advanced parallel processing with supercomputer...
TRANSCRIPT

Advanced Parallel Processing with Supercomputer Architectures
Invited Paper
This paper investigates advanced parallel processing techniques and innovative hardwarelsoftware architectures that can be applied to boost the performance of supercomputers. Critical issues on architectural choices, parallel languages, compiling techniques, resource management, concurrency control, programming envi- ronment, parallel algorithms, and performance enhancement methods are examined and the best answers are presented. We cover advanced processing techniques suitable for supempu- ten, high-end mainframes, minisupers, and array processors. The coverage emphasizes vectorization, multitasking, multiprocessing, and distributed computing. In order to achieve these operation modes, parallel languages, smart compilers, synchronization mechanisms, load balancing methods, mapping parallel algo- rithms, operating system functions, application library, and multi- discipline interactions are investigated to ensure high perfor- mance. At the end, we assess the potentials of optical and neural technologies for developing future supercomputers
I. INTRODUCTION
Parallel processing has emerged as a hot field of research and development by computer professionals. Various classes of parallel and vector supercomputers have appeared in the past two decades [2], [HI, [65], [72], [87l, [log], [116]. However, the claimed performance may not always be delivered as promised by the vendors. This is due to the factthat today's supercomputers areonegeneration behind the user's needs and yet one generation ahead of the pop- ular programming skills. In other words, we really need supersoftware to help boost the performance. This paper presents advanced hardwarelsoftware techniques that can help in the creation of a parallel programmingenvironment in which real supercomputer performance can be deliv- ered.
Usually, the effective performance of a supercomputer ranges between only'5 and 25 percent of its peak perfor- mance [35]. Such a pessimistic show of the delivered per- formance motivates many computer specialists to search for better algorithms, languages, hardware, and software
Manuscript received March 23,1987; revised June 12,1987. This research was supported in part bythe National Science Foundation under Grant DMC-84-21022, the AFOSR under Grant 86-0008, and by the NOSC under Contract 85-D-0203.
The author i s with the Department of Electrical Engineering and Computer Science, Universityof Southern California, Los Angeles, CA 900894781, USA.
I E E E Log Number 8716264.
techniques to yield higher performance. We examine below the requirements of parallel, vector, and scalar processing. Basic performance measures and benchmarking concepts areintroducedfirst.1nsubsequentsectionsweaddresscrit- ical issues on languages, compilers, processor, memory, input/output, programming, and various performance enhancement methods for parallel processing on three classes of supercomputers.
A. Evolution of Modern Supercomputers
AS illustrated in Fig. 1, the evolution of supercomputer architecture follows an increasing trend of more hardware and software functions built into a system. The skewed tree demonstrates that most of today's supercomputers are designed with look-ahead techniques, functional parallel- ism, pipelining at various levels, using explicit vectors and exploring parallel processing in SlMD (single instruction and multiple data streams) or M lMD (multiple instruction and multiple data streams) mode [45]. Most supers support concurrent scalar processing and vector processing with multiple functional units in a uniprocessor or in a multi- processor system. We reserve the term multiprocessors for shared-memory multiple-processor systems and multicom- puters for loosely coupled multiple-processor systems with distributed local memories. Some authors call multicom- puters parallel computers [28]. For vector processors, we divide them into two subclasses: the register-to-register architecture is being adapted in almost all supers [MI and minisupers [81], except in the Cyber 205 [98] which chooses a memory-to-memory architecture [65].
Parallelism refers to the simultaneous processing of jobs, job steps, programs, routines, subroutines, loops, or state- ments, as illustrated in Fig. 2. The lower the level, the finer the granularity of the software processes. In general, par- allel processing refers to parallelism exploited at any or a combination of these levels. Sofar, vectorprocessing is par- allel processing of iterations of loops at level 2. Parallel exe- cution of independent scalar statements at level 1 has been implemented in many machines with the look-ahead tech- nique using multiple functional units. Most of today's com- puters allow multiprogramming, which provides for the sharing of processor resources among multiple, indepen- dent software processes. This is done even in a unipro-
1348
00189219/87/10081348$01.00 0 1987 IEEE
PROCEEDINGS OF THE IEEE, VOL. 75, NO. IO, OCTOBER 1987

G a I/E = I/E Instruction fekh/Decode
and Execution
MM = Memory-tc-Memory
RR = Register-t4bgiiter
SIMD = Single Instruction stream and Multiple Dat. S t r e a m
"D = Multiple Instruction streams and Multiple Data Stremas
Fig. 1. Architectural evolution from sequential scalar processing to concurrent vector/ scalar processing.
h e 1 5
Level 4
Level 3
Level 2
Level 1
Job step and related Partd of
I Loop and Iterations I
Statements and
Fig. 2. Five levels of parallelism in program execution.
cessor system, in which concurrent processes are inter- leaved with their CPU and 110 activities.
Multiprocessing is a mode of parallel processing that pro- vides interactive multiprogramming among two or more processors. Independent uniprocessing exploits parallel- ism at level 1 in multiple-SISD mode. Multitasking is a spe- cial case of multiprocessing defining a software process (a task) to be a job step or subprogram at levels 3 and 4 [25]. For machines with a small number of very powerful pro- cessors (such as the Cray X-MP) parallelism is mainly per- formed at the high levels (3,4, and 5) across the processors. However, within each processor, parallelism levels 1 and 2 are still practiced. For massively parallel machines (such as the MPP [6]) parallelism is mainly pushed at the lower levels. The general trend is pushing the granularity down. Concurrent scalar processing, vector processing, and mul- tiprocessing are often desired in a modern supercomputer, if one wishes to increase the application domains [32], [W].
HWANG: PARALLEL PROCESSING WITH SUPERCOMPUTERS
B. Performance Measures and Benchmarking
Supercomputer performance is often measured in terms of Mflops (millions of floating-point operations per second) or Mips (millions of instructions per second). The Mflops measurement reflects the number crunching capability of a computer often tied to 64- or 32-bit floating-point results. The measure of Mips indicates the instruction execution rateof acomputer includingthemixtureof arithmetic, logic, and program control instructions. The relationship between Mflops and Mips varies with different machines and dif- ferent program mix. In a typical supercomputer containing scalar, vector, and control instructions, 1 Mips implies any- where between 0.5 to 10 Mflops of performance. However, this is by no means universally true for all computers.
We often use a range to indicate the expected perfor- manceofasupercomputer.The real performanceforagiven application program often approaches the low end of the range, if the problem is not skillfully programmed with suf- ficient software support. The peak speed of a machine sets the absolute upper bound in performance. There is no such term as"average" performance, because it meansverylittle to average the performance of different application pro- grams. The performance and cost range of three classes of commercial supercomputers are given in Table 1. The full- scale supers are the most expensive class, represented by Cray, ETA, and Fujitsu systems, etc. The nearsupers are high- end mainframes such as the IBM 3090NF, CDC Cyberplus, the Univac 11OO/ISP series, etc. The minisupers are the low- cost parallel/vector computers represented by the Alliant and Convex systems, etc. The superminis do not qualify as supercomputers. We l ist them here only as a reference point. Note that minisupers tend to have much higher Mflops/Mips ratio than that of the superminis. According to today's standard, a machine i s qualified as a supercom- puter if it can perform O(l0') to @IO3) Mflops in typical sci- entific or engineering computations [107].
Understandingthe benchmarks isof fundamental impor-
1349

Table 1 Supercomputer Classes and Performance1Cost Ranges
Class Peak Performance cost Representative Systems
Full-scale 200 - 2400 Mflops $2M Cray 2, Cray X-MP, supercomputers > 500 Mips to NEC SX-11SX-2,
$25M Fujitsu VP 200, ETA-10, IBM GF-11
Near supers (high-end mainframes)
50 - 500 Mflops $1 M IBM 3090NF, Loral MPP, > 50 Mips to CDC Cyberplus, Univac 1194/ISP
$4M Connection Machine, BBN Butterfly Minisupercomputers 10 - 100 Mflops $lMK Alliant FW8, Convex C-1,
(minisupers) > 10 Mips to SCS-40, Elxsi 6400, $1.5M EncorelMultimax, iPSC,
FPS 164 Max, T-Series, Warp
Superminis e 0.5 Mflops $20K VAX 8600, IBM 4300, (not a class of <5 Mips to IBM 9370, VAXi780, supercomputers, $400K Pyramid listed as a reference point)
tance to measuring the performance of supercomputers. Only preliminary benchmark data from existing supercom- puters are becoming available now. The key problem is the use of benchmarks in assuring comparability. Benchmark- ing intends to indicate the relative performance of various machines under the same workload. By definition, a com- puter benchmark is a set of key programs or sections of key programs that are executed for timing purposes. The sub- sets of key programs, called kernels, often represent the most time-consuming portion of the major codes. Kernels must be converted to run on the target machines. Using the workload fractions as weights, multiple runs are timed and compared.The kernelsare real and tractableand thus often used as standard tests. However, kernels may be too simple to reveal the limitations of the target machines [99].
The Livermore kernels are often used in evaluating the performance of scientific computers. Important steps in using kernel benchmarks have been summarized in [141]. Besides using the kernels, Jack Dongarra of Argonne National Laboratoiy has been comparing the performance of about 100 different computers (ranging from supers to micros) using the standard linear system solver, LINPACK, in a Fortran environment [35]. The timing information that he releases from time to time reflects only the relative per- formance on one problem area. To judge the overall per- formance of a computer system, one should test both ker- nelsand specific application problems. Such benchmarking performance may change with respect to software and hardware changes. The OSkompiler used makes a subtle difference, even running on the same machine. Further dif- ferences can be found in the direct use of assembly lan- guage coding or the use of compiler directives.
C. Advanced Architectural Choices
Since supercomputers are mainly used to perform numerical computations in science and engineering, most are equipped with both scalar and vector hardware units that can operate in parallel. We classify the architecture of modern supercomputers into five categories based on their interconnect and operational structures, as summarized in Table 2. The key features of these architectural choices are characterized below.
1) Multipipelined Uniprocessors: Most vector supercom- puters start as a pipelined uniprocessor containing mul-
Table 2 An Architectural Taxonomy of Supercomputers
Architecture ReDresentative Svstems
Uniprocessors with Alliant FWl, IBM 3090, multiple functional CDC 7600, units and vector FPS 164/264/364, Convex hardware options C-1, Cray 1,
Cray X-MP11, Cyber 205, Amdahl500,1100,1200, 1400 (also Fujitsu VP-50, 100,200,400) Hitachi sa1 0 NEC SX-1, SX-2, SCS-40
SlMD processor arrays or Loral MPP, ICUDAP, FPS attached processors 164/MAX,
Connection Machine, IBM-GF11
Shared-memory Cray X-MP/2,4, Cray 2,
EncorelMultimax, Elxsi 6400, Sequent 8O00, Cray 3, IBM 30901400 VF, Univax 119411SP.
multiprocessor systems Alliant FW8
Distributed-memory iPSC, Ametek 14, NCUBE, multicomputers BBN Butterfly;
CDC Cyberplus, Culler PSC, FPS T-Series, Warp
Hierarchical or Cedar, ETA-10, IBM RP3, reconfigurable systems Remps
tiplefunctional units. The memory-to-memory architecture demands much wider memory bandwidth and longer instructions, which only favors the processing of long vec- tors. For short vectors or scalars, its performance could be very poor as experienced in Cyber 205. On the contrary, the register-to-register architecture performs much better with a scalar/vector mix. The Alliant FW1 uses a cache-based register-to-register architecture, which is a compromise between the two extremes. Multiple data streams can be executed by multiple functional pipelines simultaneously, even if there is only one instruction stream in the system [721 , 11 091.
2) SlMD Processor Arrays: These are parallel processors which operate synchronously in lockstep under the same control unit. Physically, theprocessingelements (PES) form
1350 PROCEEDINGS OF THE IEEE, VOL. 75, NO. IO, OCTOBER 1987

a processor array, such as the mesh architecture in llliac IV, Loral MPP and ICUDAP [60], or the hypercube architecture in the Connection Machine [58]. Since these machines are often used in processing large-scale arrays of data, they are also called array processors. The FPS 164/Max [I81 belongs to this class. Up-to-I5 Matrix Algebra Accelerators (MAX$ are attached to an FPS 164 and operate in an SlMD mode. Most SlMD array processors are special-purpose machines, applied mainly to signal and image processing [96].
3) Shared-Memory Multiprocessors: These are tightly coupled M lMD machines using shared memory among multiple processors. The interconnect architecture falls essentially into one of two classes: the bus connect and direct connect. Most minisupers choose the bus connect, in which multiple microprocessors, parallel memories, net- work interfaces, and device controllers are tied to the same contention bus [9]. For example, the Elxsi 6400 uses a high- speed &bit bus with a bandwidth of 320 Mbytesls [ lo l l , [119]. The direct connect architectures include crossbar, partially connected graphs, and multistage networks [22], [39]. Most high-cost supers and high-end mainframes use these direct interconnects [32].
4) Distributed-Memory Multicomputers: This class cor- responds to loosely coupled MlMD systems with distrib- uted local memories attached to multiple processor nodes. The popular interconnect topologies include the hyper- cube, ring, butterflyswitch, hypertrees, and hypernets. Mes- sage passing is the major communication method among the computing nodes in a multicomputer system. Most multicomputers are designed to be scalable. The BBN but- terfly switch is a multistage network [n, [22], by which pro- cessors can access each other’s local memories. The ring architecture requires less hardware. The hypernets [69] offer a compromise in hardware demand between hypertrees [52] and hypercubes [471, [54]. Communication efficiency and hardware connectivity are the major concerns in the choice of a cost-effective multicomputer architecture.
5) Hierarchical and Reconfigurable Supercomputers: These machines haveahybrid architecturecombining both shared memory and message passing for interprocessor communications. Several research multiprocessor systems belong to this category, such as the Cedar project [88] and the ETA-IO [36] system. Hierarchical memory system is built into the system. The approach is to apply macro dataflow at the level of processor clusters and still use control flow
.
within each processor. Therefore, parallelism is exploited at multiple levels, even with different computing models. The Remps [75] was proposed to have a hierarchical archi- tecture, specially designed for solving PDE problems. Other parallel PDE machines have been reviewed in [109].
Representative supercomputer and high-end main- frames are summarized in Table 3. Table 4 summarizes var- ious minisupercomputers. Key features being listed include the degreeofparallelism (number of processors in system), processor type, memory capacity, interconnect architec- ture, and peak performance of both classes of supercom- puters. Other recent architectural studies can be found in [331, WI, [641, [MI, [811, [1071, [1091.
II. PARALLEL LANGUAGES AND COMPILING TECHNIQUES
We address below languages and system software issues for parallel processing on supercomputers. First, we review the development of concurrent programming languages and their compilers. Vectorization and multitasking tech- niqueswill be reviewed. Finally,wediscussadvanced meth- ods in developing intelligent compilers for parallellvector computers.
A. Concurrent Programming Languages
To implement fast algorithms on supercomputers, we need a high-level programming language possessing the following features:
Flexibility. The language should make it easy for the programmer to specify various forms of parallelism in application programs. Efficiency.The language should be efficiently imple- mented on various parallellvector computer systems.
Three approaches have been practiced towards the solu- tion of this language problem, as illustrated in Fig. 3.
The Compiler Approach: Most existing application soft- ware packages are coded with sequential languages such as Fortran. Intelligent compilers are needed to detect par- allelism in sequential programs and to convert them into parallel machinecode, as illustrated in Fig. 3(a). Good exam- ples include the CFTcompiler used in Cray X-MP [26] and the KAP/205 compiler designed for Cyber-205 [63]. An advantage of this approach is that software assets accu- mulated in conventional sequential codes can be used on
Serial Constructs
Cyber 205
Multitasking Cray X-MP Constructs Multiprocessor
Extended C Concurrent Intel iPSC Constructs Multicomputer
(b)
Various Multicompu
(C)
Fig. 3. Three approaches to concurrent scalar/vector programing. (a) Smart compiler approach. (b) Language extension approach. (c) New language approach.
HWANG: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1351

Table 3 Supercomputers and High-End Mainframe Systems
System Architecture Max No. of Processor Max Memory Peak Remarks and Model Configuration' Processors' Type3 Capacity' Performance' References6
Custom ECL
16 MW in CM 128 MW in SSD
840 Mflops
2 Gflops
16 Gflops
400 Mflops
10 Gflops
533 Mflops
1.3 Gflops
840 Mflops
160 Mflops
480 Mflops
67 Mflops
65 Mflops and 620 Mips per processor
>lo00 Mips 250 Mflops
256 Mips
470 Mflops
20 Mflopd
11 Gflops proc.
800 Mflops 1300 Mips
3.2 Gflops
shared registers, [21,25] among 4 Processors
16 KWILMlproc. [26]
Cray X-MPl4
Cray 2
Cray 3
Cyber 205
ETA-1 0
Fujitsu VP-200
NCE SX-2
Hitachi sa10
HEP-1
IBM 30901 400NF
Univac . 119411SP x 2
CDC Cyberplus
Connection Machine
BBN Butterfly
Loral MPP
IBM GF 11
IBM RP3
Cedar
MP with SM and direct connect
MP with SM and direct connect
MP with SM
UP with scalar Proc. and 4 Vector pipes
MP with SM
UP with multiple pipelines
UP with 16 functional pipes
UP with multiple pipelines
MP with SM and switch network
M P with SM and direct connect
MP with SM and direct connect
MC with DM and ring connect
SlMD with DM hypercube embedded in a global mesh
MP with S M via butterfly switch network
SIMD 128 X 128 mesh with DM
SlMD with a reconfigurable Benes network
MP with SMlDM and fast network
hierarchical M P with SM
4 Proc.
4 Proc. 1 IOP
16 Proc.
1 Proc.
Custom ECL
GaAdECL
Custom CMOS
256 MW
2 cw 4 MW
under development
MM architecture [631, [981
256 mW under development [361
also Amdahl1200 PI, [I331
16 pipes divided into 4 identical sets
host scalar processor [99]
MlMD pipelining [791, M I , P25l
vector facility optional [51], [138]
ISP contains [129] vector hardware
a Proc. l a IOPS
1 Proc.
Custom
Custom ECL 32 MW
32 MW 1 Proc. Custom
1 Proc. Custom 32 MW
16 Proc. Custom 256 MW
4 Proc. Custom TCM
Custom
2 GB CM 16 TB EM
16 MW 4 Proc., 4 IOPs, 2 ISPS
512 KW per processor
up to 3 rings among processors [43]
64 Proc. Custom
available 1985 [SS] 6 4 K PES
VLSIKMOS Gate arrays
32 MBytes
available 1985 [7l 256 Proc.
M68020, custom coprocessor
CMOS/SOS a PES per chip
custom floating- point proc.
32-bit RlSC
1 2 8 ~ ~
128 MB available 1983 (bit slice PES) [6]
16 K PES
under development PI
2 MBlproc. 1.1 GB total
576 PES
under development [1131
under development, (prototype 32 nrocessors) [MI
512 Proc.
256 Proc.
128 MW
256 MW Alliant/FX clusters
1352 PROCEEDINGS OF THE IEEE, VOL. 75, NO. 10, OCTOBER 1987

