a brief history of "big data"
TRANSCRIPT


SUMMARY• Welcome intro
• What is Big Data?
• Some components:
• HDFS• MapReduce• Pig• Hive• Oozie• Flume• Sqoop• Mahout• Impala
• More components:
• YARN & MapReduceV2• NoSQL & Hbase• Solr• Spark• Cloudera Manager• Hue

MOTIVATION
"There were 5 hexabytes of information created between the dawn of civilization through 2003, but that much information
is now created every 2 days, and the pace is increasing.”
Eric Schmidt, Google, August 2010
5EB 5EB 5EB5EB
5EB
5EB
?

WHAT PEOPLE THOUGHT ABOUT BIG DATA
“Big Data is a shorthand label that typically means applying the tools of artificial intelligence, like machine learning, to vast new troves of data beyond that captured in standard
databases. The new data sources include Web-browsing data trails, social network communications, sensor data and
surveillance data.”
"A process that has the potential to transform everything”
NY Times, August 2012

WHAT THEY THOUGHT LATER
“The ‘Big’ there is purely marketing… This is about you buying big expensive servers and whatnot.”
“Good data is better than big data”
“Big data is bullshit”, 2013
Quote from Harper Reed, Tech Guru for Obama re-election caimpaign in 2012

BUT, THIS WAS EXPECTED Towards disillusionment…

HOW MUCH IT WILL CHANGE THE WORLD ?
We have a long history of successes in predictions…
“I predict the internet will […] catastrophically collapse in 1996”
Robert Metcalfe, Inventor of Ethernet, 1995
And the world will end in 2012…

THERE IS NO WAY TO PREDICT THE FUTURE
“Spam will be solved in 2 years”Bill Gates, 2004
“There is no chance the iPhone will get any significant market share”
Steve Ballmer, 2007
<div>{{hello.world}}</div>
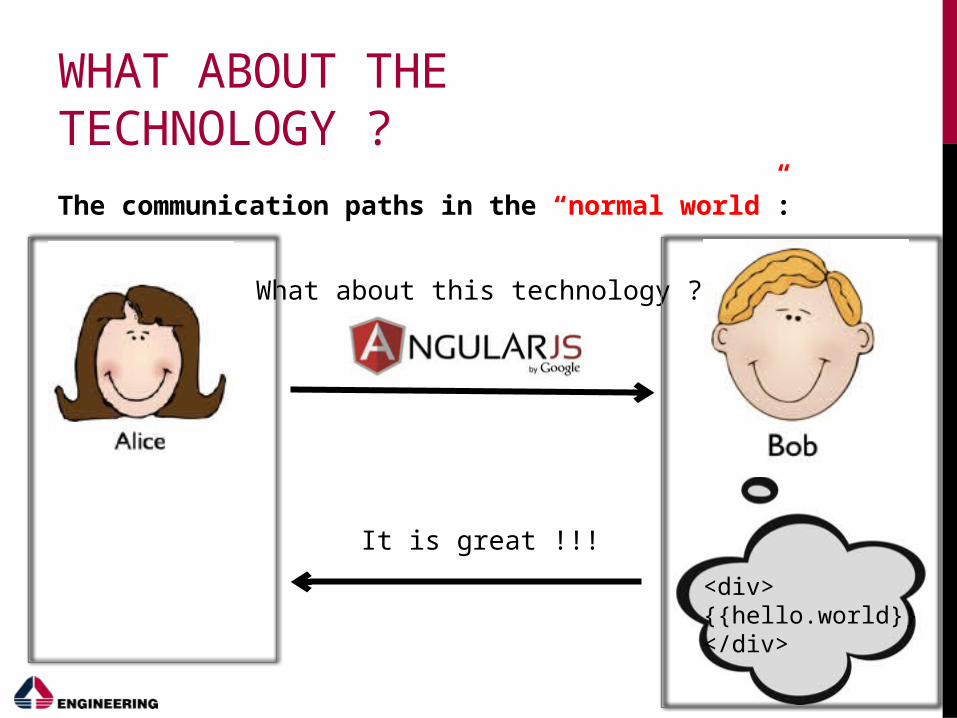
WHAT ABOUT THE TECHNOLOGY ?
The communication paths in the “normal world”:
What about this technology ?
It is great !!!

