a guided tour to computational haplotyping - · pdf filea guided tour to computational...
TRANSCRIPT

A Guided Tour to Computational Haplotyping
Tobias Marschall
June 15, 2017
Computability in Europe (CiE) @ Turku
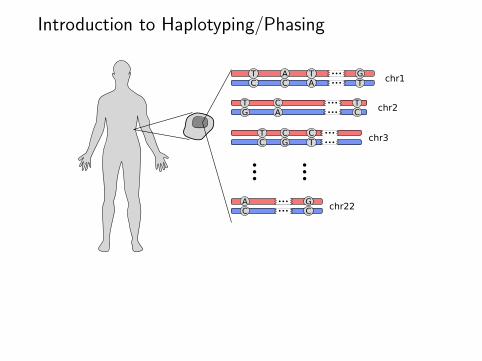
Introduction to Haplotyping/Phasing
chr1
chr2
chr3
chr22
GT
TA
AC
TC
TC
CA
TG
CT
CG
TC
GC
AC
Terminology: Phasing = Haplotyping

Introduction to Haplotyping/Phasing
C/T G/TA/C A/T chr1
G/T C/TA/C chr2
C/T C/G C/T
A/C C/G
chr3
chr22
Terminology: Phasing = Haplotyping

Introduction to Haplotyping/Phasing
chr1
chr2
chr3
chr22
GT
TA
AC
TC
TC
CA
TG
CT
CG
TC
GC
AC
Terminology: Phasing = Haplotyping

Relevance of Haplotyping
[Tewhey et al., Nature Reviews Genetics, 2011]

Relevance of Haplotyping
[Tewhey et al., Nature Reviews Genetics, 2011]

Haplotype-specific Clinical Conditions
[Tewhey et al., Nature Reviews Genetics, 2011]

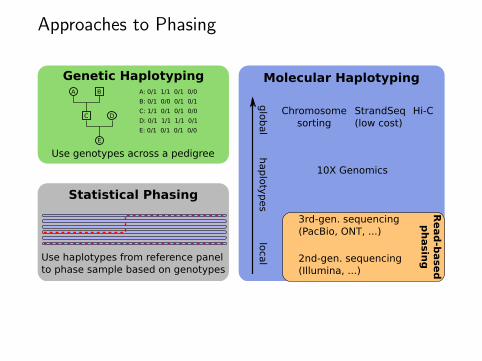
Approaches to Phasing
Genetic Haplotyping
Use genotypes across a pedigree
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0

Approaches to Phasing
Statistical Phasing
Use haplotypes from reference panelto phase sample based on genotypes
Genetic Haplotyping
Use genotypes across a pedigree
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
Approaches to Phasing
Statistical Phasing
Use haplotypes from reference panelto phase sample based on genotypes
Genetic Haplotyping
Use genotypes across a pedigree
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
Molecular Haplotyping
loca
lg
lob
al
hap
loty
pes
StrandSeq(low cost)
Chromosomesorting
2nd-gen. sequencing(Illumina, ...)
3rd-gen. sequencing(PacBio, ONT, ...)
Read
-based
ph
asin
g
10X Genomics
Hi-C

Approaches to Phasing
Statistical Phasing
Use haplotypes from reference panelto phase sample based on genotypes
Genetic Haplotyping
Use genotypes across a pedigree
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
Molecular Haplotyping
loca
lglo
bal
haplo
types
StrandSeq(low cost)
Chromosomesorting
2nd-gen. sequencing(Illumina, ...)
3rd-gen. sequencing(PacBio, ONT, ...)
Read
-based
ph
asin
g
10X Genomics
Hi-C

How to encode alleles/genotypes
TTTCATATCCATGGACACCTTCTGCT reference
T/T G/TA/C A/T genotypes
GT
TA
AC
TT haplotypes
Note
It can be convenient to write genotypes as sums: g ∈ {0, 1, 2}

How to encode alleles/genotypes
TTTCATATCCATGGACACCTTCTGCT reference
1/1 0/10/1 0/1 genotypes
01
10
10
11 haplotypes
Note
It can be convenient to write genotypes as sums: g ∈ {0, 1, 2}

How to encode alleles/genotypes
TTTCATATCCATGGACACCTTCTGCT reference
1/1 0/10/1 0/1 genotypes
01
10
10
11 haplotypes
Note
It can be convenient to write genotypes as sums: g ∈ {0, 1, 2}

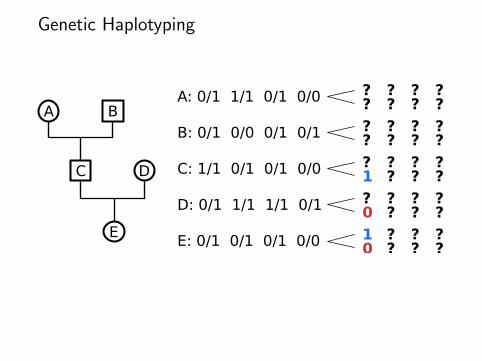
Genetic Haplotyping
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
??
??
??
??
??
??
??
??
??
??
??
??
??
??
??
??
??
??
??
??
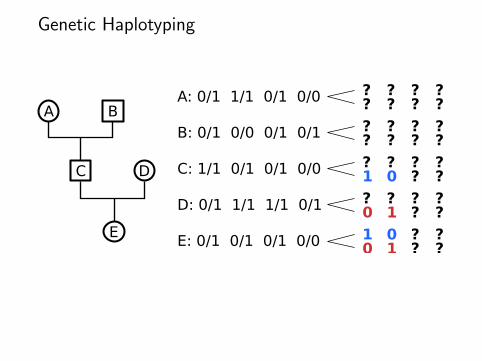
Genetic Haplotyping
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
??
??
?1
?0
10
??
??
??
??
??
??
??
??
??
??
??
??
??
??
??
Genetic Haplotyping
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
??
??
?1
?0
10
??
??
?0
?1
01
??
??
??
??
??
??
??
??
??
??

