adam induces implicit weight sparsity in rectifier neural ... · †[email protected]...
TRANSCRIPT
arX
iv:1
812.
0811
9v1
[cs
.LG
] 1
9 D
ec 2
018
978-1-5386-6805-4/18/$31.00 © 2018 IEEEDOI 10.1109/ICMLA.2018.00054
Adam Induces Implicit Weight Sparsity in Rectifier
Neural Networks
Atsushi Yaguchi∗, Taiji Suzuki†‡, Wataru Asano∗, Shuhei Nitta∗, Yukinobu Sakata∗, Akiyuki Tanizawa∗
∗Corporate Research and Development Center, Toshiba Corporation, Kawasaki, Japan†Graduate School of Information Science and Technology, The University of Tokyo, Japan
‡Center for Advanced Integrated Intelligence Research, RIKEN, Tokyo, Japan∗atsushi.yaguchi, wataru.asano, shuhei.nitta, yuki.sakata, [email protected]
Abstract—In recent years, deep neural networks (DNNs) havebeen applied to various machine leaning tasks, including imagerecognition, speech recognition, and machine translation. How-ever, large DNN models are needed to achieve state-of-the-artperformance, exceeding the capabilities of edge devices. Modelreduction is thus needed for practical use. In this paper, we pointout that deep learning automatically induces group sparsity ofweights, in which all weights connected to an output channel(node) are zero, when training DNNs under the following threeconditions: (1) rectified-linear-unit (ReLU) activations, (2) an L2-regularized objective function, and (3) the Adam optimizer. Next,we analyze this behavior both theoretically and experimentally,and propose a simple model reduction method: eliminate the zeroweights after training the DNN. In experiments on MNIST andCIFAR-10 datasets, we demonstrate the sparsity with varioustraining setups. Finally, we show that our method can efficientlyreduce the model size and performs well relative to methods thatuse a sparsity-inducing regularizer.
Index Terms—deep neural networks, model reduction, groupsparse, Adam
I. INTRODUCTION
Recently, deep learning has been successfully applied in
various machine learning tasks [1]. For example, it surpassed
human performance at an image recognition task on the
ImageNet dataset [2]. These successes are supported by the
development of activation functions such as ReLU [3], regu-
larization and normalization methods such as dropout [4] and
batch normalization (BN) [5], and network architectures such
as ResNet [6]. Recent successes are also enabled by the growth
of training datasets and increases in computing power. Because
wider or deeper network models have become necessary to
achieve high performance, hardware with limited memory and
computational power are unable to match this performance.
Reducing model size is necessary if applications, such as video
recognition for automated driving systems and surveillance
systems, are to run on edge devices, but this reduction of
model size lowers accuracy.
Various methods have been proposed for model reduction
[7]–[13]. Shi et al. [7] and Han et al. [8] reduced the
amount of computation and data without changing the original
network architecture. Shi et al. [7] did this by exploiting the
sparsity of ReLU activations to reduce the computational load
of convolution. Han et al. [8], in contrast, compressed the
amount of data by quantizing weight coefficients. Other model
0
1
2
3
4
5
6
0 50 100 150 200 250 300 350 400
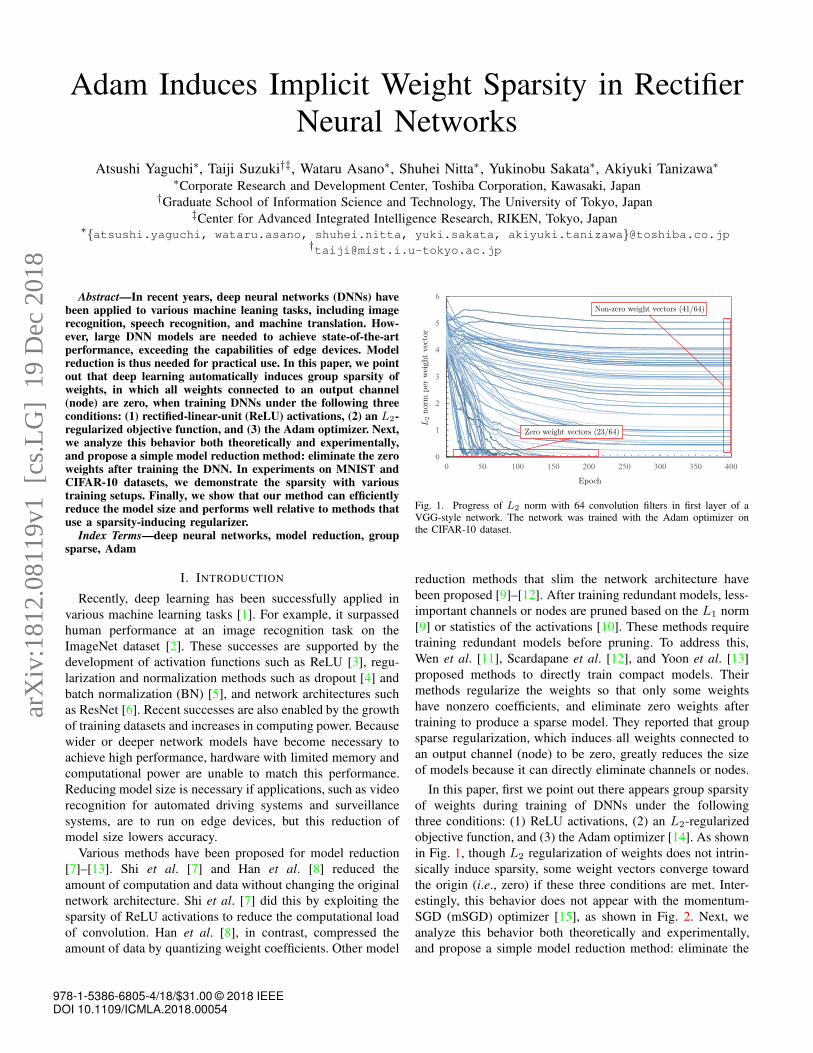
Fig. 1. Progress of L2 norm with 64 convolution filters in first layer of aVGG-style network. The network was trained with the Adam optimizer onthe CIFAR-10 dataset.
