adbis 2003 revisiting m-tree building principles tomáš skopal 1, jaroslav pokorný 2, michal...
TRANSCRIPT

ADBIS 2003
Revisiting M-tree Building Principles
Tomáš Skopal1, Jaroslav Pokorný2, Michal Krátký1, Václav Snášel1
1 Department of Computer ScienceVŠB-Technical University of Ostrava
Czech Republic
2 Department of Software EngineeringCharles University in Prague
Czech Republic

Presentation Outline
• Metric Indexing• M-tree
basic concepts motivation for the M-tree revision fat-factor multi-way insertion slim-down algorithm
• Experimental results• Conclusions

Multimedia Indexing
Reasons for indexing of multimedia databases:– Implementation of the mechanism “how to query”– Fast Retrieval
Oi = (251,250,251,251,249,...)
Vector model:
Multimedia document Feature vector

Multimedia Indexing, cont.
Every indexing model must follow a retrieval semantics. The multimedia indexing model must support the similarity queries.
Two types similarity queries:• range queries
return documents similar more than a given threshold
• k nearest neighbour queriesreturn the first k most similar documents

Metric Indexing
Feature vectors are indexed according to distances between each other.
As a dissimilarity measure, a distance function d(Oi,Oj) is specified such that the metric axioms are satisfied:
d(Oi,Oi) = 0 reflexivityd(Oi,Oj) > 0 positivityd(Oi,Oj) = d(Oj,Oi) symmetryd(Oi,Ok) + d(Ok,Oj) ≥ d(Oi,Oj) triangular inequality
Metric structures: Main memory structures: metric tree, vp-tree, mvp-treePersistent structures: M-tree, Slim-tree (modification of M-tree)

M-tree at a glance• indexing objects of a general metric space (not only vector spaces)
• up to this time the only persistent and balanced metric tree
• doesn’t directly use dimensions, just the distances between objects
(possible vector coordinates are handled by a metric defined by user)
• The correct M-tree hierarchy is guaranteed due to the triangular
inequality axiom of d. The hierarchy consists of nested metric regions.
• better resists to the „curse of dimensionality“ (it depends on the metric)
• the hierarchy of nodes allows to natively implement
the similarity queries
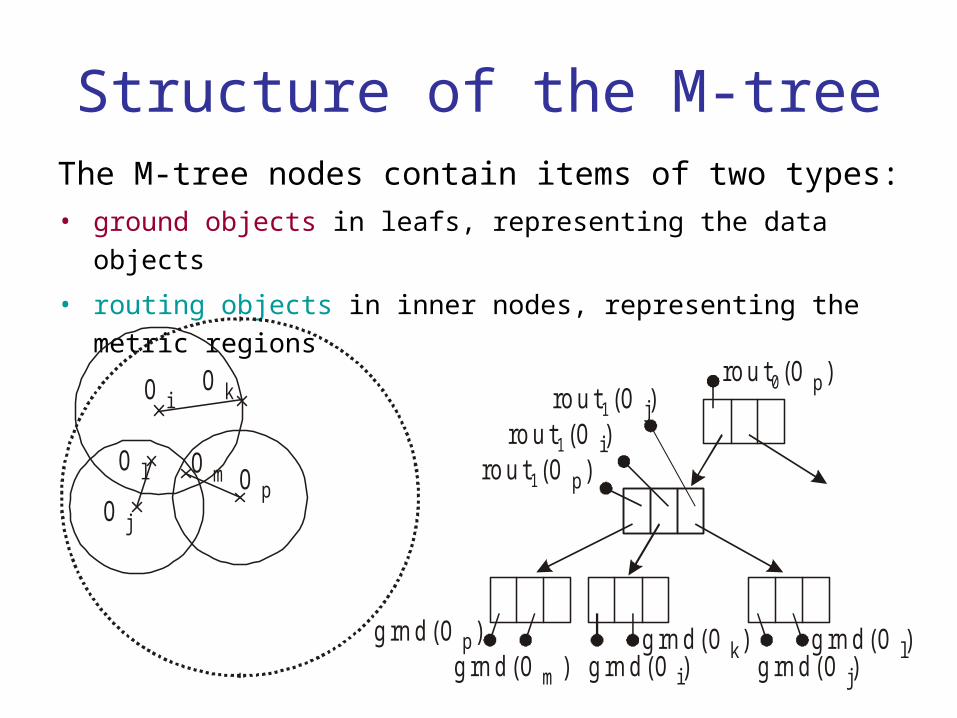
Structure of the M-treeThe M-tree nodes contain items of two types:• ground objects in leafs, representing the data objects
• routing objects in inner nodes, representing the metric regions
O j
O p
O kro u t )0(O p
ro u t )1(O p
g rn d (O p)
O i
O l O m
ro u t )1(O i
ro u t (O1 j)
g rn d (O m )g rn d (O k)
g rn d (O i)g rn d (O l)
g rn d (O j)

