“a quantitative analysis of the gnutella network traffic” cs204 final project by demetris...
Post on 19-Dec-2015
214 views
TRANSCRIPT

“A Quantitative Analysis of the Gnutella Network Traffic”
cs204 Final Project by
Demetris Zeinalipour & Theodoros Folias
<[email protected] , [email protected]>
Advisor: Michalis Faloutsos
University of California – Riverside
Department of Computer Science & Engineering
Online Resources: http://www.cs.ucr.edu/~csyiazti/cs204.html

Presentation Outline
1. Motivation.
2. Gnutella Protocol in a nutshell.
3. Related Work.
4. gnuDC – Gnutella Distributed Crawler.
5. Experiments.
6. Conclusions & Future Work.
Online Resources: http://www.cs.ucr.edu/~csyiazti/cs204.html

1. Motivation
• P2P file-sharing systems, such as Gnutella, Napster and Freenet realized a distributed infrastructure for sharing files.
• Traditionally, files were shared using the Client-Server model (e.g. http, ftp). Not scalable (centralized)
• P2P systems have shown that distributed file-searching is feasible! …and yes that they may change the way we interact on the Internet.
• Why Gnutella?– It is a Pure P2P protocol in contrast with e.g. Napster
– It is an open protocol which allows its investigation.
– It is a large community 250,000 peers at any given moment.
– It is a truly international phenomenon with a world-wide community.
– It is still not clear what kind of traffic is traversing the network

1. Motivation
• Questions :– How do these systems really look like?
– What kind of traffic are these systems carrying?
– What is the communication overhead of P2P?
– Where are file-searchers coming from and what are they looking for?
• Our contribution : – We make a quantitative analysis of the Gnutella Network Traffic at a
large-scale (17 machines, 85 nodes, 700MB log traces in 5 hours)
– To our knowledge such a large-scale measurement is not presented in any publication.
– We describe design and implementation issues of a large-scale distributed Gnutella Crawler.

2. Gnutella Protocol v0.4 (1/5)
• One of the most popular file-sharing protocols.• Operates without a central Index Server (such as
Napster).• Clients (downloaders) are also servers => servents• Clients may join or leave the network at any time =>
highly fault-tolerant but with a cost!• Searches are done within the virtual network while actual
downloads are done offline (with HTTP).• The core of the protocol consists of 5 descriptors
(PING, PONG, QUERY, QUERHIT and PUSH).

2. Gnutella Protocol (2/5)
• It is important to understand how the protocol works in order to understand our framework.
• A Peer (p) needs to connect to 1 or more other Gnutella Peers in order to participate in the virtual Network
• p initially doesn’t know IPs of its fellow file-sharers
Gnutella Network N
?
Servent p

2. Gnutella Protocol (3/5)a. HostCaches – The initial connection• P connects to a HostCache H to obtain a set of IP addresses of
active peers.• P might alternatively probe its cache to find peers it was
connected in the past.
Gnutella Network N
!
Servent p
Hostcache Servere.g. connect1.gnutellahosts.com:6346
1
2
Request/Receive a set of Active
Peers
H
Connect to network

2. Gnutella Protocol (4/5)
b. Ping/Pong – The communication overhead• Although p is already connected it must discover new peers since its
current connections may break.
• Thus, it sends periodically PING messages which are broadcasted (message flooding).
• If a host e.g. p2 is available it will respond with a PONG (routed only the same path the PING came from).
• P might utilize this response and attempt a connection to p2 in order to increase its degree. Gnutella Network N
Servent p
PING1
PONG2
Servent p2

2. Gnutella Protocol (5/5)
c. Query/QueryHit – The utilization• Query descriptors contain unstructured queries e.g. “celine dion mp3”
• They are again, like PING, broadcasted with a typical TTL=7.
• If a host e.g. p2 matches the query it will respond with a Queryhit descriptor
d. Push – Enable downloads from peers that are firewalled.• If a peer is firewalled => we can’t connect to him. Hence we request from
him to establish a connection on us and to send us the file.
Gnutella Network N
Servent p
QUERY1
QUERYHIT2
Servent p2

3. Related Work (1/3)
a. Simulating Peer-to-Peer Systems
• Most researchers use simulation Testbeds (e.g. Anthill) to validate the performance improvement they gain from new ideas (routing algorithms etc.)
• Initial assumptions (e.g. degree of nodes, graph type “random”, power-law”, “tree”), might be wrong though!
• Visualizations might also not be very helpful.
• What we would need instead are real network metrics from a large P2P Network such as Gnutella.

