alfred -
TRANSCRIPT

A Framework for Learning Web Wrappers from the Crowd
Valter Crescenzi, Paolo Merialdo, Disheng Qiu
Dipartimento di IngegneriaUniversità degli Studi Roma TreVia della Vasca Navale, 79, Rome

Extracting data
2M pages from IMDB, and we want to extract ... titles, directors etc ....
1/15

Extracting data
2M pages from IMDB, and we want to extract ... titles, directors etc ....
DB#Wrapper!
1/15

Extracting data
2M pages from IMDB, and we want to extract ... titles, directors etc ....
Inference algorithm!
DB#Wrapper!
1/15

Supervised
Supervised hard to scale
Inference algorithm!
DB#Wrapper!
1/15

Unsupervised
Unsupervised easier to scale but not accurate
Inference algorithm!
DB#Wrapper!
1/15

Automatic Annotator
Automatic annotators can not be applied in all cases
Inference algorithm!
DB#Wrapper!
+"
1/15
• Sample values• Ontology• Lexical patterns

Crowdsourcing
An opportunity to scale supervised approaches
Inference algorithm!
DB#Wrapper!
1/15

Scaling Wrapper Inference
Scaling the number of workers with Crowdsourcing platforms opens new challenges:
Issues: Contributions:
2/15

Scaling Wrapper Inference
Scaling the number of workers with Crowdsourcing platforms opens new challenges:
Issues: Contributions:
Non-expert workers
• Simple interactions to reduce the worker error rate• Membership Query (yes/no answer)
2/15

Scaling Wrapper Inference
Scaling the number of workers with Crowdsourcing platforms opens new challenges:
Issues: Contributions:
Non-expert workers
• Simple interactions to reduce the worker error rate• Membership Query (yes/no answer)
• Active Learning to carefully select queries• Dynamic Expressiveness of the inference language
Costs
2/15
Scaling Wrapper Inference
Scaling the number of workers with Crowdsourcing platforms opens new challenges:
Issues: Contributions:
Non-expert workers
• Simple interactions to reduce the worker error rate• Membership Query (yes/no answer)
• Active Learning to carefully select queries• Dynamic Expressiveness of the inference language
Costs
2/15
Quality
• Bayesian Model to evaluate the expected wrapper quality• Sampling algorithms

ALFRED
ALFRED is a wrapper inference system supervised by workers from a crowdsourcing platform.
Input annotated page (page0):
3/15

ALFRED
ALFRED is a wrapper inference system supervised by workers from a crowdsourcing platform.
r1 = /html/table/tr[1]/td/text()r2 = //*[contains(.,”Ratings:”)]/../../tr[1]/td/text()r3 = //*[contains(.,”Director:”)]/../../tr[1]/td/text()....
Inference algorithm!
Input annotated page (page0):
3/15

ALFRED
ALFRED is a wrapper inference system supervised by workers from a crowdsourcing platform.
r1 = /html/table/tr[1]/td/text()r2 = //*[contains(.,”Ratings:”)]/../../tr[1]/td/text()r3 = //*[contains(.,”Director:”)]/../../tr[1]/td/text()....
Inference algorithm!
page0
r1
r2
r3
Spirited Away
Spirited Away
Spirited Away
Input annotated page (page0):
3/15

ALFRED
ALFRED is a wrapper inference system supervised by workers from a crowdsourcing platform.
r1 = /html/table/tr[1]/td/text()r2 = //*[contains(.,”Ratings:”)]/../../tr[1]/td/text()r3 = //*[contains(.,”Director:”)]/../../tr[1]/td/text()....
Inference algorithm!
page0 page1 page2
r1
r2
r3
Spirited Away City of God Howl’s Moving Castle
Spirited Away - 9.3
Spirited Away City of God null
Input annotated page (page0):
3/15

ALFRED
ALFRED is a wrapper inference system supervised by workers from a crowdsourcing platform.
r1 = /html/table/tr[1]/td/text()r2 = //*[contains(.,”Ratings:”)]/../../tr[1]/td/text()r3 = //*[contains(.,”Director:”)]/../../tr[1]/td/text()....
Inference algorithm!
Input annotated page (page0):
Is this title the correct one?
3/15

ALFRED
ALFRED is a wrapper inference system supervised by workers from a crowdsourcing platform.
r1 = /html/table/tr[1]/td/text()r2 = //*[contains(.,”Ratings:”)]/../../tr[1]/td/text()r3 = //*[contains(.,”Director:”)]/../../tr[1]/td/text()....
Inference algorithm!
DB#Wrapper!
r1 = /html/table/tr[1]/td/text()
Input annotated page (page0):
Is this title the correct one?
3/15

Membership Query
page0 page1 page2
r1
r2
r3
Spirited Away City of God Howl’s Moving Castle
Spirited Away - 9.3
Spirited Away City of God null
4/15
Yes !

