometimesthefeaturesofcandidatescannotbe
decomposedinthisregularway§ Example:aparsetree’sfeaturesmaybetheproductions
presentinthetree
§ Differentcandidateswillthusoftensharefeatures§ We’llreturntothenon-blockcaselater
SNP VP
VN N
SNP VP
N V N
SNP VP
NP
N N
VP
V
NP
N
VP
V N

LinearModels

LinearModels:Scoring§ Inalinearmodel,eachfeaturegetsaweightw
§ Wescorehypothesesbymultiplyingfeaturesandweights:
… win the election …
… win the election …
… win the election …
… win the election …

LinearModels:DecisionRule
§ Thelineardecisionrule:
§ We’vesaidnothingaboutwhereweightscomefrom
… win the election …
… win the election …
… win the election …
… win the election …
… win the election …
… win the election …

BinaryClassification
§ Importantspecialcase:binaryclassification§ Classesarey=+1/-1
§ Decisionboundaryisahyperplane
BIAS : -3free : 4money : 2
0 10
1
2
freem
oney
+1 = SPAM
-1 = HAM

MulticlassDecisionRule
§ Ifmorethantwoclasses:§ Highestscorewins§ Boundariesaremorecomplex
§ Hardertovisualize

Learning

LearningClassifierWeights
§ Twobroadapproachestolearningweights
§ Generative:workwithaprobabilisticmodelofthedata,weightsare(log)localconditionalprobabilities§ Advantages:learningweightsiseasy,smoothingiswell-understood,
backedbyunderstandingofmodeling
§ Discriminative:setweightsbasedonsomeerror-relatedcriterion§ Advantages:error-driven,oftenweightswhicharegoodfor
classificationaren’ttheoneswhichbestdescribethedata
§ We’llmainlytalkaboutthelatterfornow

Howtopickweights?
§ Goal:choose“best”vectorwgiventrainingdata§ Fornow,wemean“bestforclassification”
§ Theideal:theweightswhichhavegreatesttestsetaccuracy/F1/whatever§ But,don’thavethetestset§ Mustcomputeweightsfromtrainingset
§ Maybewewantweightswhichgivebesttrainingsetaccuracy?§ Harddiscontinuousoptimizationproblem§ Maynot(doesnot)generalizetotestset§ Easytooverfit
Though, min-error training for MT does exactly this.

MinimizeTrainingError?§ Alossfunctiondeclareshowcostlyeachmistakeis
§ E.g.0lossforcorrectlabel,1lossforwronglabel§ Canweightmistakesdifferently(e.g.falsepositivesworsethanfalse
negativesorHammingdistanceoverstructuredlabels)
§ Wecould,inprinciple,minimizetrainingloss:
§ Thisisahard,discontinuousoptimizationproblem

LinearModels:Perceptron
§ Theperceptronalgorithm§ Iterativelyprocessesthetrainingset,reactingtotrainingerrors§ Canbethoughtofastryingtodrivedowntrainingerror
§ The(online)perceptronalgorithm:§ Startwithzeroweightsw§ Visittraininginstancesonebyone
§ Trytoclassify
§ Ifcorrect,nochange!§ Ifwrong:adjustweights

