a general-purpose machine learning method for tokenization...
TRANSCRIPT

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
A General-Purpose Machine Learning Method forTokenization and Sentence Boundary Detection
Valerio Basile Johan Bos Kilian Evang
University of Groningen{v.basile,johan.bos,k.evang}@rug.nl
Computational Linguistics in the Netherlands 2013
http://gmb.let.rug.nl 1/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Tokenization: a solved problem?
I Problem: tokenizers are often rule-based: hard to maintain,hard to adapt to new domains, new languages
I Problem: word segmentation and sentence segmentation oftenseen as separate tasks, but they inform each other
I Problem: most tokenization methods provide no alignmentbetween raw and tokenized text (Dridan and Oepen, 2012)
http://gmb.let.rug.nl 2/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Research Questions
I Can we use machine learning to avoid hand-crafting rules?
I Can we use the same method across domains and languages?
I Can we combine word and sentence boundary detection intoone task?
http://gmb.let.rug.nl 3/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Method: IOB Tagging
I widely used in sequence labeling tasks such as shallow parsing,named-entity recognition
I we propose to use it for word and sentence boundary detection
I label each character in a text with one of four tags:
. I: inside a token
. O: outside a token
. B: two types
I T: beginning of a tokenI S: beginning of the first token of a sentence
http://gmb.let.rug.nl 4/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
IOB Tagging: Example
It didn’t matter if the faces were male,
SIOTIITIIOTIIIIIOTIOTIIOTIIIIOTIIIOTIIITO
female or those of children. Eighty-
TIIIIIOTIOTIIIIOTIOTIIIIIIITOSIIIIIIO
three percent of people in the 30-to-34
IIIIIOTIIIIIIOTIOTIIIIIOTIOTIIOTIIIIIIIO
year old age range gave correct responses.
TIIIOTIIOTIIOTIIIIOTIIIOTIIIIIIOTIIIIIIIIT
I Note: discontinuous tokens are possible (Eighty-three)
http://gmb.let.rug.nl 5/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Acquiring Labeled Data: correcting a Rule-Based Tokenizer
http://gmb.let.rug.nl 6/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Method: Training a Classifier
I We use Conditional Random Fields (CRF)
I State of the art in sequence labeling tasks
I Implementation: Wapiti (http://wapiti.limsi.fr)
http://gmb.let.rug.nl 7/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Features Used for Learning
I current Unicode character
I label on previous character
I different kinds of contexts:
. either Unicode characters in the context
. or Unicode categories of these characters
I Unicode categories less in number (31), but also lessinformative than characters
I context windows sizes: 0, 1, 2, 3, 4 to the right and left ofcurrent character
http://gmb.let.rug.nl 8/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Experiments
I Three datasets (different languages, different domains):
. Newswire English
. Newswire Dutch
. Biomedical English
http://gmb.let.rug.nl 9/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Creating the Datasets
I (Newswire) English: Groningen Meaning Bank (manuallychecked part)
. 458 documents, 2,886 sentences, 64,443 tokens
. already exists in IOB format
I Newswire Dutch: Twente News Corpus (subcorpus: twodays from January 2000)
. 13,389 documents, 49,537 sentences, 860,637 tokens
. inferred alignment between raw and tokenized text
I Biomedical English: Biocreative1
. 7,500 sentences, 195,998 tokens (sentences are isolated,only word boundaries)
. inferred alignment between raw and tokenized text
http://gmb.let.rug.nl 10/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Baseline Experiment
I Newswire English without context features
I Confusion matrix:
predicted labelI T O S
gold label I 21,163 45 0 0T 26 5,316 0 53O 0 0 5,226 0S 4 141 0 123
I Main difficulty: distinguishing between T and S
http://gmb.let.rug.nl 11/21
A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
How Much Context Is Needed?
●
●
● ● ●
0 1 2 3 4
95
96
97
98
99
100
Left&right context
Acc
urac
y
● context characterscontext categories
●
●
●● ●
0 1 2 3 4
0
10
20
30
40
50
60
70
80
90
100
Left&right contextF
1 sc
ore
for
labe
l S
● context characterscontext categories
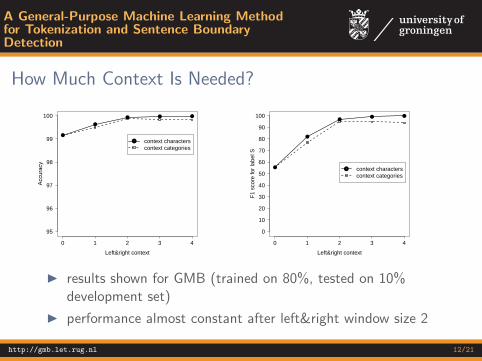
I results shown for GMB (trained on 80%, tested on 10%development set)
I performance almost constant after left&right window size 2
http://gmb.let.rug.nl 12/21
A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Characters or Categories?
