a bayesian approach to filter junk e-mail yasir iqbal master student in computer science...
TRANSCRIPT

A Bayesian Approach to filter Junk E-Mail
Yasir IQBALMaster Student in Computer Science
Universität des Saarlandes
Seminar: Classification and Clustering methods for Computational Linguistics16.11.2004

2
Presentation Overview
• Problem description (What’s Spam problem?)– Classification problem
– Naïve Bayes Classifier
• Logical system view– Features selection, representation
• Results– Precision and Recall
• Discussion

3
Spam/junk/bulk Emails
• The messages you spend your time to throw out– Spam: do not want to get, unsolicited messages– Junk: irrelevant to the recipient, unwanted– Bulk: mass mailing for business marketing (or
fill-up mailbox etc)

4
Problem examples
• „You have won!!!!“, you are almost winner of $...• “Viagra”, generic Viagra available order now• “Your order”, your item$ have to be $hipped• “Lose your weight”, no subscription required• “Assistance required”, an amount of million 25 US$• “Get login and password now”, age above 18• “Check this”, hi, your document has error• “Download it”, free celebrity wallpapers download

5
• Who? and how should one decide what is Spam?
• How to get rid of this Spam automatically?– Because “Time is money”– and offensive material in such emails
Motivation
What are the computers for?
“Let them work”

6
How to fight? (techniques)
• Rule based filtering of emails– if $SENDER$ contains “schacht” $ACTION$=$INBOX$
– if $SUBJECT$ contains “Win” $ACTION$=$DELETE$
– if $BODY$ contains “Viagra” $ACTION$=$DELETE$
– Problems: static rules, language dependent, how many rules, and who should define them?
• Statistical filter (classifier) based on message attributes– Decision Trees
– Support Vector Machines
– Naïve Bayes Classifier (We’ll discuss)
Problems: when no features can be extracted??? Error loss?

7
Classification tasks
• These are few other classification tasks:– Text Classification (like the mail message)
• Content management, information retrieval
– Document classification• Same like text classification
– Speech recognitions • “what do you mean? ”: yeh you understand ;)!
– Named Entity Recognition:• “Reading and Bath”: Cities or simple verbs?
– Biometric sensors for authentication• “fingerprints”, “face”… to identify someone