Table 4 Minisupercomputers for ParallelNectorlMultiprocessing
System Architecture Max No. of Processor Max Memory Peak Remarks and Model Configuration’ Processors’ Type3 Capacity4 Performance’ References6
~~
Alliant FX/8
Elxsi 6400
Encore/ Multimax
Balance 21 ooo
Flexible/32
Convex c-1 XP
scs-40
iPSC-VX
Ametek S-14
NCUBHIO
FPS-T
FPS 164/ MAX
ICL-DAP
Culler-PSC
Warp
MP with SM and bus connect
M P with SM and bus connect
MP with SM and bus connect
MC with SM and vus connect
MC with DM and VME buses
UP with vector hardware
UP with multiple pipes
MC with DM and hypercube
MC with DM hypercube
MC with DM and hypercube
MC with DM and hypercube
SlMD array of 15 MAXs
SlMD lockstep array processor
MP with SM and bus connect
linear systolic arrav
E CEs, 12 IPS
12 proc.
20
30
20 per cabinet
4 proc. 5 lops
1
128 CNs
256
1024
4096
‘15 MAXs 1 proc.,
64 x 64 mesh
2 proc., 1 host
10
Gate array M68010
ECULSI Custom
NS32032
NS32020 /32081
NS32020, M68020
CMOSNLSI gate array
ECULSI
Intel 80286, 80287
80286 Intel
80287
custom VLSl
CMOS transputer
custom with Weitek MAXs
custom bit-slice
custom
custom
4 MW
192 MBytes
16 MW
48 MBytes
20 MW
16 MW
4 MW
4.5 MBytes per processor
32 MW
512 MBytes
1 MByte per node
16 MW
8 MBytes
12 MW
80 MW
94 Mflops, 35.6 Mips
156 Mips
35 Mips
2 Mflops 21 Mips
3.5 Mips per processor
20 Mflops 25.5 Mips
18 Mips, 44 Mflops
20 Mflops per processor
15 Mflops
500 Mflops 2000 Mips
16 Mflops and 7.5 Mips per processor
341 Mflops
16 Mflops
5 Mflops
100 Mflops
shared cache, RR architecture [l], [I351
[ lol l
P, 811
~ 3 2 1
[411
multiple I/O (Crayetts) [23], [81]
vector hardware Cray compatible [81]
multiple 110s and memory options [54]
[31
[1101
[561
newly named as FPS “145 [la]
ICL 2900 host [60]
[811
link to a host [41 _ _
’MP = Multiprocessor, MC = Multicomputer, SM = Shared Memory, DM = Distributed Memory (Local Memory), UP = Uniprocessor. *CE = Computational Elements, IP = Interactive Processor, IOP = I/O Processor, MAX = Matrix Algebra Accelerator, CN = Computer Nodes. ’TCM = Thermal Conduction Module, RlSC = Reduced Instruction Set Computer. ‘A word has 64 bits, CM = Central Memory, EM = Extended Memory, SSD = Solid State Device. ’Mflops = Million Floating-point Operations per Second (&bits precision), Mips = Million Instructions per Second. ‘RR = Register-to-Register, and MM = Memory-to-Memory.
parallel computers with only minor modifications. How- ever, the sequential language forces the programmer to code parallel algorithms in sequential form. A compiler can enhance the performance by only a limited factor, due to the difficulty in detecting parallelism in acomplex program mix.
The Language Extensions: Sequential languages can be extended with architecture-oriented constructs to support concurrent programming. Usually, only one type of par- allelism is supported in each extended language, as illus- trated in Fig. 3(b). For instance, Fortran has been augmented with service routines like EVWAIT, LOCKON, and TASK-
START in Cray X-MP to enable multitasking [25]. Concurrent C language has been extended from C for the Fled32 mul- ticomputer [41]. Other extensions include Vectran [I l l ] , Actus-2 [112], and Vector C [97] for supporting vector pro- cessing on pipeline or array processors. Because the exten- sionsare machine-oriented, they areoften efficientlyimple- mented. However, machine dependence implies poor portability. Users may haveto recode the parallel algorithm in another extended language, when the target machines are changed.
The New Languages: With this approach, new concur- rent languages are developed for supporting parallel pro-
HWANC: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1353

cessing. Quite a few concurrent languages have been pro- posed in recent years, including the Concurrent Pascal [55], Modula-2 [IN], Occam [W, Ada [31], VAL, and SlSAL [loo]. Unlikean extended language, these new languagescontain some application-oriented parallel constructs. However, each of these languages is usually designed to support one form of parallelism, a s illustrated in Fig. 3(c). It i s probably due to this reason that none of these new languages has been universally accepted in commercial supercomputers.
Comparing these three approaches, we observe an appli- cation barrier: On the one hand, parallel algorithms and supercomputers manifest a variety of computation modes. On the other hand, each of the proposed languages s u p ports only one or two computation modes. This barrier is the major source of inflexibility and inefficiency in using conventional sequential languages to code parallel algo- rithms on supercomputers. Various languages and com- pilers used in modern supercomputers are summarized in Table 5.
We are searching for an ideal programming language for parallelhector supercomputers. Such a high-level lan- guage should be easy to learn and flexible to apply in major scientificlengineering applications. The language should be architecture-independent. In other words, it would be used in various computation modes such as SIMD, MIMD, pipelining, and dataflow, etc. Such an ideal programming language may have to be developed with a combination of the above approaches; perhaps starting with a smart corn- piler, then adding some extensions to existing popular lan- guages and gradually moving towards the development of a new language as a long-term effort. Recently, a Parallel Programminglanguage (PAL) was proposed for supporting multimode concurrent parallel programming [143]. A new languageconstruct, called a molecule, is proposed there for the programmer to specify typedprocedures explicitly for various modes of parallel computation.
B. Vectorization and Migration Techniques
Many supercomputers are equipped with vector hard- ware pipelines. We describe below the keyconceptsof vec- torization and application migration methods associated with the effective utilization of vector facilities. Our objec- tives are to develop techniques for exploiting the vector facility, to derive methods of improving vector execution performance, and to look for vectorizable code. Amdahl‘s law states that the relative performance, P, of vector p r e cessing over scalar processing is a function of the vecto- rization ratio, f, and of the vector/scalarspeedup ratio, r, as plotted in Fig 4.
1 P =
(1 - f ) + f lr (1 )
The performance P is very sensitive to the variation of f, which indicates the percentage of code which is vectoriz- able. The speedup ratio r is primarily determined by hard- ware factors.
The term vectorization refers to the compiler’s role in analyzing user programs and producing object codes to execute on the vector hardware. The portion of the com- piler which carries out the vectorization is called a vec- torizer. Vectormigration refers to the process of modifying and adapting an application program in order to reveal i ts vector content and to improve i ts performance. This implies
* * a * // I * * * I /
* * a * y
* *
50% I
- 1 . .. 30%
I 2 3 4 5 6 7 8 9 1 0
Vector/Scalar Speed Ratio
Fig.4. Speedup performance of vector processing over scalar processing in IBM 309ONF.
that migrationwill assistthevectorizingcompiler inexploit- ing the vector hardware for that program. Hazards may occur in which an apparent lack of data independence may prevent vectorization in loops.
The basic unit of vectorization is the DOLoop. Dueto the size restriction of thevector registers, it is always necessary to split long vectors into segments, called sections. For example, Cray X-MP has section size 64 and IBM 3090l400 VF has 128 elements in a section (Fig. 5) [138]. Vectorizable loops must be first sectionized. Data independence in loops is a key factor in enabling the vectorization. A recurrence
chd CPU-3
Expanded Stomge
(Shared Memory)
CPU: Central Proceasom W : Vettor Facility
Fig. 5. The architecture of IBM 3090/Model400NF.
1354 PROCEEDINGS OF THE IEEE, VOL. 75, NO. 10, OCTOBER 1987
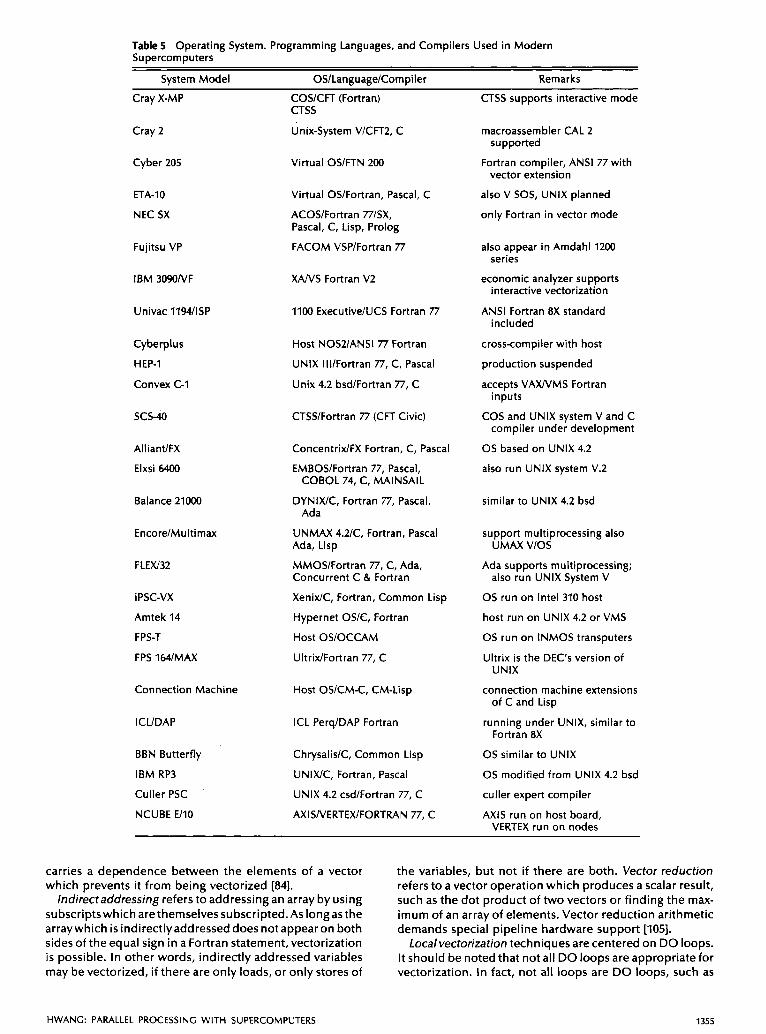
Table 5 Operating System. Programming Languages, and Compilers Used in Modern Supercomputers
System Model OSlLanguagelCompiler Remarks
Cray X-MP
Cray 2
Cyber 205
ETA-1 0
NEC SX
Fujitsu VP
IBM 3090NF
Univac 1194/ISP
Cyberplus
HEP-1
Convex C-1
SCS-40
Alliant/FX
Elxsi 6400
Balance 21000
Encore/Multimax
FLEW32
iPSC-VX
Amtek 14
FPS-T
FPS 1WMAX
Connection Machine
ICUDAP
BBN Butterfly
IBM RP3
Culler PSC
NCUBE U10
COS/CFT (Fortran) a s s Unix-System V/CFT2, C
Virtual OS/FTN 200
Virtual OS/Fortran, Pascal, C
ACOS/Fortran 77/SX, Pascal, C, Lisp, Prolog
FACOM VSPlFortran 77
X A N S Fortran V2
1100 Executive/UCS Fortran 77
Host NOSUANSI 77 Fortran
UNlX Ill/Fortran 77, C, Pascal
Unix 4.2 bsd/Fortran 77, C
CTSS/Fortran 77 (CFT Civic)
ConcentrixlFX Fortran, C, Pascal
EMBOYFortran 77, Pascal, COBOL 74, C, MAINSAIL
DYNIWC, Fortran 77, Pascal, Ada
UNMAX 4.UC, Fortran, Pascal Ada, Lisp
MMOSIFortran 77, C, Ada, Concurrent C L? Fortran
XenixlC, Fortran, Common Lisp
Hypernet O W , Fortran
Host OS/OCCAM
UltrixlFortran 77, C
Host OSICM-C, CM-Lisp
ICL PerqlDAP Fortran
ChrysalisK, Common Lisp
UNIWC, Fortran, Pascal
UNlX 4.2 csd/Fortran 77, C
AXISNERTEWFORTRAN 77, C
CTSS supports interactive mode
macroassembler CAL 2 supported
vector extension Fortran compiler, ANSI 77 with
also V SOS, UNlX planned
only Fortran in vector mode
also appear in Amdahl 1200 series
economic analyzer supports interactive vectorization
ANSI Fortran 8X standard included
cross-compiler with host
production suspended
accepts VAXNMS Fortran
COS and UNlX system V and C compiler under development
OS based on UNlX 4.2
also run UNlX system V.2
similar to UNlX 4.2 bsd
inputs
support multiprocessing also
Ada supports multiprocessing;
OS run on Intel 310 host
host run on UNlX 4.2 or VMS
OS run on INMOS transputers
Ultrix is the DEC’s version of
UMAX V/OS
also run UNlX System V
UNlX
connection machine extensions of C and Lisp
running under UNIX, similar to Fortran 8X
OS similar to UNlX
OS modified from UNlX 4.2 bsd
culler expert compiler
AXIS run on host board, VERTEX run on nodes
carries a dependence between the elements of a vector which prevents it from being vectorized [@I.
lndirectaddressing refers to addressing an array by using subscriptswhicharethemse1vessubscripted.Aslongasthe arraywhich is indirectlyaddressed does not appear on both sides of the equal sign in a Fortran statement, vectorization is possible. In other words, indirectly addressed variables may be vectorized, if there are only loads, or only stores of
the variables, but not if there are both. Vector reduction refers to avector operation which produces a scalar result, such as the dot product of two vectors or finding the max- imum of an array of elements. Vector reduction arithmetic demands special pipeline hardware support [105].
Localvectorization techniques are centered on DO loops. It should be noted that not all DO loops are appropriate for vectorization. In fact, not all loops are DO loops, such as
HWANG: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1355

a loop containing an IF statement. Some D O loops iterate too few times or have unknown iteration counts. These may not be worth the effort to vectorize. The stride of a vector is the addressing increment between successive elements. Stride1 addressing often results in better performance than addressing with longer strides. Therefore, stride minimi- zation is often practiced to enhance local vectorization. Reorganizing data may improve the stride distribution among nested D O loops.
Prolonging the innermost DO loop makes it more appro- priate for vectorization. Other local vectorization tech- niques include the use of temporary variables, linearized multidimensional subscripts and auxiliary subscripts, state- ment reordering, loop segmentation, simplifying sub- scripts, reverse unrolling, loop distribution, IF conversion, improving vector density, and the use of equivalence for longer vectors [128]. One should isolate nonvectorizable constructs, such as C A L L , recurrences, 110, relationals, and other hazards, in application programs [SI].
Globalvector migration requires the global restructuring of application programs. This is often more difficult than local vectorization. One global technique is to incorporate loops across several computation modules or subroutines. Another approach is to change the solution method. At present, most vectorizers can only perform local vectori- zation. Only exceptionally smart vectorizers can perform a limited global vector migration. Most of the global pro- gram restructuring operations are still done by skillful pro- grammers, perhaps through the help of an interactive vec- torizer, which allows the user to tune his programs as supported by the Fujitsu VP-200 compiler [133]. The IBM 3090NF system offers an economicanalyzer in itsVS Fortran compilerthat estimates the number of cycles (cost) needed to execute given sections of code, including the vectori- zation overhead. This analyzer helps users fine tune their programs with both local vectorization and global restruc- turing to enhance performance.
Multipipeline chaining as introduced in Cray X-MP sup- ports the fast execution of a sequence of vector operations [26]. On the other hand, systolic arrays offer multidimen- sional pipelines for direct execution of certain vectorized algorithms [92]. Recently, a dynamic systolic approach was proposed for fast execution of vector compound functions directly by pipeline nets 1751. These are advanced hardware facilities for supporting large-grain vector computations. The pipeline nets are more attractive than linear pipeline chains or static systolic arrays in the area of programma- bility and flexibility for general-purpose application. For example, it has been verified that the execution of most Liv- ermore loops can be speeded up greatly, if they run on reconfigurable pipeline nets. Pipeline nets are imple- mented with a programmable crossbar switch with.input buffers. We shall describe howtoconvert synchronous pro- gram graphs into pipeline nets in Section IV. To explore these advanced hardware features, even more intelligent compilers are needed. In fact, Japan’s national supercom- puter project emphasizes both advanced hardware and smart compilers [82].
C. Multiprocessing and Multitasking
Ultimately, wewant to use a supercomputer that can sup- port intrinsic multiprocessing at the process level. Such a tightlycoupled computer uses shared memoryamong mul-
tiple processors. The Denelcor HEP was designed as such an interactiveMIMD multiprocessor [79], [85], [86].The mar- keting of HEP was suspended due to the lack of multipro- cessing software. The main lesson learned from HEP is that fancy hardware alone is not enough to stretch for better performance. Multiprocessing at the process level must be supported by the following capabilities:
In
fast context switching among multiple processes res- ident in processors; multiple register sets to facilitate context switching; fast memory access with conflict free memory allo- cations; effective synchronization mechanism among multiple processors; software tools to achieve parallel processing and per- formance monitoring; system and application software for interactive users.
a multitasking environment, the tasks and data struc- ture of a job must be properly partitioned to allow parallel execution without conflict. However, the availabilityof pro- cessors, the orderof execution, and thecompletion of tasks are functions of the run-time conditions of the machine. Therefore, multitasking is nondeterministicwith respect to time. O n the other hand, tasks themselves must be deter- ministic with respect to results. To ensure successful mul- titasking, the user must precisely define and add the nec- essary communication and synchronization mechanisms and provide the protection of shared data in critical sec- tions. Critical sections, being accessed by only one task or one process at a time, may reside in shared memory, I/O files, subroutines, or other shared resources. One can use lockor unlock mechanisms to monitor the operation of crit- ical sections.
Reentrancy is a useful property for one copy of a program module to be used by more than one task in parallel. Non- reentrant code can be used only once during the lifetime of the program. Reentrant code, if residing in the critical section, can be used in a serial fashion, called seriallyreus- able code. Reentrant code, which is called many times by different tasks, must be assigned with local variables and control indicators stored in independent locations, each time the routine is called. Stack mechanism has been employed in X-MP to support reentrancy. The Cray X-MP has developed software support to realize multitasking at several levels as illustrated in Fig. 6.
Dataflowanalysis isoften performed to reveal parallelism contained in application programs. The major constraint of parallelism is the various forms of dependency as sum- marized in Fig. 7. The computational dependence is caused by either data dependence or control dependence. The nodes represent statements, processes, or even tasks. The arcsshowthedependencerelationshipamongthem..Either multiprocessing or multitasking will introduce overhead that increases overall execution time. To reduce overhead, parallelism should be exploited at the lowest level (fine granularity) possible. The storage dependence is caused by memory conflicts. Each task or process must use indepen- dent or protected storage areas to guarantee the shared data integrity. For multitasking, storage dependence is often caused by a data dependence between the iterations of a
13% PROCEEDINGS OF THE IEEE, VOL. 75, NO. 10, OCTOBER 1987

