a primer on building real time data-driven products
TRANSCRIPT

www.mapflat.com
A primer on building real-time data-driven products
Lars Albertsson, independent consultantØyvind Løkling, Schibsted Media Group

www.mapflat.com
Who’s talking?● Swedish Institute of Computer Science (distributed system test+debug tools)● Sun Microsystems (very large machines)● Google (Hangouts, productivity)● Recorded Future (NLP startup)● Cinnober Financial Tech. (trading systems)● Spotify (data processing & modelling)● Schibsted Media Group (data processing & modelling)● Mapflat - independent data engineering consultant
www.mapflat.com
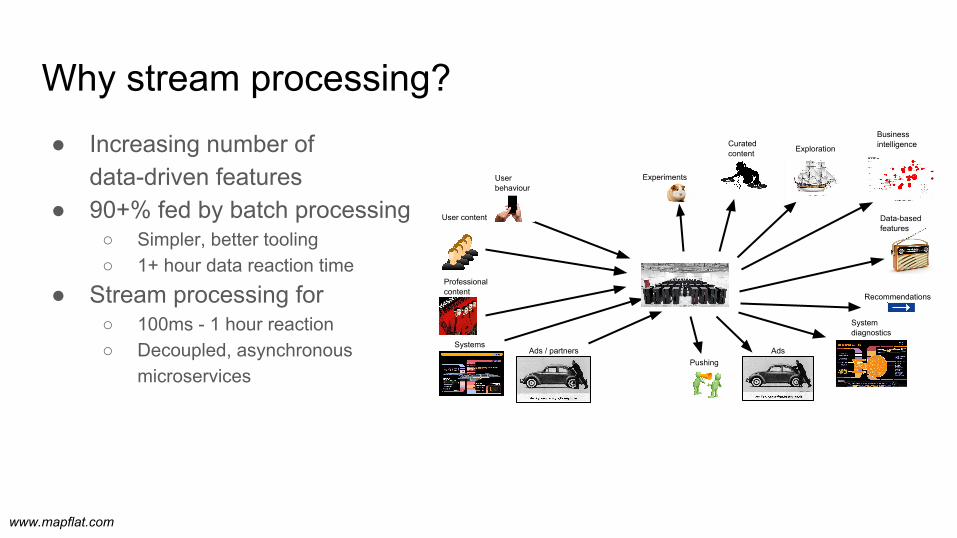
Why stream processing?● Increasing number of
data-driven features● 90+% fed by batch processing
○ Simpler, better tooling○ 1+ hour data reaction time
● Stream processing for○ 100ms - 1 hour reaction○ Decoupled, asynchronous
microservices
User content
Professional content
Ads / partners
Userbehaviour
SystemsAds
System diagnostics
Recommendations
Data-based features
Curated content
Pushing
Business intelligence
Experiments
Exploration
www.mapflat.com
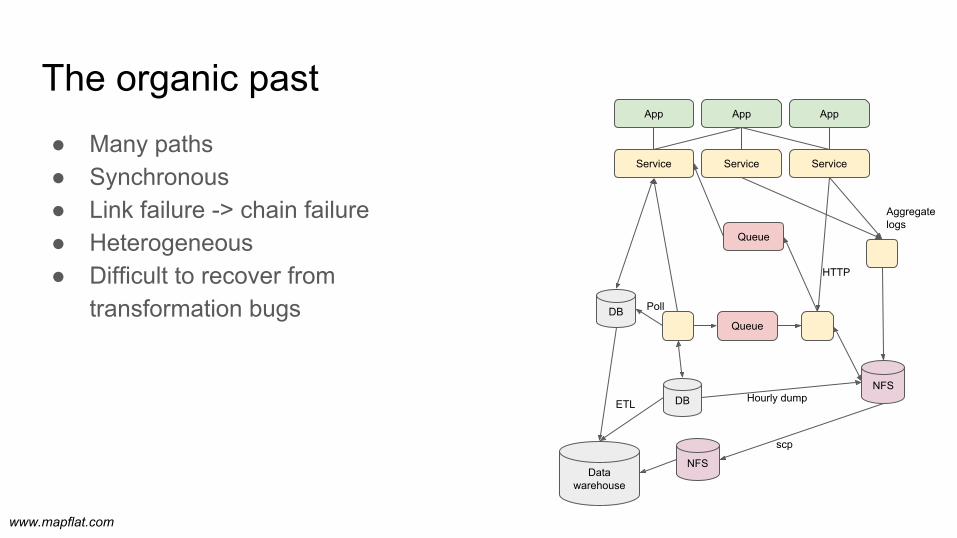