CAN YOU DO THE SAME IN THE “BIG WORLD” ?
The communication paths in the “big world”:
What about this technology ?
steep learning curve

A REAL WORLD EXAMPLE
Sarah, today I’m gonna run some wonderful Spark applications on my new Big Data cluster on Amazon EC2!!
Oh, I though that Amazon was just selling shoes!

WELCOME BACK TO 1946
ENIAC
One of the first electronic digital computers (1946).
It was 180 m2 big
A Big Data cluster (today).
We need new languages and abstractions to develop on top of it.
(more powerful than assembly !)

VOLUME
Need to process:
• 1TB
• 1PB
• 1EB
of data, and extract useful information.
How ?

VELOCITY
Need to handle:
1MB/s
1GB/s
1TB/s
of data and react in nearly real time.
How ?
Think to sensor data

VARIETY
Need to process:
• Digital Images
• Video Recording
• Free Text
data and extract useful information.
How?

VVV: THAT IS BIG DATA
Traditional systems are not suitable for data characterized by High:
• Volume: TB, PB, HB, ZB …
• Velocity: GB/s, TB/s …
• Variety: unstructured or semi-structured
Big Data Systems have been created for these purposes.

WHAT’S WRONG WITH TRADITIONAL SYSTEMS?
Oracle databases can host tables with more than 200TB of data (some of them are in Italy).
Suppose you want to run a query like:
select type, count(*) from eventsgroup by type
How much will you wait ?
Even if you reach 10GB/s of read speed from disks (with multiple SSD)…you will wait more than 5 hours !(if the instance won’t crash before…)

BIG DATA SYSTEMS ARE DISTRIBUTED
Big Data systems are a collection of software applications installed on different machines.
Each application can be used as if it was installed in a single machine.
…
1 2 3 4 5 > 10.000

GETTING STARTED
Do not try to install all software by yourself! You’ll become crazy!
Get a “Platform including Hadoop” in a virtual machine from:
(Many) applications in the VM runs in:
“pseudo-distributed mode” For:

TOWARDS PRODUCTIONCommodity On-premises Hardware
Big Data Appliance Cloud Services

HISTORY: GOOGLE FILE SYSTEMIn 2003, Google published a paper about a new distributed file system called Google File System (GFS).http://static.googleusercontent.com/media/research.google.com/it//archive/gfs-sosp2003.pdf
Their largest cluster:
• Was composed of more than 1000 nodes
• Could store more than 100 TB (it was 2003 !)
• Can be accessed by hundreds of concurrent clients
Its main purpose was that of serving the Google search engine.
But… how?

HISTORY: MAPREDUCE
In 2004, Google published another paper about a new batch processing framework, called MapReduce.http://static.googleusercontent.com/media/research.google.com/it//archive/mapreduce-osdi04.pdf
MapReduce:
• Was a parallel processing framework
• Was integrated perfectly with GFS
MapReduce was used for updating indexes in the Google search engine.

HISTORY: HADOOPIn 2005, Doug Cutting (Yahoo!) created the basis of the Big Data movement: Hadoop.
Originally, Hadoop was composed of:
1. HDFS: a Highly Distributed File System “inspired by” GFS
2. MapReduce: a parallel processing framework “inspired by” Google MapReduce
“inspired by” = “a copy of”
… but with an open source license (starting from 2009).
Hadoop was the name of his son’s toy
elephant.

HDFS: INTERNALS
A Master/Slave architecture:
• Master: takes care of directories and file block locations
• Slaves: store data blocks (128MB). Replication factor 3.

