a progressive sentence selection strategy for document summarization presenter : bo-sheng wang...
TRANSCRIPT

A progressive sentence selection strategy for document summarization
Presenter : Bo-Sheng Wang Authors :
You Quyang, Wenjie Li, Renxian Zhang, Qin Lu
IPM, 2013
1

Outlines
• Motivation• Objectives• Methodology• Experiments• Conclusions• Comments
2

Motivation
• Since there are actually many overlapping concepts in the input documents, it is indeed unnecessary and redundant to repeatedly mention one concept in the summary.
3

Objectives
• They mainly consider the problem of how to construct summaries with good saliency and coverage.
4

Methodology
• In this paper, they propose a novel sentence selection strategy that follows a progressive way to select the summary sentences
5

Methodology
• Step 1 :Define the subsuming relationship between two sentences.
6

Methodology
• Step 1 :Define the subsuming relationship between two sentences.
7

Methodology
• Step 1 :Define the subsuming relationship between two sentences.
① The relationship between two sentences is determined by the relations between the concepts.
8

Methodology
• Step 1-1 :The target is to study the subsuming relations between the words in the input documents.
① Linguistic relation database (WordNet)
② Frequency-based statistics (co-occurrence)
9

Methodology
• Step 1-1 :• The target is to study the subsuming relations
between the words in the input documents.
10

Methodology
• They expect the relations to have the characteristics listed below.
1. Sentence-level coverage.
2. Set-based coverage
3. Transitive reduction
11

Methodology-Sentence-level coverage• In document summarization, sometimes a document set just
consists of only a few documents.
(For example : 10 documents per set in the DUC 2004 data.)
They intend to study the sentence-level co-occurrence statistics instead of document-level co-occurrence.
12

Methodology-Set-based coverage• Sentence-level co-occurrence is sparser than document-level
co-occurrence due to the shorter length of sentences. • Therefore ,the sentence-level coverage of a word with respect
to another is usually much smaller. They intend to examine the coverage not only between two
words, but also between a word and a word set.
(For example : there are two common phrases ‘‘King Norodom’’ and ‘‘Prince Norodom’’. In the input documents, the coverage of ‘‘Norodom’’ with respect to either ‘‘King’’ or ‘‘Prince’’ is not large enough and thus ‘‘Norodom’’ is not recognized to be subsumed by any one of the two. On the other side, ‘‘Norodom’’ is almost entirely covered by the set {‘‘King’’, ‘‘Prince’’}. Therefore, if we can define a set-based coverage, more relations can be discovered)
13

Methodology-Transitive reduction• They also conduct a transitive reduction on the relations.
i.e : to three words a, b, c that satisfy a > b, b > c and a > c (a > b denotes a subsuming b), the long-term relationship a > c will be ignored, since we prefer to include the subsuming word b into the summary before including the subsumed word c.
14

Methodology-Necessary measures• Spanned Sentence Set(SPAN) : SPAN(w) :
The Spanned Sentence Set of a word w in document set D SD : Sentence Set
SPAN(w)={s|sϵSD ^ wϵs}= Define as the set of the sentences.
• Concept Coverage(COV) : COV(w|W)=|SPAN(w)∩∪iSPAN(wi)|/|SPAN(W)|
=Defined as the proportion of the sentences in SPAN(w) that appear in SPAN(W).
15

Methodology
16

Methodology
• Step1-2 :(1)They define the concept of “Connected Word”
i.e :W={w1,…..,wl}; W’={w’1,…..,w’m}
condition :w l1; . . . ; wlk ϵW W∪ , s.t.wi < wl1 ^ w11 < wl2 ^ . . . ^ wl(k-1) < wlk ^ wlk< w’
1
• (2)The Conditional Saliency of calculated as a weighted sum of the importance of all the ‘‘connected words’’
CS(s|s’)Σwi ϵ sLOG(MAXw’jϵs’CON(wi|w’j * score(wi)))
17

