a comprehensive survey on transfer learning
TRANSCRIPT

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
A Comprehensive Survey onTransfer Learning
By FUZHEN ZHUANG , ZHIYUAN QI , KEYU DUAN, DONGBO XI, YONGCHUN ZHU,HENGSHU ZHU, Senior Member IEEE, HUI XIONG, Fellow IEEE, AND QING HE
ABSTRACT | Transfer learning aims at improving the
performance of target learners on target domains by transfer-
ring the knowledge contained in different but related source
domains. In this way, the dependence on a large number
of target-domain data can be reduced for constructing tar-
get learners. Due to the wide application prospects, trans-
fer learning has become a popular and promising area in
machine learning. Although there are already some valuable
and impressive surveys on transfer learning, these surveys
introduce approaches in a relatively isolated way and lack the
recent advances in transfer learning. Due to the rapid expan-
sion of the transfer learning area, it is both necessary and
challenging to comprehensively review the relevant studies.
This survey attempts to connect and systematize the existing
transfer learning research studies, as well as to summarize
and interpret the mechanisms and the strategies of transfer
learning in a comprehensive way, which may help readers
have a better understanding of the current research status and
ideas. Unlike previous surveys, this survey article reviewsmore
than 40 representative transfer learning approaches, espe-
cially homogeneous transfer learning approaches, from the
perspectives of data and model. The applications of transfer
learning are also briefly introduced. In order to show the
Manuscript received March 14, 2020; revised June 11, 2020; accepted June 19,2020. This work was supported in part by the National Key Research andDevelopment Program of China under Grant 2018YFB1004300; in part by theNational Natural Science Foundation of China under Grant U1836206, GrantU1811461, Grant 61773361, and Grant 61836013; and in part by the Project ofYouth Innovation Promotion Association CAS under Grant 2017146. (FuzhenZhuang and Zhiyuan Qi contributed equally to this work.) (Correspondingauthors: Fuzhen Zhuang; Zhiyuan Qi.)
Fuzhen Zhuang, Zhiyuan Qi, Keyu Duan, Dongbo Xi, Yongchun Zhu, andQing He are with the Key Laboratory of Intelligent Information Processing,Institute of Computing Technology, Chinese Academy of Sciences (CAS), Beijing100190, China, and also with the University of Chinese Academy of Sciences,Beijing 100049, China (e-mail: [email protected]; [email protected]).
Hengshu Zhu is with Baidu Inc., Beijing 100085, China.
Hui Xiong is with Rutgers, The State University of New Jersey, Newark,NJ 08854 USA.
Digital Object Identifier 10.1109/JPROC.2020.3004555
performance of different transfer learning models, over 20 rep-
resentative transfer learning models are used for experiments.
The models are performed on three different data sets, that
is, Amazon Reviews, Reuters-21578, and Office-31, and the
experimental results demonstrate the importance of selecting
appropriate transfer learning models for different applications
in practice.
KEYWORDS | Domain adaptation; interpretation; machine
learning; transfer learning.
N O M E N C L AT U R ESymbol Definitionn Number of instances.m Number of domains.D Domain.T Task.X Feature space.Y Label space.x Feature vector.y Label.X Instance set.Y Label set corresponding to X.S Source domain.T Target domain.L Labeled instances.U Unlabeled instances.H Reproducing kernel Hilbert space.θ Mapping/coefficient vector.α Weighting coefficient.β Weighting coefficient.λ Tradeoff parameter.δ Parameter/error.b Bias.B Boundary parameter.N Iteration/kernel number.f Decision function.
0018-9219 © 2020 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.See https://www.ieee.org/publications/rights/index.html for more information.
PROCEEDINGS OF THE IEEE 1
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
L Loss function.η Scale parameter.G Graph.Φ Nonlinear mapping.σ Monotonically increasing function.Χ Structural risk.κ Kernel function.K Kernel matrix.H Centering matrix.C Covariance matrix.d Document.w Word.z Class variable.z Noise.D Discriminator.G Generator.S Function.M Orthonormal bases.Θ Model parameters.P Probability.E Expectation.Q Matrix variable.R Matrix variable.W Mapping matrix.
I. I N T R O D U C T I O NAlthough traditional machine learning technology hasachieved great success and has been successfully appliedin many practical applications, it still has some limita-tions for certain real-world scenarios. The ideal scenarioof machine learning is that there are abundant labeledtraining instances, which have the same distribution as thetest data. However, in many scenarios, collecting sufficienttraining data is often expensive, time-consuming, or evenunrealistic. Semi-supervised learning can partly solve thisproblem by relaxing the need of mass labeled data. Typ-ically, a semi-supervised approach only requires a limitednumber of labeled data, and it utilizes a large amount ofunlabeled data to improve the learning accuracy. But inmany cases, unlabeled instances are also difficult to col-lect, which usually makes the resultant traditional modelsunsatisfactory.
Transfer learning, which focuses on transferring theknowledge across domains, is a promising machine learn-ing methodology for solving the problem mentioned above.The concept about transfer learning may initially comefrom educational psychology. According to the general-ization theory of transfer, as proposed by psychologistC. H. Judd, learning to transfer is the result of thegeneralization of experience. It is possible to realize thetransfer from one situation to another, as long as a per-son generalizes his experience. According to this theory,the prerequisite of transfer is that there needs to be aconnection between two learning activities. In practice,a person who has learned the violin can learn the pianofaster than others, since both the violin and the pianoare musical instruments and may share some common
Fig. 1. Intuitive examples about transfer learning.
knowledge. Fig. 1 shows some intuitive examples abouttransfer learning. Inspired by human beings’ capabilitiesto transfer knowledge across domains, transfer learningaims to leverage knowledge from a related domain (calledsource domain) to improve the learning performance orminimize the number of labeled examples required in atarget domain. It is worth mentioning that the transferredknowledge does not always bring a positive impact onnew tasks. If there is little in common between domains,knowledge transfer could be unsuccessful. For example,learning to ride a bicycle cannot help us learn to playthe piano faster. Besides, the similarities between domainsdo not always facilitate learning, because sometimes thesimilarities may be misleading. For example, althoughSpanish and French have a close relationship with eachother and both belong to the Romance group of languages,people who learn Spanish may experience difficulties inlearning French, such as using the wrong vocabulary orconjugation. This occurs because previous successful expe-rience in Spanish can interfere with learning the wordformation, usage, pronunciation, conjugation, and so on,in French. In the field of psychology, the phenomenonthat previous experience has a negative effect on learningnew tasks is called negative transfer [1]. Similarly, in thetransfer learning area, if the target learner is negativelyaffected by the transferred knowledge, the phenomenon isalso termed as negative transfer [2], [3]. Whether negativetransfer will occur may depend on several factors, such asthe relevance between the source and the target domainsand the learner’s capacity of finding the transferable andbeneficial part of the knowledge across domains. In [3],a formal definition and some analyses of negative transferare given.
Roughly speaking, according to the discrepancy betweendomains, transfer learning can be further divided intotwo categories, that is, homogeneous and heterogeneoustransfer learning [4]. Homogeneous transfer learningapproaches are developed and proposed for handling thesituations where the domains are of the same featurespace. In homogeneous transfer learning, some studiesassume that domains differ only in marginal distributions.Therefore, they adapt the domains by correcting the sam-ple selection bias [5] or covariate shift [6]. However, thisassumption does not hold in many cases. For example,
2 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
in sentiment classification problem, a word may have dif-ferent meaning tendencies in different domains. This phe-nomenon is also called context feature bias [7]. To solvethis problem, some studies further adapt the conditionaldistributions. Heterogeneous transfer learning refers tothe knowledge transfer process in the situations wherethe domains have different feature spaces. In addition todistribution adaptation, heterogeneous transfer learningrequires feature space adaptation [7], which makes it morecomplicated than homogeneous transfer learning.
The survey aims to give readers a comprehensive under-standing about transfer learning from the perspectivesof data and model. The mechanisms and the strategiesof transfer learning approaches are introduced to allowreaders grasp how the approaches work. And a number ofthe existing transfer learning researches are connected andsystematized. Specifically, over 40 representative transferlearning approaches are introduced. Besides, we conductexperiments to demonstrate on which data set a transferlearning model performs well.
In this survey, we focus more on homogeneous transferlearning. Some interesting transfer learning topics arenot covered in this survey, such as reinforcement transferlearning [8], lifelong transfer learning [9], and onlinetransfer learning [10]. The rest of this survey is orga-nized into seven sections. Section II clarifies the differencebetween transfer learning and other related machine learn-ing techniques. Section III introduces the notation usedin this survey and the definitions about transfer learning.Sections IV and V interpret transfer learning approachesfrom the data and the model perspectives, respectively.Section VI introduces some applications of transfer learn-ing. Experiments are conducted and the results are pro-vided in Section VII. Section VIII concludes this survey.The main contributions of this survey are summarized asfollows.
1) Over 40 representative transfer learning approachesare introduced and summarized, which can givereaders a comprehensive overview about transferlearning.
2) Experiments are conducted to compare differenttransfer learning approaches. The performance ofover 20 different approaches is displayed intuitivelyand then analyzed, which may be instructive for thereaders to select the appropriate ones in practice.
II. R E L AT E D W O R KSome areas related to transfer learning are introduced.The connections and difference between them and transferlearning are clarified.
A. Semisupervised Learning
Semisupervised learning [11] is a machine learningtask and a method that lies between supervised learn-ing (with completely labeled instances) and unsupervisedlearning (without any labeled instances). Typically, a semi-supervised method utilizes abundant unlabeled instances
combined with a limited number of labeled instancesto train a learner. Semi-supervised learning relaxes thedependence on labeled instances and thus reduces theexpensive labeling costs. Note that, in semi-supervisedlearning, both the labeled and unlabeled instances aredrawn from the same distribution. In contrast, in transferlearning, the data distributions of the source and thetarget domains are usually different. Many transfer learn-ing approaches absorb the technology of semi-supervisedlearning. The key assumptions in semi-supervised learning,that is, smoothness, cluster, and manifold assumptions, arealso made use of in transfer learning. It is worth mention-ing that semi-supervised transfer learning is a controversialterm. The reason is that the concept of whether the labelinformation is available in transfer learning is ambiguousbecause both the source and the target domains can beinvolved.
B. Multiview Learning
Multiview learning [12] focuses on the machine learn-ing problems with multiview data. A view represents adistinct feature set. An intuitive example about multi-ple views is that a video object can be described fromtwo different viewpoints, that is, the image signal andthe audio signal. Briefly, multiview learning describesan object from multiple views, which results in abun-dant information. By properly considering the informa-tion from all views, the learner’s performance can beimproved. There are several strategies adopted in mul-tiview learning such as subspace learning, multikernellearning, and co-training [13], [14]. Multiview techniquesare also adopted in some transfer learning approaches.For example, Zhang et al. [15] proposed a multiview trans-fer learning framework, which imposes the consistencyamong multiple views. Yang and Gao [16] incorporatedmultiview information across different domains for knowl-edge transfer. The work by Feuz and Cook [17] introducesa multiview transfer learning approach for activity learn-ing, which transfers activity knowledge between heteroge-neous sensor platforms.
C. Multitask Learning
The thought of multitask learning [18] is to jointly learna group of related tasks. To be more specific, multitasklearning reinforces each task by taking advantage of theinterconnections between task, that is, considering boththe intertask relevance and the intertask difference. In thisway, the generalization of each task is enhanced. Themain difference between transfer learning and multitasklearning is that the former transfer the knowledge con-tained in the related domains, while the latter transfer theknowledge via simultaneously learning some related tasks.In other words, multitask learning pays equal attention toeach task, while transfer learning pays more attention tothe target task than to the source task. There are somecommons and associations between transfer learning and
PROCEEDINGS OF THE IEEE 3
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
multitask learning. Both of them aim to improve the per-formance of learners via knowledge transfer. Besides, theyadopt some similar strategies for constructing models, suchas feature transformation and parameter sharing. Note thatsome existing studies utilize both the transfer learning andthe multitask learning technologies. For example, the workby Zhang et al. [19] employs multitask and transfer learn-ing techniques for biological image analysis. The work byLiu et al. [20] proposes a framework for human actionrecognition based on multitask learning and multisourcetransfer learning.
III. O V E R V I E WIn this section, the notation used in this survey are listedfor convenience. Besides, some definitions and categoriza-tions about transfer learning are introduced, and somerelated surveys are also provided.
A. Notation
For convenience, a list of symbols and their definitionsare shown in Nomenclature. Besides, we use � · � to repre-sent the norm and superscript T to denote the transpose ofa vector/matrix.
B. Definition
In this section, some definitions about transfer learningare given. Before giving the definition of transfer learning,let us review the definitions of a domain and a task.
Definition 1 (Domain): A domain D is composed of twoparts, that is, a feature space X and a marginal distributionP (X). In other words, D = {X , P (X)}. And the symbol X
denotes an instance set, which is defined as X = {x|xi ∈X , i = 1, . . . , n}.
Definition 2 (Task): A task T consists of a label spaceY and a decision function f , that is, T = {Y, f}. Thedecision function f is an implicit one, which is expectedto be learned from the sample data.
Some machine learning models actually output the pre-dicted conditional distributions of instances. In this case,f(xj) = {P (yk|xj)|yk ∈ Y, k = 1, . . . , |Y|}.
In practice, a domain is often observed by a numberof instances with or without the label information. Forexample, a source domain DS corresponding to a sourcetask TS is usually observed via the instance-label pairs,that is, DS = {(x, y)|xi ∈ X S, yi ∈ YS, i = 1, . . . , nS};an observation of the target domain usually consists of anumber of unlabeled instances and/or limited number oflabeled instances.
Definition 3 (Transfer Learning): Given some/an obser-vation(s) corresponding to mS ∈ N
+ source domain(s)and task(s) (i.e., {(DSi , TSi)|i = 1, . . . , mS}), and some/anobservation(s) about mT ∈ N
+ target domain(s) andtask(s) (i.e., {(DTj , TTj )|j = 1, . . . , mT }), transfer learningutilizes the knowledge implied in the source domain(s) toimprove the performance of the learned decision functionsfTj (j = 1, . . . , mT ) on the target domain(s).
The above definition, which covers the situation ofmultisource transfer learning, is an extension of the onepresented in the survey [2]. If mS equals 1, the scenariois called single-source transfer learning. Otherwise, it iscalled multisource transfer learning. Besides, mT repre-sents the number of the transfer learning tasks. A fewstudies focus on the setting that mT ≥ 2 [21]. Theexisting transfer learning studies pay more attention tothe scenarios where mT = 1 (especially where mS =
mT = 1). It is worth mentioning that the observation ofa domain or a task is a concept with broad sense, whichis often cemented into a labeled/unlabeled instance set ora prelearned model. A common scenario is that we haveabundant labeled instances or have a well-trained modelon the source domain, and we only have limited labeledtarget-domain instances. In this case, the resources such asthe instances and the model are actually the observations,and the goal of transfer learning is to learn a more accuratedecision function on the target domain.
Another term commonly used in the transfer learningarea is domain adaptation. Domain adaptation refers tothe process that adapting one or more source domains totransfer knowledge and improve the performance of thetarget learner [4]. Transfer learning often relies on thedomain adaptation process, which attempts to reducethe difference between domains.
C. Categorization of Transfer Learning
There are several categorization criteria of transferlearning. For example, transfer learning problems can bedivided into three categories, that is, transductive, induc-tive, and unsupervised transfer learning [2]. The com-plete definitions of these three categories are presentedin [2]. These three categories can be interpreted from alabel-setting aspect. Roughly speaking, transductive trans-fer learning refers to the situations where the label infor-mation only comes from the source domain. If the labelinformation of the target-domain instances is available,the scenario can be categorized into inductive transferlearning. If the label information is unknown for both thesource and the target domains, the situation is known asunsupervised transfer learning. Another categorization isbased on the consistency between the source and the targetfeature spaces and label spaces. If XS = X T and YS = YT ,the scenario is termed as homogeneous transfer learning.Otherwise, if XS �= X T or/and YS �= YT , the scenario isreferred to as heterogeneous transfer learning.
According to the survey [2], the transfer learningapproaches can be categorized into four groups: instance-based, feature-based, parameter-based, and relational-based approaches. Instance-based transfer learningapproaches are mainly based on the instance weightingstrategy. Feature-based approaches transform the originalfeatures to create a new feature representation; theycan be further divided into two subcategories, thatis, asymmetric and symmetric feature-based transfer
4 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
Fig. 2. Categorizations of transfer learning.
learning. Asymmetric approaches transform the sourcefeatures to match the target ones. In contrast, symmetricapproaches attempt to find a common latent feature spaceand then transform both the source and the target featuresinto a new feature representation. The parameter-basedtransfer learning approaches transfer the knowledge atthe model/parameter level. Relational-based transferlearning approaches mainly focus on the problems inrelational domains. Such approaches transfer the logicalrelationship or rules learned in the source domain tothe target domain. For better understanding, Fig. 2shows the above-mentioned categorizations of transferlearning.
Some surveys are provided for the readers who wantto have a more complete understanding of this field. Thesurvey by Pan and Yang [2], which is a pioneering work,categorizes transfer learning and reviews the researchprogress before 2010. The survey by Weiss et al. [4]introduces and summarizes a number of homogeneousand heterogeneous transfer learning approaches. Hetero-geneous transfer learning is specially reviewed in the sur-vey by Day and Khoshgoftaar [7]. Some surveys review theliteratures related to specific themes such as reinforcementlearning [8], computational intelligence [22], and deeplearning [23], [24]. Besides, a number of surveys focuson specific application scenarios including activity recog-nition [25], visual categorization [26], collaborative rec-ommendation [27], computer vision [24], and sentimentanalysis [28].
Note that the organization of this survey doesnot strictly follow the above-mentioned categorizations.In Sections IV and V, transfer learning approaches areinterpreted from the data and the model perspectives.Roughly speaking, data-based interpretation covers theabove-mentioned instance-based and feature-based trans-fer learning approaches, but from a broader perspective.Model-based interpretation covers the above-mentionedparameter-based approaches. Since there are relatively fewstudies concerning relational-based transfer learning andthe representative approaches are well introduced in [2]
and [4], this survey does not focus on relational-basedapproaches.
IV. D ATA - B A S E D I N T E R P R E TAT I O NMany transfer learning approaches, especially thedata-based approaches, focus on transferring theknowledge via the adjustment and the transformation ofdata. Fig. 3 shows the strategies and the objectives of theapproaches from the data perspective. As shown in Fig. 3,space adaptation is one of the objectives. This objective isrequired to be satisfied mostly in heterogeneous transferlearning scenarios. In this survey, we focus more onhomogeneous transfer learning, and the main objectivein this scenario is to reduce the distribution differencebetween the source-domain and the target-domaininstances. Furthermore, some advanced approaches mayattempt to preserve the data properties in the adaptationprocess. There are generally two strategies for realizingthe objectives from the data perspective, that is, instanceweighting and feature transformation. In this section,some related transfer learning approaches are introducedin proper order according to the strategies shown in Fig. 3.
A. Instance Weighting Strategy
Let us first consider a simple scenario in which a largenumber of labeled source-domain and a limited number oftarget-domain instances are available and domains differonly in marginal distributions (i.e., P S(X) �= P T (X)
and P S(Y |X) = P T (Y |X)). For example, let us considerwe need to build a model to diagnose cancer in a spe-cific region where the elderly are the majority. Limitedtarget-domain instances are given, and relevant data areavailable from another region where young people are themajority. Directly transferring all the data from anotherregion may be unsuccessful, since the marginal distributiondifference exists, and the elderly have a higher risk ofcancer than younger people. In this scenario, it is naturalto consider adapting the marginal distributions. A simpleidea is to assign weights to the source-domain instances in
PROCEEDINGS OF THE IEEE 5
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
Fig. 3. Strategies and the objectives of the transfer learning approaches from the data perspective.
the loss function. The weighting strategy is based on thefollowing equation [5]:
E(x,y)∼P T [L(x, y; f)] = E(x,y)∼P S
�P T (x, y)
P S(x, y)L(x, y; f)
�
= E(x,y)∼P S
�P T (x)
P S(x)L(x, y; f)
�.
Therefore, the general objective function of a learning taskcan be written as [5]
minf
1
nS
nS�i=1
βiL�f(xS
i ), ySi
�+ Χ(f)
where βi (i = 1, 2, . . . , nS) is the weighting parameter.The theoretical value of βi is equal to P T (xi)/P S(xi).However, this ratio is generally unknown and is difficultto be obtained by using the traditional methods.
Kernel mean matching (KMM), which is proposed byHuang et al. [5], resolves the estimation problem of theabove unknown ratios by matching the means betweenthe source-domain and the target-domain instances in areproducing kernel Hilbert space (RKHS), that is,
arg minβi∈[0,B]
������������ 1
nS
nS�i=1
βiΦ�xS
i
�− 1
nT
nT�j=1
Φ�xT
j
�������������2
H
s.t.
������ 1
nS
nS�i=1
βi − 1
������ ≤ δ
where δ is a small parameter and B is a parameter forconstraint. The optimization problem mentioned abovecan be converted into a quadratic programming problemby expanding and using the kernel trick. This approach toestimating the ratios of distributions can be easily incor-porated into many existing algorithms. Once the weightβi is obtained, a learner can be trained on the weightedsource-domain instances.
There are some other studies attempting to estimatethe weights. For example, Sugiyama et al. [6] proposed anapproach termed Kullback–Leibler importance estimationprocedure (KLIEP). KLIEP depends on the minimization ofthe Kullback–Leibler (KL) divergence and incorporates abuilt-in model selection procedure. Based on the studies ofweight estimation, some instance-based transfer learningframeworks or algorithms are proposed. For example,Sun et al. [29] proposed a multisource framework termedtwo-stage weighting framework for multisource-domainadaptation (2SW-MDA) with the following twostages.
1) Instance weighting: The source-domain instances areassigned with weights to reduce the marginal distrib-ution difference, which is similar to KMM.
2) Domain weighting: Weights are assigned to eachsource domain for reducing the conditional dis-tribution difference based on the smoothnessassumption [30].
Then, the source-domain instances are reweighted basedon the instance weights and the domain weights. Thesereweighted instances and the labeled target-domaininstances are used to train the target classifier.