Membership Query
page0 page1 page2
r1
r2
r3
Spirited Away City of God Howl’s Moving Castle
Spirited Away - 9.3
Spirited Away City of God null
• Rules compatible with the answer more likely to be correct (Bayesian Model)
For each new answer
4/15
Yes !

Membership Query
page0 page1 page2
r1
r2
r3
Spirited Away City of God Howl’s Moving Castle
Spirited Away - 9.3
Spirited Away City of God null
• Rules compatible with the answer more likely to be correct (Bayesian Model)
For each new answer
• If no rule is good enough:• a new query is selected (Active Learning)
4/15
Yes !
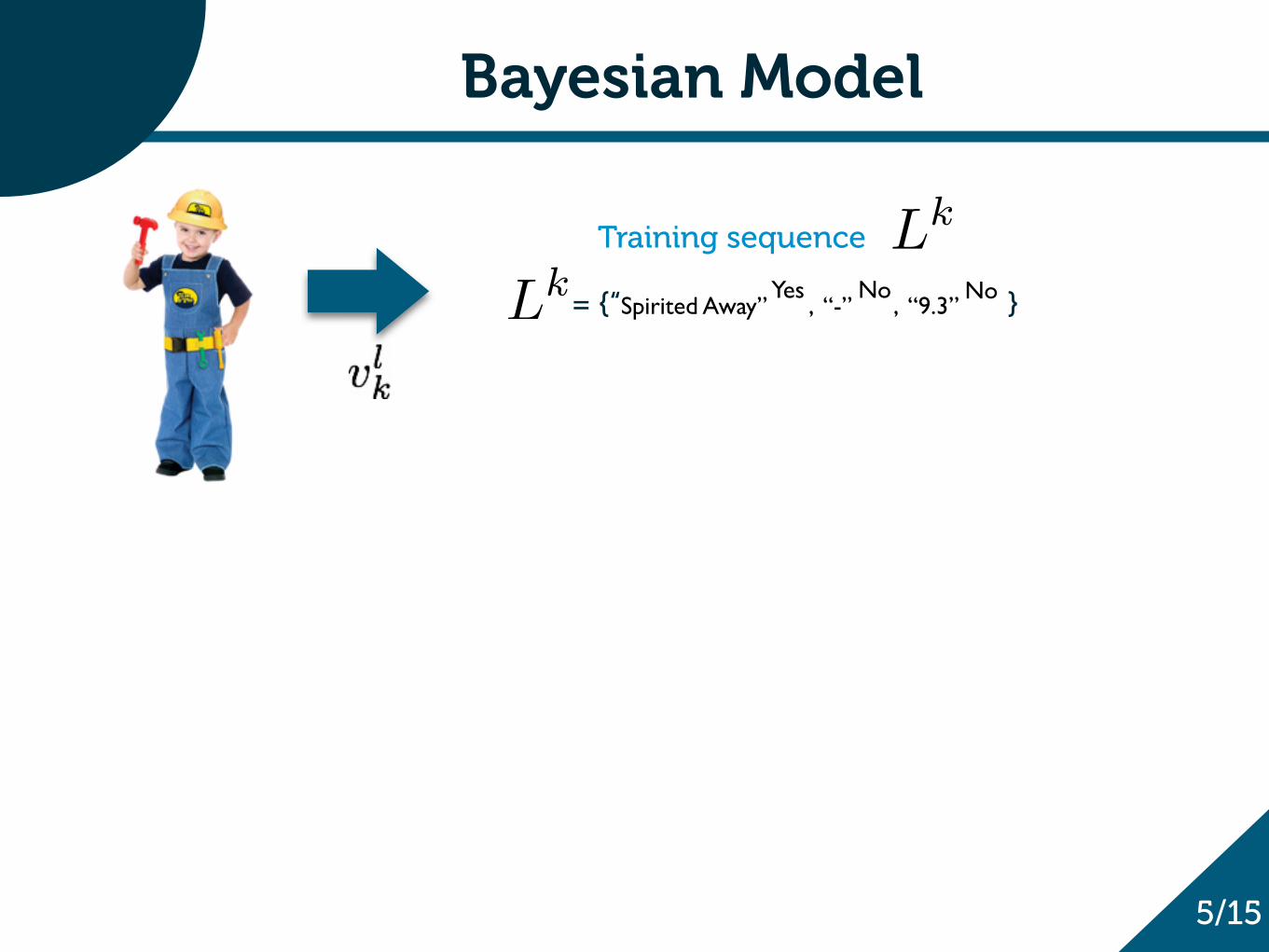
Bayesian Model
Training sequence
= {“Spirited Away” , “-” , “9.3” }Yes No No
5/15
LkLk