Similarity queries in the M-tree
O j
O p
O kro u t )0(O p
ro u t )1(O p
g rn d (O p)
O i
O l O m
ro u t )1(O i
ro u t (O1 j)
g rn d (O m )g rn d (O k)
g rn d (O i)g rn d (O l)
g rn d (O j)
Oq
A range query is specified by a query object Oq and a query radius rq. A k-NN query is based on a modified range query (using dynamic radius) and a priority queue.
During the range query evaluation, the M-tree is LIFO-passed and only the relevant (i.e. intersecting) metric regions (their nodes resp.) are further processed.

Internet-based applications: • huge public multimedia databases
(web pages, digital libraries, etc.)• millions of users
Which means:• to focus on higher retrieval efficiency
thousands of users query at a moment
• the building costs can increasethe index updates are much less frequent than querying
M-tree, revision motivation
O j
O p
O kro u t )0(O p
ro u t )1(O p
g rn d (O p)
O i
O l O m
ro u t )1(O i
ro u t (O1 j)
g rn d (O m )g rn d (O k)
g rn d (O i)g rn d (O l)
g rn d (O j)
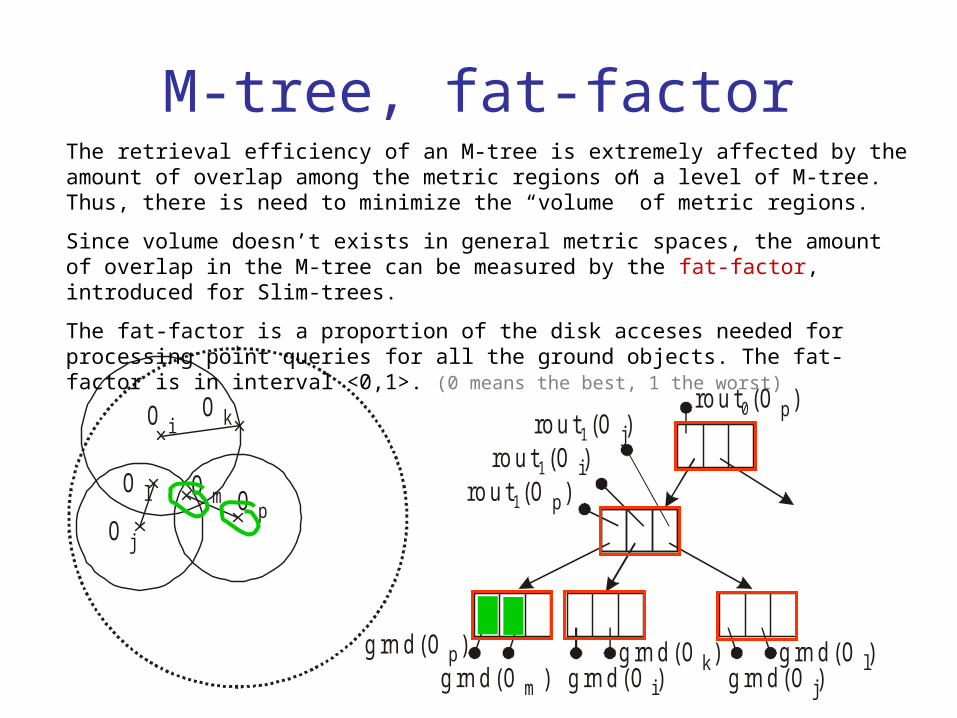
M-tree, fat-factorThe retrieval efficiency of an M-tree is extremely affected by the amount of overlap among the metric regions on a level of M-tree. Thus, there is need to minimize the “volume” of metric regions.
Since volume doesn’t exists in general metric spaces, the amount of overlap in the M-tree can be measured by the fat-factor, introduced for Slim-trees.
