a new year in data science: ml unpaused
TRANSCRIPT

A New Year in Data Science: ML Unpaused
Data Day Texas Austin, 2015-01-10
Paco Nathan, @pacoid

Observations about Machine Learning, Data Science, Big Data, Open Source, Cluster Computing, Notebooks, etc., over the past year … plus, a look ahead

Backstory

Backstory: The Sun Also Rises
Some wake early in the morning and go build buildings

Backstory: The Sun Also Rises
Some wake early in the morning and go build buildings

Backstory: The Sun Also Rises
Some gaze into the heavens, sit back, and explain the process…

Backstory: The Sun Also Rises
Some gaze into the heavens, sit back, and explain the process…
Clearly, provably, our Sun revolves around the Earth at an observable rate

Backstory: The Sun Also Rises
Others create and evaluate models to predict the Earth’s orbit of the Sun

Backstory: The Sun Also Rises
Sometimes, when the sky gods become angry and obscure the Sun as our due punishment…
We grow scared and react: sacrifices must be offered, our plans must change, etc.

Backstory: The Sun Also Rises
Sometimes, when the sky gods become angry and obscure the Sunpunishment…
We grow scared and react: sacrifices must be offered, our plans must
These points are what I’d like to discuss today

Whither Data Science?
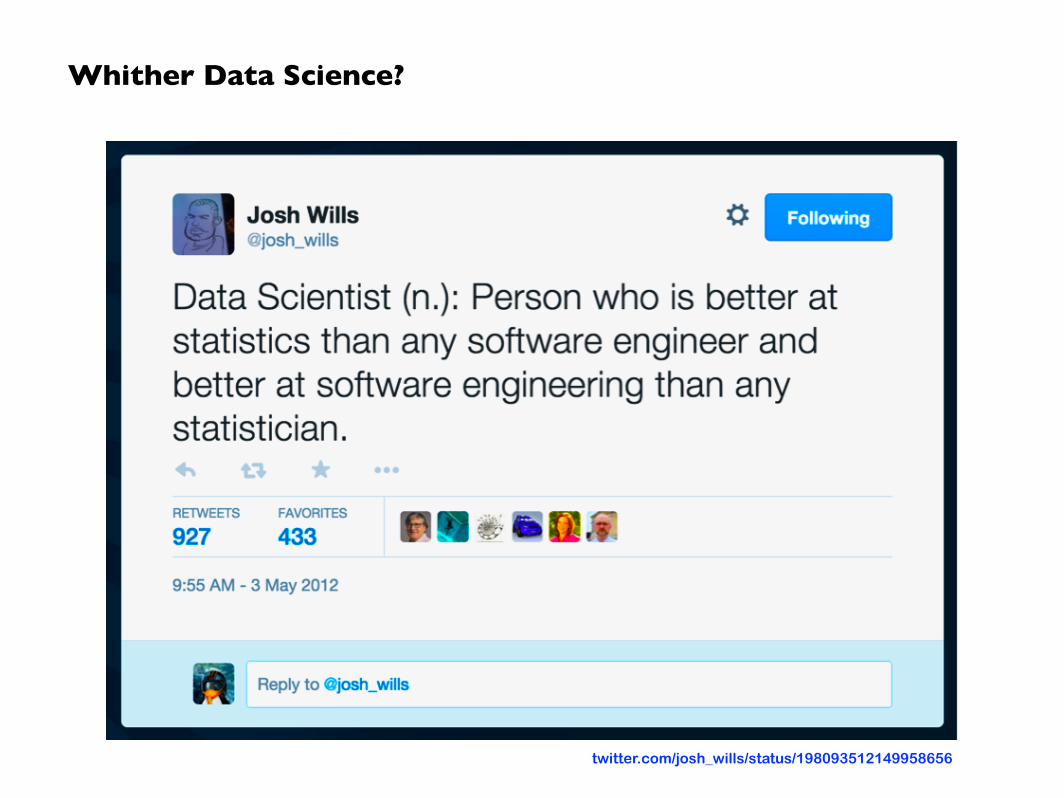
Whither Data Science?
twitter.com/josh_wills/status/198093512149958656

Feel free to disagree, but I find that definition to be flawed…
Whither Data Science?

Feel free to disagree, but I find that definition to be flawed…
1. That ignores DevOps (how’s that working out?) and Visualization/Design (ditto)
Whither Data Science?

Feel free to disagree, but I find that definition to be flawed…
1. That ignores DevOps (how’s that working out?) and Visualization/Design (ditto)
2. When the CEO asks you to help explain why revenue nose-dived over the past month… neither field has a clue about how to model business phenomena
Whither Data Science?

Software Engineering: implement and test a model that somebody selected
…almost ignores the matter of modeling entirely, at least not since old school types like Dijkstra
!
Statistics: measure and justify a model that somebody selected
…was never particularly good at teaching how to model problems – as two renowned statisticians, William Cleveland and Leo Breiman, noted
Whither Data Science?

