alex lefur intro to hadoop and mahout
TRANSCRIPT

Intro to Apache Mahout
Grant Ingersoll
Lucid Imagination
httpwwwlucidimaginationcom
Anyone Here Use Machine Learning
bull Any users ofndash Google
bull Search
bull Priority Inbox
ndash Facebook
ndash Twitter
ndash LinkedIn
Topics
bull Background and Use Cases
bull What can you do in Mahout
bull Wherersquos the community at
bull Resources
bull K-Means in Hadoop (time permitting)
Definition
bull ldquoMachine Learning is programming computers to optimize a performance criterion using example data or past experiencerdquondash Intro To Machine Learning by E Alpaydin
bull Subset of Artificial Intelligencebull Lots of related fields
ndash Information Retrievalndash Statsndash Biologyndash Linear algebrandash Many more
Common Use Cases
bull Recommend friendsdatesproducts
bull Classify content into predefined groups
bull Find similar content
bull Find associationspatterns in actionsbehaviors
bull Identify key topicssummarize textndash Documents and Corpora
bull Detect anomaliesfraud
bull Ranking search results
bull Others
Apache Mahout
bull An Apache Software Foundation project to create scalable machine learning libraries under the Apache Software Licensendash httpmahoutapacheorg
bull Why Mahoutndash Many Open Source ML libraries either
bull Lack Communitybull Lack Documentation and Examplesbull Lack Scalabilitybull Lack the Apache Licensebull Or are research-oriented
Definition httpdictionaryreferencecombrowsemahout
What does scalable mean to us
bull Goal Be as fast and efficient as possible given the intrinsic design of the algorithmndash Some algorithms wonrsquot scale to massive machine
clusters
ndash Others fit logically on a Map Reduce framework like Apache Hadoop
ndash Still others will need different distributed programming models
ndash Others are already fast (SGD)
bull Be pragmatic
Sampling of Who uses Mahout
httpscwikiapacheorgconfluencedisplayMAHOUTPowered+By+Mahout
What Can I do with Mahout Right Now
3C + FPM + O = Mahout
Collaborative Filtering
bull Extensive framework for collaborative filtering (recommenders)
bull Recommendersndash User based
ndash Item based
bull Online and Offline supportndash Offline can utilize Hadoop
bull Many different Similarity measuresndash Cosine LLR Tanimoto Pearson others
Clustering
bull Document level
ndash Group documents based on a notion of similarity
ndash K-Means Fuzzy K-Means Dirichlet Canopy Mean-Shift EigenCuts (Spectral)
ndash All MapReduce
ndash Distance Measuresbull Manhattan Euclidean
other
bull Topic Modeling
ndash Cluster words across documents to identify topics
ndash Latent DirichletAllocation (MR)
Categorizationbull Place new items into
predefined categoriesndash Sports politics
entertainment
ndash Recommenders
bull Implementationsndash Naiumlve Bayes (MR)
ndash Compl Naiumlve Bayes (MR)
ndash Decision Forests (MR)
ndash Linear Regression (Seq but Fast)
bullSee Chapter 17 of Mahout in Action for Shop It To Me use case
bullhttpawesm5FyNe
Freq Pattern Mining
bull Identify frequently co-occurrent items
bull Useful forndash Query
Recommendationsbull Apple -gt iPhone orange
OS X
ndash Related product placementbull Basket Analysis
bull MapReduce
httpwwwamazoncom
Other
bull Primitive Collections
bull Collocations (MR)
bull Math libraryndash Vectors Matrices etc
bull Noise Reduction via Singular Value Decomp (MR)
Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Anyone Here Use Machine Learning
bull Any users ofndash Google
bull Search
bull Priority Inbox
ndash Facebook
ndash Twitter
ndash LinkedIn
Topics
bull Background and Use Cases
bull What can you do in Mahout
bull Wherersquos the community at
bull Resources
bull K-Means in Hadoop (time permitting)
Definition
bull ldquoMachine Learning is programming computers to optimize a performance criterion using example data or past experiencerdquondash Intro To Machine Learning by E Alpaydin