The fat-factor is a proportion of the disk acceses needed for processing point queries for all the ground objects. The fat-factor is in interval <0,1>. (0 means the best, 1 the worst)
O wO u
O v
O z
O j
O p
rout )0(O p
rout )1(O p
grnd(O p)
O l
O mrout )1(O i
rout (O1 j)
grnd(O m)grnd(O k)
grnd(O i)grnd(O l)
grnd(O j)
O k
O i
rout )0(Ow
rout )1(O u
rout )1(Ow
grnd(O z)grnd(O w)
grnd(O v)grnd(O u)
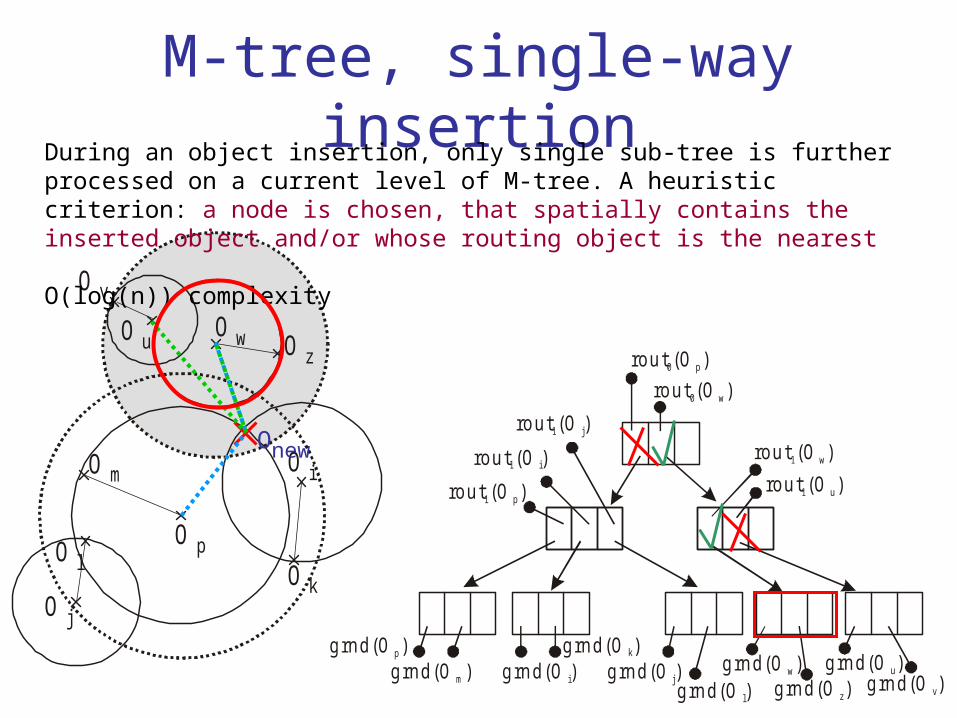
M-tree, single-way insertionDuring an object insertion, only single sub-tree is further processed on a current level of M-tree. A heuristic criterion: a node is chosen, that spatially contains the inserted object and/or whose routing object is the nearest
O(log(n)) complexity
Onew
O wO u
O v
O z
O j
O p
rout )0(O p
rout )1(O p
grnd(O p)
O l
O mrout )1(O i
rout (O1 j)
grnd(O m)grnd(O k)
grnd(O i)grnd(O l)
grnd(O j)
O k
O i
rout )0(Ow
rout )1(O u
rout )1(Ow
grnd(O z)grnd(O w)
grnd(O v)grnd(O u)
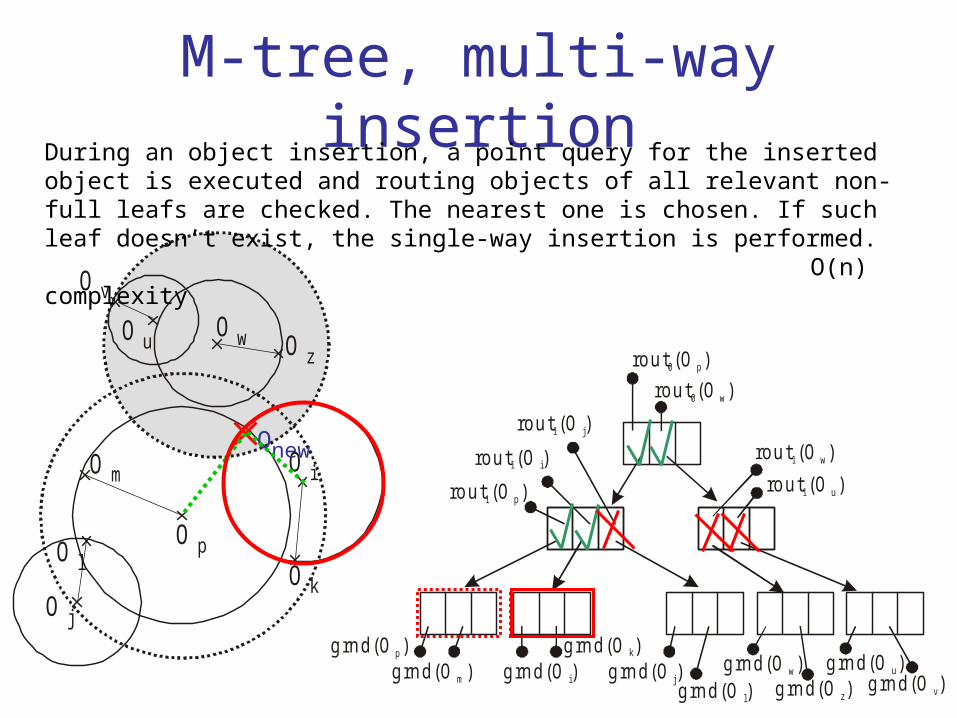
M-tree, multi-way insertionDuring an object insertion, a point query for the inserted object is executed and routing objects of all relevant non-full leafs are checked. The nearest one is chosen. If such leaf doesn’t exist, the single-way insertion is performed.
O(n) complexity
Onew

