adaptive computing on the grid – the apples project francine berman u.c. san diego
Post on 20-Dec-2015
218 views
TRANSCRIPT

Adaptive Computingon the Grid –
The AppLeS Project
Francine Berman
U.C. San Diego

Computing Today
data archives
networks
visualizationinstruments
MPPs
clusters
PCs
Workstations
Wireless

Berman, UCSD
The Computational Grid
• Computational Grid is a collection of distributed, possibly heterogeneous resources which can be used as an ensemble to execute large-scale applications

Berman, UCSD
Grid Computing
• What is it?– Running parallel and distributed programs
on multiple resources by coordinating tasks and data
– Running any program on• whatever resources are available • resources which execute the program best
• Why is Grid Computing important?• Why is Grid Computing hard?

Berman, UCSD
Why is Grid Computing Important?
• Internet/Grid increasingly serving as execution platform for large-scale computations– Web browsing = large-scale distributed search
application– Seti@home = large-scale distributed data mining
application– Walmart uses network to support massive inventory
control applications– Remote instruments, visualization facilities connected
to computers for analysis in real-time through networks– Large distributed databases being developed for
science and engineering applications (Digital Sky, weather prediction, Digital Libraries, etc.)

Berman, UCSD
Why is Grid Computing Hard - I
• Difficult to achieve predictable program performance in dynamic, multi-user environments
• To achieve performance, programs must adapt to deliverable resource performance at execution time
OGI
UTK
UCSD

Berman, UCSD
Why is Grid Computing hard - II
• Lots of infrastructure needed:– Basic services (Grid middleware)
• Single login• Authentication• File transfer• Multi-protocol communication
– User environments (User-level middleware)• Development environments and tools• Application scheduling and deployment• Performance monitoring, analysis, tuning

Berman, UCSD
Grid Computing Lab Research
• Adaptive Grid Computing– The AppLeS Project
• User-level Middleware– APST
• New Directions: Megacomputing– Genome@home
• and other projects …

Berman, UCSD
Adaptive Grid Computing with AppLeS • Joint project with Rich Wolski (U. Tenn.)• Goal:
– To develop self-scheduling Grid programs which can adapt to deliverable Grid resource performance at execution time
• Approach:– Develop adaptive application schedulers which can
• predict program performance • use these predictions to determine the most performance-
efficient schedule• deploy the “best” schedule on Grid resources
within a reasonable timeframe

How Does AppLeS Work?
App+Sched Deployment
Resource Discovery
Resource Selection
SchedulePlanning
and Performance
Modeling
DecisionModel
accessible resources
feasible resource sets
evaluatedschedules
“best” schedule
Grid Middleware
NWS
AppLeS + application
= self-scheduling application
Resources

Network Weather Service (Wolski, U. Tenn.)
• NWS – monitors current system
state
– provides best forecast of resource load from multiple models
• NWS can provide dynamic resource information for AppLeS
• NWS is stand-alone system
Sensor Interface
Reporting Interface
Forecaster
Model 2 Model 3Model 1
Fast Ethernet Bandwidth at SDSC
0
10
20
30
40
50
60
70
Time of Day
Meg
abits
per
Sec
ond
Measurements
Exponential SmoothingPredictions
Tue Wed Thu Fri Sat Sun Mon Tue

An Example AppLeS: Simple SARA
• SARA = Synthetic Aperture Radar Atlas– application developed at JPL
and SDSC
• Goal: Assemble/process files for user’s desired image– Radar organized into tracks
– User selects track of interestand properties to be highlighted
– Raw data is filtered and converted to an image format
– Image displayed in web browser

Simple SARA• AppLeS focuses on resource selection problem:
Which site can deliver data the fastest?
• Code developed by Alan Su
Data serversmay storereplicated files
Network shared by variable number of usersCompute server
accesses target tracksfrom one or moredata servers
. . .ComputeServers
DataServers
Client

Simple SARA• Simple Performance Model
• Prediction of available bandwidth provided by Network Weather Service
• User’s goal is to optimize performance by minimizing file transfer time
• Common assumptions: (> = performs better)
– vBNS > general internet
– geographically close sites > geographically far sites
– west coast sites > east coast sites
andwidthAvailableB
DataSizeerTimeFileTransf