Example:“Best”WebPage
xi = “Apple Computers”
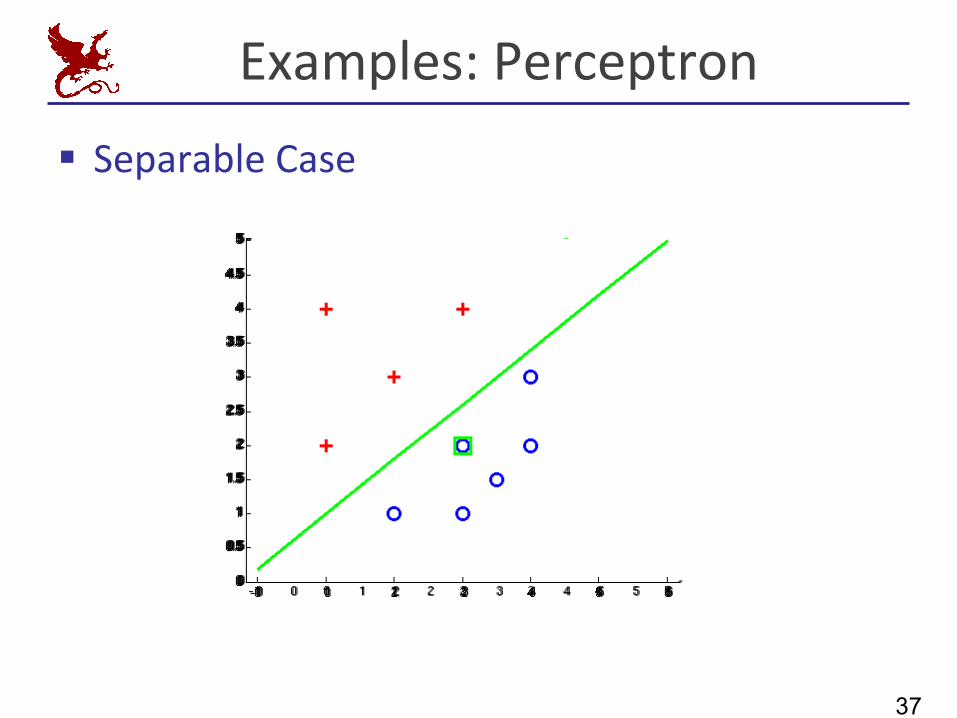
Examples:Perceptron
§ SeparableCase
37
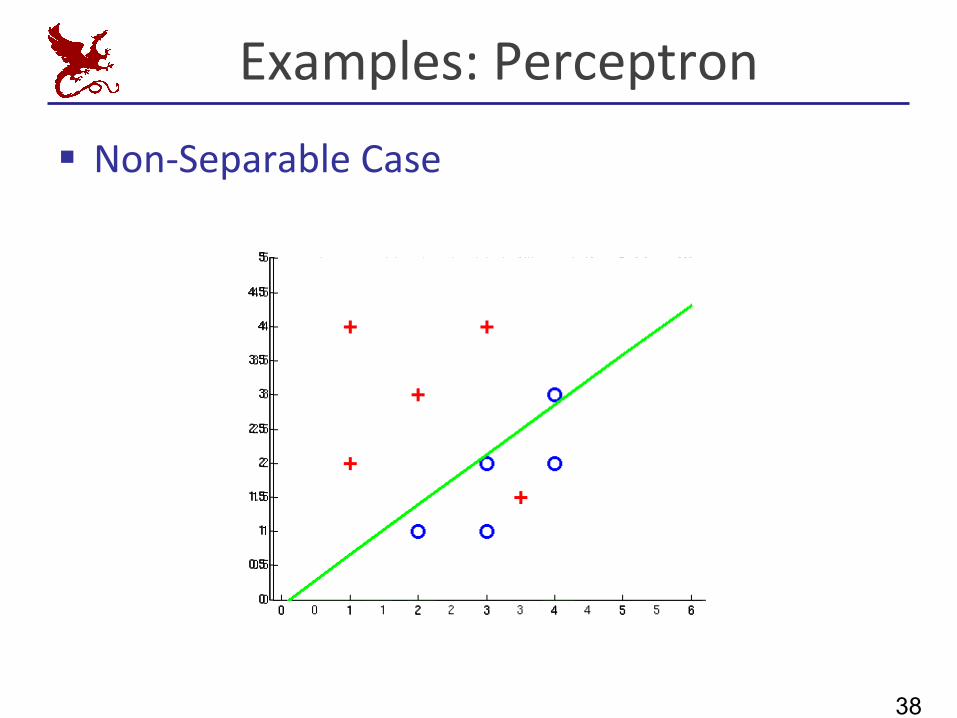
Examples:Perceptron
§ Non-SeparableCase
38

Margin

ObjectiveFunctions
§ Whatdowewantfromourweights?§ Depends!§ Sofar:minimize(training)errors:
§ Thisisthe“zero-oneloss”§ Discontinuous,minimizingisNP-complete
§ MaximumentropyandSVMshaveotherobjectivesrelatedtozero-oneloss

LinearSeparators
§ Whichoftheselinearseparatorsisoptimal?
41

ClassificationMargin(Binary)
§ Distanceofxi toseparatorisitsmargin,mi§ Examplesclosesttothehyperplanearesupportvectors§ Margin g oftheseparatoristheminimumm
m
g

ClassificationMargin
§ Foreachexamplexi andpossiblemistakencandidatey,weavoidthatmistakebyamarginmi(y) (withzero-oneloss)
§ Marging oftheentireseparatoristheminimumm
§ Itisalsothelargestg forwhichthefollowingconstraintshold

§ SeparableSVMs:findthemax-marginw
§ CanstickthisintoMatlab and(slowly)getanSVM§ Won’twork(well)ifnon-separable
MaximumMargin

WhyMaxMargin?
§ Whydothis?Variousarguments:§ Solutiondependsonlyontheboundarycases,orsupportvectors (but
rememberhowthisdiagramisbroken!)§ Solutionrobusttomovementofsupportvectors§ Sparsesolutions(featuresnotinsupportvectorsgetzeroweight)§ Generalizationboundarguments§ Workswellinpracticeformanyproblems
Support vectors

MaxMargin/SmallNorm
§ Reformulation:findthesmallestwwhichseparatesdata
§ g scaleslinearlyinw,soif||w||isn’tconstrained,wecantakeanyseparatingwandscaleupourmargin
§ Insteadoffixingthescaleofw,wecanfixg =1
Remember this condition?

