acoustic modeling lecture 10 - cs.ubc.camurphyk/software/hmm/e6820... · lecture 10: asr: sequence...
TRANSCRIPT

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 1
EE E6820: Speech & Audio Processing & Recognition
Lecture 10:ASR: Sequence Recognition
Signal template matching
Statistical sequence recognition
Acoustic modeling
The Hidden Markov Model (HMM)
Dan Ellis <[email protected]>http://www.ee.columbia.edu/~dpwe/e6820/
1
2
3
4

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 2
Signal template matching
• Framewise comparison of unknown word and stored templates:
- distance metric?- comparison between templates?- constraints?
1
10 20 30 40 50 time /frames
10
20
30
40
50
60
70
Ref
eren
ce
Test
ON
ET
WO
TH
RE
EF
OU
RF
IVE

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 3
Dynamic Time Warp (DTW)
• Find lowest-cost constrained path:
- matrix d(i,j) of distances between input frame f
i
and reference frame r
j
- allowable predecessors & transition costs T
xy
• Best path via traceback from final state
- have to store predecessors for (almost) every (i,j)
Input frames fi
Ref
eren
ce f
ram
es r
j
D(i,j) = d(i,j) + min{ }D(i-1,j) + T10D(i,j-1) + T01
D(i-1,j-1) + T11D(i-1,j)
D(i-1,j) D(i-1,j)
T10
T01
T 11 Local match cost
Lowest cost to (i,j)
Best predecessor(including transition cost)

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 4
DTW-based recognition
• Reference templates for each possible word
• Isolated word:
- mark endpoints of input word- calculate scores through each template (+prune)- choose best
• Continuous speech
- one matrix of template slices;special-case constraints at word ends
Ref
eren
ce
Input frames
ON
ET
WO
TH
RE
EF
OU
R

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 5
DTW-based recognition (2)
+ Successfully handles timing variation
+ Able to recognize speech at reasonable cost
- Distance metric?
- pseudo-Euclidean space?
- Warp penalties?
- How to choose templates?
- several templates per word?- choose ‘most representative’?- align and average?
→
need a
rigorous
foundation...

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 6
Outline
Signal template matching
Statistical sequence recognition
- state-based modeling
Acoustic modeling
The Hidden Markov Model (HMM)
1
2
3
4

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 7
Statistical sequence recognition
• DTW limited because it’s hard to optimize
- interpretation of distance, transition costs?
• Need a theoretical foundation: Probability
• Formulate as MAP choice among models:
-
X
= observed features-
M
j
= word-sequence models
-
Θ
= all current parameters
2
M*
p M j X Θ,( )M j
argmax =

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 8
Statistical formulation (2)
• Can rearrange via Bayes’ rule (& drop
p
(
X
)
):
-
p
(
X
|
M
j
)
= likelihood of obs’v’ns under model
-
p
(
M
j
)
= prior probability of model
-
Θ
A
= acoustics-related model parameters
-
Θ
L
= language-related model parameters
• Questions:
- what form of model to use for ?
- how to find
Θ
A
(training)?
- how to solve for
M
j
(decoding)?
M*
p M j X Θ,( )M j
argmax =
p X M j ΘA,( ) p M j ΘL( )M j
argmax =
p X M j ΘA,( )