The organic past● Many paths● Synchronous● Link failure -> chain failure● Heterogeneous● Difficult to recover from
transformation bugs
Service Service Service
App App App
DB Poll
Queue
Aggregate logs
NFSHourly dump
Data warehouse
ETL
Queue
NFS
scp
DB
HTTP
www.mapflat.com
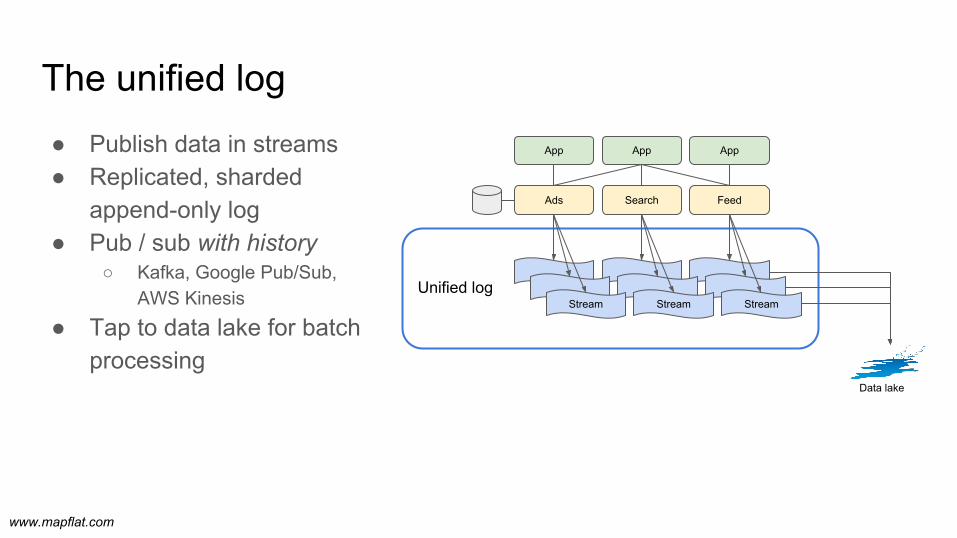
● Publish data in streams● Replicated, sharded
append-only log● Pub / sub with history
○ Kafka, Google Pub/Sub, AWS Kinesis
● Tap to data lake for batch processing
Unified log
The unified log
Ads Search Feed
App App App
StreamStream Stream
Data lake
www.mapflat.com
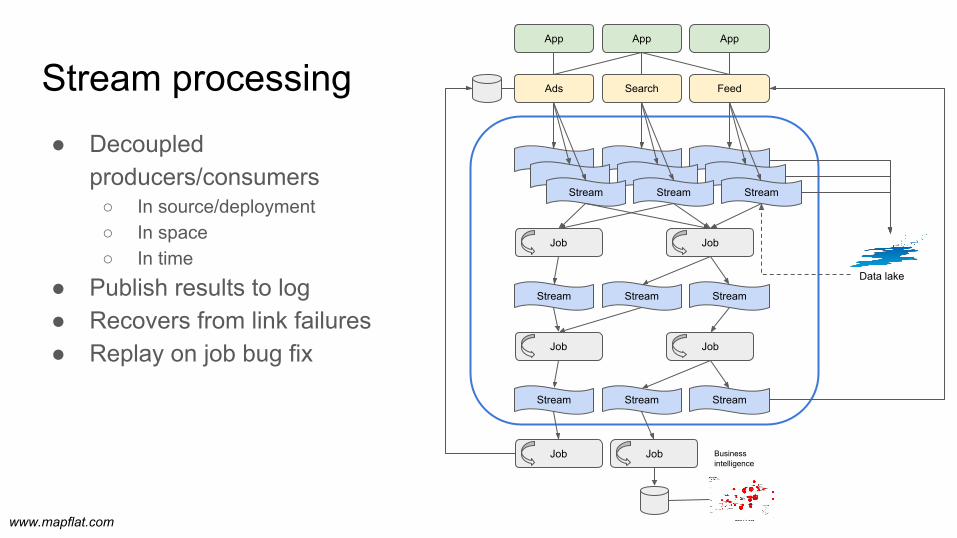
● Decoupled producers/consumers
○ In source/deployment○ In space○ In time
● Publish results to log● Recovers from link failures● Replay on job bug fix
Stream processing
Job
Ads Search Feed
App App App
StreamStream Stream
Stream Stream Stream
Job
Job
Stream Stream Stream
Job
Job
Data lake
Business intelligence
Job
www.mapflat.com
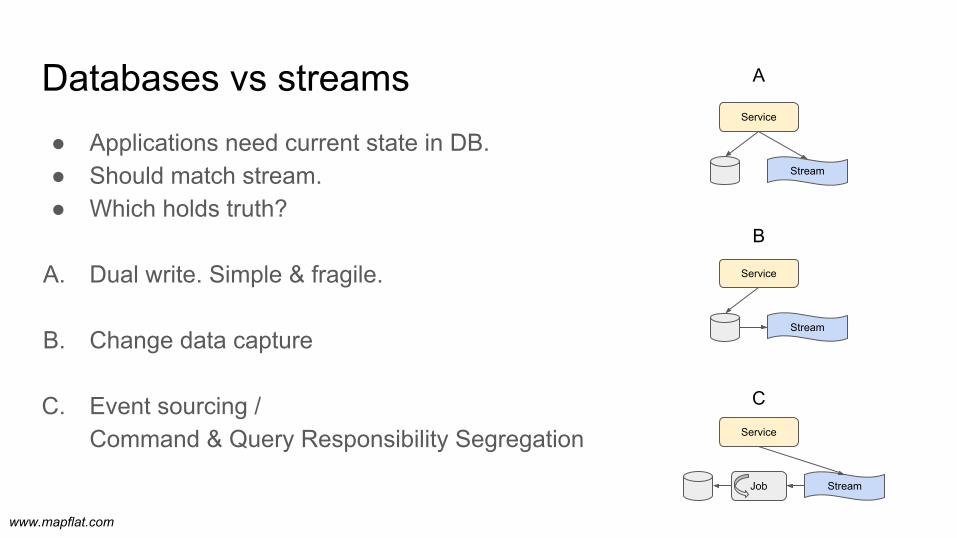
● Applications need current state in DB. ● Should match stream. ● Which holds truth?
A. Dual write. Simple & fragile.
B. Change data capture
C. Event sourcing / Command & Query Responsibility Segregation
Databases vs streams
Stream
Service
Stream
Service
Stream
Service
Job
A
B
C