HDFS: LOGICAL VIEW
A HDFS cluster appears logically as a normal POSIX file system (not fully compliant with POSIX):
• Clients are distribution unaware (eg. Shell, Hue)
• Allows creation of:
• Files and directories• ACL (Users and groups)• Read/Write/AccessChild permissions

MAPREDUCE
Algorithm:
1. Map: data is taken from HDFS and transformed
2. Shuffling: data is splitted and reorganized among nodes
3. Reduce: data is summarized and written back to HDFS
Master
HDFS NameNode
MapReduce JobTracker
Slave 1
HDFS DataNode
MapReduce TaskTracker
Slave 2
HDFS DataNode
MapReduce TaskTracker
Slave 3
HDFS DataNode
MapReduce TaskTracker
Delegation and aggregation
Shuffling (temp files)
map map map
Data locality

MAPREDUCE: WORD COUNT
M M
Map
Reduce
HDFS blocks on different machines
(splits)
3 Mappers
4 Reducers
Words in emails

MAPREDUCE: SOFTWAREThe “mapper”:
public class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1); private Text word = new Text();
public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } }}

MAPREDUCE: SOFTWAREThe “reducer”:
public class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); }}

MAPREDUCE: SOFTWARE
The “main” class:
public class WordCount { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }}
Configuration is usually pre-filled from an additional xml file
(hadoop-site.xml)

MAPREDUCE
Considerations:
• Can run in more than 10 thousand machines
• Linear scalability (theoretical/commercial feature):
• 100 nodes: 1PB in 2 hours 200 nodes: 1PB in 1 hour • 100 nodes: 1PB in 2 hours 200 nodes: 2PB in 2 hours
• Programming model:
• You can do more than word count (samples follow)• Complex data pipelines require more than 1 MapReduce
step• Difficult to write programs as MapReduce Jobs (a brand
new way of writing algorithms)• Difficult to maintain code (and to reverse engineer)

FIRST IMPROVEMENT: PIG
MapReduce job are difficult to write.
Complex pipelines require multiple jobs.
In 2006, people at Yahoo research started working on a new language to simplify creation of MapReduce jobs.
They created Pig.
The “Pig Latin” is a procedural language.
It is still used by Data Scientist at Yahoo!, and worldwide.

PIG LATINThe word count in Pig:
lines = LOAD '/tmp/input-file' AS (line:chararray);
words = FOREACH lines GENERATE FLATTEN(TOKENIZE(line)) AS word;-- remove whitespaces wordsfiltered_words = FILTER words BY word MATCHES '\\w+';
word_groups = GROUP filtered_words BY word;
word_count = FOREACH word_groups GENERATE COUNT(filtered_words) AS count, group AS word;
ordered_word_count = ORDER word_count BY count DESC;
STORE ordered_word_count INTO '/tmp/output-file';
From this kind of sources, Pig creates one or more
MapReduce jobs

PIG
Considerations:
• Procedural language, easier than MapReduce style
• Can build directed acyclic graphs (DAG) of MapReduce steps
• One step has same scalability as MapReduce counterpart
• Compatibility with many languages for writing user defined functions (UDF): Java, Python, Ruby, …
• Thanks to UDF, you can treat also unstructured data
• It’s another language
• Stackoverflow cannot help you in case of bugs !

SECOND IMPROVEMENT: HIVEIn 2009, the Facebook Data Infrastructure Team created Hive:
“An open-source data warehousing solution on top of hadoop”
Hive brings SQL to Hadoop (queries translated to MapReduce):
• You can define the structure of Hadoop files (tables, with columns and data types) and save them in Hive Metastore
• You can query tables with HiveQL, a dialect of SQL. Limitations:
• Joins only with equality conditions• Subqueries with limitations• Limitations depend on the version… Check the docs