Gammatow

SoftMarginClassification§ Whatifthetrainingsetisnotlinearlyseparable?§ Slackvariables ξi canbeaddedtoallowmisclassificationofdifficultor
noisyexamples,resultinginasoftmargin classifier
ξi
ξi
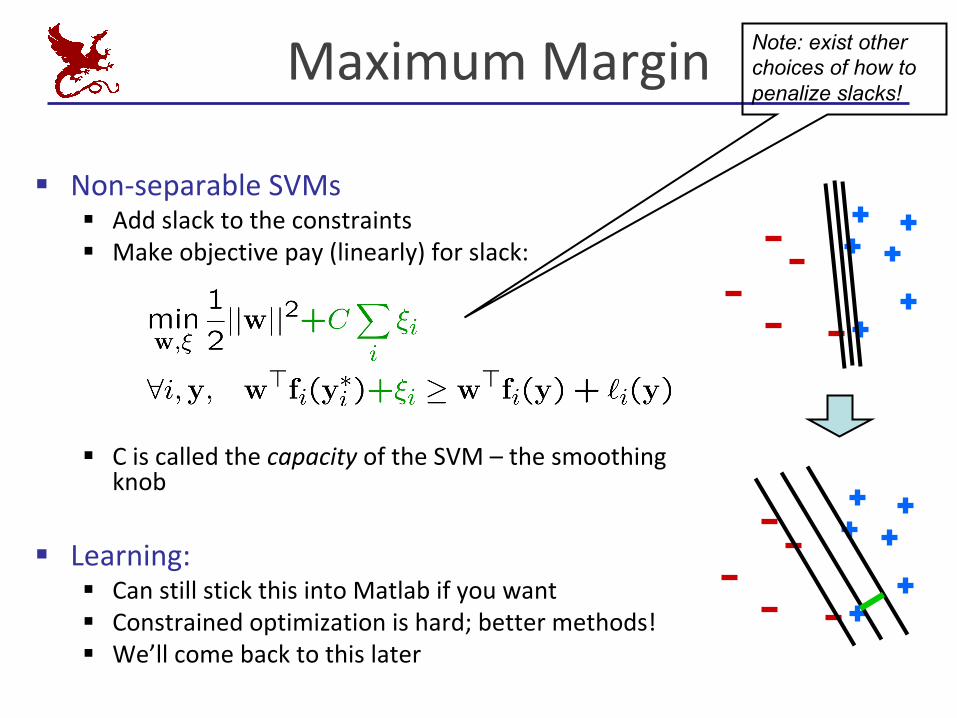
MaximumMargin
§ Non-separableSVMs§ Addslacktotheconstraints§ Makeobjectivepay(linearly)forslack:
§ Ciscalledthecapacity oftheSVM– thesmoothingknob
§ Learning:§ CanstillstickthisintoMatlabifyouwant§ Constrainedoptimizationishard;bettermethods!§ We’llcomebacktothislater
Note: exist other choices of how to penalize slacks!

MaximumMargin

Likelihood

LinearModels:MaximumEntropy
§ Maximumentropy(logisticregression)§ Usethescoresasprobabilities:
§ Maximizethe(log)conditionallikelihoodoftrainingdata
Make positiveNormalize

MaximumEntropyII
§ Motivationformaximumentropy:§ Connectiontomaximumentropyprinciple(sortof)§ Mightwanttodoagoodjobofbeinguncertainonnoisycases…
§ …inpractice,though,posteriorsareprettypeaked
§ Regularization(smoothing)

MaximumEntropy
LossComparison

Log-Loss§ Ifweviewmaxentasaminimizationproblem:
§ Thisminimizesthe“logloss”oneachexample
§ Oneview:loglossisanupperbound onzero-oneloss

RememberSVMs…
§ Wehadaconstrained minimization
§ …butwecansolveforxi
§ Giving

HingeLoss
§ Thisiscalledthe“hingeloss”§ Unlikemaxent /logloss,youstop
gainingobjectiveoncethetruelabelwinsbyenough
§ YoucanstartfromhereandderivetheSVMobjective
§ Cansolvedirectlywithsub-gradientdecent(e.g.Pegasos:Shalev-Shwartz etal07)
§ Consider the per-instance objective:
Plot really only right in binary case