bull Subset of Artificial Intelligencebull Lots of related fields
ndash Information Retrievalndash Statsndash Biologyndash Linear algebrandash Many more
Common Use Cases
bull Recommend friendsdatesproducts
bull Classify content into predefined groups
bull Find similar content
bull Find associationspatterns in actionsbehaviors
bull Identify key topicssummarize textndash Documents and Corpora
bull Detect anomaliesfraud
bull Ranking search results
bull Others
Apache Mahout
bull An Apache Software Foundation project to create scalable machine learning libraries under the Apache Software Licensendash httpmahoutapacheorg
bull Why Mahoutndash Many Open Source ML libraries either
bull Lack Communitybull Lack Documentation and Examplesbull Lack Scalabilitybull Lack the Apache Licensebull Or are research-oriented
Definition httpdictionaryreferencecombrowsemahout
What does scalable mean to us
bull Goal Be as fast and efficient as possible given the intrinsic design of the algorithmndash Some algorithms wonrsquot scale to massive machine
clusters
ndash Others fit logically on a Map Reduce framework like Apache Hadoop
ndash Still others will need different distributed programming models
ndash Others are already fast (SGD)
bull Be pragmatic
Sampling of Who uses Mahout
httpscwikiapacheorgconfluencedisplayMAHOUTPowered+By+Mahout
What Can I do with Mahout Right Now
3C + FPM + O = Mahout
Collaborative Filtering
bull Extensive framework for collaborative filtering (recommenders)
bull Recommendersndash User based
ndash Item based
bull Online and Offline supportndash Offline can utilize Hadoop
bull Many different Similarity measuresndash Cosine LLR Tanimoto Pearson others
Clustering
bull Document level
ndash Group documents based on a notion of similarity
ndash K-Means Fuzzy K-Means Dirichlet Canopy Mean-Shift EigenCuts (Spectral)
ndash All MapReduce
ndash Distance Measuresbull Manhattan Euclidean
other
bull Topic Modeling
ndash Cluster words across documents to identify topics
ndash Latent DirichletAllocation (MR)
Categorizationbull Place new items into
predefined categoriesndash Sports politics
entertainment
ndash Recommenders
bull Implementationsndash Naiumlve Bayes (MR)
ndash Compl Naiumlve Bayes (MR)
ndash Decision Forests (MR)
ndash Linear Regression (Seq but Fast)
bullSee Chapter 17 of Mahout in Action for Shop It To Me use case
bullhttpawesm5FyNe
Freq Pattern Mining
bull Identify frequently co-occurrent items
bull Useful forndash Query
Recommendationsbull Apple -gt iPhone orange
OS X
ndash Related product placementbull Basket Analysis
bull MapReduce
httpwwwamazoncom
Other
bull Primitive Collections
bull Collocations (MR)
bull Math libraryndash Vectors Matrices etc
bull Noise Reduction via Singular Value Decomp (MR)
Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Topics
bull Background and Use Cases
bull What can you do in Mahout
bull Wherersquos the community at
bull Resources
bull K-Means in Hadoop (time permitting)
Definition
bull ldquoMachine Learning is programming computers to optimize a performance criterion using example data or past experiencerdquondash Intro To Machine Learning by E Alpaydin
bull Subset of Artificial Intelligencebull Lots of related fields
ndash Information Retrievalndash Statsndash Biologyndash Linear algebrandash Many more
Common Use Cases
bull Recommend friendsdatesproducts
bull Classify content into predefined groups
bull Find similar content
bull Find associationspatterns in actionsbehaviors
bull Identify key topicssummarize textndash Documents and Corpora
bull Detect anomaliesfraud
bull Ranking search results
bull Others
Apache Mahout
bull An Apache Software Foundation project to create scalable machine learning libraries under the Apache Software Licensendash httpmahoutapacheorg
bull Why Mahoutndash Many Open Source ML libraries either