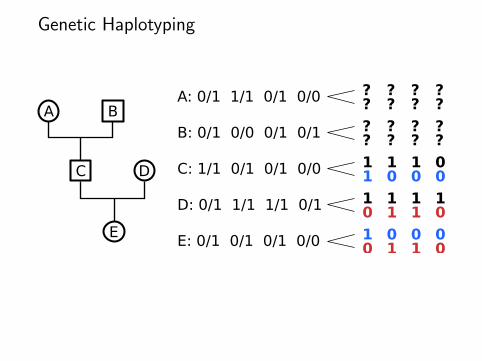
Genetic Haplotyping
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
??
??
?1
?0
10
??
??
?0
?1
01
??
??
?0
?1
01
??
??
??
??
??

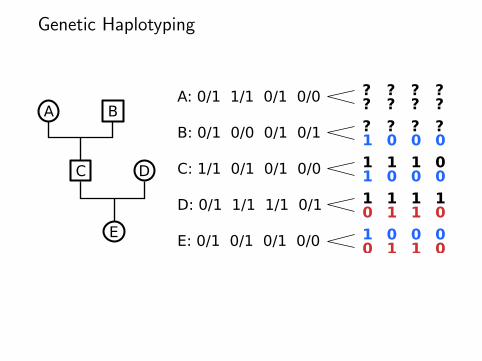
Genetic Haplotyping
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
??
??
?1
?0
10
??
??
?0
?1
01
??
??
?0
?1
01
??
??
?0
?0
00

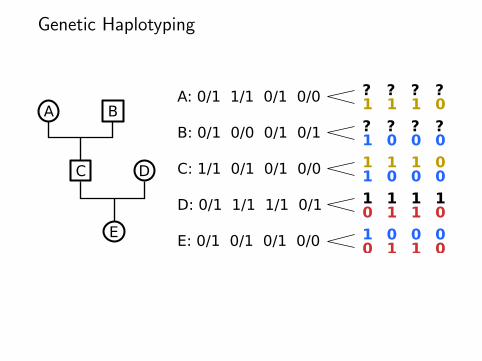
Genetic Haplotyping
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
??
??
?1
10
10
??
??
?0
11
01
??
??
?0
11
01
??
??
?0
10
00
Genetic Haplotyping
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
??
??
11
10
10
??
??
10
11
01
??
??
10
11
01
??
??
00
10
00
Genetic Haplotyping
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
??
?1
11
10
10
??
?0
10
11
01
??
?0
10
11
01
??
?0
00
10
00
Genetic Haplotyping
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
?1
?1
11
10
10
?1
?0
10
11
01
?1
?0
10
11
01
?0
?0
00
10
00

Genetic Haplotyping
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
01
01
11
10
10
11
00
10
11
01
01
10
10
11
01
00
10
00
10
00

Overview
Statistical Phasing
Use haplotypes from reference panelto phase sample based on genotypes
Genetic Haplotyping
Use genotypes across a pedigree
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
Molecular Haplotyping
loca
lglo
bal
haplo
types
StrandSeq(low cost)
Chromosomesorting
2nd-gen. sequencing(Illumina, ...)
3rd-gen. sequencing(PacBio, ONT, ...)
Read
-based
ph
asin
g
10X Genomics
Hi-C

Statistical Phasing (n+1 case)
Task: determine haplotype of additional individual
0 0 1 1 0 0 1 0 0 1 0 0 0 0 1 0 0 0 0 00 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 00 0 1 0 0 0 0 0 0 1 1 0 1 0 0 1 1 0 0 10 0 0 1 0 1 0 1 0 0 0 0 1 0 1 0 0 0 0 00 0 1 1 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 00 1 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 00 0 0 1 1 0 0 0 0 0 0 1 1 0 1 1 0 0 0 01 1 0 0 1 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0
1 2 0 0 1 0 1 0 0 0 0 0 1 1 1 2 1 0 0 1Genotypes of additional individual
Reference Haplotypes
(each genotype is written as the sum of alleles)
Rastas and Ukkonen (WABI, 2007)
This genotype parsing problem can be solved in O(r2 · n) for apanel with r rows and n columns.

Statistical Phasing (n+1 case)
Task: determine haplotype of additional individual
0 0 1 1 0 0 1 0 0 1 0 0 0 0 1 0 0 0 0 00 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 00 0 1 0 0 0 0 0 0 1 1 0 1 0 0 1 1 0 0 10 0 0 1 0 1 0 1 0 0 0 0 1 0 1 0 0 0 0 00 0 1 1 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 00 1 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 00 0 0 1 1 0 0 0 0 0 0 1 1 0 1 1 0 0 0 01 1 0 0 1 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0
1 2 0 0 1 0 1 0 0 0 0 0 1 1 1 2 1 0 0 1Genotypes of additional individual
Reference Haplotypes
(each genotype is written as the sum of alleles)
Rastas and Ukkonen (WABI, 2007)
This genotype parsing problem can be solved in O(r2 · n) for apanel with r rows and n columns.

Statistical Phasing (n+1 case)
Task: determine haplotype of additional individual
0 0 1 1 0 0 1 0 0 1 0 0 0 0 1 0 0 0 0 00 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 00 0 1 0 0 0 0 0 0 1 1 0 1 0 0 1 1 0 0 10 0 0 1 0 1 0 1 0 0 0 0 1 0 1 0 0 0 0 00 0 1 1 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 00 1 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 00 0 0 1 1 0 0 0 0 0 0 1 1 0 1 1 0 0 0 01 1 0 0 1 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0
1 2 0 0 1 0 1 0 0 0 0 0 1 1 1 2 1 0 0 1Genotypes of additional individual
Reference Haplotypes
(each genotype is written as the sum of alleles)
Rastas and Ukkonen (WABI, 2007)
This genotype parsing problem can be solved in O(r2 · n) for apanel with r rows and n columns.
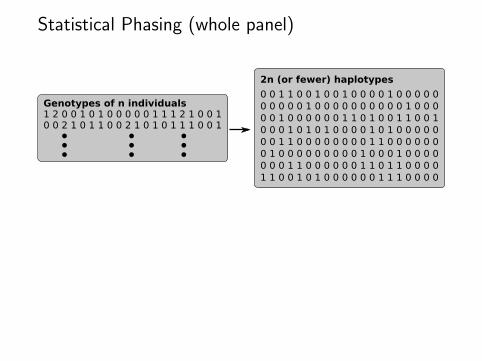
Statistical Phasing (whole panel)
0 0 1 1 0 0 1 0 0 1 0 0 0 0 1 0 0 0 0 00 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 00 0 1 0 0 0 0 0 0 1 1 0 1 0 0 1 1 0 0 10 0 0 1 0 1 0 1 0 0 0 0 1 0 1 0 0 0 0 00 0 1 1 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 00 1 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 00 0 0 1 1 0 0 0 0 0 0 1 1 0 1 1 0 0 0 01 1 0 0 1 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0
2n (or fewer) haplotypes
1 2 0 0 1 0 1 0 0 0 0 0 1 1 1 2 1 0 0 1Genotypes of n individuals
0 0 2 1 0 1 1 0 0 2 1 0 1 0 1 1 1 0 0 1
“We show here that the Pure-Parsimony approach is practical forgenotype data of up to 30 sites and 50 individuals (which is largeenough for practical use in many current haplotyping projects).”Dan Gusfield, CPM 2003.