Maxvs“Soft-Max”Margin
§ SVMs:
§ Maxent:
§ Verysimilar!Bothtrytomakethetruescorebetterthanafunctionoftheotherscores§ TheSVMtriestobeattheaugmentedrunner-up§ TheMaxentclassifiertriestobeatthe“soft-max”
You can make this zero
… but not this one

LossFunctions:Comparison
§ Zero-OneLoss
§ Hinge
§ Log
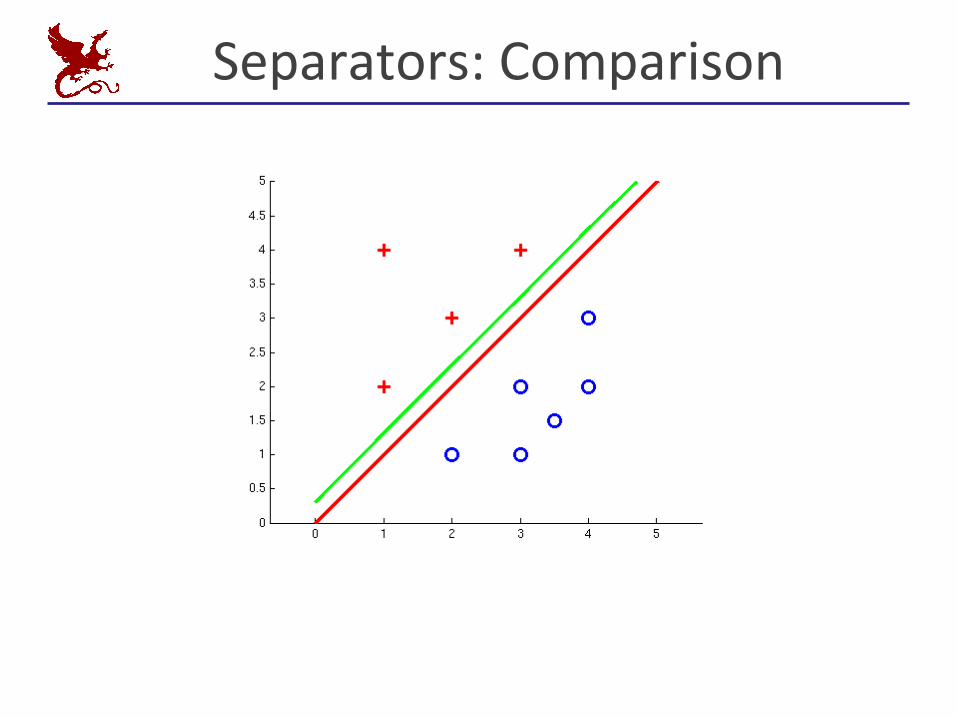
Separators:Comparison

Structure
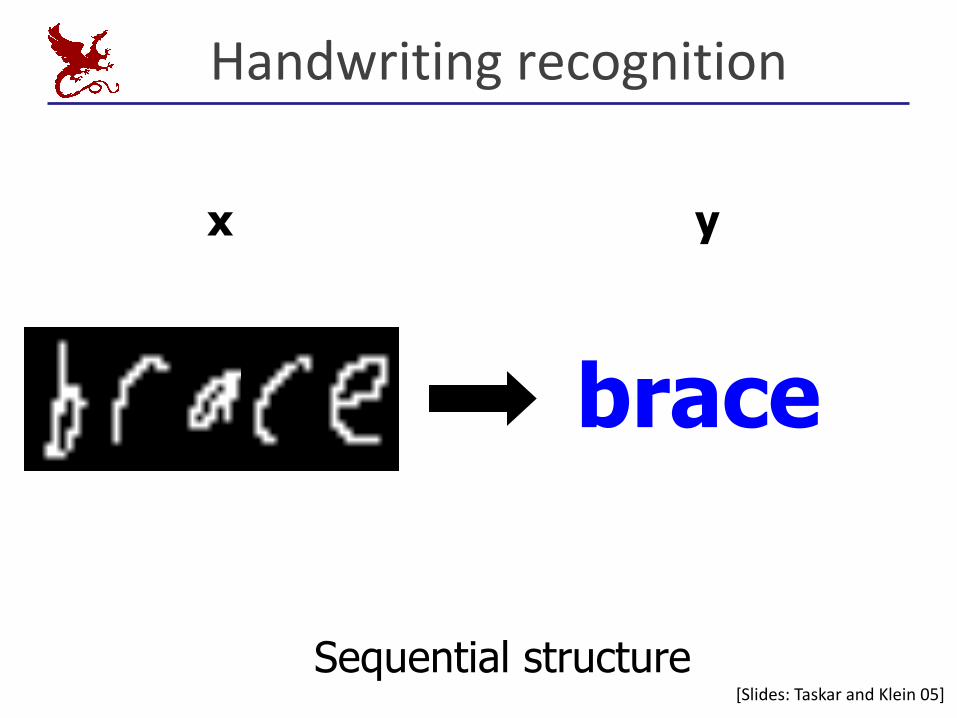
Handwritingrecognition
brace
Sequential structure
x y
[Slides:Taskar andKlein05]

