a linguistically-informed fusion approach for multimodal … · 2018-08-10 · phase, which ensured...
TRANSCRIPT

Proceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic, pages 13–24New Orleans, Louisiana, June 5, 2018. c©2018 Association for Computational Linguistics
A Linguistically-Informed Fusion Approach for Multimodal DepressionDetection
Michelle Renee MoralesLinguistics Department
The Graduate Center, CUNYNew York, NY 10016
Stefan SchererUSC Institute for
Creative TechnologiesLos Angeles, CA [email protected]
Rivka LevitanComputer Science Department
Brooklyn College, CUNYBrooklyn, NY 11210
Abstract
Automated depression detection is inherentlya multimodal problem. Therefore, it is criticalthat researchers investigate fusion techniquesfor multimodal design. This paper presents thefirst ever comprehensive study of fusion tech-niques for depression detection. In addition,we present novel linguistically-motivated fu-sion techniques, which we find outperform ex-isting approaches.
1 Introduction
Depression is an extremely heterogeneous disor-der that is difficult to diagnose. Given this dif-ficulty, psychologists and linguists have investi-gated possible objective markers and have shownthat depression influences how a person behavesand communicates, affecting facial expression,prosody, syntax, and semantics (Morales et al.,2017a). Given that depression affects both non-verbal and verbal behavior, an automated detec-tion system should be multimodal. Initial studieson depression detection from multimodal featureshave shown performance gains can be achievedby combining information from various modalities(Morales and Levitan, 2016; Scherer et al., 2014).However, few studies have investigated fusion ap-proaches for depression detection (Alghowinemet al., 2015). In this paper, we present a novel lin-guistically motivated approach to fusion: syntax-informed fusion. We compare this novel approachto early fusion and find it is able to outperform it.We also demonstrate that this approach overcomessome of the limitations of early fusion. Moreover,we test our approach’s robustness by applying thesame framework to generate a visual-informed fu-sion model. We find video-informed fusion alsooutperforms early fusion. In addition to presentingnovel fusion techniques, we also evaluate existingapproaches to fusion including early, late, and hy-
brid fusion. To the best of our knowledge, thiswork presents the first in-depth investigation of fu-sion techniques for depression detection. Lastly,we present interesting results to further support therelationship between depression and syntax.
2 Related Work
This work presents a multimodal detection systemwith a specific focus on the relationship betweendepression and syntax. This relationship motivatesa novel approach to fusion. In contrast to a simpleearly fusion approach to combining modalities, asyntax-informed early fusion approach leveragesthe relationship between syntax and depression tohelp improve system performance. In this sec-tion, we first provide background on the relation-ship between depression and language, highlight-ing both the voice and syntax. In addition, we alsoevaluate a video-informed fusion approach whichis motivated from the relationship between depres-sion and facial activity as well as the relationshipbetween facial behavior and speech production.Therefore, we also present related work on the re-lationship between visual information and depres-sion. This is followed by a review of related workon multimodal fusion techniques that have beeninvestigated for depression detection systems. Inthis section, we will only briefly cover relevantwork, for a detailed review of multimodal depres-sion detection systems see Morales et al. (2017a).
2.1 The Relationship between Depressionand Language
Researchers have investigated the relationship be-tween prosodic, articulatory, and acoustic featuresof speech and clinical ratings of depression (Cum-mins et al., 2015). In patients with depression,several changes in speech and voice have beennoted, including changes in prosody (Blankenet al., 1993), speaking rate (?Stassen et al., 1998),
13

speech pauses (Alpert et al., 2001), and voice qual-ity (Scherer et al., 2013a).
In addition to voice and speech-based markers,researchers have also provided empirical supportfor the existence of a relationship between depres-sion and syntax. Depressed individuals exhibitmany syntactic patterns including an increaseduse of first person singular pronouns (Rude et al.,2004) and a decreased use of complex syntacticconstructions, such as adverbial clauses (Zinkenet al., 2010). The relationship between syntax anddepression motivates our syntax-informed fusionapproach.
2.2 The Relationship between Depressionand Facial Activity
Similar to the relationship between language anddepression, there also exists a body of researchon the relationship between depression and facialactivity. Depression affects individuals’ facial ex-pressions, including noted decreases in expressiv-ity, eyebrow movements, and smiling (Cumminset al., 2015).