Methodology
• Step 2 :
18

Methodology
• Step :
1. To every word that is not subsumed by any other word, we regard it as a general word and attach it to ROOT-W.
2. we calculate the score of each unselected sentence based on its conditional saliency to each selected sentence.
Formula :Score(s|Sold)=Max stϵ Sold{CS(s,st)} * 1/len(s) * (1-
pos(s)) Penalizing :
Score(wi)=α * Score(wi)19

Experiments
20
• Step :① Evaluated on a generic multi-document summarization data set.
② Evaluated on a query-focused multi-document summarization data set.
• Pre-processed :– Removing the stop-words and stemming the
remaining words

Experiments-Evaluation metrics• ROUGE– State-of-the-art automatic summarization evaluation– They mainly makes use of N-gram comparison.
• DUC
21
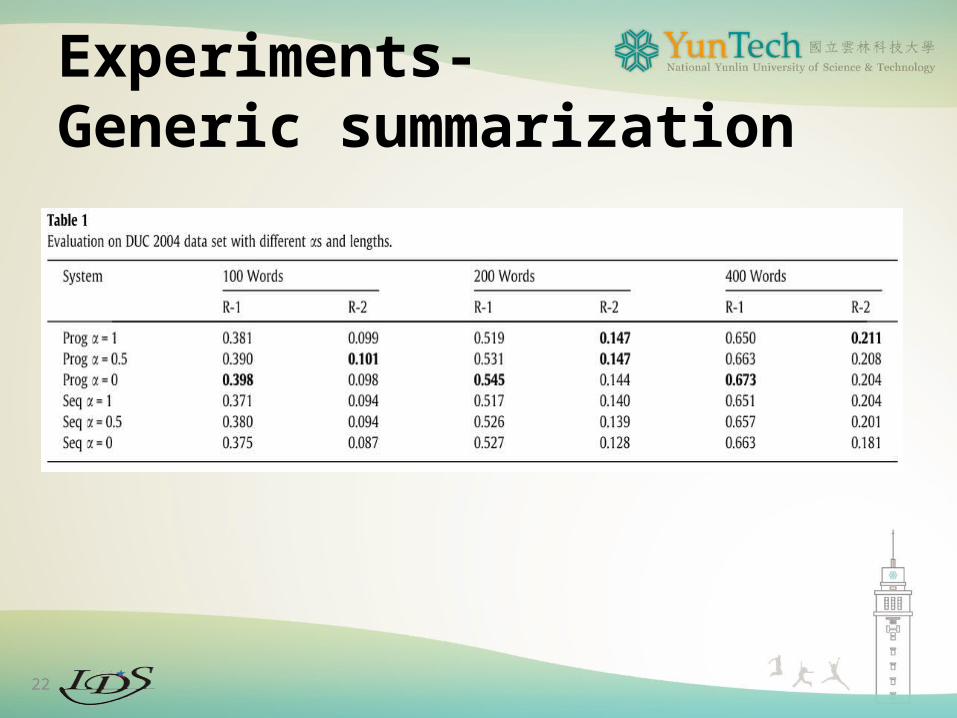
Experiments-Generic summarization
22
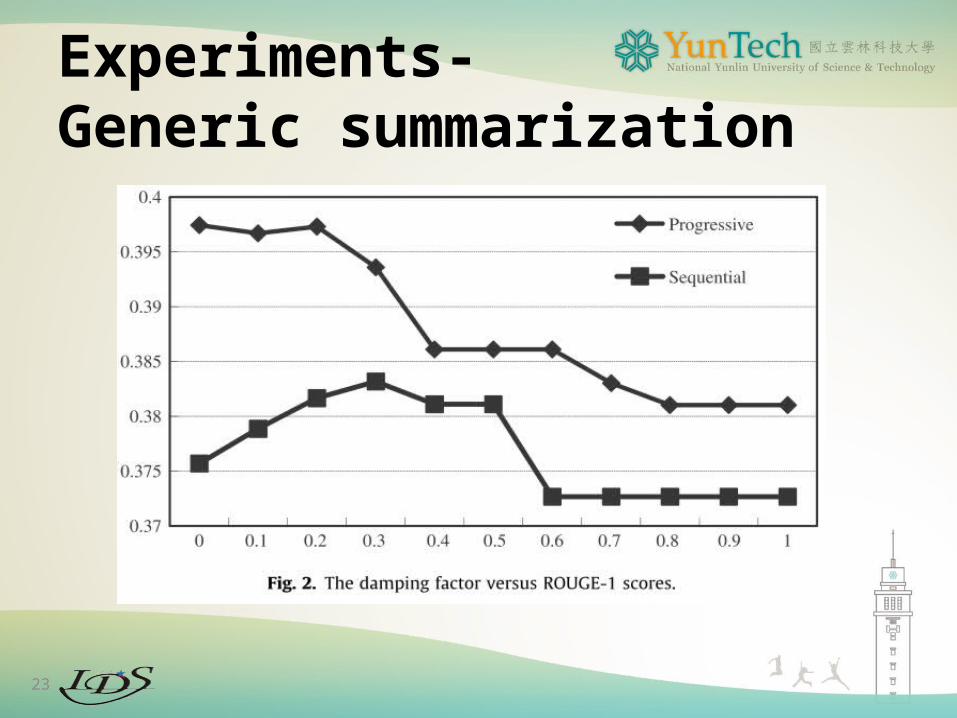
Experiments-Generic summarization
23