www.mapflat.com
Stream processing building blocks ● Aggregate
○ Calculate time windows○ Aggregate state (in memory / local database / shared database)
● Filter○ Slim down stream○ Privacy, security concerns
● Join ○ Enrich by joining with datasets, e.g. geo IP lookup, demographics○ Join streams within time windows, e.g. click-through rate
● Transform○ Bring data into same “shape”, schema

www.mapflat.com
Stream processing technologies● Spark Streaming
○ Ideal if you are already using Spark, same model○ Bridges gap between data science / data engineers, batch and stream
● Kafka Streams○ Library - new, positions itself as a lightweight alternative○ Tightly coupled to Kafka
● Others○ Storm, Heron, Flink, Samza, Google Dataflow, AWS Lambda
www.mapflat.com
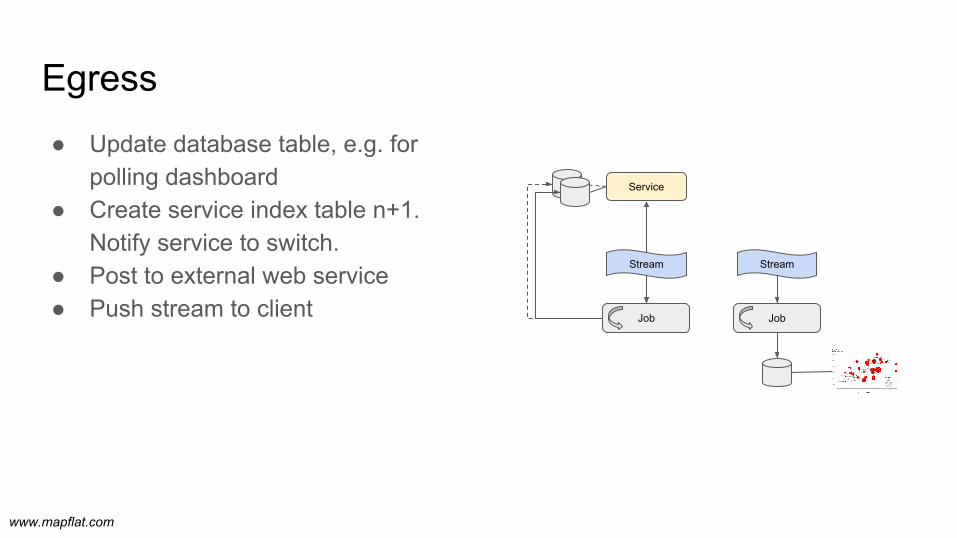
● Update database table, e.g. for polling dashboard
● Create service index table n+1. Notify service to switch.
● Post to external web service● Push stream to client
Egress
Service
Stream Stream
Job Job
www.mapflat.com
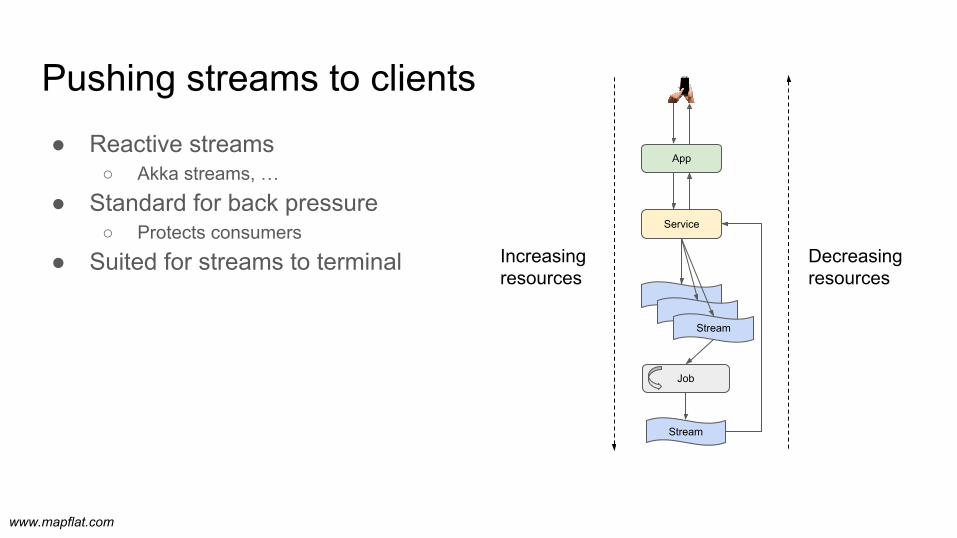
Pushing streams to clients● Reactive streams
○ Akka streams, …
● Standard for back pressure○ Protects consumers
● Suited for streams to terminal Increasing resources
Decreasing resources
Job
Service
App
Stream
Stream

www.mapflat.com
Real life challenges● Events are delayed● Events arrive out of order● Events are duplicated● Software changes● Software has bugs● Machines fail
Tooling, patterns, components do not provide sufficient solutions.
You need to plan and be aware.

www.mapflat.com
Architectural patternsStrategies for handling imperfection - bugs, late events, volumes