In addition, there also exists an interesting re-lationship between video and audio, e.g. theMcGurk effect. McGurk and MacDonald (1976)were the first to report a previously unrecognizedinfluence of vision upon speech perception. Intheir study, they showed participants a video of ayoung woman speaking, where she repeated utter-ances of the syllable [ba] which had been dubbedon to lip movements for the syllable [ga]. Par-ticipants reported hearing [da]. Then with the re-verse dubbing process, a majority reported hearing[bagba] or [gaba]. However, when participants lis-tened to only the sound of the video or when theywatched the unprocessed video, they reported thesyllables accurately as repetitions of [ba] or [ga].These findings had important implications for theunderstanding of speech perception, specificallythat visual information a person gets from seeing aperson speak changes the way they hear the sound.
These interesting relationships —between theface and voice as well as facial expressions anddepression —motivate our video-informed fusionapproach.
2.3 Existing Fusion ApproachesIn recent years, researchers have begun to investi-gate multimodal features for depression detectionsystems (Morales et al., 2017b). However, it is afairly new research interest and as a result only a
few studies have compared techniques for fusingfeatures from different modalities (Alghowinemet al., 2015). In the few studies that have investi-gated fusion techniques, the canonical fusion tech-niques have been considered, including early, late,and hybrid fusion. In the early fusion approach,features are integrated immediately after they aregenerated through simple concatenation of featurevectors. In the late fusion approach integrationoccurs after each of the modalities have made adecision. In the hybrid fusion approach outputsfrom early fusion and individual unimodal predic-tors are combined (Baltrusaitis et al., 2017).
Researchers have found early fusion, althoughsimple, to be a successful technique to combinemodalities for depression, noting improvementsover unimodal systems (Alghowinem et al., 2015;Morales and Levitan, 2016; Morales et al., 2017b;Scherer et al., 2013b). However, a drawback of theearly fusion approach is the high dimensionality ofthe combined feature vector. Given that drawback,Joshi et al. (2013) considered early fusion as wellas early fusion followed by Principal ComponentAnalysis (PCA), where 98% of the variance waskept. They found that training a depression de-tection model on this reduced dimensionality fea-ture set led to improved performance of the systemover simple early fusion.
Researchers have also investigated late and hy-brid fusion. In Alghowinem et al. (2015) a hybridfusion approach was investigated, which involvedconcatenating results from individual modalitiesto the the early fusion feature vector. A major-ity voting method was used. They evaluated howhybrid fusion and early fusion approaches com-pare to unimodal approaches. They found thatin most cases their early and hybrid fusion mod-els outperformed the unimodal models. Moreover,hybrid fusion models tended to outperform earlyfusion. Late fusion approaches have also been in-vestigated by some (Joshi et al., 2013; Meng et al.,2013). For example, Meng et al. (2013) used alate fusion approach that trained a separate modelfrom each modality and combined decisions usingthe weighted sum rule. They found that combin-ing visual and vocal features at the decision levelresulted in further system improvement for depres-sion detection.
Although, in this work, we focus on fusion ap-proaches for depression detection, there exist vari-ous studies investigating fusion for other machine
14

learning tasks. Researchers have also proposednew approaches to fusion which differ from thecanonical approaches. In particular, deep learn-ing approaches to fusion appear to be particularlypromising. For example, Mendels et al. (2017)presented a single hybrid deep model with bothacoustic and lexical features trained jointly andfound that this approach to fusion achieved state-of-the-art results for deception detection. How-ever, deep learning is not currently a good ap-proach for depression detection, since labeled cor-pora are not very large and interpretable modelsare important.
3 Dataset
In this work, we use the Distress Analysis Inter-view Corpus-Wizard of Oz (DAIC-WOZ; Gratchet al., 2014). The corpus is multimodal (video,audio, and transcripts) and is comprised of videointerviews between participants and an animatedvirtual interviewer called Ellie, which is controlledby a human interviewer in another room.
Interview participants were drawn from theGreater Los Angeles metropolitan area and in-cluded two distinct populations: (1) the generalpublic and (2) veterans of the U.S. armed forces.Participants were coded for depression, Posttrau-matic Stress Disorder (PTSD), and anxiety basedon accepted psychiatric questionnaires. All par-ticipants were fluent English speakers and all in-terviews were conducted in English. The DAIC-WOZ interviews ranged from 5 to 20 minutes.