Statistical Phasing (whole panel)
0 0 1 1 0 0 1 0 0 1 0 0 0 0 1 0 0 0 0 00 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 00 0 1 0 0 0 0 0 0 1 1 0 1 0 0 1 1 0 0 10 0 0 1 0 1 0 1 0 0 0 0 1 0 1 0 0 0 0 00 0 1 1 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 00 1 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 00 0 0 1 1 0 0 0 0 0 0 1 1 0 1 1 0 0 0 01 1 0 0 1 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0
2n (or fewer) haplotypes
1 2 0 0 1 0 1 0 0 0 0 0 1 1 1 2 1 0 0 1Genotypes of n individuals
0 0 2 1 0 1 1 0 0 2 1 0 1 0 1 1 1 0 0 1
“We show here that the Pure-Parsimony approach is practical forgenotype data of up to 30 sites and 50 individuals (which is largeenough for practical use in many current haplotyping projects).”Dan Gusfield, CPM 2003.

Challenge 1
Scale statistical phasing approaches to panels with millions ofrows and tens of millions of columns. Study the trade-off betweenspeed and accuracy of results.

Overview
Statistical Phasing
Use haplotypes from reference panelto phase sample based on genotypes
Genetic Haplotyping
Use genotypes across a pedigree
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
Molecular Haplotyping
loca
lg
lob
al
hap
loty
pes
StrandSeq(low cost)
Chromosomesorting
2nd-gen. sequencing(Illumina, ...)
3rd-gen. sequencing(PacBio, ONT, ...)
Read
-based
ph
asin
g
10X Genomics
Hi-C

Read-Based Phasing
G,A C,A G,T T,C C,A C,T G,A
G T A
A C G
A GC
C G C
T T A
T A C
C C T
A C A
Goal: Partition rows into two conflict-free sets

Read-Based Phasing
G,A C,A G,T T,C C,A C,T G,A
G T A
A C G
A GC
C G C
T T A
T A C
C C T
A C A
A C G C C T GG A T T A C A
Goal: Partition rows into two conflict-free sets

Read-Based Phasing
G,A C,A G,T T,C C,A C,T G,A
G T A
A C G
A GC
C G C
T T A
T A C
C C T
A C A
Goal: Partition rows into two conflict-free sets

Read-Based Phasing
0,1 0,1 0,1 0,1 0,1 0,1 0,1
0 0 1
1 0 0
1 00
0 0 1
1 0 1
0 1 0
1 0 1
1 0 1
Goal: Partition rows into two conflict-free sets

Read-Based Phasing
0,1 0,1 0,1 0,1 0,1 0,1 0,1
0 0 1
1 0 0
1 00
0 0 1
1 0 1
0 1 0
1 0 1
1 0 1
Goal: Partition rows into two conflict-free sets

Read-Based Phasing
0 0 1
1 0 0
1 00
0 0 1
1 0 1
0 1 0
1 0 1
1 0 1
- - - -
- - - -
- - - -
- - -
- -
-
-
-
- -
- - -
- - -
- - - -
SNP Matrix:
Goal: Partition rows into two conflict-free sets

Read-Based Phasing
0 0 1
1 0 0
1 01
0 0 1
1 0 1
0 0 0
1 0 1
1 0 1
- - - -
- - - -
- - - -
- - -
- -
-
-
-
- -
- - -
- - -
- - - -
SNP Matrix:
Goal: Partition rows into two conflict-free sets

Read-Based Phasing
0 0 1
1 0 0
1 01
0 0 1
1 0 1
0 0 0
1 0 1
1 0 1
- - - -
- - - -
- - - -
- - -
- -
-
-
-
- -
- - -
- - -
- - - -
SNP Matrix: Conflicts
Goal: Partition rows into two conflict-free sets

Possible Problem Formalizations
Issue
Sequencing and mapping errors → no conflict-free bipartition
Four problem variants
Given a SNP matrix, perform a minimum number of operationsuntil such a bipartition exists. Allowed operations can be:
1 Delete row
2 Delete column
3 Flip one entry (0↔ 1)
4 Turn entry into dash (0, 1→ −)
Bad news
All these four problem variants are NP-hard.

Possible Problem Formalizations
Issue
Sequencing and mapping errors → no conflict-free bipartition
Four problem variants
Given a SNP matrix, perform a minimum number of operationsuntil such a bipartition exists. Allowed operations can be:
1 Delete row
2 Delete column
3 Flip one entry (0↔ 1)
4 Turn entry into dash (0, 1→ −)
Bad news
All these four problem variants are NP-hard.

Possible Problem Formalizations
Issue
Sequencing and mapping errors → no conflict-free bipartition
Four problem variants
Given a SNP matrix, perform a minimum number of operationsuntil such a bipartition exists. Allowed operations can be:
1 Delete row
2 Delete column
3 Flip one entry (0↔ 1)
4 Turn entry into dash (0, 1→ −)
Bad news
All these four problem variants are NP-hard.
Bipartite Graphs
But: Computing the minimum number of vertices to be removedis NP-hard.

Bipartite Graphs
This graph is bipartite!
But: Computing the minimum number of vertices to be removedis NP-hard.

