acm sac’06, dm track dijon, france 27.04.06 “the impact of sample reduction on pca-based feature...
Post on 20-Dec-2015
216 views
TRANSCRIPT

ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
1
The Impact of Sample Reduction on PCA-based Feature Extraction
for Supervised Learning
Alexey TsymbalDepartment of Computer
ScienceTrinity College Dublin
Ireland
Seppo PuuronenDept. of CS and IS
University of JyväskyläFinland
Mykola PechenizkiyDept. of Mathematical ITUniversity of Jyväskylä
Finland
ACM SAC’06: DM Track Dijon, France April 23-27, 2006

ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
2
Outline DM and KDD background
– KDD as a process, DM strategy Supervised Learning (SL)
– Curse of dimensionality and indirectly relevant features
– Feature extraction (FE) as dimensionality reduction Feature Extraction approaches used:
– Conventional Principal Component Analysis – Class-conditional FE: parametric and non-parametric
Sampling approaches used:– Random, Stratified random, kdTree-based selective
Experiments design– Impact of sample reduction on FE for SL
Results and Conclusion
ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
3
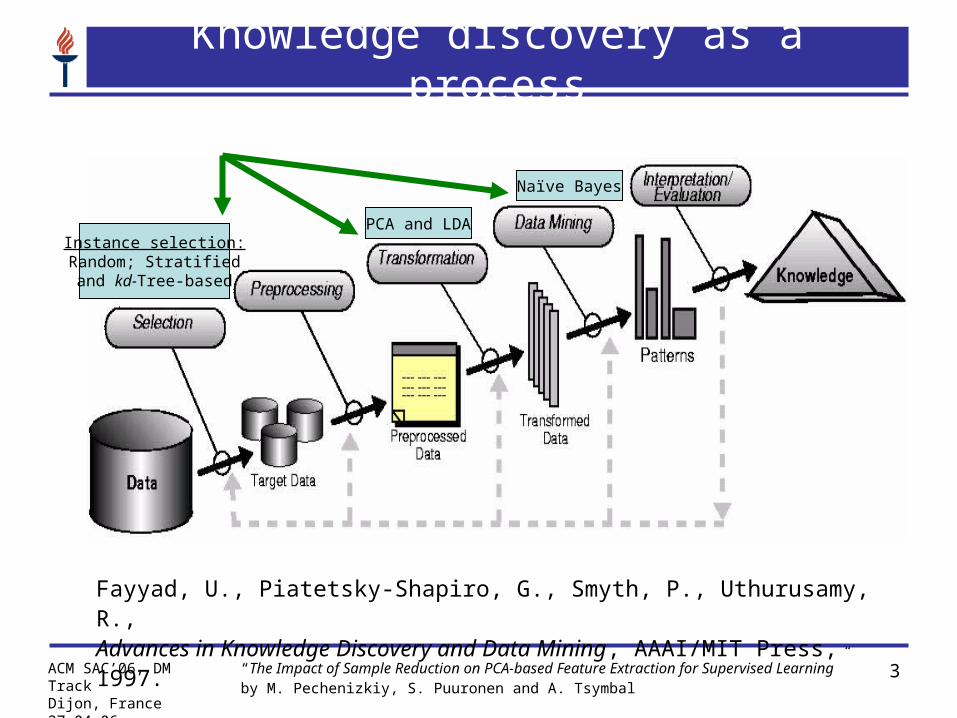
Knowledge discovery as a process
Fayyad, U., Piatetsky-Shapiro, G., Smyth, P., Uthurusamy, R., Advances in Knowledge Discovery and Data Mining, AAAI/MIT Press, 1997.
Naïve Bayes
PCA and LDAInstance selection:Random; Stratifiedand kd-Tree-based

ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
4
CLASSIFICATIONCLASSIFICATION
New instance to be classified
Class Membership ofthe new instance
J classes, n training observations, p features
Given n training instances
(xi, yi) where xi are values of
attributes and y is class
Goal: given new x0,
predict class y0
Training Set
The task of classification
Examples:
- diagnosis of thyroid diseases;
- heart attack prediction, etc.
ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
5
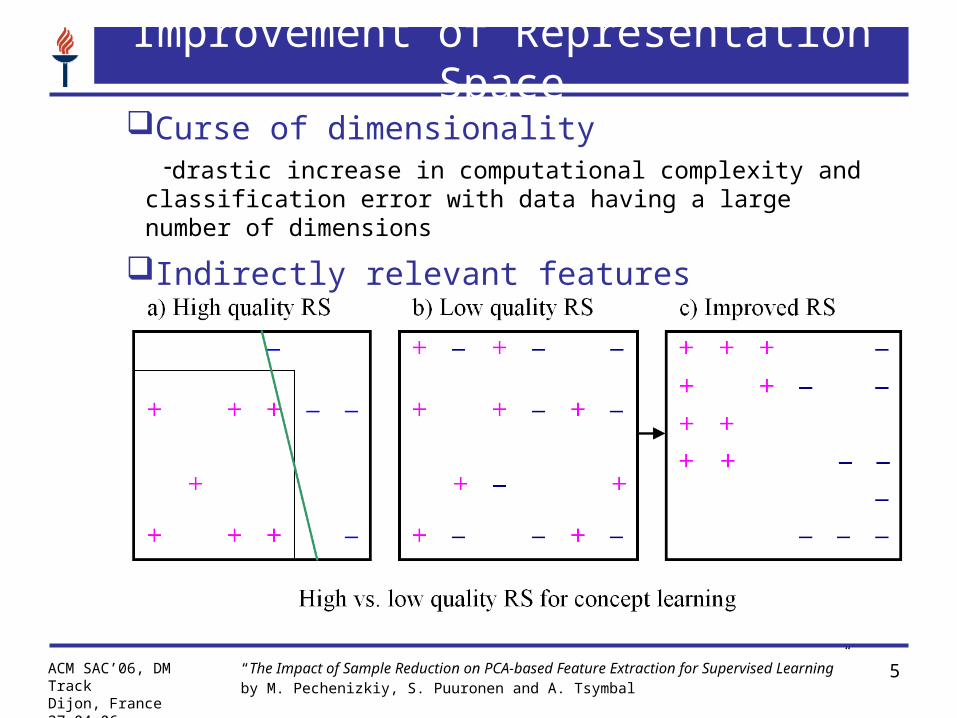
Improvement of Representation Space
Curse of dimensionality drastic increase in computational complexity and
classification error with data having a large number of dimensions
Indirectly relevant features
ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
6
representation of instances of class y1
representation of instances of class yk
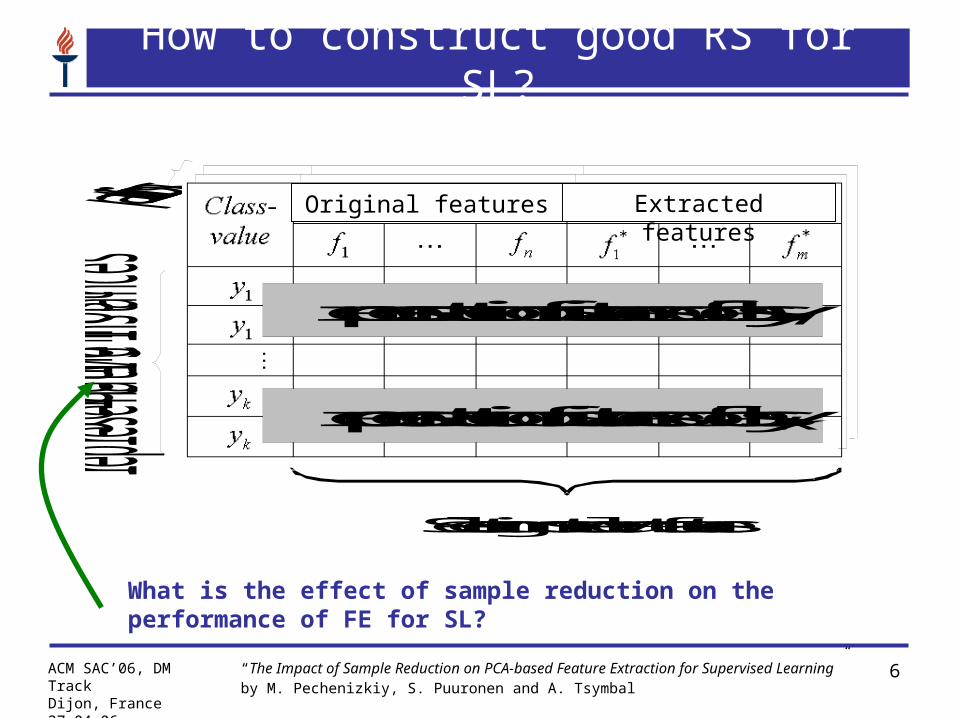
Selecting most relevant features
Selecting most
representative instances
Extracted featuresOriginal features
How to construct good RS for SL?
What is the effect of sample reduction on the performance of FE for SL?

ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
7
FE example “Heart Disease”
0.1·Age-0.6·Sex-0.73·RestBP-0.33·MaxHeartRate
-0.01·Age+0.78·Sex-0.42·RestBP-0.47·MaxHeartRate
-0.7·Age+0.1·Sex-0.43·RestBP+0.57·MaxHeartRate
100% Variance covered 87%
60% <= classification accuracy => 67%

ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
8
PCA- and LDA-based Feature Extraction
Experimental studies with these FE techniques and basic SL techniques: Tsymbal et al., FLAIRS’02; Pechenizkiy et al., AI’05
Use of class information in FE process is crucial for many datasets:
Class-conditional FE can result in better classification accuracy while solely variance-based FE has no effect on or deteriorates the accuracy.
x2 PC(1) PC(2)
a) x1
x2 PC(1) PC(2)
b) x1
No superior technique, but nonparametric approaches are more stables to various dataset characteristics

ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
9
What is the effect of sample reduction?
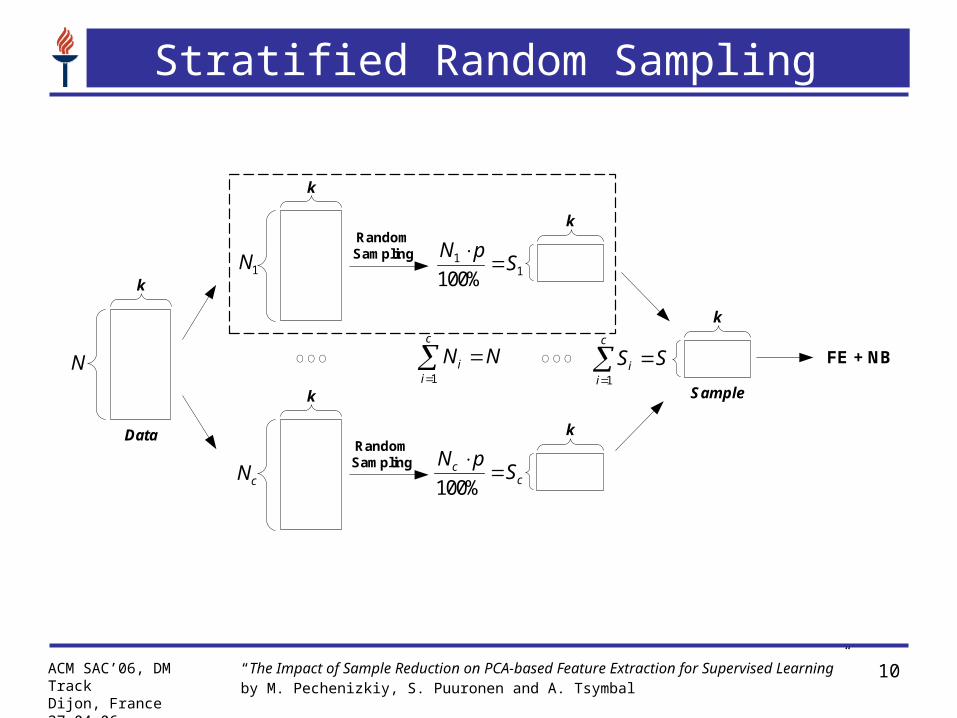
Sampling approaches used:
– Random sampling (dashed)
– Stratified random sampling
– kdTree-based sampling (dashed)
– Stratified kdTree-based sampling
kRandom Sampling
11
%100S
pN
FE + NB
kRandom Sampling
cc S
pN
%100
clas
s 1
o o o o o o
class c
NNc
ii
1
k
Sample
SSc
ii
1
k
Data
N
k
k
1N
cN
11
%100S
pN
kd-tree
building
Root
kd-tree
11N 1
nN
11
1 NNn
ii
cc S
pN
%100
kd-tree building
Root
kd-tree
cN1c
nN
c
n
i
ci NN
1
FE + NBo o o o o oo o o
k
k
k
clas
s 1
class c
Sample
SSc
ii
1
k
Data
N
k
1N
k
cN
Random Sampling
Random Sampling
ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
10
Stratified Random Sampling
kRandom Sampling
11
%100S
pN
FE + NB
kRandom Sampling
cc S
pN
%100
o o o o o oNNc
ii
1
k
Sample
SSc
ii
1
k
Data
N
k
k
1N
cN

ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
11
Stratified sampling with kd-tree based selection
11
%100S
pN
kd-tree building
Root
kd-tree
11N 1
nN
11
1 NNn
ii
cc S
pN
%100
kd-tree building
Root
kd-tree
cN1c
nN
c
n
i
ci NN
1
FE + NBo o o o o oo o o
k
k
k
clas
s 1
class c
Sample
SSc
ii
1
k
Data
N
k
1N
k
cN
Random Sampling
Random Sampling

ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
12
Experiment design
WEKA environment 10 UCI datasets SL: Naïve Bayes FE: PCA, PAR, NPAR – 0.85% variance threshold Sampling: RS, stratified RS, kdTree, stratified kdTree Evaluation:
– accuracy averaged over 30 test runs of Monte-Carlo cross validation for each sample
– 20% - test set; 80% - used for forming a train set out of which 10%-100% are selected with one of 4 sampling approaches:
• RS, stratified RS, kd-tree, stratified kd-tree
ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
13
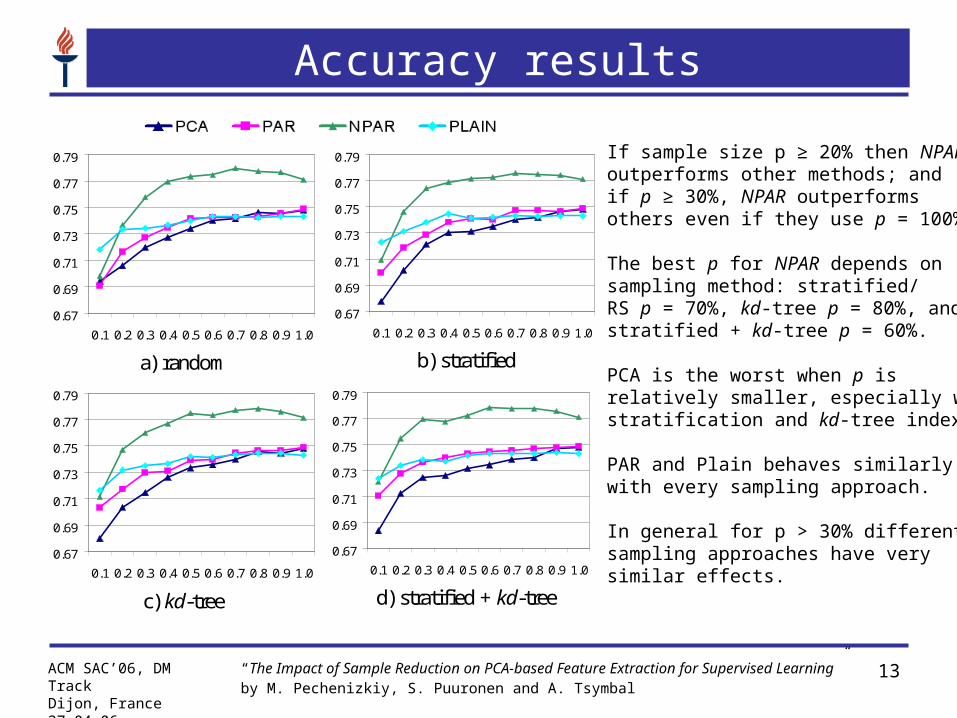
Accuracy results
0.67
0.69
0.71
0.73
0.75
0.77
0.79
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
a) random
0.67
0.69
0.71
0.73
0.75
0.77
0.79
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
b) stratified
0.67
0.69
0.71
0.73
0.75
0.77
0.79
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
c) kd-tree
0.67
0.69
0.71
0.73
0.75
0.77
0.79
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
d) stratified + kd-tree
If sample size p ≥ 20% then NPAR outperforms other methods; and if p ≥ 30%, NPAR outperforms others even if they use p = 100%.
The best p for NPAR depends on sampling method: stratified/RS p = 70%, kd-tree p = 80%, and stratified + kd-tree p = 60%.
PCA is the worst when p is relatively smaller, especially with stratification and kd-tree indexing.
PAR and Plain behaves similarly with every sampling approach.
In general for p > 30% different sampling approaches have very similar effects.

ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
14
Results: kd-Tree sampling with/out stratification
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
2.5
10 % 20 % 30 %
PCA PAR NPAR PLAIN
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
2.5
10 % 20 % 30 %
PCA PAR NPAR PLAIN
Stratification improves kd-tree sampling wrt FE for SL. The figure on the left shows the difference in NB accuracy due to use of RS in comparison with kd-tree based sampling, and the right part – due to use of RS in comparison with kd-tree based sampling with stratification
RS – kd-tree RS – stratified kd-tree

ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
15
Summary and Conclusions
FE techniques can significantly increase the accuracy of SL– producing better feature space and fighting “the curse of dimensionality”.
With large datasets only part of instances is selected for SL– we analyzed the impact of sample reduction on the process of FE for SL.
The results of our study show that – it is important to take into account both class information and information
about data distribution when the sample size to be selected is small; but– the type of sampling approach is not that much important when a large
proportion of instances remains for FE and SL;– NPAR approach extracts good features for SL with small #instances
(except RS case) in contrast with PCA and PAR approaches. Limitations of our experimental study:
– fairly small datasets, although we think that comparative behavior of sampling and FE techniques wont change dramatically;
– experiments only with Naïve Bayes, it is not obvious that the comparative behavior of the techniques would be similar with other SL techniques;
– no analysis of complexity issues, selected instances and number of extracted features, effect of noise in attributes and class information.

ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
16
Contact Info
Mykola Pechenizkiy
Department of Mathematical Information Technology,
University of Jyväskylä, FINLANDE-mail: [email protected]
Tel. +358 14 2602472Mobile: +358 44 3851845
Fax: +358 14 2603011www.cs.jyu.fi/~mpechen
THANK YOU!
MS Power Point slides of this and other recent talks and full texts of selected publications are available online at: http://www.cs.jyu.fi/~mpechen

ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
17
Extra slides
ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
18
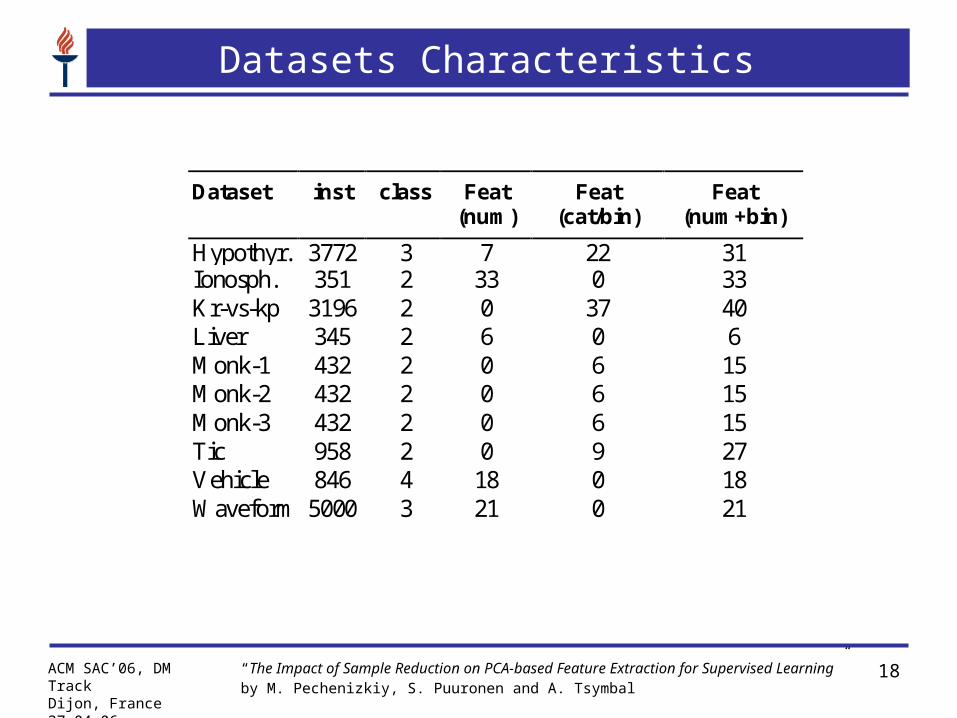
Datasets Characteristics
Dataset inst class Feat (num)
Feat (cat/bin)
Feat (num+bin)
Hypothyr. 3772 3 7 22 31 Ionosph. 351 2 33 0 33 Kr-vs-kp 3196 2 0 37 40 Liver 345 2 6 0 6 Monk-1 432 2 0 6 15 Monk-2 432 2 0 6 15 Monk-3 432 2 0 6 15 Tic 958 2 0 9 27 Vehicle 846 4 18 0 18 Waveform 5000 3 21 0 21

ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
19
Framework for DM Strategy Selection
Pechenizkiy M. 2005. DM strategy selection via empirical and constructive induction. (DBA’05)
Meta-Model, ES, KB
Feature Manipu-lators
ML algorithms/ Classifiers
Post-processors/visualisers
Meta-Data
Meta-learning
Data set
KDD-Manager Data Pre-
processors
Instances Manipu-lators
GUI
Data generator
Evaluators
ACM SAC’06, DM TrackDijon, France 27.04.06
“The Impact of Sample Reduction on PCA-based Feature Extraction for Supervised Learning” by M. Pechenizkiy, S. Puuronen and A. Tsymbal
20
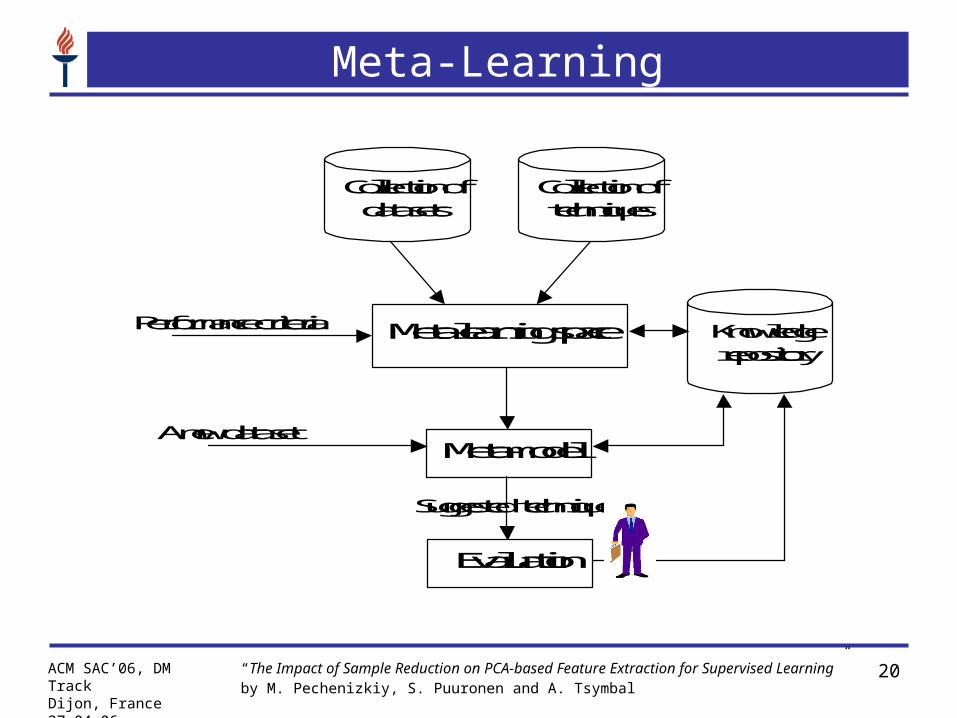
Meta-Learning
Suggested technique
A new data set Meta-model
Collection of data sets
Collection of techniques
Meta-learning space
Performance criteria
Knowledge repository
Evaluation