bull Lack Communitybull Lack Documentation and Examplesbull Lack Scalabilitybull Lack the Apache Licensebull Or are research-oriented
Definition httpdictionaryreferencecombrowsemahout
What does scalable mean to us
bull Goal Be as fast and efficient as possible given the intrinsic design of the algorithmndash Some algorithms wonrsquot scale to massive machine
clusters
ndash Others fit logically on a Map Reduce framework like Apache Hadoop
ndash Still others will need different distributed programming models
ndash Others are already fast (SGD)
bull Be pragmatic
Sampling of Who uses Mahout
httpscwikiapacheorgconfluencedisplayMAHOUTPowered+By+Mahout
What Can I do with Mahout Right Now
3C + FPM + O = Mahout
Collaborative Filtering
bull Extensive framework for collaborative filtering (recommenders)
bull Recommendersndash User based
ndash Item based
bull Online and Offline supportndash Offline can utilize Hadoop
bull Many different Similarity measuresndash Cosine LLR Tanimoto Pearson others
Clustering
bull Document level
ndash Group documents based on a notion of similarity
ndash K-Means Fuzzy K-Means Dirichlet Canopy Mean-Shift EigenCuts (Spectral)
ndash All MapReduce
ndash Distance Measuresbull Manhattan Euclidean
other
bull Topic Modeling
ndash Cluster words across documents to identify topics
ndash Latent DirichletAllocation (MR)
Categorizationbull Place new items into
predefined categoriesndash Sports politics
entertainment
ndash Recommenders
bull Implementationsndash Naiumlve Bayes (MR)
ndash Compl Naiumlve Bayes (MR)
ndash Decision Forests (MR)
ndash Linear Regression (Seq but Fast)
bullSee Chapter 17 of Mahout in Action for Shop It To Me use case
bullhttpawesm5FyNe
Freq Pattern Mining
bull Identify frequently co-occurrent items
bull Useful forndash Query
Recommendationsbull Apple -gt iPhone orange
OS X
ndash Related product placementbull Basket Analysis
bull MapReduce
httpwwwamazoncom
Other
bull Primitive Collections
bull Collocations (MR)
bull Math libraryndash Vectors Matrices etc
bull Noise Reduction via Singular Value Decomp (MR)
Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Definition
bull ldquoMachine Learning is programming computers to optimize a performance criterion using example data or past experiencerdquondash Intro To Machine Learning by E Alpaydin
bull Subset of Artificial Intelligencebull Lots of related fields
ndash Information Retrievalndash Statsndash Biologyndash Linear algebrandash Many more
Common Use Cases
bull Recommend friendsdatesproducts
bull Classify content into predefined groups
bull Find similar content
bull Find associationspatterns in actionsbehaviors
bull Identify key topicssummarize textndash Documents and Corpora
bull Detect anomaliesfraud
bull Ranking search results
bull Others
Apache Mahout
bull An Apache Software Foundation project to create scalable machine learning libraries under the Apache Software Licensendash httpmahoutapacheorg
bull Why Mahoutndash Many Open Source ML libraries either
bull Lack Communitybull Lack Documentation and Examplesbull Lack Scalabilitybull Lack the Apache Licensebull Or are research-oriented
Definition httpdictionaryreferencecombrowsemahout
What does scalable mean to us
bull Goal Be as fast and efficient as possible given the intrinsic design of the algorithmndash Some algorithms wonrsquot scale to massive machine
clusters
ndash Others fit logically on a Map Reduce framework like Apache Hadoop
ndash Still others will need different distributed programming models
ndash Others are already fast (SGD)
bull Be pragmatic
Sampling of Who uses Mahout
httpscwikiapacheorgconfluencedisplayMAHOUTPowered+By+Mahout
What Can I do with Mahout Right Now
3C + FPM + O = Mahout
Collaborative Filtering
bull Extensive framework for collaborative filtering (recommenders)
bull Recommendersndash User based
ndash Item based
bull Online and Offline supportndash Offline can utilize Hadoop