Experimental Setup• Data for image accessed over shared networks
• Data sets 1.4 - 3 megabytes, representative of SARA file sizes
• Servers used for experiments– lolland.cc.gatech.edu
– sitar.cs.uiuc
– perigee.chpc.utah.edu
– mead2.uwashington.edu
– spin.cacr.caltech.edu
via vBNS
via general internet

Experimental Results• Experiment with larger data set (3 Mbytes)
• During this time-frame, farther sites provide data faster than closer site

9/21/98 Experiments• Clinton Grand Jury webcast commenced at trial 25• At beginning of experiment, general internet provides
data faster than vBNS

Supercomputing ’99• From Portland SC’99 floor during experimental
timeframe, UCSD and UTK generally “closer” than Oregon Graduate Institute (OGI) in Portland
AppLeS/NWS
OGI
UTK
UCSD

Berman, UCSD
AppLeS Applications • We’ve developed many AppLeS applications
– Simple SARA (Su)– Jacobi2D (Wolski)– PMHD3D (Dail, Obertelli)– MCell (Casanova)– INS2D (Zagorodnov, Casanova)– SOR (Schopf)– Tomography (Smallen, Frey, Cirne, Hayes)– Mandelbrot, Ray tracing (Shao)– Supercomputer AppLeS (Cirne)– …

Berman, UCSD
User-level Middleware • AppLeS applications are “point solutions”
• What if we want to develop schedulers for structurally similar classes of applications?
• AppLeS “templates” are user-level middleware designed to promote performance and ease-of programming for application classes
• Current GCL template activity:– APST (Casanova)– AMWAT (Shao, Hayes)

Berman, UCSD
Example template: APST – AppLeS Parameter Sweep Template
• Common application structure used in various fields of science and engineering (Monte Carlo and other simulations, etc.)
• Joint work with Henri Casanova
• Large number of independent tasks
• First AppLeS Middleware package to be distributed to users
Parameter Sweeps = class of applications which are structured as multiple instances of an “experiment” with distinct parameter sets

Example Parameter Sweep Application – MCell
• MCell = General simulator for cellular microphysiology
• Uses Monte Carlo diffusion and chemical reaction algorithm in 3D to simulate complex biochemical interactions of molecules
• Simulation = many “experiments” conducted on different parameter configurations
– Experiments can be performed on separate machines
• Driving application for APST middleware

Berman, UCSD
APST Programming Model
• Why isn’t scheduling easy?
experiments

Berman, UCSD
APST Programming Model
• Why isn’t scheduling easy?– Staging of large shared files may complicate the scheduling process– Post-processing must minimize file transfer time– Adaptive scheduling necessary to account for dynamic environment

• Contingency Scheduling: Allocation developed by dynamically generating a Gantt chart for scheduling unassigned tasks between scheduling events
• Basic skeleton1. Compute the next scheduling event
2. Create a Gantt Chart G
3. For each computation and file transfer currently underway, compute an estimate of its completion time and fill in the corresponding slots in G
4. Select a subset T of the tasks that have not started execution
5. Until each host has been assigned enough work, heuristically assign tasks to hosts, filling in slots in G
6. Implement schedule
APST Scheduling Approach
1 2 1 2 1 2
Network links
Hosts(Cluster 1)
Hosts(Cluster 2)
Tim
e
Resources
Com
puta
tion
G
Schedulingevent
Schedulingevent
Com
puta
tion

Free “Parameters”
1. Frequency of scheduling events
2. Accuracy of task completion time estimates
3. Subset T of unexecuted tasks
4. Scheduling heuristic used
APST Scheduling
1 2 1 2 1 2
Network links
Hosts(Cluster 1)
Hosts(Cluster 2)
Tim
e
Resources
Com
puta
tion
G
Schedulingevent
Schedulingevent
Com
puta
tion