Stream Stream pipeline
Service
Batch pipeline
Lambda
Data lake
Kappa
Stream Stream job version n
Stream job version n+1
Data lake
Service
Stream
Switch
Dataflow
Stream Stream pipeline Service
Late events Updates
Delta
Stream Stream pipeline
Data lake
Service
Batch pipeline
Online
Nearline
Offline

www.mapflat.com
There is always a schema● Schema on write
+ Stronger safety net - catch bugs earlier- Requires upfront schema design before data can be received- Synchronised deployment of whole pipeline
● Schema on read + Allows data to be captured as is+ Easier to add/change fields- More work to keep data consistent

www.mapflat.com
Schema representation● Avro, JSON Schema● Records should include schema
○ Bundled○ Id + schema registry
● Evolution must be planned○ E.g. Backward compatible changes allowed; Incompatible -> new topic.○ Plan for replay of old messages

www.mapflat.com
Secret tip: miscount!● Sparse data structures
○ Trade little accuracy, 1-3%○ Gain space, factor 100 - 10000
● Basic approximate building blocks○ Approximate filter (Bloom filter), unique item counters (HyperLogLog), top lists (TopK),
per-item counter (Count-Min Sketch), percentiles (T-digest), nearest neighbours○ Sparse memories
● Sufficient for machine learning○ Collaborative filtering - recommendations○ Clustering○ Outlier detection○ Similarity search

www.mapflat.com
Thank you. Questions?Credits:
Øyvind Løkling, Schibsted Media Group
● Content inspirationConfluent, LinkedIn, Google, Netflix, Apache Samza
● ImagesTracey Saxby, Integration and Application Network, University of Maryland Center for Environmental Science (ian.umces.edu/imagelibrary/).