aho-corasick algorithm parallelization
TRANSCRIPT

Parallelization of a string-matching algorithmAdvanced Algorithms
Alessandro Liparoti

<Name Surname>
2String-matching: AC algorithm
String-matching algorithms are a class of algorithms that aim to find occurrences of words (patterns) within a larger string (text)
Aho-Corasick algorithm (AC) is a classic solution to exact set matching.
Given
pattern set 𝑃 = { 𝑃1, . . . , 𝑃𝑘 }
text 𝑇[1…𝑚]
total length of patterns n = 𝑖=1𝑘 |𝑃𝑖|
the AC algorithms complexity is 𝑂(𝑛 +𝑚 + 𝑧), where 𝑧is the number of pattern occurrences in 𝑇

<Name Surname>
3AC algorithm: finite-state machine
The AC algorithm builds a finite-state machine to efficiently memorize the pattern set
The FSA is memorized along with three functions
the goto function 𝑔(𝑞, 𝑎) gives the state entered
from current state 𝑞 by matching target char 𝑎
the failure function 𝑓 𝑞 , 𝑞 ≠ 0 gives the state
entered at a mismatch
the output function out 𝑞 gives the set of patterns
recognized when entering state q
<Name Surname>
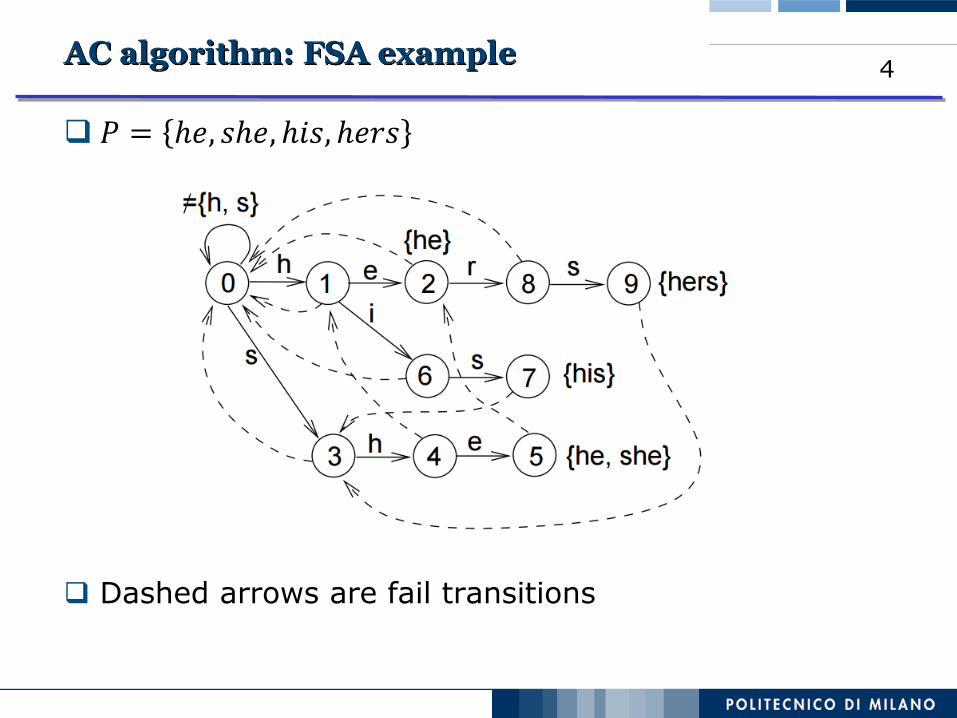
4AC algorithm: FSA example
𝑃 = ℎ𝑒, 𝑠ℎ𝑒, ℎ𝑖𝑠, ℎ𝑒𝑟𝑠
Dashed arrows are fail transitions