M-tree, slim-down algorithmA post-processing method inspired by Slim-trees, reducing the fat-factor of an M-tree.
In principle, it is a redistribution of ground objects, as well as routing objects within an existing M-tree. The redistribution is level-based, i.e. for each object the best node on the same level is tried to find (using an algorithm similar to point query). If such node is found the object is moved and the original node can me “slimmed”. The slimming starts for the leaf level and continues upwards for the higher levels.
Advantages: - a significant reduction of the fat-factor as well as of the retrieval costs - a stable algorithm (can be whenever interrupted and resumed or restarted)- doesn’t directly increase the insertion costs - e.g. can run in the “idle time”
Disadvantages:
- the overall computational complexity (for each object in index a point query must be processed)

Slim-down algorithm, exampleLet’s have a correct but poorly built M-tree. The regions are highly overlapping and the fat-factor is high.
Slimming the leaf level (Level 0)
Two ground objects can be moved to more appropriate leafs.
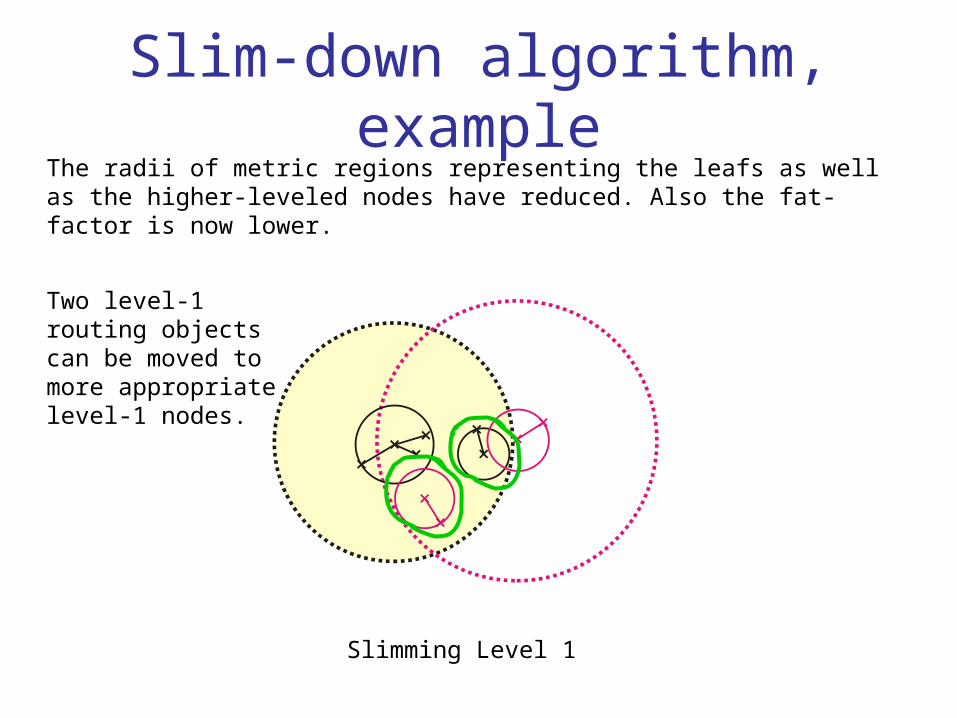
Slim-down algorithm, exampleThe radii of metric regions representing the leafs as well as the higher-leveled nodes have reduced. Also the fat-factor is now lower.
Slimming Level 1
Two level-1 routing objects can be moved to more appropriate level-1 nodes.

