air traffic control on a simd cots system stewart reddaway worldscape inc, marlton, nj will...
Post on 21-Dec-2015
214 views
TRANSCRIPT

Air Traffic Control on a SIMD COTS System
Stewart ReddawayWorldScape Inc, Marlton, NJ
Will Meilander (retired)Johnnie BakerJustin Kidman
Kent State University, Dept Computer Science, OH
IPDPS Denver, April 2005

AbstractAir Traffic Control is a demanding real-time application
Current systems have been: expensive late over-budget not up to specification complex in both algorithms and software
Modest-sized SIMD COTS systems will enable: guaranteed real-time performance simpler algorithms Substantially simpler and cheaper hardware
We cover: System & application approach some solution details
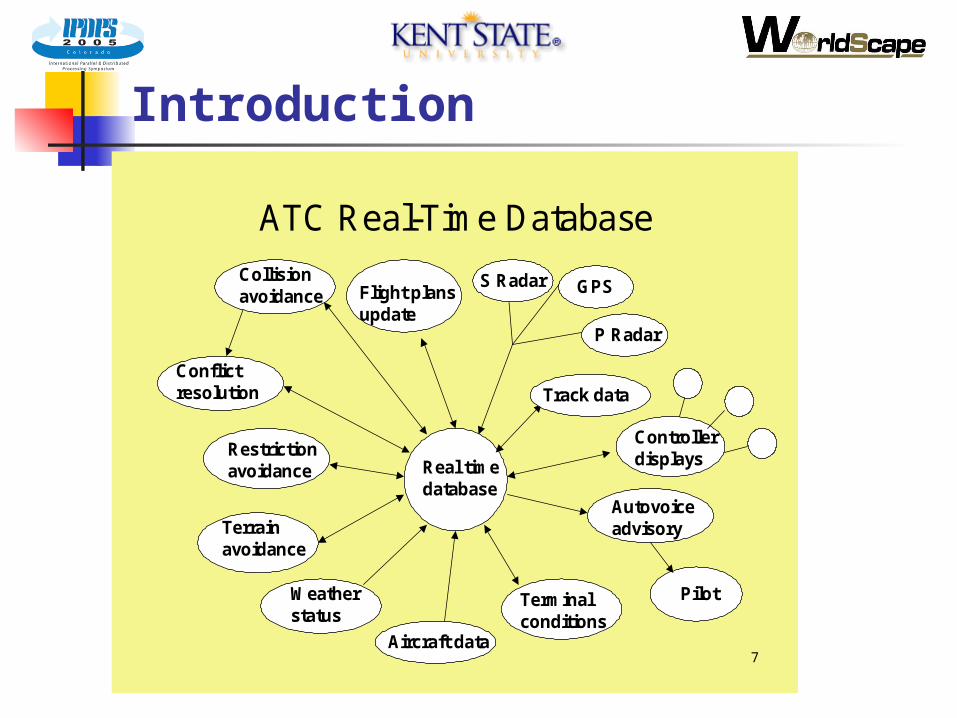
Introduction
7
ATC Real-Time Database
Real time database
Flight plans update
Collision avoidance
Conflict resolution
Restriction avoidance
Terrain avoidance
Weather status
Aircraft data
Terminal conditions
Pilot
Autovoice advisory
Controller displays
Track data
P Radar
GPSS Radar