reduction methods that slim the network architecture have
been proposed [9]–[12]. After training redundant models, less-
important channels or nodes are pruned based on the L1 norm
[9] or statistics of the activations [10]. These methods require
training redundant models before pruning. To address this,
Wen et al. [11], Scardapane et al. [12], and Yoon et al. [13]
proposed methods to directly train compact models. Their
methods regularize the weights so that only some weights
have nonzero coefficients, and eliminate zero weights after
training to produce a sparse model. They reported that group
sparse regularization, which induces all weights connected to
an output channel (node) to be zero, greatly reduces the size
of models because it can directly eliminate channels or nodes.
In this paper, first we point out there appears group sparsity
of weights during training of DNNs under the following
three conditions: (1) ReLU activations, (2) an L2-regularized
objective function, and (3) the Adam optimizer [14]. As shown
in Fig. 1, though L2 regularization of weights does not intrin-
sically induce sparsity, some weight vectors converge toward
the origin (i.e., zero) if these three conditions are met. Inter-
estingly, this behavior does not appear with the momentum-
SGD (mSGD) optimizer [15], as shown in Fig. 2. Next, we
analyze this behavior both theoretically and experimentally,
and propose a simple model reduction method: eliminate the

0
0.1
0.2
0.3
0.4
0.5
100 200 300 400 500 600 700 800 900 1000
0
0.1
0.2
0.3
0.4
0.5
100 200 300 400 500 600 700 800 900 1000
Fig. 2. L2 norm for 1000 weight vectors connecting from an input layer to a hidden layer in a 3-layer fully connected neural network (sorted in descendingorder). The network was trained with mSGD and the Adam optimizer on the MNIST dataset with the same settings for L2 regularization and number oftraining steps. “Sparsity” indicates the ratio of zero weight vectors to all vectors.
zero weights after training the DNN. Our method is easy to op-
timize since it does not rely on sparsity-inducing (non-smooth)
regularizers such as L2,1 norm, and can efficiently control the
model size by calibrating the parameter of L2 regularization.
In experiments, we demonstrate the sparsity on the MNIST
and CIFAR-10 datasets with various training setups, and show
our method can effectively reduce the model size relative to
methods that use a sparsity-inducing regularizer.
In the following, we first give our problem setting and
propose a method for model reduction (Section II), then
describe its theoretical analysis (Section III). After we briefly
review related works (Section IV), we give some experimental
results (Section V) and conclude the paper (Section VI).
II. PROPOSED METHOD
A. Problem Setting
We consider an L-layer network with parameters Θ =
W(l),b(l)L
l=2, where W(l) =
(
w(l)1 ,w
(l)2 , . . . ,w
(l)
C(l)
)
∈R
W (l−1)H(l−1)C(l−1)×C(l)
is the weight matrix between
layer l − 1 and layer l whose columns are the per-
channel weight vectors. The corresponding bias is b(l) =(
b(l)1 , b
(l)2 , . . . , b
(l)
C(l)
)⊤∈ R
C(l)
. The kernel width is W (l−1),
the kernel height is H(l−1), and the numbers of input and
output channels are C(l−1) and C(l), respectively. Fig. 3 illus-
trates the weight vectors in fully connected and convolution
layers. Note that the number of channels equals the number
of nodes in the fully connected layer, which corresponds to
the case of W (l−1) = H(l−1) = 1.
Let η(·) be an activation function. An input vector to a layer
l is then computed as x(l) = η(
W(l)⊤x(l−1) + b(l))
for the
fully connected layer. x(l) should be defined at each spatial
location for the convolution layer, but we use the notation of
the fully connected layer for simplicity. The parameters Θ are
learned by the optimization problem
minΘ
1
N
N∑
n=1
L (un,vn,Θ) +R (Θ) , (1)
where L(·) and R(·) represent a loss function and a regu-
larization function, respectively. u ∈ RDin and v ∈ R
Dout
are an input and a target vector, respectively, for the network,
and N is the number of samples in the training set. Instead
of using all samples in each timestep of the optimization, we
utilize a mini-batch of size M , in which samples are drawn
independently and uniformly from the training set.
B. Model Reduction
To reduce the model size, we utilize group sparsity by prun-
ing weights under a threshold, that is, we prune column vectors
w(l)k
(
k = 1, . . . , C(l))
in W(l), satisfying ‖w(l)k ‖2 < ξ for a
small positive constant ξ. We induce sparsity by imposing the
L2 regularization on each weight vector. We therefore define
the regularization function as
R (Θ) =λ
2
L∑
l=2
‖W(l)‖2F (λ > 0) , (2)
where λ is a regularization parameter, and ‖·‖F indicates
the Frobenius norm. We use ReLU [3], given as η(x) =max(x, 0), as the activation function for each non-output layer,
and optimize the objective function by using Adam [14]. Its
update rule for a parameter θ is given by
mt = β1mt−1 + (1− β1) gt (0 < β1 < 1)vt = β2vt−1 + (1− β2) g
2t (0 < β2 < 1)
θt = θt−1 − αmt/(1−βt
1)√
vt/(1−βt2)+ǫ
(ǫ > 0), (3)
where gt is the gradient at timestep t; β1, β2, and ǫ are positive
constants.