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 9
State-based modeling
• Assume discrete-state model for the speech:
- observations are divided up into time frames- model
→
states
→
observations:
• Probability of observations given model is:
- sum over all possible state sequences
Q
k
• How do observations depend on states?How do state sequences depend on model?
q1Qk : q2 q3 q4 q5 q6 ...
x1X1 : x2 x3 x4 x5 x6 ...
time
states
Nobserved feature
vectors
Model Mj
p X M j( ) p X1N
Qk M j,( ) p Qk M j( )⋅all Qk
∑=
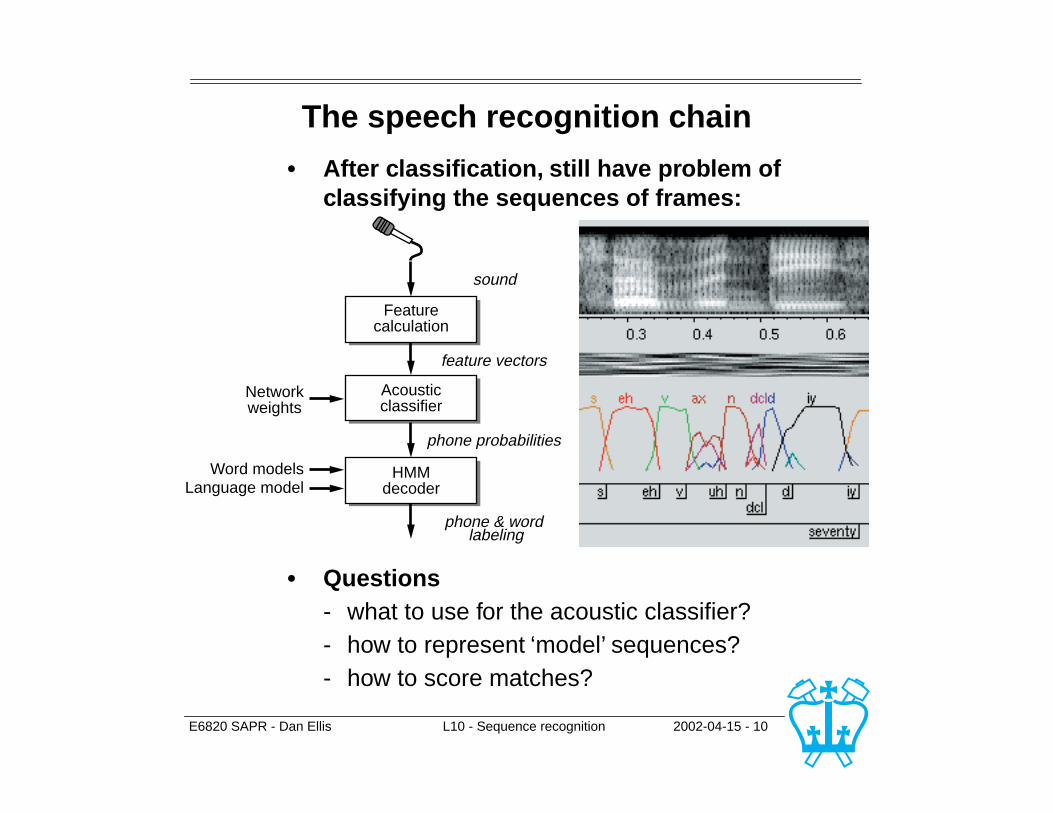
E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 10
The speech recognition chain
• After classification, still have problem of classifying the sequences of frames:
• Questions- what to use for the acoustic classifier?- how to represent ‘model’ sequences?- how to score matches?
Featurecalculation
sound
Acousticclassifier
feature vectors
Networkweights
HMMdecoder
phone probabilities
phone & word labeling
Word modelsLanguage model

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 11
Outline
Signal template matching
Statistical sequence recognition
Acoustic modeling- defining targets- neural networks & Gaussian models
The Hidden Markov Model (HMM)
1
2
3
4

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 12
Acoustic Modeling
• Goal: Convert features into probabilities of particular labels:
i.e find over some state set {qi}
- conventional statistical classification problem
• Classifier construction is data-driven- assume we can get examples of known good Xs
for each of the qis- calculate model parameters by standard training
scheme
• Various classifiers can be used- GMMs model distribution under each state- Neural Nets directly estimate posteriors
• Different classifiers have different properties- features, labels limit ultimate performance
3
p qni Xn( )

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 13
Defining classifier targets
• Choice of {qi} can make a big difference- must support recognition task- must be a practical classification task
• Hand-labeling is one source...- ‘experts’ mark spectrogram boundaries
• ...Forced alignment is another- ‘best guess’ with existing classifiers, given words
• Result is targets for each training frame:
Featurevectors
Trainingtargets g
time
w eh n

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 14
Forced alignment
• Best labeling given existing classifierconstrained by known word sequence
Featurevectors
Phoneposterior
probabilitiesKnown wordsequence
Trainingtargets
time
ow th r iy n s
ow th r iy ...
ow th r iy
Existingclassifier
ConstrainedalignmentDictionary
Classifiertraining