1. Multitasking at the job level E l p1*** 2. Multitasking at the job-step level
3. Multitasking at the program level
4. Multitasking at the loop level DO 1 Iz1.N czs OR VECTOR CODE)
Fig. 6. Four possible multitasking modes in aCrayX-MP/2,4 multiprocessor system. (Courtesy of Cray Research, Inc.)
loop. When the extent of a left-hand side array variable is less than the index range of the loop, such a storage depen- dence may occur.
Speedupfrom multitasking mayoccuronlywhen thetime saved in executing parallel tasks outweighs the overhead penalty. The overhead is very sensitive to the task granu- larity; it includes the initiation, management, and inter- action of tasks. These are often accomplished by adding additional code to the original code, as illustrated in Fig. 8. This program can benefit from multitasking, depending on
An aample pqram: DO 1 0 I = l , N
10 WRITE CONTMUE 'AI) (&) @ S, is flow dependent on Sl S, in anti-dependent on S, Ss b output dependent on SI Sa in flow dependent on Sa S, b flow dependent on Sl Data dependency graph
READ '4r) (Sl) B(r) = A(I) ( 4 A(r) = C(I) (S,)
Dependency Typa:
SS
Fig. 7. Dependency types among instructions in a typical program.
the execution time of the subroutine SUB(/) and the over- head introduced in service routines. Before one attempts toconvert a serial code into multitasked code, the expected performance should be predicted to ensure a net gain. Fac- tors affecting performance include task granularity, fre- quency o f calls, balanced partitioning o f work, and pro- gramming skill in the choice of the multitasking mechanisms [IA, [95].
The program in Fig. 8 is analyzed below to predict per- formance. This example is taken from the Cray Research multitasking guide [25]. The 100 loop has dependent iter- ationswhichcannotbeexecutedinparallel.The10loophas independent iterations, which is being attempted for mul- titasking. The execution time of the original program on one CPU consists of two parts:
TimeU - CPU) = Time(Seq) + Time(SUB)
= (0.04 + 0.96) * (20.83 s)
= 20.83 s
Consider a sequential code run on a uniprocessor (Cray X-MP/I). PROGRAM MAIN
DO1001 =1,50
DO101 =1,2 CALL SUB(J)
10 CONTINUE
100 CONTINUE
STOP END
The following multitasked code runs on a dual-processor system (Cray X-MP/Z): PROGRAM MAIN COMMON/MT/ISTART,IDONE,JOB CALL TSKSTART(IDTASK,T) SUBROUTINE T JOB = 1 COMMON/MT/ISTART,IDONE,JOB DO 100 I = 1,50 1 CALL EVWAIT(ISTART)
CALL EVPOST(ISTARl7 CALL EVCLEAR(1START) CALL SUB(1) IF (JOB.NE.l ) GO TO 2 CALL EVWAIT(ID0NE) CALL SUB(2) CALL EVCLEAR(ID0NE) CALL EVPOST(ID0NE)
100 CONTINUE GO TO 1 JOB = 2 2 RETURN CALL EVPOST(1START) END CALL TSKWAIT(1DTASK) STOP END
Fig. 8. Converting a sequential code intoa multitasked code on a CrayX-MP/2. (Courtesy of Cray Research, Inc.)
HWANC: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1357

where Time(SUB) accounts for the 96 percent of the time spent in subroutine SUB and Time (Seq) for4 percent spent on the remaining portion of the program. The total run time on 1 CPU is assumed to be 20.83 s. To execute the multi- tasked program on 2 CPUs requires
Time(2 - CPU) = Time(Seq) + 4 Time(SUB) + Overhead
(2)
because the subrouting SUB was equally divided between 2 CPUs. The overhead is calculated below with some approximation on the delays caused by workload imbal- ance and memory contention. The service routines, TSKSTART, TSKWAIT, EVPOST, EVCLEAR, EVWAIT, are used in Cray X-MP to establish the multitasking structure [25].
Overhead = TimeCTSKSTART)+ Time(TSKWAIT)+ 51 * Time(EVPOST)+ 50 * Time(EVCLEAR)+ 50 * Time(EVWAIT) + (workload imbalance delay)+ (memory contention delay)+
= 1500000 CP+ 1500 CP+ 51 * 1500 CP+ 50 * 200 CP+ 50 * 1500 CP+ (0.02 * 50 * 0.2 s)
= 0.216 s
where the CP (clock period) is equal to 9.5 ns. Therefore, Time (2 - CPU) = (0.4 * 20.83) + 4 * (0.96 * 20.83) + 0.216 = 11.05 s. We thus project the following speedup ra- tio:
Speedup = Time(1 - CPU) 20.83 Time(2 - CPU) 11.05
= - = 1.88. (3)
This speedup helps decide whether multitasking is worth- while. The actual speedup of this program as measured by Cray programmers was 1.86. This indicates that the above prediction is indeed very close.
Multitasking offers a speedup which is upper bounded by the number of processors in a system. Because vector processing offers a greater speedup potential over scalar processing (in Cray X-MP, vectorization offers a speedup in the range of 10 - 20), multitasking should not be employed at the expense of vectorization. In the case of short vector length, scalar processing may outperform vec- tor processing. In the case of small task size, vector pro- cessing (or even scalar processing) may outperform mul- titasking. Both scalar and vector codes may be multitasked, depending on the granularity and the overhead paid. For large-grain computations with reasonably low overhead (as in the above example), multitasking is appropriate and advantageous [20].
D. Intelligent Compiler and Directives
Both vectorization and multiprocessing need to be s u p ported by an intelligent compiler. Sofar, most Fortran com- pilers developed for supercomputers have some vectori- zation capability. Very few compilers have been fully developed to exploit parallelism for multiprocessing. What
we need isan intelligent compilerthat automatically detects the potential for vector and parallel processing in standard Fortran (or any other high-level language) code and gen- erates object code that uses the parallel and vector features of the hardware to full advantage. The compiler analyzes source code for data, control, and storage dependencies at the process, loop, and instruction levels. The goal is to gen- erate optimized code, which can be executed in concurrent scalar, vector, multitasked scalar, or rnultitasked vector pro- cessing modes. The optimization process is aimed at enhanced vectorization and concurrency exploitation.
Generally speaking, innermost DO loops should be vec- torized and the next outer loop should be multitasked. Nested DO loops and multidimensional array operations can thus run in multitasked vector mode. Other situations, like DO WHILE loops, can run in multitasked scalar mode. It is often very desirable to have an interactive compilerthat allows a programmer to tune his code in the optimization process. Such fine tuning can be conducted at a higher programming level (global), such as subroutines and tasks where optimization needs feedback information from the programmers. Such acompiler should providefacilitiesfor programmers to monitor and modify the code optimiza- tions. Messages and listings notify the user of conditions that affect optimization, and summarize the scope of opti- mization. Programmers then modify the optimization with inserted compiler directives [I].
Compiler’s directives are often very helpful in achieving better optimization on a global basis. The intelligence of most compilers is presently restricted to local optimization. In order to increase the degree of multiprocessing or mul- titasking, we use the compiler directives to achieve global or subglobal optimizations. The directive allows the pro- grammertooverridethecompilerwhereoptimizationdoes not enhance performance or may cause invalid results. For example,adirectivecan beadded tosuppressvectorization when the vector length is too short, and to suppress mul- titasking, if the overhead is too high.
Knuth has stated that less than 4 percent of a Fortran pro- gram generally accounts for more than half of its running time [83]. Certainly, DO loops play this role. The best per- formance results are often obtained by vectorizing and/or multitasking such loops. Loops containing data dependen- cies or recurrences may be inhibited from vectorization. Then the compiler should perform some loop transfor- mations to make the successive iterations multitaskable. This has been done in Cray X-MP as well as in Alliant FX- series multiprocessors [135]. The example shown in Fig. 9 illustrates how concurrent processing of a DO loop with data dependency can be achieved in an Alliant multipro- cessor with 3 processors (computation elements). The data dependencies are synchronized by a hardware concur- rency control bus across the processors, as shown in Fig. 10.
Compiler technology plays a crucial role in the perfor- mance of vector supercomputers. Most vectorizing com- pilersaredesigned for specific machines such as the FX/For- tran used in Alliant FW8. What we want to develop are retargetable vectorizers which require low software con- version costs, when switched among different machines [89], [90]. The compiler must be designed to exploit not only vectorization but also parallelism at higher levels.
Important optimization capabilities that should be built into an intelligent compiler include vectorization, concur-
1358 PROCEEDINGS OF THE IEEE, VOL. 75, NO. 10, OCTOBER 1987

Fig. 9. Parallel execution of a DO loop with data dependency on an Alliant FX system with three processors. (Courtesy of Alliant Computer Systems Corp.)
. . e . .
;Tyq Crceabu Switch
e . . . .
CE: Computational Elements; Concurrency IP: Interactive Proc- Control Bus SM: Shared Memory Modules;
Fig. 10. The architecture of Alliant FW8, a shared memory multiprocessor system.
rency, general, and directive optimizations. Conventional compilers can only support the general optimization. Vec- torizing compilers and multiprocessing compilers may be developed separately or jointly. The joint approach is more useful to general-purpose applications. However, its devel- opment i s much more involved. At present, the FWFortran Compiler [I] and the compiler developed for the Warp pro- cessor [4] at CMU have some limited extent of these com- bined capabilities. The Cray CFT compiler supports auto- matic vectorization and multitasking by adding those software initiation and synchronization routines [25], [131].
In real-world applications, many codes cannot be vec- torized or parallelized well. A trace scheduling compacting coupling technique has been developed by Fisher [44] for
exploiting scalar or randomly structurd parallelism. In fact, this new approach as been built into the Multiflow Trace computer series using a Very Long Instruction Word (VLIW) architecture. The method can break theconditional branch barrier by predicting the most likely execution path based on some heuristics or statistics gathered automatically by program profiling. With 1024-bit instructionwords,28oper- ations can be executed in parallel per each cycle. The trace- scheduling compiler exploits large amounts of fine-grain parallelism with the VLlW architecture. Initial benchmark data released with the Multiflow computer suggest acom- parable performance with that of IBM 3090/200 or Alliant FX/8 in running the same LINPACK program without resorting to vectorization. The capability of using a trace-
HWANC: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1359

scheduling compiler to optimize non-parallel code com- pensates exactly the weakness of vectorizing or rnulti-pro- cessing compilers.
Ill. NEW ARCHITECTURES AND CONCURRENCY CONTROL
This section deals with advanced architectures, resource management, and concurrency control techniques. These issues will greatly affect the degree of parallelism, the resource utilization rate, and thus the system throughput. Resource management includes the scheduling of multiple processors and functional units, memory allocation and access, and 110 activity control. Concurrency refers to the simultaneous execution of multiple software processes in a computer system. It combines vectorization and multi- tasking in a multiprocessing environment. Multiprocessing techniques address three critical issues: partitioning, scheduling, and synchronization [50]. Various concurrency control techniques will pave the way to developing advanced software tools for balanced parallel processing. We illustrate these advanced parallel processing tech- niques along with some innovative supercomputer archi- tectures introduced in recent years.
^ - I "3 I Unpack
A(7) B(7)
Exponent Compare
~~ ~
A(6) B(6) Scak Right
A(5) B(5)
Add Functions A(4) B(5)
A. Processor Scheduling and Activity Control
Parallel techniquesfor multiple processor scheduling and for concurrent activity control are presented below with three advanced system features: the MlMD pipelining, as introduced in HEP-1, the activitycontrol mechanism devel- oped in the Univac ISP system, the scoreboard approach in Cyberplus, and the lockstep mechanism in IBM CF-11. The HEP-1 was a tightly coupled multiprocessor consisting of sixteen processors and up to 128 memory modules that are interconnected via a pipelined packet switching network [125]. Parallelism is exploited at the process level within each processor. The system allows 50 user processes to be con- currently created in each processor. Fifty instruction streams are allowed per processor, with a maximum of 50 X 16 = 800 user instruction streams in the entire HEP system.
The pipelined HEP executes multiple instruction streams over multiple data streams. An example is shown in Fig. 11, while an add i s in progress for one process, a multiply can be executing for another, a divide for a third, a,nd a branch for a fourth. Instructions being executed concurrently are independent of each other. Thus fill-in parallelism increases processor utilization. Arbitrarily structured par-
Inst ction 0 .rids 3 T Stream 3 Instruction
Instruction Fetch Stream 2 Instruction
Omand Fetch Stream 1 Instruction
Execution Phase Stream 8 Instruction
Execution Phase
Stream 4 Instruction Result Store
MIMD Pipelie (b)
t (C)
Fig. 11. MlMD pipelining in HEP-1 multiprocessor system. (a) Conventional pipelining on uniprocessors.(b) Pipelining of instructionsfrom multiplestreams in a multiprocessor. (c) Mechanism to achieve MlMD pipelining in HEP-1.
1360 PROCEEDINGS OF THE IEEE, VOL. 75, NO. 10, OCTOBER 1987

allelism is applicable to codes that do not vectorize well. The concepts of packet-switched data forwarding [22] and of MlMD pipelining [78], [79] make HEP very attractive for solving PDE problems described by sparse matrices.
The architecture of Univac 1100/94/21SP is shown in Fig. 12 [129]. There are four central processors and four 110 pro- cessors in the mainframe 1100/94. Two IntegratedScientific Processors (ISP) are attached to form a near supercomputer,
Instruction P-
SPSUI
Interfaces-, LSP I LSP LSCIIEP] ILSP~~~LSP rspl rsp C 1 1 L I 1 1
I r 1 I I
&p Scientific ' P-n LBC
7' 1 I n k g r a d w 2 I
I
Fig. 12. The architecture of Univac 1100/94/ISP. (Courtesy of Sperry Corp.)
because each ISP isequipped with high-speed hardware for both scalar and vector arithmetic computations. Sixteen million words of main storage are shared by ten processors through multiple datapaths as shown in the schematic dia- gram. The major architectural advantage of this system lies in availability, reliability, and maintainability[l29]dueto i ts modular construction. What interests us here is the control of concurrent activities in the system. An activity is the unit of work scheduled for the ISP. Each activity is explicitly dis- patched by the 1100/94 system.
Three activity control mechanisms are used in an ISP: the mailbox, the status register, and the processor control box. The mailbox is used to convey information between 1100/94 system and the ISPs. Each ISP has a mailbox occu- pying eight words in the shared memory (the SPSU). When an activity is initiated, it contains a pointer to the processor control boxassigned for theactivity. Atactivitytermination, the mailbox is loaded with the contents of the hardware status register to report the termination status. The control box, also residing in the shared memory, contains infor- mation needed to process the activity. Another method is tousethescoreboardoriginallyusedintheCDC7600series, to match ready-to-run instructions with the available func- tional units in the processor.
Dynamic scheduling of concurrent processes depends on run-time conditions. Optimal solutions are impossible. However, there are many heuristics one can choose from, such as first-in-first-out, round-robin, shortest-process-first, or least-memory-demand-first, etc., [50], [65]. Static sched- uling is determined at compile time, which is easier to implement but potentially results in poor processor utili- zations. The trace scheduling [44] of loop-free code offers such an approach. The activity control mechanisms being presented have been practiced in many machines. Of course, data-driven and demand-driven mechanisms could be considered for dataflow [29] and reduction machines [13T], respectively. At present, these new mechanisms are still in the research domain.
The IBM GFl l is a modified SlMD computer conceived primarily for the numerical solution of problems in quan- tum chromodynamics [8]. The machine incorporates 576 floating-point processors, each with i ts own 2 Mbits of memory, and capable of 20 Mflops, giving the total machine over 1 Gbyte of memory and a peak processing speed of more than 11 Gflops. The floating-point processors are interconnected by a high-speed full Benes network, a non- blocking switch capable of realizing configurations incor- porating any permutation of the processors. Using this switch, GFl l can be organized into any of a number of dif- ferent topologies, such as the rectangular mesh of any dimension and size, any torus, a hexagonal mesh, or some irregular organization matching perfectly with a special problem. The central controller broadcasts instructions to all processors and theswitch and communicateswith a host computer.
B. lnterprocessor Communications Schemes
Processors form the major working force in a supercom- puter. Information items communicating among multiple processors include synchronization primitives, status sem- aphores, interrupt signals, variablesize messages, shared variables, and datavalues. lnterprocessor communications
Table 6 Interprocessor Communication Schemes in Modern Supercomputers
Hardware System Supporting Communication Model Structures Mechanisms
Cray X-MP
ETA-10
HEP-1
iPSC
Cyberplus
Multimax
Alliant FW8
Connection Machine
Boltzmann Machine
BBN Butterfly
IBM RP3
IBM GFll
FLEW32
Elxsi 6400
FPS-T
shared memory, shared register clusters
communication buffer, shared memory,
shared memory
hypercube interconnect
multiple rings
common budshared memory
bus, concurrency control
shared cache/rnemory
hypercubdmesh connections
AI machine using virtual connections
butterfuly switching
multistage network
network
SlMD network
multiple bus and shared memory
bus and shared memory
hypercubeltransputer
semaphore and shared variables
shared variables and synchronization funaions
tagged variables
message passing
message passing (packet switched)
data transfer via bus
(packet switched)
synchronization vis special bus
makedmessage
value passing
passing
shared variables in distributed memory
shared variables and message passing
SlMD broadcasting
message passing
message passing
OCCAM channel commands
HWANG: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1361