The flow of our method is shown in Algorithm 1 as
pseudocode. After training the network, the size is reduced by
eliminating all weight vectors having L2 norm smaller than a
threshold ξ. Since the weights converge to near the origin, it
is easy to select the threshold. Our method can also effectively
reduce the model size by directly eliminating channels or
nodes.

Fig. 3. Illustrations of weight vectors in fully connected and convolutionlayers.
III. THEORETICAL ANALYSIS
In this section, we mathematically describe the mechanism
of the sparsity and analyze convergence under certain condi-
tions.
A. Preliminaries
The gradient with respect to w(l)k , the kth weight vector in
layer l, is given by
g(l)k =
1
M
M∑
i=1
∂L (ui,vi,Θ)
∂x(l)ik
∂x(l)ik
∂w(l)k
+ λw(l)k . (4)
If the activation function is ReLU,
∂x(l)ik
∂w(l)k
=
x(l−1)i (w
(l)k
⊤x(l−1)i + b
(l)k > 0)
0 (w(l)k
⊤x(l−1)i + b
(l)k ≤ 0)
, (5)
then the gradient becomes
g(l)k =
1
M
∑
j:w(l)k
⊤
x(l−1)j
+b(l)k
>0
∂L (uj ,vj ,Θ)
∂x(l)jk
x(l−1)j + λw
(l)k .
(6)
Thus, if there are only a few samples satisfying w(l)k
⊤x(l−1)j +
b(l)k > 0 (i.e., activated samples), g
(l)k ≈ λw
(l)k , and the vanilla-
SGD is used as the optimizer with a step size α, then the
weight is updated as w(l)k ← w
(l)k −αλw
(l)k = (1− αλ)w
(l)k ,
which means the weight decays to zero if 0 < αλ < 1. From
the observation that 50 – 90% of ReLUs are not activated [3]
[7], we assume the gradient of the regularization should
be dominant for weights connected to such less-activated
ReLUs, which induces the convergence to zero. As shown in
Fig. 2, however, this behavior does not appear with mSGD.
We believe this is due to the difference in convergence rate
between the optimizers.
We conducted a preliminary experiment with the Adam
optimizer under the condition that g(l)k ≈ λw
(l)k , and found
that after the weight decays to a certain level, it oscillates
near the origin, as shown in Fig. 4. For example, a weight
decreased from an initial value of 0.2 and then began to
oscillate around 10−10. This oscillation is not observed with
mSGD. In Theorem III.2 in the following subsection, we give
the decay rate for Adam under the pre-oscillation condition.
Algorithm 1 Learning and reducing network
Require: Network with ReLU activations and learnable pa-
rameters Θ =
W(l),b(l)L
l=2Require: Stochastic objective function with L2 regularization
Require: Initial parameters Θ0, an L2-regularization param-
eter λ > 0, and a norm threshold parameter ξ > 01: t← 0 (Initialize timestep)
2: while Θt not converged do
3: t← t+ 14: Compute Θt with Adam
5: end while
6: for l = 2, . . . , L do
7: Eliminate
w(l)k
∣
∣
∣ ‖w(l)k ‖2 < ξ, k = 1, . . . , C(l)
from Θt
8: end for
9: return learned network with reduced parameters Θt
-50
-40
-30
-20
-10
0
10
20
30
40
50
0 500 1000 1500 2000 2500
Fig. 4. Convergence behavior of wt under Adam. The zero point in thevertical axis corresponds to near the origin (10−40).
B. Convergence Analysis
Here, for simplicity of notation, we omit the indices k and
l and use the subscript t to indicate the timestep, then use
a scalar weight denoted by wt. We suppose a non-activation
situation in which the gradient of the loss is zero; thus, gt =λwt. Detailed proofs of the following theorems are given in
the appendices.
Proposition III.1. Let µ = 1+αλ− q√αλ for q > 2. Under
conditions (1 − αλ + µ)2 − 4µ ≥ 0 and 0 < λα < 1, wt
decays at rate O
(
(
1− q−√
q2−4
2
√αλ
)t)
for mSGD.
Therefore, ifq−√
q2−4
2
√αλ ≥ αλ, then we obtain a conver-
gence rate faster than the O(
(1− αλ)t)
given by SGD. In
particular, we obtain a convergence rate similar to Nesterov’s
acceleration [16].
Theorem III.2. Without loss of generality, we may suppose
w0 > 0. Then, as long as t satisfies that wτ > 0 for 1 ≤ τ ≤ t,wt decays as wt = O (exp (−2t)) for Adam.
The above convergence rate is doubly exponential. Therefore,

to achieve wt ≤ δ, we require only t = Ω(log log(1/δ)) steps.
We recall that SGD and mSGD require t = Ω(log(1/δ)) steps
to achieve wt ≤ δ. Thus, the solution with Adam becomes
smaller than sufficiently small δ more rapidly than with SGD
and mSGD. We believe this rapid decay before oscillation
contributes to the sparsity with Adam.
Although our theorem for Adam does not guarantee con-
vergence to the origin, we have the following proposition.