bull Many different Similarity measuresndash Cosine LLR Tanimoto Pearson others
Clustering
bull Document level
ndash Group documents based on a notion of similarity
ndash K-Means Fuzzy K-Means Dirichlet Canopy Mean-Shift EigenCuts (Spectral)
ndash All MapReduce
ndash Distance Measuresbull Manhattan Euclidean
other
bull Topic Modeling
ndash Cluster words across documents to identify topics
ndash Latent DirichletAllocation (MR)
Categorizationbull Place new items into
predefined categoriesndash Sports politics
entertainment
ndash Recommenders
bull Implementationsndash Naiumlve Bayes (MR)
ndash Compl Naiumlve Bayes (MR)
ndash Decision Forests (MR)
ndash Linear Regression (Seq but Fast)
bullSee Chapter 17 of Mahout in Action for Shop It To Me use case
bullhttpawesm5FyNe
Freq Pattern Mining
bull Identify frequently co-occurrent items
bull Useful forndash Query
Recommendationsbull Apple -gt iPhone orange
OS X
ndash Related product placementbull Basket Analysis
bull MapReduce
httpwwwamazoncom
Other
bull Primitive Collections
bull Collocations (MR)
bull Math libraryndash Vectors Matrices etc
bull Noise Reduction via Singular Value Decomp (MR)
Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Common Use Cases
bull Recommend friendsdatesproducts
bull Classify content into predefined groups
bull Find similar content
bull Find associationspatterns in actionsbehaviors
bull Identify key topicssummarize textndash Documents and Corpora
bull Detect anomaliesfraud
bull Ranking search results
bull Others
Apache Mahout
bull An Apache Software Foundation project to create scalable machine learning libraries under the Apache Software Licensendash httpmahoutapacheorg
bull Why Mahoutndash Many Open Source ML libraries either
bull Lack Communitybull Lack Documentation and Examplesbull Lack Scalabilitybull Lack the Apache Licensebull Or are research-oriented
Definition httpdictionaryreferencecombrowsemahout
What does scalable mean to us
bull Goal Be as fast and efficient as possible given the intrinsic design of the algorithmndash Some algorithms wonrsquot scale to massive machine
clusters
ndash Others fit logically on a Map Reduce framework like Apache Hadoop
ndash Still others will need different distributed programming models
ndash Others are already fast (SGD)
bull Be pragmatic
Sampling of Who uses Mahout
httpscwikiapacheorgconfluencedisplayMAHOUTPowered+By+Mahout
What Can I do with Mahout Right Now
3C + FPM + O = Mahout
Collaborative Filtering
bull Extensive framework for collaborative filtering (recommenders)
bull Recommendersndash User based
ndash Item based
bull Online and Offline supportndash Offline can utilize Hadoop
bull Many different Similarity measuresndash Cosine LLR Tanimoto Pearson others
Clustering
bull Document level
ndash Group documents based on a notion of similarity
ndash K-Means Fuzzy K-Means Dirichlet Canopy Mean-Shift EigenCuts (Spectral)
ndash All MapReduce
ndash Distance Measuresbull Manhattan Euclidean
other
bull Topic Modeling
ndash Cluster words across documents to identify topics
ndash Latent DirichletAllocation (MR)
Categorizationbull Place new items into
predefined categoriesndash Sports politics
entertainment
ndash Recommenders
bull Implementationsndash Naiumlve Bayes (MR)
ndash Compl Naiumlve Bayes (MR)
ndash Decision Forests (MR)
ndash Linear Regression (Seq but Fast)
bullSee Chapter 17 of Mahout in Action for Shop It To Me use case
bullhttpawesm5FyNe
Freq Pattern Mining
bull Identify frequently co-occurrent items
bull Useful forndash Query
Recommendationsbull Apple -gt iPhone orange
OS X
ndash Related product placementbull Basket Analysis
bull MapReduce
httpwwwamazoncom
Other
bull Primitive Collections
bull Collocations (MR)
bull Math libraryndash Vectors Matrices etc
bull Noise Reduction via Singular Value Decomp (MR)
Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Apache Mahout