are achieved essentially by four methods: shared variables, message passing, marker passing, and value passing. These methods are implemented with shared memory, shared registers, communication buffers, concurrency control or interrupt buses, interprocessor connection rings, or net- works as summarized in Table 6. Various interconnection networks for parallel processing have been summarized in
Sharedvariables are often stored in thecommon memory shared by many processors. Many tightly coupled multi- processors use shared memory as a major means of com- munication among processors such as used in Cray Series and in the Encore/Multimax multiprocessor [9]. Besides using shared central memory, the ETA-10 also uses a com- munication buffer for fast transfer of information among central processors and 110 processors, as illustrated in Fig. 13 [36]. Tagged shared variables are used for synchronizing
~91,[1241.
concurrent processes in HEP [125]. The Cray X-MP, using shared memory for large data movement between proces- sors, also uses clusters of shared registers for direct com- munications of semaphores or status information among processors, as illustrated in Fig. 14. Synchronization, if not properly handled, may become a major barrier to parallel processing [5].
For an n-processor X-MP, the shared registers can be clus- tered inton + 1 nondisjointclustersof processors[21]. Each cluster has eight 24-bit shared addresses, eight W b i t shared scalars, and 32 I-bit semaphore registers. These shared reg- isters allow direct passing of scalar data, and semaphores among 2,3, or 4 processors per cluster. There are 4 ports to each cluster for the 4 CPUs in the X-MP/4 system. The COS operating system dynamically allocates the clusters to CPUs. An allocated cluster may be accessed by the CPU in either user mode or supervisor mode. Note that any num-
U . Register File (256 x 64 bits)
. .
I I Shred Mang ( m y be up to 2 billion bytes)
Fig. 13. The architecture of ETA-10 and its memory hierarchy. (a) System components. (b) Memory hierarchy. (Courtesy of ETA Systems.)
1362 PROCEEDINGS OF THE IEEE, VOL. 75, NO. 10, OCTOBER 1987

Shared Register Clustera
El3 CLUSTER
#! CLUSTER
E B CLUSTER
El3 CLUSTER
2 3
0 1 2 3
0 1 2 3
0 1 2 3
0 1 2 3 Porta with the same numbers
can be connected dynamically under system control.
Fig. 14. Clustering of shared registers for inter-CPU com- munication in the Cray X-MPI4.
ber of processors (2, 3, or 4) can be clustered together to perform multiple tasks of a single job. Such a dynamic mul- titasking is the key improvement of X-MP over Cray 1.
Message passing is popular among loosely coupled, dis- tributed-memory multicomputers, such as the Hypercube- structured iPSC [54], FPS T-Series [56], Ametek [3], NCUBE [IIO], and the ring-structured Cyberplus [43]. The passing of messages of arbitrary sizes and performing of complex operations on these messages demand quite powerful node processors. The hypercube topology has the advantage of being uniformly structured with log, N diameter. However, for a very large number of processor-memory nodes (N), the contention and traffic congestion problems may intro- duce appreciable communication overhead among the nodes. The CDC Cyberplus chooses a less costly multi-ring structure for packet-switched message passing among the processors, as illustrated in Fig. 15.
Fig. 15. Interprocessor communication structure in the CDC Cyberplus parallel processing system.
The Cyberplus ring structure differs from the bus struc- ture as in Multimax [9], Elxsi 6400 [IOI], and Balance 21000 [132], in that the ring carries 2n data packets simultaneously in the ring which links n processors. The traditional system bus can carry only one data element at a time. The config- uration consists of a maximum of four ring groups with 16 Cyberplus processors (accelerators) per group [43]. Each group has two rings: the 16-bit system ring provides com- munications between the Cyberplus processors and the host Cyber processor, say a CDC Cyber 1801990, and the 16- bitapplicationringprovidesdirectcommunicationsamong the Cyberplus processors themselves.
Each Cyberplus processor has fourteen functional units for memory accesses and integer operations plus an optional five floating-point units. The nineteen functional units can operate in parallel under the coordination of a scoreboard which helps set the crossbar to direct the flow of data among the functional units and initiate the simul- taneous operation of all of the functional units every machine cycle of 21 ns. This implies that each Cyberplus processor can potentially perform 620 Mips and up to 98 Mflops.
Besides the dual rings, an additional memory ring can be added to provide direct memory-to-memory communica- tions between local memories attached to the Cyberplus processors and the host Cyber processor. Sustained data transfer rates of 100 to 800 Mbytesk are built into the sys- tem. This multi-ring scheme offers direct processor-to-pro- cessor and direct memory-to-memory communications, which is highlydesirable in parallel and array processor sys- tems. In Alliant FW8 (Fig. IO), the concurrency control bus is used for synchronizing activities in different processors [I]. This idea was also previously used as an interrupt bus among the PDP-11 processors in the C.mmp project [142].
In a markerpassing system, the communication among processing cells (often with RlSC or bit-slice structures) i s done by passing single-bit markers [37 . Each processing cell can handlea few marker bits with simple Boolean oper- ations. These cells are connected by a hypercube as in the Connection Machine [58], in which all cells operate in lock- step synchronously under one external control. The mark- ers in a collection represent entities with a common prop- erty and are identified in a single broadcast, thus syn- chronization can be avoided. Value passing systems pass around continuous numbers and perform simple arith- metic operations on these values. Multiple values arriving at a processor simultaneously are combined into a single value, hence contention will not happen and synchroni- zation is unnecessary. Neural networks and Boltzmann machines have been proposed to use this scheme. The marker passing and value passing are mainly used in Al-ori- ented processing [70].
C. Memory Hierarchy and Access Methods
Supercomputers, besides being faster in speed, must have large physical memory space. The early supers, like Cray 1, used only physical memory in batch-processing mode. Most second-generation supers and minisupers are adapting UNlX in interactive mode, which implies that vir- tual memory becomes necessary besides using central memory. Memory hierarchy, allocation schemes, and accessing methods in ETA-IO [36], Cedar [MI, IBM RP3, and OMP [71], [I131 are investigated below. The memory struc-
HWANC: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1363
ture in these systems represents state-of-the-art approaches to establishing efficient physical memory and extremely large virtual space for the next generation of supercom- puters.
The ETA-10 system is a shared-memory multiprocessor supercomputer, extended from the Cyber 205, which is a multi-pipelined uniprocessor system [98]. The architecture of ETA-IO is shown in Fig. 13(a). The system, consisting of eight central processors and up to 18 110 processors under the coordination of a service processor, is targeted to have a peak performance of 10 Gflops. All 27 processors have access to the large shared memory and the communication buffer. The memory hierarchy is shown in Fig. 13(b). Essen- tially, there are four levels of memory. The large register file is managed bythecompilers running on ETA-1O.Thecentral processor memory is local to each CPU. The shared mem- ory (256 M words or 2 Gbytes) sets the limit of the physical space for active files. The disk storage, which is so large that it contains trillions of bytes, is controlled by the 110 units. Virtual memory space consists of 238 M logical addresses. All user programs and a large portion of the ETA-10 system
code run in this space. The communication buffer, acting as a mechanism for interprocessor communications, is not adirect part of thevirtual memory support system. Instead, it provides fast locking and synchronizing functions.
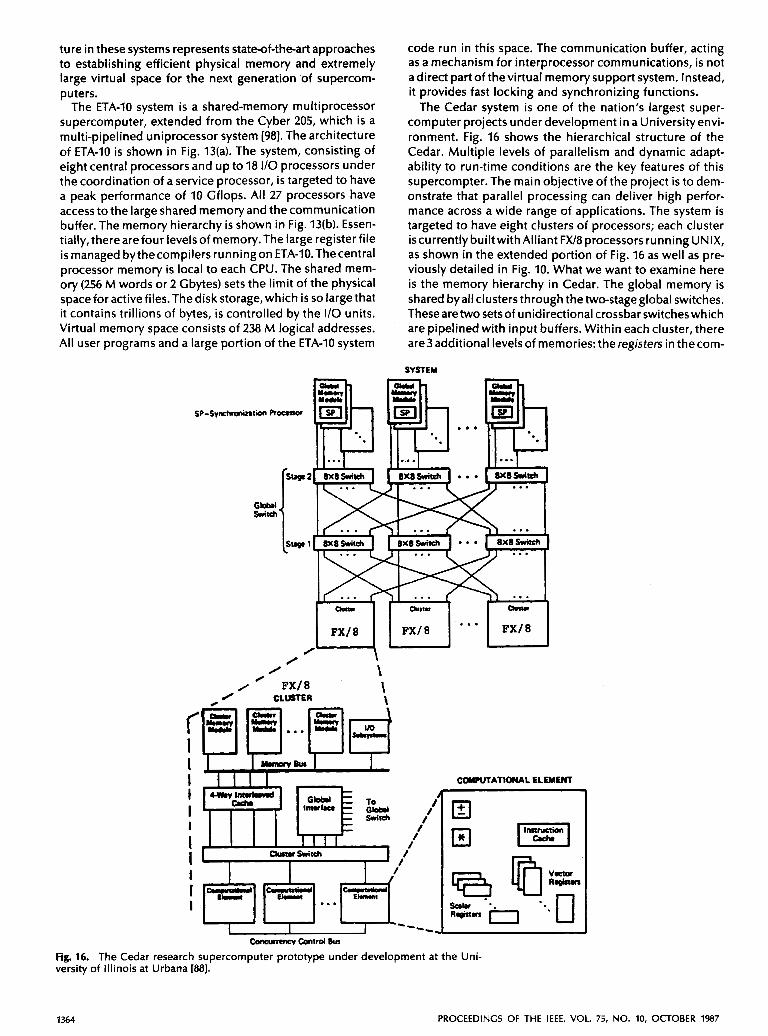
The Cedar system is one of the nation’s largest super- computer projects under development in a Universityenvi- ronment. Fig. 16 shows the hierarchical structure of the Cedar. Multiple levels of parallelism and dynamic adapt- ability to run-time conditions are the key features of this supercompter. The main objective of the project is to dem- onstrate that parallel processing can deliver high perfor- mance across a wide range of applications. The system is targeted to have eight clusters of processors; each cluster iscurrentlybuiltwithAlliantFX/8processorsrunningUNIX, as shown in the extended portion of Fig. 16 as well as pre- viously detailed in Fig. 10. What we want to examine here is the memory hierarchy in Cedar. The global memory is shared by all clusters through the two-stage global switches. Thesearetwosetsof unidirectional crossbar switcheswhich are pipelined with input buffers. Within each cluster, there are3additional levels of memories: the registers in thecom-
SYSTEM
FX/ 8 FX/ 0 FX/ 8
CQlMATlONAL ELEMENT
Camcunmc* b n t r o l &n
Fig. 16. The Cedar research supercomputer prototype under development at the Uni- versity of Illinois at Urbana [MI.
1364 PROCEEDINGS OF THE IEEE, VOL 75, NO. 10, OCTOBER 1987

putational element, the interleaved caches, and the cluster memories.
Communications among four levels are done through the cluster switch, the cluster memory bus, and the inter- cluster global switches.Thegloba1 memory is used for inter- cluster shared data and synchronization, for streaming long- vector access and as a fast backup memory for cluster mem- ory. Besides the standard FW8 hardware, the extra hardware developed at the University of Illinois includes the global interface within each cluster, the global switch, and the global memory. It would be interesting to watch the avail- ability of performance data, once the prototype enters the test run stage. An interactive supercompiler is under devel- opment, which emphasizes greatly the program restruc- turing concept that has been pushed by Kuck and asso- ciates for many years [W]. The target applications include the simulation of aerodynamic flows, dynamic structural analysis, oil explorations, etc.
The Research Parallel Processing Prototype (RP3) is being undertaken by the IBM Watson Research Center [I131 in conjunction with the NYU Ultracomputer Project [53], [121]. This experimental project aims at investigating the hard- ware and software aspects of highly parallel computations. The RP3 is an M lMD system consisting of 512 state-of-the- art 32-bit microprocessors with an RlSC architecture and a fast interconnection network (Fig. 17). The full configura- tion will provide up to 1300 Mips or 800 Mflops. The system will run on a modified version of BSD 4.2 UNlX operating system. The RP3 can be configured as a shared-memory sys-
n
Interconnection
Network
local 0 addreas
N
Node 0
Node 1
. . . - Node 511 U u
global A sequential/locd memory memory
(b) Fig. 17. The IBM RP-3 architecture and dynamic memory allocation between local and global memories. (a) RP-3 with 64 * 8 = 512 processors. (b) Dynamic memory allocation.
tem, as a message-passing system with localized memories, or as mixtures of these two paradigms. Furthermore, the system can be partitioned into completely independent submachines by controlling the degree of memory inter- leaving.
Fig. 17(b) shows how the global address space is distrib- uted across the processors. Part of each local memory is allocated to form the global memory. True local memory is accessed via the cache without going through the inter- connection network. The dynamic partitioning of memory is determined at run time. Moving the locallglobal bound- ary to the far right makes RP3 a pure shared-memory machine like the Ultracomputer. Moving it to the far left makes it a pure local-memory multicomputer using mes- sage passing. Intermediate boundary positions provide a mixed mode of computation. The architecture allows shared-memory-oriented applications to allocate private data locally to improve efficiency, while message-oriented applications use the global memory to balance the work load. A hot spot is said to occur at a memory module if it receives more than the average number of memory ref- erences from the processors. Hot spots are expected to occur, typically at shared-memory locations which contain synchronization mechanisms, shared data, common queues, etc., [108].
Recently, a new MlMD multiprocessor architecture has been proposed independently by two research groups [73], [123]. We call the architecture an Orthogonal Multiproces- sor (OMP) as shown in Fig. 18. An OMP consists of n pro-
Fig. 18. The orthogonal multiprocessor (OMP) architec- ture for n = 4 processors (RB = Row Bus, CB = Column Bus) r711.
cessors and n2 memory modules connected with n column buses and n row buses. OMP is considered a partially shared-memory multiprocessor. Memory module Mii is shared byonlytwo processorsP,and P,. Each ofthediagonal modules serves as a local memory, i.e., Mii is accessible only by P,. The organization enbles parallel access of row mem-
HWANC: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1365