The interview started with neutral questions,which were designed to build rapport and make theparticipant comfortable. The interview then pro-gressed into more targeted questions about symp-toms and events related to depression and PTSD.Lastly, the interview ended with a ‘cool-down’phase, which ensured that participants would notleave the interview in a distressed state. The de-pression label provided includes a PHQ–81 score(scale from 0 to 24) as well as a binary depressionclass label, i.e., score >= 10.
4 Features
In this work we use the OpenMM2 pipeline to ex-tract multimodal features (Morales et al., 2017b),
1http://patienteducation.stanford.edu/research/phq.pdf
2https://github.com/michellemorales/OpenMM
which uses Covarep (Degottex et al., 2014) andParsey McParseface (Andor et al., 2016) to extractvoice and syntax features.
4.1 Voice
In order to extract features from the voice,OpenMM employs Covarep (Degottex et al.,2014). The audio features extracted includeprosodic, voice quality, and spectral features.Prosodic features include Fundamental frequency(F0) and voicing boundaries (VUV). Covarepvoice quality features include Normalised ampli-tude quotient (NAQ), quasi open quotient (QOQ),the difference in amplitude of the first two har-monics of the differentiated glottal source spec-trum (H1H2), parabolic spectral parameter (PSP),maxima dispersion quotient (MDQ), spectraltilt/slope of wavelet responses (peakslope), andshape parameter of the Liljencrants-Fant modelof the glottal pulse dynamics (Rd). Spectral fea-tures include Mel cepstral coefficients (MCEP0-24), harmonic model and phase distortion mean(HMPDM0-24) and deviations (HMPDD0-12).Lastly, Covarep includes a creak feature whichis derived through a creaky voice detection algo-rithm.
4.2 Syntax
In order to generate syntactic features OpenMMemploys Google’s state-of-the-art pre-trained tag-ger: Parsey McParseface (Andor et al., 2016). Foreach sentence S, the tagger outputs POS tags. Inthis work, we make use of 17 POS tags, which areoutlined in Table ?? of the Appendix.
4.3 Visual
The visual features we consider are Action Units(AUs), which were extracted from the DAIC-WOZ corpus as part of the baseline system forthe AVEC 2017 challenge (Ringeval et al., 2017).AUs represent the fundamental actions of individ-ual muscles or groups of muscles. It is a com-monly used tool and has become standard to sys-tematically categorize physical expressions, whichhas proven very useful for psychologists. A de-tailed list of the facial AUs we consider are givenin Table ?? of the Appendix. Each AU receivesa presence score, between -5 and 5, which mea-sures how present that feature is for a given frameof video.
15

5 Fusion Approaches
5.1 Early FusionIn our early fusion approach, features are extractedfrom each modality and then concatenated to gen-erate a single feature vector. Visual and acousticfeatures are extracted at the frame level while POStags are extracted at the sentence level. Therefore,the modalities do not align automatically. In or-der to handle these differences, we first computestatistics (mean, median, standard deviation, max-imum, and minimum) across frames/sentences.This results in 370 acoustic features (74 acous-tic features ⇥ 5 statistical functionals), 100 visualfeatures (20 visual ⇥ 5 statistical functionals), and85 syntactic features (17 syntactic features ⇥ 5statistical functionals). We then fuse the featurevectors to achieve one multimodal feature vector,featuresearly.
featuresearly =
Acoustic Syntax26664
x0
x1...xi
37775 +
26664
y0
y1...yi
37775
5.2 Informed Early Fusion5.2.1 Syntax-informed Early FusionWe compare early fusion to our proposed ap-proach. Our approach leverages syntactic infor-mation to target more informative aspects of thespeech signal. Given the relationship between de-pression and syntax, we hypothesize that this ap-proach will help lead to improvements in systemperformance. First, we align the audio file andtranscript file. In order to perform alignment, weuse the tool gentle3, which is a forced-aligner builton Kaldi. We then tag each sentence and retrievethe timestamp information for each POS tag. Foreach POS tag span we extract acoustic features forthat time span.
featuresmm =
0BBB@
y0 . . . yi
x0 x0 . . . x0
x1 x1 . . . x1...
......