bull An Apache Software Foundation project to create scalable machine learning libraries under the Apache Software Licensendash httpmahoutapacheorg
bull Why Mahoutndash Many Open Source ML libraries either
bull Lack Communitybull Lack Documentation and Examplesbull Lack Scalabilitybull Lack the Apache Licensebull Or are research-oriented
Definition httpdictionaryreferencecombrowsemahout
What does scalable mean to us
bull Goal Be as fast and efficient as possible given the intrinsic design of the algorithmndash Some algorithms wonrsquot scale to massive machine
clusters
ndash Others fit logically on a Map Reduce framework like Apache Hadoop
ndash Still others will need different distributed programming models
ndash Others are already fast (SGD)
bull Be pragmatic
Sampling of Who uses Mahout
httpscwikiapacheorgconfluencedisplayMAHOUTPowered+By+Mahout
What Can I do with Mahout Right Now
3C + FPM + O = Mahout
Collaborative Filtering
bull Extensive framework for collaborative filtering (recommenders)
bull Recommendersndash User based
ndash Item based
bull Online and Offline supportndash Offline can utilize Hadoop
bull Many different Similarity measuresndash Cosine LLR Tanimoto Pearson others
Clustering
bull Document level
ndash Group documents based on a notion of similarity
ndash K-Means Fuzzy K-Means Dirichlet Canopy Mean-Shift EigenCuts (Spectral)
ndash All MapReduce
ndash Distance Measuresbull Manhattan Euclidean
other
bull Topic Modeling
ndash Cluster words across documents to identify topics
ndash Latent DirichletAllocation (MR)
Categorizationbull Place new items into
predefined categoriesndash Sports politics
entertainment
ndash Recommenders
bull Implementationsndash Naiumlve Bayes (MR)
ndash Compl Naiumlve Bayes (MR)
ndash Decision Forests (MR)
ndash Linear Regression (Seq but Fast)
bullSee Chapter 17 of Mahout in Action for Shop It To Me use case
bullhttpawesm5FyNe
Freq Pattern Mining
bull Identify frequently co-occurrent items
bull Useful forndash Query
Recommendationsbull Apple -gt iPhone orange
OS X
ndash Related product placementbull Basket Analysis
bull MapReduce
httpwwwamazoncom
Other
bull Primitive Collections
bull Collocations (MR)
bull Math libraryndash Vectors Matrices etc
bull Noise Reduction via Singular Value Decomp (MR)
Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

What does scalable mean to us
bull Goal Be as fast and efficient as possible given the intrinsic design of the algorithmndash Some algorithms wonrsquot scale to massive machine
clusters
ndash Others fit logically on a Map Reduce framework like Apache Hadoop
ndash Still others will need different distributed programming models
ndash Others are already fast (SGD)
bull Be pragmatic
Sampling of Who uses Mahout
httpscwikiapacheorgconfluencedisplayMAHOUTPowered+By+Mahout
What Can I do with Mahout Right Now
3C + FPM + O = Mahout
Collaborative Filtering
bull Extensive framework for collaborative filtering (recommenders)
bull Recommendersndash User based
ndash Item based
bull Online and Offline supportndash Offline can utilize Hadoop
bull Many different Similarity measuresndash Cosine LLR Tanimoto Pearson others
Clustering
bull Document level
ndash Group documents based on a notion of similarity
ndash K-Means Fuzzy K-Means Dirichlet Canopy Mean-Shift EigenCuts (Spectral)
ndash All MapReduce
ndash Distance Measuresbull Manhattan Euclidean
other
bull Topic Modeling
ndash Cluster words across documents to identify topics
ndash Latent DirichletAllocation (MR)
Categorizationbull Place new items into
predefined categoriesndash Sports politics
entertainment
ndash Recommenders
bull Implementationsndash Naiumlve Bayes (MR)
ndash Compl Naiumlve Bayes (MR)
ndash Decision Forests (MR)
ndash Linear Regression (Seq but Fast)
bullSee Chapter 17 of Mahout in Action for Shop It To Me use case
bullhttpawesm5FyNe
Freq Pattern Mining
bull Identify frequently co-occurrent items
bull Useful forndash Query