Software Engineering: implement and test a model that somebody selected
…almost ignores the matter of modeling entirely, at least not since old school types like
!
Statistics: measure and justify a model that somebody selected
…was never particularly good at teaching how to model problems – as two renowned statisticians, William Cleveland
Whither Data Science?
Both fields are necessary, but not sufficient

The Thorn in the Side of Big Data: too few artists Christopher Ré, Stanfordsafaribooksonline.com/library/view/strata-conference-santa/9781491900321/part92.html
Whither Data Science?

The Thorn in the Side of Big Data: too few artistsChristopher Ré, Stanfordsafaribooksonline.com/library/view/strata-conference-santa/9781491900321/part92.html
Whither Data Science?
“You should think about features and not algorithms”

Remember EJBs?

Floyd Marinescu observed about the aftermath of EJBs in Brief History…
Intended for building framework components, e.g., for IBM, Oracle, Sun, but not many others
Based on RMI, prior to notions like RESTful web services
Enterprise Java Beans: Lessons from hate-watch reality television

Maybe a handful of people in the world would ever actually need to use EJBs, but those few people wanted a spec
Then, for tragic political reasons (MSFT envy), Sun Microsystems made EJBs prominent in their Java APIs
Enterprise Java Beans: Lessons from hate-watch reality television

Fortunately, we evolved: Spring, JBoss, etc., those came along as relatively more sane tech
Now we see the Docker thing soar, with notions such as microservices displacing legacy cruft
(BTW, if you haven’t yet, check out Weave)
Enterprise Java Beans: Lessons from hate-watch reality television

I mention this because, to me, EJB represented a convoluted form of template thinking:
Enterprise Java Beans: Lessons from hate-watch reality television
developing complex web apps for the sake of developing complex web apps

Enterprise Java Beans: Lessons from hate-watch reality television
IRL developers and template thinking don’t determine public policy… right?

Enterprise Java Beans: Lessons from hate-watch reality television
To paraphrase Dean Wampler, consider WordCount a simple apps written for MapReduce in Hadoop … ~50 lines of unapologetic Java that feels hella like writing EJBs:

Enterprise Java Beans: Lessons from hate-watch reality television
Compare that with functional programming, where the same WC app is three lines of easily-read Scala when run in Apache Spark:

Enterprise Java Beans: Lessons from hate-watch reality television
Check out Dean’s talk at 11:00, “Why Scala is Taking Over the Big Data World”
Compare that with functional programming, where the same WC app is three lines of easily-read Scala when run in Apache Spark:

Enterprise Java Beans: Lessons from hate-watch reality television
Hadoop suffers because, IMHO, that convoluted EJB style of developer-centric template thinking staged a coup
Perhaps we could “donate” some OSS talent…
Send a pull request…
Or something.

Lies, Damn Lies, Statistics, and Data Science

Probability got going, formally, in the 16th c. – although interesting mathematical estimations trace back to classical times
Arabs in the 9th c. used frequency analysis – later rediscovered by Europeans during the early Italian Renaissance
Statistics followed, originally more about what we might call demographics – through 18th c.
Lies, Damn Lies, Statistics, Data Science

Laplace, Gauss, et al., bridged the fields in the late 18th c. using distributions (what we studied in Stats 101) to infer the probability of errors in estimates
!
!
Much of the 19th/20th c. work was about using goodness of fit tests, etc., justifying some distribution
• generally speaking, that require samples
• that, in turn, implies batch windows
Lies, Damn Lies, Statistics, Data Science

Lies, Damn Lies, Statistics, Data Science
That kind of template thinking in action really lurvs it some batch windows

While 19th/20th c. stats work focused on defensibility
21st c. work, w.r.t. Big Data apps, focuses more on predictability – plus there’s a shift in how we make estimates…
Lies, Damn Lies, Statistics, Data Science
BTW, doesn’t it seem weird to crunch through piles of data in large batch jobs, at large expense, when the results get used to approximate features ultimately? Why not perform that in stream?