6 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
In addition to directly estimating the weightingparameters, adjusting weights iteratively is also effective.The key is to design a mechanism to decrease the weightsof the instances that have negative effects on the targetlearner. A representative work is TrAdaBoost, which is aframework proposed by Dai et al. [31]. This frameworkis an extension of AdaBoost [32]. AdaBoost is an effec-tive boosting algorithm designed for traditional machinelearning tasks. In each iteration of AdaBoost, a learneris trained on the instances with updated weights, whichresults in a weak classifier. The weighting mechanism ofinstances ensures that the instances with incorrect clas-sification are given more attention. Finally, the resultantweak classifiers are combined to form a strong classifier.TrAdaBoost extends the AdaBoost to the transfer learn-ing scenario; a new weighting mechanism is designed toreduce the impact of the distribution difference. Specif-ically, in TrAdaBoost, the labeled source-domain andlabeled target-domain instances are combined as a whole,that is, a training set, to train the weak classifier. Theweighting operations are different for the source-domainand the target-domain instances. In each iteration, a tem-porary variable δ, which measures the classification errorrate on the labeled target-domain instances, is calcu-lated. Then, the weights of the target-domain instancesare updated based on δ and the individual classificationresults, while the weights of the source-domain instancesare updated based on a designed constant and the indi-vidual classification results. For better understanding,the formulas used in the kth iteration (k = 1, . . . , N)for updating the weights are presented repeatedly asfollows [31]:
βSk,i = βS
k−1,i
�1 +
�2 ln nS/N
�−|fk(xSi )−yS
i |
(i = 1, . . . , nS)
βTk,j = βT
k−1,j
�δk/(1− δk)
−|fk(xTj )−yT
j | (j = 1, . . . , nT ).
Note that each iteration forms a new weak classifier. Thefinal classifier is constructed by combining and ensemblinghalf the number of the newly resultant weak classifiersthrough voting scheme.
Some studies further extend TrAdaBoost. The workby Yao and Doretto [33] proposes a Multi-Source TrAd-aBoost (MsTrAdaBoost) algorithm, which mainly has thefollowing two steps in each iteration.
1) Candidate classifier construction: A group of candi-date weak classifiers are, respectively, trained onthe weighted instances in the pairs of each sourcedomain and the target domain, that is, DSi ∪ DT
(i = 1, . . . , mS).2) Instance weighting: A classifier (denoted by j and
trained on DSj ∪ DT ) which has the minimal classifi-cation error rate δ on the target-domain instances isselected, and then is used for updating the weights ofthe instances in DSj and DT .
Finally, the selected classifiers from each iteration are com-bined to form the final classifier. Another parameter-basedalgorithm, that is, TaskTrAdaBoost, is also proposed in thework [33], which is introduced in Section V-C.
Some approaches realize instance weighting strategy ina heuristic way. For example, Jiang and Zhai [34] proposeda general weighting framework. There are three terms inthe framework’s objective function, which are designed tominimize the cross-entropy loss of three types of instances.The following types of instances are used to construct thetarget classifier.
1) Labeled target-domain instance: The classifier shouldminimize the cross-entropy loss on them, which isactually a standard supervised learning task.
2) Unlabeled target-domain instance: These instances’true conditional distributions P (y|xT,U
i ) are unknownand should be estimated. A possible solution isto train an auxiliary classifier on the labeledsource-domain and target-domain instances to helpestimate the conditional distributions or assignpseudo labels to these instances.
3) Labeled source-domain instance: The authors definethe weight of xS,L
i as the product of two parts,that is, αi and βi. The weight βi is ideally equal toP T (xi)/P S(xi), which can be estimated by nonpara-metric methods such as KMM or can be set uniformlyin the worst case. The weight αi is used to filter outthe source-domain instances that differ greatly fromthe target domain.
A heuristic method can be used to produce the value of αi,which contains the following three steps.
1) Auxiliary classifier construction: An auxiliary classi-fier trained on the labeled target-domain instancesare used to classify the unlabeled source-domaininstances.
2) Instance ranking: The source-domain instances areranked based on the probabilistic prediction results.
3) Heuristic weighting (βi): The weights of the top-ksource-domain instances with wrong predictions areset to zero, and the weights of others are set to 1.
B. Feature Transformation Strategy
Feature transformation strategy is often adoptedin feature-based approaches. For example, consider across-domain text classification problem. The task is toconstruct a target classifier by using the labeled text datafrom a related domain. In this scenario, a feasible solutionis to find the common latent features (e.g., latent topics)through feature transformation and use them as a bridge totransfer knowledge. Feature-based approaches transformeach original feature into a new feature representation forknowledge transfer. The objectives of constructing a newfeature representation include minimizing the marginaland the conditional distribution difference, preserving theproperties or the potential structures of the data, and
PROCEEDINGS OF THE IEEE 7
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
Table 1 Metrics Adopted in Transfer Learning
finding the correspondence between features. The opera-tions of feature transformation can be divided into threetypes, that is, feature augmentation, feature reduction,and feature alignment. Besides, feature reduction can befurther divided into several types such as feature mapping,feature clustering, feature selection, and feature encoding.A complete feature transformation process designed in analgorithm may consist of several operations.
1) Distribution Difference Metric: One primary objectiveof feature transformation is to reduce the distributiondifference of the source and the target-domain instances.Therefore, how to measure the distribution difference orthe similarity between domains effectively is an importantissue.
The measurement termed maximum mean discrep-ancy (MMD) is widely used in the field of transfer learning,which is formulated as follows [35]:
MMD�XS , XT
�=
������������ 1
nS
nS�i=1
Φ�xS
i
�− 1
nT
nT�j=1
Φ�xT
j
�������������2
H
.
MMD can be easily computed by using kernel trick. Briefly,MMD quantifies the distribution difference by calculat-ing the distance of the mean values of the instances inan RKHS. Note that the above-mentioned KMM actuallyproduces the weights of instances by minimizing the MMDdistance between domains.
Table 1 lists some commonly used metrics and therelated algorithms. In addition to Table 1, there are someother measurement criteria adopted in transfer learning,including Wasserstein distance [59], [60] and centralmoment discrepancy [61]. Some studies focus on opti-mizing and improving the existing measurements. Let ustake MMD as an example. Gretton et al. [62] proposeda multikernel version of MMD, that is, MK-MMD, whichtakes advantage of multiple kernels. Besides, Yan et al. [63]proposed a weighted version of MMD, which attempts toaddress the issue of class weight bias.
2) Feature Augmentation: Feature augmentation opera-tions are widely used in feature transformation, especiallyin symmetric feature-based approaches. To be more spe-cific, there are several ways to realize feature augmen-tation such as feature replication and feature stacking.For better understanding, we start with a simple transferlearning approach which is established based on featurereplication.
The work by Daumé [64] proposes a simple domainadaptation method, that is, feature augmentation method
(FAM). This method transforms the original features bysimple feature replication. Specifically, in single-sourcetransfer learning scenario, the feature space is augmentedto three times its original size. The new feature represen-tation consists of general features, source-specific features,and target-specific features. Note that, for the transformedsource-domain instances, their target-specific features areset to zero. Similarly, for the transformed target-domaininstances, their source-specific features are set to zero. Thenew feature representation of FAM is presented as follows:
ΦS
�xS
i
�=
xS
i ,xSi ,0
�, ΦT
�xT
j
�=
xT
j ,0, xTj
�
where ΦS and ΦT denote the mappings to the new featurespace from the source and the target domain, respectively.The final classifier is trained on the transformed labeledinstances. It is worth mentioning that this augmentationmethod is actually redundant. In other words, augmentingthe feature space in other ways (with fewer dimensions)may be able to produce competent performance. The supe-riority of FAM is that its feature expansion has an elegantform, which results in some good properties such as thegeneralization to multisource scenarios. An extension ofFAM is proposed by Daumé et al. [65], which utilizesthe unlabeled instances to further facilitate the knowledgetransfer process.
However, FAM may not work well in handling hetero-geneous transfer learning tasks. The reason is that directlyreplicating features and padding zero vectors are less effec-tive when the source and the target domains have differentfeature representations. To solve this problem, Li et al. [67]proposed an approach termed heterogeneous feature aug-mentation (HFA) [66]. The feature representation of HFAis presented as follows:
ΦS
�xS
i
�=
W SxS
i ,xSi ,0T
�ΦT
�xT
j
�=
W T xT
j ,0S ,xTj
�
where W SxSi and W T xT
j have the same dimension;0S and 0T denote the zero vectors with the dimensionsof xS and xT , respectively. HFA maps the original featuresinto a common feature space and then performs a featurestacking operation. The mapped features, original features,and zero elements are stacked in a particular order toproduce a new feature representation.
3) Feature Mapping: In the field of traditional machinelearning, there are many feasible mapping-based methodsof extracting features such as principal component analysis(PCA) [68] and kernelized-PCA (KPCA) [69]. However,these methods mainly focus on the data variance ratherthan the distribution difference. In order to solve thedistribution difference, some feature extraction methodsare proposed for transfer learning. Let us first considera simple scenario where there is little difference in the
8 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
conditional distributions of the domains. In this case,the following simple objective function can be used to finda mapping for feature extraction
minΦ
�DIST
�XS, XT ; Φ
+ λΧ(Φ)
�/�
VAR�XS ∪XT ; Φ
�
where Φ is a low-dimensional mapping function, DIST(·)represents a distribution difference metric, Χ(Φ) is aregularizer controlling the complexity of Φ, and VAR(·)represents the variance of instances. This objective func-tion aims to find a mapping function Φ that minimizesthe marginal distribution difference between domains andmeanwhile makes the variance of the instances as large aspossible. The objective corresponding to the denominatorcan be optimized in several ways. One possible way is tooptimize the objective of the numerator with a varianceconstraint. For example, the scatter matrix of the mappedinstances can be enforced as an identity matrix. Anotherway is to optimize the objective of the numerator in ahigh-dimensional feature space at first. Then, a dimensionreduction algorithm such as PCA or KPCA can be per-formed to realize the objective of the denominator.
Furthermore, finding the explicit formulation of Φ(·) isnontrivial. To solve this problem, some approaches adoptlinear mapping technique or turn to the kernel trick.In general, there are three main ideas to deal with theabove optimization problems.
1) Mapping learning + feature extraction: A possible wayis to find a high-dimensional space at first where theobjectives are met by solving a kernel matrix learningproblem or a transformation matrix finding problem.Then, the high-dimensional features are compactedto form a low-dimensional feature representation. Forexample, once the kernel matrix is learned, the prin-cipal components of the implicit high-dimensionalfeatures can be extracted to construct a new featurerepresentation based on PCA.
2) Mapping construction + mapping learning: Anotherway is to map the original features to a con-structed high-dimensional feature space, and then alow-dimensional mapping is learned to satisfy theobjective function. For example, a kernel matrix canbe constructed based on a selected kernel function atfirst. Then, the transformation matrix can be learned,which projects the high-dimensional features into acommon latent subspace.
3) Direct low-dimensional mapping learning: It is usuallydifficult to find a desired low-dimensional mappingdirectly. However, if the mapping is assumed to satisfycertain conditions, it may be solvable. For example,if the low-dimensional mapping is restricted to be alinear one, the optimization problem can be easilysolved.
Some approaches also attempt to match the condi-tional distributions and preserve the structures of the data.To achieve this, the above simple objective function needs
to incorporate new terms or/and constraints. For exam-ple, the following general objective function is a possiblechoice:
minΦ
μDIST�XS , XT ; Φ
�+ λ1Χ
GEO(Φ) + λ2Χ(Φ)
+ (1− μ)DIST�Y S |XS , Y T |XT ; Φ
�s.t. Φ(X)THΦ(X) = I, with H = I − (1/n) ∈ R
n×n
where μ is a parameter balancing the marginal and theconditional distribution difference [70], ΧGEO(Φ) is a reg-ularizer controlling the geometric structure, Φ(X) is thematrix whose rows are the instances from both the sourceand the target domains with the extracted new featurerepresentation, H is the centering matrix for constructingthe scatter matrix, and the constraint is used to maxi-mize the variance. The last term in the objective functiondenotes the measurement of the conditional distributiondifference.
Before the further discussion about the above objectivefunction, it is worth mentioning that the label informationof the target-domain instances is often limited or evenunknown. The lack of the label information makes itdifficult to estimate the distribution difference. In orderto solve this problem, some approaches resort to thepseudo-label strategy, that is, assigning pseudo labels tothe unlabeled target-domain instances. A simple methodof realizing this is to train a base classifier to assignpseudo labels. By the way, there are some other methods ofproviding pseudo labels such as co-training [71], [72] andtri-training [73], [74]. Once the pseudo-label informationis complemented, the conditional distribution differencecan be measured. For example, MMD can be modifiedand extended to measure the conditional distribution dif-ference. Specifically, for each label, the source-domainand the target-domain instances that belong to the sameclass are collected, and the estimation expression of theconditional distribution difference is given by [38]
|Y|�k=1
������������ 1
nSk
nSk�
i=1
Φ�xS
i
�− 1
nTk
nTk�
j=1
Φ�xT
j
�������������2
H
where nSk and nT
k denote the numbers of the instancesin the source and the target domains with the samelabel Yk, respectively. This estimation actually measuresthe class-conditional distribution [i.e., P (x|y)] differenceto approximate the conditional distribution [i.e., P (y|x)]difference. Some studies improve the above estimation. Forexample, the work by Wang et al. [70] uses a weightedmethod to additionally solve the class imbalance problem.For better understanding, the transfer learning approachesthat are the special cases of the general objective func-tion presented in the previous paragraph are detailed asfollows.
PROCEEDINGS OF THE IEEE 9
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
1) μ = 1 and λ1 �= 0: The objective function of MMDembedding (MMDE) is given by [75]
minK
MMD�XS , XT ; Φ
�− λ1
nS + nT�i�=j
||Φ(xi)− Φ(xj)||2
s.t. ∀(xi ∈ k-NN(xj)) ∧ (xj ∈ k-NN(xi))
||Φ(xi)−Φ(xj)||2 = ||xi − xj ||2�xi,xj ∈ XS ∪XT
�
where k-NN(x) represents the k nearest neighborsof the instance x. Weinberger et al. [76] design theabove objective function motivated by maximum vari-ance unfolding (MVU). Instead of employing a scattermatrix constraint, the constraints and the secondterm of this objective function aim to maximize thedistance between instances as well as preserve localgeometry. The desired kernel matrix K can be learnedby solving a semi-definite programming (SDP) [77]problem. After obtaining the kernel matrix, PCA isapplied to it, and then the leading eigenvectors areselected to help construct a low-dimensional featurerepresentation.
2) μ = 1 and λ1 = 0: The work by Pan et al. [36], [78]proposes an approach termed transfer componentanalysis (TCA). TCA adopts MMD to measure themarginal distribution difference and enforces the scat-ter matrix as the constraint. Different from MMDEthat learns the kernel matrix and then further adoptsPCA, TCA is a unified method that just needs tolearn a linear mapping from an empirical kernelfeature space to a low-dimensional feature space.In this way, it avoids solving the SDP problem, whichresults in relatively low computational burden. Thefinal optimization problem can be easily solved viaeigen-decomposition. TCA can also be extended toutilize the label information. In the extended ver-sion, the scatter matrix constraint is replaced by anew one that balances the label dependence (mea-sured by HSIC) and the data variance. Besides,a graph Laplacian regularizer [30] is also added topreserve the geometry of the manifold. Similarly,the final optimization problem can also be solved byeigen-decomposition.
3) μ = 0.5 and λ1 = 0: Long et al. [38] pro-posed an approach termed joint distribution adap-tation (JDA). JDA attempts to find a transformationmatrix that maps the instances to a low-dimensionalspace where both the marginal and the conditionaldistribution difference are minimized. To realize it,the MMD metric and the pseudo-label strategy areadopted. The desired transformation matrix can beobtained by solving a trace optimization problemvia eigen-decomposition. Furthermore, it is obviousthat the accuracy of the estimated pseudo labels
affects the performance of JDA. In order to improvethe labeling quality, the authors adopt the iterativerefinement operations. Specifically, in each iteration,JDA is performed, and then a classifier is trainedon the instances with the extracted features. Next,the pseudo labels are updated based on the trainedclassifier. After that, JDA is performed repeatedly withthe updated pseudo labels. The iteration ends whenconvergence occurs. Note that JDA can be extendedby utilizing the label and structure information [79],clustering information [80], various statistical andgeometrical information [81], and so on
4) μ ∈ (0, 1) and λ1 = 0: The article by Wang et al. [70]proposes an approach termed balanced distributionadaptation (BDA), which is an extension of JDA. Dif-ferent from JDA which assumes that the marginal andthe conditional distributions have the same impor-tance in adaptation, BDA attempts to balance themarginal and the conditional distribution adaptation.The operations of BDA are similar to JDA. In addition,the authors also proposed the weighted BDA (WBDA).In WBDA, the conditional distribution difference ismeasured by a weighted version of MMD to solve theclass imbalance problem.
It is worth mentioning that some approaches transformthe features into a new feature space (usually of a highdimension) and train an adaptive classifier simultaneously.To realize this, the mapping function of the features andthe decision function of the classifier need to be associated.One possible way is to define the following decision func-tion: f(x) = θ · Φ(x) + b, where θ denotes the classifierparameter; b denotes the bias. In light of the represen-ter theorem [82], the parameter θ can be defined asθ =
�ni=1 αiΦ(xi), and thus we have
f(x) =n�
i=1
αiΦ(xi) · Φ(x) + b =n�
i=1
αiκ(xi,x) + b
where κ denotes the kernel function. By using the kernelmatrix as the bridge, the regularizers designed for themapping function can be incorporated into the classi-fier’s objective function. In this way, the final optimiza-tion problem is usually about the parameter (e.g., αi)or the kernel function. For example, the article byLong et al. [39] proposes a general framework termedadaptation regularization-based transfer learning (ARTL).The goals of ARTL are to learn the adaptive classifier,to minimize the structural risk, to jointly reduce themarginal and the conditional distribution difference, andto maximize the manifold consistency between the datastructure and the predictive structure. The authors alsoproposed two specific algorithms under this frameworkbased on different loss functions. In these two algo-rithms, the coefficient matrix for computing MMD andthe graph Laplacian matrix for manifold regularization areconstructed at first. Then, a kernel function is selected to
10 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
construct the kernel matrix. After that, the classifier learn-ing problem is converted into a parameter (i.e., αi) solvingproblem, and the solution formula is also given in [39].
In ARTL, the choice of the kernel function affects theperformance of the final classifier. In order to construct arobust classifier, some studies turn to kernel learning. Forexample, the article by Duan et al. [83] proposes a unifiedframework termed domain transfer multiple kernel learn-ing (DTMKL). In DTMKL, the kernel function is assumed tobe a linear combination of a group of base kernels, that is,κ(xi,xj) =
�Nk=1 βkκk(xi,xj). DTMKL aims to minimize
the distribution difference, the classification error, andso on, simultaneously. The general objective function ofDTMKL can be written as follows:
minβk,f
σ�
MMD(XS , XT ; κ)�
+ λΧL(βk, f)
where σ is any monotonically increasing function, f isthe decision function with the same definition as theone in ARTL, and ΧL(βk, f) is a general term repre-senting a group of regularizers defined on the labeledinstances such as the ones for minimizing the classifica-tion error and controlling the complexity of the resultantmodel. Rakotomamonjy et al. [84] developed an algorithmto learn the kernel and the decision function simulta-neously by using the reduced gradient descent method.In each iteration, the weight coefficients of base kernelsare fixed to update the decision function at first. Then,the decision function is fixed to update the weight coef-ficients. Note that DTMKL can incorporate many existingkernel methods. The authors proposed two specific algo-rithms under this framework. The first one implements theframework by using hinge loss and support vector machine(SVM). The second one is an extension of the first onewith an additional regularizer utilizing pseudo-label infor-mation, and the pseudo labels of the unlabeled instancesare generated by using base classifiers.
4) Feature Clustering: Feature clustering aims to finda more abstract feature representation of the originalfeatures. Although it can be regarded as a way of fea-ture extraction, it is different from the above-mentionedmapping-based extraction.
For example, some transfer learning approaches implic-itly reduce the features by using the co-clusteringtechnique, that is, simultaneously clustering both thecolumns and rows of (or say, co-cluster) a contin-gency table based on the information theory [85]. Thearticle by Dai et al. [41] proposes an algorithm termedCo-Clustering-Based Classification (CoCC), which is usedfor document classification. In a document classificationproblem, the transfer learning task is to classify thetarget-domain documents (represented by a document-to-word matrix) with the help of the labeled sourcedocument-to-word data. CoCC regards the co-clusteringtechnique as a bridge to transfer the knowledge. In CoCC
algorithm, both the source and the target document-to-word matrices are co-clustered. The source document-to-word matrix is co-clustered to generate the word clustersbased on the known label information, and these wordclusters are used as constraints during the co-clusteringprocess of the target-domain data. The co-clustering crite-rion is to minimize the loss in mutual information, and theclustering results are obtained by iteration. Each iterationcontains the following two steps.
1) Document clustering: Each row of the targetdocument-to-word matrix is reordered based on theobjective function for updating the document clusters.
2) Word clustering: The word clusters are adjusted tominimize the joint mutual-information loss of thesource and the target document-word matrices.
After several times of iterations, the algorithm converges,and the classification results are obtained. Note that,in CoCC, the word clustering process implicitly extracts theword features to form unified word clusters.
Dai et al. [42] also proposed an unsupervised clusteringapproach, which is termed as self-taught clustering (STC).Similar to CoCC, this algorithm is also a co-clustering-based one. However, STC does not need the labelinformation. STC aims to simultaneously co-cluster thesource-domain and the target-domain instances with theassumption that these two domains share the same featureclusters in their common feature space. Therefore, twoco-clustering tasks are separately performed at the sametime to find the shared feature clusters. Each iteration ofSTC has the following steps.
1) Instance clustering: The clustering results of thesource-domain and the target-domain instances areupdated to minimize their respective loss in mutualinformation.
2) Feature clustering: The feature clusters are updated tominimize the joint loss in mutual information.
When the algorithm converges, the clustering results of thetarget-domain instances are obtained.
Different from the above-mentioned co-clustering-basedones, some approaches extract the original features intoconcepts (or topics). In the document classification prob-lem, the concepts represent the high-level abstractness ofthe words (e.g., word clusters). In order to introduce theconcept-based transfer learning approaches easily, let usbriefly review the latent semantic analysis (LSA) [86],the probabilistic LSA (PLSA) [87], and the dual-PLSA [88].
1) LSA: LSA is an approach to mapping the document-to-word matrix to a low-dimensional space (i.e., a latentsemantic space) based on the singular value decom-position SVD) technique. In short, LSA attempts tofind the true meanings of the words. To realize this,SVD technique is used to reduce the dimensionality,which can remove the irrelevant information andfilter out the noise information from the raw data.
2) PLSA: PLSA is developed based on a statistical viewof LSA. PLSA assumes that there is a latent class
PROCEEDINGS OF THE IEEE 11
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
variable z, which reflects the concept, associatingthe document d and the word w. Besides, d andw are independently conditioned on the concept z.The diagram of this graphical model is presented asfollows:
dP (di|zk)←−−−−−
P (zk)⇓z
P (wj |zk)−−−−−−→ w
where the subscripts i, j, and k represent theindexes of the document, the word, and the con-cept, respectively. PLSA constructs a Bayesian net-work, and the parameters are estimated by using theexpectation-maximization (EM) algorithm [89].