HIVE: SAMPLE QUERIES
An example of Hive query (you have seen it before):
select type, count(*) from eventsgroup by type
Another query:
select o.product, u.country from order o join user u on o.user_id = u.id
Can be executed on many PB of data (having an appropriate
number of machines)
How can you translate it in MapReduce ?
How many MR steps ?
Order and User are folders with text files in HDFS. Hive consider them as tables
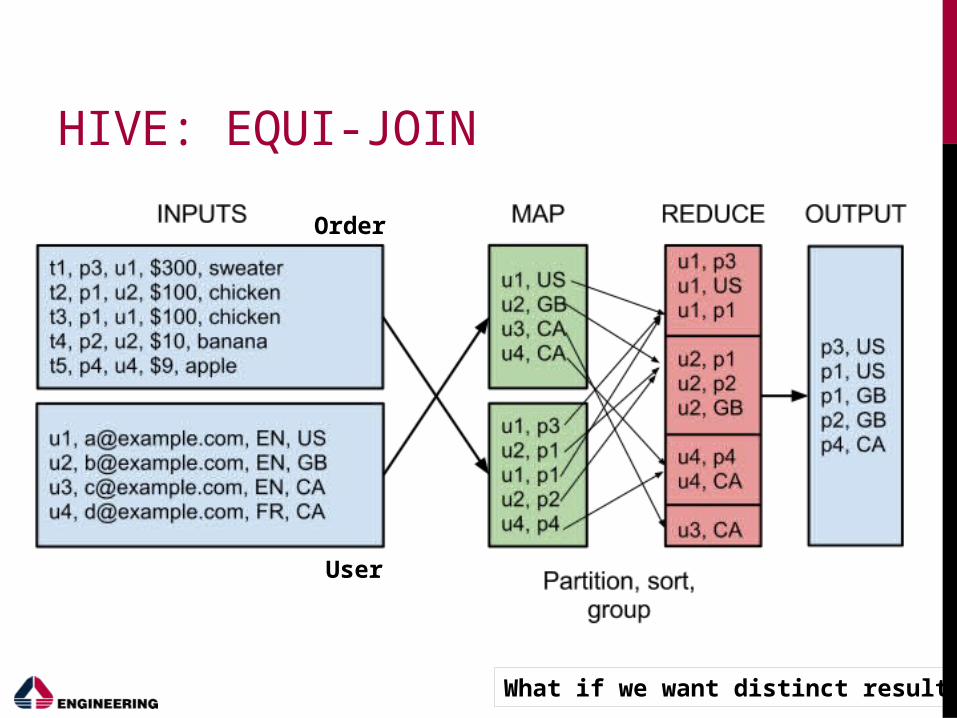
HIVE: EQUI-JOIN
User
Order
What if we want distinct results ?