CFGParsing
The screen was a sea of red
Recursive structure
x y
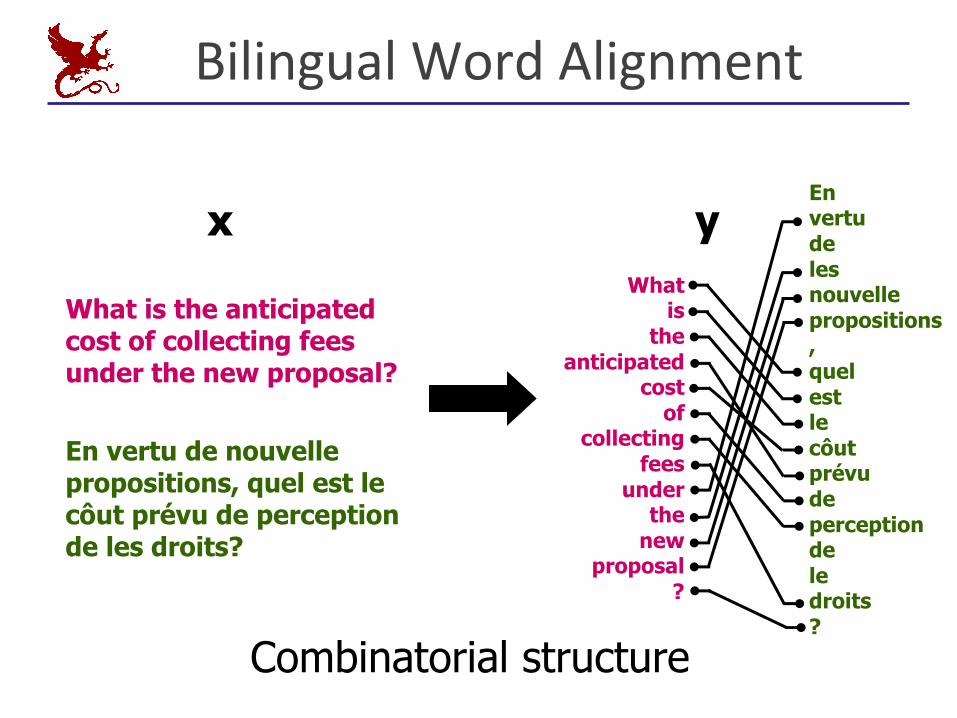
BilingualWordAlignment
What is the anticipated cost of collecting fees under the new proposal?
En vertu de nouvelle propositions, quel est le côut prévu de perception de les droits?
x yWhat
is the
anticipatedcost
ofcollecting
fees under
the new
proposal?
En vertu delesnouvelle propositions, quel est le côut prévu de perception de le droits?
Combinatorial structure