3) Dual-PLSA: The dual-PLSA is an extension of PLSA.This approach assumes there are two latent variableszd and zw associating the documents and the words.Specifically, the variables zd and zw reflect the con-cepts behind the documents and the words, respec-tively. The diagram of the dual-PLSA is provided asfollows:
dP�
di|zdk1
�
←−−−−−−− zdP�
zdk1
,zwk2
�
←−−−−−−−→ zwP�
wj |zwk2
�
−−−−−−−→ w.
The parameters of the dual-PLSA can also be obtainedbased on the EM algorithm.
Some concept-based transfer learning approaches areestablished based on PLSA. For example, the article byXue et al. [90] proposes a cross-domain text classi-fication approach termed topic-bridged PLSA (TPLSA).TPLSA, which is an extension of PLSA, assumes that thesource-domain and the target-domain instances share thesame mixing concepts of the words. Instead of performingtwo PLSAs for the source domain and the target domainseparately, the authors merge those two PLSAs as anintegrated one by using the mixing concept z as a bridge,that is, each concept has some probabilities to producethe source-domain and the target-domain documents. Thediagram of TPLSA is provided as follows:
���dS
dT
��
P(dSi |zk)
========P(dT
i|zk)
zP(zk|wj)←−−−−−− w.
Note that PLSA does not require the label information.In order to exploit the label information, the authorsadd the concept constraints, which include must-link andcannot-link constraints, as the penalty terms in the objec-tive function of TPLSA. Finally, the objective function isiteratively optimized to obtain the classification results[i.e., arg maxzP (z|dT
i )] by using the EM algorithm.The work by Zhuang et al. [91], [92] proposes
an approach termed collaborative dual-PLSA (CD-PLSA)for multidomain text classification (mS source domainsand mT target domains). CD-PLSA is an extension of
dual-PLSA. Its diagram is shown as follows:
P(Dk0)⇓D →
P�
di|zdk1
,Dk0
�
⇓d ← zd
P�
zdk1
,zwk2
�
←−−−−−−−→zw→P�
wj |zwk2
,Dk0
�
⇓w
�
where 1 ≤ k0 ≤ mS + mT denotes the domain index.The domain D connects both the variables d and w butis independent of the variables zd and zw. The labelinformation of the source-domain instances is utilized byinitializing the value P (di|zd
k1 ,Dk0) (k0 = 1, . . . , mS).Due to the lack of the target-domain label information,the value P (di|zd
k1 ,Dk0) (k0 = mS + 1, . . . , mS + mT )can be initialized based on any supervised classifier. Sim-ilarly, the authors adopt the EM algorithm to find theparameters. Through the iterations, all the parameters inthe Bayesian network are obtained. Thus, the class labelof the ith document in a target domain (denoted by Dk)can be predicted by computing the posterior probabilities,i.e., arg maxzdP (zd|di,Dk).
Zhuang et al. [93] further proposed a generalframework that is termed as homogeneous-identical-distinct-concept (HIDC) model. This framework isalso an extension of dual-PLSA. HIDC is composedof three generative models, that is, identical-concept,homogeneous-concept, and distinct-concept models.These three graphical models are presented asfollows:
Identical-concept model: D→d←zd
� →zw
IC→w
Homogeneous-concept model: �D→d←zd
� →zw
HC→w
Distinct-concept model: � �D→d←zd
� →zw
DC→w .
The original word concept zw is divided into three types,that is, zw
IC, zwHC, and zw
DC. In the identical-concept model,the word distributions only rely on the word concepts,and the word concepts are independent of the domains.However, in the homogeneous-concept model, the worddistributions also depend on the domains. The differ-ence between the identical and the homogeneous con-cepts is that zw
IC is directly transferable, while zwHC is the
domain-specific transferable one that may have differenteffects on the word distributions for different domains.In the distinct-concept model, zw
DC is actually the nontrans-ferable domain-specific one, which may only appear in aspecific domain. The above-mentioned three models arecombined as an integrated one, that is, HIDC. Similar toother PLSA-related algorithms, HIDC also uses EM algo-rithm to get the parameters.
12 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
5) Feature Selection: Feature selection is another kind ofoperation for feature reduction, which is used to extractthe pivot features. The pivot features are the ones thatbehave in the same way in different domains. Due to thestability of these features, they can be used as the bridgeto transfer the knowledge. For example, Blitzer et al. [94]proposed an approach termed structural correspondencelearning (SCL). Briefly, SCL consists of the following stepsto construct a new feature representation.
1) Feature selection: SCL first performs feature selectionoperations to obtain the pivot features.
2) Mapping learning: The pivot features are utilized tofind a low-dimensional common latent feature spaceby using the structural learning technique [95].
3) Feature stacking: A new feature representation is con-structed by feature augmentation, that is, stacking theoriginal features with the obtained low-dimensionalfeatures.
Take the part-of-speech tagging problem as an example.The selected pivot features should occur frequently insource and target domains. Therefore, determiners can beincluded in pivot features. Once all the pivot features aredefined and selected, a number of binary linear classifierswhose function is to predict the occurrence of each pivotfeature are constructed. Without the loss of generality,the decision function of the ith classifier, which is usedto predict the ith pivot feature, can be formulated asfi(x) = sign(θi · x), where x is assumed to be a binaryfeature input. And the ith classifier is trained on all theinstances excluding the features derived from the ith pivotfeature. The following formula can be used to estimate theith classifier’s parameters, that is
θi = arg minθ
1
n
n�j=1
L (θ · xj , Rowi(xj)) + λ�θ�2
where Rowi(xj) denotes the true value of the unlabeledinstance xj in terms of the ith pivot feature. By stacking theobtained parameter vectors as column elements, a matrixW is obtained. Next, based on SVD, the top-k left singularvectors, which are the principal components of the matrixW , are taken to construct the transformation matrix W .At last, the final classifier is trained on the labeled instancesin an augmented feature space, that is, ([xL
i ; W TxLi ]T, yL
i ).
6) Feature Encoding: In addition to feature extractionand selection, feature encoding is also an effective tool.For example, autoencoders, which are often adopted indeep learning area, can be used for feature encoding.An autoencoder consists of an encoder and a decoder. Theencoder tries to produce a more abstract representationof the input, while the decoder aims to map back thatrepresentation and to minimize the reconstruction error.Autoencoders can be stacked to build a deep learningarchitecture. Once an autoencoder completes the trainingprocess, another autoencoder can be stacked at the top of
it. The newly added autoencoder is then trained by usingthe encoded output of the upper-level autoencoder as itsinput. In this way, deep learning architectures can thus beconstructed.
Some transfer learning approaches are developedbased on autoencoders. For example, the article byGlorot et al. [96] proposes an approach termed stackeddenoising autoencoder (SDA). The denoising autoencoder,which can enhance the robustness, is an extension ofthe basic one [97]. This kind of autoencoder contains arandomly corrupting mechanism that adds noise to theinput before mapping. For example, an input can be cor-rupted or partially destroyed by adding a masking noise orGaussian noise. The denoising autoencoder is then trainedto minimize the denoising reconstruction error betweenthe original clean input and the output. The SDA algorithmproposed in this article mainly encompasses the followingsteps.
1) Autoencoder training: The source-domain andtarget-domain instances are used to train a stack ofdenoising autoencoders in a greedy layer-by-layerway.
2) Feature encoding and stacking: A new feature rep-resentation is constructed by stacking the encodingoutput of intermediate layers, and the features ofthe instances are transformed into the obtained newrepresentation.
3) Learner training: The target classifier is trained on thetransformed labeled instances.
Although the SDA algorithm has excellent performancefor feature extraction, it still has some drawbacks suchas high computational and parameter-estimation cost.In order to shorten the training time and to speed uptraditional SDA algorithms, Chen et al. [98], [99] proposeda modified version of SDA, that is, marginalized stackedlinear denoising autoencoder (mSLDA). This algorithmadopts linear autoencoders and marginalizes the randomlycorrupting step in a closed form. It may seem that linearautoencoders are too simple to learn complex features.However, the authors observe that linear autoencoders areoften sufficient to achieve competent performance whenencountering high-dimensional data. The basic architec-ture of mSLDA is a single-layer linear autoencoder. Thecorresponding single-layer mapping matrix W (augmentedwith a bias column for convenience) should minimize theexpected squared reconstruction loss function, that is,
W = arg minW
1
2n
n�i=1
EP (xi|x)
||xi −W xi||2
�
where xi denotes the corrupted version of the input xi.The solution of W is given by [98], [99]
W =
�n�
i=1
xiE[xi]T
��n�
i=1
E
�xix
Ti
��−1
.
PROCEEDINGS OF THE IEEE 13
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
When the corruption strategy is determined, the aboveformulas can be further expanded and simplified into aspecific form. Note that, in order to insert nonlinearity,a nonlinear function is used to squash the output of eachautoencoder after we obtain the matrix W in a closedform. Then, the next linear autoencoder is stacked to thecurrent one in a similar way to SDA. In order to deal withhigh-dimensional data, the authors also put forward anextension approach to further reduce the computationalcomplexity.
7) Feature Alignment: Note that feature augmentationand feature reduction mainly focus on the explicit fea-tures in a feature space. In contrast, in addition to theexplicit features, feature alignment also focuses on someimplicit features such as the statistic features and thespectral features. Therefore, feature alignment can playvarious roles in the feature transformation process. Forexample, the explicit features can be aligned to generatea new feature representation, or the implicit features canbe aligned to construct a satisfied feature transformation.
There are several kinds of features that can be aligned,which includes subspace features, spectral features, andstatistic features. Take the subspace feature alignment asan example. A typical approach mainly has the followingsteps.
1) Subspace generation: In this step, the instances areused to generate the respective subspaces for thesource and the target domains. The orthonormalbases of the source- and the target-domain subspacesare then obtained, which are denoted by MS and MT ,respectively. These bases are used to learn the shiftbetween the subspaces.
2) Subspace alignment (SA): In the second step, a map-ping, which aligns the bases MS and MT of the sub-spaces, is learned. And the features of the instancesare projected to the aligned subspaces to generatenew feature representation.
3) Learner training: Finally, the target learner is trainedon the transformed instances.
For example, the work by Fernando et al. [100] proposesan approach termed SA. In SA, the subspaces are generatedby performing PCA; the bases MS and MT are obtained byselecting the leading eigenvectors. Then, a transformationmatrix W is learned to align the subspaces, which is givenby [100]
W = arg minW
||MSW −MT ||2F = MTSMT
where || · ||F denotes the Frobenius norm. Note that thematrix W aligns MS with MT , or say, transforms thesource subspace coordinate system into the target subspacecoordinate system. The transformed low-dimensionalsource-domain and target-domain instances are given byXSMSW and XT MT , respectively. Finally, a learner canbe trained on the resultant transformed instances.
In light of SA, a number of transfer learningapproaches are established. For example, the article bySun and Saenko [101] proposes an approach that alignsboth the subspace bases and the distributions, which istermed as subspace distribution alignment between twosubspaces (SDA-TS). In SDA-TS, the transformation matrixW is formulated as W = MT
SMT Q, where Q is a matrixused to align the distribution difference. The transforma-tion matrix W in SA is a special case of the one in SDA-TSby setting Q to an identity matrix. Note that SA is asymmetrical feature-based approach, while SDA-TS is anasymmetrical one. In SDA-TS, the labeled source-domaininstances are projected to the source subspace, thenmapped to the target subspace, and finally mapped backto the target domain. The transformed source-domaininstances are formulated as XSMSWMT
T .Another representative subspace feature alignment
approach is geodesic flow kernel (GFK), which is proposedby Gong et al. [102]. GFK is closely related to a previousapproach termed geodesic flow subspaces (GFSs) [103].Before introducing GFK, let us review the steps of GFS atfirst. GFS is inspired by incremental learning. Intuitively,utilizing the information conveyed by the potential pathbetween two domains may be beneficial to the domainadaptation. GFS generally takes the following steps to alignfeatures.
1) Subspace generation: GFS first generates twosubspaces of the source and the target domains byperforming PCA, respectively.
2) Subspace interpolation: The two obtained subspacescan be viewed as two points on the Grassmannmanifold [104]. A finite number of the interpo-lated subspaces are generated between these twosubspaces based on the geometric properties of themanifold.
3) Feature projection and stacking: The original featuresare transformed by stacking the corresponding projec-tions from all the obtained subspaces.
Despite the usefulness and superiority of GFS, there isa problem about how to determine the number of theinterpolated subspaces. GFK resolves this problem by inte-grating infinite number of the subspaces located on thegeodesic curve from the source subspace to the target one.The key of GFK is to construct an infinite-dimensional fea-ture space that incorporating the information of all the sub-spaces lying on the geodesic flow. In order to compute theinner product in the resultant infinite-dimensional space,the GFK is defined and derived. In addition, a subspace-disagreement measure is proposed to select the optimaldimensionality of the subspaces; a rank-of-domain metricis also proposed to select the optimal source domain whenmultisource domains are available.
Statistic feature alignment is another kind of featurealignment. For example, Sun et al. [105] proposed anapproach termed co-relation alignment (CORAL). CORALconstructs the transformation matrix of the source features
14 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
by aligning the second-order statistic features, that is,the covariance matrices. The transformation matrix W isgiven by [105]
W = arg minW
||W TCSW − CT ||2F
where C denotes the covariance matrix. Note that, com-pared to the above subspace-based approaches, CORALavoids subspace generation as well as projection and isvery easy to implement.
Some transfer learning approaches are establishedbased on spectral feature alignment (SFA). In traditionalmachine learning area, spectral clustering is a clusteringtechnique based on graph theory. The key of this techniqueis to utilize the spectrum, that is, eigenvalues, of thesimilarity matrix to reduce the dimension of the featuresbefore clustering. The similarity matrix is constructed toquantitatively assess the relative similarity of each pairof data/vertices. On the basis of spectral clustering andfeature alignment, SFA is proposed by Pan et al. [106].SFA is an algorithm for sentiment classification. Thisalgorithm tries to identify the domain-specific words anddomain-independent words in different domains, and thenaligns these domain-specific word features to constructa low-dimensional feature representation. SFA generallycontains the following five steps.
1) Feature selection: In this step, feature selectionoperations are performed to select the domain-independent/pivot features. This article presentsthree strategies to select domain-independent fea-tures. These strategies are based on the occurrencefrequency of words, the mutual information betweenfeatures and labels [107], and the mutual informationbetween features and domains, respectively.
2) Similarity matrix construction: Once the domain-specific and the domain-independent features areidentified, a bipartite graph is constructed. Each edgeof this bipartite graph is assigned with a weightthat measures the co-occurrence relationship betweena domain-specific word and a domain-independentword. Based on the bipartite graph, a similarity matrixis then constructed.
3) SFA: In this step, a spectral clustering algorithm isadapted and performed to align domain-specific fea-tures [108], [109]. Specifically, based on the eigen-vectors of the graph Laplacian, a feature alignmentmapping is constructed, and the domain-specific fea-tures are mapped into a low-dimensional featurespace.
4) Feature stacking: The original features and the low-dimensional features are stacked to produce the finalfeature representation.
5) Learner training: The target learner is trainedon the labeled instances with the final featurerepresentation.
There are some other spectral transfer learningapproaches. For example, the work by Ling et al. [110]proposes an approach termed cross-domain spectral clas-sifier (CDSC). The general ideas and steps of this approachare presented as follows.
1) Similarity matrix construction: In the first step, twosimilarity matrices are constructed corresponding tothe whole instances and the target-domain instances,respectively.
2) SFA: An objective function is designed with respect toa graph-partition indicator vector; a constraint matrixis constructed, which contains pair-wise must-linkinformation. Instead of seeking the discrete solutionof the indicator vector, the solution is relaxed tobe continuous, and the eigen-system problem corre-sponding to the objective function is solved to con-struct the aligned spectral features [111].
3) Learner training: A traditional classifier is trained onthe transformed instances.
To be more specific, the objective function has a form ofthe generalized Rayleigh quotient, which aims to find theoptimal graph partition that respects the label informationwith small cut-size [112], to maximize the separation ofthe target-domain instances, and to fit the constraints ofthe pair-wise property. After eigen-decomposition, the lasteigenvectors are selected and combined as a matrix, andthen the matrix is normalized. Each row of the normalizedmatrix represents a transformed instance.
V. M O D E L - B A S E D I N T E R P R E TAT I O NTransfer learning approaches can also be interpreted fromthe model perspective. Fig. 4 shows the correspondingstrategies and the objectives. The main objective of atransfer learning model is to make accurate predictionresults on the target domain, for example, classificationor clustering results. Note that a transfer learning modelmay consist of a few sub-modules such as classifiers,extractors, or encoders. These submodules may play differ-ent roles, for example, feature adaptation or pseudo-labelgeneration. In this section, some related transfer learningapproaches are introduced in proper order according to thestrategies shown in Fig. 4.
A. Model Control Strategy
From the perspective of model, a natural thought isto directly add the model-level that regularizers to thelearner’s objective function. In this way, the knowledgecontained in the preobtained source models can be trans-ferred into the target model during the training process.For example, the article by Duan et al. [113], [114]proposes a general framework termed domain adaptationmachine (DAM), which is designed for multisource transferlearning. The goal of DAM is to construct a robust classifierfor the target domain with the help of some preobtainedbase classifiers that are, respectively, trained on multiple
PROCEEDINGS OF THE IEEE 15
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
Fig. 4. Strategies and objectives of the transfer learning approaches from the model perspective.
source domains. The objective function is given by
minfTLT,L(fT ) + λ1Χ
D(fT ) + λ2Χ(fT )
where the first term represents the loss function usedto minimize the classification error of the labeledtarget-domain instances, the second term denotes differentregularizers, and the third term is used to control thecomplexity of the final decision function fT . Differenttypes of the loss functions can be adopted in LT,L(fT ) suchas the square error or the cross-entropy loss. Some transferlearning approaches can be regarded as the special casesof this framework to some extent.
1) Consensus regularizer: The work by Luo et al. [115]proposes a framework termed consensus regular-ization framework (CRF) [116]. CRF is designedfor multisource transfer learning with no labeledtarget-domain instances. The framework constructsmS classifiers corresponding to each source domain,and these classifiers are required to reach mutualconsensuses on the target domain. The objective func-tion of each source classifier, denoted by fS
k (withk = 1, . . . , mS), is similar to that of DAM, which ispresented as follows:
minfS
k
−nSk�i=1
log P�ySk
i |xSki ; fS
k
�+ λ2Χ
�fS
k
�
+λ1
nT,U�i=1
�yj∈Y
S
�� 1
mS
mS�k0=1
P�yj |xT,U
i ; fSk0
���
where fSk denotes the decision function correspond-
ing to the kth source domain, and S(x) = −x log x.The first term is used to quantify the classificationerror of the kth classifier on the kth source domain,
and the last term is the consensus regularizer in theform of cross-entropy. The consensus regularizer cannot only enhance the agreement of all the classifiersbut also reduce the uncertainty of the predictionson the target domain. The authors implement thisframework based on the logistic regression. A differ-ence between DAM and CRF is that DAM explicitlyconstructs the target classifier, while CRF makes thetarget predictions based on the reached consensusfrom the source classifiers.
2) Domain-dependent regularizer: Fast-DAM is a specificalgorithm of DAM [113]. In light of the manifoldassumption [30] and the graph-based regularizer[117], [118], fast-DAM designs a domain-dependentregularizer. The objective function is given by
minfT
nT,L�j=1
�fT
�xT,L
j
�− yT,L
j
�2
+ λ2Χ(fT )
+λ1
mS�k=1
βk
nT,U�i=1
�fT
�xT,U
i
�− fS
k
�xT,U
i
��2
where fSk (k = 1, 2, . . . , mS) denotes the preob-
tained source decision function for the kth sourcedomain and βk represents the weighting parameterthat is determined by the relevance between thetarget domain and the kth source domain and can bemeasured based on the MMD metric. The third termis the domain-dependent regularizer, which trans-fers the knowledge contained in the source classifiermotivated by domain dependence. Duan et al. [113]also introduced and added a new term to the aboveobjective function based on ε-insensitive loss function[119], which makes the resultant model have highcomputational efficiency.
3) Domain-dependent regularizer + universumregularizer: Univer-DAM is an extension of the
16 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
fast-DAM [114]. Its objective function contains anadditional regularizer, that is, Universum regularizer.This regularizer usually utilizes an additional data settermed Universum where the instances do not belongto either the positive or the negative class [120].The authors treat the source-domain instances as theUniversum for the target domain, and the objectivefunction of Univer-DAM is presented as follows:
minfT
nT,L�j=1
�fT
�xT,L
j
�− yT,L
j
�2
+ λ2
nS�j=1
�fT
�xS
j
��2
+ λ1
mS�k=1
βk
nT,U�i=1
�fT
�xT,U
i
�− fS
k
�xT,U
i
��2
+ λ3Χ(fT ).
Similar to fast-DAM, the ε-insensitive loss functioncan also be utilized [114].
B. Parameter Control Strategy
The parameter control strategy focuses on theparameters of models. For example, in the application ofobject categorization, the knowledge from known sourcecategories can be transferred into target categories viaobject attributes such as shape and color [121]. Theattribute priors, that is, probabilistic distribution parame-ters of the image features corresponding to each attribute,can be learned from the source domain and then used tofacilitate learning the target classifier. The parameters of amodel actually reflect the knowledge learned by the model.Therefore, it is possible to transfer the knowledge at theparametric level.
1) Parameter Sharing: An intuitive way of controllingthe parameters is to directly share the parameters ofthe source learner to the target learner. Parameter shar-ing is widely employed especially in the network-basedapproaches. For example, if we have a neural network forthe source task, we can freeze (or say, share) most of itslayers and only finetune the last few layers to produce atarget network. The network-based approaches are intro-duced in Section V-D.