A previous analysis at Kent State (1)
Two tables from Meilander, Jin and Baker [2002]
ATC – Worst-Case Environment Reports per second 12,000 IFR flights 4,000 VFR/backup flights 10,000 Controllers 600
There are thus up to 14000 flights in all 4000 flights controlled by this system 12000 radar reports/sec (6000 dealt with in each 0.5 sec)
Static scheduling is key to guaranteed real-time database operation
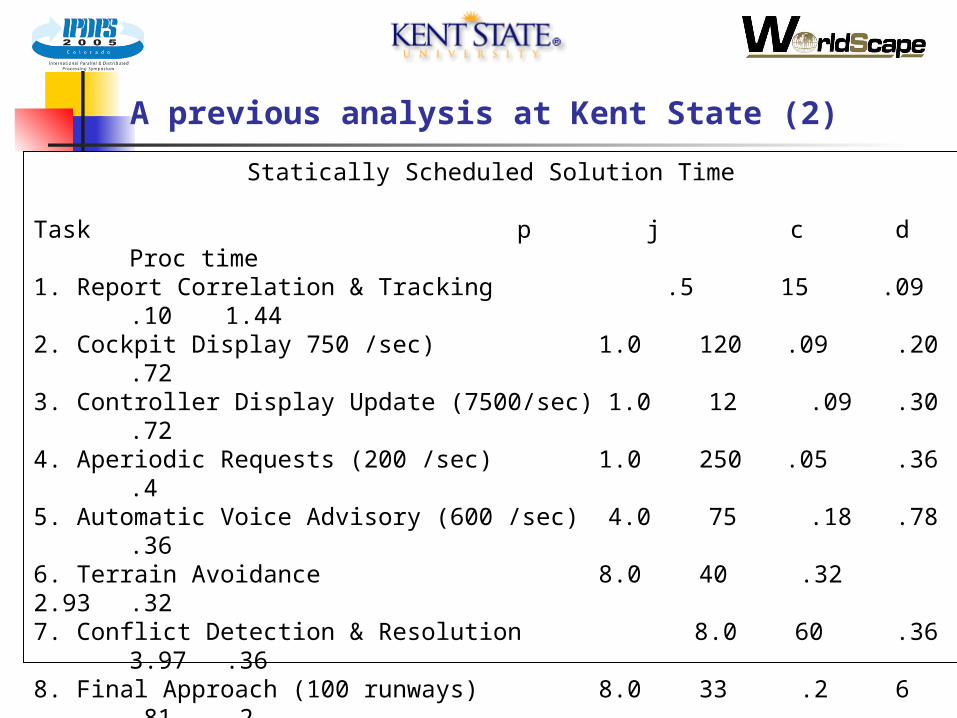
A previous analysis at Kent State (2)
Statically Scheduled Solution Time
Task p j c d Proc time1. Report Correlation & Tracking .5 15 .09 .10 1.442. Cockpit Display 750 /sec) 1.0 120 .09 .20 .723. Controller Display Update (7500/sec) 1.0 12 .09 .30 .724. Aperiodic Requests (200 /sec) 1.0 250 .05 .36 .45. Automatic Voice Advisory (600 /sec) 4.0 75 .18 .78 .366. Terrain Avoidance 8.0 40 .32 2.93 .327. Conflict Detection & Resolution 8.0 60 .36 3.97 .368. Final Approach (100 runways) 8.0 33 .2 6 .81
.2Summation of Tasks in a period P
4.52The system period P (in which all tasks must be completed) is 8 secondsp the task period time, determines the next task release time ri + 1 = ri + pj is the execution time, in microseconds, for each jobset in a task,c is the cost for each task for the worst-case set of jobsets,d the deadline time for each task ri + c + .01 (includes 10 ms interrupt proc. per task)