Bayesian Model
Training sequence
= {“Spirited Away” , “-” , “9.3” }Yes No No
5/15
LkLk
a rule r is correct:
none of the candidate rules is correct:
Probability that:
P (r|Lk)
P (R|Lk)

Bayesian update:
Bayesian Model
Training sequence
= {“Spirited Away” , “-” , “9.3” }Yes No No
5/15
LkLk
a rule r is correct:
none of the candidate rules is correct:
Probability that:
P (r|Lk)
P (R|Lk)

Bayesian update:
Bayesian Model
Training sequence
= {“Spirited Away” , “-” , “9.3” }Yes No No
5/15
LkLk
a rule r is correct:
none of the candidate rules is correct:
Probability that:
P (r|Lk)
P (R|Lk)

Active Learning
page0 page1 page2
r1
r2
r3
Spirited Away City of God Howl’s Moving Castle
Spirited Away - 9.3
Spirited Away City of God null
ALFRED actively selects the queries; a good policy saves money
6/15

Active Learning
• Random (baseline)Values are randomly selected
• EntropyValues are selected by maximizing the Entropy (most uncertain value)
• GreedyValues are selected by minimizing the queries to confirm the most likely rule
• LuckyHybrid approach, it starts with an Entropy algorithm and then switch to Greedy to confirm the best rule
page0 page1 page2
r1
r2
r3
Spirited Away City of God Howl’s Moving Castle
Spirited Away - 9.3
Spirited Away City of God null
ALFRED actively selects the queries; a good policy saves money
6/15

Expressiveness
The candidate rules are generated observing the first annotated page
Should we use all the XPath expressiveness or just a fragment?
7/15
Expressiveness of the fragment Number of candidate rules

Expressiveness
Pool of candidate rules organized in fragments:
The candidate rules are generated observing the first annotated page
Should we use all the XPath expressiveness or just a fragment?
7/15
Expressiveness of the fragment Number of candidate rules

Expressiveness
Pool of candidate rules organized in fragments:
/html/table/tr[1]/td/text() Absolute Rules (complete path from root)
The candidate rules are generated observing the first annotated page
Should we use all the XPath expressiveness or just a fragment?
7/15
Expressiveness of the fragment Number of candidate rules

Expressiveness
Pool of candidate rules organized in fragments:
/html/table/tr[1]/td/text() Absolute Rules (complete path from root)
//*[contains(.,”Spirited Away”)]/text()//*[contains(.,”Ratings:”)]/../../tr[1]/td/text()//*[contains(.,”Director:”)]/../../tr[1]/td/text()
Relative Rules (path from a textual node)
The candidate rules are generated observing the first annotated page
Should we use all the XPath expressiveness or just a fragment?
7/15
Expressiveness of the fragment Number of candidate rules

Expressiveness
Pool of candidate rules organized in fragments:
/html/table/tr[1]/td/text() Absolute Rules (complete path from root)
//*[contains(.,”Spirited Away”)]/text()//*[contains(.,”Ratings:”)]/../../tr[1]/td/text()//*[contains(.,”Director:”)]/../../tr[1]/td/text()
Relative Rules (path from a textual node)
The candidate rules are generated observing the first annotated page
.... other XPaths
Should we use all the XPath expressiveness or just a fragment?
7/15
Expressiveness of the fragment Number of candidate rules

Expressiveness
/html/table/tr[1]/td/text()//*[contains(.,”Spirited Away”)]/text()//*[contains(.,”Ratings:”)]/../../tr[1]/td/text()//*[contains(.,”Director:”)]/../../tr[1]/td/text()
Correct (absolute) rule:/html/table/tr[1]/td/text()
• The fragment is too expressive: the correct rule can be generated • But many MQ are needed to find it
8/15

Expressiveness
• The fragment is just expressive enough: the correct rule can be generated. • Few queries are needed to find it
/html/table/tr[1]/td/text()
/html/table/tr[1]/td/text()//*[contains(.,”Spirited Away”)]/text()//*[contains(.,”Ratings:”)]/../../tr[1]/td/text()//*[contains(.,”Director:”)]/../../tr[1]/td/text()
Correct (absolute) rule:/html/table/tr[1]/td/text()
• The fragment is too expressive: the correct rule can be generated • But many MQ are needed to find it
8/15