MULTIPLE MR JOBS
Hive and Pig produce multiple MapReduce jobs and run them in sequence.
What if we want to define a custom workflow of MR/Hive/Pig jobs ?
Oozie:
• Configure Jobs
• Define Workflow
• Schedule execution
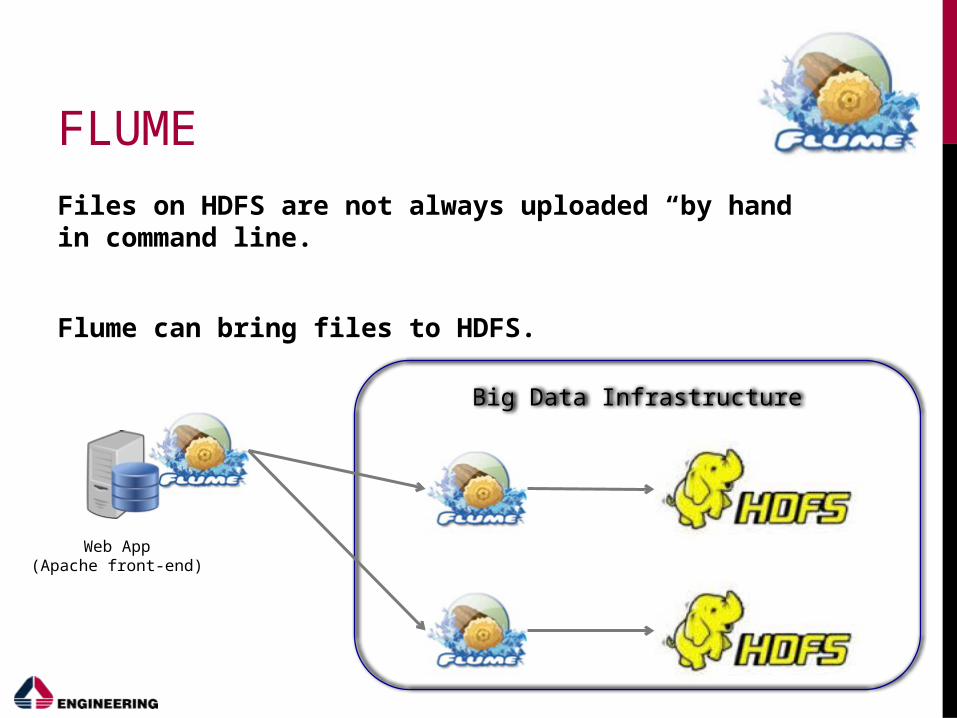
FLUME
Files on HDFS are not always uploaded “by hand” in command line.
Flume can bring files to HDFS.
Web App(Apache front-end)
Big Data Infrastructure
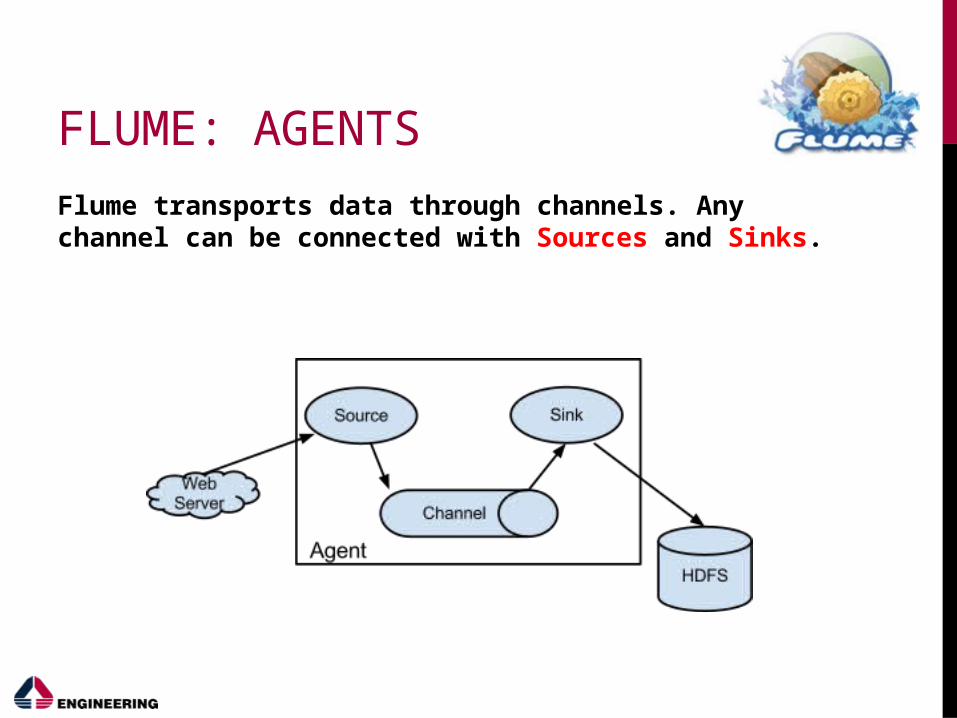
FLUME: AGENTS
Flume transports data through channels. Any channel can be connected with Sources and Sinks.

CHANNEL COMPOSITION
When you have multiple web servers. You can also send output to multiple
locations (multiplexing)

CONFIGURING FLUME
A simple agent (simple-flume.conf):
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
A netcat source listens for incoming telnet data

CONFIGURING FLUME (CONT.)# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
A logger sink just outputs data (useful for debugging)

TESTING FLUME
Run the example with the command:
flume-ng agent --conf conf --conf-file \
example.conf --name a1 \
-Dflume.root.logger=INFO,console
Then, open another terminal and send telnet commands to the listening agent..

INGESTING FROM JDBC
Another tool useful to ingest data in HDFS from relational databases is Sqoop2.
With Sqoop2, you can configure Jobs made of:
• A JDBC Source (table or query)
• A HDFS Sink (folder with type and compression options). Other type of sink are also supported, eg. HBase.
Jobs can be configured and run with: sqoop2-shell (or hue).
Real-time synch is not supported

MACHINE LEARNING: MAHOUT
Mahout is about “Machine learning on top of Hadoop”.
Main packages:
• Collaborative Filtering
• Classification
• Clustering
Many algorithms run on MapReduce.
Other algorithms run on other engines. Some of them can run only locally (not parallelizable).
Sample usage: mahout kmeans –i … -o … -k …

