a deferred cleansing method for rfid data analytics ibm almaden research center jun rao sangeeta...
TRANSCRIPT

A Deferred Cleansing Method for RFID Data Analytics
IBM Almaden Research CenterJun Rao
Sangeeta Doraiswamy Latha S. Colby
University of California at Los AngelesHetal Thakkar

RFID and Its Applications• Radio Frequency Identification
– Radio-based barcode– Becoming widely used in supply-chain, asset tracking …– Standardization based on Electronic Product Code (EPC)
EPC Rtime Reader Biz_loc
e1 t1 r1 warehouse
e2 t1 r1 warehouse
e1 t1 + 30 hours r2 distribution center
e2 t1 + 40 hours r2 distribution center
e1 t1 + 65 hours r3 store
… … … …
• Analytics on RFID data– simple: where is e1 at time t1 +50?– complex: average time spent per hop in the supply chain

RFID Data Tends to be Dirty• Various types of anomalies
– Physical: radio interference, media type, etc Redundant reads : (e1, t1, r1, l1) (e1, t1+2 secs, r1, l1) False reads : (e1, t1, r1, l1) ---> (e1, t1, r2, l2) Missing reads : (e1, t1, r1, l1) <--- (e1, t1+3, r2, l2) (e1, t1 + 10, r3, l3)– Logical: tend to be application dependent (e1, t1, r1, back room) (e1, t1+2, r2, sales floor) (e1, t1+5, r1, back room) (e1, t1+9, r2, sales floor)
• Small number of anomalies ---> large error in analysis• Cleaning RFID data is imperative!

Eager Cleansing vs. Deferred Cleansing• Conventional approach to cleansing is eager
– At the edge server: de-dup, smoothing, …– Before loading into a warehouse (ETL)
• have more context than the edge
– Clean once, reuse at query time– Typically reducing data size downstream– Best strategy if applicable
• Sometimes eager cleansing is not applicable– Don’t know how to clean until analyzing the data– More than one cleaned version (app-dependant anomalies)– Law enforcement (pharmaceutical e-pedigree tracking )
• We propose deferred cleansing– Load everything– Clean at query time– Has runtime overhead, but offers flexibility– Complementary to eager cleansing

Overview of Our Approach
DATABASE
2 4
3
5
CLEANSING RULES ENGINE
RULES TABLE EPC READS TABLE
USER RULE
1
6
USER QUERY
QUERY REWRITE ENGINE

Outline
• Cleansing rules and their implementation
• Query rewrite over cleansing rules
• Experimental results
• Conclusion

• EPC sequences, each of which has all reads of a EPC in rtime order– Very useful for cleansing as well as querying
RFID Data Characteristics
Duplicate removal: with v1 as ( select biz_loc as loc_current, max(biz_loc) over (partition by epc order by rtime asc rows between 1 preceding and 1 preceding) as loc_before from R )select * from v1 where loc_current != loc_before or loc_before is null;
(e1, t1, r1, l1)(e1, t1+2 secs, r1, l1)
EPC Rtime Reader Biz_loce1 t1 r1 warehouse
e1 t1+ 30 hours r2 distribution center
e1 t1 + 65 hours r3 store
e2 t1 r1 warehouse
e2 t1 + 40 hours r2 distribution center
… … … …
• Many sequence-based languages proposed
• But SQL/OLAP (standardized in SQL 99) can do sequence processing!

Exploit SQL/OLAP for Sequence-based Cleansing
• Pros– more efficient (compared with self-joins)– standardized (supported by major DB vendors)– integrated: parallelism, optimization
• Cons– complex syntax
• Solution– specify cleansing rules in a simpler language (based on SQL-TS)
• have impact on query rewrite as well– implement rules in DBMS using SQL/OLAP

Cycle Rule• Scenario Back room (X) Sales floor (Y) case (epc1)
Pattern Condition Action
(A, B, C) A.biz_loc=C. biz_loc andA.biz_loc != B.biz_loc
DELETE B
[X Y X Y X Y] [X Y]
CLUSTER BY epcSEQUENCE BY rtime
an ordered list of singleton references
target reference