Bipartite Graphs
But: Computing the minimum number of vertices to be removedis NP-hard.

Bipartite Graphs
This graph is NOT bipartite!
But: Computing the minimum number of vertices to be removedis NP-hard.

Bipartite Graphs
After removing vertices, it is bipartite.
But: Computing the minimum number of vertices to be removedis NP-hard.

Deleting Rows and Bipartite Graphs
Given a SNP matrix, perform a minimum number ofoperations until the matrix permits a conflict-free bipartition.Allowed operations can be:
1 Delete row
2 Delete column
3 Flip one entry (0↔ 1)
4 Turn entry into dash (0, 1→ −)

Deleting Rows and Bipartite Graphs
0 0 1
1 0 0
1 01
0 0 1
1 0 1
0 0 0
1 0 1
1 0 1
- - - -
- - - -
- - - -
- - -
- -
-
-
-
- -
- - -
- - -
- - - -
SNP Matrix: Conflicts

Deleting Rows and Bipartite Graphs
0 0 1
1 0 0
1 01
0 0 1
1 0 1
0 0 0
1 0 1
1 0 1
- - - -
- - - -
- - - -
- - -
- -
-
-
-
- -
- - -
- - -
- - - -
SNP Matrix: Conflicts

Deleting Rows and Bipartite Graphs
0 0 1
1 0 0
0 0 1
1 0 1
1 0 1
1 0 1
- - - -
- - - -
- - -
- -
-
-
- -
- - -
- - - -
SNP Matrix: Conflicts

Which of the Formulations is Most Relevant?
Given a SNP matrix, perform a minimum number ofoperations until the matrix permits. Allowed operations can be:
1 Delete row
2 Delete column
3 Flip one entry (0↔ 1)
4 Turn entry into dash (0, 1→ −)
Problem 3 = Minimum Error Correction (MEC) problem
Problem 3 and 4 are equivalent
Problem 4 can also be expressed as graph bipartization

WhatsHap Algorithm (Sketch)
0
1
1
-
-
-
0
1
0
-
-
-
0
0
0
1
-
-
0
1
0
0
-
-
1
1
1
-
-
-
3 4 5 4 3
Fragment matrix:
Coverage:
Approach: FPT algorithm with “coverage” as parameter.
coverage: number of active rows in a column
can be bounded without loosing relevant information
Dynamic Programming
Proceed column-wise. For each column:
1 Enumerate all bipartitions of rows that cover that column
2 Compute number of bit-flips incurred by each bipartition
3 Project costs to “intersection column”

WhatsHap Algorithm (Sketch)
0
1
1
-
-
-
0
1
0
-
-
-
0
0
0
1
-
-
0
1
0
0
-
-
1
1
1
-
-
-
3 4 5 4 3
Fragment matrix:
Coverage:
Approach: FPT algorithm with “coverage” as parameter.
coverage: number of active rows in a column
can be bounded without loosing relevant information
Dynamic Programming
Proceed column-wise. For each column:
1 Enumerate all bipartitions of rows that cover that column
2 Compute number of bit-flips incurred by each bipartition
3 Project costs to “intersection column”

Adding Weights (wMEC)
0
1
1
-
-
-
0
1
0
-
-
-
0
0
0
1
-
-
0
1
0
0
-
-
1
1
1
-
-
-
MEC Problem
Flip a minimum number ofbits such that a conflict-freebipartition of rows exists.
Weights set to −10 · log10(pwrong), where pwrong is theprobability that that position has been wrongly sequenced
Minimizing weights = finding maximum likelihood solution

Adding Weights (wMEC)
0
1
1
-
-
-
32
15
7
0
1
0
-
-
-
25
3
12
0
0
0
1
-
-
13
15
23
0
1
0
0
-
-
34
29
17
20
1
1
1
-
-
-
17
31
19
10
wMEC Problem
Flip a minimum-cost set ofbits such that a conflict-freebipartition of rows exists.
Weights set to −10 · log10(pwrong), where pwrong is theprobability that that position has been wrongly sequenced
Minimizing weights = finding maximum likelihood solution

Adding Weights (wMEC)
0
1
1
-
-
-
32
15
7
0
1
0
-
-
-
25
3
12
0
0
0
1
-
-
13
15
23
0
1
0
0
-
-
34
29
17
20
1
1
1
-
-
-
17
31
19
10
wMEC Problem
Flip a minimum-cost set ofbits such that a conflict-freebipartition of rows exists.
Weights set to −10 · log10(pwrong), where pwrong is theprobability that that position has been wrongly sequenced
Minimizing weights = finding maximum likelihood solution

Fixed-parameter tractable (FPT) algorithms
Notation
n: number of columns, i.e. number of variants to be phased
m: number of rows, i.e. number of reads
L: maximum read length, i.e. maximum number of variantscovered by any read
c: maximum coverage, i.e. maximum number of activereads per column
k: maximum number of errors per column
He et al. (2010): O(2Lmn)
Patterson et al. (2014): O(2c · n)
HapCol (Pirola et al., 2015): O(ckLn)

Haplotype distance measures
true haplotype: 0 0 1 1 1 1 1 0 0
predicted: 0 0 1 1 1 0 0 1 1
Hamming distance: 4 (rate: 4/9)
Other measures
Switch/flip decomposition
Decompose into short/long switches
N50/N95/N99 of error-free blocks
etc.

Haplotype distance measures
true haplotype: 0 0 1 1 1 1 1 0 0switch space: 0 1 0 0 0 0 1 0
predicted: 0 0 1 1 1 0 0 1 1switch space: 0 1 0 0 1 0 1 0
Hamming distance: 4 (rate: 4/9)Switch distance: 1 (rate: 1/8)
Other measures
Switch/flip decomposition
Decompose into short/long switches
N50/N95/N99 of error-free blocks
etc.

Haplotype distance measures
true haplotype: 0 0 1 1 1 1 1 0 0switch space: 0 1 0 0 0 0 1 0
predicted: 0 0 1 1 1 0 0 1 1switch space: 0 1 0 0 1 0 1 0
Hamming distance: 4 (rate: 4/9)Switch distance: 1 (rate: 1/8)
Other measures
Switch/flip decomposition
Decompose into short/long switches
N50/N95/N99 of error-free blocks
etc.