Proposition III.3. If wt converges to w∗ as t→∞, then the
limit point must satisfy w∗ = 0.
Substituting a condition: gt = λwt into Eq. (3), the step size
of Adam for a sufficiently large t can be represented as
|wt − wt−1| =
∣
∣
∣
∣
∣
∣
−α 1− β1√
(1− β2)
∑t−1i=0 β
t−1−i1 wi
√
∑t−1i=0 β
t−1−i2 w2
i + ǫ
∣
∣
∣
∣
∣
∣
.
If wt converges to w∗, then as∑∞
τ=t βτ1 → 0,
∑∞τ=t β
τ2 → 0
for t → ∞, it holds that letting ǫ = ǫ∑
ti=0 βi
2, the step size
becomes
|wt+1 − wt| =
∣
∣
∣
∣
∣
∣
∣
∣
−α(1− β1)
∑ti=0
βi1
√
(1− β2)∑t
i=0βi2
w∗ + o(1)√
(w∗)2 + ǫ
∑
ti=0 βi
2
+ o(1)
∣
∣
∣
∣
∣
∣
∣
∣
=
∣
∣
∣
∣
∣
∣
∣
−α
(
1− βt1
)
√
(
1− βt2
)
w∗
√
(w∗)2 + ǫ
+ o(1)
∣
∣
∣
∣
∣
∣
∣
t→∞
−→
∣
∣
∣
∣
∣
∣
∣
−αw∗
√
(w∗)2 + ǫ
∣
∣
∣
∣
∣
∣
∣
.
The above must be a Cauchy sequence if it converges; that
is, the step size must be 0, which is satisfied with w∗ = 0.
IV. RELATED WORK
In this section, we briefly review related works, including
analyses on training DNNs from the viewpoints of activation
functions and optimizers, and methods of model reduction.
Group sparsity as discussed in this paper relates to the
vanishing gradient problem [17], which is generally caused
by saturation nonlinearities such as sigmoid and tanh. These
functions have certain regimes in which the gradient vanishes,
and ReLU also possesses such a regime (specifically, x < 0).
Li et al. [18] showed that unsupervised pretraining encourages
sparse activations with sigmoid and ReLU in the resulting
DNNs. Though it has been known that some units never
activate across the entire training dataset, the so-called dying-
ReLU [19], detailed analysis of this has not been reported. The
remedy for this problem is leaky-ReLU [20] given by
η(x) =
x (x > 0)ρx (x ≤ 0)
, (7)
which parameterizes the negative slope (ρ) to prevent its
gradients from vanishing in the negative regime. In the next
section, we compare various activation functions, including
leaky-ReLU and saturation nonlinearities, in terms of sparsity.
SGD is a common optimizer for training DNNs. It is a
simple method but achieves good generalization performance
by careful tuning of step-size and acceleration via the mo-
mentum term [15]. In contrast, adaptive gradient methods,
including Adagrad [21], RMSprop [22], Adam [14], and
AdaDelta [23], commonly attain faster convergence than the
SGD by automatically adjusting the step size. Compared
with the SGD, however, their generalization performances are
worse in many cases. Theoretical analysis has been conducted,
and improvements have been reported [24]–[26]. Wilson et
al. [24] proved that the adaptive methods do not converge
to an optimum in a simple convex optimization problem.
Reddi et al. [25] proved that the non-convergence of Adam is
due to the step-size scaling according to the moving average
of the squared gradient, and proposed an improved method,
AMSGRAD. Loshchilov et al. [26] proposed AdamW, which
decouples the weight-decay term from the update rule of
Adam, and showed it achieves performance similar to that
of mSGD. Despite these analyses of Adam, it has not been
reported that Adam induces implicit weight sparsity in training
DNNs. In the next section, we compare Adam against various
optimizers including mSGD, adaptive gradient methods, and
the improved methods of Adam [25], [26].
There are two broad approaches to model reduction: pruning
redundant weights after learning and learning with sparsity-
inducing regularizers on weights. In an example of the former
approach, Li et al. [9] exploit the L1 norm of weight vectors
to prune less important channels after learning the DNN, and
Polyak et al. [10] do the same based on the statistics of
ReLU activations. However, selecting the pruning threshold
is difficult, and fine-tuning after pruning is necessary for
recovering the accuracy. In our method, since the weights
converge to near the origin, it is easy to select the threshold,
which only need to be smalls, such as 10−15, and the fine-
tuning is optional. In the latter approach, Wen et al. [11],
Scardapane et al. [12], and Yoon et al. [13] minimize the L2,1
norm of weight vectors with the objective function so that
channel-level group sparsity is obtained. Our method yields
sparsity based on the L2 norm, which is a smooth function,
making it easy to optimize. We show the effectiveness of our
method relative to the other methods [11] [12] below.
V. EXPERIMENTS
In this section, we demonstrate the sparsity under various
training setups and compare our model reduction method with
others that use sparsity-inducing regularizers. The experiments
were on image classification tasks using MNIST [28] and
CIFAR-10 datasets [29]. In all experiments on both datasets,
we used softmax function in output layer and cross-entropy
loss for training networks.
A. Demonstration of Sparsity
On the MNIST dataset, we used fully connected networks
with the experimental setup summarized in Table I as the

TABLE IBASELINE SETUP OF EXPERIMENTS ON MNIST DATASET.