ories or of column memories by all processors simulta- neously. A bus controller coordinates the switching between the row buses (RBi ) and the column buses (CBi) for the processors to access the memories orthogonally. This is particularlyattractive in implementing many parallel algorithms, which have the orthogonal memory access pat- terns, such as often found in matrix arithmetic, signal and image processing, linear programming, and solution of PDE problems. Detailed applications of the OMP for parallel processing can be found in [71].
D. IIO Multiprocessing and Front End
Many supercomputing tasks are 110 bound, especially those in a real-time environment. High-speed CPU oper- ations alone cannot solve such I/O-bound problems effi- ciently. We choose the 110 architectures in Cray 2, ETA-IO, Convex C-I, and Alliant FW8 to discuss how parallel pro- cessingcan beapplied to solve the 110 bottleneck problem. Of course, many I/O problems can be greatlyalleviated with the use of large central memory as described in Section III- C. What we wish to achieve is to transform I/O-bound prob- lems into CPU-bound problems with the practice of con- current 110 operations.
In Cray 2 [26], a foreground processor is used to handle all OS and 110 f.unctions. Four QGbit communication chan- nels are used to connect the foreground processor to four background processors, peripheral controllers, and com- mon memory, as shown in Fig. 19. Data traffic travels directly
(256 Mworda) Common Memory
I I I I
Foreground Processor
Fig. 19. The architecture of Cray 2 with four background processors for parallel computations under the supervision of a foreground processor which handles OS and I10 func- tions.
between the controllers and the common memory of 256 Mwords. This I 10 section greatly alleviates the communi- cation bottleneck with the outside world. Cray 2 uses an interactive OS based on the UNlX System V. Forty periph- eral devices can be attached to these high-speed 110 chan- nels. In ETA-IO, 18 110 processors are used to perform con- current I/O operations as described in Fig. 13(a).
In Alliant FX18 (Fig. IO), 12 interactive processors (IPS) are used to offload the computational complex by executing
interactive user jobs, 110, and other OS activities in parallel. Each IP is built around a Motorola 68012 microprocessor on a Multibus card. The IP interfaces with the IP cache which provides access to global memory and to I/O devices via the Multibus. A Multibus DMA device can transfer data at 1.96 Mbitsls. High system I/O throughput is achieved with mul- tiple IPS. Each IP can sustain a bandwidth of 3.92 Mbitsls to i ts associated cache.
The 110 subsystem in Convex C-I is shown in the right side of Fig. 20. Five intelligent channelcontrol units (CCUs) are attached to a high-speed bus. Each CCU is an auton- omous 110 processor with its own local memory and cache. OSfunctionsaredistributed between thecentral processor and the CCUs. Interrupts and device driver routines are executed bytheCCUs.TheMultibus I/Oprocessorcan s u p port up to 18 controllers for a total of up to 80 device con- trollers. The high-speed parallel interface taps the user with an 80-Mbit/s 110 bandwidth. The service processor unit (5PU)controlsdiagnostic program execution, initializesthe CPU's functional units, and handles the OS functions.
The I/O architectures in the above systems indicate a clear trend in demanding higher 110 bandwidth in modern supercomputers. To match with the high I10 data transfer rate, the I/O processors must use high-speed cache (such as in C-I and FW8) or a communication buffer (as in ETA-IO and Cray 2). These buffer memories form a staged memory system all the way from device controllers to the central memory. Concurrent I/O processing dem'ands the use of a large number of I10 processors or communication chan- nels. The front end is often used to support OS and I/O operations and to coordinate the operations between the CPUs and the I10 subsystem.
f. Process Migration and Load Balancing
In practice, it is often true that the number of processes in a parallel computer exceeds the number of processors available. In dynamic load balancing, processes are allo- cated to processors at run time. Processes automatically migrate from heavily loaded processors to lightly loaded ones. By attaining awell-balanced load, we can achieve bet- ter processor utilization and thus higher performance. In a static load balancing method, processes are allocated to processors at compile time. Such static techniques require fairly accurate compile time predictions of the resource uti- lization of each process. For programs with unpredictable run-time resource utilization, dynamic load balancing is more desirable because it allows the system to continu- ously adapt to rapidly changing run-time conditions [104], [106].
Three dynamic load balancing methods are evaluated below byexperimentingon al6-node iPSC hypercube mul- ticomputer. Impacts on performance are demonstrated with respect to machine size, computational grain sizes, and threshold levels used in load balancing. Popular mea- sures of load in a multiprocessor or multicomputer system include the CPU time, communication time, memory uti- lization, the number of concurrent processes, and even the rate of page faults. These load balancing results were orig- inally presented in [671 for a multicomputer environment. The method, after minor modifications, can be also applied in hierarchically structured supercomputers.
1) Receiver-Initiated Load Balancing: This load balancing
1366 PROCEEDINGS OF THE IEEE, VOL. 75, NO. 10, OCTOBER 1987

0 1 I I U "
Iw
Fig. 20. The architecture of Convex C-1 with multiple functional units in CPU, five 110 processors, and a host processor. (Courtesy of Convex Computer Corp.).
method is initiated by the receiving processor using a draft- ing approach. Each receiving node sends requests forwork and exchanges load information only with neighboring processors. A process can migrate only once to void the possibility of circulating processes. The local and external loads can be in one of three states: H-load, N-load, and L- load. An H-load node is a candidate for migration pro- cesses. An N-load node does not participate in load bal- ancing. An L-load node requests work from H-load nodes in i ts neighborhood using a draffingprofoco/[106], such as using a draft age which is determined by the number of active processes handled by the processor. The drafting node will request a process from the node with the highest draft age among those responding. This is a very conserv- ative policy, where migration takes placeonlyafter alengthy drafting protocol.
2) Sender-lnitiafed Load Balancing: This method is based on a gradient approach, in which the roles of the idle and busy processors are reversed, so that the busy processors initiate the load balancing. The system exerts some control over the behaviors of the nodes by setting the neighbor- hood diameter and a static system-wide threshold T. The threshold serves dual purposes: First, a node will begin exporting processes only when its local load exceeds the threshold. Secondly, the threshold determines the load information propagated by the node in a lightly loaded sys-
tem. The sender-initiated method has the advantage of immediately beginning process migration as soon as a node enters a heavily loaded state. There is no necessity to wait for lightly loaded nodes to engage in a lengthy protocol before migration begins.
3) Hybrid Load Balancing: The receiver-initiated method acts in favor of heavily loaded systems, in which the net- work traffic can be minimized by restricting to, at most, one migration per process. The sender-initiated method is in favor of lightly loaded systems in which the load balancing process converges much faster. The hybrid method uses the receiver-initiated drafting when the system load becomes excessive and the sender-initiated scheme when the system load is light. Intuitively, this hybrid method will result in better balanced loads among the node processors. This is verified below by experimenting the scheme on the iPSC.
The hybrid method requires a distributed mechanism to manage the switching between sender-initiated and receiver-initiated modes of operation. Each node operates in either sender-initiated or receiver-initiated mode de- pending on i ts local environment. All nodes are initialized to sender-initiated mode. A nodewill switch to receiver-ini- tiated mode when more than a threshold number of its neighbors become heavily loaded. We refer to this thresh- old as the hybrid threshold H, to distinguish it from the
HWANG: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1367

threshold value T, that defines low and heavy load. If the number of heavily loaded neighbors falls below the hybrid threshold, the node switches back to the sender-initiated mode.
A parallel computer is scalable if i ts performance increases linearly with a corresponding increase in the number of processors. Fig. 2?(a) shows the scalability of an iPSC hypercube with four to sixteen processor nodes. The best performance is obtained under the hybrid load bal- ancing. The low performance of the receiver-initiated method is attributed to the high overhead incurred during system initialization. Process migration must wait for load information from busy processors before they can begin drafting. During initialization, only the root node is doing useful work. The drafting method should be reserved for the most heavily loaded stages of the computation. The sender-initiated method workswellduringtheinitial stages of computation when the load is light. This method tends to produce excessive process migration. The ability of the hybrid method to switch to the less expensive receiver-ini- tiated method accounts for its better performance.
In Fig. 21(b), the performance curve for the hybrid method is monotonically decreasing. At smaller grain sizes, process
SPeedoP 16
I : : : < : : : : : : : * : : : , ;I
migration is likely to occur more rapidly as the system reaches heavy load. The receiver-initiated method is then used to control the amount of migration and the overhead. At larger grain sizes, this advantage is lost and the perfor- mance of the hybrid method approaches that of the sender- initiated method. The sender-initiated method has a per- formancepeakaroundthegrain size50.At largergrain sizes there is less parallelism available and hence a consequent drop in performance. The receiver-initiated method has an essentially flat curve.
The basic function of the thresholdlevelis to divide nodes into busy and idle classes. A node with local load below the threshold is idle, above the threshold it is busy. The system- wide threshold level determines when load balancing will be activated. In Fig. 21(c), a wide range of performance val- ues is displayed for the hybrid method under different threshold values. If the threshold is set too low, load values are artificially high and the switch from sender-initiated to receiver-initiated method takes place too soon. Process propagation is cut off with consequent loss of parallelism and performance. The performance falloff at higher thresh- old levels occurs because nodes appear idle when they are in fact supporting heavy computation. In all three methods,
t : : : : - : : : : ,
A = Hybrid Method
0 = Receiver-Initiated = Senda-hitiakd
1°A 0 5 3 e = = - - - - - - . I I I I I , , , ,
0 2 4 6 8 10 12 14 16 18 20 h h o l d L m l
(C)
Fig. 21. TheeffectofthreeloadbalancingmethodsontheperformanceoftheiPSChyper- cubewith16nodes[67].(a)Theeffeaofmachinesize.(b)Theeffectofprocessgranularity. (c) The effect of threshold levels used in trigger load balancing [67].
15
1368 PROCEEDINGS OF THE IEEE, VOL. 75, NO. 10, OCTOBER 1987

the drafting method shows a very poor performance and the hybrid method demonstrates i ts power in averaging the load among multiple processors [67].
IV. PROGRAMMING AND APPLICATION SOFTWARE
We address next the issues related to the creation of a parallel programming environment for supercomputers. An ideal programming environment is outlined, in which the users are aided with system tools and visual aids for program trace, resource mapping, and analysis of data structures. Then we examine various techniques needed to enhance concurrent programming and thus system per- formance. These include algorithm design, granularity tradeoffs, load balancing, resource sharing, deadlock avoidance, synchronization schemes, asynchronous par- allelization, 110 behavior, memory contention, miscella- neous OS services, and software conversion considera- tions. Finally, we elaborate on multi-discipline interactions towards the development of efficient software packages in key application areas.
A. User-Friendly Programming Environments
The advent of multiprocessor or multicomputer systems poses new problems for the software designers. Three problems stand out as crucial for optimizing performance of parallel algorithms. They are memory contention, prob- lem decomposition, and interprocessor communication. Contention refers to the attempt to simultaneously access memory by different processes. Problem decomposition refers to the problem of allocating code to the various pro- cessors. lnterprocessor communication refers to the mes- sages that must be sent between processors to coordinate their operation [5]. We describe below several methods to establish a programming environment that aids in the solu- tion of these problems.
A programming environment is a collection of software tools that can be used to develop software. Well-known programming environments are UNlX & C, Interlisp, and Smalltalk. With the advent of parallel architectures new issues in programming environment design arise. Thereare three key issues that must be adequately addressed. The first is, what information is going to be collected. The sec- ond is, how is the information recorded and displayed. The third is what mechanisms should be provided to alter exe- cution. One must be able to monitor the performance of all functional units of the system. For many systems, a fixed processor topology is used such as a ring, mesh, cube, cu be connected cycles, hypercube, etc. For these systems, prob- lem decomposition to fit the network is essential. For other systems, e.g., Cedar and RP3, it is possible to dynamically reconfigure the processors in different ways. In this latter case, problem decomposition is enhanced by the ability to reconfigure processor interconnectivity.
To help determine what should be displayed and acces- sible with respect to the executing software, is to include on the screen all of the traditional views of a program. A system such as PECAN presents on the screen: the program listing, data type schema, parse tree, symbol table, flow graph, execution stack, and input-output dialog. The abil- ity to instantly view and access all of this information sub- stantially improves the programmer’s ability to understand what is going on with his program.
For multiprocessor systems the problem of data collec- tion is exacerbated by the volume of material that may be produced during an execution. The traditional “table-of- numbers” can easily swamp any person’s ability to deter- mine performance factors. One approach to solving this problem is the display of data using graphical techniques. The second part of the data display problem is the sheer volume of material. It is impossible to view all these data in real time nor is itdesirableto run testcases multipletimes. Thus we need a new medium that can store large volumes of data and have them displayed in a graphical form.
The goal is to design and construct a programming envi- ronment that would be used by creators of parallel algo- rithms. The hardware would consist of a supercomputer coupled to a high-resolution, color display, a mouse, key- board, videodisk recorder, and player. The software con- tains support for color graphics monitor plus associated windowing software. There must be software for manip- ulating the videodisk, both for recording and playback. All of these components would be obtained from current industrial sources. An ideal programming environment should be user-friendly. Listed below are the desired run- time software supports in order to create such an environ- ment.
l twi l l display a map of the multiprocessor architecture that is available. Elements of the map can be examined separately using a zoom-in feature. For each functional element it will display an instan- taneous picture of i ts activity. For each processor one can see i ts waivactive states, access to memory, and 110 activity. Each processor can indicate the code segment that is executing. Identical code segments are identified by color. It will permit the tracking of memory accesses, whether there is local memory or shared memory or both. Collection of graphical data in the form of video images are stored on disk. Videodisk segments can be ref- erenced, examined, and played back. Statistical routines are available for analysis of the dig- ital form of the data. The program can be edited, recompiled, and re-executed in the environment.
Given such a visual programming environment, we expect a balancedsystem where all processors appear to be active. Queues for memory access are nonempty and input and output processors are active. An unbalanced system is immediately perceived as one or more processors are idle and memoryaccesses are wasted. Another information fac- tor is the rate of transfer of the external media. These may not be capable of sustaining the rate required by the pro- cessors. This should be visible in the environment. Another common situation is when processors are divided into sev- eral levels. Each level may contain a cluster of processors that act in conjunction, but on different levels the proces- sors behave entirely differently. Thus any attempt at bal- ancing must also focus on the interaction across levels of processors.
B. Techniques of Concurrent Programming
Concurrent programming is inherently a nondetermin- istic process. The tradeoffs lie in vector processing versus parallel processing. Bucher [I51 has indicated that asyn-
HWANC: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1369

chronous parallelization of codes seems to be conceptually simpler than vectorization. Furthermore, synchronized parallelism i s much easier to implementthan asynchronous parallelism. A race situation may exist in parallel branches of an asynchronous algorithm. In support of parallel pro- cessing, resource sharing must be employed. We have already addressed some resource control techniques in Section Ill; including the scheduling of parallel works, the interprocessor communication mechanisms, and load bal- ancing techniques. In what follows, we discuss the use of counting semaphores for deadlock avoidance and process synchronization.
Counting Semaphores are indivisible for lock, unlock, deadlock prevention, and synchronization of asynchro- nous processes. A simple definition of the P(S) and V ( S ) operators is given below, where S is a semaphore repre- senting the availability of a specific resource type.
P(S) : 1 IF S = 0 THEN COT0 1
V(S): S: = s + 1 (4)
The value of S is typically initialized as 0 in the creation of concurrent processes as exemplified below, where SI and S2 are two resource types being shared by two processes.
ELSE S: = S - 1
Process One Process TWO
Serial Serial Work Work
WS,) RS,)
* Parallel Parallel Work Work
P(SJ V(SA
Serial Serial Work Work
If the value of a semaphore is initialized as 1, it can be used as a lock for specifying a critical section as follows:
P ( s )
Critical Section
V(S)
Dijkstra has indicated three basic requirements for the execution of critical sections [30]. Knuth [83] has re-enforced statement 3) as stated in 4).
, 1) At any given time, only one process is in the critical
2) Stopping one process outside the critical section has
3) The decision as to which process enters the critical
4) Every process wanting to enter the critical section will
section.
no effect on other processes.
section cannot be postponed indefinitely.
be eventually allowed to do so.
Another form of shared variable for interprocess syn- chronization is the use of monitors, a structured way of implementing mutual exclusion. Beside having variables
representing the state of some resource, a monitor contains also procedures that implement operations on that resource; and the associated initialization code, which ini- tializes the values of variables before the monitor is called. Monitors are used to implement mutual exclusion. The Concurrent Pascal [55] supports monitors for this purpose.
System deadlock refers to the situation in a multipro- cessor when multiple processes are holding resources and preventing each other from completing their executions. In general, a deadlock can be prevented, i f one or more of the following necessary conditions are removed:
a) Motualexclusions: Each process has exclusive control of i ts allocated resources.
b) Nonpreemption: A process cannot release its allo- cated resources until completion.
c) Wait for: Processes can hold resources while waiting for additional resources.
d) Circular wait: Multiple processes wait for each other’s resources in a circular dependence situation.
The example shown in Fig. 22 shows a circular wait sit- uation among four concurrent processes. By modifying the
P(S1) P(S2)
P(S2) P(S4)
P(S3) P(S5)
P(S5) P(S5) P(S1)
P(S3) P(SG) P(S6)
V(SS) P(S1) P(S5)
V(S3) .
V(S1) V(S5) V(S2) V(S4) V(S3) V(S2)
V(S6) V(S6)
V(S1) V(S1) V(S5) V(S5)
(b) (C)
Fig. 22. The resolution of a system deadlock among four processes. (Deadlock is prevented in (c) with no cycles on the resource allocation graph.) (a) Four concurrent pro- cessessharing six resourcetypes represented by semaphore variables S,, Sl, . . , S6. (b) Resource allocation graph cor- respondingto(a).Possibledeadlockwithexistanceof acycle. (c) Resource allocation graph modified from changing the request pattern in P,. No possibility of deadlock exists.
1370 PROCEEDINGS OF THE W E , VOL. 75, NO. 10, O C T O B E R 1987