In addition to network-based parameter sharing, matrix-factorization-based parameter sharing is also workable.For example, Zhuang et al. [122] proposed an approachfor text classification, which is referred to as matrix tri-factorization-based classification framework (MTrick). Theauthors observe that, in different domains, different wordsor phrases sometimes express the same or similar connota-tive meaning. Thus, it is more effective to use the conceptsbehind the words rather than the words themselves asa bridge to transfer the knowledge in source domains.Different from PLSA-based transfer learning approachesthat utilize the concepts by constructing Bayesian net-works, MTrick attempts to find the connections between
the document classes and the concepts conveyed bythe word clusters through matrix tri-factorization. Theseconnections are considered to be the stable knowledgethat is supposed to be transferred. The main idea is todecompose a document-to-word matrix into three matri-ces, that is, document-to-cluster, connection, and cluster-to-word matrices. Specifically, by performing the matrixtri-factorization operations on the source and the targetdocument-to-word matrices, respectively, a joint optimiza-tion problem is constructed, which is given by
minQ,R,W
�XS −QSRW S�2 + λ1�XT −QT RW T�2
+ λ2�QS − QS�2
s.t. normalization constraints
where X denotes the document-to-word matrix, Q denotesthe document-to-cluster matrix, R represents the transfor-mation matrix from document clusters to word clusters,W denotes the cluster-to-word matrix, nd denotes thenumber of the documents, and QS represents the labelmatrix. The matrix QS is constructed based on the classinformation of the source-domain documents. If the ithdocument belongs to the kth class, QS
[i,k] = 1. In the aboveobjective function, the matrix R is actually the sharedparameter. The first term aims to tri-factorize the sourcedocument-to-word matrix, and the second term decom-poses the target document-to-word matrix. The last termincorporates the source-domain label information. Theoptimization problem is solved based on the alternatingiteration method. Once the solution of QT is obtained,the class index of the kth target-domain instance is the onewith the maximum value in the kth row of QT .
Furthermore, Zhuang et al. [123] extended MTrick andproposed an approach termed Triplex Transfer Learn-ing (TriTL). MTrick assumes that the domains share thesimilar concepts behind their word clusters. In contrast,TriTL assumes that the concepts of these domains canbe further divided into three types, that is, domain-independent, transferable domain-specific, and nontrans-ferable domain-specific concepts, which is similar toHIDC. This idea is motivated by dual transfer learning(DTL), where the concepts are assumed to be composedof the domain-independent ones and the transferabledomain-specific ones [124]. The objective function of TriTLis provided as follows:
minQ,R,W
mS+mT�k=1
�������Xk −Qk
�RDI RTD RND
k
����W DI
W TDk
W NDk
����������
2
s.t. normalization constraints
where the definitions of the symbols are similar to thoseof MTrick and the subscript k denotes the index of thedomains with the assumption that the first mS domains
PROCEEDINGS OF THE IEEE 17
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
are the source domains and the last mT domains arethe target domains. The authors proposed an iterativealgorithm to solve the optimization problem. And in theinitialization phase, W DI and W TD
k are initialized based onthe clustering results of the PLSA algorithm, while W UT
k israndomly initialized; the PLSA algorithm is performed onthe combination of the instances from all the domains.
There are some other approaches developed basedon matrix factorization. Wang et al. [125] proposeda transfer learning framework for image classification.Wang et al. [126] proposed a softly associative approachthat integrates two matrix tri-factorizations into a jointframework. Do et al. [127] utilized matrix tri-factorizationto discover both the implicit and the explicit similarities forcross-domain recommendation.
2) Parameter Restriction: Another parameter-control-type strategy is to restrict the parameters. Different fromthe parameter sharing strategy that enforces the modelsshare some parameters, parameter restriction strategy onlyrequires the parameters of the source and the target mod-els to be similar.
Take the approaches to category learning as examples.The category-learning problem is to learn a new decisionfunction for predicting a new category (denoted by the(k + 1)th category) with only limited target-domaininstances and k preobtained binary decision functions.The function of these preobtained decision functionsis to predict which of the k categories an instancebelongs to. In order to solve the category-learning prob-lem, Tommasi and Caputo [128] proposed an approachtermed single-model knowledge transfer (SMKL). SMKL isbased on least-squares SVM (LSS-SVM). The advantage ofLS-SVM is that LS-SVM transforms inequality constraints toequality constraints and has high computational efficiency;its optimization is equivalent to solving a linear equationsystem problem instead of a quadratic programming prob-lem. SMKL selects one of the preobtained binary decisionfunctions and transfers the knowledge contained in itsparameters. The objective function is given by
minf
1
2
������θ − βθ������2 +
λ
2
nT,L�j=1
ηj
�f�xT,L
j
�− yT,L
j
�2
where f(x) = θ · Φ(x) + b, β is the weighting parametercontrolling the transfer degree, θ is the parameter ofa selected preobtained model, and ηj is the coefficientfor resolving the label imbalance problem. The kernelparameter and the tradeoff parameter are chosen basedon cross-validation. In order to find the optimal weight-ing parameter, the authors refer to an earlier work[129]. Cawley [129] proposed a model selection mech-anism for LS-SVM, which is based on the leave-one-outcross-validation method. The superiority of this methodis that the leave-one-out error for each instance can beobtained in a closed form without performing the real
cross-validation experiment. Motivated by Cawley’s work,the generalization error can be easily estimated to guidethe parameter setting in SMKL.
Tommasi et al. [130] further extended SMKL by uti-lizing all the preobtained decision functions. In [130],an approach that is referred to as multimodel knowledgetransfer (MMKL) is proposed. Its objective function ispresented as follows:
minf
1
2
����������θ −
k�i=1
βiθi
����������2
+λ
2
nT,L�j=1
ηj
�f�xT,L
j
�− yT,L
j
�2
where θi and βi are the model parameter and theweighting parameter of the ith preobtained decision func-tion, respectively. The leave-one-out error can also beobtained in a closed form, and the optimal value of βi
(i = 1, 2, . . . , k) is the one that maximizes the generaliza-tion performance.
C. Model Ensemble Strategy
In sentiment analysis applications related to productreviews, data or models from multiple product domainsare available and can be used as the source domains [131].Combining data or models directly into a single domainmay not be successful because the distributions of thesedomains are different from each other. Model ensem-ble is another commonly used strategy. This strategyaims to combine a number of weak classifiers to makethe final predictions. Some previously mentioned transferlearning approaches already adopted this strategy. Forexample, TrAdaBoost and MsTrAdaBoost ensemble theweak classifiers via voting and weighting, respectively.In this section, several typical ensemble-based transferlearning approaches are introduced to help readers bet-ter understand the function and the appliance of thisstrategy.
As mentioned in Section IV-A, TaskTrAdaBoost, whichis an extension of TrAdaBoost for handling multisourcescenarios, is proposed in the article [33]. TaskTrAdaBoostmainly has the following two stages.
1) Candidate classifier construction: In the first stage,a group of candidate classifiers are constructed byperforming AdaBoost on each source domain. Notethat, for each source domain, each iteration ofAdaBoost results in a new weak classifier. In order toavoid the over-fitting problem, the authors introduceda threshold to pick the suitable classifiers into thecandidate group.
2) Classifier selection and ensemble: In the second stage,a revised version of AdaBoost is performed on thetarget-domain instances to construct the final clas-sifier. In each iteration, an optimal candidate classi-fier which has the lowest classification error on thelabeled target-domain instances is picked out andassigned with a weight based on the classification
18 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
error. Then, the weight of each target-domaininstance is updated based on the performance of theselected classifier on the target domain. After the iter-ation process, the selected classifiers are ensembledto produce the final predictions.
The difference between the original AdaBoost and the sec-ond stage of TaskTrAdaBoost is that, in each iteration,the former constructs a new candidate classifier on theweighted target-domain instances, while the latter selectsone preobtained candidate classifier which has the min-imal classification error on the weighted target-domaininstances.
The article by Gao et al. [132] proposes anotherensemble-based framework that is referred to as locallyweighted ensemble (LWE). LWE focuses on the ensem-ble process of various learners; these learners could beconstructed on different source domains, or be built byperforming different learning algorithms on a single sourcedomain. Different from TaskTrAdaBoost that learns theglobal weight of each learner, the authors adopted thelocal-weight strategy, that is, assigning adaptive weightsto the learners based on the local manifold structure ofthe target-domain test set. In LWE, a learner is usuallyassigned with different weights when classifying differenttarget-domain instances. Specifically, the authors adopt agraph-based approach to estimate the weights. The stepsfor weighting are outlined as follows.
1) Graph construction: For the ith source learner, a graphGT
Siis constructed by using the learner to classify
the target-domain instances in the test set; if twoinstances are classified into the same class, they areconnected in the graph. Another graph GT is con-structed for the target-domain instances as well byperforming a clustering algorithm.
2) Learner weighting: The weight of the ith learner forthe jth target-domain instance xT
j is proportional tothe similarity between the instance’s local structuresin GT
Siand GT . And the similarity can be measured
by the percentage of the common neighbors of xTj in
these two graphs.
Note that this weighting scheme is based on theclustering-manifold assumption, that is, if two instancesare close to each other in a high-density region, they oftenhave similar labels. In order to check the validity of thisassumption for the task, the target task is tested on thesource-domain training set(s). Specifically, the clusteringquality of the training set(s) is quantified and checked byusing a metric such as purity or entropy. If the clusteringquality is not satisfactory, uniform weights are assignedto the learners instead. Besides, it is intuitive that if themeasured structure similarity is particularly low for everylearner, weighting and combining these learners seemsunwise. Therefore, the authors introduce a threshold andcompare it to the average similarity. If the similarity islower than the threshold, the label of xT
j is determinedby the voting scheme among its reliable neighbors, where
the reliable neighbors are the ones whose label predictionsare made by the combined classifier.
The above-mentioned TaskTrAdaBoost and LWEapproaches mainly focus on the ensemble process.In contrast, some studies focus more on the constructionof weak learners. For example, ensemble framework ofanchor adapters (ENCHOR) is a weighting ensembleframework proposed by Zhuang et al. [133]. An anchoris a specific instance. Different from TrAdaBoost whichadjusts weights of instances to train and produce anew learner iteratively, ENCHOR constructs a groupof weak learners via using different representations ofthe instances produced by anchors. The thought is thatthe higher similarity between a certain instance and ananchor, the more likely the feature of that instance remainsunchanged relative to the anchor, where the similaritycan be measured by using the cosine or Gaussian distancefunction. ENCHOR contains the following steps.
1) Anchor selection: In this step, a group of anchors areselected. These anchors can be selected based onsome rules or even randomly. In order to improve thefinal performance of ENCHOR, Zhuang et al. [133]proposed a method of selecting high-quality anchors.
2) Anchor-based representation generation: For eachanchor and each instance, the feature vector of aninstance is directly multiplied by a coefficient thatmeasures the distance from the instance to the anchor.In this way, each anchor produces a new pair ofanchor-adapted source and target instance sets.
3) Learner training and ensemble: The obtained pairsof instance sets can be, respectively, used to trainlearners. Then, the resultant learners are weightedand combined to make the final predictions.
The framework ENCHOR is easy to be realized in a parallelmanner in that the operations performed on each anchorare independent.
D. Deep Learning Technique
Deep learning methods are particularly popular in thefield of machine learning. Many researchers utilize thedeep learning techniques to construct transfer learningmodels. For example, the SDA and the mSLDA approachesmentioned in Section IV-B6 utilize the deep learningtechniques. In this section, we specifically discuss the deep-learning-related transfer learning models. The deep learn-ing approaches introduced are divided into two types, thatis, nonadversarial (or say, traditional) ones and adversarialones.
1) Traditional Deep Learning: As said earlier,autoencoders are often used in deep learning area.In addition to SDA and mSLDA, there are some otherreconstruction-based transfer learning approaches.For example, the article by Zhuang et al. [44], [134]proposes an approach termed transfer learning with deepautoencoders (TLDAs). TLDA adopts two autoencodersfor the source and the target domains, respectively.
PROCEEDINGS OF THE IEEE 19
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
These two autoencoders share the same parameters.The encoder and the decoder both have two layers withactivation functions. The diagram of the two autoencodersis presented as follows:
XS (W1,b1)−−−−−→QS (W2,b2)−−−−−−−−−−−→Softmax Regression
RS (W2,b2)−−−−−→QS (W1,b1)−−−−−→XS
⇑KL Divergence
⇓
XT (W1,b1)−−−−−→QT (W2,b2)−−−−−−−−−−−→Softmax Regression
RT (W2,b2)−−−−−→QT (W1,b1)−−−−−→XT .
There are several objectives of TLDA, which are listed asfollows.
1) Reconstruction error minimization: The output of thedecoder should be extremely close to the input ofencoder. In other words, the distance between XS
and XS as well as the distance between XT and XT
should be minimized.2) Distribution adaptation: The distribution difference
between QS and QT should be minimized.3) Regression error minimization: The output of the
encoder on the labeled source-domain instances, thatis, RS, should be consistent with the correspondinglabel information Y S.
Therefore, the objective function of TLDA is given by
minΘLREC(X, X) + λ1KL(QS�QT ) + λ2Χ(W, b, W , b)
+λ3LREG(RS, Y S)
where the first term represents the reconstruction error,the second term KL(·) represents the KL divergence,the third term controls the complexity, and the last termrepresents the regression error. TLDA is trained by usinga gradient descent method. The final predictions can bemade in two different ways. The first way is to directlyuse the output of the encoder to make predictions. Andthe second way is to treat the autoencoder as a featureextractor, and then train the target classifier on the labeledinstances with the feature representation produced by theencoder’s first-layer output.
In addition to the reconstruction-based domainadaptation, discrepancy-based domain adaptation is also apopular direction. In earlier research, the shallow neuralnetworks are tried to learn the domain-independentfeature representation [135]. It is found that the shallowarchitectures often make it difficult for the resultantmodels to achieve excellent performance. Therefore,many studies turn to utilize deep neural networks.Tzeng et al. [136] added a single adaptation layer anda discrepancy loss to the deep neural network, whichimproves the performance. Furthermore, Long et al. [137]performed multilayer adaptation and utilized multikerneltechnique, and they proposed an architecture termed deepadaptation networks (DANs).
For better understanding, let us review DAN in detail.DAN is based on AlexNet [138] and its architecture ispresented as follows [137]:
full−−→6th
RS6
full−−→7th
RS7
full−−→8th
RS8
�f(XS)
�XS
XT
conv−−→1st
QS1
QT1
conv−−→···
QS5
QT5� � !
⇑MK-MMD
⇓⇑
MK-MMD⇓
⇑MK-MMD
⇓
Five Convolutional Layersfull−−→6th
RT6
full−−→7th
RT7
full−−→8th
RT8
�f(XT )
�� � !
Three Fully Connected Layers.
In the above network, the features are first extractedby five convolutional layers in a general-to-specific man-ner. Next, the extracted features are fed into one of thetwo fully connected networks switched by their originaldomains. These two networks consist of three fully con-nected layers that are specialized for the source and thetarget domains. DAN has the following objectives.
1) Classification error minimization: The classificationerror of the labeled instances should be minimized.The cross-entropy loss function is adopted to measurethe prediction error of the labeled instances.
2) Distribution adaptation: Multiple layers, whichinclude the representation layers and the outputlayer, can be jointly adapted in a layer-wise manner.Instead of using the single-kernel MMD to measurethe distribution difference, the authors turn toMK-MMD. Gretton et al. [62] adopt the linear-timeunbiased estimation of MK-MMD to avoid numerousinner product operations.
3) Kernel parameter optimization: The weighting para-meters of the multiple kernels in MK-MMD should beoptimized to maximize the test power [62].
The objective function of the DAN network is given by
minΘ
maxκ
nL�i=1
L�f�xL
i
�, yL
i
�+λ
8�l=6
MK-MMD�RS
l , RTl ; κ
�
where l denotes the index of the layer. The above opti-mization is actually a minimax optimization problem. Themaximization of the objective function with respect to thekernel function κ aims to maximize the test power. Afterthis step, the subtle difference between the source andthe target domains are magnified. This train of thought issimilar to the generative adversarial network (GAN) [139].In the training process, the DAN network is initializedby a pretrained AlexNet [138]. There are two categoriesof parameters that should be learned, that is, the net-work parameters and the weighting parameters of themultiple kernels. Given that the first three convolutionallayers output the general features and are transferable,Yosinski et al. [140] freeze them and finetune the last twoconvolutional layers and the two fully connected layers.
20 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
The last fully connected layer (or say, the classifier layer)is trained from scratch.
Long et al. [141] further extended the above DANapproach and proposed the DAN framework. The newcharacteristics are summarized as follows.
1) Regularizer adding: The framework introduces anadditional regularizer to minimize the uncertainty ofthe predicted labels of the unlabeled target-domaininstances, which is motivated by entropy minimiza-tion criterion [142].
2) Architecture generalizing: The DAN framework canbe applied to many other architectures such asGoogLeNet [143] and ResNet [144].
3) Measurement generalizing: The distribution differencecan be estimated by other metrics. For example,in addition to MK-MMD, Chwialkowski et al. [145]also present the mean embedding test for distributionadaptation.
The objective function of the DAN framework is given by
minΘ
maxκ
nL�i=1
L�f�xL
i
�, yL
i
�+ λ1
lend�l=lstrt
DIST�RS
l , RTl
�
+λ2
nT,U�i=1
�yj∈Y
S�P
�yj |f
�xT,U
i
���
where lstrt and lend denote the boundary indexes of the fullyconnected layers for adapting the distributions.
There are some other impressive works. For example,Long et al. [146] constructed residual transfer networksfor domain adaptation, which is motivated by deep resid-ual learning. Besides, another work by Long et al. [147]proposes the joint adaptation network (JAN), whichadapts the joint distribution difference of multiple lay-ers. Sun and Saenko [148] extended CORAL for deepdomain adaptation and proposed an approach termedDeep CORAL (DCORAL), in which the CORAL loss is addedto minimize the feature covariance. Chen et al. [149]realized that the instances with the same label should beclose to each other in the feature space, and they notonly add the CORAL loss but also add an instance-basedclass-level discrepancy loss. Pan et al. [150] constructedthree prototypical networks (corresponding toDS ,DT , andDS ∪ DT ) and incorporated the thought of multimodelconsensus. They also adopt pseudo-label strategy andadapt both the instance-level and class-level discrepancy.Kang et al. [151] proposed the contrastive adaptation net-work (CAN), which is based on the discrepancy metrictermed contrastive domain discrepancy. Zhu et al. [152]aimed to adapt the extracted multiple feature represen-tations and proposed the multirepresentation adaptationnetwork (MRAN).
Deep learning technique can also be used for mul-tisource transfer learning. For example, the work byZhu et al. [153] proposes a framework that is referred to
as multiple feature spaces adaptation network (MFSAN).The architecture of MFSAN consists of a common-featureextractor, mS domain-specific feature extractors, and mS
domain-specific classifiers. The corresponding schematic isshown as follows:
XS1 · · ·XS
k · · ·XSmS
XT
Common−−−−−→Extractor
QS1 · · ·QS
k · · ·QSmS
QT
Domain-Specific−−−−−−−−−→Extractors
RS1 · · ·RS
k · · ·RSmS
RT1 · · ·RT
k · · ·RTmS
Domain-Specific−−−−−−−−−→Classifiers
Y S1 · · · Y S
k · · · Y SmS
Y T1 · · · Y T
k · · · Y TmS
.
In each iteration, MFSAN has the following steps.
1) Common feature extraction: For each source domain(denoted by DSk with k = 1, . . . , mS), the source-domain instances (denoted by XS
k ) are separatelyinput to the common-feature extractor to produceinstances in a common latent feature space (denotedby QS
k ). Similar operations are also performed onthe target-domain instances (denoted by XT ), whichproduces QT .
2) Specific feature extraction: For each source domain,the extracted common features QS
k is fed to the kthdomain-specific feature extractor. Meanwhile, QT isfed to all the domain-specific feature extractors,which results in RT
k with k = 1, . . . , mS.3) Data classification: The output of the kth
domain-specific feature extractor is input to the kthclassifier. In this way, mS pairs of the classificationresults are predicted in the form of probability.
4) Parameter updating: The parameters of the networkare updated to optimize the objective function.
There are three objectives in MFSAN, that is, classifi-cation error minimization, distribution adaptation, andconsensus regularization. The objective function is givenby
minΘ
mS�i=1
L�Y S
i , Y Si
�+ λ1
mS�i=1
MMD�RS
i , RTi
�
+ λ2
mS�i�=j
���Y Ti − Y T
j
���where the first term represents the classification errorof the labeled source-domain instances, the second termmeasures the distribution difference, and the third termmeasures the discrepancy of the predictions on thetarget-domain instances.
2) Adversarial Deep Learning: The thought of adversariallearning can be integrated into deep-learning-based trans-fer learning approaches. As mentioned above, in the DANframework, the network Θ and the kernel κ play a minimaxgame, which reflects the thought of adversarial learning.However, the DAN framework is a little different from thetraditional GAN-based methods in terms of the adversarialmatching. In the DAN framework, there is only a few
PROCEEDINGS OF THE IEEE 21
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
parameters to be optimized in the max game, which makesthe optimization easier to achieve equilibrium. Beforeintroducing the adversarial transfer learning approaches,let us briefly review the original GAN framework and therelated work.
The original GAN [139], which is inspired by thetwo-player game, is composed of two models, a generatorG and a discriminator D. The generator produces thecounterfeits of the true data for the purpose of confusingthe discriminator and making the discriminator producewrong detection. The discriminator is fed with the mixtureof the true data and the counterfeits, and it aims to detectwhether a data is the true one or the fake one. These twomodels actually play a two-player minimax game, and theobjective function is as follows:
minG
maxD
Ex∼Ptrue [log D(x)] + Ez∼Pz[log (1− D(G(z)))]
where z represents the noise instances (sampled from acertain noise distribution) used as the input of the gener-ator for producing the counterfeits. The entire GAN canbe trained by using the back-propagation algorithm. Whenthe two-player game achieves equilibrium, the generatorcan produce almost true-looking instances.
Motivated by GAN, many transfer learning approachesare established based on the assumption that a goodfeature representation contains almost no discrimina-tive information about the instances’ original domains.For example, the work by Ganin et al. [155] proposesa deep architecture termed domain-adversarial neuralnetwork (DANN) for domain adaptation [154]. DANNassumes that there is no labeled target-domain instance towork with. Its architecture consists of a feature extractor,a label predictor, and a domain classifier. The correspond-ing diagram is as follows.
Label−−−−−→Predictor
Y S,L
Y T,U
XS,L
XT,U
Feature−−−−−→Extractor
↑QS,L
QT,U
"Domain−−−−−→Classifier
S
T(Domain Label).
The feature extractor acts like the generator, which aimsto produce the domain-independent feature representationfor confusing the domain classifier. The domain classi-fier plays the role like the discriminator, which attemptsto detect whether the extracted features come from thesource domain or the target domain. Besides, the labelpredictor produces the label prediction of the instances,which is trained on the extracted features of the labeledsource-domain instances, that is, QS,L. DANN can betrained by inserting a special gradient reversal layer (GRL).After the training of the whole system, the feature extractorlearns the deep feature of the instances, and the outputY T,U is the predicted labels of the unlabeled target-domaininstances.