IMPALA
Add Interactivity to SQL queries: Cloudera Impala

WHAT’S NEXT ?
Next topic: MapReduce V2

SOME PROBLEMS WITH MAPREDUCE• Paradigm: MapReduce is a new “template” algorithm. Difficult
to translate existing algorithms in MapReduce.
• Expressiveness: a single MapReduce job is often not sufficient for enterprise data processing. You need to write multiple jobs.
• Interactivity: MapReduce is terribly slow for small amounts of data (time for initialization). Hive queries cannot be interactive.
• Maintainability: writing a single MapReduce job can be cumbersome. Writing a pipeline of MapReduce jobs produce 100% unmaintainable code.
?
Nobody still writes MapReduce jobs directly

AN “UNEXPECTED” ISSUE WITH MR
With “real” Big Data (Volume), another issue is coming:
Performance:
When you have multiple PB of data, scalability is not linear anymore.
Google has replaced MapReduce with “Cloud Dataflow” since many years.
HDFS MAP SPILL REDUCESHUFFLE HDFS
Disk and network are the slowest components: imagine a pipeline of 20 MR jobs…
partition
w r wr
network transfer

MAPREDUCE 2MapReduce v1 had too many components.
Changes:
• Resource Management has been moved to YARN
• MR API rewritten (changed package from org.apache.hadoop.mapred to org.apache.hadoopmapreduce)

YARN
Yet Another Resource Negotiator: started in 2008 at Yahoo!
Introduced in major data platforms in 2012.
Negotiate (allocate containers with):
• RAM
• DISK
• CPU
• NETWORK

YARN: ADVANTAGES
YARN is considered the Hadoop Data Operating System.
Hortonworks Data Platform

HDFS LIMITATIONS
MapReduce problems have been solved with MR2.
What about HDFS ?
• Can store large volumes of files
• Supports any format, from text files to custom records
• Supports “transparent” compression of data
• Parallel retrieve and storage of batches
• Does not provide:
• Fast random read/write (HDFS is append only)• Data updates (rewrite the entire block: 128MB)

HBASE: THE HADOOP DATABASE
Google solved the problem starting from 2004.
In 2006 they published a paper about “Big Table”.http://static.googleusercontent.com/media/research.google.com/it//archive/bigtable-osdi06.pdf
The Hadoop community made their own version of Big Table in 2010.
It has been called HBase. It provides with:
• Fast read/write access to single records
• Organization of data in tables, column families and columns
• Also: performance, replication, availability, consistency…

HBase
HBASE: DATA MODEL
Table Table
Column Family Col. Family
Col. Family Col. Family
Col. Col. Col.
Cell
Cell
Cellput “value” to table1, cf1:col1 (row_key)
get * from table1 (row_key)delete from table1, cf1:col1 (row_key)
scan …

HBASE: ARCHITECTURE
We will have a whole presentation on HBase…
Hadoop Master
HMaster NameNode
Hadoop Slave 1
Region Server
DataNode
Hadoop Slave 2
Region Server
DataNode
HDFS

ACCESS HBASE
Different ways to access HBase:
• HBase Driver API:
• CRUDL• MapReduce
• Hadoop InputFormat and OutputFormat to read/write data in batches
• Hive/Impala
• Do SQL on HBase: limitations in “predicate pushdown”• Apache Phoenix:
• A project to “translate” SQL queries into Driver API Calls

NOSQL
Some Data Platforms include different NoSQL databases.
Similar to HBase
Graphs
Documents
Key/Value
Not Only SQL NOw SQL

SOLR
NoSQL databases have some “features” in common:
• You need to model the database having the queries in mind
• You need to add redundancy (to do different queries)
• Lack of a “good” indexing system (secondary indexes absent or limited)
A Solution:
• Solr
Full Text Search

APACHE SPARK: THE GAME CHANGER
“Apache Spark is a fast and general engine for large-scale data processing”
Spark vs MapReduce:• Faster• Clearer• Shorter• Easier• More powerful

KEY DIFFERENCE
A MapReduce complex algorithm:
A Spark complex algorithm:
Map Reduce
HDFS
The developer writes multiple applications,
each one with 1 map and 1 reduce step.
A scheduler (Oozie) is programmed to execute
all applications in a configurable order.
The developer writes 1 application using a
simple API.
The Spark Framework executes the application.
Data is processed in memory as much as
possible.