StructuredModels
Assumption:
Scoreisasumoflocal“part”scores
Parts=nodes,edges,productions
space of feasible outputs
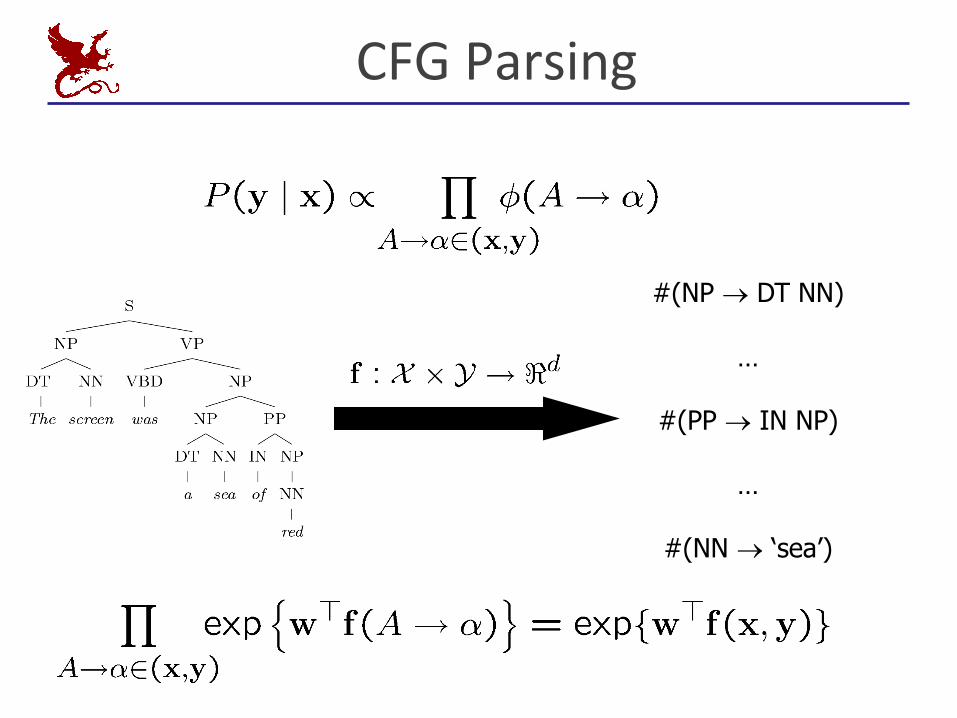
CFGParsing
#(NP ® DT NN)
…
#(PP ® IN NP)
…
#(NN ® ‘sea’)

Bilingualwordalignment
§ association§ position§ orthography
Whatis
theanticipated
costof
collecting fees
under the
new proposal
?
En vertu delesnouvelle propositions, quel est le côut prévu de perception de le droits?
j
k

EfficientDecoding§ Commoncase:youhaveablackboxwhichcomputes
atleastapproximately,andyouwanttolearnw
§ Easiestoptionisthestructuredperceptron[Collins01]§ Structureentershereinthatthesearchforthebestyistypicallya
combinatorialalgorithm(dynamicprogramming,matchings,ILPs,A*…)§ Predictionisstructured,learningupdateisnot

StructuredMargin(Primal)
Rememberourprimalmarginobjective?
minw
1
2kwk22 + C
X
i
✓max
y
�w>fi(y) + `i(y)
�� w>fi(y
⇤i )
◆
Stillapplieswithstructuredoutputspace!

StructuredMargin(Primal)
minw
1
2kwk22 + C
X
i
�w>fi(y) + `i(y)� w>fi(y
⇤i )�
y = argmaxy�w>fi(y) + `i(y)
�Justneedefficientloss-augmenteddecode:
rw = w + CX
i
(fi(y)� fi(y⇤i ))
Stillusegeneralsubgradient descentmethods!(Adagrad)

StructuredMargin(Dual)§ Remembertheconstrainedversionofprimal:
§ Dualhasavariableforeveryconstrainthere

§ Wewant:
§ Equivalently:
FullMargin:OCR
a lot!…
“brace”
“brace”
“aaaaa”
“brace” “aaaab”
“brace” “zzzzz”

§ Wewant:
§ Equivalently:
‘It was red’
Parsingexample
a lot!
SA B
C D
SA BD F
SA B
C D
SE F
G H
SA B
C D
SA B
C D
SA B
C D
…
‘It was red’
‘It was red’
‘It was red’
‘It was red’
‘It was red’
‘It was red’

§ Wewant:
§ Equivalently:
‘What is the’‘Quel est le’
Alignmentexample
a lot!…
123
123
‘What is the’‘Quel est le’
123
123
‘What is the’‘Quel est le’
123
123
‘What is the’‘Quel est le’
123
123
123
123
123
123
123
123
‘What is the’‘Quel est le’
‘What is the’‘Quel est le’
‘What is the’‘Quel est le’

CuttingPlane(Dual)§ Aconstraintinductionmethod[Joachimsetal09]
§ Exploitsthatthenumberofconstraintsyouactuallyneedperinstanceistypicallyverysmall
§ Requires(loss-augmented)primal-decodeonly
§ Repeat:§ Findthemostviolatedconstraintforaninstance:
§ Addthisconstraintandresolvethe(non-structured)QP(e.g.withSMOorotherQPsolver)

CuttingPlane(Dual)§ Someissues:
§ CaneasilyspendtoomuchtimesolvingQPs§ Doesn’texploitsharedconstraintstructure§ Inpractice,worksprettywell;fastlikeperceptron/MIRA,morestable,noaveraging