Preprocess divide each pixel value by 255Data augmentation NoBatch size / #epochs 64 / 100Learning rate schedule multiplied by 0.5 every 25 epochs
L2-norm threshold ξ = 1.0× 10−15
L2 regularization Yes (λ = 5.0× 10−4)# hidden layers 1# nodes per layer 1000Activation function ReLUBatch normalization Yes (before activation)Initializer Xavier [27] for weights, 0 for biasesOptimizer Adam
(α = 0.001, β1 = 0.9, β2 = 0.999, ǫ = 10−8)
TABLE IICOMPARISONS WITH DIFFERENT OPTIMIZERS, ACTIVATION FUNCTIONS,
AND OTHER COMPONENTS ON MNIST DATASET.
Optimizer Adam (baseline) mSGD adagrad RMSprop
Acc. [%] 98.43 98.35 98.31 98.31Sparsity [%] 70.00 0.00 0.00 65.20
Activation ReLU (baseline) tanh ELU sigmoidAcc. [%] 98.43 98.39 98.27 98.42Sparsity [%] 70.00 1.70 77.00 0.00
Others baseline He init. w/o BN w/o L2 reg.
Acc. [%] 98.43 98.42 98.26 98.45Sparsity [%] 70.00 68.70 82.10 0.00
baseline, and evaluated different activation functions, opti-
mizers, and other components. Table II shows the validation
accuracy and sparsity of the weight vectors produced by the
different setups. There is not much difference in terms of
accuracy, but the sparsity varies for each component. Near
the top of Table II, RMSprop yields sparsity as well as that
of Adam. RMSprop is basically a special case of Adam by
setting β1 = 0, and we see it has similar convergence. The
middle of Table II shows the results for different activation
functions. Sparsity is obtained by ReLU and by exponential
linear units (ELU) [30]. Since its gradients mostly vanish in
the negative regime except near the origin, we see it behaves
like ReLU, that is, the gradient of the objective function is
dominated by that of L2 regularization, and it yields similar
sparsity. While tanh obtains only limited sparsity, it indicates
that saturation nonlinearities have the potential for sparsity. We
also investigated the behavior of leaky-ReLU [20]. We plotted
the distributions of L2 norm with changing its negative slope ρas shown in Fig. 5. In the case of ρ = 0, which corresponds to
ReLU, we can see there are two modes: the lower mode for
(near-) zero weights and the other mode for active weights.
Observing that the lower mode shifts as the negative slope
increases, we see that leaky-ReLU can alleviate the decay of
weights by propagating gradients for negative inputs.
Additionally, we evaluated the behavior with an initializer
proposed by He et al. [2] and with or without BN layer
and L2 regularization. The bottom of Table II shows that the
initializer and BN layer make no appreciable difference, but
L2 regularization is needed for sparsity, as expected. Next, we
10-16 10-14 10-12 10-10 10-8 10-6 10-4 10-2 100
0
10-10
10-9
10-8
10-7
10-6
10-5
10-4
10-3
10-2
10-1
1
+5000
Fig. 5. Distributions of L2 norm per weight vector for the negative slope ofleaky-ReLU.
0
1
2
3
4
5
6
0 50 100 150 200
0
0.2
0.4
0.6
0.8
1
0 50 100 150 200
Fig. 6. Progress of L2 norm (upper) and activation rate (lower) with 23convolution filters in first layer of a VGG-style network. The network wastrained with Adam and mSGD on the CIFAR-10 dataset.
investigated the effects of the number of nodes in the hidden
layer and the number of layers in the network. Table III shows
the validation accuracy and number of retained weight vectors
(i.e., nodes) after training for the different number of nodes.
It can be observed that networks having a small number of
nodes results in low accuracy and the weights of those are
fully retained. We attribute this to such networks not being
redundant, meaning that each node in the networks contributes
to decreasing the loss (i.e., each node is well activated). In
contrast, the numbers of retained weights (and accuracies) in
networks with more than 500 nodes were almost identical.
This result indicate that wide networks can be reduced to a
certain narrow model without sacrificing accuracy. The results
with different number of layers are shown in Table IV, where
each network was trained with 1000 nodes in each layer. The
results indicate that the number of retained weights becomes
small in the deeper layers (except for the last hidden layer).
On the CIFAR-10 dataset, we trained a VGG-style covolu-
tional neural network with almost the same setup as in [31].
During a preprocessing step, each image was normalized to
have mean 0 and standard deviation 1 over three channels, and

TABLE IIICOMPARISONS WITH DIFFERENT NUMBERS OF HIDDEN NODES ON MNIST DATASET.
# of nodes 10 50 100 500 1000 (baseline) 2000
Acc. [%] 93.92 97.46 98.17 98.48 98.43 98.45# of remaining weights 10 50 100 291 300 288
TABLE IVCOMPARISONS WITH DIFFERENT NUMBERS OF HIDDEN LAYERS ON MNIST DATASET.