Slim-down algorithm, example
The slimmed M-tree
Again, the radii of metric regions as well as the fat-factor have reduced.
The root level cannot be slimmed because no parent node exists.

Experimental results
• synthetic datasets of clustered tuples
• used metric: L2 (Euclidean)
• dimensionality: 2 – 50• number of tuples: 20,000 – 1,000,000• index sizes: 1 – 400 MB• node capacity: 20• M-tree height: 3 – 5
Experiments were performed on an Intel Pentium®4, 2.53GHz, 512 MB DDR333, under Windows XP™ pro.
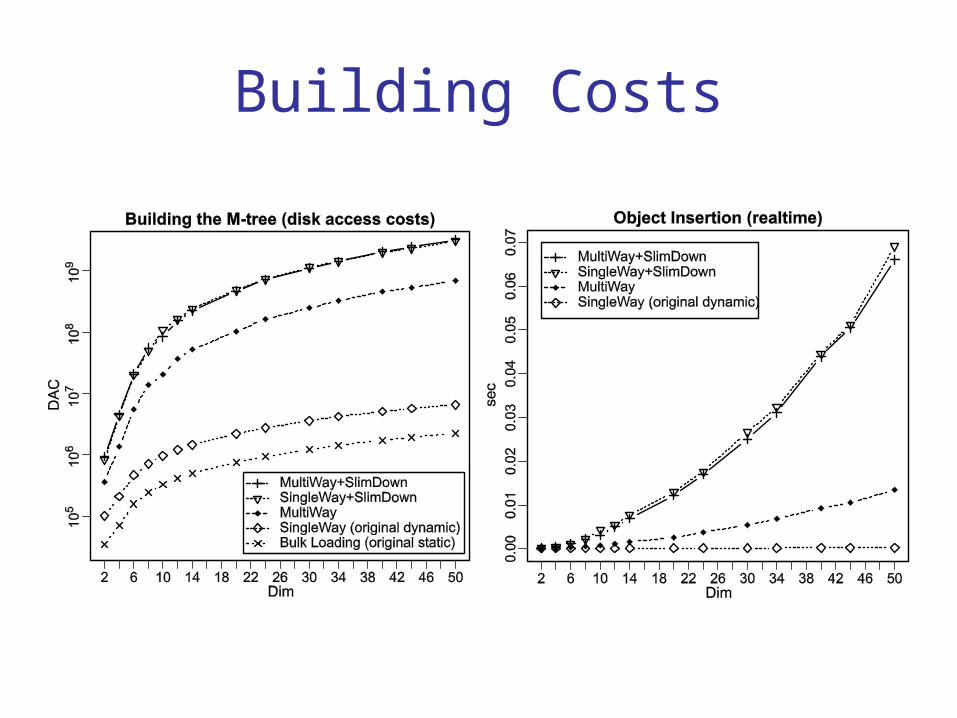
Building Costs