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 15
Gaussian Mixture Models vs. Neural Nets
• GMMs fit distribution of features under states:
- separate ‘likelihood’ model for each state qi
- match any distribution given enough data
• Neural nets estimate posteriors directly
- parameters set to discriminate classes
• Posteriors & likelihoods related by Bayes’ rule:
p x qk( ) 1
2π( )d
Σk1 2⁄
----------------------------------- 12--- x µµµµk–( )T Σk
1– x µk–( )–exp⋅=
p qk x( ) F w jk F wijxij∑[ ]⋅
j∑[ ]=
p qk x( )
p x qk( ) Pr q
k( )⋅p x q j( ) Pr q j( )⋅
j∑-----------------------------------------------=

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 16
Outline
Signal template matching
Statistical sequence recognition
Acoustic classification
The Hidden Markov Model (HMM)- generative Markov models- hidden Markov models- model fit likelihood- HMM examples
1
2
3
4

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 17
Markov models
• A (first order) Markov model is a finite-state system whose behavior depends only on the current state
• E.g. generative Markov model:
3
A
S
E
C
Bp(qn+1|qn)
SABCE
0 1 0 0 0
0 0 0 0 1
0 .8 .1 .1 00 .1 .8 .1 00 .1 .1 .7 .1
S A B C E
qn
qn+1.8 .8
.7
.1
.1
.1.1.1
.1
.1
S A A A A A A A A B B B B B B B B B C C C C B B B B B B C E
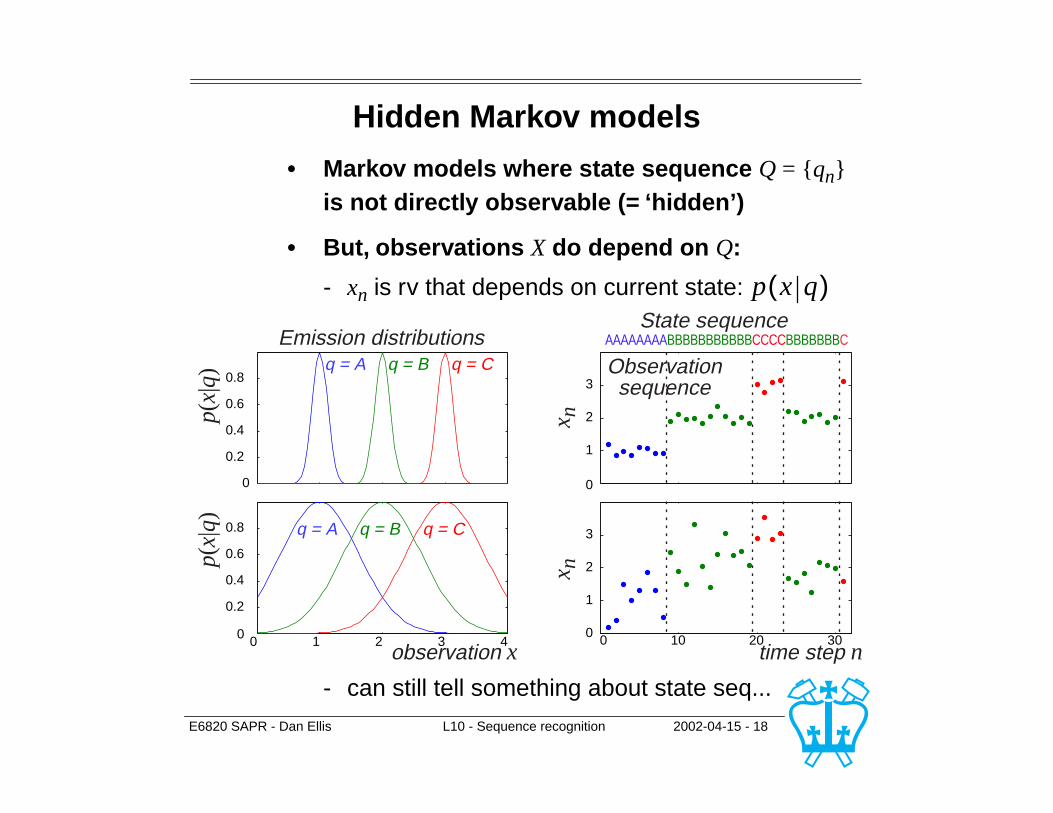
E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 18
Hidden Markov models
• Markov models where state sequence Q = {qn} is not directly observable (= ‘hidden’)
• But, observations X do depend on Q:
- xn is rv that depends on current state:
- can still tell something about state seq...
p x q( )
1
2
3
0
0.2
0.4
0.6
0.8
0 10 20 300
0
1
2
3
0 1 2 3 40
0.2
0.4
0.6
0.8
observation x time step n
State sequenceEmission distributions
Observationsequence
x nx n
p(x|
q)p(
x|q)
q = A q = B q = C
q = A q = B q = CAAAAAAAABBBBBBBBBBBCCCCBBBBBBBC