Expressiveness
• The fragment is just expressive enough: the correct rule can be generated. • Few queries are needed to find it
/html/table/tr[1]/td/text()
/html/table/tr[1]/td/text()//*[contains(.,”Spirited Away”)]/text()//*[contains(.,”Ratings:”)]/../../tr[1]/td/text()//*[contains(.,”Director:”)]/../../tr[1]/td/text()
Correct (absolute) rule:/html/table/tr[1]/td/text()
• The fragment is too expressive: the correct rule can be generated • But many MQ are needed to find it
8/15
State-of-the-art approaches fall in the first case !They statically define the expressiveness of the XPath fragment

Expressiveness
• The fragment is just expressive enough: the correct rule can be generated. • Few queries are needed to find it
/html/table/tr[1]/td/text()
/html/table/tr[1]/td/text()//*[contains(.,”Spirited Away”)]/text()//*[contains(.,”Ratings:”)]/../../tr[1]/td/text()//*[contains(.,”Director:”)]/../../tr[1]/td/text()
Correct (absolute) rule:/html/table/tr[1]/td/text()
• The fragment is too expressive: the correct rule can be generated • But many MQ are needed to find it
8/15
State-of-the-art approaches fall in the first case !They statically define the expressiveness of the XPath fragment

R0 : Absolute Rules
R1 : R0 + Relative Rules
.....
Expressiveness
5%
70%25%
We defined simple XPath fragments. Empirically observed: too expressive fragments are not actually needed.
9/15

Rules are organized in a Hierarchy of Fragments with increasing expressiveness
R0 : Absolute Rules
R1 : R0 + Relative Rules
.....
Expressiveness
5%
70%25%
We defined simple XPath fragments. Empirically observed: too expressive fragments are not actually needed.
9/15

Rules are organized in a Hierarchy of Fragments with increasing expressiveness
R0 : Absolute Rules
R1 : R0 + Relative Rules
.....
Inspired by Structural Risk Minimization (SRM)*: a Machine Learning technique to address overfitting
*Details: Shawe-Taylor et all - IEEE Transactions on Information Theory, 44(5):1926–1940, 1998
Expressiveness
5%
70%25%
We defined simple XPath fragments. Empirically observed: too expressive fragments are not actually needed.
9/15

Dynamic Expressiveness
R0 : Absolute Rules
10/15

Dynamic Expressiveness
R0 : Absolute Rules
10/15
P (R|Lk)No solution?
> ?�R

Dynamic Expressiveness
R0 : Absolute Rules
10/15
P (R|Lk)No solution?
> ?�R
Expands the expressiveness
No