resource claim ordering in Process 4, the deadlock can be prevented, since there is no circular wait loop in the depen- dence graph, where SI, Sz, * , S6 are six resource sem- aphores being shared by the four processes. Each resource is assumed to have a single copy. Static deadlock preven- tion as outlined above may result in poor resource utili- zation. Dynamic deadlock avoidance depends on the run- time conditions, which may introduce a heavy overhead in detecting the potential existence of a deadlock. Although dynamic detection may lead to better resource utilization, the tradeoffs in detection and recovery costs must be con- sidered.
At present, most parallel computers choose a static pre- vention method due to its simplicity to implement. Sophis- ticated dynamic avoidance or a recovery scheme for the deadlock problem requires one to minimize the incurred costs to justify for the net gains. The gain lies in better resource utilization, if those static deadlock prevention constraints are removed. To break a deadlock by aborting some noncritical processes should result in a minimum recovery cost. A meaningful analysis of the recovery costs associated with various options is very time-consuming. This is the main reason why sophisticated deadlock recov- ery system has not been built into current multiprocessors. The static prevention may be rather primitive, but costs very little to implement. Further research is needed to make the dynamic recovery system more Cost-effective.
C. Mapping Algorithms Onto Parallel Architectures
Algorithm design usually involves several phases of development: The physical problem must be first modeled by a mathematical formulation such as differential equa- tions or algebraic systems. In most cases, these equations or systems are defined over a real domain such as contin- uous time functions. In order for the computer to solve these systems, some form of discretization and numerical approximation must be employed. For example, in solving problems described by partialdifferentialequations (PDEs), either finite-difference or finite-element methods can be used in the discretization process. Then numerical schemes are sought such as to employ iterative or direct methods in solving PDEs. Finally, one needs to partition the algo- rithm in order to map with parallel or vector architectural configurations. We concentrate below on the last phase in mapping of decomposed algorithms onto parallel archi- tectures.
Three approaches have been identified in designing par- allel algorithms. The first converts a given sequential atgo- rithm into a parallel version. This is often not a straight- forward process. Careful dataflow analysis must be employed to reveal all datdprogram dependencies. The inhibitors for parallelization or vectorization must be checked to avoid inefficiency in the programming. Very often the problem size does not match the machine size. Algorithmic transformation may be needed to establish a perfect match between the two sides of the problem. The second approach is to invent a new parallel algorithm. This looks more difficult. However, it is often more efficient, because the new algorithm can be specifically tailored to the target machine. Most algorithm designers choose a combined approach by startingwith a parallel algorithm for a similar problem and then try modifying it for the problem
at hand. These approaches have been treated in [a ] , [60],
The mapping problem arises when the communication structure of a parallel algorithm differs from the intercon- nection architecture of the target parallel computer [12]. This problem will be worsened when the number of pro- cesses created in the algorithm exceeds the number of pro- cessors available in the architecture. The implementation complexityof the algorithm depends on the degree of par- allelism, granularity, communication and synchronization overheads, 110 demands, and other implementation over- heads. For regularly structured architectures, such as arrays [4], [92], [94], [1271, prisms [118], pyramids [134], hypercubes [122], hypernets [69], etc., the algorithm is more sensitive to architecturetopologyand machinesize.Agoodmatch may make a big difference in performance. Recently, several design methodologies for synthesizing parallel algorithms and VLSl architectures have been proposed in [12], [19], [93]. Program transformation is the key in establishing the per- fect match.
Algorithm designers must be aware that communication complexitycouldoverweigh thecomputational complexity if one adds the complexities from I10 and memory con- tention. The problem could be even more severe. This brings us to the concept of balanced parallel computations, in which the effective bandwidths of all subsystems are matched to yield the best possible performance. In a mes- sage-passing multicomputer, the communication com- plexity may dominate the performance. The confronting goal is to minimize all the complexities coming from com- putation, communication, 110, and memoryaccess in a bal- anced manner. Simply chasing the bottlenecks will not be sufficient if implementation efficiency becomes a major concern.
Welist somecandidatealgorithmsfor parallel processing in Table 7. For algorithms which emphasize local opera- tions, as seen in most low-level image and signal processing applications, the array (mesh) and pyramid are more suit- able. For large-grain computations with global or unknown dependence, the algorithm is better implemented on shared-memory multiprocessors. Mapping algorithms onto array processors has been treated by many researchers [19], [74], [92], [93]. We illustrate in Fig. 23 a sequence of graph transformations to convert a dataflowgraph into apipeline net for vector processing of a compound vector function consisting of six operators. The numbers in the dataflow graph represent nodal and edge delays. The nodes cor- respond to operations and the edges indicate the partial ordering relationships among the operations. Details of this systematic approach to designing pipeline nets can be found in [74].
Developing algorithms for multiprocessors or multicom- puters demand a balanced partition of the algorithm. Par- titioned algorithms must be synchronized, because differ- ent granularities may exist in subprograms [Iq, [20], [&]. Partitioned algorithms can be further divided into pre- scheduled or self-scheduled ones. A prescheduled algo- rithm i s allocated with resources at compile time. In order to do this correctly, some prediction of the computation times and resource demand patterns of various subpro- grams must be known in advance. The self-scheduled algo- rithms obtain their resources at run time. Such a dynamic allocation of resources depends on an optimizing sched-
[65lt 1791, [1141.
HWANG: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1371

Table 7 Candidate Algorithms for Parailelization or Vectorization
Algorithms and Category Computations
matrix decomposition conversion of matrices sparse matrix operations linear system solution eigenvalue computations least squares problems
convolution and correlation digital filtering fast Fourier transforms feature extraction pattern recognition scene analysis and vision
Vectodmatrix arithmetic matrix multiplication
SignaVimage processing
Optimization processes
Statistical analysis
Partial differential equations
linear programming sorting and searching integer programming branch and bound
combinatorial analysis constrained optimization
probability distribution
variance analysis nonparametric statistics multivariate statistics sampling and
algorithms
functions
histogramming
ordinary differential
partial differential equations finite-element analysis domain decomposition numerical integration
equations
Special functions and graph algorithms
power series and functions interpolation and
approximation searching techniques graph matching logic set operations transitive closures
uler in the OS kernel. All ready-to-run subprograms are queued to match with theavailabilityof resourcetypes, such as processors or memories.
Another important class of algorithms is asynchronous algorithms, in which no forced synchronization is con- ducted amongconcurrent subprograms[65],[91],[114].This is based on a relaxation principle, in which each processor will not wait for another processor to provide it with data. Instead, each processor works with the most recently avail- able data wherever they may come from. Because of this relaxation,asynchronousalgorithmsaredifficuIttovalidate for correctness. Race conditions may exist to produce untraceable results. One can design a parallel algorithm which consists of synchronized and asynchronous por- tions. Such a combined mode can be constructed in a hier- archical manner, so that the best match can be established between the programming levels and the underlying resource architecture. Recently, divide-and-conquer algo- rithms have been evaluated for parallel processing [62], [130].
To overcome the difficulty associated with 110-bound
(d) Fig. 23. Designing a pipeline net with a sequence of graph transformations on the synchronous data flow graph of a given compound vector computation [74]. (a) The given data flow graph. (b) After equivalent graph transformation. (c) After moving four units of edge delay into nodes. (d) The final pipeline net.
problems, one can overlap computation with data transfer, such as using double bufferingto isolate the input and out- put of a large volume of data movement. To reduce transfer time, extended main memory (such as the SSD in Cray2 and the communication buffer in ETA-IO) can be used to close up the speed gaps. One can also trade serial I10 for small- grain problems with parallel I/O for large-grain problems. The memory contention can be alleviated by skewed mem- ory allocation schemes to avoid access conflicts or to use smart conflict resolution logic with multiported memory banks.
D. Mathematical Software and Application Packages
Mathematical software serves as the bridge between numerical analystswho design thealgorithm and computer users who need application software. The creation, doc- umentation, maintenance, and availability of software productsarecrucial totheeffective useof supercomputers. We examine below five major classes of software libraries that have been developed in recent years. Representative application software packages are summarized in Table 8. Most of these packages are coded in Fortran and only a few have versions also in Pascal, Algol, Ada, or C. The formation of a typical application software organization is illustrated in Fig. 24. This demonstrates how a software library is used in selecting special computing modules to form an appli- cation package which is callable from the user’s main pro- gram. Such systematized collections of software modules have inspired the creation of many useful software pack- ages.
7) Major Numbered Software Libraries: Several software libraries have been playing major roles in scientific com-
1372 PROCEEDINGS OF THE IEEE, VOL. 75, NO. 10, OCTOBER 1987

Table 8 Some Software Packages and Their Applications APPLICATION
Software Package ~~
Special Applications LINPACK solving linear systems of
equations
MG3D a seismic 3-D integration code for oil exploration
SPECTRAL short-term weather forecasting
PlCF
AIR 3D
NASTRAN
a particle-incell simulation program for plasma research experiments
a Navia-Stokes code for 3-D aerodynamic simulation
a PDE solver for finite-element analysis
ELLPACK elliptic PDE solver
FUNPACK routines for computing special functions and integrals
EISPACK eigenvalue problem solvers
MINPACK
SPARSPAK
ESSL
BCSLIB
SIATEC
routines for unconstrained and constrained optimizations
package for solving large-scale
an IBM library for vectodmatrix
spare matrices
computations
Boeing Computer Services Center
a core library supplied by
a common math library jointly developed by several National Laboratories
Math Advantage a mathematical package which is runable over 30 computer systems
putations. They are commonly known as the IMSL, PORT, NAG, and NATS [24]. IBM has developed the SSP (Scientific Subroutine Package), which was later used also in Univac and CDC machines. Today IMSL (International Mathemat- ical and Statistical Libraries) supports most mainframesand superminis at various computer centers [76]. There are 495 usercallable Fortran subroutines in IMSL, which perform basic mathematic functions, differential equations, matrix arithmetic, linear programming, etc. The PORT mathe- matical subroutine library emphasizing portability among heterogeneous machines was developed at Bell Labs [49]. The NAG (Numerical Algorithms Group) library was devel- oped in both Fortran and Algol 60 versions [a]. Both PORT and NAG routines have been used in Cray 1 benchmarking experiments. The NATS (National Activity toTest Software), backed by NSF and DOE, has promoted the development of several scientific software packages [14].
2) Important Scientific Software Packages: The LINPACK is a package for solving linear systems whose matrices are general, banded, symmetric indefinite, symmetric positive definite triangular, or triangular [MI. The FUNPACK is a package of special function routines, such as Bessel func- tions, exponential integrals, etc. The EISPACK, a package for solving eigenvalue problems, consists of 58 subrou- tines. These routines are being altered to take account of
SOFTWARE PACKAOE - I----------- 1 L-l m i
I
n
W (b)
Fig. 24. Application softwarepackagingand atypical math- ematical software library. (Courtesy of Boeing Computer Services Co.) (a) Forming an application software package with modules selected from a software library. (b) Major software categories in the Boeing Software Library.
vector machine architectures and paging OS with Fortran 77 extensions. The MINIPACK is a systematized collection of software for unconstrained, linearly constrained, and large-scale optimizations. These PACKS are among many other application software packages that are currently in use [24].
3) Software for Solving Differential Equations: Many sci- entifidengineering problems are characterized by ordinary differential equations (ODEs) or partial differential equa- tions (PDEs). Mathematical software for ODEs includes the DEPAC developed at Sandia National Laboratories. Elliptic PDE problems are being attacked by the ELLPACK and the FISHPAK for fluid dynamics modeling. Since many ODE or PDE problems resort to the solution of large-scale sparse matrices, the SPARSPAKand theYale package[24] have been developed to meet this demand. In fact, efforts in devel-
HWANC: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1373

oping parallel PDE solvers are presently in progress at USC [75] and at Purdue [115] among many other efforts [109].
4) Software Routines Supplied by Vendors: Major main- frame and supercomputer manufacturers have each devel- oped some scientifidengineering routines. Cray offers SCLlLlB with functions microcoded for fast execution on thecraycomputers. Besidesusingthevectorizingcompiler CFT, Cray application groups have also developed impres- sive multitasking software tools [25]. These tools have been applied in running some benchmark codes, such as the SPECTRAL for short-term weather forecasting. This multi- tasked SPECTRAL code shows a speedup of 3.77 running on a Cray X-MP14 as compared with a Cray X-MPl1. IBM has supplied the ESSL (Engineering and Scientific Subroutine Library) for vector facility attached to the 3090 mainframe [138]. FPS has a math library of 500 routines for their array processor families. The vendor-developed libraries are mostly machine-dependent, Portability is potentially a seri- ous problem with these packages. To help alleviate this portability problem, the Math Advantage [126] was com- mercially developed to supply over 200 routines in Fortran, C, and Ada versions runnableon over 30computer systems, including some parallel and vector architectures.
5) Software Development by User Groups: The Boeing Mathematical Software Library is being upgraded to sup- port CDC, IBM, FPS, and Craycomputers. The Boeing library structureisshowninFig.24(b),wheretheBCSLIBisthecore library containing basic computing modules and some util- ity software. The outer software includes the dense matrix software form LINPAK, general sparse matrix routines, and other software routines mentioned earlier. This multilevel library structure is being optimized towards a vector library for the CDC Cyber 205 and Cray machines through a con- version approach. For example, the CRAYPACK is being developed with Cray Assembly Languages (CAL) to exploit the Cray architecture. Another interesting effort is the SLA- TEC Common Math Library, which provides a means for several National Laboratories (Sandia, Los Alamos, AF Weapons Lab., LLNL, NBS, etc.) to foster the exchange of software experiences in using supercomputers [16].
Most of the above Fortran-coded software packages were originally written for conventional scalar processors. Some software libraries have responded to the call for vectori- zation and multiprocessing. However, theconversion from serial codes to parallel codes has been limited in isolated cases. These applications software libraries are presently taking very little advantage of the parallel hardware. Attempts to achieve vectorization have been made more often than thosefor multitaskingor distributed computing. This is due to the fact that vector uniprocessors appeared at least 5 years ahead of their multiprocessor extensions. However, this time lag in development is being shortened. Most minisupers extend their uniprocessor systems to mul- tiprocessor versions in less than 3 years. The extensions from Alliant FX/1 to FX/8 [135] and from Convex C-1 to CXS are good examples [23].
Towards the parallelization and vectorization of appli- cation software, most supercomputers choose the intelli- gent compiler approach or restructure the underlying algo- rithms or mathematical model used. One has to realize that mathematical software i s application-driven. Many of the above software libraries should be unified or standardized towards better portability, model sharing, routine sharing, and extended applicability. Proprietory restriction should
be minimized and software documentation should be improved to benefit both designers and users of parallell vector computers.
V. THE FUTURE OF SUPERCOMPUTERS
We assess below recent advances in computer science and technologies in connection with the development of thenext-generation supercomputers. In ordertoeffectively design and use ultra-powerful supercomputers, we call for a multi-discipline development of a new science of parallel computation. The new computing technologies being assessed include GaAs circuits, optical computing, and arti- ficial neurocomputers. Supercomputers are useful tools to improve the equality of human civilization. Due to hard- warelsoftware limitations, the performance of existing supers lags behind the leading-edgedemand of computing power in science and technology. i n order to make new advances in these leading edges, we demand a new gen- eration of supercomputers, which are at least O(1d) to 0(104) faster than today’s fastest machines. This demands a system which can execute O(104 to 0(1O1*) instructions per second [27, [136].
It has been projected that the fifth-generation super- computers will emphasize massive parallelism and distrib- uted computing through a modular construction. The hard- warewill makefurther advances in packaging, interconnect techniques, ultra large-scale integration three-dimensional IC design, GaAs or JJ technology, and optical interconnects and components. The recent breakthrough in supercon- ductor research may also have great impacts on supercom- puter technologies. In the software area, concurrent lan- guages, functional programming, and symbolic processing will play an increasing role. These advances in parallel-pro- cessing hardware and software will make the future super- computers not only faster but also smarter [@].
A. Optical Computing and Neurocomputers
Supercomputing technologies are presently advancing in three areas: i) GaAs circuits for building the Cray 3 and some 32-bit RlSC processors. ii) Optical crossbar intercon- nectsand electrooptical gate arrays. iii) Neural networksfor a connectionist model of parallel computation. Besides numerical supercomputing, increasing efforts have been exerted in developing Al-oriented supercomputers thatcan perform machine perception and reasoning applied to knowledge engineering and intelligence processing. We assess below these new research directions and comment on their potential impacts to supercomputers and appli- cations.
A technology road map is illustrated in Fig. 25. Presently, most supers or minisupers are made in ECL or CMOS tech- nology due to their high density and lower cost. However, the non-silicon devices (GaAs and HMET) are about five times faster than the ECL family (50 ps versus 250 ps). GaAs is more radiation-resistant and has a wider operating tem- perature range (-200OC to 200°C). The difficulties in GaAs are lesser density (3k gatesldie) and a lower yield in wafer production. The integration level of GaAs devices is pres- ently about 10 times lower and the cost about 100 times higherthan in theirsiliconcounterparts. However,thetrend isthatVLSi inGaAs is becoming available in laboratoryenvi- ronments [103]. The potential GaAs applications lie in real- time signal processing and supercomputing in environ-
1374 ‘PROCEEDINGS OF THE IEEE, VOL. 75, NO. 10, OCTOBER 1987
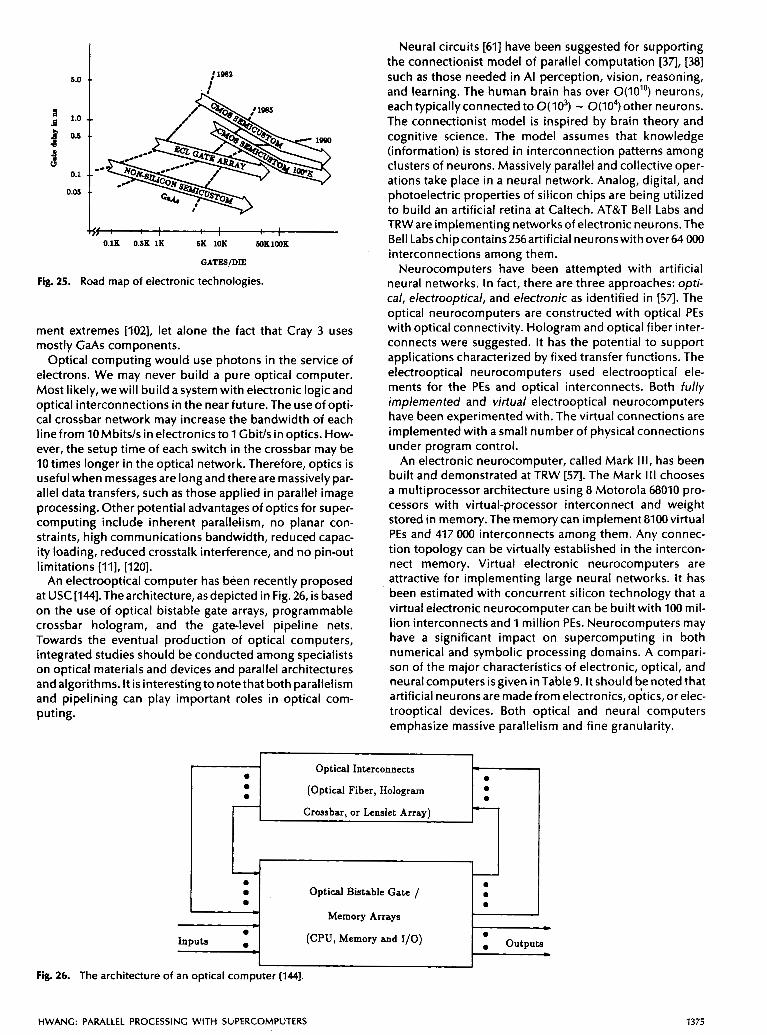
1.0 I ; l%l 8
‘ I , . , I ‘ I , , 0.1H O.SK l K 5K 1OK SOKlmK
GATES/DIE
Fig. 25. Road map of electronic technologies.
ment extremes [102], let alone the fact that Cray 3 uses mostly GaAs components.
Optical computing would use photons in the service of electrons. We may never build a pure optical computer. Most likely, we will build a system with electronic logic and optical interconnections in the near future. The use of opti- cal crossbar network may increase the bandwidth of each linefromlOMbits/sinelectronicstolGbit/sinoptics.How- ever, the setup time of each switch in the crossbar may be 10 times longer in the optical network. Therefore, optics is useful when messages are long and there are massively par- allel data transfers, such as those applied in parallel image processing. Other potential advantages of optics for super- computing include inherent parallelism, no planar con- straints, high communications bandwidth, reduced capac- ity loading, reduced crosstalk interference, and no pin-out limitations [ll], [120].
An electrooptical computer has been recently proposed at USC [l44]. The architecture, as depicted in Fig. 26, is based on the use of optical bistable gate arrays, programmable crossbar hologram, and the gate-level pipeline nets. Towards the eventual production of optical computers, integrated studies should be conducted among specialists on optical materials and devices and parallel architectures and algorithms. It is interestingtonotethat both parallelism and pipelining can play important roles in optical com- puting.
Neural circuits [61] have been suggested for supporting the connectionist model of parallel computation [371, [38] such as those needed in AI perception, vision, reasoning, and learning. The human brain has over O(lO’o) neurons, each typically connected to O( IO3) - 0(104) other neurons. The connectionist model is inspired by brain theory and cognitive science. The model assumes that knowledge (information) is stored in interconnection patterns among clusters of neurons. Massively parallel and collective oper- ations take place in a neural network. Analog, digital, and photoelectric properties of silicon chips are being utilized to build an artificial retina at Caltech. AT&T Bell Labs and TRW are implementing networks of electronic neurons. The Bell Labschipcontains256artificial neuronswithover64 OOO interconnections among them.
Neurocomputers have been attempted with artificial neural networks. In fact, there are three approaches: opti- cal, electrooptical, and electronic as identified in [57l. The optical neurocomputers are constructed with optical PES with optical connectivity. Hologram and optical fiber inter- connects were suggested. It has the potential t o support applications characterized by fixed transfer functions. The electrooptical neurocomputers used electrooptical ele- ments for the PES and optical interconnects. Both fully implemented and virtual electrooptical neurocomputers have been experimented with. The virtual connections are implemented with a small number of physical connections under program control.
An electronic neurocomputer, called Mark Ill, has been built and demonstrated at TRW [571. The Mark Ill chooses a multiprocessor architecture using 8 Motorola 68010 pro- cessors with virtual-processor interconnect and weight stored in memory. The memory can implement 8100 virtual PES and 417 OOO interconnects among them. Any connec- tion topology can be virtually established in the intercon- nect memory. Virtual electronic neurocomputers are attractive for implementing large neural networks. I t has been estimated with concurrent silicon technology that a virtual electronic neurocomputer can be built with 100 mil- lion interconnects and l million PES. Neurocomputers may have a significant impact on supercomputing in both numerical and symbolic processing domains. A compari- son of the major characteristics of electronic, optical, and neural computers is given in Table 9. It should be noted that artificial neurons are made from electronics, optics, or elec- trooptical devices. Both optical and neural computers emphasize massive parallelism and fine granularity.
Optical Interconnects - 0 0
0
Crossbar, or Lenslet Array)
(Optical Fiber, Hologram 0 0 0 - -
__I - 0
Memory Arrays 0 0
0 0 0 Optical Bistable Gate /
m
c 0
- Inputs 0 0 outputs
(CPU, Memory and I/O) 0
m - Fig. 26. The architecture of an optical computer (1441.
HWANC: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1375