Berman, UCSD
APST Scheduling Heuristics
Self-scheduling Algorithms• workqueue• workqueue w/ work stealing• workqueue w/ work duplication• ...
Gantt chart heuristics:• MinMin, MaxMin• Sufferage, XSufferage• ...
Scheduling Algorithmsfor APST Applications
Easy to implement and quick No need for performance predictions Insensitive to data placement
More difficult to implement Needs performance predictions Sensitive to data placement
Simulation results (HCW ’00 paper) show that: • Heuristics are worth it• Xsufferage is good heuristic even when predictions are bad• Complex environments require better planning (Gantt chart)
Gantt Chart Algorithms• Min-min• Max-min• Sufferage, • XSufferage
Berman, UCSDNetSolveGlobus
Legion
NWS NinfIBP
Condor
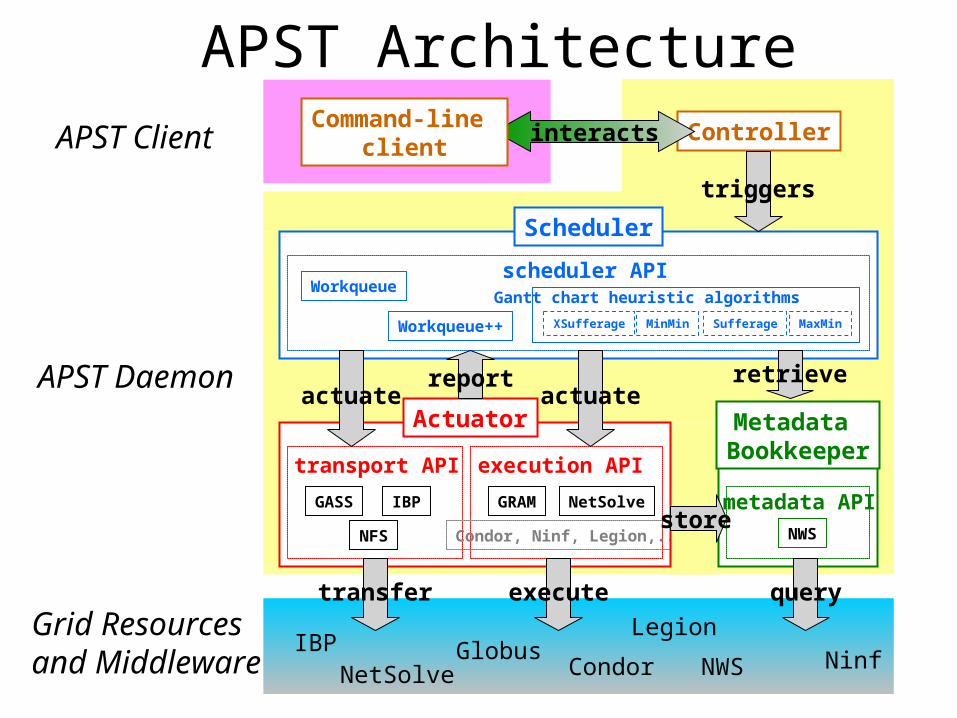
APST Architecture
transport API execution API
metadata API
scheduler API
Grid Resourcesand Middleware
APST Daemon
GASS IBP
NFS
GRAM NetSolve
Condor, Ninf, Legion,.. NWS
WorkqueueGantt chart heuristic algorithms
Workqueue++ MinMin MaxMinSufferageXSufferage
APST Client ControllerinteractsCommand-line
client
Metadata Bookkeeper
Actuator
Scheduler
triggers
transfer execute query
store
actuate actuatereport retrieve

Berman, UCSD
APST• APST being used for
– INS2D, INS3D (NASA Fluid Dynamics applications)– MCell (Salk, Biological Molecular Modeling application)– Tphot (SDSC, Proton Transport application)– NeuralObjects (NSI, Neural Network simulations)– CS simulation applications for our own research (Model validation)
• Actuator’s APIs are interchangeable and mixable– (NetSolve+IBP) + (GRAM+GASS) + (GRAM+NFS)
• Scheduler allows for dynamic adaptation, multithreading
• No Grid software is required– However lack of it (NWS, GASS, IBP) may lead to poorer performance
• Details in SC’00 paper
• Will be released in next 2 months to PACI, IPG users