...xi xi . . . xi
1CCCA
In other words, we are specifically extracting fea-tures at the POS level and we are continuously
3https://github.com/lowerquality/gentle
updating our audio features each time we comeacross a POS tag. For example, each time we see aVERB we use its timestamp information to extractmean F0 from that specific window and we do thiscontinuously, updating our F0 value every timewe come across a VERB. In the end, we have amean F0 value across all VERBs, ADJs, NOUNs,etc., as shown in featuresmm. This representa-tion is different from early fusion in that it condi-tions the audio features on POS information, pro-viding a representation that does not simply addfeatures from each modality, but instead aims tojointly represent them.
5.2.2 Video-informed Early FusionIn order to test the robustness of our novel fu-sion approach —informed early fusion —we per-form additional experiments using other modali-ties. The relationship between a person’s facialbehavior and speech production, motivates ourvideo-informed fusion approach. Similar to oursyntax-informed approach, where we target POStags’ time frames to identify more informative as-pects of the speech signal, we also target aspectsof the speech signal using visual information. Wehypothesize that targeting informative aspects ofthe speech signal using visual cues will help boostsystem performance when compared with a simpleearly fusion system.
Similar to syntax-informed fusion, this repre-sentation conditions the audio features on AU in-formation. For each frame of video, we identifythe AU with the highest presence (value between-5 and 5). Therefore, we assume only one AU canoccur per frame. For the AU with the highest pres-ence, we extract acoustic features across that spanof time. For each AU, we then aggregate its acous-tic features across the entire video. In the end, wehave a mean value for each acoustic feature acrossall AUs.
5.3 Late Fusion
We explore two types of late fusion approaches:(1) voting and (2) ensemble. In our voting ap-proach, we train separate classification modelsfor each modality. Each unimodal system makesa classification prediction, depressed or not de-pressed. We then take the majority vote as our ul-timate prediction. We also consider an ensembleapproach. In our ensemble late fusion approach,we again train separate classification models foreach modality. The models’ predictions are then
16

Modality Fusion Type Precision Recall F1-score
A – 0.34 0.70 0.45
S – 0.21 0.96 0.35
V – 0.16 0.52 0.25
A + S E 0.34 0.70 0.45
A + S I 0.40 0.69 0.49
A + S E + I 0.36 0.62 0.44
A + V E 0.37 0.70 0.48
A + V I 0.36 0.77 0.49
A + V E + I 0.34 0.74 0.46
Table 1: Results for 5-fold cross-validation using SVM. Results reported for the audio(A), syntax (S), video (V), and fusion (A + S) approaches. Fusion types include early(E), syntax-informed (I), and both (E + I).
used as features to train a new classification sys-tem. The predictions from the newly trained clas-sification system are then used as the final predic-tion.
5.4 Hybrid Fusion
In our hybrid fusion approach, outputs from earlyfusion and individual unimodal predictors arecombined. Therefore, we train separate classifi-cation models for each modality. We then takethe predictions from each unimodal system andconcatenate it with the early fused feature vec-tors. These new feature vectors (early fusion +unimodal predictors) are then used to train a newmodel to make the ultimate prediction.
6 Results
6.1 Binary Classification Experiments
In order to evaluate our approach, we conduct aseries of participant-level binary classification ex-periments. We train both unimodal and multi-modal models. Our early + syntax-informed fu-sion model combines both the early fusion andsyntax-informed fusion feature sets, by early fu-sion, i.e. simple concatenation. Using scikit-learn4 we train a Support Vector Machine (SVM)for classification, (linear kernel, C = 0.1). We con-duct 5-fold cross-validation on 136 participant in-terviews (depressed = 26, non-depressed = 110).
4http://scikit-learn.org/
During cross-validation, each fold is speaker inde-pendent and drawn at random. Given the skew-ness of the dataset, we set the SVM model’s classweight parameter to ‘balanced’, which automati-cally adjusts the weights of the model inverselyproportional to the class frequencies in the data,helping adjust for the class imbalance. Given thepossibility of sparse feature values and the dif-ferences in dimensionality across feature sets, wealso perform feature selection. We use scikit-learn’s Select K-Best feature selection approach,which computes the ANOVA F-value across fea-tures and identifies the K most significant features.We set K to 20 and evaluate each feature set’s bestset. We report our findings in Table ??. We reportprecision, recall, and F1-score for the depressedclass. We choose to report these values instead ofthe average values across both classes because thedepressed class label is the harder class to detect.As a result, the non-depressed class usually reportsvery high scores which tend to inflate the averagescore. If we can increase the performance of thedepressed class, it can be assumed that the overallperformance will go up as a result.