MIGRATION
Many applications originally developed on MapReduce are gradually migrating to Spark (migration in progress).
Pig on Spark (Spork): just using “-x spark” in shell
Hive on Spark: “set hive.execution.engine=spark”
Since 25/04/2014: No more MapReduce based algorithms

USAGE
RDDs can be used as normal Scala collections, there are only small differences in the API.
val book = sc.textFile(”/books/dante/inferno.txt")
val words = book.flatMap(f => f.split(" "))
val chart = words
.map(w => (w, 1))
.reduceByKey((n1, n2) => n1 + n2)
.top(4)(Ordering.by(t => t._2))
SCALA !

STREAMING
Spark has a “Streaming” component.
Storm streaming model is different
SAME SCALA API

SPARK COMPONENTSSpark libraries are developed on top of the Spark core framework for large scale data processing:
• Spark SQL: execute SQL queries on heterogeneous distributed datasets
• Spark Streaming: execute micro-batches on streaming data
• Spark MLib: ready-to-use machine learning algorithms
• Spark GraphX: algorithms and abstractions for working with graphs
Spark Core
Spark SQLSpark
Streaming Spark MLibSpark
GraphX
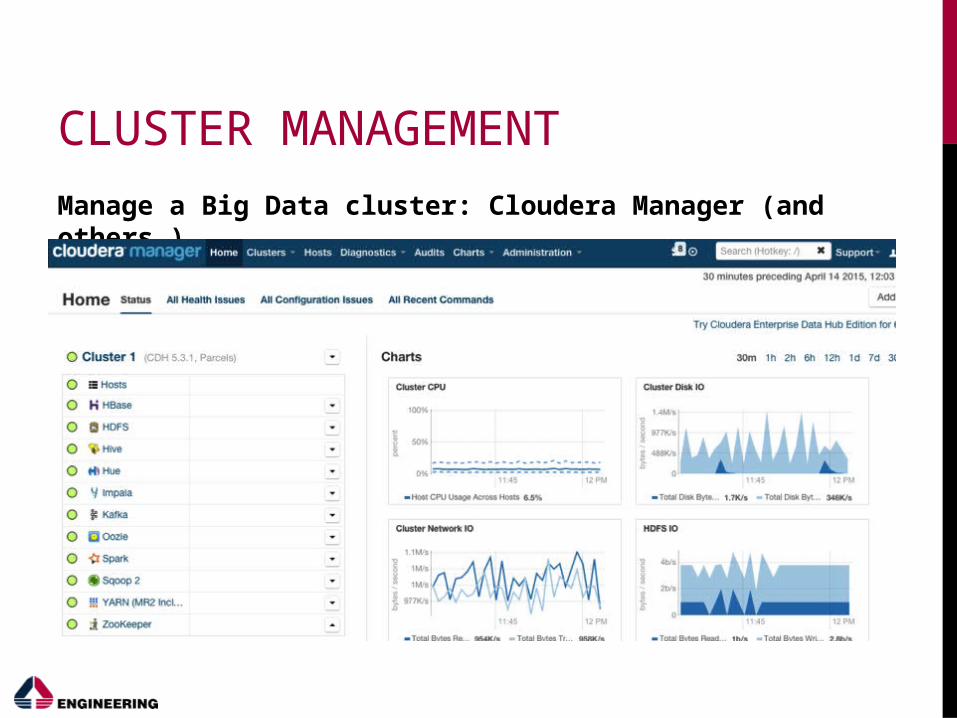
CLUSTER MANAGEMENT
Manage a Big Data cluster: Cloudera Manager (and others…)

DATA MANAGEMENT
Simplify the management of data: Hue

THE PUZZLE
Manager
Version 2
+ Dataframes+ MLLib+ GraphX

REORGANIZE THE IDEAS
A common “data platform on top of Hadoop”: Hortonworks

AGAIN
Cloudera Data Hub.