●
●
● ● ●
0 1 2 3 4
95
96
97
98
99
100
Left&right context
Acc
urac
y
● context characterscontext categories
●
●
●● ●
0 1 2 3 4
0
10
20
30
40
50
60
70
80
90
100
Left&right context
F1
scor
e fo
r la
bel S
● context characterscontext categories
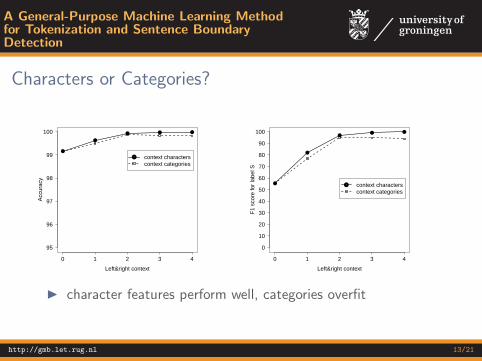
I character features perform well, categories overfit
http://gmb.let.rug.nl 13/21
A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Applying the Method to Dutch
●
●
● ● ●
0 1 2 3 4
95
96
97
98
99
100
Left&right context
Acc
urac
y
● context characterscontext categories
●
●
●● ●
0 1 2 3 4
0
10
20
30
40
50
60
70
80
90
100
Left&right context
F1
scor
e fo
r la
bel S
● context characterscontext categories
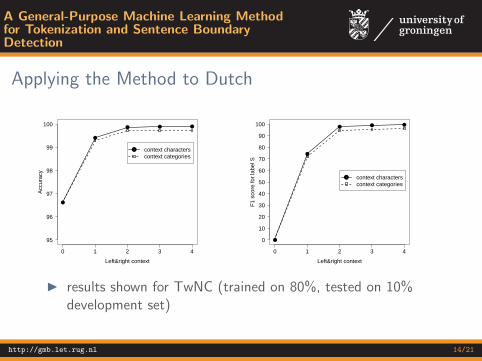
I results shown for TwNC (trained on 80%, tested on 10%development set)
http://gmb.let.rug.nl 14/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Applying the Method to Biomedical English
●
●● ● ●
0 1 2 3 4
95
96
97
98
99
100
Left&right context
Acc
urac
y
● context characterscontext categories
●
● ● ● ●
0 1 2 3 4
0
10
20
30
40
50
60
70
80
90
100
Left&right contextF
1 sc
ore
for
labe
l S
● context characterscontext categories
I results shown for Biocreative1 (trained on 80%, tested on10% development set)
I in this corpus: sentences isolated, sentence boundarydetection trivial
http://gmb.let.rug.nl 15/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
What Kinds of Erros Does More Context Fix?
I examples from English newswire, 2-window vs. 4-windowcharacter models
context: er Iran to the U.N. Security Council, whi
gold: IIOTIIIOTIOTIIOTIIIOTIIIIIIIOTIIIIIITOTII
2-window: IIOTIIIOTIOTIIOTIIIOSIIIIIIIOTIIIIIITOTII
4-window: IIOTIIIOTIOTIIOTIIIOTIIIIIIIOTIIIIIITOTII
context: by Sunni voters. Shi'ite leaders have not
gold: TIOTIIIIOTIIIIITOSIIIIIIOTIIIIIIOTIIIOTII
2-window: TIOTIIIIOTIIIIITOSIITIIIOTIIIIIIOTIIIOTII
4-window: TIOTIIIIOTIIIIITOSIIIIIIOTIIIIIIOTIIIOTII
http://gmb.let.rug.nl 16/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Examples of Errors Still Made by the Best Model
I examples from English newswire, 4-window character model
I probable causes: too simple features, not enough training data
context: ive arms race it cannot win. Taiwan split
gold: IIIOTIIIOTIIIOTIOTIITIIOTIITOSIIIIIOTIIII
4-window: IIIOTIIIOTIIIOTIOTIIIIIOTIITOSIIIIIOTIIII
context: ally paved with gold? Moses Bittok probab
gold: IIIIOTIIIIOTIIIOTIIITOSIIIIOTIIIIIOTIIIII
4-window: IIIIOTIIIIOTIIIOTIIIIOTIIIIOTIIIIIOTIIIII
http://gmb.let.rug.nl 17/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Is It Fast Enough?
I Tested on 4-core, 2.67 GHz desktop machine
I Training: around 1’30” for best model on 40,000 Dutchsentences
I Labeling: around 3,000 sentences/second
http://gmb.let.rug.nl 18/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Future Work
I Compare with existing rule-based tokenizers
I Compare with existing sentence-boundary detectors
I Can we build universal models (trained on mixed-language,mixed-domain corpora)?
I Experiment with more complex features
I Software release
http://gmb.let.rug.nl 19/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
Conclusions
I Word and sentence segmentation can be recast as a combinedtagging task
I Supervised learning: shift of labor from writing rules tocorrecting labels
I Learning this task with CRF achieves high speed and accuracy
I Our tagging method does not lose the connection betweenoriginal text and tokens
I Possible drawback of tagging method: no changes to originaltext possible, e.g. normalization of punctuation etc.
http://gmb.let.rug.nl 20/21

A General-Purpose Machine Learning Methodfor Tokenization and Sentence BoundaryDetection
References I
Dridan, R. and Oepen, S. (2012). Tokenization: Returning to along solved problem — a survey, contrastive experiment,recommendations, and toolkit —. In Proceedings of the 50thAnnual Meeting of the Association for Computational Linguistics(Volume 2: Short Papers), pages 378–382, Jeju Island, Korea.Association for Computational Linguistics.
http://gmb.let.rug.nl 21/21