Recommendationsbull Apple -gt iPhone orange
OS X
ndash Related product placementbull Basket Analysis
bull MapReduce
httpwwwamazoncom
Other
bull Primitive Collections
bull Collocations (MR)
bull Math libraryndash Vectors Matrices etc
bull Noise Reduction via Singular Value Decomp (MR)
Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Sampling of Who uses Mahout
httpscwikiapacheorgconfluencedisplayMAHOUTPowered+By+Mahout
What Can I do with Mahout Right Now
3C + FPM + O = Mahout
Collaborative Filtering
bull Extensive framework for collaborative filtering (recommenders)
bull Recommendersndash User based
ndash Item based
bull Online and Offline supportndash Offline can utilize Hadoop
bull Many different Similarity measuresndash Cosine LLR Tanimoto Pearson others
Clustering
bull Document level
ndash Group documents based on a notion of similarity
ndash K-Means Fuzzy K-Means Dirichlet Canopy Mean-Shift EigenCuts (Spectral)
ndash All MapReduce
ndash Distance Measuresbull Manhattan Euclidean
other
bull Topic Modeling
ndash Cluster words across documents to identify topics
ndash Latent DirichletAllocation (MR)
Categorizationbull Place new items into
predefined categoriesndash Sports politics
entertainment
ndash Recommenders
bull Implementationsndash Naiumlve Bayes (MR)
ndash Compl Naiumlve Bayes (MR)
ndash Decision Forests (MR)
ndash Linear Regression (Seq but Fast)
bullSee Chapter 17 of Mahout in Action for Shop It To Me use case
bullhttpawesm5FyNe
Freq Pattern Mining
bull Identify frequently co-occurrent items
bull Useful forndash Query
Recommendationsbull Apple -gt iPhone orange
OS X
ndash Related product placementbull Basket Analysis
bull MapReduce
httpwwwamazoncom
Other
bull Primitive Collections
bull Collocations (MR)
bull Math libraryndash Vectors Matrices etc
bull Noise Reduction via Singular Value Decomp (MR)
Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

What Can I do with Mahout Right Now
3C + FPM + O = Mahout
Collaborative Filtering
bull Extensive framework for collaborative filtering (recommenders)
bull Recommendersndash User based
ndash Item based
bull Online and Offline supportndash Offline can utilize Hadoop
bull Many different Similarity measuresndash Cosine LLR Tanimoto Pearson others
Clustering
bull Document level
ndash Group documents based on a notion of similarity
ndash K-Means Fuzzy K-Means Dirichlet Canopy Mean-Shift EigenCuts (Spectral)
ndash All MapReduce
ndash Distance Measuresbull Manhattan Euclidean
other
bull Topic Modeling
ndash Cluster words across documents to identify topics
ndash Latent DirichletAllocation (MR)
Categorizationbull Place new items into
predefined categoriesndash Sports politics
entertainment
ndash Recommenders
bull Implementationsndash Naiumlve Bayes (MR)
ndash Compl Naiumlve Bayes (MR)
ndash Decision Forests (MR)
ndash Linear Regression (Seq but Fast)
bullSee Chapter 17 of Mahout in Action for Shop It To Me use case
bullhttpawesm5FyNe
Freq Pattern Mining
bull Identify frequently co-occurrent items
bull Useful forndash Query
Recommendationsbull Apple -gt iPhone orange
OS X
ndash Related product placementbull Basket Analysis
bull MapReduce
httpwwwamazoncom
Other
bull Primitive Collections
bull Collocations (MR)
bull Math libraryndash Vectors Matrices etc
bull Noise Reduction via Singular Value Decomp (MR)
Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Collaborative Filtering
bull Extensive framework for collaborative filtering (recommenders)
bull Recommendersndash User based
ndash Item based
bull Online and Offline supportndash Offline can utilize Hadoop
bull Many different Similarity measuresndash Cosine LLR Tanimoto Pearson others
Clustering
bull Document level
ndash Group documents based on a notion of similarity
ndash K-Means Fuzzy K-Means Dirichlet Canopy Mean-Shift EigenCuts (Spectral)
ndash All MapReduce
ndash Distance Measuresbull Manhattan Euclidean