A fascinating, relatively new area pioneered by relatively few people – e.g., Philippe Flajolet
Provides approximation with error bounds using much less resources (RAM, CPU, etc.)
highlyscalable.wordpress.com/2012/05/01/probabilistic-structures-web-analytics-data-mining/
Lies, Damn Lies, Statistics, Data Science
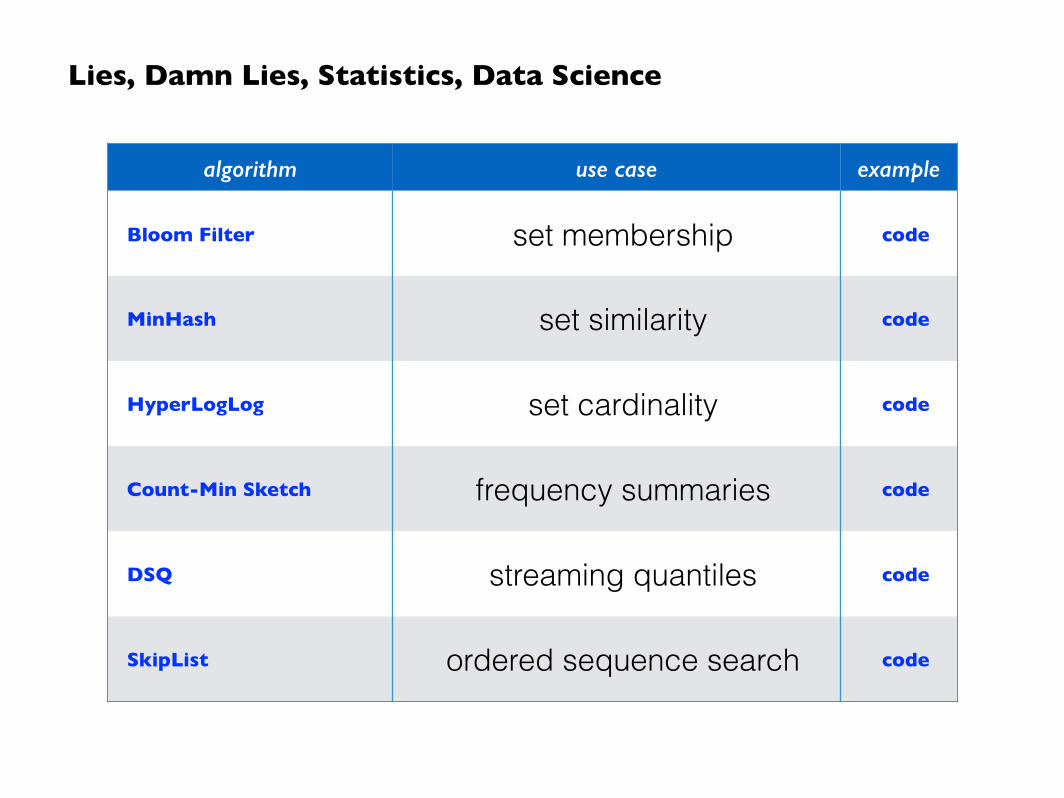
algorithm use case example
Bloom Filter set membership code
MinHash set similarity code
HyperLogLog set cardinality code
Count-Min Sketch frequency summaries code
DSQ streaming quantiles code
SkipList ordered sequence search code
Lies, Damn Lies, Statistics, Data Science

Lies, Damn Lies, Statistics, Data Science
E.g., ±4% could buy you two orders of magnitude reduction in the required memory footprint for an analytics app !OSS projects such as Algebird and BlinkDB provide for this newer approach to the math of approximations at scale

Lies, Damn Lies, Statistics, Data Science
E.g., ±4% could buy you two orders of magnitude reduction in the required memory footprint for an analytics app !OSS projects such as provide for this newer approach to the math of approximati
Oscar Boykin at 14:00, “Aggregators: Modeling Data Queries Functionally”
co-author of Algebird, Scalding

The Interzone

Data Science is inherently interdisciplinary
To paraphrase Chris Ré, emphasis on algorithms is relatively minor in the grand scheme –
Especially when compared to needs for modeling business problems effectively
To wit: beyond phenomenology, leading into quantitative analysis and repeatable results
On the one hand, CS + Stats do not quite address those needs…
The Interzone

On the other hand, Physics does well to teach modeling –
I like to hire physicists to work on Data teams…
The Interzone
They tend to get the interdisciplinary aspects: got the math background, coding experience, generally good at systems engineering, etc.
Not saying we should all rush out to get Physics degrees; there’s something to be learned there, vital for the work and priorities ahead

I mention this because we are at a crossroads, which has more to do with the physical world – some talks here at DDTx15 help illustrate that
Vast implications for Health Care, Transportation, Agriculture, Energy, Gov, Manufacturing in general…
More about that in a bit –
The Interzone