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 19
(Generative) Markov models (2)
• HMM is specified by:
- transition probabilities
- (initial state probabilities )
- emission distributions
p qnj qn 1–
i( ) aij≡
p q1i( ) πi≡
p x qi( ) bi x( )≡
k a t
k a t •
k a t •
••
•
•
•kat
k a t •
0.9 0.1 0.0 0.01.0 0.0 0.0 0.0
0.0 0.9 0.1 0.00.0 0.0 0.9 0.1
p(x|q)
x
- states qi
- transition probabilities aij
- emission distributions bi(x)

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 20
Markov models for speech
• Speech models Mj
- typ. left-to-right HMMs (sequence constraint)- observation & evolution are conditionally
independent of rest given (hidden) state qn
- self-loops for time dilation
ae1S Eae2 ae3 q1
x1
q2
x2
q3
x3
q4
x4
q5
x5

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 21
Markov models for sequence recognition
• Independence of observations:
- observation xn depends only current state qn
• Markov transitions:
- transition to next state qi+1 depends only on qi
p X Q( ) p x1 x2 …xN, , q1 q2 …qN, ,( )=
p x1 q1( ) p x2 q2( ) … p xN qN( )⋅ ⋅=
p xn qn( )n 1=
N∏= bqnxn( )
n 1=
N∏=
p Q M( ) p q1 q2 …qN, , M( )=
p qN q1…qN 1–( ) p qN 1– q1…qN 2–( )…p q2 q1( ) p q1( )=
p qN qN 1–( ) p qN 1– qN 2–( )…p q2 q1( ) p q1( )=
p q1( ) p qn qn 1–( )n 2=
N∏= πq1aqn 1– qnn 2=
N∏=

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 22
Model fit calculation
• From ‘state-based modeling’:
• For HMMs:
• Hence, solve for M* :
- calculate for each available model,
scale by prior →
• Sum over all Qk ???
p X M j( ) p X1N
Qk M j,( ) p Qk M j( )⋅all Qk
∑=
p X Q( ) bqnxn( )
n 1=
N∏=
p Q M( ) πq1aqn 1– qnn 2=
N∏⋅=
p X M j( )p M j( ) p M j X( )

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 23
Summing over all paths
q0 q1 q2 q3 q4
S A A A ES A A B ES A B B ES B B B E
.9 x .7 x .7 x .1 = 0.0441
.9 x .7 x .2 x .2 = 0.0252
.9 x .2 x .8 x .2 = 0.0288
.1 x .8 x .8 x .2 = 0.0128Σ = 0.1109 Σ = p(X | M) = 0.4020
2.5 x 0.2 x 0.1 = 0.052.5 x 0.2 x 2.3 = 1.152.5 x 2.2 x 2.3 = 12.650.1 x 2.2 x 2.3 = 0.506
0.00220.02900.36430.0065
SABE
AS B E0.9• 0.1 •0.7• 0.2 0.1•• 0.8 0.2•• • 1
All possible 3-emission paths Qk from S to Ep(Q | M) = Πn p(qn|qn-1) p(X | Q,M) = Πn p(xn|qn) p(X,Q | M)
Observationlikelihoods
x1 x2 x3
AB
p(x|q)
q{ 2.5 0.2 0.10.1 2.2 2.3
A B ES0.9
0.1
0.7
0.2
0.1
0.8
0.2
Model M1 xn
n1
p(x|B)p(x|A)
2 3
Observationsx1, x2, x3
S0 1 2 3 4
A
B
E
Sta
tes
time n
0.1
0.9
0.80.2
0.7
0.8 0.2
0.2
0.7
0.1
Paths