Fat-factor, node utilization
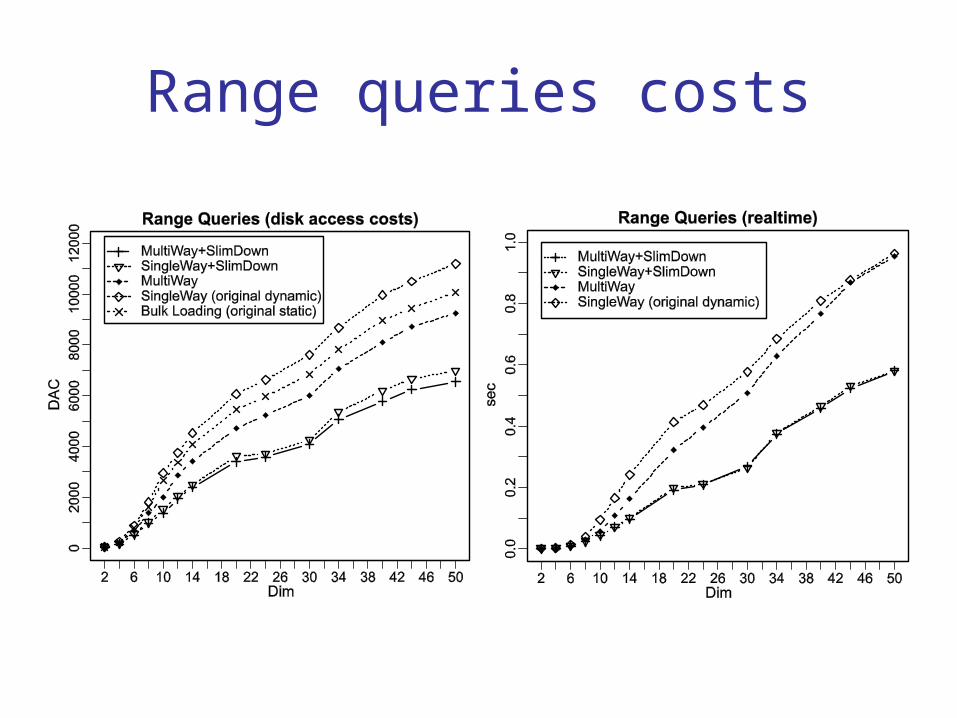
Range queries costs
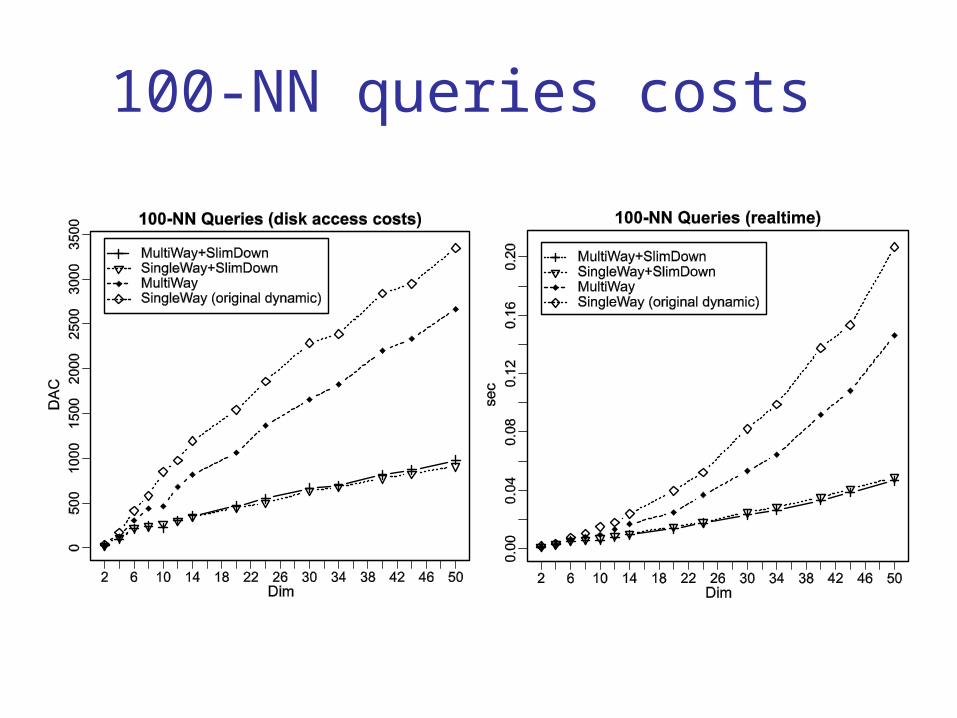
100-NN queries costs

Conclusions
New M-tree building techniques were proposed, improving the M-tree retrieval efficiency. These techniques are beneficial especially for modeling query-intensive MDBMS scenarios.
The multi-way insertion improves the M-tree retrieval efficiency by up to 50%.
The slim-down algorithm improves the M-tree retrieval efficiency by up to 300%.

References
T.Skopal, J.Pokorny, M.Kratky, V.Snasel. Revisiting M-tree Building Principles, ADBIS 2003, Dresden
P. Ciaccia, M. Patella, P. Zezula. M-tree: An Efficient Access Method for Similarity Search in Metric Spaces, VLDB 1997, Athens
C. Traina Jr., A. Traina, B. Seeger, C. Faloutsos. Slim-Trees: High performance metric trees minimizing overlap between nodes. LNCS 1777, 2000.