The Libraries

Most of the ML libraries that one encounters today focus on two general kinds of solutions:
• convex optimization
• matrix factorization
The Libraries: Alexandria Redux
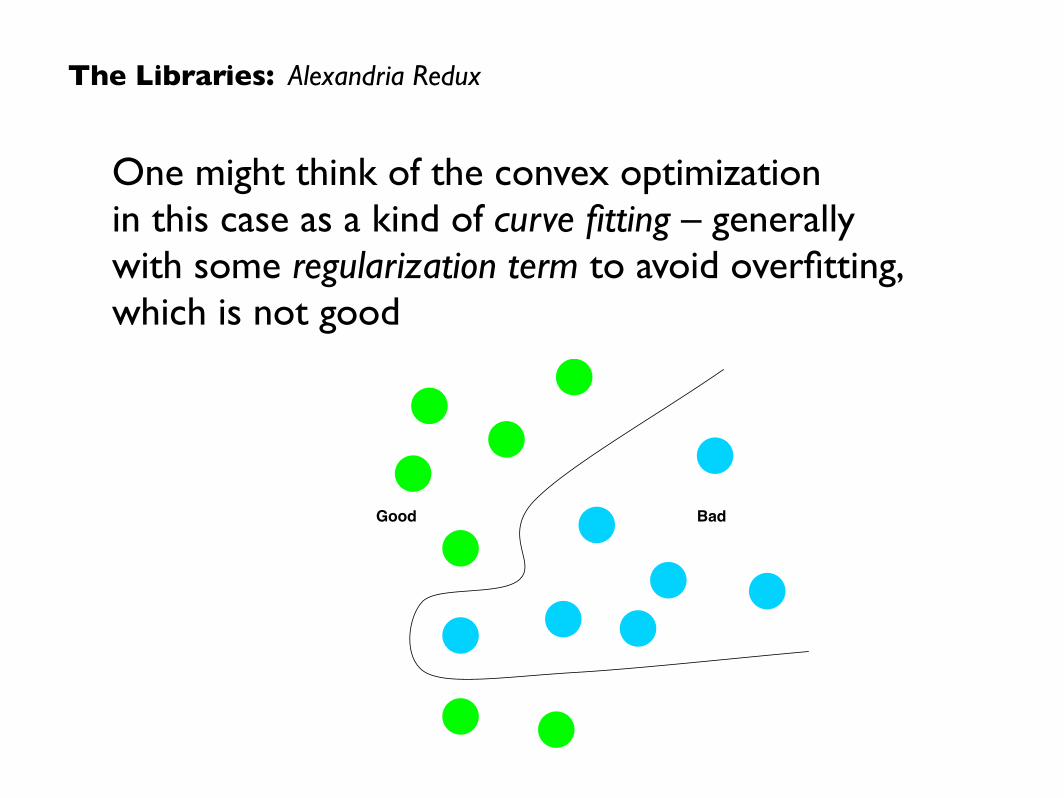
One might think of the convex optimization in this case as a kind of curve fitting – generally with some regularization term to avoid overfitting, which is not good
Good Bad
The Libraries: Alexandria Redux

For supervised learning, used to create classifiers:
1. categorize the expected data into N classes
2. split a sample of the data into train/test sets
3. use learners to optimize classifiers based onthe training set, to label the data into N classes
4. evaluate the classifiers against the test set, measuring error in predicted vs. expected labels
The Libraries: Alexandria Redux

Bokay, great for security problems with simply two classes: good guys vs. bad guys
How do you decide what the classes are for more complex problems in business?
That’s where the matrix factorization parts come in handy…
The Libraries: Alexandria Redux

For unsupervised learning, which is often used to reduce dimension:
1. create a covariance matrix of the data
2. solve for the eigenvectors and eigenvalues of the matrix
3. select the top N eigenvectors, based on diminishing returns for how they explain variance in the data
4. those eigenvectors define your N classes
The Libraries: Alexandria Redux

An excellent overview of ML definitions (up to this point) is given in:
The Libraries: Alexandria Redux
To wit: Generalization = Representation + Optimization + Evaluation
A Few Useful Things to Know about Machine Learning Pedro Domingos CACM 55:10 (Oct 2012) http://dl.acm.org/citation.cfm?id=2347755

evaluationoptimizationrepresentationcirca 2010
ETL into cluster/cloud
datadata
visualize,reporting
Data Prep
Features
Learners, Parameters
UnsupervisedLearning
Explore
train set
test set
models
Evaluate
Optimize
Scoringproduction
datause
cases
data pipelines
actionable resultsdecisions, feedback
bar developers
foo algorithms
Algorithms and developer-centric template thinking only go so far in a workflow…
Results are shown in blue, and the real work is highlighted in red
The Libraries: Alexandria Redux