Modern SIMD Chips
Chips considered:
200 MHz CS301 250 MHz CSX600 due in Q2 2005.
These SIMD chips have:
powerful PEs (Processing Elements) 64 – 96 PEs per chip floating and fixed point in every PE 4 – 6 kB of “poly” RAM in each PE 96 GB/s load/store between poly RAM and register files fast I/O (up to 11 GB/s) each PE can specify its own address for I/O to external “mono”
RAM
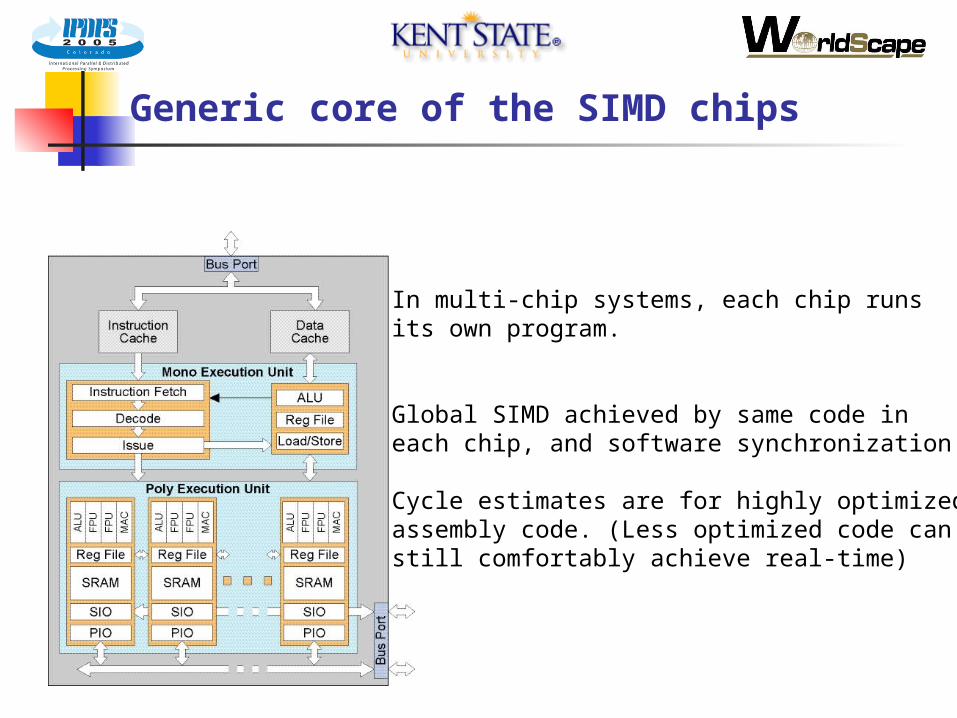
Generic core of the SIMD chips
In multi-chip systems, each chip runs its own program.
Global SIMD achieved by same code in each chip, and software synchronization
Cycle estimates are for highly optimized assembly code. (Less optimized code can still comfortably achieve real-time)

SIMD boards
CS301
CS301 boards contain 2 CS301 chips & 1 GB of “mono” DRAM. Proprietary ClearConnect bus runs from one CS301, across the
other CS301 and (via FPGA) to DRAM PCI interface connects to host computer such as a PC Kent State University will use this COTS board
CSX600
CSX600 board has 2 SIMD chips, each with on-chip DRAM interface
ClearConnect bus connects chips and (via FPGA) board 64-bit PCI-X interface

Analysis for a modern SIMD system
Modern chip fast enough to process many tracks per PE
Previous analysis had a PE for every track
Both algorithms are SIMD
~100 tracks per PE possible, so 14000 require ~140 PEs
Either three 64-PE chips or two 96-PE chips

Reduction and broadcast operations (1)
SIMD for ATC requires efficient global Reduction ops
Global synchronization required
This is the “difficult part” of the application
ATC uses global tests and PickOne
Other operations included for completeness.

Reduction and broadcast operations (2)
Global test (AND or OR)
Is a Boolean condition true anywhere?
Each PE first reduced to a single Boolean
Hardware reduces Boolean/PE to scalar (~15 cycles)
Multi-chip systems must (without hardware help): check that all chips have finished combine the results.
Each chip posts on DRAM that it has finished and its result, and then checks all chips have finished, reads results and computes global result
This across-chip work is ~100 cycles
Thus within-chip tests take ~15 cycles, and across-chip ~115 cycles

Reduction and broadcast operations (3)
PickOne (no special hardware for this non-trivial work)
PickOne picks the first False element in a Boolean array in 3 stages:
each PE finds if it has any F find first PE (if any) with an F finds first F in the PE
A “binary chop” does across-PE work in ~120 cycles: a global test looks for an F in the first half of PEs if not, the second half is chosen the chosen half is tested to find the quarter with 64 PEs, 6 such tests find the first F
With multiple chips, each chip posts its result on DRAM. After synchronization, chips read results and compute which is selected