# of hidden layers 1 (baseline) 2 3 4 5
Acc. [%] 98.43 98.73 98.78 98.88 98.68# of remaining weights in each hidden layer 300 128-227 153-75-186 177-78-76-160 168-87-73-75-160
horizontal flipping was applied as data augmentation. We again
used the initializer proposed by He et al. [2] for weights and
applied dropout [4] to convolution and fully connected layers,
as in [31]. With the same parameter of λ = 5.0 × 10−4, we
compared against other optimizers: mSGD, AMSGRAD [25],
and AdamW [26]. An initial learning rate of 0.1 was used
for mSGD and 0.0005 for the others. The batch size, learning
rate scheduling, and L2-norm threshold for model reduction
are shown in Table I. The maximum validation accuracy
during the training for 400 epochs and the ratio of reduced
parameters at that time are reported in Table V. We can see
that parameters are not reduced by AMSGRAD and AdamW,
that is, these optimizers do not induce sparsity. Instead of using
the moving average of the squared gradient, AMSGRAD uses
its maximum until each timestep. Thus, AMSGRAD does not
induce sparsity because the step-size tends to decrease as the
training progresses, and so weights decay more slowly. For
AdamW, the lack of sparsity is because the rate of decay in the
weights is similar to that of SGD since the weight-decay term
is decoupled from the step-size computation of Adam. We can
see that Adam achieves accuracy similar to that of AMSGRAD
but reduces more than 50% of parameters. However, there is
still a gap in accuracy between Adam and mSGD. We suspect
that this gap may result from the implicit weight sparsity of
Adam.
Next, we observed relationships between activation rate
of channels (ReLUs) and L2 norm of their weight vectors
during the training. We again trained a VGG-style network by
Adam and mSGD with the same setups as above. We picked
up 23 of 64 filters in first convolution layer, which resulted
in convergence to zero with Adam. The progress of their
activation rate and L2 norm with both optimizers is illustrated
in Fig. 6, respectively. Activation rate of a filter was computed
as follows: counted nonzero pixels in a feature map after the
ReLU layer; divided it by the feature map size; and computed
it for all training images, then averaged it. In Fig. 6, we can see
that L2 norm and activation rate with Adam jointly decrease
to zero while those with mSGD converge to some nonzero
values as the training progress. This observation indicates that
activation rate of ReLU decreases in conjunction with L2 norm
of its input weight vector. Thus, we see that the weight decays
rapidly with Adam even when ReLU is not completely inactive
TABLE VCOMPARISONS WITH DIFFERENT OPTIMIZERS ON CIFAR-10 DATASET.
Optimizer Acc. [%] Reduced [%]
mSGD (as in [31]) 92.45 -mSGD (our implementation) 93.13 0.00AMSGRAD 92.64 0.00AdamW 91.97 0.00Adam 92.61 53.23
TABLE VICOMPARISONS WITH OTHER MODEL REDUCTION METHOD ON MNIST
DATASET.
Method Error [%] Reduced [%] #Neurons
Baseline (cited from [11]) 1.43 - 784-500-300-10Wen et al. (cited from [11]) 1.53 83.5 434-174-78-10ours 1.45 83.7 784-91-174-10
(i.e., a condition: gt = λwt is not exactly satisfied).
B. Comparisons on Model Reduction
We conducted comparisons with other model reduction
methods in which the group sparsity of weights is explicitly in-
duced by the regularizer. On the MNIST dataset, we compared
with a method proposed by Wen et al. [11]. We used the same
network model as in [11], namely, a 4-layer fully connected
network without BN layer, having 500 and 300 nodes in its
hidden layers. We trained it with He’s initializer [2] and the
same setup as in Table I. Our method is slightly better than
[11] in accuracy while comparable in reduction rate, as shown
in Table VI.
Moreover, we compared with a method proposed by Scar-
dapane et al. [12] on the CIFAR-10 dataset, using the same
model and setup as the experiment in a previous subsection.
We implemented their method, in which the model was trained
by mSGD with initial learning rate of 0.1. The threshold of
model reduction was set as 1.0× 10−6 for the other method.
For investigating the trade-off between accuracy and reduction
rate, we used several parameters of the regularization (λ). The
network was trained 5 times for each λ with different initial
weights, and the accuracy and ratio of reduced parameters
were plotted in Fig. 7. It can be seen that our method basically
outperforms the other method in accuracy while achieving the

82
84
86
88
90
92
94
0 20 40 60 80 100
Our method
Scardapane et al. [12]
Fig. 7. Trade-off between accuracy and ratio of reduced parameterson CIFAR-10 dataset. The following regularization parameters were used:1.0 × 10−5, 5.0 × 10−5, 1.0 × 10−4, 2.5× 10−4, 5.0× 10−4, 7.5×10−4, 0.001, 0.0015, 0.0025, 0.005, 0.0075, 0.01, 0.025, 0.05 for ourmethod and 1.0 × 10−6, 2.0 × 10−6, 3.0 × 10−6, 4.0 × 10−6, 5.0 ×10−6, 7.0×10−6, 9.0×10−6, 1.0×10−5, 1.25×10−5, 1.5×10−5, 1.75×10−5, 2.0× 10−5, 3.0× 10−5, 4.0× 10−5 for the other method [12].
same reduction rate. The other method sometimes achieved
low accuracy, and ours was more stable. Therefore, our
method can efficiently control the model size by calibrating a
parameter of L2 regularization.
VI. CONCLUSIONS
In this paper, we have analyzed the implicit weight sparsity
induced by Adam, ReLU, and L2 regularization in both theo-
retical and experimental aspects. Assuming that weight decay
by L2 regularization becomes dominant under the existence of
less-activated ReLUs, we have mathmatically described that
Adam requires Ω(log log(1/δ)) steps to achieve a sufficiently
small weight of δ, which is faster than the Ω(log(1/δ))of mSGD. We believe this difference leads to sparsity of
weights with Adam. Additionally, we proposed a method for
model reduction by simply eliminating the zero weights after
training the DNN. In experiments on MNIST and CIFAR-10
datasets, we demonstrated the sparsity with various training
setups and found that other activation functions and optimizers
having properties similar to ReLU and Adam, respectively,
also achieve sparsity. Finally, we confirmed that our method
can efficiently reduce the model size and exhibits favorable
performance relative to that of other methods that use a
sparsity-inducing regularizer.