Table 9 Major Characteristics of Electronic, Optical, and Neutral Computers
Characteristics Electronic Computers Optical Computers Neural Computers Swtiching speed O(10-9 - O(10-”) s in Si, O(10-12) - s in O(IO-’~) s in electronic,
O(lO-’) s in biological neurons
CaAs, JJ, HEMT optical gate arrays 0(10-13) in optical, and
Processor largegrain and O(1) - fine-grain and massive fine-grain and massive granularity and processors per parallelism parallelism parallelism system
bandwidth Communication O(10) - O(ld) Mbits/s O(1) - O(ld) Gbitds potentially very high,
because all cells could fire simultaneously
Physical a103 - qld) transistors aid) - 0(105 gates per O(1d) electronic neurons integration per CMOS chip optical array per silicon chip
Control synchronous with digital synchronouslasynchronous distributed and self- complexity clocking (absence of clock skewing) organizing
Power aid) W per board at @lo-’) w per array at technology dependent,
(using optics) to high (using electronics)
requirements O(lO)-MHz clock rate O(lO)-MHz clock rate ranging from low
Reliability and architecture and technology less interference and could inherently robust due to maintenance dependent be very costly cooperative operations
B. Towards a Science of Parallel Computation
The way parallel computation is handled today is quite ad hoc and it lacks both theoretical foundations and engi- neering methodologies. In the pasttwodecades,there have been growing demands for increasing interdisciplinary communications towards the development of a new Sci- ence of Parallel Computation [IO], [13], [40], [SS], [MI. To develop such a scientific discipline, we may have to go through three phases: exploratory, paradigmatic, and post- paradigmatic. The exploratory phase encourages compet- ing paradigmstogothrough experimentation, observation, and classification stages, which are primarily driven by internal forces. The paradigmatic phase will conclude with theemergenceof different paradigms thatwill organizethe field. Research will focus on the accepted paradigms that will be driven by both internal and external forces. The last phase must be based on well-tested theories of parallel computation. The discipline must be exploited to solve real problems in society. At this stage the research will be driven largely by external forces.
At present, the state of parallel computation is still in the exploratory and paradigmatic phases. Gorden Bell has noted: “Manytheories have been invalidated, stagnant, and sterile because of the lack of parallel computers. The core program in parallelism should provide the impetus so that all basic mathematical theory, hardware machines and operating systems, languages, algorithms and applications are inherently parallel within a decade” [IO]. This clearly indicates the need of multidiscipline interactions. In fact, the NSF Computer and Information Science and Engi- neering Directorate is encouraging research in parallelism be applied to supercomputing, automation, robotics, intel- ligent systems, ultra-large scale integrated systems, sci- entific simulations, engineering designs, networks, and distributed computing.
Multidiscipline interactions are demanded in parallel supercomputing. Four groups of professionals should be involved, namely the theoreticians, experimentalists, com- putation scientists, and application engineers [117]. Appli-
1376
cations drive the development of particular parallel pro- cessing software. The barriers lie in partial systems, confirmation bias, and lack of performance spectrum and project database. Comparative analysis is needed to deter- mine the effectiveness, robustness, efficiency, extensibil- ity, economy, ease of use, reliability, and maintainability of parallel systems and to broaden their application domains. Of course, we need the cooperation between academic and industrial communities to distribute new discoveries and to publish key concepts, principles, paradigms, and pre- scriptive terminologies. This could become one of the major thrusts in computer sciencelengineering education. The lack of vision in pushing this thrust area will be the major barrier in achieving new advances in science and tech- nology.
VI. CONCLUSIONS We have evaluated the state of parallel processing on
state-of-the-art supercomputers. Recent advances in super- computer architectures, parallel processing software, resource and concurrency control, and concurrent pro- grammingtechniquesarecategoricallyassessed.The inten- tion is to bring together important issues and evaluate best answers to uphold performance. New research findings and high-risk hardwarelsoftware approaches are being trans- ferred to the computer industry slowly. However, low-cost supercomputing is becoming a major driving force in high- tech markets. This has triggered the thought of personal Supercomputers for the future.
The rise of the computer industry in producing mini- supers, mainframe extensions, array processors, scientific superstations, AI machines, optical computers, and artifi- cial neurocomputers have had great impact on the devel- opment of future supercomputers. We conclude with the following observations: First, newtechnologies, innovative architectures, and more exotic computers will appear. Sec- ond, the cost of future supercomputers must be affordable in general-purpose applications. Third, a new generation of programmers must be trained to achieve parallel pro- cessing. Fourth, we envision the emerging Science of Par-
PROCEEDINGS OF THE IEEE, VOL. 75, NO. 10, OCTOBER 1987

allel Computation, which will serve as the foundation of supercomputing and artificial intelligence [a], [70], [139].
ACKNOWLEDGMENT
The author would like to thank J. Abarbanel and S. Mistry for typing the manuscript, and his Ph.D. students D. Kim, A. Louri,R. Chowkwanyun, H. C. Wang,Z.Xu,and J.Ghosh at USC for assisting in the preparation of the tables and illustrations.
REFERENCES
Alliant Computer Systems Corp., Alliant FX/Series: Product Summary. Acton, MA: June 1985. G. S. Almasi, “Overview of parallel processing,” Parallel Comput., vol. 2, no. 2, pp. 191-204, Nov. 1985. Ametek Computer Research Division, “Concurrent pro- cessing on hypercube,” Tech. Rep., Feb. 1987. M. Anaratone, E. Arnould, T. Gross, H. T. Kung, M. S. Lam, 0. Menziloioglu, K. Sarocky, and J. A. Webb, “Warp archi- tecture and implementation,” in Proc. 73th Anr;u. lnt. Symp. on Computer Architecture, pp. 346-356, June 1986. T. S. Axelrod, “Effects of synchronization barriers on mul- tiprocessor performance,” Parallel Comput., vol. 3, no. 2, pp. 129-140, May 1986. K. E. Batcher, “Design of a massively parallel processor,” /E€€ Trans. Comput., vol. C-29, pp. 836-840, Sept. 1980. BBN Labs., Butterfly Parallel Processor Overview, Version 1, Mar. 1986. 1. Beetam, M. Denneau, and D. Weingarten, “The GFl l supercomputer,” in Proc. 72th Annu. lnt. Symp. on Com- puter Architecture, pp. 108-115, June 1985. C. G. Bell, ”Multis: A new class of multiprocessor com- puter,” Science, vol. 228, pp. 462-467, 1985. C. G. Bell, “Parallelism advancing computing technolo- gies,’’ Keynote Speech, ACMiComputer Society Fall Joint Computer Conf., Nov. 2-6, 1986. T. E. Bell, “Advanced technology: Optical computing,” /E€€ Spectrum, vol. 23, pp. 34-57, Aug. 1986. F. Berman and L. Snyder, “On mapping parallel algorithms into parallel architectures,”]. ParallelDistributedComput., accepted to appear, 1987. A. J. Bernstein, “Analysis of programs for parallel process- ing,’’ / F E E Trans. Comput., vol. C-25, pp. 746-757, Oct. 1986. J. M. Boyle etal., “NATS, A collaborative effort to certify and disseminate mathematical software,” Proc. NCC, pp. 630- 635, 1972. I. Y. Bucher, “The computation speed of supercomputers,” in Proc. ACM Sigmetrics Conf. on Measurement and Mod- eling of Computer Systems, pp. 151-165, Aug. 1983. B. Buzbee, “The SLATEC common mathematical library,” in W. R. Cowell, Ed., Sources and Development of Mathemat- icalSoftware. Englewood Cliffs, NJ: Prentice-Hall, pp. 302- 320. D. A. Calahan, “Task granularity studies on a many-pro- cessor CRAY X-MP,” Parallel Comput., pp. 109-118, June 1985. A. L. Charlesworth and J. L. Gustafson, “Introducing rep- licated VLSl to supercomputing: The FPS-16441MAX scientific computer,” /€€E Computer, vol. 19, pp. 10-23, Mar. 1986. M. Chen, “A design methodology for synthesizing parallel algorithms and architectures,” 1. Parallel Distributed Com- put., pp. 462-491, Dec. 1986. S. C.Chen, J. Dongarra, and C. C. Hsiung, ”Multiprocessing for linearalgebraalgorithmson theCrayX-MP/2: Experience with small granularity,”]. ParallelDistributedComput., Aug. 1984. S. S. Chen, “Cray X-MP-4 series,” Cray Research presen- tations, Aug. 1985. C. Y. Chin and K. Hwang, “Packet switching networks for multiprocessors and dataflow computers,” /E€€ Trans. Comput., vol. C-33, pp. 991-1003, Nov. 1984. Convex Computer Corporation, “Convex C1 series: XP pro- cessors,” Richardson, TX, Tech. Notes Edition, 1987. W. R. Cowell, Ed., Sources and Development of Mathemat-
ical Software. Englewood Cliffs, NJ: Prentice-Hall, 1984. [25] Cray Research Inc., “Multitasking user guide,” Tech. Note
SN-0222, Feb. 1984. [26] Cray Research Inc., Tbe Cray 2 Computer Systems. Techni-
cal Brochure, 1985. [27] DARPA, “Strategic computing: New-generation computing
technology,” Tech. Rep., Defense Advanced Research Proj- ects Agency, Oct. 1983.
[28] D. B. Davis, “Parallel computers diverge,” High Technol- ogy, pp. 16-22, Feb. 1987.
[29] J. B. Dennis, “Dataflow supercomputer,”lEEEComputer, vol. 13, no. 11, pp. 48-56, Nov. 1980.
[30] E. W. Dijkstra, “Solution of a problem in concurrent pro- gramming,” Commun. ACM, pp. 569-570, Sept. 1965.
[31] U.S. DOD, Programming Language Ada: Reference Manual, vol. 106. New York, NY: Springer-Verlag, 1981.
[32] J. J. Dongarra, “A survey of high performance computers,” in Dig. Papers: /E€€ Computer Society COMPCON, pp. 8-11, Spring 1986.
[33] J. J. Dongarra and I . S. Duff, “Advanced computer archi- tectures,” Argonne National Lab., Argonne, IL, Tech. Rep., Oct. 1985.
[34] J. J. Dongarra and G. W. Stewart, “LINPACK-A package for solving linear systems,” in W. R. Cowell, Ed., Sources and Development ofMathematicalSoftware. Englewood Cliffs, NJ: Prentice-Hall, 1984, pp. 20-48.
[35] J. J. Dongarra, ”Performance of various computers using standard linear equations software in a Fortran environ- ment,” in W. J. Karplus, Ed., Multiprocessors and Array Pro- cessors. San Diego, CA: Simulation Councils Inc., Jan. 1987,
[36] ETA Systems, “ETA-IO system overview: Introduction,”Tech. Note, Pub-1006, Revision A, Feb. 1986.
(371 S. E. Fahlman and G. E. Hinton, “Connectionist architec- tures for artificial intelligence,” / F E E Computer, vol. 20, pp. 100-109, Jan. 1987.
[38] J. A. Feldman and D. H. Ballard, “Connectionist models and their properties,” Cogn. Sci., vol. 6, pp. 205-254, 1982.
[39] T. Y. Feng, “A survey of interconnection networks,” / E € € Computer, vol. 14, pp. 12-27, Dec. 1981.
[40] -, “Parallel processors and processing,” ACM Comput. Surv., special issue, Mar. 1977.
[41] P. R. Fenner, “The Fled32 for real-time multicomputer sim- ulation,” in W. J. Karplus, Ed., Multiprocessors and Array Processors. San Diego, CA: Simulation Councils, Inc., Jan.
[42] S. Fernbach, “Supercomputers-Past, present, prospects,” 1. Future Generation Comput. Syst., pp. 23-30, 1984.
[43] M. W. Ferrante, “Cyberplusand MapV interprocessor com- munications for parallel and array processor systems,” in W. J. Karplus, Ed., Multiprocessors and Array Processors. San Diego, CA: Simulation Councils, Inc., Jan. 1987, pp. 45- 54.
[44] J. A. Fisher, “Trace sceduling: A technique for global micro- code compaction,” /E€€ Trans. Cornput., vol. C-30, no. 7, pp.
1451 M. J. Flynn, “Some computer organizations and their effec- tiveness,’’ /€€E Trans. Comput., vof. C-21, pp. 948-960, Sept. 1972.
[46] B. Ford and 1. C. Pool, ”The evolving NAG library service,” in W. R. Cowell, Ed., Sources and Development of Mathe- maticalSohare. Englewood Cliffs, NJ: Prentice-Hall, 1984,
[47l G. FOX, “Questions and unexpected answers in concurrent computation,” Tech. Rep. C P-288, Caltech., Concurrent Computation Program, California Institute of Technology/ Jet Propulsion Labs., Pasadena, CA, June 1986.
[481 G. C. Fox and S. W. Otto, “Algorithms for concurrent pro- cessors,” Phys. Today, vol. AR-370, pp. 13-20, May 1984.
[49] P. A. Fox, A. D. Hall, and N. L. Schryer, ”The PORT math- ematical subroutine library,” ACM Trans. Math. Software, pp. 104-126, 1978.
[501 D. Gajski and J. K. Pier, ”Essential issues in multiprocessor systems,’’ /E€€ Computer, vol. 18, no. 6, pp. 9-28, June 1985.
[511 D. H. Gibson, D. W. Rain, and H. F. Walsh,”Engineeringand scientific processing on the IBM 3090,” ISM Syst. I., vol. 25, no. 1, pp. 36-50, Jan. 1986.
[521 I . R. Goodman and C. H. Sequin, “Hypertree: A multipro-
pp. 15-33.
1987, pp. 127-136.
478-490, July 1981.
pp. 375-398.
HWANG: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1377