Phasing Error RateS
witc
h er
ror
rate
2 3 4 5 10 15 60Coverage
Real data
hapCUTGATK/ReadBackedPhasingphASERWhatsHap
0.01%
0.1%
1%
10%
Genome in a Bottle (GIAB) data from PacBio for chromosome 1compared to statistical phasing using 1000 Genomes phase 3reference panel

Phasing Error RateS
witc
h er
ror
rate
2 3 4 5 10 15 60Coverage
0.01%
0.1%
1%
10%
Simulated data
2 3 4 5 10 15 60Coverage
Real data
hapCUTGATK/ReadBackedPhasingphASERWhatsHap
0.01%
0.1%
1%
10%
Genome in a Bottle (GIAB) data from PacBio for chromosome 1compared to statistical phasing using 1000 Genomes phase 3reference panel

Overview
Statistical Phasing
Use haplotypes from reference panelto phase sample based on genotypes
Genetic Haplotyping
Use genotypes across a pedigree
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
Molecular Haplotyping
loca
lg
lob
al
hap
loty
pes
StrandSeq(low cost)
Chromosomesorting
2nd-gen. sequencing(Illumina, ...)
3rd-gen. sequencing(PacBio, ONT, ...)
Read
-based
ph
asin
g
10X Genomics
Hi-C

Overview
Statistical Phasing
Use haplotypes from reference panelto phase sample based on genotypes
Genetic Haplotyping
Use genotypes across a pedigree
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
Molecular Haplotyping
loca
lg
lob
al
hap
loty
pes
StrandSeq(low cost)
Chromosomesorting
2nd-gen. sequencing(Illumina, ...)
3rd-gen. sequencing(PacBio, ONT, ...)
Read
-based
ph
asin
g
10X Genomics
Hi-C

Technology overview
Cloud 1
2*100bp/pair~40%
1 0 0 1 - - - - - - - - - - - - - - - -- - 1 0 0 0 0 - - - - - - - - - - - - -
Read 1Read 2
PacB
io 23 15 7 25
25 17 12 32 17
1 0 - - - - - - - - - - - - - - - - - -- - 1 - - - - - - - - - - - - - - - - -
Read 1Read 2
Illum
ina
23 15
25
Str
Seq 1 - - - - - - 0 - 0 - - 0 - - - - 0 - 00 - - - - 0 - - - 1 - - - - - - - 1 - -
23 15
25
2317
1315
25 17
15 25
Cell 1Cell 2
10
X 25 12 32 17
37 13 18Cloud 2
1 - - 1 - - - - - - - - - - - - - - - -- - 1 - - - - - - 1 1 - - - - - - - - -
Pair 1Pair 2Hi-
C 23 25
25 12 11
1 - - 1 - - - - - - - - - - - - - - - -- - - 0 - - 0 - - - - - - - - - - - - -
Pair 1Pair 2
mate
pair
s
33 25
2122
Span[bp]
Density
~500bp
~3kbp
~100kbp 10%
~10kbp 100%
fullchromosome
2%
largevariance
2*100bp/pair
2*100bp/pair~6.6%
1 - 0 - - 1 1 - - - - - - - - - - - - -- - - - - - - 1 1 - - - 1 - - - - - - -
In human: ~1 heterzygous variant / 1000bp

Haplotype blocks from individual technologies
0.06% 30204
1927
199
1
1.25%
4.66%
57.6%
Illumina
PacBio
10X Genomics
Strand-seq(134 cells)
SNVs
in la
rges
t
segm
ent
No. o
f seg
men
ts
0 20 40 60 100 102 104
NA12878 Chromosome 1
swit
ch e
rror
rate
[%
]
0.3%
0.2%
0.1%
0%
PacB
io
10X G
enom
ics
Illum
ina
Stra
nd-seq
0.13% 0.025% 0.3% 0.32%
Ground truth: phasing basedon platinum genomespedigree (17 family members)

Haplotype blocks from individual technologies
0.06% 30204
1927
199
1
1.25%
4.66%
57.6%
Illumina
PacBio
10X Genomics
Strand-seq(134 cells)
SNVs
in la
rges
t
segm
ent
No. o
f seg
men
ts
0 20 40 60 100 102 104
NA12878 Chromosome 1
swit
ch e
rror
rate
[%
]
0.3%
0.2%
0.1%
0%
PacB
io
10X G
enom
ics
Illum
ina
Stra
nd-seq
0.13% 0.025% 0.3% 0.32%
Ground truth: phasing basedon platinum genomespedigree (17 family members)

Combining Data Sources
Cloud 1
2*100bp/pair~40%
1 0 0 1 - - - - - - - - - - - - - - - -- - 1 0 0 0 0 - - - - - - - - - - - - -
Read 1Read 2
PacB
io 23 15 7 25
25 17 12 32 17
1 0 - - - - - - - - - - - - - - - - - -- - 1 - - - - - - - - - - - - - - - - -
Read 1Read 2
Illum
ina
23 15
25
Str
Seq 1 - - - - - - 0 - 0 - - 0 - - - - 0 - 00 - - - - 0 - - - 1 - - - - - - - 1 - -
23 15
25
2317
1315
25 17
15 25
Cell 1Cell 2
10
X 25 12 32 17
37 13 18Cloud 2
1 - - 1 - - - - - - - - - - - - - - - -- - 1 - - - - - - 1 1 - - - - - - - - -
Pair 1Pair 2Hi-
C 23 25
25 12 11
1 - - 1 - - - - - - - - - - - - - - - -- - - 0 - - 0 - - - - - - - - - - - - -
Pair 1Pair 2
mate
pair
s
33 25
2122
Span[bp]
Density
~500bp
~3kbp
~100kbp 10%
~10kbp 100%
fullchromosome
2%
largevariance
2*100bp/pair
2*100bp/pair~6.6%
1 - 0 - - 1 1 - - - - - - - - - - - - -- - - - - - - 1 1 - - - 1 - - - - - - -
In human: ~1 heterzygous variant / 1000bp