Berman, UCSD
How Do We Know the APST Scheduling Heuristics are Good?
• Experiments:– We ran large-sized
instances of MCell across a distributed platform
– We compared execution times for both workqueue and Gantt chart heuristics.
University of Tennessee, Knoxville
NetSolve+
IBP
University of California, San Diego
GRAM+
GASS
Tokyo Institute of Technology
NetSolve+
NFS
NetSolve+
IBP
APST DaemonAPST Client

Berman, UCSD
ResultsExperimental Setting:
Mcell simulation with 1,200 tasks:• composed of 6 Monte-Carlo simulations• input files: 1, 1, 20, 20, 100, and 100 MB
4 scenarios:
Initially(a) all input files are only in Japan(b) 100MB files replicated in California(c) in addition, one 100MB file replicated in Tennessee(d) all input files replicated everywhere
workqueue
Gantt-chart algs

Berman, UCSD
New GCL Directions: Megacomputing (Internet Computing)
• Grid programs– Can reasonably obtain some
information about environment (NWS predictions, MDS, HBM, …)
– Can assume that login, authentication, monitoring, etc. available on target execution machines
– Can assume that programs run to completion on execution platform
• Mega-programs– Cannot assume any
information about target environment
– Must be structured to treat target device as unfriendly host (cannot assume ambient services)
– Must be structured for “throwaway” end devices
– Must be structured to run continuously

Berman, UCSD
Success with Megacomputing• Seti@home
– Over 2 million users– Sustains over 22
teraflops in production use
• Entropia.com • Can we run non-
embarrassingly parallel codes successfully at this scale?– Computational
Biology, Genomics …
– Genome@home

Berman, UCSD
Genome@home• Joint work with Derrick
Kondo, Joy Xin, Matt DeVico
• Application template for peer-to-peer platforms
• First algorithm (Needleman-Wunsch Global Alignment) uses dynamic programming
• Plan is to use template with additional genomics applications
• Being developed for internet rather than Grid environment
G T A A G
A 0 0 1 1 0
T 0 1 0 1 1
A 0 0 2 2 1
C 0 0 1 2 2
C 0 0 1 2 2
G 1 0 1 2 3
Optimal alignments determined by traceback

Berman, UCSD
Mega-programs• Provide the algorithmic/application counterpart for very large scale
platforms– peer-to-peer platforms, Entropia, etc.– Condor flocks– Large “free agent” environments– Globus– New platforms: networks of low-level devices, etc.
• Different computing paradigm than MPP, Grid
Globus free agents…Entropia Condor
DNAAlignment
Genome@home
Algorithm 2
Algorithm 3

Berman, UCSD
• Thanks!– NSF, NPACI, NASA IPG,
TITECH, UTK
• Coming soon to a computer near you:
– Release of APST and AMWAT (AppLeS Master/ Worker Application Template) v0.1 by NPACI All-hands meeting (Feb ’01)
– First prototype of genome@home: 2001
– GCL software and papers: http://gcl.ucsd.edu
• Grid Computing Lab:– Fran Berman ([email protected])– Henri Casanova– Walfredo Cirne– Holly Dail– Matt DeVico– Marcio Faerman– Jim Hayes– Derrick Kondo– Graziano Obertelli– Gary Shao– Otto Sievert– Shava Smallen– Alan Su– Atsuko Takefusa (visiting)– Renata Teixeira– Nadya Williams– Eric Wing– Qiao Xin

Berman, UCSD
Parameter Sweep Heuristics• Currently studying scheduling heuristics useful for parameter sweeps in
Grid environments
• HCW 2000 paper compares several heuristics– Min-Min [task/resource that can complete the earliest is assigned first]
– Max-Min [longest of task/earliest resource times assigned first]
– Sufferage [task that would “suffer” most if given a poor schedule assigned first, as computed by max - second max completion times]
– Extended Sufferage [minimal completion times computed for task on each cluster, sufferage heuristic applied to these]
– Workqueue [randomly chosen task assigned first]
• Criteria for evaluation:
– How sensitive are heuristics to location of shared input files and cost of data transmission?
– How sensitive are heuristics to inaccurate performance information?

APST/MCell Simulation Results with “Quality of Information”