There are some other related impressive works. Thework by Tzeng et al. [156] proposes a unified adver-sarial domain adaptation framework. The work byShen et al. [59] adopts Wasserstein distance for domainadaptation. Hoffman et al. [157] adopted cycle-consistencyloss to ensure the structural and semantic consistency.Long et al. [158] proposed the conditional domainadversarial network (CDAN), which utilizes a conditionaldomain discriminator to assist adversarial adaptation.Zhang et al. [159] adopted a symmetric design for thesource and the target classifiers. Zhao et al. [160] uti-lized domain adversarial networks to solve the multisourcetransfer learning problem. Yu et al. [161] proposed adynamic adversarial adaptation network.
Some approaches are designed for some specialscenarios. Take the partial transfer learning as an exam-ple. The partial transfer learning approaches are designedfor the scenario that the target-domain classes are lessthan the source-domain classes, that is, YS ⊆ YT .In this case, the source-domain instances with differentlabels may have different importance for domain adap-tation. To be more specific, the source-domain and thetarget-domain instances with the same label are morelikely to be potentially associated. However, since thetarget-domain instances are unlabeled, how to identifyand partially transfer the important information from thelabeled source-domain instances is a critical issue.
The article by Zhang et al. [162] proposes an approachfor partial domain adaptation, which is called impor-tance weighted adversarial nets-based domain adaptation(IWANDA). The architecture of IWANDA is different fromthat of DANN. DANN adopts one common feature extractorbased on the assumption that there exists a commonfeature space where QS,L and QT,U have the similardistribution. However, IWANDA uses two domain-specificfeature extractors for the source and the target domains,respectively. Specifically, IWANDA consists of two featureextractors, two domain classifiers, and one label predictor.The diagram of IWANDA is presented as follows:
Label−−−−−→Predictor
Y S,L
Y T,U
XS,L Source Feature−−−−−−−−→Extractor
↑QS,L
XT,UTarget Feature−−−−−−−−→
ExtractorQT,U
↓
"+βS
−−−−−→+Y T,U
2nd Domain−−−−−−−→Classifier
S2
T2
1st Domain−−−−−−→Classifier
S1
T1
Weight−−−−−→Function
βS
.
Before training, the source feature extractor and the labelpredictor are pretrained on the labeled source-domaininstances. These two components are frozen in the trainingprocess, which means that only the target feature extractorand the domain classifiers should be optimized. In eachiteration, the above network is optimized by taking thefollowing steps.
22 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
1) Instance weighting: In order to solve the partial trans-fer issue, the source-domain instances are assignedwith weights based on the output of the first domainclassifier. The first domain classifier is fed with QS,L
and QT,U , and then outputs the probabilistic predic-tions of their domains. If a source domain instanceis predicted with a high probability of belonging tothe target domain, this instance is highly likely toassociate with the target domain. Thus, this instanceis assigned with a larger weight and vice versa.
2) Prediction making: The label predictor outputs thelabel predictions of the instances. The second classi-fier predicts which domain an instance belongs to.
3) Parameter updating: The first classifier is optimized tominimize the domain classification error. The secondclassifier plays a minimax game with the target fea-ture extractor. This classifier aims to detect whethera instance is the instance from the target domain orthe weighted instance from the source domain, and toreduce the uncertainty of the label prediction Y T,U .The target feature extractor aims to confuse the sec-ond classifier. These components can be optimized ina similar way to GAN or by inserting a GRL.
In addition to IWANDA, the work by Cao et al. [163]constructs the selective adversarial network for par-tial transfer learning. There are some other studiesrelated to transfer learning. For example, the work byWang et al. [164] proposes a minimax-based approach toselect high-quality source-domain data. Chen et al. [165]investigated the transferability and the discriminability inthe adversarial domain adaptation and proposed a spectralpenalization approach to boost the existing adversarialtransfer learning methods.
VI. A P P L I C AT I O NIn previous sections, a number of representative trans-fer learning approaches are introduced, which havebeen applied to solving a variety of text-related/image-related problems in their original articles. For example,MTrick [122] and TriTL [123] utilize the matrix factor-ization technique to solve cross-domain text classificationproblems; the deep-learning-based approaches such asDAN [137], DCORAL [148], and DANN [154], [155] areapplied to solving image classification problems. Insteadof focusing on the general text-related or image-relatedapplications, in this section, we mainly focus on the trans-fer learning applications in specific areas such as medicine,bioinformatics, transportation, and recommender systems.
A. Medical Application
Medical imaging plays an important role in the medicalarea, which is a powerful tool for diagnosis. With thedevelopment of computer technology such as machinelearning, computer-aided diagnosis has become a popularand promising direction. Note that medical images aregenerated by special medical equipment, and their labeling
often relies on experienced doctors. Therefore, in manycases, it is expensive and hard to collect sufficient trainingdata. Transfer learning technology can be utilized for med-ical imaging analysis. A commonly used transfer learningapproach is to pretrain a neural network on the sourcedomain (e.g., ImageNet, which is an image database con-taining more than fourteen million annotated images withmore than 20 000 categories [166]) and then finetune itbased on the instances from the target domain.
For example, Maqsood et al. [167] finetuned theAlexNet [138] for the detection of Alzheimer’s dis-ease. Their approach has the following four steps. First,the MRI images from the target domain are preprocessedby performing contrast stretching operations. Second,the AlexNet architecture [138] is pretrained over Ima-geNet [166] (i.e., the source domain) as a starting pointto learn the new task. Third, the convolutional layersof AlexNet are fixed, and the last three fully connectedlayers are replaced by the new ones including one softmaxlayer, one fully connected layer, and one output layer.Finally, the modified AlexNet is finetuned by training onthe Alzheimer’s data set [168] (i.e., the target domain).The experimental results show that the proposed approachachieves the highest accuracy for the multiclass classifica-tion problem (i.e., Alzheimer’s stage detection).
Similarly, Shin et al. [169] finetuned the pretrained deepneural network for solving the computer-aided detectionproblems. Byra et al. [170] utilized the transfer learningtechnology to help assess knee osteoarthritis. In additionto imaging analysis, transfer learning has some otherapplications in the medical area. For example, the workby Tang et al. [171] combines the active learning and thedomain adaptation technologies for the classification ofvarious medical data. Zeng et al. [172] utilized transferlearning for automatically encoding ICD-9 codes that areused to describe a patient’s diagnosis.
B. Bioinformatics Application
Biological sequence analysis is an important task inthe bioinformatics area. Since the understanding of someorganisms can be transferred to other organisms, trans-fer learning can be applied to facilitate the biologicalsequence analysis. The distribution difference problemexists significantly in this application. For example,the function of some biological substances may remainunchanged but with the composition changed betweentwo organisms, which may result in the marginal dis-tribution difference. Besides, if two organisms have acommon ancestor but with long evolutionary distance,the conditional distribution difference would be signifi-cant. The work by Schweikert et al. [173] uses the mRNAsplice site prediction problem as the example to analyzethe effectiveness of transfer learning approaches. In theirexperiments, the source domain contains the sequenceinstances from a well-studied model organism, that is,Caenorhabditis elegans, and the target organisms include
PROCEEDINGS OF THE IEEE 23
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
two additional nematodes (i.e., Caenorhabditis remaneiand Pristionchus pacificus), Drosophila melanogaster, andthe plant Arabidopsis thaliana. A number of transfer learn-ing approaches, for example, FAM [64] and the variant ofKMM [5], are compared with each other. The experimentalresults show that transfer learning can help improve theclassification performance.
Another widely encountered task in the bioinformaticsarea is gene expression analysis, for example, predict-ing associations between genes and phenotypes. In thisapplication, one of the main challenges is the data spar-sity problem, since there is usually very little data ofthe known associations. Transfer learning can be used toleverage this problem by providing additional informa-tion and knowledge. For example, Petegrosso et al. [174]proposed a transfer learning approach to analyze andpredict the gene–phenotype associations based on thelabel propagation algorithm (LPA) [175]. LPA utilizesthe protein–protein interaction (PPI) network and theinitial labeling to predict the target associations basedon the assumption that the genes that are connectedin the PPI network should have the similar labels. Theauthors extended LPA by incorporating multitask andtransfer-learning technologies. First, human phenotypeontology (HPO), which provides a standardized vocabu-lary of phenotypic features of human diseases, is utilizedto form the auxiliary task. In this way, the associations canbe predicted by utilizing phenotype paths and both thelinkage knowledge in HPO and in the PPI network; theinteracted genes in PPI are more likely to be associatedwith the same phenotype and the connected phenotypesin HPO are more likely to be associated with the samegene. Second, gene ontology (GO), which contains theassociation information between gene functions and genes,is used as the source domain. Additional regularizersare designed, and the PPI network and the commongenes are used as the bridge for knowledge transfer. Thegene-GO term and gene-HPO phenotype associations areconstructed simultaneously for all the genes in the PPI net-work. By transferring additional knowledge, the predictedgene-phenotype associations can be more reliable.
Transfer learning can also be applied to solving the PPIprediction problems. Xu et al. [176] proposed an approachto transfer the linkage knowledge from the source PPInetwork to the target one. The proposed approach is basedon the collective matrix factorization technique [177],where a factor matrix is shared across domains.
C. Transportation Application
One application of transfer learning in the transporta-tion area is to understand the traffic scene images. In thisapplication, a challenge problem is that the images takenfrom a certain location often suffer from variations becauseof different weather and light conditions. In order to solvethis problem, Di et al. [178] proposed an approach thatattempts to transfer the information of the images that
were taken from the same location in different conditions.In the first step, a pretrained network is finetuned toextract the feature representations of images. In the sec-ond step, the feature transformation strategy is adoptedto construct a new feature representation. Specifically,the dimension reduction algorithm (i.e., partial LSs regres-sion [179]) is performed on the extracted features togenerate low-dimension features. Then, a transformationmatrix is learned to minimize the domain discrepancy ofthe dimension-reduced data. Next, the SA operations areadopted to further reduce the domain discrepancy. Notethat, although images under different conditions oftenhave different appearances, they often have the similarlayout structure. Therefore, in the final step, the cross-domain dense correspondences are established betweenthe test image and the retrieved best matching image atfirst, and then the annotations of the best matching imageare transferred to the test image via the Markov randomfield model [180], [181].
Transfer learning can also be applied to the task of driverbehavior modeling. In this task, sufficient personalizeddata of each individual driver are usually unavailable.In such situations, transferring the knowledge containedin the historical data for the newly involved driver isa promising alternative. For example, Lu et al. [182]proposed an approach to driver model adaptation inlane-changing scenarios. The source domain contains thesufficient data describing the behavior of the sourcedrivers, while the target domain has a few numbers ofdata about the target driver. In the first step, the data fromboth domains are preprocessed by performing PCA to gen-erate low-dimension features. The authors assume that thesource and the target data are from two manifolds. There-fore, in the second step, a manifold alignment approach isadopted for domain adaptation. Specifically, the dynamictime warping algorithm [183] is applied to measuringsimilarity and finding the corresponding source-domaindata point of each target-domain data point. Then, localProcrustes analysis [184] is adopted to align the twomanifolds based on the obtained correspondences betweendata points. In this way, the data from the source domaincan be transferred to the target domain. And in the finalstep, a stochastic modeling method (e.g., Gaussian mixtureregression [185]) is used to model the behavior of thetarget driver. The experimental results demonstrate thatthe transfer learning approach can help the target drivereven when few target-domain data are available. Besides,the results also show that when the number of targetinstances are very small or very large, the superiority oftheir approach is not obvious. This may be because therelationship across domains cannot be found exactly withfew target-domain instances, and in the case of sufficienttarget-domain instances, the necessity of transfer learningis reduced.
Besides, there are some other applications of trans-fer learning in the transportation area. For example,Liu et al. [186] applied transfer learning to driver poses
24 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
recognition. Wang et al. [187] adopted the regularizationtechnique in transfer learning for vehicle-type recognition.Transfer learning can also be utilized for anomalous activ-ity detection [188], [189], traffic sign recognition [190],and so on
D. Recommender-System Application
Due to the rapid increase of the amount of information,how to effectively recommend the personalized contentfor individual users is an important issue. In the field ofrecommender systems, some traditional recommendationmethods, for example, factorization-based collaborativefiltering, often rely on the factorization of the user-iteminteraction matrix to obtain the predictive function. Thesemethods often require a large amount of training data tomake accurate recommendations. However, the necessarytraining data, for example, the historical interaction data,are often sparse in real-world scenarios. Besides, for newregistered users or new items, traditional methods areoften hard to make effective recommendations, which isalso known as the cold-start problem.
Recognizing the above-mentioned problems in recom-mender systems, kinds of transfer learning approaches,for example, instance-based and feature-based approacheshave been proposed. These approaches attempt to makeuse of the data from other recommender systems (i.e.,the source domains) to help construct the recommendersystem in the target domain. Instance-based approachesmainly focus on transferring different types of instances,for example, ratings, feedbacks, and examinations, fromthe source domain to the target domain. The work byPan et al. [191] leverages the uncertain ratings (repre-sented as rating distributions) of the source domain forknowledge transfer. Specifically, the source-domain uncer-tain ratings are used as constraints to help complete therating matrix factorization task on the target domain.Hu et al. [192] proposed an approach termed trans-fer meeting hybrid, which extracts the knowledge fromunstructured text by using an attentive memory networkand selectively transfer the useful information.
Feature-based approaches often leverage and transferthe information from a latent feature space. For example,Pan et al. [193] proposed an approach termed coordinatesystem transfer (CST) to leverage both the user-side andthe item-side latent features. The source-domain instancescome from another recommender system, sharing commonusers and items with the target domain. CST is devel-oped based on the assumption that the principle coor-dinates, which reflect the tastes of users or the factorsof items, characterize the domain-independent structureand are transferable across domains. CST first constructstwo principle coordinate systems, which are actually thelatent features of users and items, by applying sparsematrix tri-factorization on the source-domain data, andthen transfer the coordinate systems to the target domainby setting them as constraints. The experimental results
show that CST significantly outperforms the nontransferbaselines (i.e., average filling model and latent factoriza-tion model) in all data sparsity levels [193].
There are some other studies about cross-domain rec-ommendation [194]–[197]. For example, He et al. [198]proposed a transfer learning framework based on theBayesian neural network. Zhu et al. [199] proposed a deepframework, which first generates the user and item featurerepresentations based on the matrix factorization tech-nique, and then employs a deep neural network to learnthe mapping of features across domains. Yuan et al. [200]proposed a deep domain adaptation approach based onautoencoders and a modified DANN [154], [155] to extractand transfer the instances from rating matrices.
E. Other Applications
1) Communication Application: In addition to WiFi local-ization tasks [2], [36], transfer learning has also beenemployed in wireless-network applications. For example,Bastug et al. [201] proposed a caching mechanism; theknowledge contained in contextual information, which isextracted from the interactions between devices, is trans-ferred to the target domain. Besides, some studies focuson the energy saving problems. The work by Li et al. [202]proposes an energy saving scheme for cellular radio accessnetworks, which utilizes the transfer-learning expertise.The work by Zhao and Grace [203] applies transferlearning to topology management for reducing energyconsumption.
2) Urban-Computing Application: With a large amountof data related to our cities, urban-computing is a promis-ing researching track in directions of traffic monitoring,health care, social security, and so on Transfer learn-ing has been applied to alleviate the data scarcity prob-lem in many urban computing applications. For example,Guo et al. [204] proposed an approach for chain store siterecommendation, which leverages the knowledge fromsemantically relevant domains (e.g., other cities with thesame store and other chain stores in the target city) to thetarget city. Wei et al. [205] proposed a flexible multimodaltransfer learning approach that transfers knowledge froma city that have sufficient multimodel data and labels tothe target city to alleviate the data sparsity problem.
Transfer learning has been applied to some recognitiontasks such as hand gesture recognition [206], face recog-nition [207], activity recognition [208], and speech emo-tion recognition [209]. Besides, transfer-learning expertisehas also been incorporated into some other areas suchas sentiment analysis [28], [96], [210], fraud detection[211], social network [212], and hyperspectral imageanalysis [54], [213].
VII. E X P E R I M E N TTransfer learning techniques have been successfullyapplied in many real-world applications. In this section,we perform experiments to evaluate the performance of
PROCEEDINGS OF THE IEEE 25
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
Table 2 Statistical Information of the Preprocessed Data Sets
some representative transfer learning models1 [214] ofdifferent categories on two mainstream research areas,that is, object recognition and text classification. The datasets are introduced at first. Then, the experimental resultsand further analyses are provided.
A. Data Set and Preprocessing
Three data sets are studied in the experiments, thatis, Office-31, Reuters-21578, and Amazon Reviews. Forsimplicity, we focus on the classification tasks. The sta-tistical information of the preprocessed data sets is listedin Table 2.
1) Amazon reviews2 [107]: Is a multidomain sentimentdata set which contains product reviews taken fromAmazon.com of four domains (books, kitchen, elec-tronics, and DVDs). Each review in the four domainshas a text and a rating from zero to five. In theexperiments, the ratios that are less than three aredefined as the negative ones, while others are definedas the positive ones. The frequency of each word inall reviews is calculated. Then, the 5000 words withthe highest frequency are selected as the attributes ofeach review. In this way, we finally have 1000 pos-itive instances, 1000 negative instances, and about5000 unlabeled instances in each domain. In theexperiments, every two of the four domains areselected to generate 12 tasks.
2) Reuters-215783 : Is a data set for text categorization,which has a hierarchical structure. The data set con-tains five top categories (Exchanges, Orgs, People,Places, and Topics). In out experiment, we use thetop three big category Orgs, People, and Places togenerate three classification tasks (Orgs versus Peo-ple, Orgs versus Places, and People versus Places).In each task, the subcategories in the correspond-ing two categories are separately divided into twoparts. Then, the resultant four parts are used as thecomponents to form two domains. Each domain hasabout 1000 instances, and each instance has about4500 features. Specifically, taking the task Orgs versusPeople as an example, one part from Orgs and onepart from People and combined to form the sourcedomain; similarly, the remaining two parts form the
1https://github.com/FuzhenZhuang/Transfer-Learning-Toolkit2http://www.cs.jhu.edu/ mdredze/data sets/sentiment/3https://archive.ics.uci.edu/ml/data sets/Reuters-21578+Text+
Categorization+Collection
target domain. Note that the instances in the threecategories are all labeled. In order to generate theunlabeled instances, the labeled instances are selectedfrom the data set, and their labels are ignored.
3) Office-31 [215]: Is an object recognition data setwhich contains 31 categories and three domains, thatis, Amazon, Webcam, and DSLR. These three domainshave 2817, 498, and 795 instances, respectively. Theimages in Amazon are the online e-commerce picturestaken from Amazon.com. The images in Webcam arethe low-resolution pictures taken by web cameras.And the images in DSLR are the high-resolution pic-tures taken by DSLR cameras. In the experiments,every two of the three domains (with the order con-sidered) are selected as the source and the targetdomains, which results in six tasks.
B. Experiment Setting
Experiments are conducted to compare somerepresentative transfer learning models. Specifically,eight algorithms are performed on the data set Office-31for solving the object recognition problem. Besides,14 algorithms are performed and evaluated on the data setReuters-21578 for solving the text classification problem.In the sentiment classification problem, 11 algorithms areperformed on Amazon Reviews. The classification resultsare evaluated by accuracy, which is defined as follows:
accuracy =|{x|xi ∈ Dtest ∧ f(xi) = yi}|
|Dtest|
where Dtest denotes the test data and y denotes the truthclassification label; f(x) represents the predicted classifi-cation result. Note that some algorithms need the baseclassifier. In these cases, an SVM with a linear kernel isadopted as the base classifier in the experiments. Besides,the source-domain instances are all labeled. And for theperformed algorithms (except TrAdaBoost), the target-domain instances are unlabeled. Each algorithm was exe-cuted three times, and the average results are adopted asour experimental results.
The evaluated transfer learning models include:HIDC [93], TriTL [123], CD-PLSA [91], [92],MTrick [122], SFA [106], mSLDA [98], [99], SDA [96],GFK [102], SCL [94], TCA [36], [78], CoCC [41],JDA [38], TrAdaBoost [31], DAN [137], DCORAL [148],MRAN [152], CDAN [158], DANN [154], [155],JAN [147], and CAN [151].
26 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.
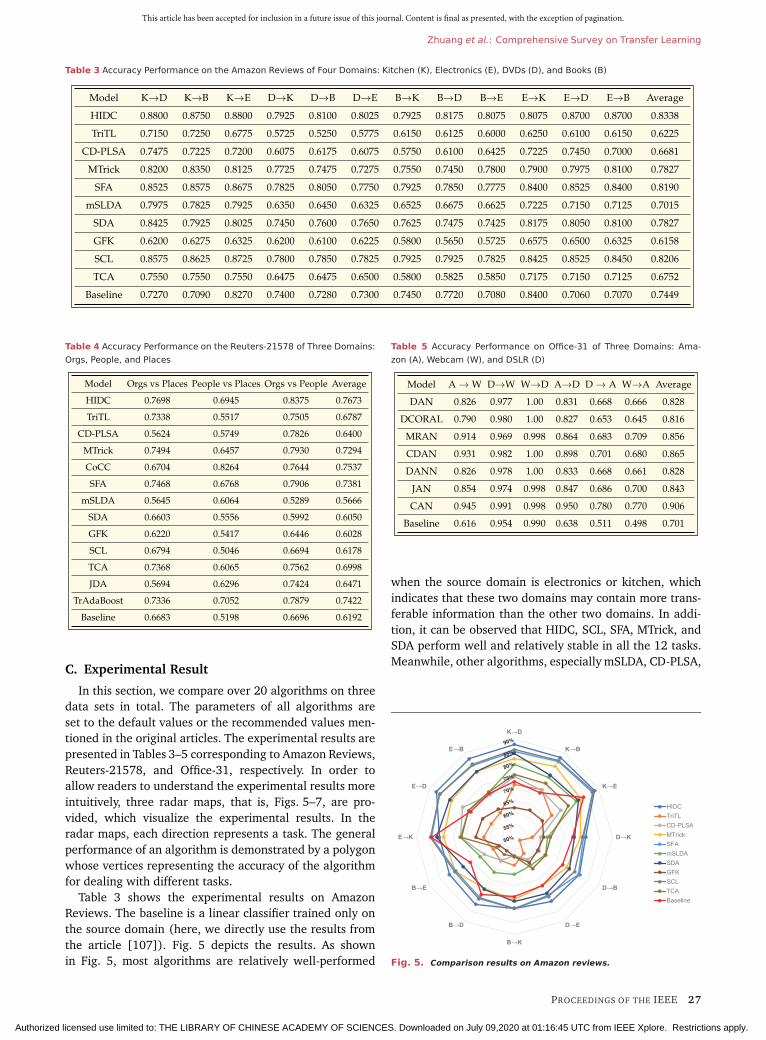
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
Table 3 Accuracy Performance on the Amazon Reviews of Four Domains: Kitchen (K), Electronics (E), DVDs (D), and Books (B)
Table 4 Accuracy Performance on the Reuters-21578 of Three Domains:
Orgs, People, and Places
C. Experimental Result
In this section, we compare over 20 algorithms on threedata sets in total. The parameters of all algorithms areset to the default values or the recommended values men-tioned in the original articles. The experimental results arepresented in Tables 3–5 corresponding to Amazon Reviews,Reuters-21578, and Office-31, respectively. In order toallow readers to understand the experimental results moreintuitively, three radar maps, that is, Figs. 5–7, are pro-vided, which visualize the experimental results. In theradar maps, each direction represents a task. The generalperformance of an algorithm is demonstrated by a polygonwhose vertices representing the accuracy of the algorithmfor dealing with different tasks.