We find that the novel syntax-informed fusionapproach performs best, with an F1-score of 0.49.We believe this approach is able to leverage syn-tactic information to target more informative as-pects of the speech signal resulting in higher per-forming models. By conditioning acoustic mod-els on syntactic information this approach com-
17
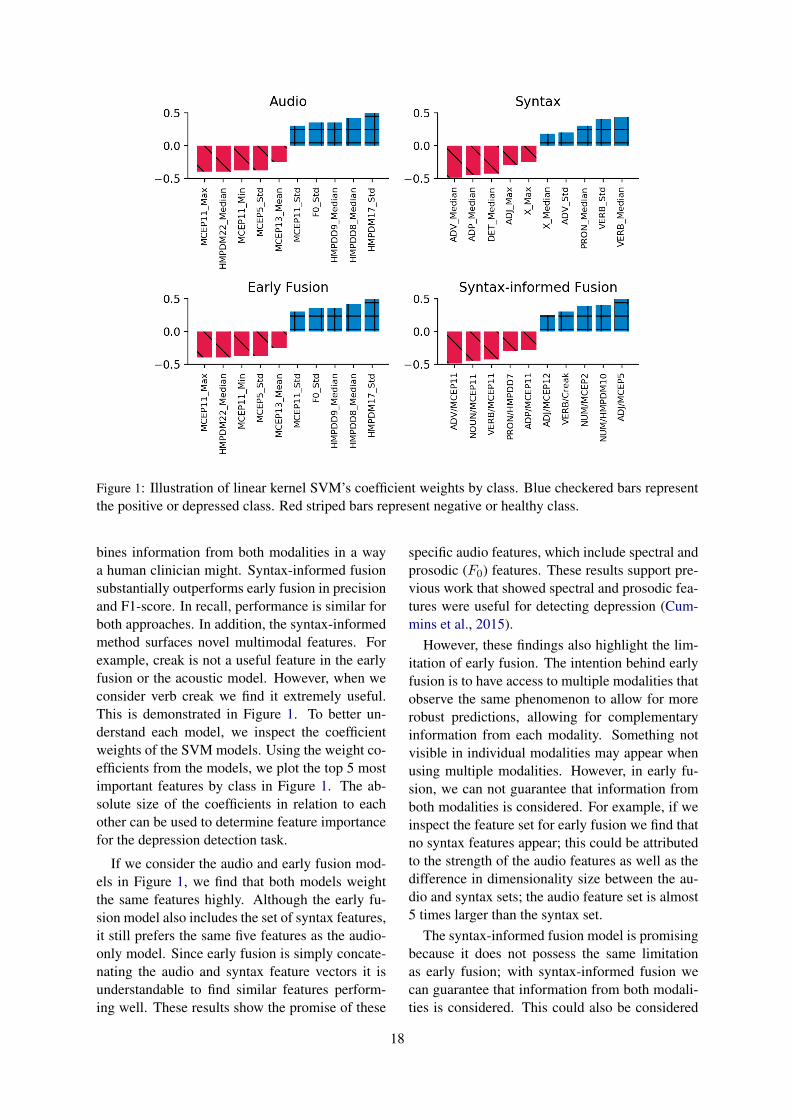
Figure 1: Illustration of linear kernel SVM’s coefficient weights by class. Blue checkered bars representthe positive or depressed class. Red striped bars represent negative or healthy class.
bines information from both modalities in a waya human clinician might. Syntax-informed fusionsubstantially outperforms early fusion in precisionand F1-score. In recall, performance is similar forboth approaches. In addition, the syntax-informedmethod surfaces novel multimodal features. Forexample, creak is not a useful feature in the earlyfusion or the acoustic model. However, when weconsider verb creak we find it extremely useful.This is demonstrated in Figure 1. To better un-derstand each model, we inspect the coefficientweights of the SVM models. Using the weight co-efficients from the models, we plot the top 5 mostimportant features by class in Figure 1. The ab-solute size of the coefficients in relation to eachother can be used to determine feature importancefor the depression detection task.