3. Related Work (2/3)
a. Obtaining data from different physical locations“Tracing a large-scale Peer to Peer System : An hour in the life of Gnutella”, E. Markatos, CCGrid 2002
• They Obtained traffic log traces from 3 different physical locations (Norway, Greece, USA).
• The collected data from all three locations are almost identical.• They found that the gnutella traffic is bursty and remains bursty over
several time scales.• The results also show that there are high locality patterns in QUERY
messages. This observation might lead to better caching policies at peers
• Their study also reveals that there is topology mismatch between the physical topology and the virtual gnutella topology, since collected data are identical among their 3 different crawlers.
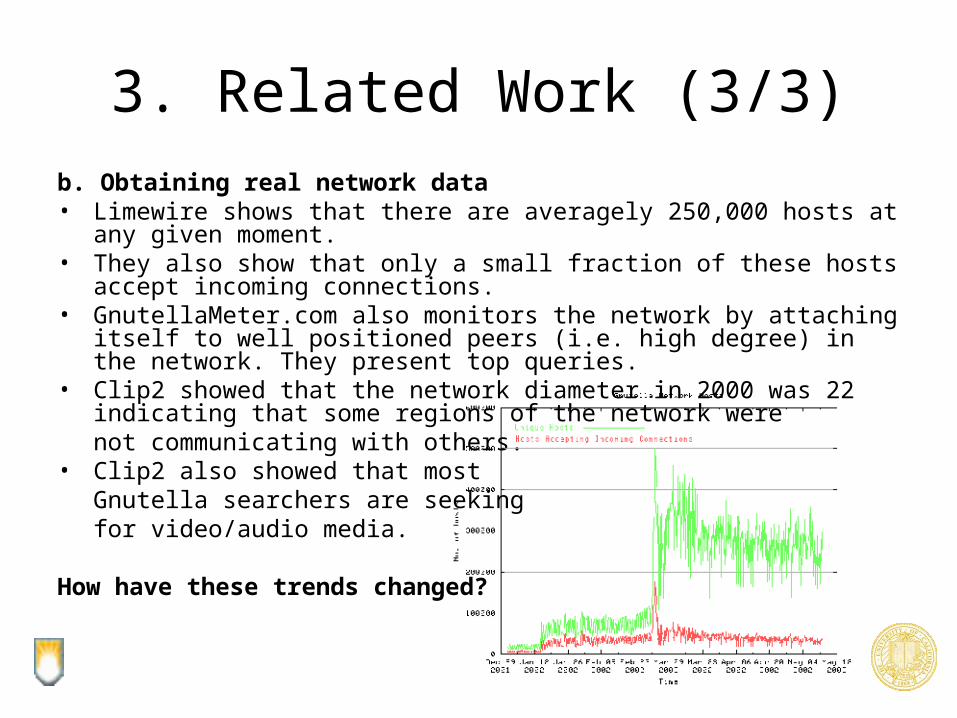
3. Related Work (3/3)b. Obtaining real network data• Limewire shows that there are averagely 250,000 hosts at any given
moment.• They also show that only a small fraction of these hosts accept incoming
connections.• GnutellaMeter.com also monitors the network by attaching itself to well
positioned peers (i.e. high degree) in the network. They present top queries.• Clip2 showed that the network diameter in 2000 was 22 indicating that
some regions of the network werenot communicating with others.
• Clip2 also showed that mostGnutella searchers are seekingfor video/audio media.
How have these trends changed?

4. gnuDC – Gnutella Distributed Crawler (1/6)
• gnuDC is a Large Scale distributed Gnutella Crawler which monitors the network by attaching itself to it with large numbers of peers.
• A determinant factor between a WWW Crawler and a P2P Crawler is that the latter needs to obtain results (snapshot) in a relatively short amount of time.
• Design Issues and an architecture for a Distributed P2P Crawler were not described in any other publication.
• What should be the responsibilities of a P2P Crawler and how should we design it?