Experiments-Generic summarization
24

Experiments-Generic summarization
25
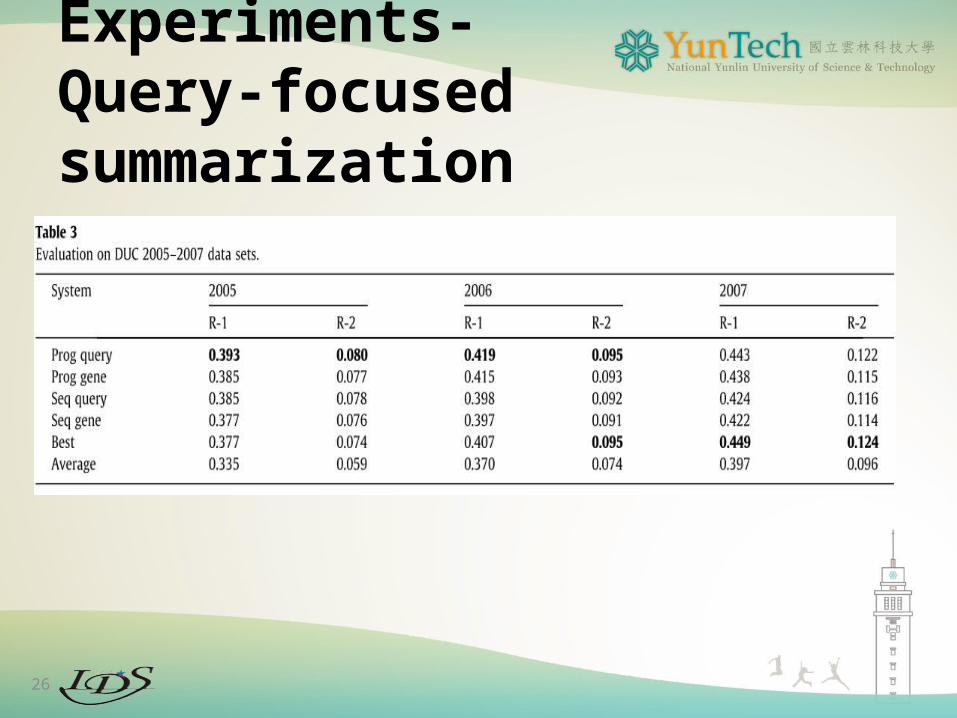
Experiments-Query-focused summarization
26

Conclusions
• Progressive system consistently performs better than the sequential system on every data set.
• The method competes comparably with the best submitted systems.
• The results clearly demonstrate the advantages of the progressive sentence selection strategy in constructing summaries with better saliency and coverage.
27

Comments
• Advantages– The method that have better saliency and coverage. – In unsupervised case, find the number of
categories can be save some time.
• Applications– Object Discovery
28

Comments
• Advantages– The method that have better saliency and coverage.
• Disadvantage– The method spend some time than traditional
methods.
• Applications– Sentence selection
29