Combining Data Sources
Cloud 1
2*100bp/pair~40%
1 0 0 1 - - - - - - - - - - - - - - - -- - 1 0 0 0 0 - - - - - - - - - - - - -
Read 1Read 2
PacB
io 23 15 7 25
25 17 12 32 17
1 0 - - - - - - - - - - - - - - - - - -- - 1 - - - - - - - - - - - - - - - - -
Read 1Read 2
Illum
ina
23 15
25
Str
Seq 1 - - - - - - 0 - 0 - - 0 - - - - 0 - 00 - - - - 0 - - - 1 - - - - - - - 1 - -
23 15
25
2317
1315
25 17
15 25
Cell 1Cell 2
10
X 25 12 32 17
37 13 18Cloud 2
1 - - 1 - - - - - - - - - - - - - - - -- - 1 - - - - - - 1 1 - - - - - - - - -
Pair 1Pair 2Hi-
C 23 25
25 12 11
1 - - 1 - - - - - - - - - - - - - - - -- - - 0 - - 0 - - - - - - - - - - - - -
Pair 1Pair 2
mate
pair
s
33 25
2122
Span[bp]
Density
~500bp
~3kbp
~100kbp 10%
~10kbp 100%
fullchromosome
2%
largevariance
2*100bp/pair
2*100bp/pair~6.6%
1 - 0 - - 1 1 - - - - - - - - - - - - -- - - - - - - 1 1 - - - 1 - - - - - - -
In human: ~1 heterzygous variant / 1000bp

Integrating Strand-seq and PacBio data
Varia
nt 1
Varia
nt 2
Varia
nt n
1 - - - - - - 0 - 0 - - 0 - - - - 0 - 00 - - - - 0 - - - 1 - - - - - - - 1 - -- 1 - - - 0 - - - - - 0 1 - - - - - 0 -- - 0 - - - 1 - 0 - 1 - - - - 1 - - - 0- 0 - - - - - 0 - - 1 - - - 1 - - - 1 -0 - - - 0 - - - - - - - - 0 - 1 - - - -
23 15
25
2317
15
25 17
15 25
Cell 1 (W)Cell 1 (C)Cell 2 (W)Cell 2 (C)Cell 3 (W)Cell 3 (C)
21 30 2 25 29
131425233111
43
19 24 19 5
15282631
1 0 0 1 - - - - - - - - - - - - - - - -- 0 0 1 1 - - - - - - - - - - - - - - -- 1 1 1 0 - - - - - - - - - - - - - - -- - 1 0 0 0 0 - - - - - - - - - - - - -
Read 1Read 2
PacB
io 23 15 7 25
25 17 12 32
Str
an
d-s
eq
37 18 23 31 22
14 25 4 31Read 3Read 4
[Porubsky∗, Garg∗, Sanders∗, ..., Marschall, in revision]

Integrating Strand-seq and PacBio data
Varia
nt 1
Varia
nt 2
Varia
nt n
1 0 0 - - - 1 0 0 0 1 - 0 - 1 1 - 0 1 00 1 - - 0 0 - - - 1 - 0 1 0 - 1 - 1 0 -
23 15
25
1725 17
15 25
Hap 1Hap 2 21 30 2 25 29
25142523311143
24 19 5
1528
1 0 0 1 - - - - - - - - - - - - - - - -- 0 0 1 1 - - - - - - - - - - - - - - -- 1 1 1 0 - - - - - - - - - - - - - - -- - 1 0 0 0 0 - - - - - - - - - - - - -
Read 1Read 2
PacB
io 23 15 7 25
25 17 12 32
Str
an
d-s
eq
conse
nsu
s
37 18 23 31 22
14 25 4 31Read 3Read 4
[Porubsky∗, Garg∗, Sanders∗, ..., Marschall, in revision]

Haplotype blocks: Strand-seq + PacBio (10-fold)
0
25
50
75
10
0
0
5
10
20
40
60
80
100
120
134
Strand-seqcells
SNVs in largest block
0
25
50
75
10
0
0
5
10
20
40
60
80
100
120
134
[Porubsky∗, Garg∗, Sanders∗, ..., Marschall, in revision]

Hamming error rates
Depth of coverage
Ham
min
g e
rror
rate
Strand-seqcells
51020406080100120134
2 3 4 5 10 15 25 30 all
2%
3%
4%
Ground truth: Illumina Platinum genomes, genetic phasing from17-member pedigree
[Porubsky∗, Garg∗, Sanders∗, ..., Marschall, in revision]

Challenge 2
Solve sparse MEC instances optimally. In particular thoseresulting from combinations of technologies.

Overview
Statistical Phasing
Use haplotypes from reference panelto phase sample based on genotypes
Genetic Haplotyping
Use genotypes across a pedigree
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
Molecular Haplotyping
loca
lglo
bal
haplo
types
StrandSeq(low cost)
Chromosomesorting
2nd-gen. sequencing(Illumina, ...)
3rd-gen. sequencing(PacBio, ONT, ...)
Read
-based
ph
asin
g
10X Genomics
Hi-C

Overview
Statistical Phasing
Use haplotypes from reference panelto phase sample based on genotypes
Genetic Haplotyping
Use genotypes across a pedigree
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
Molecular Haplotyping
loca
lglo
bal
haplo
types
StrandSeq(low cost)
Chromosomesorting
2nd-gen. sequencing(Illumina, ...)
3rd-gen. sequencing(PacBio, ONT, ...)
Read
-based
ph
asin
g
10X Genomics
Hi-C
Supported by mostpackages for statistical phasing(SHAPEIT, beagle, etc.)
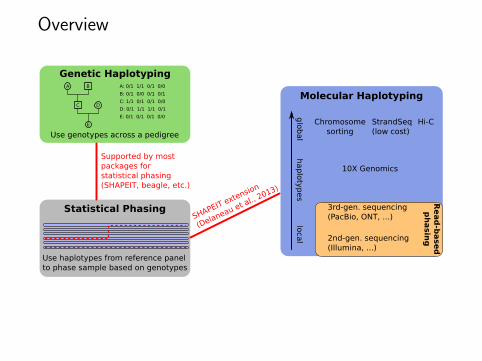
Overview
Statistical Phasing
Use haplotypes from reference panelto phase sample based on genotypes
Genetic Haplotyping
Use genotypes across a pedigree
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
Molecular Haplotyping
loca
lglo
bal
haplo
types
StrandSeq(low cost)
Chromosomesorting
2nd-gen. sequencing(Illumina, ...)
3rd-gen. sequencing(PacBio, ONT, ...)
Read
-based
ph
asin
g
10X Genomics
Hi-C
SHAPEIT extension
(Delaneau et al., 2013)
Supported by mostpackages for statistical phasing(SHAPEIT, beagle, etc.)