4. gnuDC – Gnutella Distributed Crawler (2/6)
Design Issues of a Distributed P2P Crawler
1. Obtain Network Statistics in a small Interval.• A P2P network might be very large which implies that sequential
discovery won’t return expected results.
• Parallelizing the discovery process might be easy by partitioning the hosts to be discovered among K parallel crawlers.
2. Scale with the Network Size.• A few years ago Gnutella had a few thousands hosts. Today
250,000 at any given moment. Distributed Discovery is a must.
• What is desirable?1. purely distributed approaches ?
2. Distributed approaches with centralized indexes (e.g. SETI@Home)?
• gnuDC is based on a hybrid approach were each crawler runs in its own memory space, logs information on local disks and notifies a central index when new IPs are found

4. gnuDC – Gnutella Distributed Crawler (3/6)
Design Issues of a Large Distributed P2P Crawler (cont’d)
3. Maintain Network Health.• The Crawlers should not affect the regular operation of the network.
• Typically a message’s TTL is decreased when it traverses a Crawler. This shouldn’t happen!
4. Platform Independence.• Our distributed crawler is aimed to run on a NOW.
• Network of Workstations are typically heterogeneous (Linux, SunOS, Unix).
• Java is based on a “write once, use everywhere” philosophy.
• It also provides a strong core for networking, Threads, RMI and others.
• It makes it an ideal language for our purpose.

4. gnuDC – Gnutella Distributed Crawler (4/6)
gnuDC Architecture.• It consists of an IP Index Server, several distributed gnuBricks,
a Log Aggregator and a Log Analyzer.• Components operate asynchronously and independently.• The whole system is bootstrapped by 1 Unix script
gnuDC - gnutella Distributed Crawler
gnuDC Brick
LogManager
P2P NetworkModule
Local Logsconfig.txt
IP Index Server
Local Repository
gnuDC Brick
gnuDC Brick
gnuDC Brick
Local Logs
Local Logs
Local Logs
.
.
. Logs Aggregator
Local Repository
Logs Analyzer
Results
1
23
4
GnutellaNetwork

4. gnuDC – Gnutella Distributed Crawler (5/6)
a) IP Index Server• Multi-threaded Engine which maintains and indexes IP
addresses of active Gnutella peers.• Uses double buffering for flushing results to secondary storage.• Sustains high loads and indexes at a rates
Avg:2,500 IPs/sec with a Peak: 5,000 IPs/sec. • The cost for the in-memory data structures is 300MB for 240,000
IPs.

4. gnuDC – Gnutella Distributed Crawler (6/6)
b) gnuDC Bricks• Configurable and self-adaptive Gnutella clients.
• Implementation based on the Jtella API
• gnuDC bricks are independent from each other and run in different memory spaces.
c) Log Aggregator• Collects and Aggregates data that is dispersed on the remote disks of
the gnuDC bricks.
• Uses ssh along with bash scripts to make the harvesting process easy.
d) Log Analyzer• Combination of bash scripts, C++ routines and Java programs for
analyzing the harvested data based on various criteria.
• Aggregating and Analyzing takes approximately 7-10 minutes for 700MB of log traces.

5. Experiments 1/6• We deployed gnuDC on 85 nodes running on 17 AMD Athlons 4, 1.4 GHz with
1GB RAM running Mandrake Linux 8.0 interconnected with a 10/100 LAN connection.
• On the 1st of June 2002, we performed our first "long" crawl.• We also performed several other small scale experiments to gather data on
specific issues.
Technical Difficulties.• We were crawling only during early morning hours (i.e. 1:30 a.m. - 6:30 a.m.)
because during weekdays the machines were used by students.• Huge amounts of log traces. e.g. 700MB log traces in 5 hours, so we had
problems due to quota limitations.• Department's Administrators blocked any remote access (i.e. establishing a
TCP connection on any port number of a lab machine). the crawler couldn’t accept any incoming connections. the degree of a gnuBrick decreased in this way from 100 to 30 connections

5. Experiments 2/6a) Analysis of Gnutella Messages (ALL)• Our sample includes 56 million messages.
• The communication overhead (ping/pong) of Gnutella is 63%
• The utilization of the network (query/queryhit) is only 37%
• The huge communication overhead might be due to the fact that Gnutella network connections are highly unstable.
• The proportion of queries with queryhits is satisfactory, although we can’t say if users are satisfied by the actual query results.
• General queries such as ”mpeg video” may increase this number.