Table 3 shows the experimental results on AmazonReviews. The baseline is a linear classifier trained only onthe source domain (here, we directly use the results fromthe article [107]). Fig. 5 depicts the results. As shownin Fig. 5, most algorithms are relatively well-performed
Table 5 Accuracy Performance on Office-31 of Three Domains: Ama-
zon (A), Webcam (W), and DSLR (D)
when the source domain is electronics or kitchen, whichindicates that these two domains may contain more trans-ferable information than the other two domains. In addi-tion, it can be observed that HIDC, SCL, SFA, MTrick, andSDA perform well and relatively stable in all the 12 tasks.Meanwhile, other algorithms, especially mSLDA, CD-PLSA,
Fig. 5. Comparison results on Amazon reviews.
PROCEEDINGS OF THE IEEE 27
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
Fig. 6. Comparison results on Reuters-21578.
and TriTL, are relatively unstable; the performance of themfluctuates in a range about 20%. TriTL has a relativelyhigh accuracy on the tasks where the source domain iskitchen, but has a relatively low accuracy on other tasks.The algorithms TCA, mSLDA, and CD-PLSA have similarperformance on all the tasks with an accuracy about 70%on average. Among the well-performed algorithms, HIDCand MTrick are based on feature reduction (feature clus-tering), while the others are based on feature encoding(SDA), feature alignment (SFA), and feature selection(SCL). Those strategies are currently the mainstreams offeature-based transfer learning.
Table 4 presents the comparison results on Reuter-21578 (here, we directly use the results of the baselineand CoCC from articles [78] and [41]). The baseline isa regularized LS regression model trained only on thelabeled target domain instances [78]. Fig. 6, which has thesame structure of Fig. 5, visualizes the performance. Forclarity, 13 algorithms are divided into two parts that corre-spond to the two subfigures in Fig. 6. It can be observedthat most algorithms are relatively well-performed forOrgs versus Places and Orgs versus People, but poor forPeople versus Places. This phenomenon indicates that thediscrepancy between People and Places may be relativelylarge. TrAdaBoost has a relatively good performance in thisexperiment because it uses the labels of the instances inthe target domain to reduce the impact of the distributiondifference. Besides, the algorithms HIDC, SFA, and MTrickhave relatively consistent performance in the three tasks.These algorithms are also well-performed in the previousexperiment on Amazon Reviews. In addition, the top twowell-performed algorithms in terms of People versus Placesare CoCC and TrAdaBoost.
In the third experiment, seven deep-learning-basedtransfer learning models (i.e., DAN, DCORAL, MRAN,CDAN, DANN, JAN, and CAN) and the baseline (i.e.,the Alexnet [138], [140] pretrained on ImageNet [166]and then directly trained on the target domain) are per-formed on the data set Office-31 (here, we directly usethe results of CDAN, JAN, CAN, and the baseline fromthe original articles [137], [147], [151], [158]). TheResNet-50 [144] is used as the backbone network for all
these three models. The experimental results are providedin Table 5 and the average performance is visualizedin Fig. 7. As shown in Fig. 7, all of these seven algorithmshave excellent performance, especially on the tasks D→Wand W → D, whose accuracy is very close to 100%. Thisphenomenon reflects the superiority of the deep-learning-based approaches and is consistent with the fact that thedifference between Webcam and DSLR is smaller thanthat between Webcam/DSLR and Amazon. Clearly, CANoutperforms the other six algorithms. In all the six tasks,the performance of DANN is similar to that of DAN, andis better than that of DCORAL, which indicates the effec-tiveness and the practicability of incorporating adversariallearning.
It is worth mentioning that, in the above experiments,the performance of some algorithms is not ideal. Onereason is that we use the default parameter settings pro-vided in the algorithms’ original articles, which may not besuitable for the data set we selected. For example, GFK wasoriginally designed for object recognition, and we directlyadopt it into text classification in the first experiment,
Fig. 7. Comparison results on Office-31.
28 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
which turns out to produce an unsatisfactory result (havingabout 62% accuracy on average). The above experimentalresults are just for reference. These results demonstratethat some algorithms may not be suitable for the data setsof certain domains. Therefore, it is important to choosethe appropriate algorithms as the baselines in the processof research. Besides, in practical applications, it is alsonecessary to find a suitable algorithm.
VIII. C O N C L U S I O N A N D F U T U R ED I R E C T I O NIn this survey article, we have summarized the mechanismsand the strategies of transfer learning from the perspec-tives of data and model. The survey gives the clear def-initions about transfer learning and manages to use aunified symbol system to describe a large number of repre-sentative transfer learning approaches and related works.We have basically introduced the objectives and strategiesin transfer learning based on data-based interpretationand model-based interpretation. Data-based interpretationintroduces the objectives, the strategies, and some transferlearning approaches from the data perspective. Similarly,model-based interpretation introduces the mechanismsand the strategies of transfer learning but from the modellevel. The applications of transfer learning have also beenintroduced. At last, experiments have been conductedto evaluate the performance of representative transferlearning models on two mainstream area, that is, object
recognition and text categorization. The comparisons ofthe models have also been given, which reflects that theselection of the transfer learning model is an importantresearch topic as well as a complex issue in practicalapplications.
Several directions are available for future research inthe transfer learning area. First, transfer learning tech-niques can be further explored and applied to a widerrange of applications. And new approaches are needed tosolve the knowledge transfer problems in more complexscenarios. For example, in real-world scenarios, sometimesthe user-relevant source-domain data comes from anothercompany. In this case, how to transfer the knowledgecontained in the source domain while protecting userprivacy is an important issue. Second, how to measure thetransferability across domains and avoid negative transferis also an important issue. Although there have been somestudies on negative transfer, negative transfer still needsfurther systematic analyses [3]. Third, the interpretabilityof transfer learning also needs to be investigated further[216]. Finally, theoretical studies can be further conductedto provide theoretical support for the effectiveness andapplicability of transfer learning. As a popular and promis-ing area in machine learning, transfer learning shows someadvantages over traditional machine learning such as lessdata dependence and less label dependence. We hope ourwork can help readers have a better understanding of theresearch status and the research ideas.
R E F E R E N C E S[1] D. N. Perkins and G. Salomon, Transfer of
Learning. Oxford, U.K.: Pergamon, 1992.[2] S. Jialin Pan and Q. Yang, “A survey on transfer
learning,” IEEE Trans. Knowl. Data Eng., vol. 22,no. 10, pp. 1345–1359, Oct. 2010.
[3] Z. Wang, Z. Dai, B. Poczos, and J. Carbonell,“Characterizing and avoiding negative transfer,” inProc. IEEE/CVF Conf. Comput. Vis. PatternRecognit., Long Beach, CA, USA, Jun. 2019,pp. 11293–11302.
[4] K. Weiss, T. M. Khoshgoftaar, and D. Wang,“A survey of transfer learning,” J. Big Data, vol. 3,no. 1, Dec. 2016.
[5] J. Huang, A. J. Smola, A. Gretton,K. M. Borgwardt, and B. Schölkopf, “Correctingsample selection bias by unlabeled data,” in Proc.20th Annu. Conf. Neural Inf. Process. Syst.,Vancouver, BC, Canada, Dec. 2006,pp. 601–608.
[6] M. Sugiyama, T. Suzuki, S. Nakajima, H. Kashima,P. von Bünau, and M. Kawanabe, “Directimportance estimation for covariate shiftadaptation,” Ann. Inst. Stat. Math., vol. 60, no. 4,pp. 699–746, Dec. 2008.
[7] O. Day and T. M. Khoshgoftaar, “A survey onheterogeneous transfer learning,” J. Big Data,vol. 4, no. 1, Dec. 2017.
[8] M. E. Taylor and P. Stone, “Transfer learning forreinforcement learning domains: A survey,”J. Mach. Learn. Res., vol. 10, pp. 1633–1685,Jul. 2009.
[9] H. B. Ammar, E. Eaton, J. M. Luna, and P. Ruvolo,“Autonomous cross-domain knowledge transfer inlifelong policy gradient reinforcement learning,”in Proc. 24th Int. Joint Conf. Artif. Intell., BuenosAires, Argentina, Jul. 2015, pp. 3345–3351.
[10] P. Zhao and S. C. H. Hoi, “OTL: A framework ofonline transfer learning,” in Proc. 27th Int. Conf.Mach. Learn., Haifa, Israel, Jun. 2010,pp. 1231–1238.
[11] O. Chapelle, B. Schlkopf, and A. Zien,Semi-Supervised Learning. Cambridge, MA, USA:MIT Press, 2010.
[12] S. Sun, “A survey of multi-view machine learning,”Neural Comput. Appl., vol. 23, nos. 7–8,pp. 2031–2038, Dec. 2013.
[13] C. Xu, D. Tao, and C. Xu, “A survey on multi-viewlearning,” 2013, arXiv:1304.5634. [Online].Available: http://arxiv.org/abs/1304.5634
[14] J. Zhao, X. Xie, X. Xu, and S. Sun, “Multi-viewlearning overview: Recent progress and newchallenges,” Inf. Fusion, vol. 38, pp. 43–54,Nov. 2017.
[15] D. Zhang, J. He, Y. Liu, L. Si, and R. Lawrence,“Multi-view transfer learning with a large marginapproach,” in Proc. 17th ACM SIGKDD Int. Conf.Knowl. Discovery Data Mining, San Diego, CA,USA, 2011, pp. 1208–1216.
[16] P. Yang and W. Gao, “Multi-view discriminanttransfer learning,” in Proc. 23rd Int. Joint Conf.Artif. Intell., Beijing, China, Aug. 2013,pp. 1848–1854.
[17] K. D. Feuz and D. J. Cook, “Collegial activitylearning between heterogeneous sensors,” Knowl.Inf. Syst., vol. 53, no. 2, pp. 337–364, Mar. 2017.
[18] Y. Zhang and Q. Yang, “An overview of multi-tasklearning,” Nat. Sci. Rev., vol. 5, no. 1, pp. 30–43,Jan. 2018.
[19] W. Zhang et al., “Deep model based transfer andmulti-task learning for biological image analysis,”in Proc. 21th ACM SIGKDD Int. Conf. Knowl.Discovery Data Mining, Sydney, NSW, Australia,2015, pp. 1475–1484.
[20] A.-A. Liu, N. Xu, W.-Z. Nie, Y.-T. Su, andY.-D. Zhang, “Multi-domain and multi-tasklearning for human action recognition,” IEEETrans. Image Process., vol. 28, no. 2, pp. 853–867,Feb. 2019.
[21] X. Peng, Z. Huang, X. Sun, and K. Saenko,“Domain agnostic learning with disentangled
representations,” in Proc. 36th Int. Conf. Mach.Learn., Long Beach, CA, USA, Jun. 2019,pp. 5102–5112.
[22] J. Lu, V. Behbood, P. Hao, H. Zuo, S. Xue, andG. Zhang, “Transfer learning using computationalintelligence: A survey,” Knowl.-Based Syst., vol. 80,pp. 14–23, May 2015.
[23] C. Tan, F. Sun, T. Kong, W. Zhang, C. Yang, andC. Liu, “A survey on deep transfer learning,” inProc. 27th Int. Conf. Artif. Neural Netw., Rhodes,Greece, Oct. 2018, pp. 270–279.
[24] M. Wang and W. Deng, “Deep visual domainadaptation: A survey,” Neurocomputing, vol. 312,pp. 135–153, Oct. 2018.
[25] D. Cook, K. D. Feuz, and N. C. Krishnan, “Transferlearning for activity recognition: A survey,” Knowl.Inf. Syst., vol. 36, no. 3, pp. 537–556, Sep. 2013.
[26] L. Shao, F. Zhu, and X. Li, “Transfer learning forvisual categorization: A survey,” IEEE Trans.Neural Netw. Learn. Syst., vol. 26, no. 5,pp. 1019–1034, May 2015.
[27] W. Pan, “A survey of transfer learning forcollaborative recommendation with auxiliarydata,” Neurocomputing, vol. 177, pp. 447–453,Feb. 2016.
[28] R. Liu, Y. Shi, C. Ji, and M. Jia, “A survey ofsentiment analysis based on transfer learning,”IEEE Access, vol. 7, pp. 85401–85412, Jun. 2019.
[29] Q. Sun, R. Chattopadhyay, S. Panchanathan, andJ. Ye, “A two-stage weighting framework formulti-source domain adaptation,” in Proc. 25thAnnu. Conf. Neural Inf. Process. Syst., Granada,Spain, Dec. 2011, pp. 505–513.
[30] M. Belkin, P. Niyogi, and V. Sindhwani, “Manifoldregularization: A geometric framework forlearning from labeled and unlabeled examples,”J. Mach. Learn. Res., vol. 7, pp. 2399–2434,Nov. 2006.
[31] W. Dai, Q. Yang, G.-R. Xue, and Y. Yu, “Boostingfor transfer learning,” in Proc. 24th Int. Conf.
PROCEEDINGS OF THE IEEE 29
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
Mach. Learn., Corvallis, OR, USA, Jun. 2007,pp. 193–200.
[32] Y. Freund and R. E. Schapire, “A decision-theoreticgeneralization of on-line learning and anapplication to boosting,” J. Comput. Syst. Sci.,vol. 55, no. 1, pp. 119–139, Aug. 1997.
[33] Y. Yao and G. Doretto, “Boosting for transferlearning with multiple sources,” in Proc. IEEEComput. Soc. Conf. Comput. Vis. Pattern Recognit.,San Francisco, CA, USA, Jun. 2010,pp. 1855–1862.
[34] J. Jiang and C. Zhai, “Instance weighting fordomain adaptation in NLP,” in Proc. 45th Annu.Meeting Assoc. Comput. Linguistics, Prague, CzechRepublic, Jun. 2007, pp. 264–271.
[35] K. M. Borgwardt, A. Gretton, M. J. Rasch,H.-P. Kriegel, B. Schölkopf, and A. J. Smola,“Integrating structured biological data by kernelmaximum mean discrepancy,” Bioinformatics,vol. 22, no. 14, pp. 49–57, Jul. 2006.
[36] S. J. Pan, I. W. Tsang, J. T. Kwok, and Q. Yang,“Domain adaptation via transfer componentanalysis,” IEEE Trans. Neural Netw., vol. 22, no. 2,pp. 199–210, Feb. 2011.
[37] M. Ghifary, W. B. Kleijn, and M. Zhang, “Domainadaptive neural networks for object recognition,”in Proc. Pacific Rim Int. Conf. Artif. Intell., GoldCoast, QLD, Australia, Dec. 2014, pp. 898–904.
[38] M. Long, J. Wang, G. Ding, J. Sun, and P. S. Yu,“Transfer feature learning with joint distributionadaptation,” in Proc. IEEE Int. Conf. Comput. Vis.,Sydney, NSW, Australia, Dec. 2013,pp. 2200–2207.
[39] M. Long, J. Wang, G. Ding, S. J. Pan, and P. S. Yu,“Adaptation regularization: A general frameworkfor transfer learning,” IEEE Trans. Knowl. DataEng., vol. 26, no. 5, pp. 1076–1089, May 2014.
[40] S. Kullback and R. A. Leibler, “On information andsufficiency,” Ann. Math. Statist., vol. 22, no. 1,pp. 79–86, 1951.
[41] W. Dai, G.-R. Xue, Q. Yang, and Y. Yu,“Co-clustering based classification forout-of-domain documents,” in Proc. 13th ACMSIGKDD Int. Conf. Knowl. Discovery Data Mining,San Jose, CA, USA, 2007, pp. 210–219.
[42] W. Dai, Q. Yang, G.-R. Xue, and Y. Yu, “Self-taughtclustering,” in Proc. 25th Int. Conf. Mach. Learn.,Helsinki, Finland, 2008, pp. 200–207.
[43] J. Davis and P. Domingos, “Deep transfer viasecond-order Markov logic,” in Proc. 26th Annu.Int. Conf. Mach. Learn., Montreal, QC, Canada,Jun. 2009, pp. 217–224.
[44] F. Zhuang, X. Cheng, P. Luo, S. J. Pan, and Q. He,“Supervised representation learning: Transferlearning with deep autoencoders,” in Proc. 24thInt. Joint Conf. Artif. Intell., Buenos Aires,Argentina, Jul. 2015, pp. 4119–4125.
[45] I. Dagan, L. Lee, and F. Pereira, “Similarity-basedmethods for word sense disambiguation,” in Proc.35th Annu. Meeting Assoc. Comput. Linguistics 8thConf. Eur. Chapter Assoc. Comput. Linguistics(ACL/EACL), Madrid, Spain, Jul. 1997, pp. 56–63.
[46] B. Chen, W. Lam, I. Tsang, and T.-L. Wong,“Location and scatter matching for dataset shift intext mining,” in Proc. IEEE Int. Conf. Data Mining,Sydney, NSW, Australia, Dec. 2010, pp. 773–778.
[47] S. Dey, S. Madikeri, and P. Motlicek, “Informationtheoretic clustering for unsuperviseddomain-adaptation,” in Proc. IEEE Int. Conf.Acoust., Speech Signal Process. (ICASSP),Shanghai, China, Mar. 2016, pp. 5580–5584.
[48] W.-H. Chen, P.-C. Cho, and Y.-L. Jiang, “Activityrecognition using transfer learning,” Sens. Mater.,vol. 29, no. 7, pp. 897–904, Jul. 2017.
[49] J. Giles, K. K. Ang, L. S. Mihaylova, andM. Arvaneh, “A subject-to-subject transfer learningframework based on Jensen-Shannon divergencefor improving brain-computer interface,” in Proc.IEEE Int. Conf. Acoust., Speech Signal Process.(ICASSP), Brighton, U.K., May 2019,pp. 3087–3091.
[50] L. M. Bregman, “The relaxation method of findingthe common point of convex sets and itsapplication to the solution of problems in convexprogramming,” USSR Comput. Math. Math. Phys.,
vol. 7, no. 3, pp. 200–217, 1967.[51] S. Si, D. Tao, and B. Geng, “Bregman
divergence-based regularization for transfersubspace learning,” IEEE Trans. Knowl. Data Eng.,vol. 22, no. 7, pp. 929–942, Jul. 2010.
[52] H. Sun, S. Liu, S. Zhou, and H. Zou,“Unsupervised cross-view semantic transfer forremote sensing image classification,” IEEE Geosci.Remote Sens. Lett., vol. 13, no. 1, pp. 13–17,Jan. 2016.
[53] H. Sun, S. Liu, and S. Zhou, “Discriminativesubspace alignment for unsupervised visualdomain adaptation,” Neural Process. Lett., vol. 44,no. 3, pp. 779–793, Dec. 2016.
[54] Q. Shi, Y. Zhang, X. Liu, and K. Zhao, “Regularisedtransfer learning for hyperspectral imageclassification,” IET Comput. Vis., vol. 13, no. 2,pp. 188–193, Mar. 2019.
[55] A. Gretton, O. Bousquet, A. J. Smola, andB. Schölkopf, “Measuring statistical dependencewith Hilbert-Schmidt norms,” in Proc. 18th Int.Conf. Algorithmic Learn. Theory, Singapore,Oct. 2005, pp. 63–77.
[56] H. Wang and Q. Yang, “Transfer learning bystructural analogy,” in Proc. 25th AAAI Conf. Artif.Intell., San Francisco, CA, USA, Aug. 2011,pp. 513–518.
[57] M. Xiao and Y. Guo, “Feature space independentsemi-supervised domain adaptation via kernelmatching,” IEEE Trans. Pattern Anal. Mach. Intell.,vol. 37, no. 1, pp. 54–66, Jan. 2015.
[58] K. Yan, L. Kou, and D. Zhang, “Learningdomain-invariant subspace using domain featuresand independence maximization,” IEEE Trans.Cybern., vol. 48, no. 1, pp. 288–299, Jan. 2018.
[59] J. Shen, Y. Qu, W. Zhang, and Y. Yu, “Wassersteindistance guided representation learning fordomain adaptation,” in Proc. 32nd AAAI Conf.Artif. Intell., New Orleans, FL, USA, Feb. 2018,pp. 4058–4065.
[60] C.-Y. Lee, T. Batra, M. H. Baig, and D. Ulbricht,“Sliced Wasserstein discrepancy for unsuperviseddomain adaptation,” in Proc. IEEE/CVF Conf.Comput. Vis. Pattern Recognit., Long Beach, CA,USA, Jun. 2019, pp. 10285–10295.
[61] W. Zellinger, T. Grubinger, E. Lughofer,T. Natschläger, and S. Saminger-Platz, “Centralmoment discrepancy (CMD) for domain-invariantrepresentation learning,” in Proc. 5th Int. Conf.Learn. Represent., Toulon, France, Apr. 2017,pp. 1–13.
[62] A. Gretton et al., “Optimal kernel choice forlarge-scale two-sample tests,” in Proc. 26th Annu.Conf. Neural Inf. Process. Syst., Lake Tahoe,Dec. 2012, pp. 1205–1213.
[63] H. Yan, Y. Ding, P. Li, Q. Wang, Y. Xu, and W. Zuo,“Mind the class weight bias: Weighted maximummean discrepancy for unsupervised domainadaptation,” in Proc. IEEE Conf. Comput. Vis.Pattern Recognit., Honolulu, HI, USA, Jul. 2017,pp. 2272–2281.
[64] H. Daumé, III, “Frustratingly easy domainadaptation,” in Proc. 45th Annu. Meeting Assoc.Comput. Linguistics, Prague, Czech Republic,Jun. 2007, pp. 256–263.
[65] H. Daumé, III, A. Kumar, and A. Saha,“Co-regularization based semi-supervised domainadaptation,” in Proc. 24th Annu. Conf. Neural Inf.Process. Syst., Vancouver, BC, Canada, Dec. 2010,pp. 478–486.