Overview
Statistical Phasing
Use haplotypes from reference panelto phase sample based on genotypes
Genetic Haplotyping
Use genotypes across a pedigree
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
Molecular Haplotyping
loca
lglo
bal
haplo
types
StrandSeq(low cost)
Chromosomesorting
2nd-gen. sequencing(Illumina, ...)
3rd-gen. sequencing(PacBio, ONT, ...)
Read
-based
ph
asin
g
10X Genomics
Hi-C
SHAPEIT extension
(Delaneau et al., 2013)
Supported by mostpackages for statistical phasing(SHAPEIT, beagle, etc.)
Garg, Martin, Marschall
(ISMB 2016)
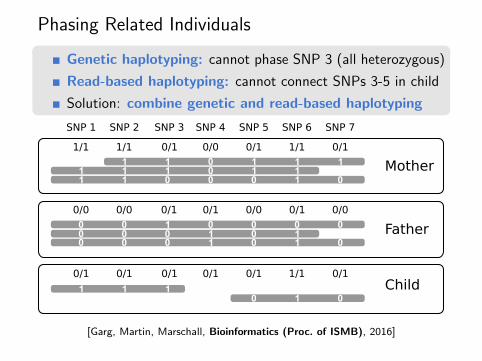
Phasing Related Individuals
Genetic haplotyping: cannot phase SNP 3 (all heterozygous)
Read-based haplotyping: cannot connect SNPs 3-5 in child
Solution: combine genetic and read-based haplotyping
Child
SNP 1 SNP 2 SNP 3 SNP 4 SNP 5 SNP 6 SNP 7
1/1 1/1 1/10/1 0/1 0/10/0
Mother
0/0 0/0 0/00/0 0/10/10/1
0/1 0/1 0/1 0/1 0/1 0/11/1
Father
[Garg, Martin, Marschall, Bioinformatics (Proc. of ISMB), 2016]
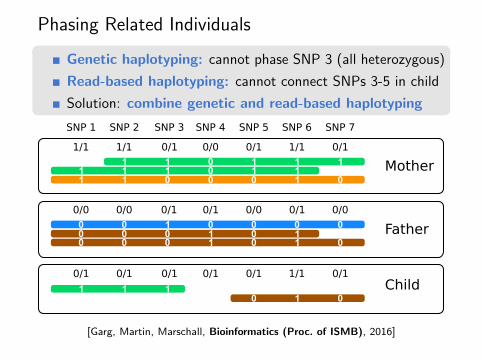
Phasing Related Individuals
Genetic haplotyping: cannot phase SNP 3 (all heterozygous)
Read-based haplotyping: cannot connect SNPs 3-5 in child
Solution: combine genetic and read-based haplotyping
Child
SNP 1 SNP 2 SNP 3 SNP 4 SNP 5 SNP 6 SNP 7
1/1 1/1 1/10/1 0/1 0/10/0
Mother
0/0 0/0 0/00/0 0/10/10/1
0/1 0/1 0/1 0/1 0/1 0/11/1
Father
[Garg, Martin, Marschall, Bioinformatics (Proc. of ISMB), 2016]

Phasing Related Individuals
Genetic haplotyping: cannot phase SNP 3 (all heterozygous)
Read-based haplotyping: cannot connect SNPs 3-5 in child
Solution: combine genetic and read-based haplotyping
Child
SNP 1 SNP 2 SNP 3 SNP 4 SNP 5 SNP 6 SNP 7
1/1 1/1 1/10/1 0/1 0/10/0
Mother
0/0 0/0 0/00/0 0/10/10/1
0/1 0/1 0/1 0/1 0/1 0/11/1
Father
[Garg, Martin, Marschall, Bioinformatics (Proc. of ISMB), 2016]

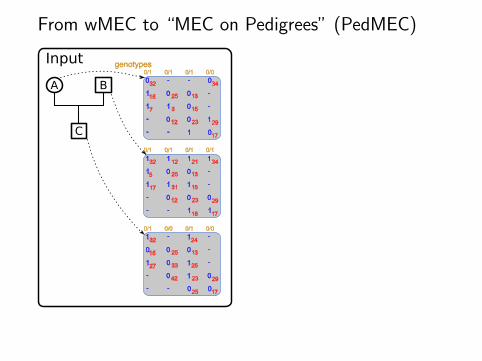
From wMEC to “MEC on Pedigrees” (PedMEC)
1
0
1
-
-
32
15
27
0
0
0
-
-
25
33
42
0
1
1
0
-
13
25
23 0
0
-
-
124
29
17
1
1
1
-
-
32
5
17
0
1
0
-
25
31
12
0
1
0
1
13
15
23 0
1
-
-
34
29
17
0
1
1
-
-
32
15
7
0
1
0
-
-
25
3
12
0
0
0
1
-
13
15
23
0
1
0
-
-
34
29
17
A B
C
1 1 12112
18
Input
25
From wMEC to “MEC on Pedigrees” (PedMEC)
1
0
1
-
-
32
15
27
0
0
0
-
-
25
33
42
0
1
1
0
-
13
25
23 0
0
-
-
124
29
17
1
1
1
-
-
32
5
17
0
1
0
-
25
31
12
0
1
0
1
13
15
23 0
1
-
-
34
29
17
0
1
1
-
-
32
15
7
0
1
0
-
-
25
3
12
0
0
0
1
-
13
15
23
0
1
0
-
-
34
29
17
A B
C
1 1 12112
18
Input0/1 0/1 0/1 0/0
genotypes
0/1 0/1 0/1 0/1
0/1 0/0 0/1 0/0
25