Reduction and broadcast operations (4)
Max and Min
Each PE finds its own max, followed by a single across-PE stage
Bits are worked through starting with the MS, progressively eliminating PEs that cannot be biggest and retaining at least one PE in the “competition”
Test the next bit of all remaining PEs. If any bit is T, PEs with F are eliminated.
A record of the global test results gives the scalar max
Algorithm is constant time and takes ~20 cycles/bit.
For multiple chips, results are posted in mono RAM, each chip reads them and computes the global max. This adds about 100 cycles

Reduction and broadcast operations (5)
Sum
After within-PE sums, across-PE work uses a "log(n)" approach (within-chip Sum takes ~200 cycles)
Across-chip adds about 100 cycles.
Broadcast
Broadcasting to all PEs is part of the chip instruction set For multi-chip systems, each chip accesses the same
mono RAM If the mono data is stable (eg when correlating a sequence
of radar reports) no validity check is needed, but other cases may need validity to be semaphored

Report Correlation & Tracking (1)
An ATC system has many radars reporting object positions
~6000 radar reports assembled in 0.5 sec are trial correlated against all tracks
The track database is in mono DRAM. Correlation starts by loading 3 position coordinates/track, plus uncertainties, into poly RAM
14000 tracks and 192 PEs mean 73 tracks per PE
6 values (x, y, h plus uncertainties) broadcast for each report. Boxes of uncertainty around both track and report positions are tested for intersection
3 possibilities: report intersected by a unique track. Report data stored for updating that
track, and track marked not to correlate again two or more tracks intersect - marked as multiple hits uncorrelated report earmarked for wider tolerance correlation rounds
6 comparisons and 5 Booleans per track per report

Report Correlation & Tracking (2) (omit?)
For each report, correlations in each PE are counted, and the within-PE track number of first correlated track found. Count is 0, 1, many.
A global OR finds if there are any hits. If no hits, mark report for the next correlation round. If hit(s), PickOne finds first nonzero PE, and its count is
decremented
A global test checks for multiple hits. Any tracks involved are marked
If correlation unique, report data is copied to unique track
Correlation repeated for unmatched reports, with wider tolerances
Remaining unmatched reports start new tracks

Report Correlation & Tracking (3) (omit?)
Starting new tracks
Before Correlation starts: identify empty track locations count within-PE empty tracks form within-PE list of empty track locations global “scan sum” to give each PE its first “empty number” location
This work is done only once and takes negligible time
For each unmatched report: increment a mono count of new tracks compare this count with each PE’s empty track numbers
(e.g. if this is the 57th new track, only one PE will have this empty track number in its range)
within-PE address used to initiate a track with the report data

Report Correlation & Tracking (4) (omit?)
Higher Quality Correlation
Two error components in a radar report: along the radar radius (radar response time error) across the radius (azimuth angle error)
Other than for short range, errors are much bigger in azimuth than range
An eccentric ellipse is ideal, but an elongated report box is quite good
However, in system coordinates the rectangle is not usually aligned with the axes. Computing efficiency requires a box that is aligned
To include all possible good correlations makes an aligned box much bigger, but that will also include dubious correlations
“Radar coordinates”, with axes along and perpendicular to the radar radius, align the original radar box to the axes.