other
bull Topic Modeling
ndash Cluster words across documents to identify topics
ndash Latent DirichletAllocation (MR)
Categorizationbull Place new items into
predefined categoriesndash Sports politics
entertainment
ndash Recommenders
bull Implementationsndash Naiumlve Bayes (MR)
ndash Compl Naiumlve Bayes (MR)
ndash Decision Forests (MR)
ndash Linear Regression (Seq but Fast)
bullSee Chapter 17 of Mahout in Action for Shop It To Me use case
bullhttpawesm5FyNe
Freq Pattern Mining
bull Identify frequently co-occurrent items
bull Useful forndash Query
Recommendationsbull Apple -gt iPhone orange
OS X
ndash Related product placementbull Basket Analysis
bull MapReduce
httpwwwamazoncom
Other
bull Primitive Collections
bull Collocations (MR)
bull Math libraryndash Vectors Matrices etc
bull Noise Reduction via Singular Value Decomp (MR)
Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Clustering
bull Document level
ndash Group documents based on a notion of similarity
ndash K-Means Fuzzy K-Means Dirichlet Canopy Mean-Shift EigenCuts (Spectral)
ndash All MapReduce
ndash Distance Measuresbull Manhattan Euclidean
other
bull Topic Modeling
ndash Cluster words across documents to identify topics
ndash Latent DirichletAllocation (MR)
Categorizationbull Place new items into
predefined categoriesndash Sports politics
entertainment
ndash Recommenders
bull Implementationsndash Naiumlve Bayes (MR)
ndash Compl Naiumlve Bayes (MR)
ndash Decision Forests (MR)
ndash Linear Regression (Seq but Fast)
bullSee Chapter 17 of Mahout in Action for Shop It To Me use case
bullhttpawesm5FyNe
Freq Pattern Mining
bull Identify frequently co-occurrent items
bull Useful forndash Query
Recommendationsbull Apple -gt iPhone orange
OS X
ndash Related product placementbull Basket Analysis
bull MapReduce
httpwwwamazoncom
Other
bull Primitive Collections
bull Collocations (MR)
bull Math libraryndash Vectors Matrices etc
bull Noise Reduction via Singular Value Decomp (MR)
Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Categorizationbull Place new items into
predefined categoriesndash Sports politics
entertainment
ndash Recommenders
bull Implementationsndash Naiumlve Bayes (MR)
ndash Compl Naiumlve Bayes (MR)
ndash Decision Forests (MR)
ndash Linear Regression (Seq but Fast)
bullSee Chapter 17 of Mahout in Action for Shop It To Me use case
bullhttpawesm5FyNe
Freq Pattern Mining
bull Identify frequently co-occurrent items
bull Useful forndash Query
Recommendationsbull Apple -gt iPhone orange
OS X
ndash Related product placementbull Basket Analysis
bull MapReduce
httpwwwamazoncom
Other
bull Primitive Collections
bull Collocations (MR)
bull Math libraryndash Vectors Matrices etc
bull Noise Reduction via Singular Value Decomp (MR)
Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Freq Pattern Mining
bull Identify frequently co-occurrent items
bull Useful forndash Query
Recommendationsbull Apple -gt iPhone orange
OS X
ndash Related product placementbull Basket Analysis
bull MapReduce
httpwwwamazoncom
Other
bull Primitive Collections
bull Collocations (MR)
bull Math libraryndash Vectors Matrices etc
bull Noise Reduction via Singular Value Decomp (MR)
Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Other
bull Primitive Collections
bull Collocations (MR)
bull Math libraryndash Vectors Matrices etc
bull Noise Reduction via Singular Value Decomp (MR)
Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Prepare Data from Raw content
bull Data Sourcesndash Lucene integration
bull binmahout lucenevector hellip
ndash Document Vectorizerbull binmahout seqdirectory hellip
bull binmahout seq2sparse hellip
ndash Programmaticallybull See the Utils module in Mahout and the IteratorltVectorgt
classes
ndash Database
ndash File system
How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

How to Command Line
bull Most algorithms have a Driver programndash $MAHOUT_HOMEbinmahoutsh helps with most tasks