[66] L. Duan, D. Xu, and I. W. Tsang, “Learning withaugmented features for heterogeneous domainadaptation,” in Proc. 29th Int. Conf. Mach. Learn.,Edinburgh, Scotland, Jun. 2012, pp. 1–8.
[67] W. Li, L. Duan, D. Xu, and I. W. Tsang, “Learningwith augmented features for supervised andsemi-supervised heterogeneous domainadaptation,” IEEE Trans. Pattern Anal. Mach.Intell., vol. 36, no. 6, pp. 1134–1148, Jun. 2014.
[68] K. I. Diamantaras and S. Y. Kung, PrincipalComponent Neural Networks. New York, NY, USA:Wiley, 1996.
[69] B. Schölkopf, A. Smola, and K.-R. Müller,“Nonlinear component analysis as a kerneleigenvalue problem,” Neural Comput., vol. 10,
no. 5, pp. 1299–1319, Jul. 1998.[70] J. Wang, Y. Chen, S. Hao, W. Feng, and Z. Shen,
“Balanced distribution adaptation for transferlearning,” in Proc. IEEE Int. Conf. Data Mining(ICDM), New Orleans, FL, USA, Nov. 2017,pp. 1129–1134.
[71] A. Blum and T. Mitchell, “Combining labeled andunlabeled data with co-training,” in Proc. 11thAnnu. Conf. Comput. Learn. theory, Madison, WI,USA, Jul. 1998, pp. 92–100.
[72] M. Chen, K. Q. Weinberger, and J. C. Blitzer,“Co-training for domain adaptation,” in Proc. 25thAnnu. Conf. Neural Inf. Process. Syst., Granada,Spain, Dec. 2011, pp. 2456–2464.
[73] Z.-H. Zhou and M. Li, “Tri-training: Exploitingunlabeled data using three classifiers,” IEEE Trans.Knowl. Data Eng., vol. 17, no. 11, pp. 1529–1541,Nov. 2005.
[74] K. Saito, Y. Ushiku, and T. Harada, “Asymmetrictri-training for unsupervised domain adaptation,”in Proc. 34th Int. Conf. Mach. Learn., Sydney, NSW,Australia, Aug. 2017, pp. 2988–2997.
[75] S. J. Pan, J. T. Kwok, and Q. Yang, “Transferlearning via dimensionality reduction,” in Proc.23rd AAAI Conf. Artif. Intell., Chicago, IL, USA,Jul. 2008, pp. 677–682.
[76] K. Q. Weinberger, F. Sha, and L. K. Saul, “Learninga kernel matrix for nonlinear dimensionalityreduction,” in Proc. 21st Int. Conf. Mach. Learn.,Banff, AB, Canada, Jul. 2004, pp. 106–113.
[77] L. Vandenberghe and S. Boyd, “Semidefiniteprogramming,” SIAM Rev., vol. 38, no. 1,pp. 49–95, Mar. 1996.
[78] S. J. Pan, I. W. Tsang, J. T. Kwok, and Q. Yang,“Domain adaptation via transfer componentanalysis,” in Proc. 21st Int. Joint Conf. Artif. Intell.,Pasadena, CA, USA, Jul. 2009, pp. 1187–1192.
[79] C.-A. Hou, Y.-H.-H. Tsai, Y.-R. Yeh, andY.-C.-F. Wang, “Unsupervised domain adaptationwith label and structural consistency,” IEEE Trans.Image Process., vol. 25, no. 12, pp. 5552–5562,Dec. 2016.
[80] J. Tahmoresnezhad and S. Hashemi, “Visualdomain adaptation via transfer feature learning,”Knowl. Inf. Syst., vol. 50, no. 2, pp. 585–605,Feb. 2017.
[81] J. Zhang, W. Li, and P. Ogunbona, “Jointgeometrical and statistical alignment for visualdomain adaptation,” in Proc. IEEE Conf. Comput.Vis. Pattern Recognit., Honolulu, HI, USA,Jul. 2017, pp. 5150–5158.
[82] B. Schölkopf, R. Herbrich, and A. J. Smola,“A generalized representer theorem,” in Proc. Int.Conf. Comput. Learn. Theory, Amsterdam, TheNetherlands, Jul. 2001, pp. 416–426.
[83] L. Duan, I. W. Tsang, and D. Xu, “Domain transfermultiple kernel learning,” IEEE Trans. PatternAnal. Mach. Intell., vol. 34, no. 3, pp. 465–479,Mar. 2012.
[84] A. Rakotomamonjy, F. Bach, S. Canu, andY. Grandvalet, “SimpleMKL,” J. Mach. Learn. Res.,vol. 9, pp. 2491–2521, Nov. 2008.
[85] I. S. Dhillon, S. Mallela, and D. S. Modha,“Information-theoretic co-clustering,” in Proc. 9thACM SIGKDD Int. Conf. Knowl. Discovery DataMining, Washington, DC, USA, Aug. 2003,pp. 89–98.
[86] S. Deerwester, S. T. Dumais, G. W. Furnas,T. K. Landauer, and R. Harshman, “Indexing bylatent semantic analysis,” J. Amer. Soc. Inf. Sci.,vol. 41, no. 6, pp. 391–407, Sep. 1990.
[87] T. Hofmann, “Probabilistic latent semanticanalysis,” in Proc. 15th Conf. Uncertainty Artif.Intell., Stockholm, Sweden, Jul. 1999,pp. 289–296.
[88] J. Yoo and S. Choi, “Probabilistic matrixtri-factorization,” in Proc. IEEE Int. Conf. Acoust.,Speech Signal Process., Taipei, Taiwan, Apr. 2009,pp. 1553–1556.
[89] A. P. Dempster, N. M. Laird, and D. B. Rubin,“Maximum likelihood from incomplete data viathe EM algorithm,” J. Roy. Statist. Soc. B,Methodol., vol. 39, no. 1, pp. 1–38, 1977.
[90] G.-R. Xue, W. Dai, Q. Yang, and Y. Yu,“Topic-bridged PLSA for cross-domain text
30 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
classification,” in Proc. 31st Annu. Int. ACM SIGIRConf. Res. Develop. Inf. Retr., Singapore, Jul. 2008,pp. 627–634.
[91] F. Zhuang et al., “Collaborative dual-PLSA: Miningdistinction and commonality across multipledomains for text classification,” in Proc. 19th ACMInt. Conf. Inf. Knowl. Manage., Toronto, ON,Canada, Oct. 2010, pp. 359–368.
[92] F. Zhuang et al., “Mining distinction andcommonality across multiple domains usinggenerative model for text classification,” IEEETrans. Knowl. Data Eng., vol. 24, no. 11,pp. 2025–2039, Nov. 2012.
[93] F. Zhuang, P. Luo, P. Yin, Q. He, and Z. Shi,“Concept learning for cross-domain textclassification: A general probabilistic framework,”in Proc. 23rd Int. Joint Conf. Artif. Intell., Beijing,China, Aug. 2013, pp. 1960–1966.
[94] J. Blitzer, R. McDonald, and F. Pereira, “Domainadaptation with structural correspondencelearning,” in Proc. Conf. Empirical Methods NaturalLang. Process., Sydney, NSW, Australia, Jul. 2006,pp. 120–128.
[95] R. K. Ando and T. Zhang, “A framework forlearning predictive structures from multiple tasksand unlabeled data,” J. Mach. Learn. Res., vol. 6,pp. 1817–1853, Nov. 2005.
[96] X. Glorot, A. Bordes, and Y. Bengio, “Domainadaptation for large-scale sentiment classification:A deep learning approach,” in Proc. 28th Int. Conf.Mach. Learn., Bellevue, WA, USA, Jun. 2011,pp. 513–520.
[97] P. Vincent, H. Larochelle, Y. Bengio, andP.-A. Manzagol, “Extracting and composing robustfeatures with denoising autoencoders,” in Proc.25th Int. Conf. Mach. Learn., Helsinki, Finland,Jul. 2008, pp. 1096–1103.
[98] M. Chen, Z. Xu, K. Weinberger, and F. Sha,“Marginalized denoising autoencoders for domainadaptation,” in Proc. 29th Int. Conf. Mach. Learn.,Edinburgh, Scotland, Jun. 2012, pp. 767–774.
[99] M. Chen, K. Q. Weinberger, Z. E. Xu, and F. Sha,“Marginalizing stacked linear denoisingautoencoders,” J. Mach. Learn. Res., vol. 16,no. 12, pp. 3849–3875, 2015.
[100] B. Fernando, A. Habrard, M. Sebban, andT. Tuytelaars, “Unsupervised visual domainadaptation using subspace alignment,” in Proc.IEEE Int. Conf. Comput. Vis., Sydney, NSW,Australia, Dec. 2013, pp. 2960–2967.
[101] B. Sun and K. Saenko, “Subspace distributionalignment for unsupervised domain adaptation,”in Proc. Brit. Mach. Vis. Conf., Swansea, U.K.,Sep. 2015, pp. 24.1–24.10.
[102] B. Gong, Y. Shi, F. Sha, and K. Grauman, “Geodesicflow kernel for unsupervised domain adaptation,”in Proc. IEEE Conf. Comput. Vis. Pattern Recognit.,Providence, RI, USA, Jun. 2012, pp. 2066–2073.
[103] R. Gopalan, R. Li, and R. Chellappa, “Domainadaptation for object recognition: Anunsupervised approach,” in Proc. Int. Conf.Comput. Vis., Nov. 2011, pp. 999–1006.
[104] M. I. Zelikin, Control Theory and Optimization I(Encyclopaedia of Mathematical Sciences),vol. 86. Berlin, Germany: Springer, 2000.
[105] B. Sun, J. Feng, and K. Saenko, “Return offrustratingly easy domain adaptation,” in Proc.30th AAAI Conf. Artif. Intell., Phoenix, AZ, USA,Feb. 2016, pp. 2058–2065.
[106] S. J. Pan, X. Ni, J.-T. Sun, Q. Yang, and Z. Chen,“Cross-domain sentiment classification via spectralfeature alignment,” in Proc. 19th Int. Conf. WorldWide Web, Raleigh, North Carolina, Apr. 2010,pp. 751–760.
[107] J. Blitzer, M. Dredze, and F. Pereira, “Biographies,bollywood, boom-boxes and blenders: Domainadaptation for sentiment classification,” in Proc.45th Annu. Meeting Assoc. Comput. Linguistics,Prague, Czech Republic, Jun. 2007, pp. 440–447.
[108] F. R. K. Chung, Spectral Graph Theory. Providence,RI, USA: AMS, 1997.
[109] A. Y. Ng, M. I. Jordan, and Y. Weiss, “On spectralclustering: Analysis and an algorithm,” in Proc.15th Annu. Conf. Neural Inf. Process. Syst.,Vancouver, BC, Canada, Dec. 2001, pp. 849–856.
[110] X. Ling, W. Dai, G.-R. Xue, Q. Yang, and Y. Yu,“Spectral domain-transfer learning,” in Proc. 14thACM SIGKDD Int. Conf. Knowl. Discovery DataMining, Las Vegas, NV, USA, Aug. 2008,pp. 488–496.
[111] S. D. Kamvar, D. Klein, and C. D. Manning,“Spectral learning,” in Proc. 18th Int. Joint Conf.Artif. Intell., Acapulco, Aug. 2003, pp. 561–566.
[112] J. Shi and J. Malik, “Normalized cuts and imagesegmentation,” IEEE Trans. Pattern Anal. Mach.Intell., vol. 22, no. 8, pp. 888–905, Aug. 2000.
[113] L. Duan, I. W. Tsang, D. Xu, and T.-S. Chua,“Domain adaptation from multiple sources viaauxiliary classifiers,” in Proc. 26th Int. Conf. Mach.Learn., Montreal, QC, Canada, Jun. 2009,pp. 289–296.
[114] L. Duan, D. Xu, and I. W. Tsang, “Domainadaptation from multiple sources:A domain-dependent regularization approach,”IEEE Trans. Neural Netw. Learn. Syst., vol. 23no. 3, pp. 504–518, Mar. 2012.
[115] P. Luo, F. Zhuang, H. Xiong, Y. Xiong, and Q. He,“Transfer learning from multiple source domainsvia consensus regularization,” in Proc. 17th ACMConf. Inf. Knowl. Manage., Napa Valley, CA, USA,Oct. 2008, pp. 103–112.
[116] F. Zhuang, P. Luo, H. Xiong, Y. Xiong, Q. He, andZ. Shi, “Cross-domain learning from multiplesources: A consensus regularization perspective,”IEEE Trans. Knowl. Data Eng., vol. 22, no. 12,pp. 1664–1678, Dec. 2010.
[117] T. Evgeniou, C. A. Micchelli, and M. Pontil,“Learning multiple tasks with kernel methods,”J. Mach. Learn. Res., vol. 6, pp. 615–637,Apr. 2005.
[118] T. Kato, H. Kashima, M. Sugiyama, and K. Asai,“Multi-task learning via conic programming,” inProc. 21st Annu. Conf. Neural Inf. Process. Syst.,Vancouver, BC, Canada, Dec. 2007, pp. 737–744.
[119] A. J. Smola and B. Schölkopf, “A tutorial onsupport vector regression,” Statist. Comput.,vol. 14, no. 3, pp. 199–222, Aug. 2004.
[120] J. Weston, R. Collobert, F. Sinz, L. Bottou, andV. Vapnik, “Inference with the Universum,” in Proc.23rd Int. Conf. Mach. Learn., Pittsburgh, PA, USA,Jun. 2006, pp. 1009–1016.
[121] X. Yu and Y. Aloimonos, “Attribute-based transferlearning for object categorization with zero/onetraining example,” in Proc. Eur. Conf. Comput. Vis.,Heraklion, Greece, Sep. 2010, pp. 127–140.
[122] F. Zhuang, P. Luo, H. Xiong, Q. He, Y. Xiong, andZ. Shi, “Exploiting associations between wordclusters and document classes for cross-domaintext categorization,” Stat. Anal. Data Min., vol. 4,no. 1, pp. 100–114, Feb. 2011.
[123] F. Zhuang, P. Luo, C. Du, Q. He, Z. Shi, andH. Xiong, “Triplex transfer learning: Exploitingboth shared and distinct concepts for textclassification,” IEEE Trans. Cybern., vol. 44, no. 7,pp. 1191–1203, Jul. 2014.
[124] M. Long, J. Wang, G. Ding, W. Cheng, X. Zhang,and W. Wang, “Dual transfer learning,” in Proc.12th SIAM Int. Conf. Data Mining, Anaheim, CA,USA, Apr. 2012, pp. 540–551.
[125] H. Wang, F. Nie, H. Huang, and C. Ding, “Dyadictransfer learning for cross-domain imageclassification,” in Proc. Int. Conf. Comput. Vis.,Barcelona, Spain, Nov. 2011, pp. 551–556.
[126] D. Wang et al., “Softly associative transferlearning for cross-domain classification,” IEEETrans. Cybern., early access, Jan. 2019, doi:10.1109/TCYB.2019.2891577.
[127] Q. Do, W. Liu, J. Fan, and D. Tao, “Unveilinghidden implicit similarities for cross-domainrecommendation,” IEEE Trans. Knowl. Data Eng.,early access, Jun. 2019, doi:10.1109/TKDE.2019.2923904.
[128] T. Tommasi and B. Caputo, “The more you know,the less you learn: From knowledge transfer toone-shot learning of object categories,” in Proc.Brit. Mach. Vis. Conf., London, U.K., Sep. 2009,pp. 80.1–80.11.
[129] G. C. Cawley, “Leave-one-out cross-validationbased model selection criteria for weightedLS-SVMs,” in Proc. IEEE Int. Joint Conf. Neural
Netw., Vancouver, BC, Canada, Jul. 2006,pp. 1661–1668.
[130] T. Tommasi, F. Orabona, and B. Caputo, “Safety innumbers: Learning categories from few exampleswith multi model knowledge transfer,” in Proc.IEEE Comput. Soc. Conf. Comput. Vis. PatternRecognit., San Francisco, CA, USA, Jun. 2010,pp. 3081–3088.
[131] C.-K. Lin, Y.-Y. Lee, C.-H. Yu, and H.-H. Chen,“Exploring ensemble of models in taxonomy-basedcross-domain sentiment classification,” in Proc.23rd ACM Int. Conf. Inf. Knowl. Manage.,Shanghai, China, Nov. 2014, pp. 1279–1288.
[132] J. Gao, W. Fan, J. Jiang, and J. Han, “Knowledgetransfer via multiple model local structuremapping,” in Proc. 14th ACM SIGKDD Int. Conf.Knowl. Discovery Data Mining, Las Vegas, NV, USA,Aug. 2008, pp. 283–291.
[133] F. Zhuang, P. Luo, S. J. Pan, H. Xiong, and Q. He,“Ensemble of anchor adapters for transferlearning,” in Proc. 25th ACM Int. Conf. Inf. Knowl.Manage., Indianapolis, IN, USA, Oct. 2016,pp. 2335–2340.
[134] F. Zhuang, X. Cheng, P. Luo, S. J. Pan, and Q. He,“Supervised representation learning with doubleencoding-layer autoencoder for transfer learning,”ACM Trans. Intell. Syst. Technol., vol. 9, no. 2,pp. 1–17, Jan. 2018.
[135] M. Ghifary, W. B. Kleijn, and M. Zhang, “Domainadaptive neural networks for object recognition,”in Proc. 13th Pacific Rim Int. Conf. Artif. Intell.,Gold Coast, QLD, Australia, Dec. 2014,pp. 898–904.
[136] E. Tzeng, J. Hoffman, N. Zhang, K. Saenko, andT. Darrell, “Deep domain confusion: Maximizingfor domain invariance,” 2014, arXiv:1412.3474.[Online]. Available:http://arxiv.org/abs/1412.3474
[137] M. Long, Y. Cao, J. Wang, and M. I. Jordan,“Learning transferable features with deepadaptation networks,” in Proc. 32nd Int. Conf.Mach. Learn., Lille, France, Jul. 2015, pp. 97–105.
[138] A. Krizhevsky, I. Sutskever, and G. E. Hinton,“Imagenet classification with deep convolutionalneural networks,” in Proc. 26th Annu. Conf. NeuralInf. Process. Syst., Lake Tahoe, NV, USA, Dec. 2012,pp. 1097–1105.
[139] I. Goodfellow et al., “Generative adversarial nets,”in Proc. 28th Annu. Conf. Neural Inf. Process. Syst.,Montreal, QC, Canada, Dec. 2014,pp. 2672–2680.
[140] J. Yosinski, J. Clune, Y. Bengio, and H. Lipson,“How transferable are features in deep neuralnetworks?” in Proc. 28th Annu. Conf. Neural Inf.Process. Syst., Montreal, QC, Canada, Dec. 2014,pp. 3320–3328.
[141] M. Long, Y. Cao, Z. Cao, J. Wang, andM. I. Jordan, “Transferable representationlearning with deep adaptation networks,” IEEETrans. Pattern Anal. Mach. Intell., vol. 41, no. 12,pp. 3071–3085, Dec. 2019, doi:10.1109/TPAMI.2018.2868685.
[142] Y. Grandvalet and Y. Bengio, “Semi-supervisedlearning by entropy minimization,” in Proc. 18thAnnu. Conf. Neural Inf. Process. Syst., Vancouver,BC, Canada, Dec. 2004, pp. 529–536.
[143] C. Szegedy et al., “Going deeper withconvolutions,” in Proc. IEEE Conf. Comput. Vis.Pattern Recognit., Boston, MA, USA, Jun. 2015,pp. 1–9.
[144] K. He, X. Zhang, S. Ren, and J. Sun, “Deepresidual learning for image recognition,” in Proc.IEEE Conf. Comput. Vis. Pattern Recognit.,Las Vegas, NV, USA, Jun. 2016, pp. 770–778.
[145] K. P. Chwialkowski, A. Ramdas, D. Sejdinovic, andA. Gretton, “Fast two-sample testing with analyticrepresentations of probability measures,” in Proc.29th Annu. Conf. Neural Inf. Process. Syst.,Montreal, QC, Canada, Dec. 2015,pp. 1981–1989.
[146] M. Long, H. Zhu, J. Wang, and M. I. Jordan,“Unsupervised domain adaptation with residualtransfer networks,” in Proc. 30th Annu. Conf.Neural Inf. Process. Syst., Barcelona, Spain,Dec. 2016, pp. 136–144.
PROCEEDINGS OF THE IEEE 31
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
[147] M. Long, H. Zhu, J. Wang, and M. I. Jordan, “Deeptransfer learning with joint adaptation networks,”in Proc. 34th Int. Conf. Mach. Learn., Sydney, NSW,Australia, Aug. 2017, pp. 2208–2217.
[148] B. Sun and K. Saenko, “Deep CORAL: Correlationalignment for deep domain adaptation,” in Proc.Eur. Conf. Comput. Vis. Workshops, Amsterdam,The Netherlands, Oct. 2016, pp. 443–450.
[149] C. Chen, Z. Chen, B. Jiang, and X. Jin, “Jointdomain alignment and discriminative featurelearning for unsupervised deep domainadaptation,” in Proc. 33rd AAAI Conf. Artif. Intell.,Honolulu, HI, USA, Jan. 2019, pp. 3296–3303.
[150] Y. Pan, T. Yao, Y. Li, Y. Wang, C.-W. Ngo, andT. Mei, “Transferrable prototypical networks forunsupervised domain adaptation,” in Proc.IEEE/CVF Conf. Comput. Vis. Pattern Recognit.,Long Beach, CA, USA, Jun. 2019, pp. 2239–2247.
[151] G. Kang, L. Jiang, Y. Yang, and A. G. Hauptmann,“Contrastive adaptation network for unsuperviseddomain adaptation,” in Proc. IEEE/CVF Conf.Comput. Vis. Pattern Recognit., Long Beach, CA,USA, Jun. 2019, pp. 4893–4902.
[152] Y. Zhu et al., “Multi-representation adaptationnetwork for cross-domain image classification,”Neural Netw., vol. 119, pp. 214–221, Nov. 2019.
[153] Y. Zhu, F. Zhuang, and D. Wang, “Aligningdomain-specific distribution and classifier forcross-domain classification from multiplesources,” in Proc. 33rd AAAI Conf. Artif. Intell.,Honolulu, HI, USA, Jan. 2019, pp. 5989–5996.
[154] Y. Ganin and V. Lempitsky, “Unsupervised domainadaptation by backpropagation,” in Proc. 32nd Int.Conf. Mach. Learn., Lille, France, Jul. 2015,pp. 1180–1189.
[155] Y. Ganin et al., “Domain-adversarial training ofneural networks,” J. Mach. Learn. Res., vol. 17,pp. 1–35, Apr. 2016.
[156] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell,“Adversarial discriminative domain adaptation,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit.,Honolulu, HI, USA, Jul. 2017, pp. 2962–2971.