Report Correlation & Tracking (5)
Estimating cycles
In worst case, 6000 reports are estimated to need ~7300 correlations each: 1000 fail to correlate on first round, 300 fail on second round
Per track work (for 73 tracks/PE) is: 6 compares 5 Boolean ops one step of count hits and find the first address
~40 cycles inner loop gives ~21 M cycles per 0.5 sec
Each report needs ~1 PickOne and ~2.2 global tests. Reduction ~2.2 M cycles
Total ~23.7 M cycles, a 19.7% load at 250 MHz in a 0.5 sec period.
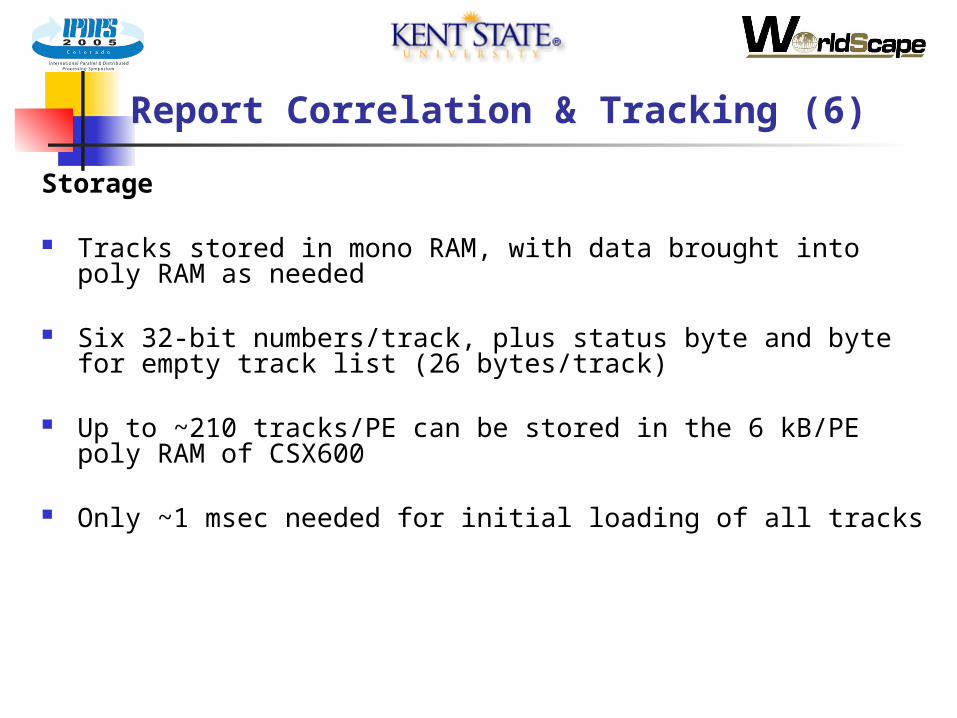
Report Correlation & Tracking (6)
Storage
Tracks stored in mono RAM, with data brought into poly RAM as needed
Six 32-bit numbers/track, plus status byte and byte for empty track list (26 bytes/track)
Up to ~210 tracks/PE can be stored in the 6 kB/PE poly RAM of CSX600
Only ~1 msec needed for initial loading of all tracks

Report Correlation & Tracking (7)
Faster Reductions in bulk
Big speedup can be achieved by processing several (e.g. 16) reports before doing across-PE reductions.
Detail in future paper