bull Prepare the Datandash Different algorithms require different setup
bull Run the algorithmndash Single Nodendash Hadoop
bull Print out the results or incorporate into applicationndash Several helper classes
bull LDAPrintTopics ClusterDumper etc
Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Whatrsquos Happening Now
bull Unified Framework for Clustering and Classification
bull 05 release on the horizon (May)
bull Working towards 10 release by focusing on
ndash Tests examples documentation
ndash API cleanup and consistency
bull Gearing up for Google Summer of Code
ndash New MR work for Hidden Markov Models
Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Summary
bull Machine learning is all over the web today
bull Mahout is about scalable machine learning
bull Mahout has functionality for many of todayrsquos common machine learning tasks
bull Many Mahout implementations use Hadoop
Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Resources
bull httpmahoutapacheorg
bull httpcwikiapacheorgMAHOUT
bull user|devmahoutapacheorg
bull httpsvnapacheorgreposasfmahouttrunk
bull httphadoopapacheorg
Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Resources
bull ldquoMahout in Actionrdquo ndash Owen Anil Dunning and Friedman
ndash httpawesm5FyNe
bull ldquoIntroducing Apache Mahoutrdquo ndash httpwwwibmcomdeveloperworksjavalibraryj-mahout
bull ldquoTaming Textrdquo by Ingersoll Morton Farris
bull ldquoProgramming Collective Intelligencerdquo by Toby Segaran
bull ldquoData Mining - Practical Machine Learning Tools and Techniquesrdquo by Ian H Witten and Eibe Frank
bull ldquoData-Intensive Text Processing with MapReducerdquo by Jimmy Lin and Chris Dyer
K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

K-Means
bull Clustering Algorithm
ndash Nicely parallelizable
httpenwikipediaorgwikiK-means_clustering
K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

K-Means in Map-Reduce
bull Inputndash Mahout Vectors representing the original content
ndash Eitherbull A predefined set of initial centroids (Can be from Canopy)
bull --k ndash The number of clusters to produce
bull Iteratendash Do the centroid calculation (more in a moment)
bull Clustering Step (optional)
bull Outputndash Centroids (as Mahout Vectors)
ndash Points for each Centroid (if Clustering Step was taken)
Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

Map-Reduce Iteration
bull Each Iteration calculates the Centroids using
ndash KMeansMapper
ndash KMeansCombiner
ndash KMeansReducer
bull Clustering Step
ndash Calculate the points for each Centroid using
ndash KMeansClusterMapper
KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

KMeansMapper
bull During Setupndash Load the initial Centroids (or the
Centroids from the last iteration)
bull Map Phasendash For each input
bull Calculate itrsquos distance from each Centroid and output the closest one
bull Distance Measures are pluggablendash Manhattan Euclidean Squared
Euclidean Cosine others
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt
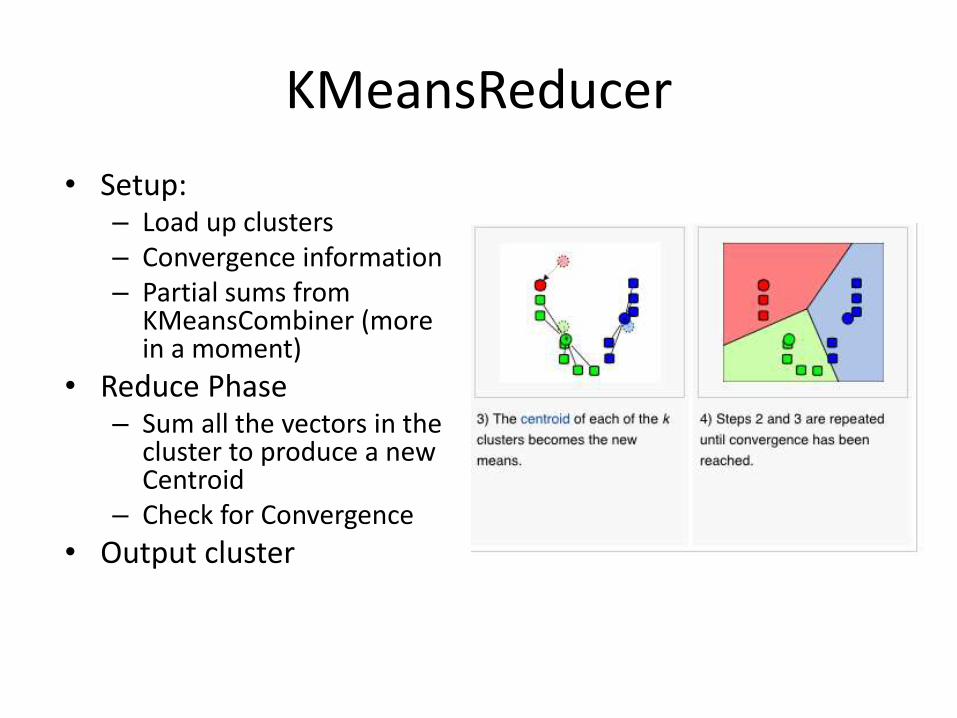
KMeansReducer
bull Setupndash Load up clustersndash Convergence informationndash Partial sums from
KMeansCombiner (more in a moment)
bull Reduce Phasendash Sum all the vectors in the
cluster to produce a new Centroid
ndash Check for Convergence
bull Output cluster
KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

KMeansCombiner
bull Just like KMeansReducer but only produces partial sum of the cluster based on the data local to the Mapper
KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt

KMeansClusterMapper
bull Some applications only care about what the Centroids are so this step is optional
bull Setupndash Load up the clusters and the DistanceMeasure
used
bull Map Phasendash Calculate which Cluster the point belongs to
ndash Output ltClusterId Vectorgt