If we consider the audio and early fusion mod-els in Figure 1, we find that both models weightthe same features highly. Although the early fu-sion model also includes the set of syntax features,it still prefers the same five features as the audio-only model. Since early fusion is simply concate-nating the audio and syntax feature vectors it isunderstandable to find similar features perform-ing well. These results show the promise of these
specific audio features, which include spectral andprosodic (F0) features. These results support pre-vious work that showed spectral and prosodic fea-tures were useful for detecting depression (Cum-mins et al., 2015).
However, these findings also highlight the lim-itation of early fusion. The intention behind earlyfusion is to have access to multiple modalities thatobserve the same phenomenon to allow for morerobust predictions, allowing for complementaryinformation from each modality. Something notvisible in individual modalities may appear whenusing multiple modalities. However, in early fu-sion, we can not guarantee that information fromboth modalities is considered. For example, if weinspect the feature set for early fusion we find thatno syntax features appear; this could be attributedto the strength of the audio features as well as thedifference in dimensionality size between the au-dio and syntax sets; the audio feature set is almost5 times larger than the syntax set.
The syntax-informed fusion model is promisingbecause it does not possess the same limitationas early fusion; with syntax-informed fusion wecan guarantee that information from both modali-ties is considered. This could also be considered
18

Modality/Features Fusion Type Precision Recall F1-score
A + S Early 0.34 0.70 0.45
A + S Informed 0.40 0.69 0.49
A + S Late - ensemble 0.36 0.78 0.49
A + S Hybrid - informed 0.36 0.78 0.49
A + S Hybrid - early 0.34 0.74 0.46
A + V Early 0.37 0.70 0.48
A + V Informed 0.36 0.77 0.49
A + V Late - ensemble 0.36 0.78 0.49
A + V Hybrid - informed 0.36 0.78 0.49
A + V Hybrid - early 0.50 0.74 0.35
A + S + V Early 0.37 0.70 0.48
A + S + V Late - vote 0.50 0.17 0.25
A + S + V Late - ensemble 0.36 0.78 0.49
Table 2: Results for fusion experiments using SVM.Results for fusion approaches including fea-tures from audio (A), syntax (S), and video (V).
a drawback of syntax-informed fusion, in circum-stances where one would like to be agnostic re-garding the value of each modality. However, ina task for which multiple modalities are knownto be important and interconnected, such as de-pression detection, it is valuable to represent themjointly. The syntax-informed fusion model in Fig-ure 1 demonstrates that syntax-informed fusion isable to capture important information from bothmodalities. We find the best features used to dis-tinguish between classes are spectral features thatspan the production of pronouns, verbs, and ad-verbials. In other words, the best syntax-informedfeatures represent a fused multimodal representa-tion of the best features from each unimodal do-main.
We also find further support of the relationshipbetween depression and syntax. From the syntax-only model, we find pronouns (PRON) to be usefulin identifying the depressed class, which supportsprevious findings that pronoun use can help iden-tify depression (Rude et al., 2004). In addition, wefind the POS tag category X (other) to be usefulin distinguishing between classes. After manuallyinspecting the transcripts, we find the X POS tag isoften assigned to filler words such as uh, um, mm.
These results suggest filler words can be helpfulin identifying depression. Lastly, we find adver-bials (ADV) to be useful in distinguishing betweenclasses. These results are especially interesting be-cause Zinken et al. (2010) argued that adverbialclauses could help predict the improvement of de-pression symptoms. To the best of our knowledge,these results are the first to show support that ad-verbial clauses could also help predict depression.
We find similar results for video-informed fu-sion. Video-informed fusion outperforms earlyfusion in recall and F1-score. Similar to syntax-informed fusion we find that video-informed fusedfeatures are able to jointly capture the most in-formative features from each individual modality.For example, we find the best performing acous-tic features and AUs from the unimodal systemsto appear together in the video-informed system 5.
6.2 Fusion Experiments
In addition to evaluating how well our novel ap-proach compares to early fusion, we also evalu-ate other types of fusion such as late and hybridfusion. These series of experiments follow the
5Full charts of the the video-informed coefficient weightscan be viewed in Figure 2 of the Appendix
19

same configuration as our first series of experi-ments: 5 fold cross-validation using SVM (lin-ear kernel, C = 0.1, class weights balanced). Weevaluate each method of fusion —early, informed,late (vote/ensemble), and hybrid (early/informed)—and report our results in Table ??.