From wMEC to “MEC on Pedigrees” (PedMEC)
1
0
1
-
-
32
15
27
0
0
0
-
-
25
33
42
0
1
1
0
-
13
25
23 0
0
-
-
124
29
17
1
1
1
-
-
32
5
17
0
1
0
-
25
31
12
0
1
0
1
13
15
23 0
1
-
-
34
29
17
0
1
1
-
-
32
15
7
0
1
0
-
-
25
3
12
0
0
0
1
-
13
15
23
0
1
0
-
-
34
29
17
A B
C
1 1 12112
18
91 22 87recombination costInput
0/1 0/1 0/1 0/0genotypes
0/1 0/1 0/1 0/1
0/1 0/0 0/1 0/0
25
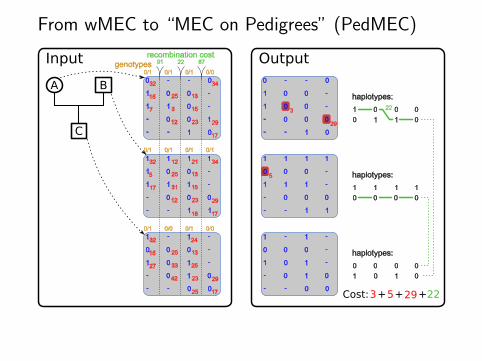
From wMEC to “MEC on Pedigrees” (PedMEC)
1
0
1
-
-
32
15
27
0
0
0
-
-
25
33
42
0
1
1
0
-
13
25
23 0
0
-
-
124
29
17
1
1
1
-
-
32
5
17
0
1
0
-
25
31
12
0
1
0
1
13
15
23 0
1
-
-
34
29
17
0
1
1
-
-
32
15
7
0
1
0
-
-
25
3
12
0
0
0
1
-
13
15
23
0
1
0
-
-
34
29
17
A B
C
1 1 12112
18
91 22 87recombination costInput
1
0
1
-
-
0
0
0
-
-
0
1
1
0
-
0
0
-
-
1
1
1
-
-
0
1
0
-
0
1
0
1
0
1
-
-
0
1
1
-
-
0
0
0
-
-
0
0
0
1
- 0
0
0
-
-
1 1 1
0
1 0 0 0
0 1 1 0
haplotypes:
1 1 1 1
0 0 0 0
haplotypes:
0 0 0 0
1 0 1 0
haplotypes:
Output
3
5
22
Cost:3+5+ 22
0/1 0/1 0/1 0/0genotypes
0/1 0/1 0/1 0/1
0/1 0/0 0/1 0/0
25
29
29+

Solving PedMEC
Ideas
Use similar approach as for wMEC
Add additional dimension to DP table: transmission statusi.e. which haplotype in each parent was transmitted to child
Runtime
Two extra bits for each mother-father-child relationship:
O(22t+c ·M) (hiding some ugly terms)
where c is the maximum of sum of coverages across individualsand t is the number mother-father-child relationship.
Still feasible for, e.g., t = 1 and c = 3 · 5. Linear in the number ofvariants. Independent of read length.

Solving PedMEC
Ideas
Use similar approach as for wMEC
Add additional dimension to DP table: transmission statusi.e. which haplotype in each parent was transmitted to child
Runtime
Two extra bits for each mother-father-child relationship:
O(22t+c ·M) (hiding some ugly terms)
where c is the maximum of sum of coverages across individualsand t is the number mother-father-child relationship.
Still feasible for, e.g., t = 1 and c = 3 · 5. Linear in the number ofvariants. Independent of read length.

Solving PedMEC
Ideas
Use similar approach as for wMEC
Add additional dimension to DP table: transmission statusi.e. which haplotype in each parent was transmitted to child
Runtime
Two extra bits for each mother-father-child relationship:
O(22t+c ·M) (hiding some ugly terms)
where c is the maximum of sum of coverages across individualsand t is the number mother-father-child relationship.
Still feasible for, e.g., t = 1 and c = 3 · 5. Linear in the number ofvariants. Independent of read length.

Phasing Related Individuals (Performance)
single individual2x
3x
5x
10x15x
0 0.5 1.0 1.5 2.0
0
5
10
15
20
unph
ase
d h
ete
rozy
gous
SN
Ps
[%]
phasing error rate [%]
(simulated PacBio data)
[Garg, Martin, Marschall, Bioinformatics (Proc. of ISMB), 2016]

Phasing Related Individuals (Performance)
single individualpedigree
2x
3x
5x
10x15x
2x3x
5x
0 0.5 1.0 1.5 2.0
0
5
10
15
20
unph
ase
d h
ete
rozy
gous
SN
Ps
[%]
phasing error rate [%]
(simulated PacBio data)
[Garg, Martin, Marschall, Bioinformatics (Proc. of ISMB), 2016]

Challenge 3: Solving PedMEC
High coverage: Solve the PedMEC problem for cases wheretime linear in 2c is infeasible.
Large pedigrees: Solve the PedMEC problem for cases wheretime linear in 22t is infeasible.

Challenge 4: Unify all three paradigms
Statistical Phasing
Use haplotypes from reference panelto phase sample based on genotypes
Genetic Haplotyping
Use genotypes across a pedigree
A B
C D
E
A: 0/1 1/1 0/1 0/0
B: 0/1 0/0 0/1 0/1
C: 1/1 0/1 0/1 0/0
D: 0/1 1/1 1/1 0/1
E: 0/1 0/1 0/1 0/0
Molecular Haplotyping
loca
lglo
bal
haplo
types
StrandSeq(low cost)
Chromosomesorting
2nd-gen. sequencing(Illumina, ...)
3rd-gen. sequencing(PacBio, ONT, ...)
Read
-based
ph
asin
g
10X Genomics
Hi-C
CHALLENGE:Unify all
three paradigms

Summary
Intro to genetic, read-based, and population-based haplotyping
Chromosome-length haplotyping feasible for singleindividuals
PedMEC unifies read-based and pedigree-based haplotyping
Four challenges:
1 Scale statistical phasing approaches to panels with millions ofrows and tens of millions of columns
2 Solve sparse MEC instances3 Solve PedMEC for high coverages and large pedigrees4 Integrate genetic, read-based, and population-based
haplotyping