R1 : R0 + Relative Rules
Dynamic Expressiveness
R0 : Absolute Rules
10/15
P (R|Lk)No solution?
> ?�R
Expands the expressiveness
No
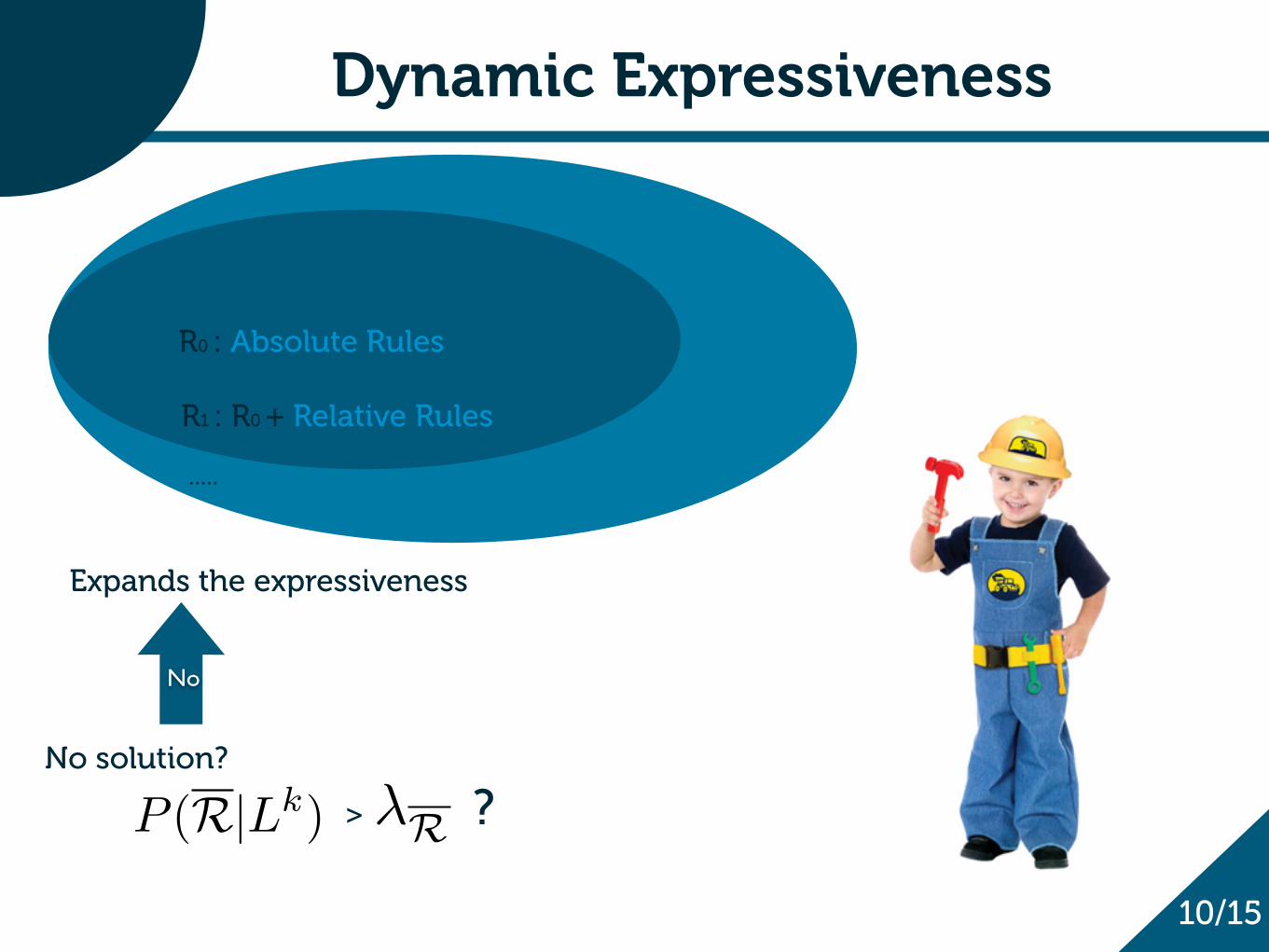
.....
R1 : R0 + Relative Rules
Dynamic Expressiveness
R0 : Absolute Rules
10/15
P (R|Lk)No solution?
> ?�R
Expands the expressiveness
No

.....
R1 : R0 + Relative Rules
Dynamic Expressiveness
R0 : Absolute Rules
10/15
P (r|Lk)Is r good enough?
> ?�r
Expands the expressiveness
No

.....
R1 : R0 + Relative Rules
Yes
Terminates
Dynamic Expressiveness
R0 : Absolute Rules
10/15
P (r|Lk)Is r good enough?
> ?�r
Expands the expressiveness
No

Results
Site Entity |Pages|www.imdb.com Actor 500k
www.imdb.com Movies 500k
www.allmusic.com Band 500k
www.allmusic.com Albums 500k
www.nasdaq.com Stock Quotes 7k
Dataset: 40 attributes
Measures:
• Costs - #MQ• Quality - Precision and Recall
11/15

Results: Dynamic Expressiveness
Strategy #MQ (SRM off) #MQ (SRM on) % MQ saved P (SRM on) R (SRM on)
RANDOM 379 190 50% 0,998 0,977
GREEDY 398 169 58% 0,998 0,983
LUCKY 196 132 33% 0,996 0,995
ENTROPY 205 116 44% 0,998 0,99
12/15

Results: Dynamic Expressiveness
Strategy #MQ (SRM off) #MQ (SRM on) % MQ saved P (SRM on) R (SRM on)
RANDOM 379 190 50% 0,998 0,977
GREEDY 398 169 58% 0,998 0,983
LUCKY 196 132 33% 0,996 0,995
ENTROPY 205 116 44% 0,998 0,99
Dynamic Expressiveness saves a lot of queries
12/15