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 24
The ‘forward recursion’
• Dynamic-programming-like technique to calculate sum over all Qk
• Define as the probability of getting to
state qi at time step n (by any path):
• Then can be calculated recursively:
αn i( )
αn i( ) p x1 x2 …xn qn=qi, , ,( ) p X1
nqn
i,( )≡=
αn 1+ j( )
Time steps n
Mo
del
sta
tes
qi
αn(i+1)
αn(i)
ai+1j
aij
bj(xn+1)
αn+1(j) = [Σ αn(i)·aij]·bj(xn+1)i=1
S

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 25
Forward recursion (2)
• Initialize
• Then total probability
→ Practical way to solve for p(X | Mj) and henceperform recognition
α1 i( ) πi bi x1( )⋅=
p X1N
M( ) αN i( )i 1=
S
∑=
ObservationsX
p(X | M1)·p(M1)
p(X | M2)·p(M2)
Choose best

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 26
Optimal path
• May be interested in actual qn assignments
- which state was ‘active’ at each time frame- e.g. phone labelling (for training?)
• Total probability is over all paths...
• ... but can also solve for single best path= “Viterbi” state sequence
• Probability along best path to state :
- backtrack from final state to get best path- final probability is product only (no sum)
→ log-domain calculation just summation
• Total probability often dominated by best path:
qn 1+j
αn 1+*
j( ) αn*
i( )aij{ }i
max b j xn 1+( )⋅=
p X Q*, M( ) p X M( )≈

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 27
Interpreting the Viterbi path
• Viterbi path assigns each xn to a state qi
- performing classification based on bi(x)
- ... at the same time as applying transition constraints aij
• Can be used for segmentation- train an HMM with ‘garbage’ and ‘target’ states- decode on new data to find ‘targets’, boundaries
• Can use for (heuristic) training- e.g. train classifiers based on labels...
0 10 20 300
1
2
3
Viterbi labels:
Inferred classification
x n
AAAAAAAABBBBBBBBBBBCCCCBBBBBBBC

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 28
Recognition with HMMs
• Isolated word
- choose best
• Continuous speech- Viterbi decoding of one large HMM gives words
p M X( ) p X M( ) p M( )∝Model M1
p(X | M1)·p(M1) = ...
Model M2p(X | M2)·p(M2) = ...
Model M3p(X | M3)·p(M3) = ...
Input
w ah n
th r iy
t uw
Inputp(M1)
p(M2)
p(M3)sil
w ah n
th r iy
t uw

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 29
HMM example: Different state sequences
K AS
0.8
0.2
0.9
0.1T E
0.8
0.2Model M1
K OS
0.8
0.2
0.9
0.1T E
0.8
0.2Model M2
Emissiondistributions
00 1 2 3 4
0.2
0.4
0.6
0.8
p(x | q)
xp(
x | K
)p(
x | T
)p(
x | A
)
p(x |
O)