Reader Rule
• Scenario docking door (reader D) warehouse (has location tag)forklift (reader X) r1 (readerD) r2 (readerX)
Pattern Condition Action
(A, *B) B.reader = ‘readerX’ and B.rtime – A.rtime < t2 mins
DELETE A
SQL/OLAP implementation max(case when reader = 'readerX' then 1 else 0 end) over (… range between 1 macro sec following and t2 min following) as has_readerX_after
B is a set reference
t2 mins
X

Missing Rule• Scenario L1 L2 L3
case (epcC) X X pallet (epcP) X X X
r1. Pattern Condition Action
(X,A,Y) A.is_pallet=1 and( (X.is_pallet=0 and A.biz_loc=X.biz_loc and A.rtime-X.rtime<5 mins) OR (Y.is_pallet=0 and A.biz_loc=Y.biz_loc and Y.rtime-A.rtime<5 mins) )
MODIFYA.has_case_nearby=1
r2. Pattern Condition Action
(A,*B) A.is_pallet=0 or (A.has_case_nearby=0 and B.has_case_nearby=1)
KEEP A
(X)

Query RFID Data over Cleansing Rules
• Q=σs(R)
• Q[C] is the answer to Q with respect to rule C
• Naïve implementation: Q[C] = σs(ФC(R)), where ФC is cleans input using rule C
• Traditional predicate pushdown through view not directly applicable
• Can we do this Q[C] = ФC(σs(R))? (incorrect)

t1-2 t1 t1+2
case on forklift r1(readerD) r2(readerX )
Example 1
σs(ФC(R)): {}
e1 = σrtime<t1(ФC(σrtime<t1+5(R)))
(expanded rewrite)
ФC(σs(R)): {r1}
Pattern Condition Action
(A, *B) B.reader = ‘readerX’ and B.rtime – A.rtime < 5 mins
DELETE A
Reader rule
Q1:σrtime<t1(R) ]

t2-2 t2 t2+2 case r3 (loc1) r4 (loc1) Q2:σrtime>t2(R) [
Example 2
σs(ФC(R)): {}
ФC(σs(R)): {r4}
Pattern Condition Action
(E, F) E.biz_loc = F.biz_loc DELETE F
Duplicate rule
e2=σrtime>t2(ФC(RepcΠepc(σrtime>t2(R))))
(Join-back rewrite, always applicable)

Rewrite Summary
• Expanded rewrite– work at rule level, instead of SQL/OLAP level– collect conditions in cleansing rules referencing target
reference– keep only position preserving conditions– run transitivity between surviving rule conditions and
query conditions– predicates derived on target reference can be pushed
down• Choose the rewrite between expanded and join-back• Extended to support multiple rules and join queries

Experimental Setup
steps (100)
biz_stepdesctype comment
parent(s*50)
child_epc parent_epc
locs (13k)
glndescsitestatecitycomment
caseR(s*1.5k)
epc rtimereaderbiz_locbiz_step
EPC_info(s*50)
epcproductlotmanufacture_date,expiration_datecomment
product (1,000)
productmanufacturercomment
palletR(s*30)
epc … RFID Data Schema