8
Training methods
• Offline learning: –some training data, prepared manually, with annotation (used to train the system before test)
•<email type=“spam”>hi, have you thought online credit?</email>•<email type=“normal_email”>Soha! sorry cannot reach at 18:00</email>
• Online learning:–At run-time user increases “knowledge” of the system by a kind of “feedback” to the given decision.
•Example: We can click on “Spam” or “Not Spam” in Yahoo mail service.
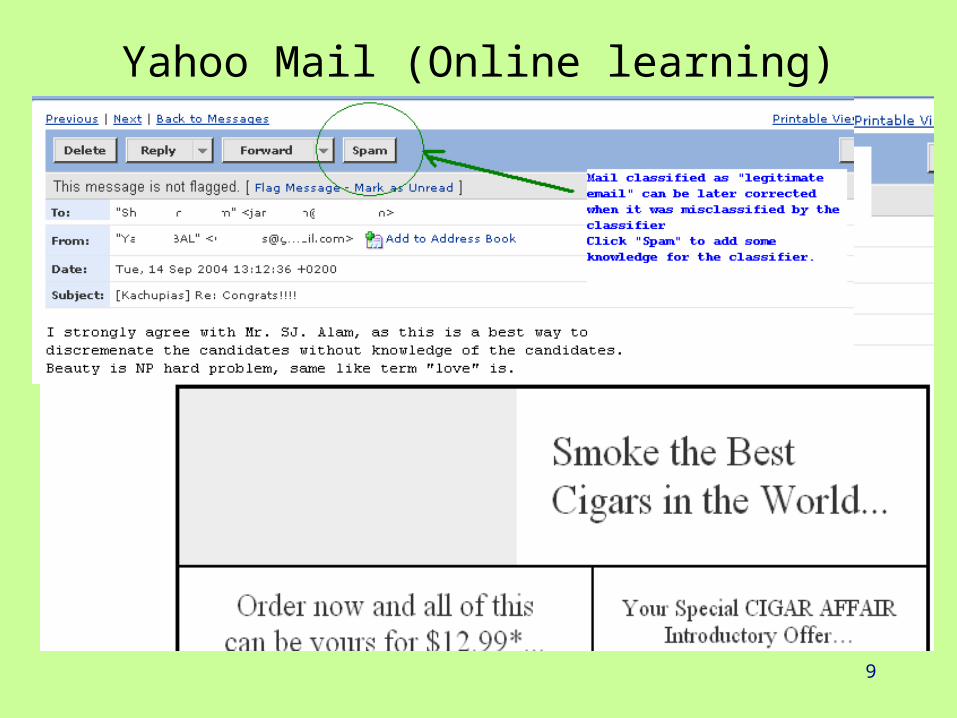
9
Yahoo Mail (Online learning)
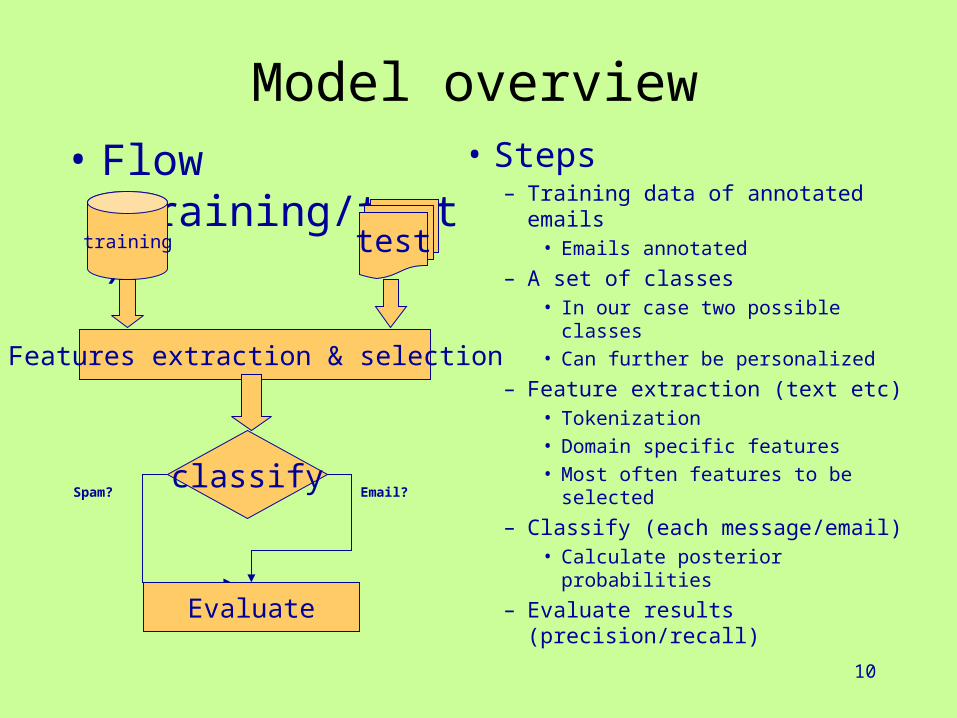
10
Model overview• Flow (training/test) • Steps
– Training data of annotated emails• Emails annotated
– A set of classes• In our case two possible classes
• Can further be personalized
– Feature extraction (text etc)• Tokenization
• Domain specific features
• Most often features to be selected
– Classify (each message/email)• Calculate posterior probabilities
– Evaluate results (precision/recall)
testtraining
Features extraction & selection
classify
Evaluate
Email?Spam?

11
Message attributes (features)
• These are the indicators for classification the messages into “legitimate” or “Spam”
• Features of the email messages– Words (tokens): free, win, online, enlarge,
weight, money, offer…– Phrases :”FREE!!!”, “only $”, “order now”…– Special characters : $pecial, grea8, “V i a g r a”– Mail headers :sender name, to and from email
address, domain name / IP address,

12
Feature vector matrix (binary variables)
Email# “online” “Viagra” “Order now!!!” “offer” “win” SPAM?
1 1 0 1 0 1 YES
2 1 1 1 1 0 YES
3 1 0 0 1 0 NO
4 0 1 1 1 1 YES
5 0 0 1 1 0 NO
Words/phrases as features, 1 if the feature exists, otherwise 0

13
Feature Selection
• How to select most prominent features?– Words/Tokens, phrases, header information
• Text of the email, HTML messages, header fields, email address
– Removing insignificant features• Calculate the mutual information between each
feature and the class

14
B
Conditional probability
• Probability of an event B while given an observed event A– P(B | A) = P(A|B) * P(B) / P(A)
• Probability of even A must be > 0 (must have occurred)
A Feature set
SPAM EMAIL
P that A and B occurred together Calculate P that these features belong to SPAM or EMAIL class