cessor interconnection topology,” / € € E Trans. Comput., vol. C-30, no. 12, pp. 923-933, Dec. 1981.
[53] A. Gottlieb, R. Grishman, R. Kruskal, C. P. McAalifte, K. P. Randolph, and M. Snir, “The NYU ultracomputerdesigning an MlMD shared memory parallel computer,” /€€€ Trans. Comput., vol. C-32, no. 2, pp. 175-189, Feb. 1983.
[54] J. Graham and J. Rattner, “Expert computation on the iPSC concurrent computer,” in W. J. Karplus, Ed., Multiproces- sors and Array Processors. San Diego, CA: Simulation Councils, Inc., Jan. 1987, pp. 167-176.
[55] P. B. Hansen, “The programming language concurrent Pas- cal,” /€€€ Trans. Software Eng., vol. SE-1, no. 2, pp 199-206, June 1975.
(561 S . Hawkinson, “The FPS T series: A parallel vector super computer,” in W. J. Karplus, Ed., Multiprocessors andArray Processors. San Diego, CA Simulation Councils, Inc., Jan.
[57l R. Hecht-Nielson, “Performance limits of optical, electro- optical, and electronic neurocomputers,” Tech. Rep., TRW Rancho Carmel AI Center, San Diego, CA, 1986.
[a] W. D. Hillis, The Connection Machine. Cambridge, MA: MIT Press, 1985.
[59] C. A. R. Hoare, “Toward a theory of parallel programming,” in C. A. R. Hoare, Ed., Operating Systems Techniques. New York, NY: Academic Press, 1972.
[60] R. W. Hockney, ParallelComputers. Bristol, Eng1and:Adam Hilger, Ltd., 1981.
[61] J. J. Hopfield and D. W. Tank, “Computing with neural cir- cuits: A model,“ Science, vol. 233, pp. 625-633, Aug. 1986.
[62] E. Horowitz, ”Divideandconquer for parallel processing,” / € E Trans. Comput., vol. C-30, no. 4, Apr. 1981.
[63] C. Huson, T. Mache, J. Davies, M. Wolfe, and B. Leasure, “The KAP-205: An advanced sourceto-source vectorizer for the Cyber 205 supercomputer,” in Proc. lnt. Conf. on Par- allel Processing, pp. 827-832, Aug. 1986.
[64] K. Hwang, Ed., Supercomputers: Design and Applications. Washington, DC: IEEE Computer Society Press, Aug. 1984.
[65] K. Hwang and F. A. Briggs, Computer Architecture and Par- allel Processing. New York, NY: McGraw-Hill, 1984.
[a] K. Hwang and Y. H. Cheng, “Partitioned matrix algorithms for VLSl arithmetic systems,” I € € € Trans. Comput., vol. C-
[67l K. Hwang and R. Chowkwanyun, ”Dynamic load balancing for messagepassing multiprocessors,” Tech. Rep. CRI-87- 04, USC Computer Research Institute, Jan. 1987.
[68] K. Hwang and D. DeGroot, Eds., Parallel Processing for Supercomputing and Artificial Intelligence. New York, NY: McCraw-Hill, 1988 (in press).
[69] K. Hwang and J. Chosh, “Hypernets: Acommunication-effi- cient architecture for constructing massively parallel com- puters,” / € € E Trans. Comput. (Special Issue on Supercom- puting), vol. C-36, Dec. 1987.
[70] K. Hwang, J. Ghosh, and R. Chowkwanyun, ”Computer architectures for AI processing,” / € € E Computer (Special Issue on New AI Systems), vol. 20, pp. 19-29, Jan. 1987.
[71] K. Hwang, D. Kim, and P. S. Tseng, “An orthogonal multi- processor architecture for efficient parallel processing,”/€€€ Trans. Comput., to be published.
[72] K. Hwang, 5. P. Su, and L. M. Ni, “Vector computer archi- tecture and processing techniques,” in M. Yovits, Ed., Advances in Computers, vol. 19. New York, NY: Academic
[73] K. Hwang and P. S. Tseng, “An efficient VLSl multiprocessor Press, 1981, pp. 115-197.
for signallimage processing,” in froc. / € E lnt. Conf. on Computer Design: VLSl in Computers (Oct. 7-10, 1985), PP.
[74] K. Hwang and Z. Xu, “Pipeline nets for compound vector supercomputing,” I€€€ Trans. Comput., Jan. 1988.
[75] K. Hwang, Z. Xu, and A. Louri, “Remps: An electrcmptical supercomputer for parallel solution PDE problems,” in Proc. 2nd lnt. Conf. on Supercomputing (May 5-8,1987).
[76] IMSL Inc., lMSL Library Reference Manual. Houston, TX: IMSL, 1980.
[77l lnmos Ltd., OCCAM Programming Manual. Englewood Cliffs, NJ: Prentice-Hall, 1984.
[78] H. F. Jordan, “Performance measurement of HEP-A pipe- lined MlMD computer,’’ in Proc. 7OthAnnu. Symp. on Com- puter Architecture, pp. 207-212, June 1983.
1987, pp. 147-156.
31, pp. 1215-1224, Dec. 1982.
172-175.
[79] H. F. Jordan, “Structuring parallel algorithms in an MIMD, shared memoryenvironment,” ParallelComput., pp. 93-110, May 1986.
1 8 0 1 R. M. Karp and R. E. Miller,”Propertiesof a model for parallel computations: Determinancy, terminating, and queuing,”
[81] W. J. Karplus, Ed., Multiprocessors and Arrays Processors. San Diego, CA: The Society of Computer Simulation, Jan. 1987.
[82] H. Kashiwagi and K. Miura, “Japanese superspeed com- puter project,” Proc. Adv. Reactor Computation, Mar. 1983.
[83] D. E. Knuth, “An empirical study of Fortran programs,” Soft- ware Pract. Exper., vol. 1, no. 2, pp. 105-133, Apr.-June, 1971.
1 8 4 1 P. M. Kogge and H. S. Stone, ”A parallel algorithm for effi- cient solution of a general class of recurrence equations,” / E € € Trans. Cornput., vol. C-22, pp. 786-793, 1973.
[85] J. S. Kowalik, R. Lord, and S. Kumar, ”Design and perfor- mance of algorithms for MlMD parallel computers,” in J.S. Kowalik, Ed., Proc. of the NATO Workshop on High Speed Computations. Berlin, W. Germany, Springer-Verlag, 1984,
[86] J. S. Kowalik, Ed., Parallel MlMD Computation: H€P Super- computerandltsApplications. Cambridge, MA: MIT Press, 1985.
1871 E. W. Kozdrowicki and D. J. Theis, “Second generation of vector supercomputers,” / € € E Computer, vo1.13, pp. 71-83, Nov. 1980.
[88] D. J. Kuck, E. S. Davidson, D. H. Lawrie, and A. H. Sameh, “Parallel supercomputing today and the cedar approach,” Science, vol. 231, pp. 967-974, Feb. 1986.
[89] D. J. Kuck, R. H. Kuhn, B. Leasure, and M. Wolfe, “The struc- ture of an advanced retargetable vectorizer,” in Proc. COMPSAC, Oct. 1980.
[90] D. J. Kuck, A. H. Sameh, et a/ . , “The effects of program restructuring, algorithm change, and architecture choice on program,” in Proc. lnt, Conf. on Parallel Processing, pp.
[91] H.T. Kung, “The structureof parallel algorithms,” in M. Yov- its, Ed., Advances in Computers, vol. 18. New York, NY: Academic Press, 1980, pp. 65-112.
[92] H. T. Kung and C. E. Leiserson, “Systolic arrays (for VLSI),” SlAM Sparse Matrix Proc., pp. 245-282, 1978.
[93] S. Y. Kung, VLSl Array Processors. Englewood Cliffs, NJ: Prentice-Hall, 1987.
[94] -, “On supercomputing with systoWwavefront array processors,” Proc. I € € € , vol. 72, pp. 867-884, July 1984.
[95] J. Larson, ”Multitasking on the Cray X-MP/2 multiproces- sor,’’ / € € E Computer, vol. 12, pp. 62-69, July 1984.
[%I S. Levialdi, Ed., lntegrated Technology for Parallel lmage Processing. New York, NY: Academic Press, 1985.
[97l K. C. Li and H. Schwetman, “Vectorizing C: A vector pro- cessing language,”]. ParallelDistributedComput., vol. 2, no. 2, pp. 132-169, May 1985.
[98] N. R. Lincoln, “Technology and design tradeoffs in the cre ation of a modern supercomputer,” /E€€ Trans. Comput., vol. C-31, pp. 363-376, May 1982.
[99] 0. Lubeck, J. Moore, and R. Mendez, “A benchmark com- parison of three supercomputers: Fujitsu VP-200, Hitachi S810/20, and Cray X-MP/2,” l€€€ Computer, vol. 18, pp. 10- 29, Dec. 1985.
[lo01 J. McCraw, S. Skedzielewski, S. Allan, D. Grit, R. Oldehoeft, J. R. W. Glauert, I. Dobes, and P. Hohensee,”SISAL-Streams and iteration in a single assignment language,” Lawrence Livermore National Laboratory, Tech. Rep., Mar. 1985.
[loll S. K. McGrogan, ”Modifying algorithms to achieve greater than linear performance improvements on the ELXSl 6400 multiprocessor,” in W. J. Karplus, Ed., Multiprocessors and Arrayfrocessors. San Diego, CA. Simulation Councils, Inc., Jan. 1987, pp. 103-110.
[I021 V. Milutinovic, N. Lopez-Benitez, and K. Hwang, “A GaAs- based microprocessor architecture for real-time applica- tions,” /E€€ Trans. Comput., vol. 36, pp. 714-727, June 1987.
[lo31 V. Milutinovic, Ed., “GaAs: Atechnology for environmental extremes,” Special Issue in /€€€Computer, vol. 19, Oct. 1986.
[I041 L. M. Ni and K. Hwang, “Optimal load balancing in a mul- tiple processor system with many job classes,” l€€€ Trans. Software E r g . , vol. SE-11, pp. 491-496, May 1985.
[lo51 -,“Vector reduction techniques for arithmetic systems,”
SIAM). Appl. Math., pp. 1390-1411, NOV. 1986.
pp. 257-276.
129-138, Aug. 1984.
1378 PROCEEDINGS OF THE IEEE, VOL. 75, NO. 10, OCTOBER 1987

lEEE Trans. Comput., vol. C-34, pp. 404-411, May 1985. 11061 L. M. Ni, C. Xu, and T. B. Gendreau, “A distributed drafting
algorithm for load balancing,” /€€E Trans. Software Eng., vol. SE-11, no. 10, pp. 1153-1161, Oct. 1985.
[lo7 C. Norrie, “Supercomputers for superproblems: An archi- tectural introduction,” /E€€ Computer, vol. 17, pp. 62-74, Mar. 1984.
[I081 V. A. Norton and G. F. Pfister, ”A methodology for pre- dicting multiprocessor performance,” in Proc. 7985 lnt. Conf. on Parallel Processing, pp. 772-781, Aug. 1985.
(1091 J. M. Ortega and R. G . Voigt, ”Solution of PDEs on vector and parallel computers,” SlAM Rev., vol. 27, pp. 149-240, June 1985.
[I101 J. F. Palmer, “The NCUBE family of parallel supercompu- ters,” W. J. Karplus, Ed., Multiprocessors and Array Pro- cessors. San Diego,CA: SimulationCouncils, Inc.,Jan.1987.
[ l l l ] G. Paul, “VECTRAN and the proposed vector/array exten- sions to ANSI FORTRAN for scientific and engineering com- putations,” in Proc. ISM Conf. on Parallel Computers and Scientific Computations (Rome, Italy, Mar. 1982).
[I121 R. H. Perrot, R. W. Lyttle, and P. S. Dhillon, “Thedesign and implementation of a Pascal-based language for array pro- cessor architectures,”]. Parallel Distributed Comput., Aug. 1987.
[I131 G . F. Pfister, W. C. Brantley, D. A. George, S. L. Harvey, W. J. Kleinfelder, K. P. McAuliffe, E.A. Melton,V.A. Norton,and J. Weiss, “The IBM research parallel processor prototype (RP3): Introduction and architecture,” in Proc. lnt. Conf. on Parallel Processing, pp. 764-711, Aug. 1985.
[I141 M. Quinn, Designing Efficient Algorithms for Parallel Com- puters. New York: NY: McGraw-Hill, 1987.
[115] J. Rice and R. F. Boisvert, Solving Elliptic Problems Using ELLIPACK. New York, NY: Springer-Verlag, 1985.
[116] J. P. Riganati and P. B. Schneck, “Supercomputing,” lEEE Computer, vol. 17, pp. 97-113, Oct. 1984.
[117 G. Rodrigue, E. D. Giroux, and M. Pratt, “Perspective on large-scale scientific computation,’’ /E€€ Computer, vol. 13,
[I181 A. Rosenfeld, “The Prism machine: An alternative to pyra- mid,”]. Parallel Distributed Comput., vol. 3, no. 3, pp. 404- 411, Sept. 1986.
[I191 J. Sanguinetti, “Performance of a message-based multipro- cessor,’’ /E€€ Computer, vol. 19, pp. 47-55, Sept. 1986.
[120] A. Sawchuk, “The state of optical computing,” in Distin- guished Lecture Series, USC Computer Research Institute, Jan. 29,1987.
[I211 J. T. Schwartz, “Ultracomputers,” ACM Trans. Programming Languages Syst., pp. 484-521, Apr. 1980.
[122] C. L. Seitz, “The cosmic cube,” Commun. ACM, pp. 22-33, Jan. 1985.
[I231 I. D. Sherson and Y. Ma, “Orthogonal access multipro- cessing: An architecture for numerical applications,” Proc. 8th Symp. on Computer Arithmetic (Lake Como, Italy, May
[124] H. J. Siegel, Interconnection Networks for Large-Scale Par- allel Processing. Boston, MA: Lexington Books, 1984.
[I251 B. J. Smith, ”Architecture and applications of the HEP mul- tiprocessor computer system,” Real-Timesignal Processing
[I261 W. R. Smith, “Quantitative technology corporation math advantage: A compatible, optimized math library,” in W. J. Karplus, Ed., Multiprocessors and Array Processors. San Diego, CA Simulation Councils, Inc., Jan. 1987.
[I271 L. Snyder, “Supercomputers and VLSI,” in Advances in Computers. New York, NY: Academic Press, pp. 1-33.
[I281 D. 8. Sol1,“Vectorization andvector migrationtechniques,” Tech. Bull., IBM Publishing Services,225 Carpenter East, Irv- ing, TX, June 1986.
[I291 Sperry Corporation, Sperry Integrated Scientific Processor System. P. 0. Box 64942, St. Paul, MN 55164, 1985.
pp. 65-80, OCt. 1980.
18-21,1987).
lV, VOI. 298, pp. 241-248, Aug. 1981.
[lu)] Q. Stout, ”Divide and conquer algorithms for parallel image processing,” 1. Parallel Distributed Comput., vol. 4, no. 2, Feb. 1987.
(1311 P. J. Sydow,“Optimizationguide,”Tech. Rep. SN4220,Cray Research, Inc., 1983.
[I321 Sequent Computer Systems, Guide to Parallel Program- ming. Beaverton, OR: SCS, 1987.
[I331 H. Tamura, S. Kamiya, and T. Ishigai, “FACOM VP-100/200: Supercomputers with ease of use,” Parallel Comput., pp. 87-108, June 1985.
[I341 S. L. Tanimoto, “A pyramidal approach to parallel process- ing,’’ in Proc. 70th Annu. Symp. on Computer Architecture,
[135] J.Test, M. Myszewski,and R. C. Swift, “The Alliant FWSeries: Automatic parallelism in a multiprocessor mini-supercom- puter,” in W. J. Karplus, Ed., Multiprocessors andArray Pro- cessors. San Diego, CA SimulationCouncils, Inc.,Jan.1987,
(1361 E. A. Torrero, Ed., Next-Generation Computers. New York, NY: lEEE PRESS, 1985.
- [ I37 P. C. Treleaven, D. R. Brownbridge, and R. P. Hopkins, “Data- driven and demanddriven computer architecture,” ACM Comput. Surv., pp. 93-143, Mar. 1982.
[I381 S. G. Tucker, “The IBM 3090 system: An overview,” ISMSyst. I., vol. 25, no. 1, pp. 4-19, Jan. 1986.
[139] L. Uhr, Parallel Multicomputer Architectures for Artificial Intelligence. New York, NY: Wiley-lnterscience, 1987.
[I401 N. Wirth, Programmingin Modula-2. New York, NY: Sprin- ger-Verlag, 1982.
[I411 J. Worlton, “Understanding supercomputer benchmarks,” Datamation, pp. 121-130, Sept. 1984.
[I421 W. A. Wulf, R. Levin, and S. P. Harbison, Hydra/C.mmp:An Experimental Computer System. New York, NY: McGraw- Hill, 1981.
[I431 2. Xu and K. Hwang, “Molecule: A language construct for layered development of parallel programs,” lEEE Trans. Software Eng., to appear in 1987.
[I441 Z. Xu, K. Hwang, and K. Jenkins, “Opcom: An architecture for optical computing based on pipeline networking,” in Proc. 20th Annu. Hawaii lnt. Conf. on Systems Sciences, pp. 147-156, Jan. 1987.
pp. 372-378, 1983.
pp. 35-44.
HWANG: PARALLEL PROCESSING WITH SUPERCOMPUTERS 1379