evaluationoptimizationrepresentationcirca 2010
ETL into cluster/cloud
datadata
visualize,reporting
Data Prep
Features
Learners, Parameters
UnsupervisedLearning
Explore
train set
test set
models
Evaluate
Optimize
Scoringproduction
datause
cases
data pipelines
actionable resultsdecisions, feedback
bar developers
foo algorithms
Algorithms and developer-centric template thinking only go so far
Results are shown in is highlighted in
1. focus on features not algorithms
2. learn how to model business problems by leveraging data
3. notice the workflows needed?
4. leave the dev-centric thinking for odd city council meetings
The Libraries: Alexandria Redux
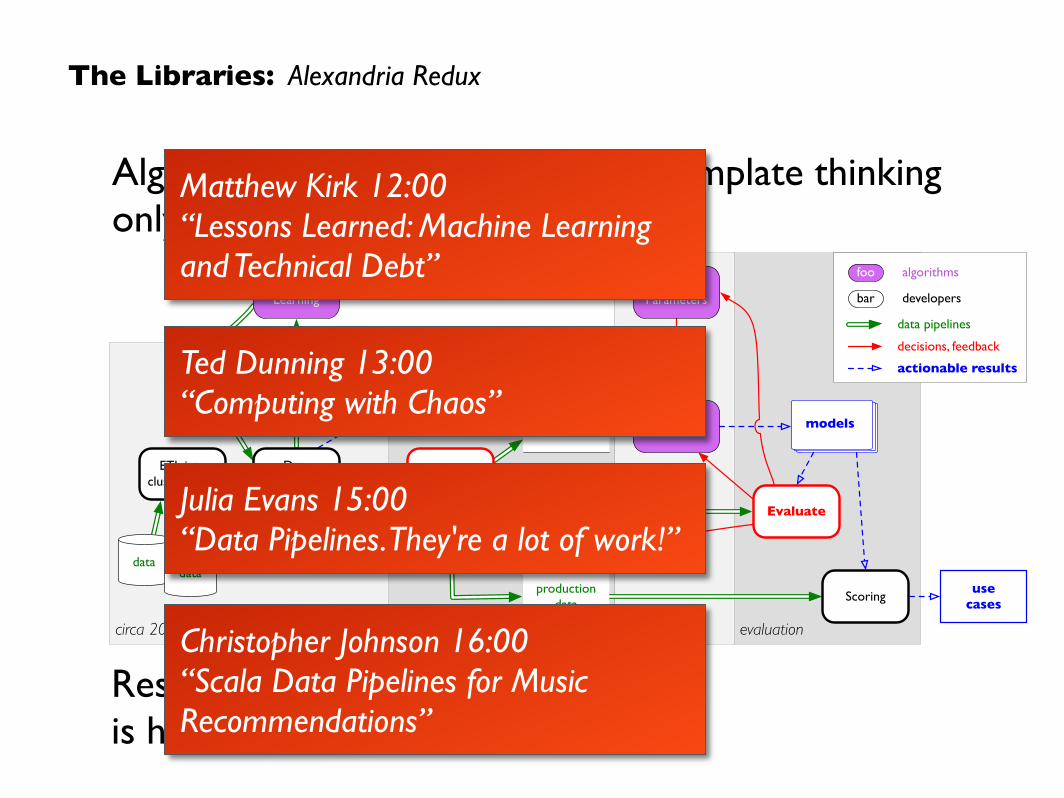
evaluationoptimizationrepresentationcirca 2010
ETL into cluster/cloud
datadata
visualize,reporting
Data Prep
Features
Learners, Parameters
UnsupervisedLearning
Explore
train set
test set
models
Evaluate
Optimize
Scoringproduction
datause
cases
data pipelines
actionable resultsdecisions, feedback
bar developers
foo algorithms
Algorithms and developer-centric template thinking only go so far
Results are shown in is highlighted in
The Libraries: Alexandria Redux
Matthew Kirk 12:00 “Lessons Learned: Machine Learning and Technical Debt”
Ted Dunning 13:00 “Computing with Chaos”
Julia Evans 15:00 “Data Pipelines. They're a lot of work!”
Christopher Johnson 16:00 “Scala Data Pipelines for Music Recommendations”

Even so, business demands exceed far beyond what classifiers and labels alone can give us…
Businesses lurv Optimization, gobs of it; in that context ML libraries today merely scratch the surface
Round hole, square peg
The Libraries: Alexandria Redux

Imagine that you compete with FedEx… how do you optimize delivery routes for airplanes, trucks, trains, nanodrones, hoverboards, etc.?
Which do you optimize: fuel cost, delivery time, maintenance schedules, minimizing lost packages?
Doesn’t sound much like online advertising, social networks, or any episode of Silicon Valley
The Libraries: Alexandria Redux

ML, Unpaused

What were the origins of machine learning?
• Marvin Minsky @MIT, 1950s
• Support Vector Machines @Bell Labs, 1990s
• Google @Stanford, 1990s
• Ray Kurzweil, 2000s
Nope…
ML, Unpaused

ML has been an aspect of AI research for a long while, through several different vectors
A good early history (up to 1980s) is given in:
ML, Unpaused
Machine Learning: A Historical and Methodological Analysis Jaime Carbonell, Ryszard Michalski, Tom Mitchell AI Magazine 4:3 (1983) http://dx.doi.org/10.1609/aimag.v4i3.406
To wit:
task-oriented studies, knowledge acquisition, cognitive simulation, theoretical exploration … overall, a much broader class of optimization problems