Likelihood,Structured
§ Structureneededtocompute:§ Log-normalizer§ Expectedfeaturecounts
§ E.g.ifafeatureisanindicatorofDT-NNthenweneedtocomputeposteriormarginalsP(DT-NN|sentence)foreachpositionandsum
§ Alsoworkswithlatentvariables(morelater)
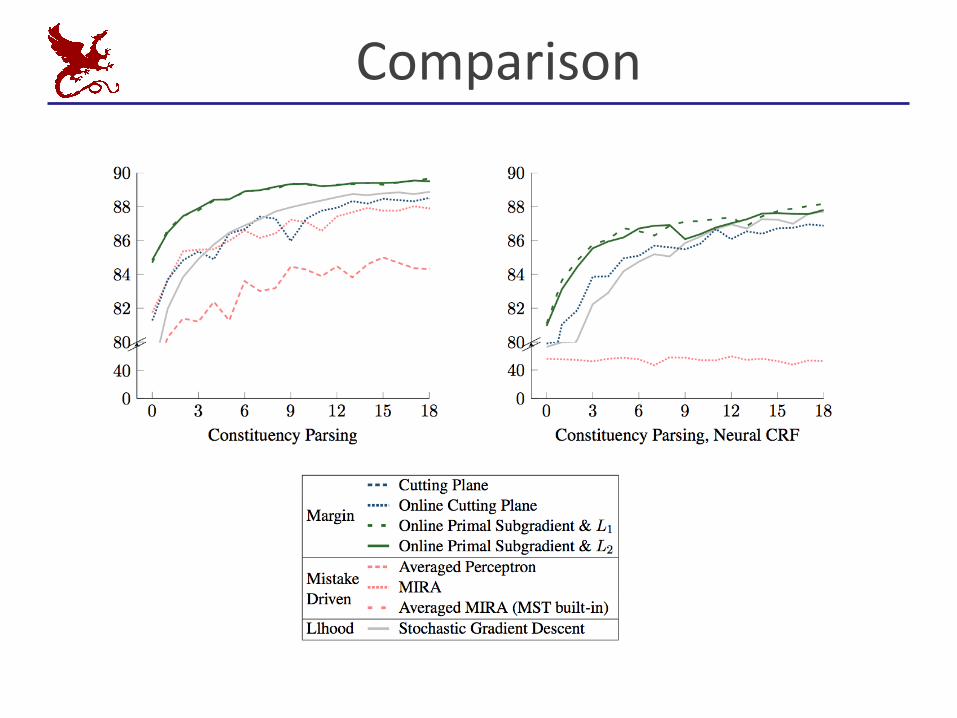
Comparison
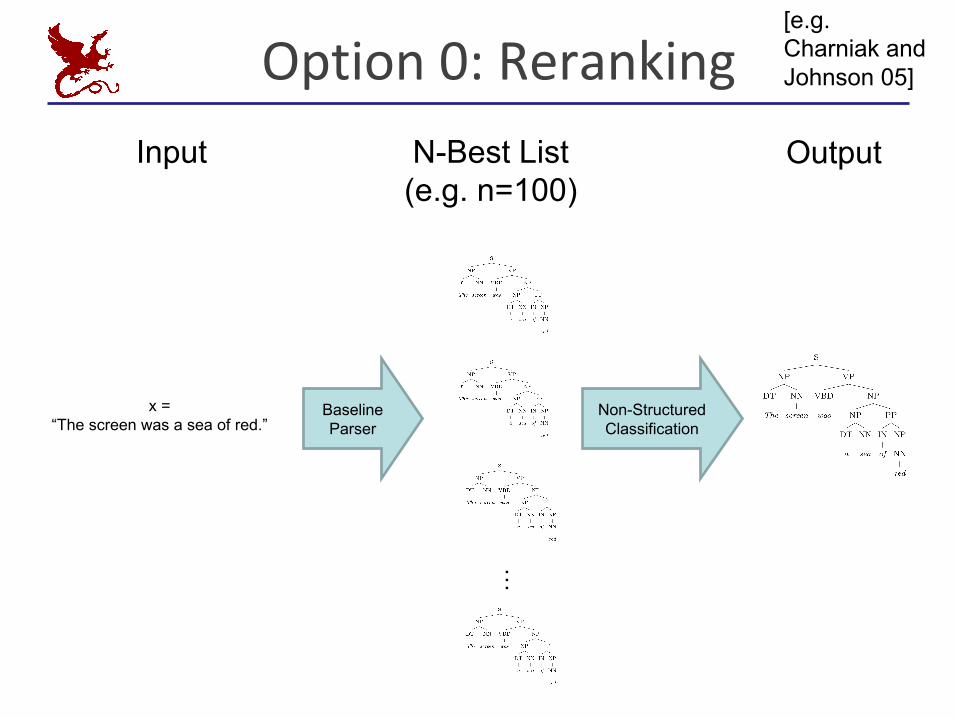
Option0:Reranking
x = “The screen was a sea of red.”
…Baseline Parser
Input N-Best List(e.g. n=100)
Non-Structured Classification
Output
[e.g. Charniak and Johnson 05]

