a quick start guide to using hdf5 files in globe claritas
DESCRIPTION
GLOBE Claritas V6.0 includes support for a new data format based on the HDF5 standard; here's how to get started with HDF5 files, and the benefits they bringTRANSCRIPT

V6.0

Getting Started With HDF5
• Why have we brought in a new data format?• What actually is HDF5?• How do I create HDF5 files?• How do I read in HDF5 files
– Reading one file at a time– Reading multiple files and selections
• Points to Note• Future Developments

SEGY is great but…• It is designed to be read sequentially from tape
– and our “index” file solution didn’t scale well to “big data”– and our index file solution only allowed primary key access
• It only has 240 bytes of 32-bit integer headers defined– and our extended trace headers didn’t scale well to “big data”
• Some processes require “n-key random access”– “surface consistent” suite, PreSTM, 3DSRME etc.
• You need to read the whole file to access trace headers– Some “database” systems offer more flexibility
• Parallel I/O doesn’t scale well on large clusters

So what is HDF5?• Developed over the last 20 years
• Initially by National Centre for Supercomputing Applications http://www.ncsa.illinois.edu/• Now developed by the HDF5 Group http//:www.hdfgroup.org
• A suite of technologies, not just a file format• General purpose library and file format for storing scientific data• Fully supported set of command line tools, APIs and interfaces
• A pan-industry open standard• Used for storage by both MatLab and Scilab, can be read by Mathmatica• Fully supported set of command line tools, APIs and interfaces
• A self describing format• No ambiguity about integer or floating point types or storage in trace bytes• Names can be allocated to components, as you would in a database structure
• Built for “big data”• Petabyte+ scale datasets running on tens of thousands of cores

Our Implementation of HDF5HDFView 2.9 : free, third party tool, showing how any HDF5 application can open the new
format
Data, Processing History, 400-byte reel header, 3200-byte text
header, history and trace headers from Claritas extended SEGY all
present
Seismic samples displayed graphically – could also be
displayed as a table
All trace headers – SEGY 240byte and extended - opened in a
spreadsheet; full mathematical operations
We have “encapsulated” the GLOBE Claritas SEGY in HDF5
The 400-byte binary reel header opened as a table, so that values
can be edited or modified
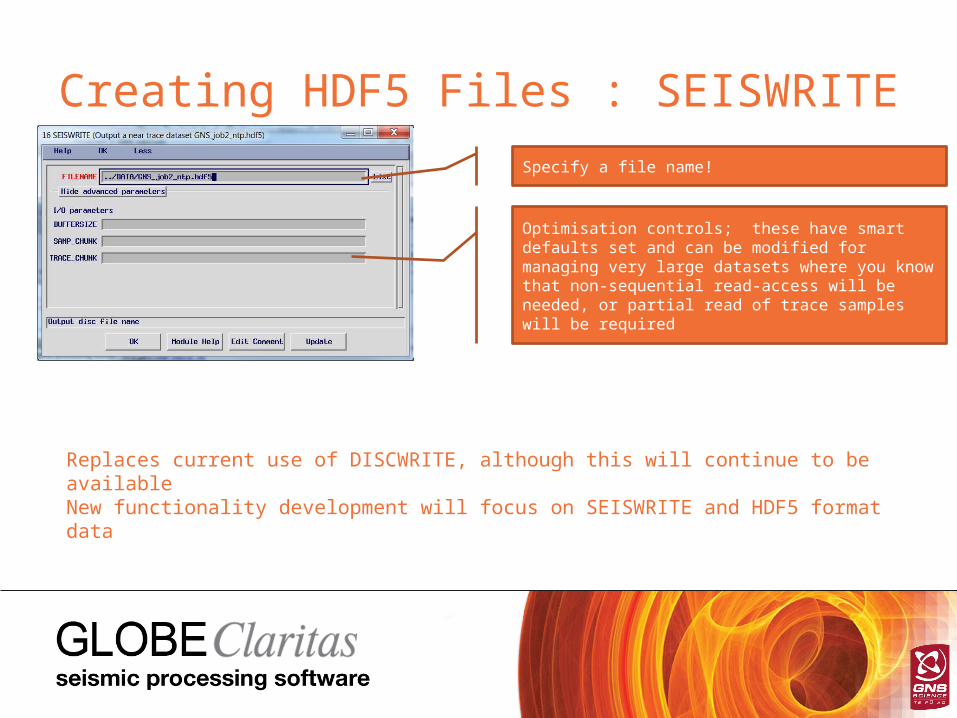
Creating HDF5 Files : SEISWRITE
Specify a file name!
Optimisation controls; these have smart defaults set and can be modified for managing very large datasets where you know that non-sequential read-access will be needed, or partial read of trace samples will be required
Replaces current use of DISCWRITE, although this will continue to be availableNew functionality development will focus on SEISWRITE and HDF5 format data

Reading HDF5 files : SEISREAD
With HDF5 format, you use SEISREAD in place of the DISCxxxxx ModulesYou don’t need to worry about the order of data on disc, just how you want to read it

Simple ReadingFile Name
Primary key order; default is all, ascending
Secondary key order; default is all, ascending
Tertiary key order; only when needed
You can read data in ANY order; original order doesn’t matter

Selection and Repeats
6 Repeat copies specified
Primary key SHOTID with only SHOTID 900 only selected; note tolerance
Secondary key CHANNEL, all selected, in ascending order (default)
Six copies of SHOTID 900 passed to the processing flow, with REPEAT set from 1-6

More Complex Selections
Two copies of SHOTIDs from 100 to 900 with an increment of 100, all channels in ascending, with REPEAT set to 1 and 2
More complex SHOTID selection using the same syntax as DISCREAD; note tolerance is set to 0

Sorting to CDP (DISCGATH)
Identical to simple reading
Specify CDP and primary keySpecify CDPTRACE as secondary key
Default is to read all data in ascending primary/secondary key order

Reading Multiple Files
Seismic File List used in the same format as with DISCREAD, with selections
SETRAEPEAT parameter used as per DISCREAD to create panels, files are merged if this is “no”
Primary Key defined here is used in the Seismic File List definition
This last file has a “native” ordering of CDP, CDPTRACE, but will be order to SHOT, CHANNEL on read, automatically

Points to Note
• Can only specify a primary key in a Seismic File List– Same as DISCWRITE, although the original data order no longer matters
• User needs to managed extended trace headers merge– Use DELHDR prior to merging files; will be removed in future releases
• Files can be 10-15% larger than SEGY• Compatible with Cluster File Systems (Gluster etc.)• I/O above about 2Gbytes should be improved

Future development• Improved PKEY/SKEY/TKEY selection handling• Direct update of trace headers from applications
– Geometry, SV (FB picks) etc.
• Add HDF5 support in KPRET2D – Only module where this is not available
• Add full parallel I/O to iMage suite– Increase parallel scalability even further
• Algorithmic optimisation– Re-write to take full advantage of random access