An era of anticipation – AI was making inroads…
• emphasis on capturing/representing knowledge and expertise – production use cases in medicine
• Fifth Generation Computing (parallel h/w) in Japan ⇒ MCC, etc.
However:
• few outside academia had enough cluster compute power – aside from 3-letter agencies and AT&T
• meanwhile ML was not yet considered “academic” enough within academia
Circa early 1980s:
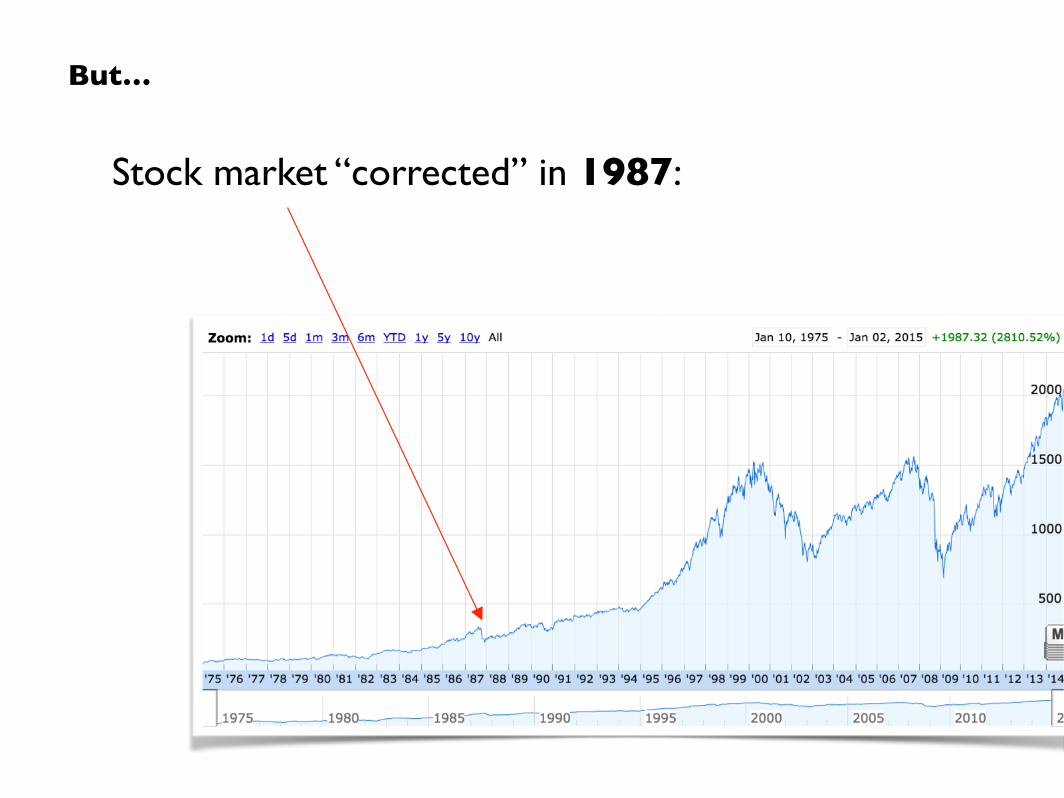
Stock market “corrected” in 1987:
But…

Some fundamental tech platforms emerge…
• Hubble Space Telescope, Human Genome Project, WWW, electric cars relaunched
And throughout that decade:
• Linux, Java @Sun, JavaScript @Netscape
• Firefly, an initial commercial ML app on teh interwebs @MIT Media Lab
• Rise of e-commerce leveraging horizontal scale-out with commodity hardware
Circa early 1990s:

Stock market “tumbled” in 2000:
But…

GOOG AMZN EBAY YHOO LNKD NFLX FB TWTR emerged out of the dust…
• web apps dominated for search, e-commerce, social networks, etc.
• did we mention EJBs and template thinking?
• mobile picked up traction
• recommender systems went mainstream
• AI picked up with semantic web efforts…
Circa early 2000s:

Stock market “went free-fall” in 2008:
But…

Successful e-commerce firms have IPO’ed and are now busy building skyscrapers in downtown SF…
Circa mid 2010s:
LinkedIn, 350 Bush
Transbay Transit
Salesforce, 415 Mission

An odd truism about the hubris of the uber-wealthy and the timing of their skyscraper projects…
But…
Sears Tower, Chicago
Lehman Brothers, London
Fontainebleau, Las Vegas

An odd truism about the hubris of the uber-wealthy and the timing of their skyscraper projects…
But…

Businesses lurv Optimization, lots of it…
• ML circa 1985 focused on those needs, but got knocked back to something inevitably more aristotelian and predictable
• Outside of Silicon Valley, we’ve made big strides
• One danger: next downturn cycle, VCs might reshape tech industry, reverting to “safe bets”
Circa mid 2010s: Back to the Future
However, a few extremely interesting aspects have emerged…

evaluationoptimizationrepresentationcirca 2010
ETL into cluster/cloud
datadata
visualize,reporting
Data Prep
Features
Learners, Parameters
UnsupervisedLearning
Explore
train set
test set
models
Evaluate
Optimize
Scoringproduction
datause
cases
data pipelines
actionable resultsdecisions, feedback
bar developers
foo algorithms
We have approximation, deep learning and symbolic regression to assist on “Features”
evaluationoptimizationrepresentationcirca 2010
ETL into cluster/cloud
datadata
visualize,reporting
Data Prep
Features
Learners, Parameters
UnsupervisedLearning
Explore
train set
test set
models
Evaluate
Optimize
Scoringproduction
datause
cases
data pipelines
actionable resultsdecisions, feedback
bar developers
foo algorithms
Or, maybe, cognitive computing will help on several of the more difficult aspects of this…
Circa mid 2010s: Extremely Interesting Emerging Aspects