Results: Dynamic Expressiveness
Strategy #MQ (SRM off) #MQ (SRM on) % MQ saved P (SRM on) R (SRM on)
RANDOM 379 190 50% 0,998 0,977
GREEDY 398 169 58% 0,998 0,983
LUCKY 196 132 33% 0,996 0,995
ENTROPY 205 116 44% 0,998 0,99
Dynamic Expressiveness saves a lot of queries
Small quality loss: The expressiveness is not expanded when it is needed
12/15
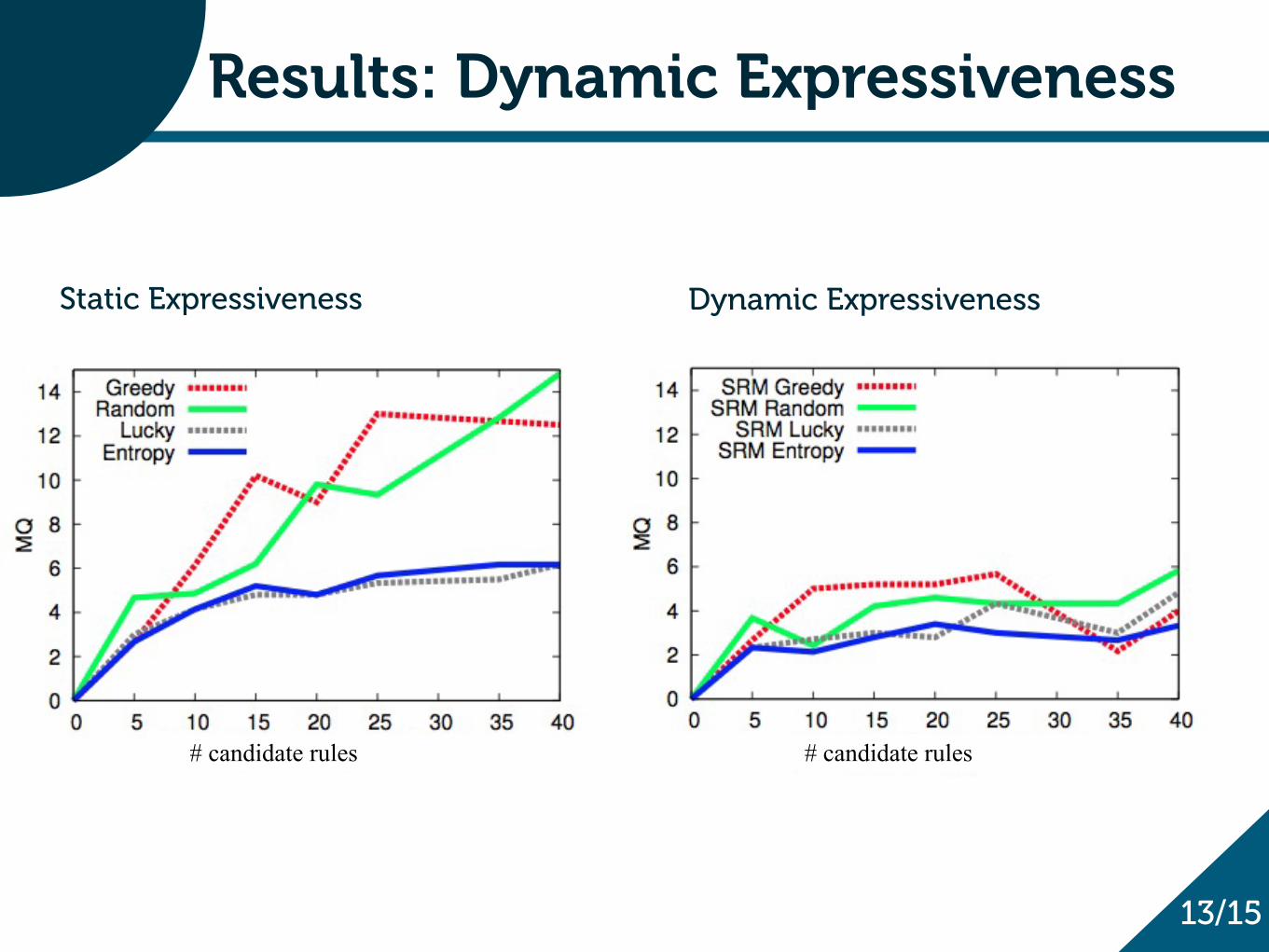
Results: Dynamic Expressiveness
Static Expressiveness Dynamic Expressiveness
# candidate rules # candidate rules
13/15

Results: Dynamic Expressiveness
Static Expressiveness Dynamic Expressiveness
“Simple” attributes: complex algorithms are not needed
# candidate rules # candidate rules
13/15

Results: Dynamic Expressiveness
Static Expressiveness Dynamic Expressiveness
“Simple” attributes: complex algorithms are not needed
“Complex” attributes: Entropy, Lucky and Dynamic Expressiveness saves a lot of queries
# candidate rules # candidate rules
13/15