5. Experiments 2/6a) Analysis of Gnutella Messages (ALL)• We observed a correlation between the flow of Ping/Pong and
Query/Queryhit pairs although there is formally no relation.
It is interesting to investigate this further.
• Ironically although a Ping message generates many Pong messages (~4x) a query message generates a queryhit only 1/8 of the time.
Ping
Pong
Query
Queryhit
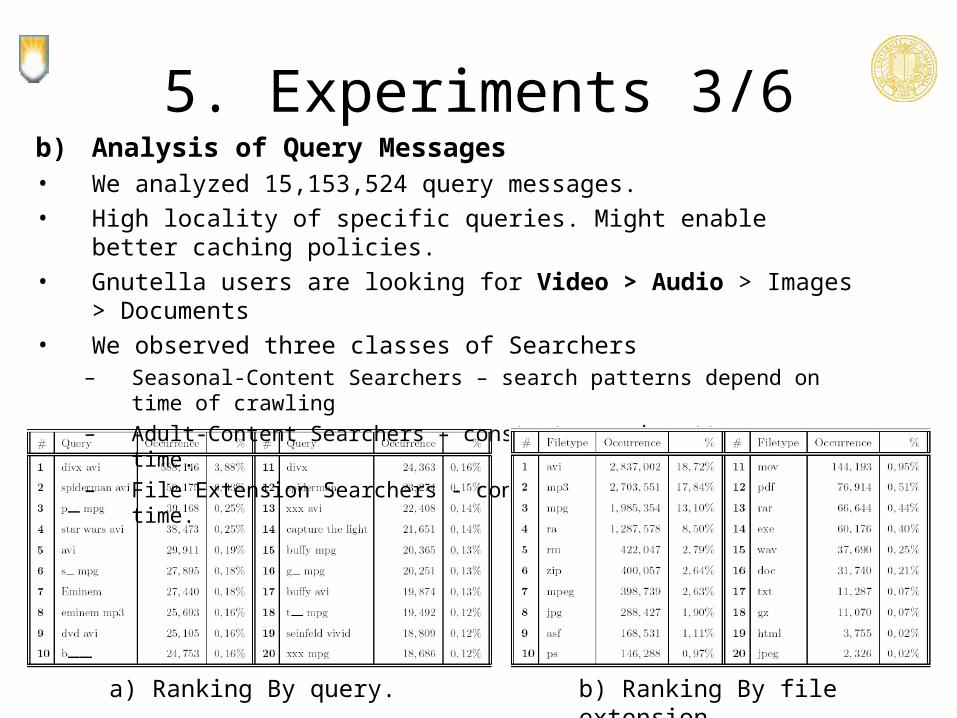
5. Experiments 3/6b) Analysis of Query Messages• We analyzed 15,153,524 query messages.
• High locality of specific queries. Might enable better caching policies.
• Gnutella users are looking for Video > Audio > Images > Documents
• We observed three classes of Searchers– Seasonal-Content Searchers – search patterns depend on time of crawling– Adult-Content Searchers – constant search patterns over time.– File Extension Searchers - constant search patterns over time.
b) Ranking By file extension.a) Ranking By query.