Reranking§ Advantages:
§ Directlyreducetonon-structuredcase§ Nolocalityrestrictiononfeatures
§ Disadvantages:§ Stuckwitherrorsofbaselineparser§ Baselinesystemmustproducen-bestlists§ But,feedbackispossible[McCloskey,Charniak,Johnson2006]

M3Ns§ Anotheroption:expressallconstraintsinapackedform
§ MaximummarginMarkovnetworks[Taskar etal03]§ Integratessolutionstructuredeeplyintotheproblemstructure
§ Steps§ ExpressinferenceoverconstraintsasanLP§ Usedualitytotransformminimax formulationintomin-min§ Constraintsfactorinthedualalongthesamestructureastheprimal;
alphasessentiallyactasadual“distribution”§ Variousoptimizationpossibilitiesinthedual

Example:Kernels
§ Quadratickernels
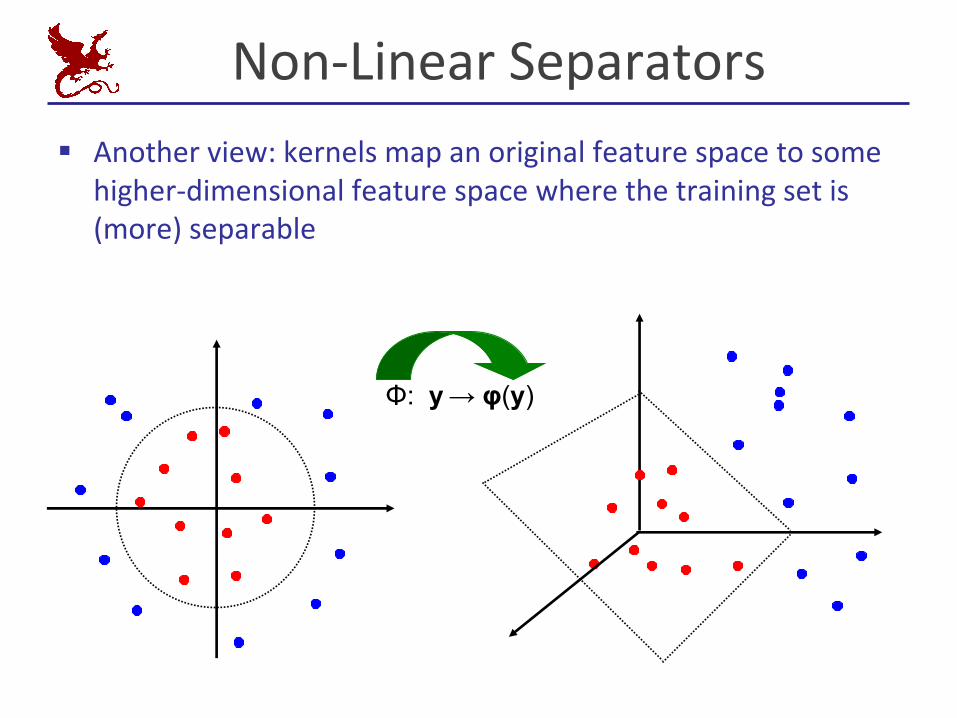
Non-LinearSeparators§ Anotherview:kernelsmapanoriginalfeaturespacetosome
higher-dimensionalfeaturespacewherethetrainingsetis(more)separable
Φ: y → φ(y)

WhyKernels?§ Can’tyoujustaddthesefeaturesonyourown(e.g.addall
pairsoffeaturesinsteadofusingthequadratickernel)?§ Yes,inprinciple,justcomputethem§ Noneedtomodifyanyalgorithms§ But,numberoffeaturescangetlarge(orinfinite)§ Somekernelsnotasusefullythoughtofintheirexpanded
representation,e.g.RBFordata-definedkernels[HendersonandTitov05]
§ Kernelsletuscomputewiththesefeaturesimplicitly§ Example:implicitdotproductinquadratickerneltakesmuchless
spaceandtimeperdotproduct§ Ofcourse,there’sthecostforusingthepuredualalgorithms…