ACKNOWLEDGMENT
TS was partially supported by MEXT Kakenhi (25730013,
25120012, 26280009, 15H05707 and 18H03201), Japan Dig-
ital Design, JST-PRESTO and JST-CREST.
REFERENCES
[1] Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521,pp. 436–444, 2015.
[2] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers:Surpassing human-level performance on imagenet classification,” inProc. IEEE International Conference on Computer Vision (ICCV), 2015.
[3] X. Glorot, A. Bordes, and Y. Bengio, “Deep sparse rectifier neuralnetworks,” in Proc. International Conference on Artificial Intelligence
and Statistics (AISTATS), 2011, pp. 315–323.
[4] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhut-dinov, “Dropout: A simple way to prevent neural networks from overfit-ting,” Journal of Machine Learning Research, vol. 15, pp. 1929–1958,2014.
[5] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep net-work training by reducing internal covariate shift,” in Proc. International
Conference on Machine Learning (ICML), 2015, pp. 448–456.
[6] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for imagerecognition,” in Proc. IEEE International Conference on Computer
Vision and Pattern Recognition (CVPR), 2016.
[7] S. Shi and X. Chu, “Speeding up convolutional neural networks by ex-ploiting the sparsity of rectifier units,” arXiv preprint arXiv:1704.07724,2017.
[8] S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deepneural network with pruning, trained quantization and huffman coding,”in Proc. International Conference on Learning Representations (ICLR),2016.
[9] H. Li, A. Kadav, I. Durdanovic, H. Samet, and H. P. Graf, “Pruning filtersfor efficient convnets,” in Proc. International Conference on Learning
Representations (ICLR), 2017.
[10] A. Polyak and L. Wolf, “Channel-level acceleration of deep facerepresentations,” IEEE Access, vol. 3, pp. 2163–2175, 2015.
[11] W. Wen, C. Wu, Y. Wang, Y. Chen, and H. Li, “Learning structured spar-sity in deep neural networks,” in Proc. Advances in Neural Information
Processing Systems (NIPS), 2016, pp. 2074–2082.
[12] S. Scardapane, D. Comminiello, A. Hussain, and A. Uncini, “Groupsparse regularization for deep neural networks,” Neurocomputing, vol.241, pp. 81–89, 2017.
[13] J. Yoon and S. J. Hwang, “Combined group and exclusive sparsity fordeep neural networks,” in Proc. International Conference on Machine
Learning (ICML), 2017, pp. 3958–3966.
[14] D. P. Kingma and J. L. Ba, “Adam: a method for stochastic optimiza-tion,” in Proc. International Conference on Learning Representations
(ICLR), 2015.
[15] N. Qian, “On the momentum term in gradient descent learning algo-rithms,” Neural networks : the official journal of the International Neural
Network Society, vol. 12, no. 1, pp. 145–151, 1999.
[16] Y. Nesterov, Introductory Lectures on Convex Optimization, ser. AppliedOptimization. Springer, 2004, vol. 87.
[17] Y. Bengio, P. Simard, and P. Frasconi, “Learning long-term dependen-cies with gradient descent is difficult,” IEEE Transactions on Neural
Networks, vol. 5, no. 2, pp. 157–166, 1994.
[18] J. Li, T. Zhang, W. Luo, J. Yang, X. Yuan, and J. Zhang, “Sparsenessanalysis in the pretraining of deep neural networks,” IEEE Transactions
on Neural Networks and Learning Systems, vol. 28, no. 6, pp. 1425–1438, 2017.
[19] F.-F. Li, A. Karpathy, and J. Johnson. (2015) Cs231n: Convolutionalneural networks for visual recognition. [Online]. Available:http://cs231n.github.io/neural-networks-1/
[20] A. L. Maas, A. Y. Hannun, and A. Y. Ng, “Rectifier nonlinearitiesimprove neural network acoustic models,” in ICML Workshop on Deep
Learning for Audio, Speech and Language Processing, 2013.
[21] J. Duchi, E. Hazan, and Y. Singer, “Adaptive subgradient methodsfor online learning and stochastic optimization,” Journal of Machine
Learning Research, vol. 12, pp. 2121–2159, 2011.
[22] T. Tieleman and G. Hinton, “Lecture 6.5-rmsprop: Divide the gradientby a running average of its recent magnitude,” COURSERA: Neural
networks for machine learning, 2012.
[23] M. D. Zeiler, “Adadelta: An adaptive learning rate method,” arXiv
preprint arXiv:1212.5701, 2012.
[24] A. C. Wilson, R. Roelofs, M. Stern, N. Srebro, and B. Recht, “Themarginal value of adaptive gradient methods in machine learning,” inProc. Advances in Neural Information Processing Systems (NIPS), 2017,pp. 4151–4161.
[25] S. J. Reddi, S. Kale, and S. Kumar, “On the convergence of adam andbeyond,” in Proc. International Conference on Learning Representations
(ICLR), 2018.
[26] I. Loshchilov and F. Hutter, “Fixing weight decay regularization inadam,” arXiv preprint arXiv:1711.05101, 2017.

[27] X. Glorot and Y. Bengio, “Understanding the difficulty of training deepfeedforward neural networks,” in Proc. International Conference on
Artificial Intelligence and Statistics (AISTATS), 2010, pp. 249–256.