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 30
Model inference:Emission probabilities
0 2 4 6 8 10 12 14 16 180
2
4
Observationsequence
xn
time n / steps
0
2
4
-3-2-10
-10
-5
0
0
2
4
-3-2-10
-10
-5
0
log p(X,Q* | M) = -47.5
log p(X | M) = -47.0
log p(Q* | M) = -8.3
log p(X | Q*,M) = -39.2
Model M2
state alignment
log trans.prob
log obs.l'hood
state alignment
log trans.prob
log obs.l'hood
log p(X,Q* | M) = -33.5
log p(X | M) = -32.1
log p(Q* | M) = -7.5
log p(X | Q*,M) = -26.0
Model M1
K
AT
O
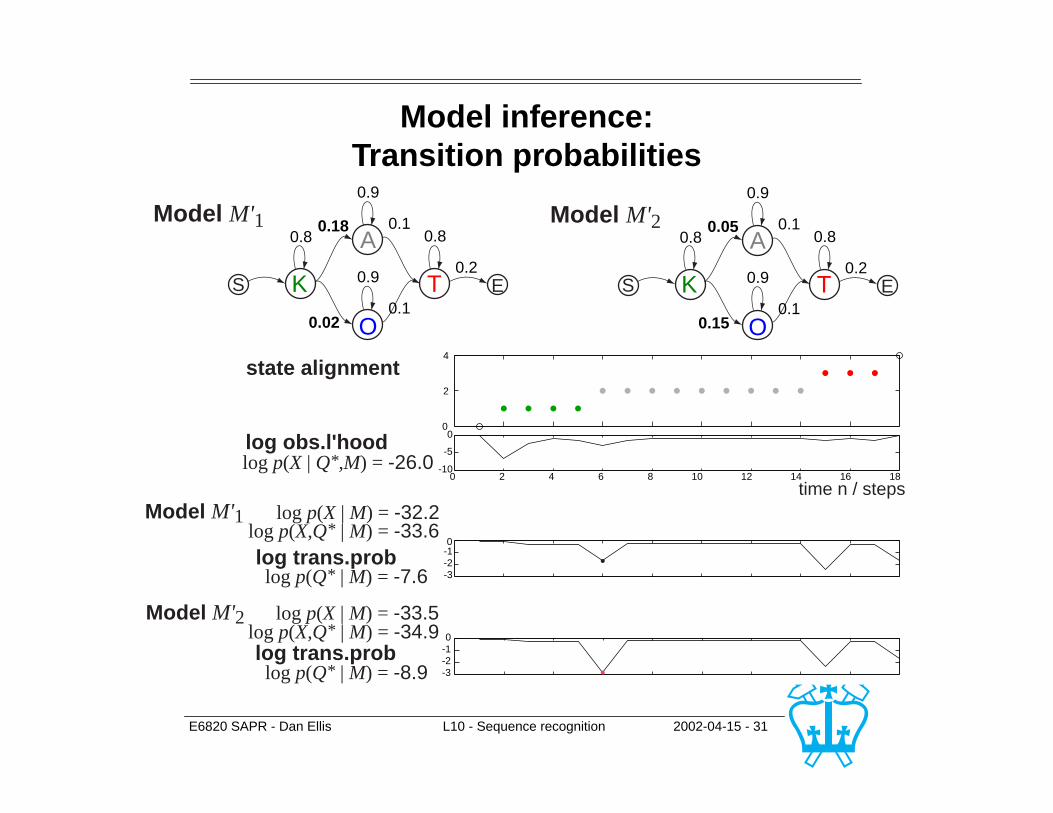
E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 31
Model inference:Transition probabilities
K
A
S
0.80.18
0.9
0.1
0.02
0.9
0.1T E
0.8
0.2
Model M'1
O
K
A
S
0.80.05
0.9
0.1
0.15
0.9
0.1T E
0.8
0.2
O
Model M'2
-3-2-10
0
0 2 4 6 8 10 12 14 16 18
time n / steps
0
2
4
-3-2-1
0
-10
-5
log trans.problog p(X,Q* | M) = -34.9
log p(X | M) = -33.5
log p(Q* | M) = -8.9
Model M'2
state alignment
log trans.prob
log obs.l'hood
log p(X,Q* | M) = -33.6log p(X | M) = -32.2
log p(Q* | M) = -7.6
log p(X | Q*,M) = -26.0
Model M'1

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 32
Validity of HMM assumptions
• Key assumption is conditional independence:
Given qi, future evolution & obs. distributionare independent of previous events- duration behavior: self-loops imply exponential
distribution
- independence of successive xns
?
n
p(N = n)
γ 1−γγ(1−γ)
n
xn
p(xn|qi)
p X( ) p xn qi( )∏=

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 33
Recap: Recognizer Structure
• Know how to execute each state
• .. training HMMs?
• .. language/word models
Featurecalculation
sound
Acousticclassifier
feature vectors
Networkweights
HMMdecoder
phone probabilities
phone & word labeling
Word modelsLanguage model

E6820 SAPR - Dan Ellis L10 - Sequence recognition 2002-04-15 - 34
Summary
• Speech is modeled as a sequence of features- need temporal aspect to recognition- best time-alignment of templates = DTW
• Hidden Markov models are rigorous solution- self-loops allow temporal dilation- exact, efficient likelihood calculations