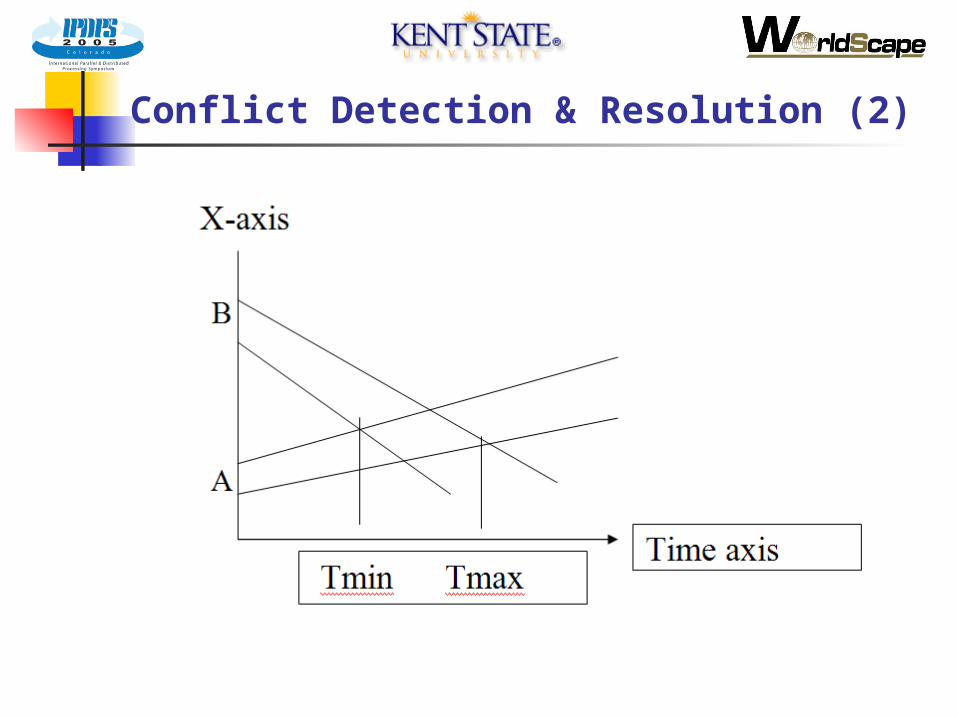
Conflict Detection & Resolution (1)
Conflict detection
Tracks projected 20 mins and each IFR track checked for conflict with any other track
For each dimension: Compute min and max closing velocity Compute min and max current track separation Division gives min and max tolerance on the time for that
dimension to coincide
Conflict Detection & Resolution (2)

Conflict Detection & Resolution (3)
Potential conflict if, across the 3 dimensions, biggest min time is smaller than smallest max time. (Ken Batcher algorithm.)
Conflict declared after two potential conflicts Conflict resolution
Track heading or altitude adjusted, and algorithm run again. Continues until conflict resolved and no new ones created

Conflict Detection & Resolution (3)
Implementation
21 of 73 tracks/PE are IFR 49 bytes/track. 73 tracks take ~3.6 kB out of 6 kB poly RAM/PE.
Active IFR track broadcast and conflict detection performed on all tracks: 6 subtracts to get min and max closing velocities 6 subtracts to get min and max distances 6 divides to get min and max times 4 compares to find max min and min max Subtract max min from min max. Sign is result one step of within-PE OR
Global OR checks for conflict, and PickOne finds the conflicting track
~330 cycles/track/PE. 4000 IFR tracks ~86 M cycles. Processing load < 5%

Cockpit Display
x, y, h positions of all tracks transferred to poly RAM
Batch of 750 IFR flights, processed one at a time
IFR flight’s x, y, h and velocity broadcast to all PEs
All track coordinates transformed so they are centered on broadcast track and rotated to coordinates in which the broadcast track is heading “North”
Tracks selected in 10 mile x 10 mile box elongated to include a 30 sec projection of the IFR flight
12 hit tracks is assumed to be worst case average
~5.9 M cycles

Controller Display Update
~7500 out of 14000 tracks in the controlled area are selected
Information on them sent to all control stations
Each station selects the tracks in its local area
The information is track position (x, y, h), heading and speed, all 16-bit
Speed is in knots using BCD (3 or 4 decimals)
Each track is made into a fixed size message of 16B including flight ID
The task is fast as there is no “all against all” component

Terrain Avoidance (1) Warn ~7500 flights (~40/PE) within local control boundaries if
they risk running into ground terrain Every 8 secs flights projected 1 min and tested against the
terrain map. The terrain map is an irregular 3D mesh surface with thousands
of triangles. Both natural topography and buildings/masts etc
Flights loaded to poly RAM and triangles broadcast one at a time
Terrain overhangs not included. Only base of flight projection box needed
Algorithm
Compute intersection of base surface and plane of a triangle. Collision if part of line lies in both the triangle and the base surface
~30 arithmetic, comparison or Boolean operations

Terrain Avoidance (2)
Performance
Proportional to number of triangles.
x and y for all 14k flights input to poly RAM, and used to select flights
Pack tracks and construct mono addresses to load rest of track data
The base of the flight projections are computed
For each triangle: broadcast 40 bytes, ~50 cycles compute intersections, 40 x ~70 = ~2.8k cycles within-PE OR of hits, 40 x ~2 = ~80 cycles single-chip global test for any hits, ~15 cycles
With 20k triangles, ~60 M cycles
Information on intersections is extracted and output to controller affected
Load ~3.8%. 20k triangles is manageable