Circa mid 2010s: Extremely Interesting Emerging Aspects
DeepDive @Stanford http://deepdive.stanford.edu/
Knowledge Graph @Google http://www.google.com/insidesearch/features/search/knowledge.html
IBM Watson http://www.ibm.com/smarterplanet/us/en/ibmwatson/
Scaled Inference https://scaledinference.com/

Circa mid 2010s: Extremely Interesting Emerging Aspects
Rhetorical postures: “Is AI a good idea, or potentially harmful?” – per Elon Musk, et al.

Circa mid 2010s: Extremely Interesting Emerging Aspects
Clearly: good idea brewbot.io
Rhetorical postures: “Is AI a good idea, or potentially harmful?” – per Elon Musk, et al.

Circa mid 2010s: Extremely Interesting Emerging Aspects
Speaking of which, a highly recommended podcast by actual data scientists drinking really good beers: partiallyderivative.com

Circa mid 2010s: Extremely Interesting Emerging Aspects
2015: Notebooks in Containers in the Cloud
“Keep simple things simple and complex things possible.” databricks.com/product
Publishing Workflows for Jupyter Andrew Odewahn, Kyle Kelley, Rune Madsen odewahn.github.io/publishing-workflows-for-jupyter
IPython Interactive Demo Nature Magazine + Rackspace nature.com/news/ipython-interactive-demo-7.21492

2015: Notebooks in Containers in the Cloud
“Keep simple things simple and complex things possible.” databricks.com/product
Publishing Workflows for Jupyter Andrew Odewahnodewahn.github.io/publishing-workflows-for-jupyter
IPython Interactive DemoNature Magazine + Rackspace nature.com/news/ipython-interactive-demo-7.21492
Circa mid 2010s: Extremely Interesting Emerging Aspects
Makes me wonder about the “data engineer” role … notebooks simplify ops needs, while ultimately the domain experts wield the real power with data

Frontstory

Frontstory: The Sun Also Rises
Some wake early in the morning and go build buildings
dev-centric templates

Some gaze into the heavens, sit back, and explain the process…
20th c. stats
Frontstory: The Sun Also Rises

Sometimes, when the sky gods become angry and obscure the Sun as our due punishment… VCs during recessions
Frontstory: The Sun Also Rises

Others create and evaluate models to predict the Earth’s orbit of the Sun
What’s needed most
Frontstory: The Sun Also Rises

Forward Motion:
SV trend: early data scientists displace old-school product managers
Because there are hard problems to be solved…
Because we need new eyes on target…
Because use cases…

Because Use Cases

Because Use Cases: Health Care
“In fact, using our Topological Data Analysis system, they were able to discover multiple types of Type 2 diabetes … huge impact on all the hundreds of millions of people” – Ayasdi
“Nobody knows what to do with those archives … They’re just sitting there, costing money. This is just seen as a big opportunity. It’s like, ‘Oh, this is what we were saving this up for!’” – Enlitic
“Sloan-Kettering is also training Watson on 1,500 real-world lung cancer cases, helping it to decipher physician notes and learn from the hospital’s expertise in treating cancer.” – IBM Watson
Employing tech such as deep learning and cognitive computing for vital use cases in health care:

Because Use Cases: Transportation
http://automatic.com/ !Detects events like hard braking, acceleration – uploaded in real-time with geolocation to a Spark Streaming pipeline … data trends indicate road hazards, blind intersections, bad signal placement, and other input to improve traffic planning. Also detects inefficient vehicle operation, under-inflated tires, poor driving behaviors, aggressive acceleration, etc.

Because Use Cases: Education
https://databricks.com/blog/2014/12/08/pearson… !Integrates Kafka + Spark Streaming + Cassandra + Blur, running within a YARN cluster on AWS to provide a scalable, reliable, cloud-based platform for services that analyze student performance across product and institution boundaries.
Delivers immersive learning experiences designed for how students read, think, and learn; as well as efficacy insights to both learners and institutions which were not possible before. !Reliability features handle Kafka node failures, receiver failures, leader changes, committed offset in ZK, plus adjustable data-rate throughput.