As mentioned previously, in regards to early fu-sion methods, the informed fusion approaches out-perform simple early fusion. When we comparethe syntax and video-informed fusion techniqueswith other approaches, such as late and hybrid fu-sion, we do not find differences between the sys-tems. When we evaluate systems that use all threemodalities (A + S + V), we find a late ensembleapproach performs best. We also find that late fu-sion techniques which rely on voting perform theworst. We believe these results can be attributedto the low performing unimodal video system, asdemonstrated in Table ??. This finding highlightsa weakness of the late fusion (voting) approach.Since it weighs the prediction from each systemequally, this can lead to poor performance whenone of the unimodal systems is weak.
7 Conclusion
In this work, we present a novel approach to earlyfusion: informed fusion. The syntax-informed fu-sion approach is able to leverage syntactic infor-mation to target more informative aspects of thespeech signal. We find that syntax-informed fu-sion approach outperforms early fusion. Givensome of the limitations to early fusion, we be-lieve syntax-informed fusion is a promising al-ternative dependent on the classification task. Inaddition, we evaluate this approach’s robustnessby evaluating the technique with other modali-ties. Specifically, we evaluate video-informed fu-sion and confirm our findings that informed fusionoutperforms early fusion. We also confirm pre-vious findings that spectral features and prosodicfeatures are useful in identifying depression. Inaddition, we present further support for the rela-tionship between syntax and depression. Specif-ically we find pronouns, adverbials, and fillers tobe useful in identifying individuals with depres-sion. Lastly, we perform an in-depth investigationof fusion techniques and find that informed, late,and hybrid approaches perform comparably. Tothe best of our knowledge, this work representsthe most comprehensive empirical study of fu-sion techniques for multimodal depression detec-
tion. However, this analysis is conducted on onedataset. Future work will consider extending thisstudy to include many of the publicly-available ex-isting datasets.
ReferencesSharifa Alghowinem, Roland Goecke, Jeffrey F Cohn,
Michael Wagner, Gordon Parker, and MichaelBreakspear. 2015. Cross-cultural detection of de-pression from nonverbal behaviour. In AutomaticFace and Gesture Recognition (FG), 2015 11thIEEE International Conference and Workshops on,volume 1, pages 1–8. IEEE.
Murray Alpert, Enrique R Pouget, and Raul R Silva.2001. Reflections of depression in acoustic mea-sures of the patients speech. Journal of AffectiveDisorders, 66(1):59–69.
Daniel Andor, Chris Alberti, David Weiss, AliakseiSeveryn, Alessandro Presta, Kuzman Ganchev, SlavPetrov, and Michael Collins. 2016. Globally nor-malized transition-based neural networks. arXivpreprint arXiv:1603.06042.
Tadas Baltrusaitis, Chaitanya Ahuja, and Louis-Philippe Morency. 2017. Multimodal machinelearning: A survey and taxonomy. CoRR,abs/1705.09406.
Gerhard Blanken, Jurgen Dittmann, Hannelore Grimm,John C Marshall, and Claus-W Wallesch. 1993. Lin-guistic disorders and pathologies: an internationalhandbook, volume 8. Walter de Gruyter.
Nicholas Cummins, Stefan Scherer, Jarek Krajewski,Sebastian Schnieder, Julien Epps, and Thomas FQuatieri. 2015. A review of depression and suiciderisk assessment using speech analysis. Speech Com-munication, 71:10–49.
Gilles Degottex, John Kane, Thomas Drugman, TuomoRaitio, and Stefan Scherer. 2014. Covarepa collabo-rative voice analysis repository for speech technolo-gies. In 2014 IEEE International Conference onAcoustics, Speech and Signal Processing (ICASSP),pages 960–964. IEEE.
Jyoti Joshi, Roland Goecke, Sharifa Alghowinem, Ab-hinav Dhall, Michael Wagner, Julien Epps, GordonParker, and Michael Breakspear. 2013. Multimodalassistive technologies for depression diagnosis andmonitoring. Journal on Multimodal User Interfaces,7(3):217–228.
Harry McGurk and John MacDonald. 1976. Hearinglips and seeing voices. 264:746–748.