Future development
Noisy Crowds: workers mistakes vs task redundancy* How to evaluate the accuracy of the worker?
Another query or another worker?
Same learning framework, different problems: NLP, Crawling
14/15
*Demo Title: ALFRED: Crowd Assisted Data Extraction When: Tomorrow 17h Where: Imperial Room

Thank you for the attention !!
15/15

15/15
Redundancy
0
0,5
1
0 1 2 3 4
P(r1)
P(r2)
P(r3)
# MQ
0
0,5
1
0 1 2 3 4
P(r1)
P(r2)
P(r3)
Not Accurate Worker
# MQ
0
0,5
1
0 1 2 3 4
P(r1)
P(r2)
P(r3)
# MQ
Many Workers
Accurate Worker

... selecting the right sample set is crucial
Sampling & Quality
2M pages from IMDB, we have to work with a sample set but ....

... selecting the right sample set is crucial
Sampling & Quality
2M pages from IMDB, we have to work with a sample set but ....

... selecting the right sample set is crucial
Sampling & Quality
2M pages from IMDB, we have to work with a sample set but ....
Inference algorithm!

... selecting the right sample set is crucial
Sampling & Quality
2M pages from IMDB, we have to work with a sample set but ....
Inference algorithm!

... selecting the right sample set is crucial
Sampling & Quality
2M pages from IMDB, we have to work with a sample set but ....
Inference algorithm!

... selecting the right sample set is crucial
Sampling & Quality
2M pages from IMDB, we have to work with a sample set but ....
Inference algorithm!

... selecting the right sample set is crucial
Sampling & Quality
2M pages from IMDB, we have to work with a sample set but ....
Wrapper!
Inference algorithm!

... selecting the right sample set is crucial
Sampling & Quality
2M pages from IMDB, we have to work with a sample set but ....
Wrapper!
Inference algorithm!
DB#
... Not all pages look like the pages about famous movies

Sampling & Quality
page0
r1
r2
r3
Spirited Away
Spirited Away
Spirited Away
r1 = r2 = r3

Sampling & Quality
page0
r1
r2
r3
Spirited Away
Spirited Away
Spirited Away
r1 = r2 = r3
page0 page1
r1
r2
r3
Spirited Away City of God
Spirited Away -
Spirited Away City of God
r1 = r3 != r2

Sampling & Quality
page0
r1
r2
r3
Spirited Away
Spirited Away
Spirited Away
r1 = r2 = r3
page0 page1
r1
r2
r3
Spirited Away City of God
Spirited Away -
Spirited Away City of God
r1 = r3 != r2
page0 page1 page2
r1
r2
r3
Spirited Away City of God Howl’s Moving Castle
Spirited Away - 9.3
Spirited Away City of God null
r1 != r3 != r2

Sampling & Quality
page0
r1
r2
r3
Spirited Away
Spirited Away
Spirited Away
r1 = r2 = r3
page0 page1
r1
r2
r3
Spirited Away City of God
Spirited Away -
Spirited Away City of God
r1 = r3 != r2
page0 page1 page2
r1
r2
r3
Spirited Away City of God Howl’s Moving Castle
Spirited Away - 9.3
Spirited Away City of God null
r1 != r3 != r2
Pages make apparent the differences among the rules
Find a small set that makes apparent the same differences observed in the
whole set of pages*

Sampling & Quality
The problem.
Find the smallest set that makes apparent the differences among the rules:(e.g., 100 pages that make apparent the same differences that we would observe in 2M pages).
It is a NP-Hard problem !! Reduction to SET-Cover problem:Find the smallest set of pages that cover all the group of rules (group = equivalent rules).
The smallest set is not needed:A greedy algorithm O(|Pages|) in time and O(1) in space works very well in practice.

XPath rules
For every page p: if (p makes apparent new differences) representative pages += p
An offline algorithm that can be easily parallelized
Sampling & Quality

Results: Sampling
Three sample sets:• Biased
Pages collected by crawling the website
• RandomPages randomly picked from the whole set of pages
• RepresentativePages collected by our sampling algorithm

Results: Sampling
Entity Sampling |Pages| P R
Movies
Biased 250 0.98 0.71
Movies Random 250 0.99 0.99Movies
Representative 42 1.00 1.00
Actors
Biased 250 1.00 1.00
Actors Random 250 1.00 0.96Actors
Representative 30 1.00 1.00
Stocks
Biased 86 1.00 0.98
Stocks Random 86 1.00 0.99Stocks
Representative 15 1.00 1.00
Albums
Biased 258 1.00 0.99
Albums Random 258 1.00 1.00Albums
Representative 59 1.00 1.00
Bands
Biased 289 1.00 0.68
Bands Random 289 1.00 1.00Bands
Representative 36 1.00 1.00