Because Use Cases: Language, everywhere
http://idibon.com/ !!!Our social fabric is encoded as text documents, and similarly it get tested, deployed, maintained, and monitored there – it’s the launch point for cognitive computing.
http://digitalreasoning.com/

http://digitalreasoning.com/
Because Use Cases: Language, everywhere
http://idibon.com/!!!Our social fabric is encoded as text documents, and similarly it get tested, deployed, maintained, and monitored there – it’s the launch point for cognitive computing.
Robert Munroe, 12:00 “Building Better Experts: co-optimization of human and machine intelligence at Idibon”
Andrew Trask, David Gilmore 11:00 “Deep Learning for Natural Language Processing”

Because Use Cases: Geospatial
Advanced geo uses cases throughout all levels of gov and industry for Big Data, machine learning, graph algorithms, approximations, etc.
If you roll trucks you probably use licenses from ESRI.
Also consider the IoT sensor data, e.g., from National Instruments' customers – where does it go, what do organizations use to analyze it?
These are the large-scale optimization problems you were looking for…
http://esri.github.io/gis-tools-for-hadoop/ (and Spark) http://thunderheadxpler.blogspot.com/ http://geotrellis.io/ http://www.oculusinfo.com/tiles/ https://databricks.com/blog/2014/12/03/app...

Because Use Cases: Telecom, Travel, Banking, etc.
http://spark-summit.org/2014/talk/stratio-streaming…
Stratio represents one of the most sophisticated integrations for Spark Streaming – the union of a real-time messaging bus with a complex event processing engine: Kafka, Spark Streaming, Cassandra, along with the Siddhi CEP engine
Telecom, in particular, is leveraging this new streaming technology as a big win near-term
http://www.openstratio.org/https://github.com/stratio https://github.com/Stratio/streaming-cep-engine
BTW if you’re in Madrid next fall check out Big Data Hispano

Because Use Cases…
Common theme: many of those use cases are powered by Apache Spark –
Especially notice Spark Streaming, which is a big game-changer for analytics across industry

Because Use Cases…
Common theme: many of those use cases are powered by
Especially notice game-changer for analytics across industry
Taylor Goetz 11:00 “Beyond the Tweeting Toaster: IoT Streaming Analytics With Apache Storm, Kafka, and Arduino”
Hari Shreedharan 12:00 “Real Time Data Processing Using Spark Streaming”

Because Use Cases: Agriculture
Ag+Data Issues http://radar.oreilly.com/2014/04/agdata.html
Data Guild whitepaper: Ag Systems + Data Outlook http://goo.gl/OK8RFf
• livelihood for 40% of world population • $15T/year annual GDP globally • data-intensive issues, much legal impasse
Over a half billion small farms worldwide, and most are family-run farms that rely on rain-fed agriculture
Nudge, and I just might propose DWave clusters into cold craters on the Lunar South Pole with routers @L5 and an LLO skyhook… to handle the vector quantization demands. Or something.
airshipse.g., JP Aerospace, 40 km
atmostatse.g., Titan Aerospace, 20 km
microsatse.g., Planet Labs, 400 km
robotse.g., Blue River, 1 m
sensorse.g., Hortau, -0.3 m
dronese.g., HoneyComb, 120 m
Layered Sensing Networks

Resources

Apache Spark developer certificate program
• http://oreilly.com/go/sparkcert
• defined by Spark experts @Databricks
• assessed by O’Reilly Media
• establishes the bar for Spark expertise
certification:

MOOCs:
Anthony Joseph UC Berkeley begins 2015-02-23 edx.org/course/uc-berkeleyx/uc-berkeleyx-cs100-1x-introduction-big-6181
Ameet Talwalkar UCLA begins 2015-04-14 edx.org/course/uc-berkeleyx/uc-berkeleyx-cs190-1x-scalable-machine-6066

community:
spark.apache.org/community.html
events worldwide: goo.gl/2YqJZK
!video+preso archives: spark-summit.org
resources: databricks.com/spark-training-resources
workshops: databricks.com/spark-training


confs:Strata CA San Jose, Feb 18-20 strataconf.com/strata2015
Spark Summit East NYC, Mar 18-19 spark-summit.org/east
Big Data Tech Con Boston, Apr 26-28 bigdatatechcon.com
Strata EULondon, May 5-7 strataconf.com/big-data-conference-uk-2015
Spark Summit 2015 SF, Jun 15-17 spark-summit.org

books:
Fast Data Processing with Spark Holden Karau Packt (2013) shop.oreilly.com/product/9781782167068.do
Spark in Action Chris FreglyManning (2015*) sparkinaction.com/
Learning Spark Holden Karau, Andy Konwinski, Matei ZahariaO’Reilly (2015*) shop.oreilly.com/product/0636920028512.do

presenter:
Just Enough Math O’Reilly, 2014
justenoughmath.compreview: youtu.be/TQ58cWgdCpA
monthly newsletter for updates, events, conf summaries, etc.: liber118.com/pxn/
Enterprise Data Workflows with Cascading O’Reilly, 2013
shop.oreilly.com/product/0636920028536.do