<Name Surname>
5AC algorithm: matching phase
The AC algorithm uses the FSA to match the text against the keywords
𝐴𝐶_𝑚𝑎𝑡𝑐ℎ𝑖𝑛𝑔 𝑇 1…𝑚
𝑞 ≔ 0; // initial state (root)
𝒇𝒐𝒓 𝑖 ≔ 1 𝒕𝒐 𝑚 𝒅𝒐
𝒘𝒉𝒊𝒍𝒆 𝑔 𝑞, 𝑇 𝑖 = 0 𝒅𝒐
𝑞 ≔ 𝑓 𝑞 ; // follow a fail
𝑞 ≔ 𝑔 𝑞, 𝑇 𝑖 ; // follow a goto
𝒊𝒇 𝑜𝑢𝑡 𝑞 ≠ 0 𝒕𝒉𝒆𝒏 𝒑𝒓𝒊𝒏𝒕 𝑖, 𝑜𝑢𝑡 𝑞 ;
𝒆𝒏𝒅𝒇𝒐𝒓
The number of steps of the loop is equal to the length of the text

<Name Surname>
6Parallelization step
Idea: parallelize the matching phase of the AC algorithm (the FSA can be built once for each pattern data set)
The 𝑚 steps of the loop can be split in 𝑘 chunks, each one of length 𝑙 = 𝑚 𝑘 and then each chunk can be processed by a thread
Feasible because a chunk can be independently analyzed
𝑚 = 19 𝑘 = 3 𝑙 = 7

<Name Surname>
7Parallelization: problems
The splitting phase as performed before can lead to missing occurrences
Let assume 𝑃 = 𝑎𝑑𝑣, 𝑜𝑟𝑖𝑡, 𝑒𝑑
Each thread would run AC on its related chunk
Thread 1: 𝑇 = 𝑎𝑑𝑣𝑎𝑛𝑐𝑒
Thread 2: 𝑇 = 𝑑 𝑎𝑙𝑔𝑜𝑟
Thread 3: 𝑇 = 𝑖𝑡ℎ𝑚𝑠
None of them would find the occurrences of the second and third keyword
Needed a redundancy for text overlapping twochunks

<Name Surname>
8Parallelization: solutions
The maximum needed overlap o is the lenght of the longest word in the pattern data set – 1
Each chunk will contain the last o characters of the previous one
However: orit correctly found by thread 3 but ed incorrectly matched twice (threads 1 and 2)
Correction: start counting matches only after o characters read

<Name Surname>
9Implementation
AC has been implemented in C using openMP; the matching-phase has been split among threads using the pragma for structure
Input: text, keywords, number of threads
Output: number of occurences
The chunk size 𝑙 is computed with the following formula
𝑙 = 𝑚 + 𝑜𝑣 ( 𝑘 − 1)
The output variable is aggregated after the end of the loop ( reduction statement )

<Name Surname>
10Implementation
Each read character is converted in its ASCII code
Therefore, the FSA
allows 256 different
transitions
It allows to use the AC
algorithm even with
non-textual files
Binary files must be
read bytewise

<Name Surname>
11Test
Very large input files have been used in order to test the algorithm’s performance
a text file containing the English version of the bible
a dictionary including the 10000 most common English words
A single test consists of an aggregation measure of 10 different runs of the algorithm on the inputs using the same number of threads

<Name Surname>
12Test
1 2 3 4 5 6 7 8 9 10
0
50
100
150
200
250
300
350
number of threads
execution t
ime (
sec)
i7 4700MQ - 4 cores/8 threads
Mean
Minimum

<Name Surname>
13Test
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
0
15
30
45
60
75
90
105
number of threads
execution t
ime (
sec)
12 cores/24 threads machine
mean
min

<Name Surname>
14Conclusion
In this work it has been showed a parallelization procedure for a serial-designed algorithm
The more threads are used the faster the algorithm runs until a certain point after which we do not get any improvements
Parallelization improves performance but requires modifications not always clear from the beginning that often lead to overheads