[157] J. Hoffman et al., “CyCADA: Cycle-consistentadversarial domain adaptation,” in Proc. 35th Int.Conf. Mach. Learn., Stockholm, Sweden, Jul. 2018,pp. 1994–2003.
[158] M. Long, Z. Cao, J. Wang, and M. I. Jordan,“Conditional adversarial domain adaptation,” inProc. 32nd Annu. Conf. Neural Inf. Process. Syst.,Montreal, QC, Canada, Dec. 2018,pp. 1640–1650.
[159] Y. Zhang, H. Tang, K. Jia, and M. Tan,“Domain-symmetric networks for adversarialdomain adaptation,” in Proc. IEEE Conf. Comput.Vis. Pattern Recognit., Long Beach, CA, USA,Jun. 2019, pp. 5031–5040.
[160] H. Zhao, S. Zhang, G. Wu, J. M. F. Moura,J. P. Costeira, and G. J. Gordon, “Adversarialmultiple source domain adaptation,” in Proc. 32ndAnnu. Conf. Neural Inf. Process. Syst., Montreal,QC, Canada, Dec. 2018, pp. 8559–8570.
[161] C. Yu, J. Wang, Y. Chen, and M. Huang, “Transferlearning with dynamic adversarial adaptationnetwork,” in Proc. IEEE Int. Conf. Data Mining,Beijing, China, Nov. 2019, pp. 1–9.
[162] J. Zhang, Z. Ding, W. Li, and P. Ogunbona,“Importance weighted adversarial nets for partialdomain adaptation,” in Proc. IEEE/CVF Conf.Comput. Vis. Pattern Recognit., Salt Lake City, UT,USA, Jun. 2018, pp. 8156–8163.
[163] Z. Cao, M. Long, J. Wang, and M. I. Jordan,“Partial transfer learning with selective adversarialnetworks,” in Proc. IEEE/CVF Conf. Comput. Vis.Pattern Recognit., Salt Lake City, UT, USA,Jun. 2018, pp. 2724–2732.
[164] B. Wang et al., “A minimax game for instancebased selective transfer learning,” in Proc. 25thACM SIGKDD Int. Conf. Knowl. Discovery DataMining, Anchorage, AK, USA, Jul. 2019,pp. 34–43.
[165] X. Chen, S. Wang, M. Long, and J. Wang,“Transferability vs. discriminability: Batch spectralpenalization for adversarial domain adaptation,”in Proc. 36th Int. Conf. Mach. Learn., Long Beach,CA, USA, Jun. 2019, pp. 1081–1090.
[166] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, andL. Fei-Fei, “ImageNet: A large-scale hierarchicalimage database,” in Proc. IEEE Conf. Comput. Vis.Pattern Recognit., Miami, FL, USA, Jun. 2009,pp. 248–255.
[167] M. Maqsood et al., “Transfer learning assistedclassification and detection of Alzheimer’s diseasestages using 3D MRI scans,” Sensors, vol. 19,no. 11, pp. 1–19, Jun. 2019.
[168] D. S. Marcus, A. F. Fotenos, J. G. Csernansky,J. C. Morris, and R. L. Buckner, “Open accessseries of imaging studies: Longitudinal MRI datain nondemented and demented older adults,”J. Cognit. Neurosci., vol. 22, no. 12,pp. 2677–2684, Dec. 2010.
[169] H.-C. Shin et al., “Deep convolutional neuralnetworks for computer-aided detection: CNNarchitectures, dataset characteristics and transferlearning,” IEEE Trans. Med. Imag., vol. 35, no. 5,pp. 1285–1298, May 2016.
[170] M. Byra et al., “Knee menisci segmentation andrelaxometry of 3D ultrashort echo time cones MRimaging using attention U-net with transferlearning,” Magn. Reson. Med., vol. 83, no. 3,pp. 1109–1122, Sep. 2020, doi:10.1002/mrm.27969.
[171] X. Tang, B. Du, J. Huang, Z. Wang, and L. Zhang,“On combining active and transfer learning formedical data classification,” IET Comput. Vis.,vol. 13, no. 2, pp. 194–205, Mar. 2019.
[172] M. Zeng, M. Li, Z. Fei, Y. Yu, Y. Pan, and J. Wang,“Automatic ICD-9 coding via deep transferlearning,” Neurocomputing, vol. 324, pp. 43–50,Jan. 2019.
[173] G. Schweikert, G. Ratsch, C. Widmer, andB. Scholkopf, “An empirical analysis of domainadaptation algorithms for genomic sequenceanalysis,” in Proc. 22nd Annu. Conf. Neural Inf.Process. Syst., Vancouver, BC, Canada, Dec. 2008,pp. 1433–1440.
[174] R. Petegrosso, S. Park, T. H. Hwang, and R. Kuang,“Transfer learning across ontologies forphenome–genome association prediction,”Bioinformatics, vol. 33, no. 4, pp. 529–536,Feb. 2017.
[175] T. Hwang and R. Kuang, “A heterogeneous labelpropagation algorithm for disease gene discovery,”in Proc. 10th SIAM Int. Conf. Data Mining,Columbus, OH, USA, Apr. 2010, pp. 583–594.
[176] Q. Xu, E. W. Xiang, and Q. Yang, “Protein-proteininteraction prediction via collective matrixfactorization,” in Proc. IEEE Int. Conf. Bioinf.Biomed., Hong Kong, Dec. 2010, pp. 62–67.
[177] A. P. Singh and G. J. Gordon, “Relational learningvia collective matrix factorization,” in Proc. 14thACM SIGKDD Int. Conf. Knowl. Discovery DataMining, Las Vegas, NV, USA, Aug. 2008,pp. 650–658.
[178] S. Di, H. Zhang, C.-G. Li, X. Mei, D. Prokhorov,and H. Ling, “Cross-domain traffic sceneunderstanding: A dense correspondence-basedtransfer learning approach,” IEEE Trans. Intell.Transp. Syst., vol. 19, no. 3, pp. 745–757,Mar. 2018.
[179] H. Abdi, “Partial least squares regression andprojection on latent structure regression (PLSRegression),” Wiley Interdiscip. Rev.-Comput.Statist., vol. 2, no. 1, pp. 97–106, Jan. 2010.
[180] S. Della Pietra, V. Della Pietra, and J. Lafferty,“Inducing features of random fields,” IEEE Trans.Pattern Anal. Mach. Intell., vol. 19, no. 4,pp. 380–393, Apr. 1997.
[181] C. Liu, J. Yuen, and A. Torralba, “Nonparametricscene parsing via label transfer,” IEEE Trans.Pattern Anal. Mach. Intell., vol. 33, no. 12,pp. 2368–2382, Dec. 2011.
[182] C. Lu, F. Hu, D. Cao, J. Gong, Y. Xing, and Z. Li,“Transfer learning for driver model adaptation inlane-changing scenarios using manifoldalignment,” IEEE Trans. Intell. Transp. Syst., earlyaccess, Jul. 2019, doi:10.1109/TITS.2019.2925510.
[183] D. J. Berndt and J. Clifford, “Using dynamic timewarping to find patterns in time series,” in Proc.Knowl. Discovery Databases Workshop, Seattle,
WA, USA, Jul. 1994, pp. 359–370.[184] N. Makondo, M. Hiratsuka, B. Rosman, and
O. Hasegawa, “A non-linear manifold alignmentapproach to robot learning from demonstrations,”J. Robot. Mechatron., vol. 30, no. 2, pp. 265–281,Apr. 2018.
[185] P. Angkititrakul, C. Miyajima, and K. Takeda,“Modeling and adaptation of stochasticdriver-behavior model with application to carfollowing,” in Proc. IEEE Intell. Vehicles Symp. (IV),Baden-Baden, Germany, Jun. 2011, pp. 814–819.
[186] Y. Liu, P. Lasang, S. Pranata, S. Shen, andW. Zhang, “Driver pose estimation using recurrentlightweight network and virtual data augmentedtransfer learning,” IEEE Trans. Intell. Transp. Syst.,vol. 20, no. 10, pp. 3818–3831, Oct. 2019.
[187] J. Wang, H. Zheng, Y. Huang, and X. Ding,“Vehicle type recognition in surveillance imagesfrom labeled Web-nature data using deep transferlearning,” IEEE Trans. Intell. Transp. Syst., vol. 19,no. 9, pp. 2913–2922, Sep. 2018.
[188] K. Gopalakrishnan, S. K. Khaitan, A. Choudhary,and A. Agrawal, “Deep convolutional neuralnetworks with transfer learning for computervision-based data-driven pavement distressdetection,” Construct. Building Mater., vol. 157,pp. 322–330, Dec. 2017.
[189] S. Bansod and A. Nandedkar, “Transfer learningfor video anomaly detection,” J. Intell. Fuzzy Syst.,vol. 36, no. 3, pp. 1967–1975, Mar. 2019.
[190] G. Rosario, T. Sonderman, and X. Zhu, “Deeptransfer learning for traffic sign recognition,” inProc. IEEE Int. Conf. Inf. Reuse Integr.,Salt Lake City, UT, USA, Jul. 2018, pp. 178–185.
[191] W. Pan, E. W. Xiang, and Q. Yang, “Transferlearning in collaborative filtering with uncertainratings,” in Proc. 26th AAAI Conf. Artif. Intell.,Toronto, ON, Canada, Jul. 2012, pp. 662–668.
[192] G. Hu, Y. Zhang, and Q. Yang, “Transfer meetshybrid: A synthetic approach for cross-domaincollaborative filtering with text,” in Proc. WorldWide Web Conf., San Francisco, CA, USA,May 2019, pp. 2822–2829.
[193] W. Pan, E. W. Xiang, N. N. Liu, and Q. Yang,“Transfer learning in collaborative filtering forsparsity reduction,” in Proc. 24th AAAI Conf. Artif.Intell., Atlanta, GA, USA, Jul. 2010, pp. 230–235.
[194] W. Pan and Q. Yang, “Transfer learning inheterogeneous collaborative filtering domains,”Artif. Intell., vol. 197, pp. 39–55, Apr. 2013.
[195] F. Zhuang, Y. Zhou, F. Zhang, X. Ao, X. Xie, andQ. He, “Sequential transfer learning:Cross-domain novelty seeking trait mining forrecommendation,” in Proc. 26th Int. Conf. WorldWide Web Companion, Perth, WA, Australia,Apr. 2017, pp. 881–882.
[196] J. Zheng, F. Zhuang, and C. Shi, “Local ensembleacross multiple sources for collaborative filtering,”in Proc. 26th ACM Conf. Inf. Knowl. Manage.,Singapore, Nov. 2017, pp. 2431–2434.
[197] F. Zhuang, J. Zheng, J. Chen, X. Zhang, C. Shi,and Q. He, “Transfer collaborative filtering frommultiple sources via consensus regularization,”Neural Netw., vol. 108, pp. 287–295, Dec. 2018.
[198] J. He, R. Liu, F. Zhuang, F. Lin, C. Niu, and Q. He,“A general cross-domain recommendationframework via Bayesian neural network,” in Proc.18th IEEE Int. Conf. Data Mining, Singapore,Nov. 2018, pp. 1001–1006.
[199] F. Zhu, Y. Wang, C. Chen, G. Liu, M. A. Orgun, andJ. Wu, “A deep framework for cross-domain andcross-system recommendations,” in Proc. 27th Int.Joint Conf. Artif. Intell., Stockholm, Sweden,Jul. 2018, pp. 3711–3717.
[200] F. Yuan, L. Yao, and B. Benatallah, “DARec: Deepdomain adaptation for cross-domainrecommendation via transferring rating patterns,”in Proc. 29th Int. Joint Conf. Artif. Intell., Macao,China, Aug. 2019, pp. 4227–4233.
[201] E. Bastug, M. Bennis, and M. Debbah, “A transferlearning approach for cache-enabled wirelessnetworks,” in Proc. 13th Int. Symp. Model. Optim.Mobile, Ad Hoc, Wireless Netw., Mumbai, India,May 2015, pp. 161–166.
[202] R. Li, Z. Zhao, X. Chen, J. Palicot, and H. Zhang,
32 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
“TACT: A transfer actor-critic learning frameworkfor energy saving in cellular radio accessnetworks,” IEEE Trans. Wireless Commun., vol. 13,no. 4, pp. 2000–2011, Apr. 2014.
[203] Q. Zhao and D. Grace, “Transfer learning for QoSaware topology management in energy efficient5G cognitive radio networks,” in Proc. 1st Int.Conf. 5G Ubiquitous Connectivity, Äkäslompolo,Finland, Nov. 2014, pp. 152–157.
[204] B. Guo, J. Li, V. W. Zheng, Z. Wang, and Z. Yu,“Citytransfer: Transferring inter- and intra-cityknowledge for chain store site recommendationbased on multi-source urban data,” in Proc. ACMInteract., Mobile, Wearable Ubiquitous Technol.,Jan. 2018, pp. 1–23.
[205] Y. Wei, Y. Zheng, and Q. Yang, “Transferknowledge between cities,” in Proc. 22nd ACMSIGKDD Int. Conf. Knowl. Discovery Data Mining,San Francisco, CA, USA, Aug. 2016,pp. 1905–1914.
[206] U. Cote-Allard et al., “Deep learning forelectromyographic hand gesture signalclassification using transfer learning,” IEEE Trans.
Neural Syst. Rehabil. Eng., vol. 27, no. 4,pp. 760–771, Apr. 2019.
[207] C.-X. Ren, D.-Q. Dai, K.-K. Huang, and Z.-R. Lai,“Transfer learning of structured representation forface recognition,” IEEE Trans. Image Process.,vol. 23, no. 12, pp. 5440–5454, Dec. 2014.
[208] J. Wang, Y. Chen, L. Hu, X. Peng, and P. S. Yu,“Stratified transfer learning for cross-domainactivity recognition,” in Proc. IEEE Int. Conf.Pervasive Comput. Commun., Athens, Greece,Mar. 2018, pp. 1–10.
[209] J. Deng, Z. Zhang, E. Marchi, and B. Schuller,“Sparse autoencoder-based feature transferlearning for speech emotion recognition,” in Proc.Humaine Assoc. Conf. Affect. Comput. Intell.Interact., Geneva, Switzerland, Sep. 2013,pp. 511–516.
[210] D. Xi, F. Zhuang, G. Zhou, X. Cheng, F. Lin, andQ. He, “Domain adaptation with categoryattention network for deep sentiment analysis,” inProc. Web Conf., Taipei, Taiwan, Apr. 2020,pp. 3133–3139.
[211] Y. Zhu et al., “Modeling users’ behavior sequences
with hierarchical explainable network forcross-domain fraud detection,” in Proc. Web Conf.,Taipei, Taiwan, Apr. 2020, pp. 928–938.
[212] J. Tang, T. Lou, J. Kleinberg, and S. Wu, “Transferlearning to infer social ties across heterogeneousnetworks,” ACM Trans. Inf. Syst., vol. 34, no. 2,pp. 1–43, Apr. 2016.
[213] L. Zhang, L. Zhang, D. Tao, and X. Huang, “Sparsetransfer manifold embedding for hyperspectraltarget detection,” IEEE Trans. Geosci. Remote Sens.,vol. 52, no. 2, pp. 1030–1043, Feb. 2014.
[214] F. Zhuang et al., “Transfer learning toolkit: Primersand benchmarks,” 2019, arXiv:1911.08967.[Online]. Available:http://arxiv.org/abs/1911.08967
[215] K. Saenko, B. Kulis, M. Fritz, and T. Darrell,“Adapting visual category models to newdomains,” in Proc. 11th Eur. Conf. Comput. Vis.,Heraklion, Greece, Sep. 2010, pp. 213–226.
[216] Z. C. Lipton, “The mythos of modelinterpretability,” ACM Queue, vol. 16, no. 3,pp. 1–27, May 2018.
A B O U T T H E A U T H O R S
Fuzhen Zhuang received the B.E. andPh.D. degrees in computer science fromthe Institute of Computing Technology, Chi-nese Academy of Sciences, Beijing, China,in 2006 and 2011, respectively.He is currently an Associate Profes-
sor with the Institute of Computing Tech-nology, Chinese Academy of Sciences.He has published more than 100 papersin some prestigious refereed journals and conference proceed-ings such as the IEEE TRANSACTIONS ON KNOWLEDGE AND DATAENGINEERING, the IEEE TRANSACTIONS ON CYBERNETICS, the IEEETRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS,the ACM Transactions on Intelligent Systems and Technology, Infor-mation Sciences, Neural Networks, SIGKDD, IJCAI, AAAI, TheWeb-Conf, SIGIR, ICDE, ACM CIKM, ACM WSDM, SIAM SDM, and IEEEICDM. His research interests include transfer learning, machinelearning, data mining, multitask learning, and recommendationsystems.Dr. Zhuang is a Senior Member of CCF. He was a recipient of the
Distinguished Dissertation Award of CAAI in 2013.
Zhiyuan Qi received the B.E. degree insoftware engineering from Sun Yat-sen Uni-versity, Guangzhou, China, in 2019.He is currently a Visiting Student with
the Institute of Computing Technology, Chi-nese Academy of Sciences, Beijing, China.He has published several journal articles inthe IEEE Computational Intelligence Mag-azine, IEEE ACCESS, Neurocomputing, andNumerical Algorithms. He serves as a reviewer for some jour-nals, including IEEE ACCESS and the IEEE TRANSACTIONS ON
COMPUTATIONAL SOCIAL SYSTEMS. His current research interestsinclude transfer learning, machine learning, recommender sys-tems, and time-variant problems solving.
Keyu Duan is currently pursuing the B.E.degree in software engineeringwith BeihangUniversity, Beijing, China.He has been with the Institute of Com-
puting Technology, Chinese Academy ofSciences, Beijing, as a Visiting Student,since May 2019. His main research interestsinclude transfer learning and data mining.
Dongbo Xi received the B.S. degree incomputer science and technology from theNanjing University of Aeronautics and Astro-nautics, Nanjing, China, in 2017. He is cur-rently pursuing the M.S. degree with theInstitute of Computing Technology, ChineseAcademy of Sciences, Beijing, China.He has published several papers in con-
ference proceedings, including AAAI, WWW,and SIGIR. His research interests include recommender systemsand transfer learning.
Yongchun Zhu received the B.S. degreefrom Beijing Normal University, Beijing,China, in 2018. He is currently pursuing theM.S. degree with the Institute of ComputingTechnology, Chinese Academy of Sciences,Beijing.He has published some papers in jour-
nals and conference proceedings, includ-ing the IEEE TRANSACTIONS ON NEURALNETWORKS AND LEARNING SYSTEMS, Neural Networks, AAAI, WWW,and PAKDD. His main research interests include transfer learningand meta learning.
Hengshu Zhu (Senior Member, IEEE)received the B.E. and Ph.D. degrees in com-puter science from the University of Sci-ence and Technology of China (USTC), Hefei,China, in 2009 and 2014, respectively.He is currently a Principal Data Scien-
tist and an Architect at Baidu Inc., Bei-jing, China. He has published prolificallyin refereed journals and conference pro-ceedings, including the IEEE TRANSACTIONS ON KNOWLEDGE AND
DATA ENGINEERING (TKDE), the IEEE TRANSACTIONS ON MOBILE
COMPUTING (TMC), the ACM Transactions on Information Systems(ACM TOIS), the ACM Transactions on Knowledge Discovery fromData (TKDD), ACM SIGKDD, ACM SIGIR, WWW, IJCAI, and AAAI.His research interests include data mining and machine learning,with a focus on developing advanced data analysis techniques forinnovative business applications.
PROCEEDINGS OF THE IEEE 33
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Zhuang et al.: Comprehensive Survey on Transfer Learning
Dr. Zhu is a Senior Member of ACM and CCF. He was a recipientof the Distinguished Dissertation Award of CAS in 2016, the Dis-tinguished Dissertation Award of CAAI in 2016, the Special Prize ofPresident Scholarship for Postgraduate Students of CAS in 2014,the Best Student Paper Award of KSEM-2011, WAIM-2013, CCDM-2014, and the Best Paper Nomination of ICDM-2014. He has servedregularly on the organization and program committees of numerousconferences, including as a Program Co-Chair of the KDD Cup-2019 Regular ML Track and a Founding Co-Chair of the InternationalWorkshop on Organizational Behavior and Talent Analytics (OBTA)and the International Workshop on Talent and Management Com-puting (TMC), in conjunction with ACM SIGKDD.
Hui Xiong (Fellow, IEEE) received the Ph.D.degree from the University of Minnesota(UMN), Minneapolis, MN, USA.He is currently a Full Professor with the
Rutgers, The State University of New Jersey,Newark, NJ, USA. He is an ACM DistinguishedScientist.Dr. Xiong received the 2018 Ram Charan
Management Practice Award as the GrandPrix Winner from the Harvard Business Review, the RBS Dean’sResearch Professorship in 2016, the Rutgers University Board ofTrustees Research Fellowship for Scholarly Excellence in 2009,the ICDM Best Research Paper Award in 2011, and the IEEE ICDMOutstanding Service Award in 2017, from the Rutgers, The StateUniversity of New Jersey. He is a Co-Editor-in-Chief of Encyclopediaof GIS and an Associate Editor of the IEEE TRANSACTIONS ON BIGDATA (TBD), the ACM Transactions on Knowledge Discovery fromData (TKDD), and the ACM Transactions on Management Informa-tion Systems (TMIS). He has served regularly on the organizationand program committees of numerous conferences, including as aProgram Co-Chair of the Industrial and Government Track for the18th ACM SIGKDD International Conference on Knowledge Discov-ery and Data Mining (KDD), the IEEE 2013 International Conferenceon Data Mining (ICDM), and the Research Track for the 2018 ACMSIGKDD International Conference on KDD, and a General Co-Chairof the IEEE 2015 ICDM.
Qing He received the B.S. degree in math-ematics from Hebei Normal University, Shi-jiazhuang, China, in 1985, the M.S. degreein mathematics from Zhengzhou University,Zhengzhou, China, in 1987, and the Ph.D.degree in fuzzy mathematics and artificialintelligence from Beijing Normal University,Beijing, China, in 2000.From 1987 to 1997, he was with the Hebei
University of Science and Technology, Shijiazhuang. He is currentlya Professor with the Institute of Computing Technology, ChineseAcademy of Sciences, Beijing, where he is also a Doctoral Tutor.He is also a Professor with the Graduate University of ChineseAcademy of Sciences, Beijing. His research interests include datamining, machine learning, classification, and fuzzy clustering.
34 PROCEEDINGS OF THE IEEE
Authorized licensed use limited to: THE LIBRARY OF CHINESE ACADEMY OF SCIENCES. Downloaded on July 09,2020 at 01:16:45 UTC from IEEE Xplore. Restrictions apply.