Results: Sampling
Entity Sampling |Pages| P R
Movies
Biased 250 0.98 0.71
Movies Random 250 0.99 0.99Movies
Representative 42 1.00 1.00
Actors
Biased 250 1.00 1.00
Actors Random 250 1.00 0.96Actors
Representative 30 1.00 1.00
Stocks
Biased 86 1.00 0.98
Stocks Random 86 1.00 0.99Stocks
Representative 15 1.00 1.00
Albums
Biased 258 1.00 0.99
Albums Random 258 1.00 1.00Albums
Representative 59 1.00 1.00
Bands
Biased 289 1.00 0.68
Bands Random 289 1.00 1.00Bands
Representative 36 1.00 1.00
Representative perfect

Results: Sampling
Entity Sampling |Pages| P R
Movies
Biased 250 0.98 0.71
Movies Random 250 0.99 0.99Movies
Representative 42 1.00 1.00
Actors
Biased 250 1.00 1.00
Actors Random 250 1.00 0.96Actors
Representative 30 1.00 1.00
Stocks
Biased 86 1.00 0.98
Stocks Random 86 1.00 0.99Stocks
Representative 15 1.00 1.00
Albums
Biased 258 1.00 0.99
Albums Random 258 1.00 1.00Albums
Representative 59 1.00 1.00
Bands
Biased 289 1.00 0.68
Bands Random 289 1.00 1.00Bands
Representative 36 1.00 1.00

Results: Sampling
Entity Sampling |Pages| P R
Movies
Biased 250 0.98 0.71
Movies Random 250 0.99 0.99Movies
Representative 42 1.00 1.00
Actors
Biased 250 1.00 1.00
Actors Random 250 1.00 0.96Actors
Representative 30 1.00 1.00
Stocks
Biased 86 1.00 0.98
Stocks Random 86 1.00 0.99Stocks
Representative 15 1.00 1.00
Albums
Biased 258 1.00 0.99
Albums Random 258 1.00 1.00Albums
Representative 59 1.00 1.00
Bands
Biased 289 1.00 0.68
Bands Random 289 1.00 1.00Bands
Representative 36 1.00 1.00
Biased: recall loss

Results: Sampling
Entity Sampling |Pages| P R
Movies
Biased 250 0.98 0.71
Movies Random 250 0.99 0.99Movies
Representative 42 1.00 1.00
Actors
Biased 250 1.00 1.00
Actors Random 250 1.00 0.96Actors
Representative 30 1.00 1.00
Stocks
Biased 86 1.00 0.98
Stocks Random 86 1.00 0.99Stocks
Representative 15 1.00 1.00
Albums
Biased 258 1.00 0.99
Albums Random 258 1.00 1.00Albums
Representative 59 1.00 1.00
Bands
Biased 289 1.00 0.68
Bands Random 289 1.00 1.00Bands
Representative 36 1.00 1.00

Results: Sampling
Entity Sampling |Pages| P R
Movies
Biased 250 0.98 0.71
Movies Random 250 0.99 0.99Movies
Representative 42 1.00 1.00
Actors
Biased 250 1.00 1.00
Actors Random 250 1.00 0.96Actors
Representative 30 1.00 1.00
Stocks
Biased 86 1.00 0.98
Stocks Random 86 1.00 0.99Stocks
Representative 15 1.00 1.00
Albums
Biased 258 1.00 0.99
Albums Random 258 1.00 1.00Albums
Representative 59 1.00 1.00
Bands
Biased 289 1.00 0.68
Bands Random 289 1.00 1.00Bands
Representative 36 1.00 1.00
Random: better than biased

State of Art
• 2006 - Interactive wrapper generation with minimal user effort. U. Irmik et al. WWW
• 2006 - Active learning with multiple views. I. Muslea et al. JAIR
Supervised Wrapper Induction

State of Art
• 2008 - Wrapper inference for ambiguous web pages. C. Valter and P. Merialdo JAAI
• 2005 - Web Data Extraction Based on Partial Tree Alignment Yanhong Zhai WWW.
Unsupervised Wrapper Induction

State of Art
• 2012 - D.I.A.D.E.M. J. Furche and G. Gottlob WWW
• 2011 - Automatic wrappers for large scale web extraction. N.N. Dalvi et al. VLDB.
Automatic Annotators