15
How to apply to the problem?
• When X={x1, x2, x3, x4…xn} is a feature vector– a set of feature (feature vector), X={“online”, “credit”, “now!!!”…”Zinc”}
• C={c1, c2, c3, c4…ck} is a set of classes– in our case only two classes i.e. C={“SPAM”, “LEGITIMATE”}.
• P(C=ck | X = x) = P(X=x | C=ck ) * P(C=ck ) / P(X=x)– assumption is made that each feature is independent from other
• P(SPAM | “online credit $”) = P(“online”|SPAM) * P(“credit”|SPAM) * P(“$”|SPAM) *
P(SPAM) /
P(“online”) * P(“credit”) * P(“$”)

16
Classification (Naïve Bayes)
• P(CSPAM | x1,x2,x3…xn) = P(x1,x2,x3…xn | CSPAM)*P(SPAM) / P(x1,x2,x3…xn)
• Prior probability– Let us say we observe 35% of emails as junk/spam
• P(SPAM)=0.35 and P(LEGITIMATE)=0.65
• Posterior probability (for Spam)– Is conditional probability of certain features in certain
class P(x1,x2,x3…xn | CSPAM) [assumption of independence of features]
n
i
SPAMixp1
| )(

17
Classifier
• Finally we classify – If the mail is a Spam?
• P(SPAM | X) / P(LEGITIMATE | X) >= • Choice of depends on the “cost” we imply on
misclassification (as a threshold)
– What’s cost?• Classifying an important email as SPAM is worse
• Classifying a SPAM as email is not that worst!

18
Experiments• Used features selection to decrease dimensions of
features/data
• Corpus of 1789 actual (1578 junks, 211 legitimate)
• Features from the text tokens
– removed too rare tokens
– Added about 35 hand-crafted phrase features
– 20 non textual domain specific features
– Non-Alphanumeric characters and percentage of numeric were handy indicators
– Top 500 features according to Mutual Info between classes and features (greater this value )

19
Evaluation?
• How to know how good is our classifier?– Calculate precision and recall!
• Precision is percentage of emails classified as SPAM, that are in fact SPAM
• Recall is percentage of all SPAM emails that are correctly classified as SPAM
Ideal precision/recall curve
1
1
0 Recall
Precision

20
Results

21
Conclusion
• It is very successful to use automatic filter
• Hand-crafted features enhance performance
• Success in this problem is confirmation that the technique can be used in other text categorization tasks.
• Spam filter could be enhanced to classify other types of emails like “business”, “friends” (subclasses).

22
Discussion• What are we classifying? (Objects)• What are the features?
– What could be the features?
• Bayesian classification– Strong and weak points– Possible improvements?– Why Bayesian instead of other methods?– What are the questionable assumptions?
• Subclasses?• How to control error loss?
– When a normal email is moved to trash… or a junk mail in the inbox?

23
Merci, Danke, Muchas Gracias, Ačiu, شكريه
• All of you are very patient, thank you!• Special thanks to Irene
– For such an opportunity to talk about classification– Her hard work & help for me to prepare this talk
• Thanks Sabine, Stefan for conducting this seminar
• Thank you (for support): – Imran Rauf http://www.mpi-sb.mpg.de/~irauf/
– Habib Ur Rahman (“ دا نشت اضط (”حبيب• and now?…maybe thanks to spammers also

24
References
Sahami et al; " A Bayesian Approach to Filtering Junk E-Mail” 1998
Manning, Schütze: “Foundations of Statistical Natural Language Processing”, 2000.

25
Extra slides
• ;) oder …

26
• What are we classifying? (Objects)– Emails (to be classified as “normal” or “Spam”)
• What are the features? “indicator for any class”– What could be the features? “words, phrases, headers”
• Naïve Bayesian classification– Strong and weak points
• High throughput, simple calculation,
• Assumption of independent features might not always hold truth
– Possible improvements?• ??? Detect feature dependency
– Why Bayesian instead of other methods?• See strong points

27
– What are the questionable assumptions?• “features are independent of each other”
• Subclasses?– Emails could be classified in subclasses:
» SPAM “PORNO_SPAM”, “BUSINESS_SPAM”
» LEGITIMATE “BUSINESS”, “APPOINTMENTS”.. etc
• How to control error loss?– When a normal email is moved to trash… or a
junk mail in the inbox?

28
Bayesian networks
CLASS
x1 x2 x3 ... xn
-nodes influence parent
-features are independent
CLASS
x1 x2 x3 ... xn
-nodes influence parent & siblings
-features are dependent