[28] Y. Lecun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learningapplied to document recognition,” Proceedings of the IEEE, vol. 86,no. 11, pp. 2278–2324, 1998.
[29] A. Krizhevsky and G. Hinton, “Learning multiple layers of features fromtiny images,” Technical report, University of Toronto, 2009.
[30] D.-A. Clevert, T. Unterthiner, and S. Hochreiter, “Fast and accuratedeep network learning by exponential linear units (elus),” in Proc.
International Conference on Learning Representations (ICLR), 2016.
[31] S. Zagoruyko. (2015) 92.45% on cifar-10 in torch. [Online]. Available:http://torch.ch/blog/2015/07/30/cifar.html
APPENDICES
A. Convergence of mSGD (Proposition III.1)
The update rule of mSGD for a weight wt is given by
vt+1 = µvt − αλwt (0 < µ < 1)wt+1 = wt + vt+1
.
The condition (1− αλ+ µ)2 − 4µ ≥ 0 implies that
µ2 + 2(1− αλ− 2)µ+ (1 − αλ)2 ≥ 0
⇒|µ− (1 + λα)| ≥ 2√αλ.
Since 0 < µ < 1, µ must satisfy µ ≤ 1+λα−2√αλ under the
assumption 0 < λα < 1. Here, letting µ = 1 + αλ − q√αλ
for q > 2 and defining β =2−q
√αλ+√
(q2−4)αλ
2 and γ =2−q
√αλ−√
(q2−4)αλ
2 , we have that
wt =
(1 − γ)(βt + βt−1γ + · · ·+ βγt−1) + γt
w0
=
(1 − γ)βt 1− (γ/β)t
1− γ/β+ γt
w0
=
1− γ
β − γβt+1[1− (γ/β)t] + γt
w0.
The right-hand side can be evaluated as
1− γ
β − γβt+1[1− (γ/β)t] + γt ≤
[
(q +√
q2 − 4)
2√
q2 − 4+ 1
]
βt
=
[
(q +√
q2 − 4)
2√
q2 − 4+ 1
](
1− q −√
q2 − 4
2
√αλ
)t
= O
(
1− q −√
q2 − 4
2
√αλ
)t
.
B. Convergence of Adam (Theorem III.2)
Let ν = α(1−β1)√1−β2
. Then, by the update rule, wt is recursively
given by
wt = wt−1 − νmt√vt + ǫ
,
for mt = wt−1 + β1wt−2 + · · · + βt1w0 and vt = w2
t−1 +β2w
2t−2 + · · ·+ βt
2w20 .
First, notice that if β1 ≤ β2, then the difference between
wt and wt−1 is bounded by
ν
∣
∣
∣
∣
wt−1 + β1wt−2 + · · ·+ βt1w0√
vt + ǫ
∣
∣
∣
∣
≤ ν|wt−1|+ β1|wt−2|+ · · ·+ βt
1|w0|√vt + ǫ
≤ ν
√
w2t−1 + β1w2
t−2 + · · ·+ βt1w
20√
vt + ǫ(1 + β1 + · · ·+ βt
1)
≤ ν
√vt√
vt + ǫ
1
1− β1≤ α√
1− β2
=: ν′.
Hence, we see that, as long as wt > ν′, positivity of wt+1 is
ensured: wt+1 > 0.
Suppose that w0 > 0 and t is an integer such that, for
1 ≤ t′ ≤ t, wt′ > δ ≥ ν′. In this setting,
wt ≤ wt−1 −ν√
vt + ǫwt−1 = wt−1
(
1− ν√vt + ǫ
)
.
Therefore, we have wt < wt−1 < · · · < w0, and
vτ+1 ≤ w20(1 + β2 + β2
2 + · · ·+ βτ2 ) ≤
w20
1− β2.
Here, letting ξ = 1− ν√w2
0/(1−β2)+ǫ, we have wτ ≤ ξτw0 (1 ≤
τ ≤ t). From this observation, we again evaluate vτ as
vτ+1 = w2τ + β2w
2τ−1 + · · ·+ βτ
2w20
≤ (ξτ + β2ξτ−1 + · · ·+ βτ
2 )w20
≤ (τ + 1)maxξ, β2τw20 .
Now, let τ∗ be the smallest τ such that (τ+1)maxξ, β2τ ≤1/2. By this definition, if kτ∗ ≤ τ ≤ (k + 1)τ∗, then
vτ+1 ≤ (1/2)kw20 .
Therefore, for kτ∗ ≤ τ ≤ (k + 1)τ∗,
wτ+1 ≤ wτ
(
1− ν√
(1/2)kw20 + ǫ
)
.
Now, supposing that k satisfies ǫ ≤ (1/2)kw20 (otherwise, we
have w2τ ≤ ǫ), the above inequality yields
wτ+1 ≤ exp
(
−τ∗k−1∑
κ=1
ν√
(1/2)κw20 + ǫ
)
w0
≤ exp
(
−τ∗k−1∑
κ=1
ν
w02(κ−1)/2
)
w0
= exp
(
−τ∗ ν
w0(2k−1 − 1)
)
w0
≤ exp
(
−τ∗ ν
w0(2(τ/τ
∗)/2−1 − 1)
)
w0,
which is doubly exponential. Therefore, to achieve wτ+1 ≤ δ,we require only
τ ≥(
τ∗
log(2)+ 1
)
log
[
w0log (w0/δ)
ντ∗+ 1
]
= Ω(log log(1/δ)).