Sporadic (Aperiodic) requests
This task:
inputs to various database tables in mono RAM responds to queries to the database. Once per second the host writes buffered messages to the
database With no simultaneous tasks, there are no synchronization or
scheduling issues Queries extract data from tables and transmit it to requesters Most messages are small, but some, such as wind table update,
are quite large Estimated maximum of 200 messages per second. ~1 M cycles

Automatic Voice Advisory (AVA)
AVA advises uncontrolled (VFR) flights of other aircraft and terrain
Gives a near equivalent to Cockpit Display
Computing similar to Cockpit Display, but simpler
~60% of the load of Cockpit Display

Final Approach (Runways)
Each flight plan specifies: departure terminal and planned departure time destination terminal and planned arrival time
Every 8 secs information for each of ~100 runways is gathered, a queue organized and any consequential modifications inserted in each flight plan
The relevant controller is informed of recommended flight changes
Stacking is minimized by delaying tracks in flight. (In emergencies, flights get stack detail from the controller)
~870k cycles, a load of < 0.1%

Speedup with Sorting (1)
Most tasks include “all against all” matching involving proximity. Sorting can greatly speed these up.
This is still SIMD computing. The sorting has data-independent deterministic speed. The rest has some data dependence, but big speedup even in worst cases
The dramatic speed gains can be used for: less optimized coding more complex or bigger requirements less hardware
The disadvantage is more complex algorithms

Speedup with Sorting (2)
Correlation
Input x and sort (including track numbers) with PE LS Fetch track data using addresses constructed from track numbers ~200 bins for x. Min poly track address for each bin in mono array Use min and max x for each report to TLU track addresses needed Worst case average number of tracks/PE ~20x fewer than without
sorting Core correlation cycles ~1.2 M; 4 other contributions:
sort time reduction operations finding the range of poly addresses final output of update data
Cycles reduce ~12x, from ~24M to ~1.92 M (with bulk Reduction)

Speedup with Sorting (3)
Terrain Avoidance
The 20k triangles permanently sorted on min value of x The sorted triangles have PE LS and RAM address MS Worst case speedup ~9x
Conflict Detection
Sorting by x velocity and x position gives speedup of ~3x
Cockpit Display and Automatic Voice Advisory
Sorting on x gives speedup of ~9x for both tasks
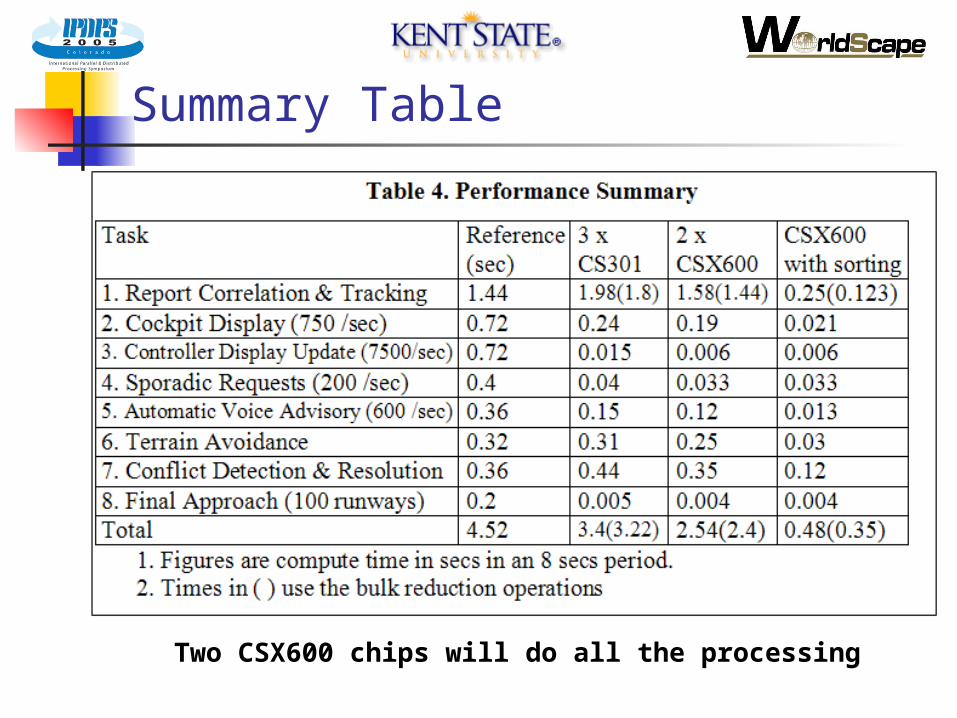
Summary Table
Two CSX600 chips will do all the processing