Gideon Mendels, Sarah Ita Levitan, Kai-Zhan Lee,and Julia Hirschberg. 2017. Hybrid acoustic-lexicaldeep learning approach for deception detection.
20

Hongying Meng, Di Huang, Heng Wang, HongyuYang, Mohammed AI-Shuraifi, and Yunhong Wang.2013. Depression recognition based on dynamicfacial and vocal expression features using partialleast square regression. In Proceedings of the 3rdACM international workshop on Audio/visual emo-tion challenge, pages 21–30. ACM.
Michelle Renee Morales and Rivka Levitan. 2016.Speech vs. text: A comparative analysis of fea-tures for depression detection systems. In SpokenLanguage Technology Workshop (SLT), 2016 IEEE,pages 136–143. IEEE.
Michelle Renee Morales, Stefan Scherer, and RivkaLevitan. 2017a. A Cross-modal Review of Indica-tors for Depression Detection Systems. In Proceed-ings of the Fourth Workshop on Computational Lin-guistics and Clinical Psychology, pages 1–12, Van-couver, Canada. Association for Computational Lin-guistics.
Michelle Renee Morales, Stefan Scherer, and RivkaLevitan. 2017b. OpenMM: An Open-Source Mul-timodal Feature Extraction Tool. In Proceedingsof Interspeech 2017, pages 3354–3358, Stockholm,Sweden. ISCA.
Fabien Ringeval, Bjorn W. Schuller, Michel F. Val-star, Jonathan Gratch, Roddy Cowie, Stefan Scherer,Sharon Mozgai, Nicholas Cummins, MaximilianSchmi, and Maja Pantic. 2017. Avec 2017 real-lifedepression, and aect recognition workshop and chal-lenge.
Stephanie Rude, Eva-Maria Gortner, and James Pen-nebaker. 2004. Language use of depressed anddepression-vulnerable college students. Cognition& Emotion, 18(8):1121–1133.
Stefan Scherer, Giota Stratou, Jonathan Gratch, andLouis-Philippe Morency. 2013a. Investigating voicequality as a speaker-independent indicator of depres-sion and ptsd. In Interspeech, pages 847–851.
Stefan Scherer, Giota Stratou, Gale Lucas, MarwaMahmoud, Jill Boberg, Jonathan Gratch, Louis-Philippe Morency, et al. 2014. Automatic audiovi-sual behavior descriptors for psychological disorderanalysis. Image and Vision Computing, 32(10):648–658.
Stefan Scherer, Giota Stratou, and Louis-PhilippeMorency. 2013b. Audiovisual behavior descriptorsfor depression assessment. In Proceedings of the15th ACM on International conference on multi-modal interaction, pages 135–140. ACM.
H. H Stassen, S Kuny, and D Hell. 1998. The speechanalysis approach to determining onset of improve-ment under antidepressants. European Neuropsy-chopharmacology, 8(4):303–310.
Jorg Zinken, Katarzyna Zinken, J Clare Wilson, LisaButler, and Timothy Skinner. 2010. Analysis of syn-tax and word use to predict successful participation
in guided self-help for anxiety and depression. Psy-chiatry research, 179(2):181–186.
21

A Appendix
POS Tag Description
ADJ Adjectives
ADV Adverbs
ADP Adpositions
AUX Auxiliaries
CONJ Conjunctions
DET Determiners
INTJ Interjections
NOUN Nouns
NUM Cardinal numbers
PPRON Proper nouns
PRON Pronouns
PRT Particles or other functions words
PUNCT Punctuation
SCONJ Subordinating conjunctions
SYM Symbols
VERB Verbs
X Other
Table 3: Description of POS tags.
22

Action Unit Description
1 Inner brow raise
2 Outer brow raise
4 Brow lowerer
5 Upper lid raiser
6 Check raiser
7 Lid tightener
9 Nose wrinkler
10 Upper lip raiser
12 Lip corner puller
14 Dimpler
15 Lip corner depressor
17 Chin raiser
18 Lip puckerer
20 Lip strecher
23 Lip tightener
24 Lip pressor
25 Lips part
26 Jaw drop
28 Lip suck
43 Eyes closed
Table 4: Description of facial AUs.
23

Figure 2: Illustration of linear kernel SVM’s coefficient weights by class. Blue checkered bars representthe positive or depressed class. Red striped bars represent negative or healthy class.
24