Queries and Rules
q1. “Dwell” analysis: average staying time between adjacent locations.with v1 as( select biz_loc as current_loc, rtime, max(rtime) over (… rows 1 preceding) as prev_time, max(biz_loc) over (… rows 1 preceding) as prev_loc from caseR where rtime <= T1 )select l1.loc_desc, l2.loc_desc, avg(rtime-prev_time)from v1, locs l1, locs l2where v1.prev_loc = l1.gln and v1.current_loc = l2.glngroup by l1.loc_desc, l2.loc_desc
q2. Site analysisselect p.manufacturer, count(distinct s.type), count(distinct c.reader)from caseR c, steps s, locs l, epc_info i, product pwhere c.biz_step=s.biz_step and c.biz_loc=l.gln and c.epc=i.epc and i.product=p.product and c.rtime >= T2 and l.site = ‘distribution center 2’group by p.manufacturer
rule name
1. reader on case reads2. duplicate on case reads3. replacing on case reads4. cycle on case reads5. missing on case+pallet reads
• 1 GB base data• Varying anomaly percentage
– implemented by inversing the rules• DB2 UDB V8.2• Indexes on queries attributes
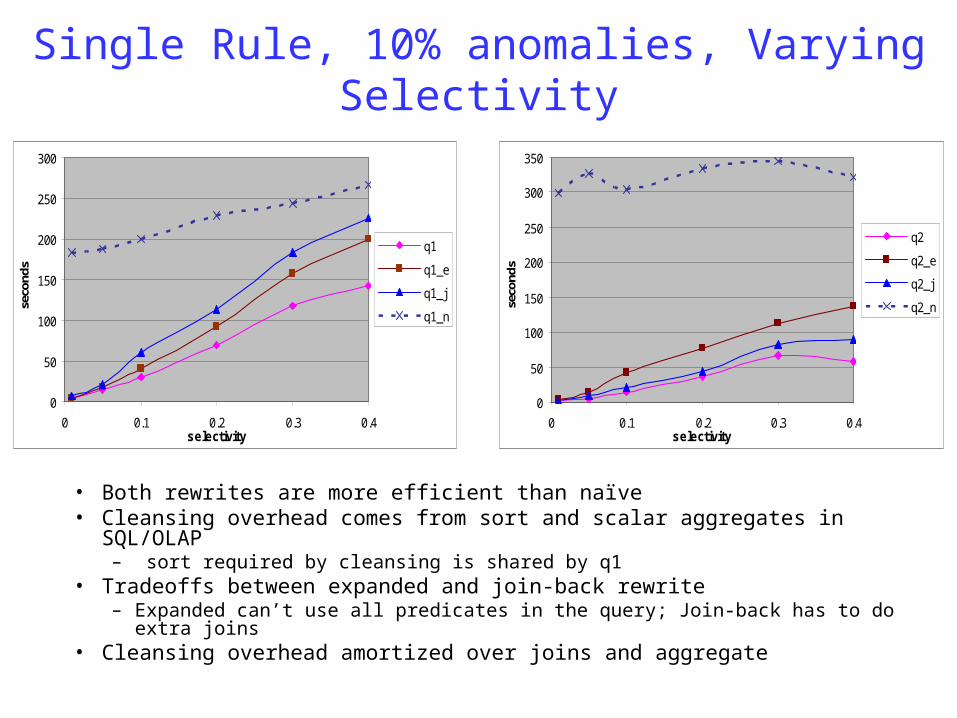
Single Rule, 10% anomalies, Varying Selectivity
• Both rewrites are more efficient than naïve• Cleansing overhead comes from sort and scalar aggregates in SQL/OLAP
– sort required by cleansing is shared by q1• Tradeoffs between expanded and join-back rewrite
– Expanded can’t use all predicates in the query; Join-back has to do extra joins• Cleansing overhead amortized over joins and aggregate
0
50
100
150
200
250
300
350
0 0.1 0.2 0.3 0.4selectivity
seco
nds
q2
q2_e
q2_j
q2_n
0
50
100
150
200
250
300
0 0.1 0.2 0.3 0.4selectivity
seco
nds
q1
q1_e
q1_j
q1_n

10% selectivity, 10% anomalies, Varying Rules
0
100
200
300
400
500
600
1 2 3 4 5# of rules
seco
nd
s
q2
q2_e
q2_j
q2_n
0
100
200
300
400
500
600
1 2 3 4 5# of rules
seco
nd
s
q1
q1_e
q1_j
q1_n
• Additional overhead per extra rule is moderate– sort required in SQL/OLAP is amortized in multiple rules
• “Missing rule” adds the most overhead– Has to sort both case reads as well as pallet reads

Conclusion
• Proposed a deferred cleansing approach to RFID data– Complementary to eager cleansing– Has overhead, but offers flexibility
• SQL-TS based cleansing rules for simplicity• SQL-OLAP implementation for efficiency• Two query rewrites exploit query predicates and
guarantee correctness• Experimental results show deferred cleansing is
affordable for typical analytical queries

Extended SQL-TS
• Cluster by (epc) and sequence by (rtime) define sequences• Pattern defines an ordered list of references
– a reference with no * sign refers to a single row – a reference with a * sign refers to a set of rows
• Where clause specifies condition on attributes in references– existential semantic on set reference
• Action is defined on a singleton reference (target reference)
DEFINE [rule name]ON [table name]FROM [table name]CLUSTER BY [cluster key]SEQUENCE BY [sequence key]AS [pattern]WHERE [condition]ACTION [DELETE | MODIFY | KEEP]
AS (A, B) WHERE A.biz_loc =B.biz_locDELETE B