A staged plan of work
1. Establish requirements and algorithms2. Code in a high level language (Cn) for one CS3013. Speed and space optimization. Real-time speed for
~5000 tracks4. Extend reduction codes to 2 SIMD chips ~10000
tracks5. Move application to CSX600 board. ~20k tracks6. Demonstrations, reports and presentations.7. Using sorting, develop much faster codes
Kent State well placed with CS301 board
Steps 1 through 6 will take ~12 months

References
[1] W. Meilander, M. Jin, J. Baker. Tractable Real-Time Air Traffic Control Automation. Proceedings of the 14th IASTED International Conference Parallel and Distributed Computing and Systems, Cambridge, USA, 2002, pp. 483-488
[2] www.clearspeed.com
[3] To be published.
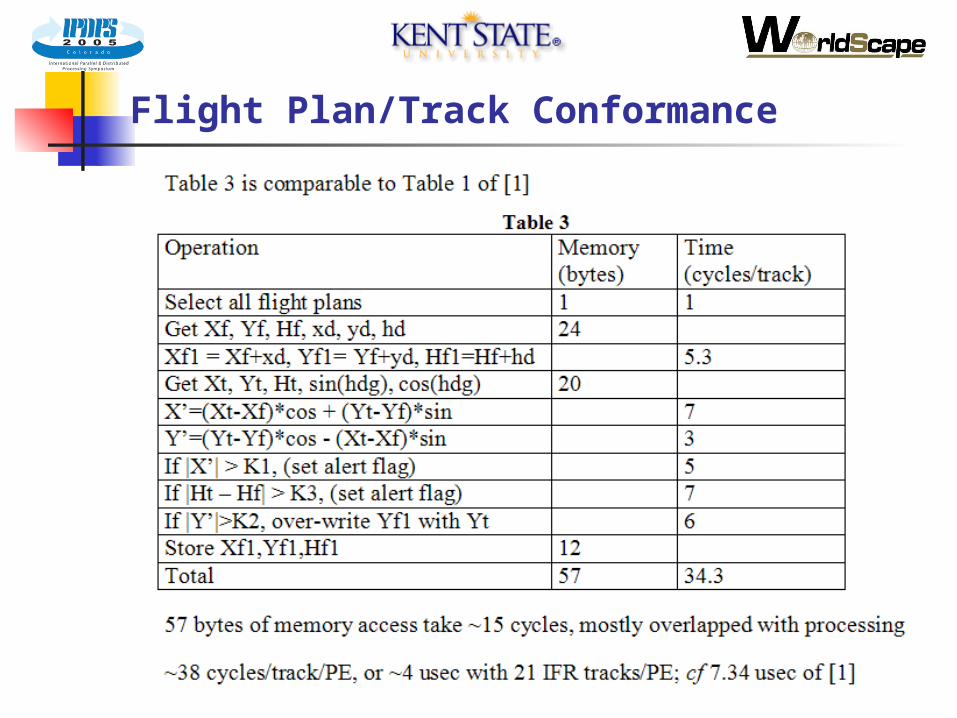
Flight Plan/Track Conformance