5. Experiments 4/6c) Analysis of Gnutella IP Addresses• We analyzed 294,000 unique IP Addresses (the initial number was
larger but we filtered out IP addresses designated for private networks (i.e. 192.x.x.x, 172.16.x.x and 10.x.x.x).
• We implemented MRDL – Multithreaded Reverse DNS Lookup Engine which resolves in parallel 100 IP/second.
• MRDL resolved 244,522 IP Addresses. 16,92% were not resolvable.
From which domains are Gnutella Users coming from?
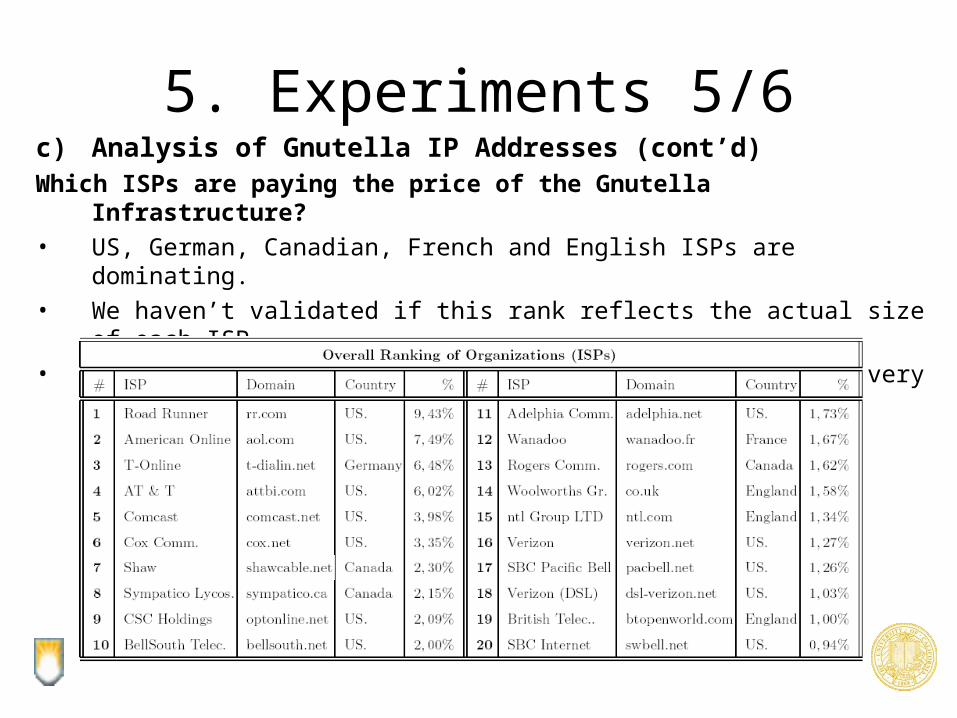
5. Experiments 5/6c) Analysis of Gnutella IP Addresses (cont’d)Which ISPs are paying the price of the Gnutella Infrastructure?
• US, German, Canadian, French and English ISPs are dominating.
• We haven’t validated if this rank reflects the actual size of each ISP.
• Interestingly Asian ISPs (e.g. from Japan) are listed very low in this rank although they are technologically advanced.

5. Experiments 6/6d) Analysis of Hop Count found in IP Addresses (cont’d)Gnutella clients are conforming to the Protocol specifications
• Only a few queries are coming from father than 7 hops.
• The protocol thwarts excessive network resources consumption.
• The bar graph presents a bimodal distribution with 2 peaks.
at hopcount 1 and 7. It is interesting to investigate why so many queries are coming from so close (i.e. 1). It is probably connections are weak.
log/normal scale normal/normal scale

6. Conclusions and Future WorkSummary of main observations
1. The Gnutella communication overhead is huge.
Ping/Pong: 63% | Query/QueryHits: 37%.
2. Gnutella users can be classified in three main categories.
Season-Content, Adult-Content and File Extension Searchers.
3. Gnutella Users are mainly interested in video > audio > images > documents.
4. Although Gnutella is a truly international phenomenon its largest segment is contributed by only a few countries.
5. The clients started conforming to the specifications of the protocol and that they thwart excessive network resources consumption.
• We are interested in examining more carefully other data (e.g. User-Agents) that we have collected but which we haven’t analyzed due to time shortage.
• Our metrics might facilitate the development of more advanced P2P protocols which might take into consideration various bottlenecks and characteristics of current solutions, such as Gnutella.
Online Resources: http://www.cs.ucr.edu/~csyiazti/cs204.html